

哦耶!冲进小米了!
程序计数器:每个线程都有一个程序计数器。当线程执行 Java 方法时,程序计数器保存当前执行指令的地址,以便在 JVM 调用其他方法或恢复线程执行时重新回到正确的位置。Java 虚拟机栈:每个线程都有一个虚拟机栈。虚拟机栈保存着方法执行期间的局部变量、操作数栈、方法出口等信息。线程每调用一个 Java 方法时,会创建一个栈帧(Stack Frame),栈帧包含着该方法的局部变量、操作数栈、方法返回
今天就跟大家分享小米的Java 开发的面经,面试问题全都是 Java 问题,一共 10 来个问题,相比于互联网大厂面试难度是小了一点。

小米面经
ArrayList和LinkedList的区别?
-
底层数据结构:ArrayList使用数组作为底层数据结构,而LinkedList使用双向链表作为底层数据结构
-
随机访问性能:ArrayList支持通过索引直接访问元素,因为底层数组的连续存储特性,所以时间复杂度为O(1)。而LinkedList需要从头或尾部开始遍历链表,时间复杂度为O(n)。
-
插入和删除操作:ArrayList在尾部插入和删除元素的时间复杂度为O(1),因为它只需要调整数组的长度即可。但在中间或头部插入和删除元素时,需要将后续元素进行移动,时间复杂度为O(n)。而LinkedList在任意位置插入和删除元素的时间复杂度为O(1),因为只需要调整节点的指针即可。
-
内存占用:ArrayList在每个元素中都存储了实际的数据,而LinkedList在每个节点中存储了数据和前后节点的指针。因此,相同数量的元素情况下,LinkedList通常比ArrayList占用更多的内存空间。
hashmap的put过程,说一下扩容机制
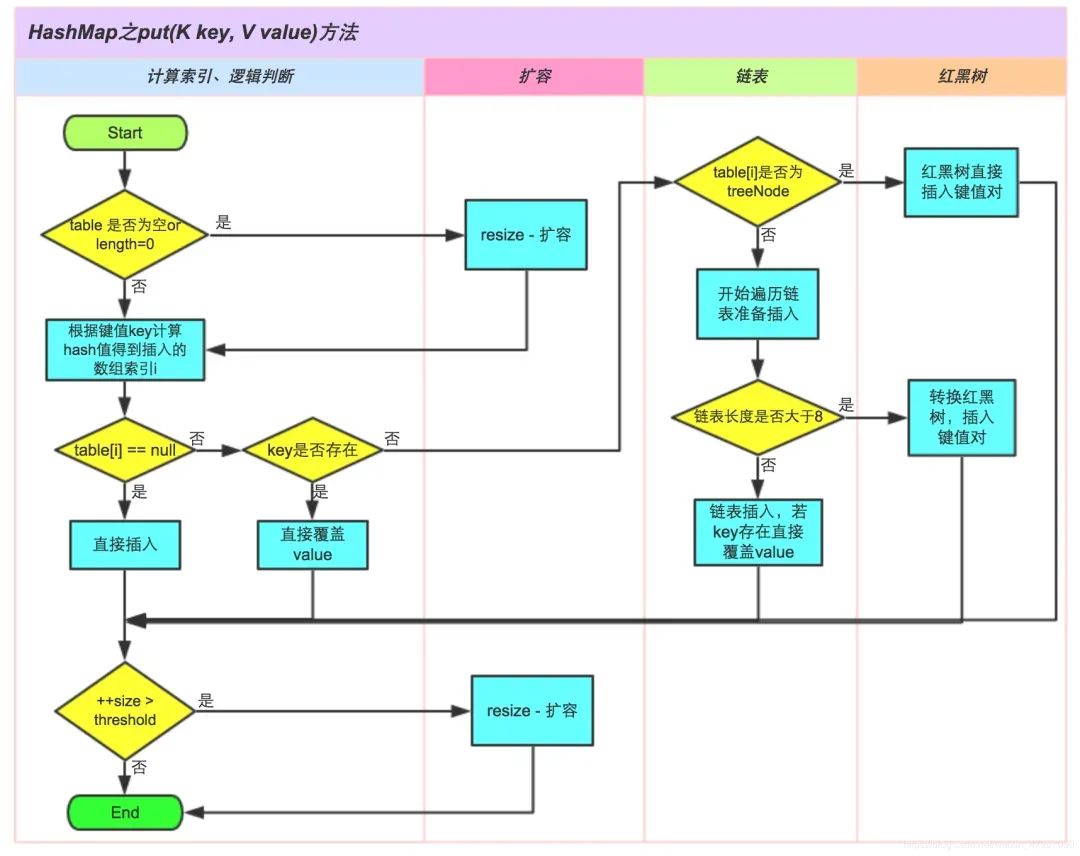
HashMap HashMap的put()方法用于向HashMap中添加键值对。当调用HashMap的put()方法时,会按照以下详细流程执行:
第一步:根据要添加的键的哈希码计算在数组中的位置(索引)。
第二步:检查该位置是否为空(即没有键值对存在)
-
如果为空,则直接在该位置创建一个新的Entry对象来存储键值对。将要添加的键值对作为该Entry的键和值,并保存在数组的对应位置。将HashMap的修改次数(modCount)加1,以便在进行迭代时发现并发修改。
第三步:如果该位置已经存在其他键值对,检查该位置的第一个键值对的哈希码和键是否与要添加的键值对相同?
