
使用SPSS进行简单的数据分析(数据+报告+过程)
使用SPSS进行数据分析的全过程。包括数据导入、数据设定、数据统计和数据分析。
一、准备数据
本次分析采用的是居民健康状况数据,数据有编号、身高、体重、代谢综合症、性别、胆固醇。
变量视图:

数据视图: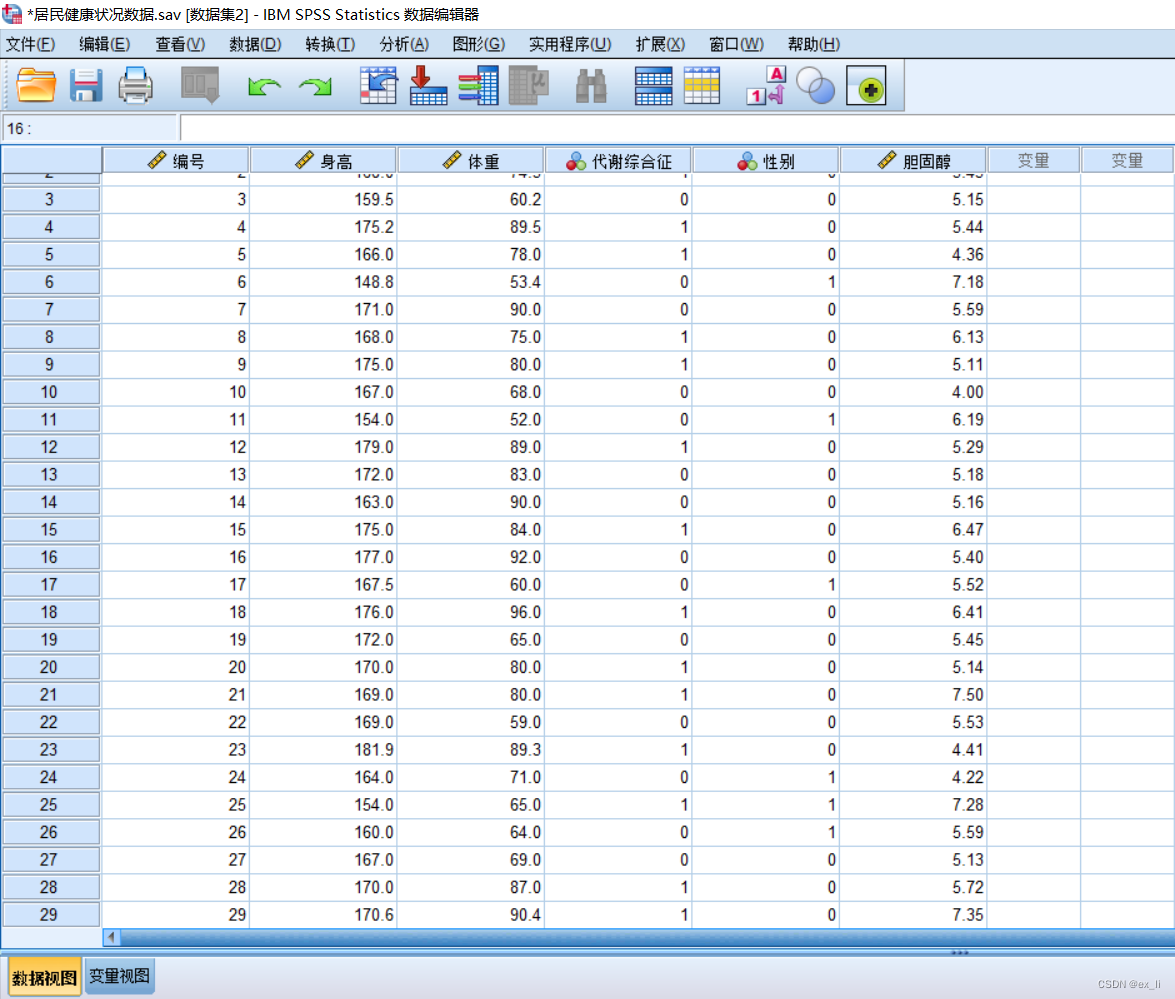
计算BMI变量:

