

目标检测——YOLO算法解读(通俗易懂版)
yolo算法通俗易懂版本解读
论文:You Only Look Once: Unified, Real-Time Object Detection
作者:Joseph Redmon, Santosh Divvala, Ross Girshick, Ali Farhadi
链接:https://arxiv.org/abs/1506.02640
代码:http://pjreddie.com/yolo/
yolo系列检测算法开山之作,通过仔细研读论文及代码,尝试用通俗简单的文字来解读一下yolo检测算法的思想
YOLO系列算法解读:
PP-YOLO系列算法解读:
1、算法概述
之前的检测算法,例如R-CNN系列都是将检测当作分类来看待(通过算法遍历或者学习得到候选框,然后分类),但是YOLO算法将检测看作回归问题来解决,整个过程是一个端到端的过程,速度相较于前面的检测算法有非常大的提升,单张图片推理速度达到45帧/秒,Fast YOLO版本可以达到155帧/秒。

文章创新点:
1、由于检测被看作是回归问题,所以网络结构非常简单,图片只需经过一次网络前向推理就可以得到最终的预测框及类别。
2、yolo是基于全局图片进行推理,不像滑窗和region proposal-base算法那样只是基于感兴趣区域做推理。由于yolo训练和推理都是基于整张图片,而Fast R-CNN是基于局部感兴趣区域训练,所以它将背景误认为目标的错误较多,yolo相对于Fast R-CNN的背景误报少了一半。
3、yolo能学习到目标的通用化表示特征,相较于其他之前的检测算法如DPM、R-CNN系列,泛化性能更强。
不足之处:YOLO在精度上仍然落后于最先进的检测算法。虽然它可以快速识别图像中的目标,但很难精确定位某些目标,尤其是小目标。
2、YOLO细节
2.1 由分类到检测

分类任务中,上图经过卷积神经网络,最终输出one-hot向量,假如分类类别为10类(猫为第二个类别),则图片的类别预测过程为:image->conv+bn+relu+pooling->…->fc(10)->one-hot向量,我们期望得到0100000000的输出结果,该输出结果是一个向量。
而对于检测任务,对于上图中的单个目标单个类别而言,其实也是输出一个向量,如下:

该目标框可以用(cx,cy,w,h)来表示,其中(cx,cy)是矩形框中心点坐标,w,h是矩形框的宽高;当然,也可以用(x1,y1,w,h)或者(x1,y1,x2,y2)等方式来表示,其中(x1,y1)代表矩形框左上角点坐标,(x2,y2)代表矩形框右下角点坐标。但说到底,这些表示矩形框的形式都是一个向量,所以对于这种单类别单目标的检测任务,就可以看成分类一样,image->conv+bn+relu+pooling->…->fc(5)->(c,cx,cy,w,h),其中c表示这个框是否是目标的概率,也叫目标置信度。
如何训练这种单类别单目标的检测任务呢?
找上千张类似上图这种图片中单个猫的图片标注,图片标签设置为(1,cx*,cy*,w*,h*),1代表图片中的标注是存在真实目标的,(cx*,cy*,w*,h*)代表标注目标的groundtruth,这样就可以通过网络conv+bn+relu+pooling->…->fc(5)输出的预测值(c,cx,cy,w,h)与groundtruth标注(1,cx*,cy*,w*,h*)通过常用的均方误差或者平方和误差完成网络的训练。
注意这种方式从本质上区别于R-CNN系列的区域候选框加分类的检测方式,传统的检测方法包括R-CNN系列本质上都是训练一个二分类器用于对候选框区分背景/前景,然后进行bounding box微调。候选框的选取,传统方式有滑动窗口,R-CNN,Fast R-CNN用的Selective Search,Fast R-CNN用的RPN网络学习出来的。而上面提到的方式是直接通过网络回归出目标框,简单很多。如下图对比效果

上一种是单个类别单个目标的情况,下面上难度,对于如下单类别多目标的情况又该如何?