-
如果相同,则表示找到了相同的键,直接将新的值替换旧的值,完成更新操作。
第四步:如果第一个键值对的哈希码和键不相同,则需要遍历链表或红黑树来查找是否有相同的键:
如果键值对集合是链表结构:
-
从链表的头部开始逐个比较键的哈希码和equals()方法,直到找到相同的键或达到链表末尾。
-
如果找到了相同的键,则使用新的值取代旧的值,即更新键对应的值。
-
如果没有找到相同的键,则将新的键值对添加到链表的头部。
如果键值对集合是红黑树结构:
-
在红黑树中使用哈希码和equals()方法进行查找。根据键的哈希码,定位到红黑树中的某个节点,然后逐个比较键,直到找到相同的键或达到红黑树末尾。
-
如果找到了相同的键,则使用新的值取代旧的值,即更新键对应的值。
-
如果没有找到相同的键,则将新的键值对添加到红黑树中。
第五步:检查链表长度是否达到阈值(默认为8):
-
如果链表长度超过阈值,且HashMap的数组长度大于等于64,则会将链表转换为红黑树,以提高查询效率。
第六步:检查负载因子是否超过阈值(默认为0.75):
-
如果键值对的数量(size)与数组的长度的比值大于阈值,则需要进行扩容操作。
第七步:扩容操作:
-
创建一个新的两倍大小的数组。
-
将旧数组中的键值对重新计算哈希码并分配到新数组中的位置。
-
更新HashMap的数组引用和阈值参数。
第八步:完成添加操作。
需要注意的是,HashMap中的键和值都可以为null。此外,HashMap是非线程安全的,如果在多线程环境下使用,需要采取额外的同步措施或使用线程安全的ConcurrentHashMap。
hashmap为啥线程不安全?
-
JDK 1.7 HashMap 采用数组 + 链表的数据结构,多线程背景下,在数组扩容的时候,存在 Entry 链死循环和数据丢失问题。
-
JDK 1.8 HashMap 采用数组 + 链表 + 红黑二叉树的数据结构,优化了 1.7 中数组扩容的方案,解决了 Entry 链死循环和数据丢失问题。但是多线程背景下,put 方法存在数据覆盖的问题。
hashmap 调用get方法一定安全吗?
不是,调用 get 方法有几点需要注意的地方:
-
*空指针异常(NullPointerException)**:如果你尝试用
null作为键调用get方法,而HashMap没有被初始化(即为null),那么会抛出空指针异常。不过,如果HashMap已经初始化,使用null作为键是允许的,因为HashMap支持null键。 -
线程安全:
HashMap本身不是线程安全的。如果在多线程环境中,没有适当的同步措施,同时对HashMap进行读写操作可能会导致不可预测的行为。例如,在一个线程中调用get方法读取数据,而另一个线程同时修改了结构(如增加或删除元素),可能会导致读取操作得到错误的结果或抛出ConcurrentModificationException。如果需要在多线程环境中使用类似HashMap的数据结构,可以考虑使用ConcurrentHashMap。
currentHashMap为啥线程安全?
JDK 1.7 ConcurrentHashMap
在 JDK 1.7 中它使用的是数组加链表的形式实现的,而数组又分为:大数组 Segment 和小数组 HashEntry。
Segment 是一种可重入锁(ReentrantLock),在 ConcurrentHashMap 里扮演锁的角色;HashEntry 则用于存储键值对数据。一个 ConcurrentHashMap 里包含一个 Segment 数组,一个 Segment 里包含一个 HashEntry 数组,每个 HashEntry 是一个链表结构的元素。
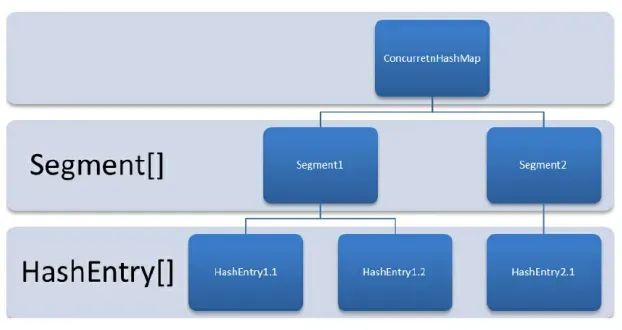
分段锁技术将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问,能够实现真正的并发访问。
JDK 1.8 ConcurrentHashMap
在 JDK 1.7 中,ConcurrentHashMap 虽然是线程安全的,但因为它的底层实现是数组 + 链表的形式,所以在数据比较多的情况下访问是很慢的.