根据BMI值评判个人健康状况,新增评判结果变量,如果值为1,正常;为2,过轻;为3,肥胖。

二、数据分析:
(1)简单的统计分析
选中性别列,鼠标右击,点击描述统计,可以得到描述统计分析


交叉表:分析-描述统计-交叉表
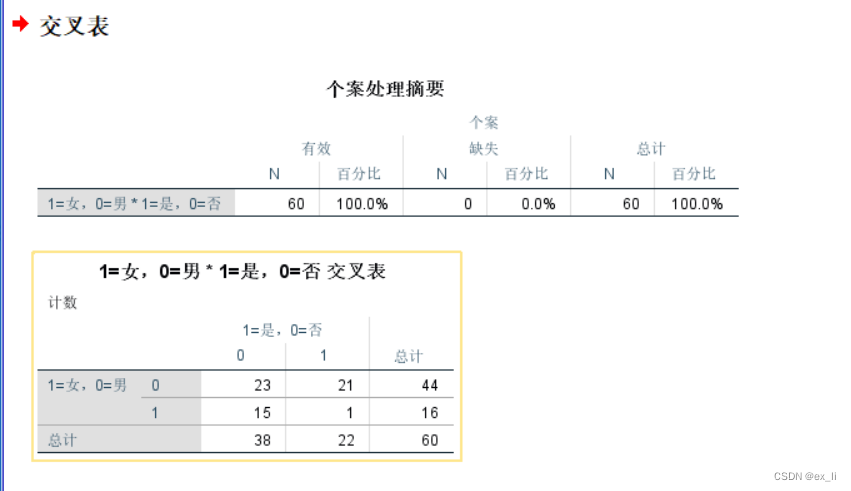
(2)交叉频数分布
分析-描述统计-交叉表

(3)复杂的交叉频数分布表
分析-描述统计-交叉表

(4)条形图
图形-旧对话框-条形图-简单(选择个案组摘要)

双击-元素-显示数据标签
(5)簇状条形图
图形-旧对话框-条形图-簇状(选择个案组摘要)
(6)堆积条形图
图形-旧对话框-条形图-堆积(选择个案组摘要)
(7)饼图
图形-旧对话框-饼图(选择个案组摘要)。选择分类变量到分区定义依据。
(8)直方图
图形-旧对话框-直方图-变量处选择身高或者体重。
双击-元素-显示分布曲线

(9)茎叶图
分析-描述统计-探索

(10)箱线图
图形-旧对话框-箱线图-简单-确定。生成图之后点击中间横线-右击-显示数据标签。
(11)散点图
图形-旧对话框-散点图-简单散点图-(X轴身高,Y轴体重)-确定。双击图像-元素-总计拟合线。
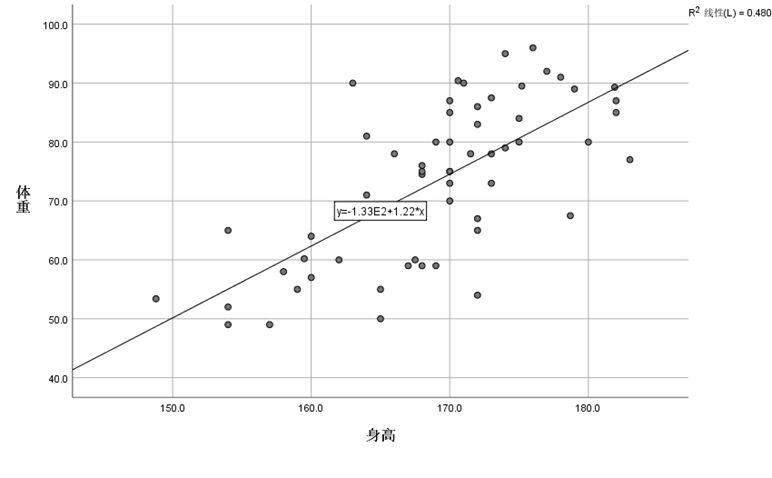
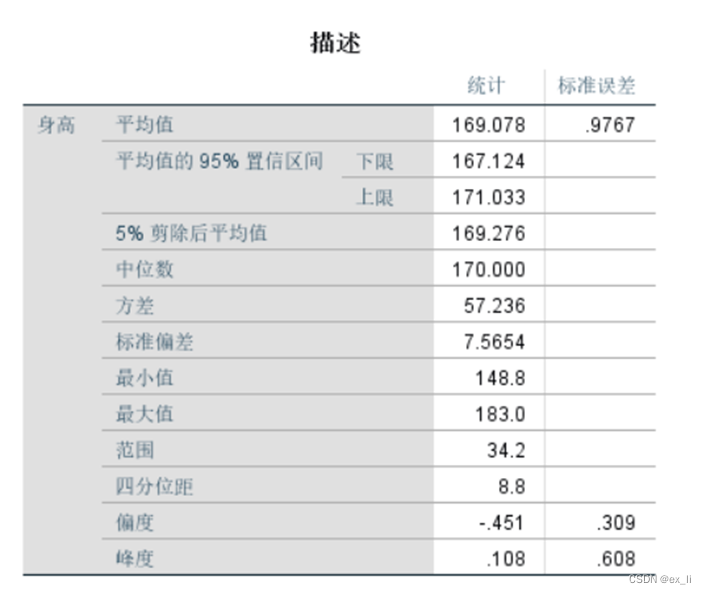
(12)描述统计量
分析-描述统计-探索-因变量为身高-统计中选描述-选项中选成列排除个案-确定
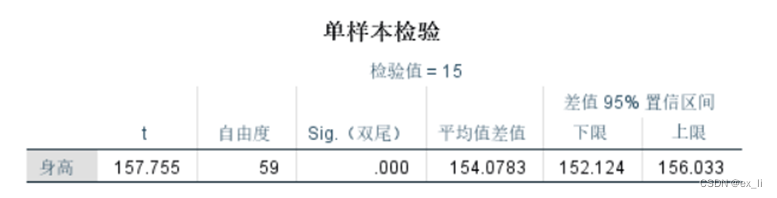
(13)参数估计
分析-比较平均值-单样本T检验-选择身高--检验值为0-确定