根据全卷积网络思想,特征图区域和原图区域在空间位置上是对应关系,所以对于这种单类别多目标的图片,我们可以“分而治之”,将上图横竖切分成4个区域,每个区域就是单类别单目标这种简单形式了,效果如下:
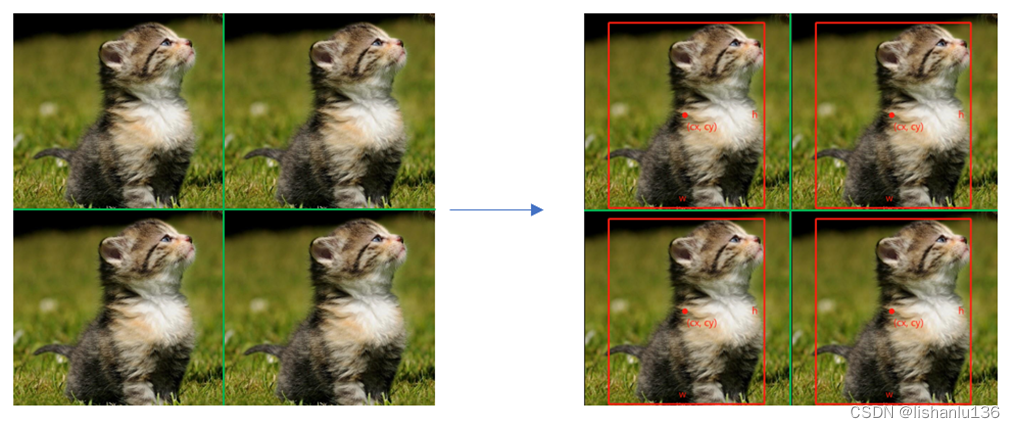
所以网络输出形式由单个目标变成多个目标就成为了如下形式:

对于如下图比较复杂的多目标情况,我们可以切分得更细,例如4x4,输出16个矩形框来预测目标,如下:
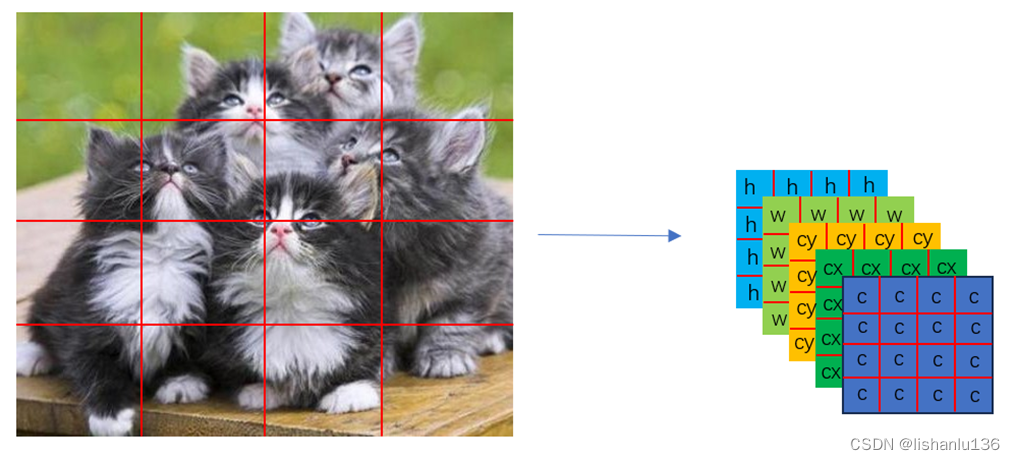
图中只有5只猫,我们用16个矩形框来预测,显然是冗余的,但是最终输出的预测框,只要c值置信度未达到我们设置的阈值,我们最终会视为此区域不包含目标,例如上图最左上角区域。针对上图这种复杂的多目标,我们该如何确定具体哪个区域负责回归哪个目标呢?yolo给的回答是目标的groundtruth矩形框的中心点落在哪个区域,哪个区域就负责回归这个目标,如在上图检测猫头的任务对应的区域c值设置为:

左上角区域我们设置groundtruth时c值为0,代表背景,此区域在训练过程中也就不需要回归矩形框。
介绍到这里,虽然举的例子还是比较简单,但是有点yolo的雏形了。针对于更广泛的情况:1、划分的区域中存在多个目标怎么办?(即多个groundtruth标注框中心点落在同一个区域),2、目标存在多个类别怎么办? 这些才是常见目标检测任务遇到的情况,这也是上述例子的推广,针对这些情况的处理方式都将在yolo中得到体现。
2.2 YOLO网络设计
根据2.1节提到的例子推广第一种情况:划分的区域中存在多个目标怎么办?
简单的做法,我们可以把区域划分得更细,这样就能减少多个groundtruth标注框中心点落在同一个区域的概率,但这种做法治标不治本,划分得多细也没有定论。YOLO的做法是将图片切分成7x7大小的区域,每个区域设置两个bounding box用于匹配落在同一区域的多个groundtruth,所以这也导致了YOLO最多预测98个(7x7x2)矩形框输出。
针对推广的第二种情况:目标存在多类别怎么办?
YOLO的做法是对每个区域做softmax分类即可。
YOLO网络设计的弊端:虽然一个区域设置两个bounding box匹配groundtruth用于适应不同尺度目标,但是一个区域只能预测一个类别,若真的在一个区域出现两个目标,即使两个bounding box都预测到了,根据类别限制也只能取一个。综上所述,yolo的基本思想就是“分而治之”,它将图片切分成7x7大小的区域块,然后每个区域设置两个bounding box以适应不同尺度的目标,再在每个区域中去回归目标框。
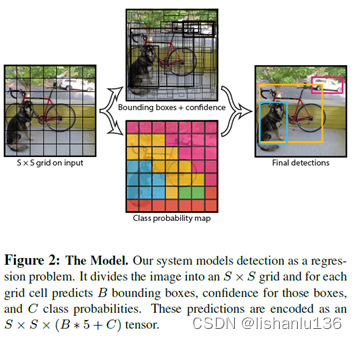
针对于VOC数据设计的YOLO最后输出tensor为7x7x(2x5+20),20代表VOC数据集的类别,不包含背景类。YOLO网络是基于GoogLeNet设计的,总共包含24个卷积层和两个全连接层;Fast YOLO只含有9个卷积层和更少的卷积核,YOLO网络结构如下图:
2.3 YOLO训练过程
有监督的预训练,GoogLeNet用ImageNet1000-class数据集预训练得到top-5精度88%的模型,取前20个卷积层然后接average-pooling和全连接层。对于检测任务,输入由原来的224x224调整到448x448。
输出设置,针对最后一层的概率输出和预测框输出,都归一化到0-1,宽高wh是矩形框宽高与图像的宽高比值,预测框x,y是相对于该区域格子位置的偏移量,所以也是0-1的范围。
损失函数设置,网络最后一层采用线性激活函数,误差采用平方和误差(sum-squared error)。为了处理正负样本不平衡问题,作者将有目标的回归损失和没目标的noobj损失设置了权重,分别为5和0.5。由于平方和误差针对大目标和小目标的权重是一样的,但是目标检测任务需要的是小目标框对小偏差比大目标对小偏差更加敏感,这样才能加大对小目标的学习力度,所以作者对bounding box做了开根号处理。损失函数公式如下:

如何确定区域块(grid)内哪个bounding box负责预测groundtruth?
答:groundtruth中心点落入这个grid内,该grid内的所有bounding box和该groundtruth做IoU,最大IoU对应的bounding box负责预测该groundtruth。
训练设置,基于VOC2007和2012数据集训练了135个epochs,batchsize设置为64,momentum设置0.9,decay设置为0.0005。学习率根据epochs调节:第一个epoch采用10-3->10-2,然后直到75个epoch都采用10-2,75到105个epoch采用10-3,最后105到135采用10-4。为了避免过拟合,作者也采用了dropout和数据增强,dropout rate设置为0.5,数据增强引入了原始图像大小的20%的随机缩放和平移和HSV空间的最高1.5倍的随机调整曝光度和饱和度。
2.4 YOLO推理过程
就像前面描述的那样,网络预测每张图像的98个边界框和每个框的类概率。YOLO的网格设计在边界框预测中加强了空间多样性,通常情况下,一个对象目标落在哪个网格单元是很清楚的,网络也只会预测每个对象的一个框。但是针对于大的同时跨越几个grid cell的目标对象,通常需要用nms(非极大值抑制,Non-maximal suppression)来合并重复预测框了。
2.5 YOLO的限制
YOLO对边界框预测施加了很强的空间约束,因为每个网格单元只能预测两个框,并且只能有一个类。这个空间约束限制了YOLO模型可以预测的附近物体的数量,YOLO模型难以处理成群出现的小物体,比如鸟群。由于预测的bounding box(也就是后面的anchor)设置是基于VOC数据集得到的,所以难以推广到其他宽高比的目标对象。网络结构包含多个下采样,用于预测边界框的特征比较粗糙,后续期待更强的主干网络。
3、实验结果
YOLO与近期Real-Time算法在VOC2007数据集上比较结果如下:
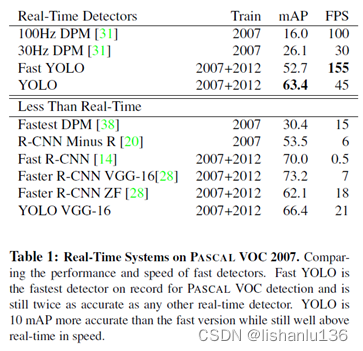
与传统检测算法相比,YOLO在mAP和速度方面都有很大提升,与R-CNN系列深度学习方法相比,都用VGG-16作为主干网络的情况下,mAP有一定差距,但是速度提升很大。
YOLO在VOC2012竞赛上的榜单情况如下:
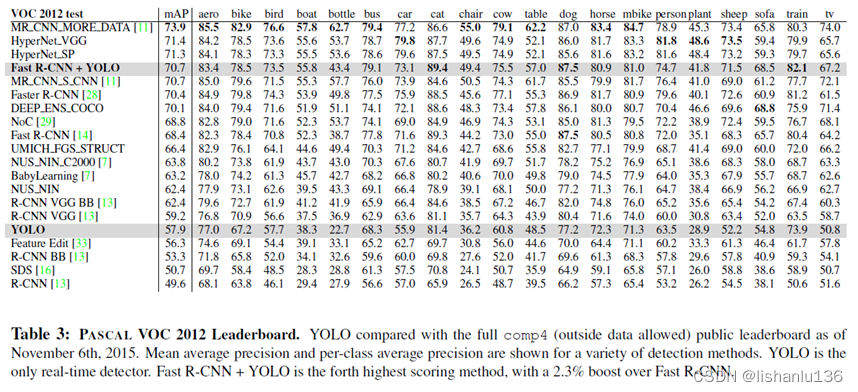
可以看到YOLO算法距离top算法的mAP还有一定差距,特别是在小目标问题上,例如瓶子、羊和电视/监视器等类别。
4、创新点和不足
- 创新点:
1、利用“分而治之”的思想,将检测任务当做回归问题看待,一次完成全部的检测工作,速度极快。
2、基于整张图片提取特征,相比R-CNN系列采用的局部特征得到的背景误报情况少很多。 - 不足:
1、精度相对于R-CNN系列的二阶段检测方法还是有差距,直接预测矩形框坐标的方式不及R-CNN系列基于提议框预测偏移量的方式;
2、网络最终输出的预测框数量限制于区域网络数的设置及bounding box数量设置,对检测密集目标效果不好,对检测小目标也不好;
3、bounding box依照数据集中目标而定,所以难以推广到其他目标,其他目标的话需要修改bounding box的宽高比。
4、YOLO主干网络提取特征能力不足,后续需要改进。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)