(14)假设检验
分析-比较平均值-单样本T检验-选择身高-检验值设置数值-确定
(15)拟合优度检验(卡方检验)
分析-非参数检验-旧对话框-卡方-选择“评判结果”-确定

原假设:无显著差异。渐近显著性水平(P值)。由于P=0.000<a=0.05,因此拒绝原假设,表明居民身体健康状况的评判结果的偏好表现出显著差异。
(16)独立性检验
分析-描述统计-交叉表-统计(按照下面设定)-单元格计数中选择实测和期望-确定



由于P<a,因此拒绝原假设,认为居民身体健康状况评判结果与性别不独立,或者说居民身体健康状况评判结果与性别有关。从几个数值的值来看,BMI指数,也即肥胖跟男女性别有关系。
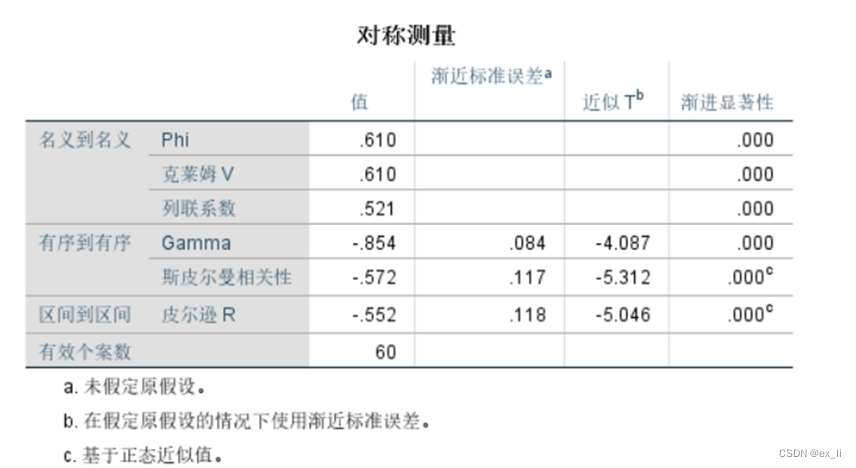
上图为相关性测量。相关性度量中的Phi值、克莱姆 V以及列连系数显著性检验结果均显著,这表明肥胖性与性别两个变量不独立,即它们之间存在显著的相关性。
以上就是使用SPSS进行数据分析的全过程。包括数据导入、数据设定、数据统计和数据分析。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)