因为要遍历整个链表,而 JDK 1.8 则使用了数组 + 链表/红黑树的方式优化了 ConcurrentHashMap 的实现,具体实现结构如下:
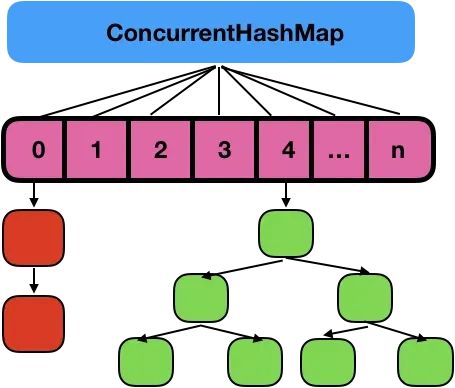
JDK 1.8 ConcurrentHashMap 主要通过 volatile + CAS 或者 synchronized 来实现的线程安全的。
添加元素时首先会判断容器是否为空:
-
如果为空则使用 volatile 加 CAS 来初始化
-
如果容器不为空,则根据存储的元素计算该位置是否为空。
-
如果根据存储的元素计算结果为空,则利用 CAS 设置该节点;
-
如果根据存储的元素计算结果不为空,则使用 synchronized ,然后,遍历桶中的数据,并替换或新增节点到桶中,最后再判断是否需要转为红黑树,这样就能保证并发访问时的线程安全了。
-
如果把上面的执行用一句话归纳的话,就相当于是ConcurrentHashMap通过对头结点加锁来保证线程安全的,锁的粒度相比 Segment 来说更小了,发生冲突和加锁的频率降低了,并发操作的性能就提高了。
而且 JDK 1.8 使用的是红黑树优化了之前的固定链表,那么当数据量比较大的时候,查询性能也得到了很大的提升,从之前的 O(n) 优化到了 O(logn) 的时间复杂度。
synchronized和reetrantlock区别是什么?
synchronized 和 ReentrantLock 都是 Java 中提供的可重入锁:
-
用法不同:synchronized 可用来修饰普通方法、静态方法和代码块,而 ReentrantLock 只能用在代码块上。
-
获取锁和释放锁方式不同:synchronized 会自动加锁和释放锁,当进入 synchronized 修饰的代码块之后会自动加锁,当离开 synchronized 的代码段之后会自动释放锁。而 ReentrantLock 需要手动加锁和释放锁
-
锁类型不同:synchronized 属于非公平锁,而 ReentrantLock 既可以是公平锁也可以是非公平锁。
-
响应中断不同:ReentrantLock 可以响应中断,解决死锁的问题,而 synchronized 不能响应中断。
-
底层实现不同:synchronized 是 JVM 层面通过监视器实现的,而 ReentrantLock 是基于 AQS 实现的。
reetrantlock的实现原理说一下?
ReentrantLock的可重入功能基于AQS的同步状态:state。其原理大致为:当某一线程获取锁后,将state值+1,并记录下当前持有锁的线程,再有线程来获取锁时,判断这个线程与持有锁的线程是否是同一个线程:
-
如果是,将state值再+1
-
如果不是,阻塞线程。当线程释放锁时,将state值-1,当state值减为0时,表示当前线程彻底释放了锁,然后将记录当前持有锁的线程的那个字段设置为null,并唤醒其他线程,使其重新竞争锁。
// acquires的值是1
final boolean nonfairTryAcquire(int acquires) {
// 获取当前线程
final Thread current = Thread.currentThread();
// 获取state的值
int c = getState();
// 如果state的值等于0,表示当前没有线程持有锁
// 尝试将state的值改为1,如果修改成功,则成功获取锁,并设置当前线程为持有锁的线程,返回true
if (c == 0) {
if (compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
// state的值不等于0,表示已经有其他线程持有锁
// 判断当前线程是否等于持有锁的线程,如果等于,将state的值+1,并设置到state上,获取锁成功,返回true
// 如果不是当前线程,获取锁失败,返回false
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0) // overflow
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
jvm内存结构介绍一下
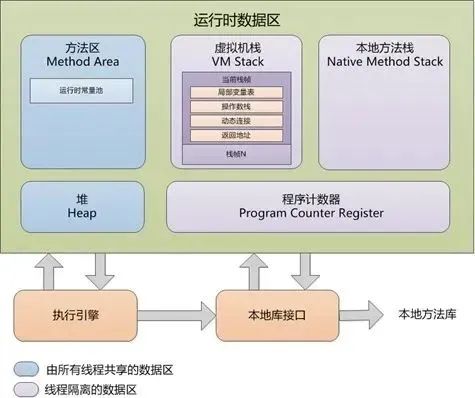
JVM的内存结构主要分为以下几个部分:
-
程序计数器:每个线程都有一个程序计数器。当线程执行 Java 方法时,程序计数器保存当前执行指令的地址,以便在 JVM 调用其他方法或恢复线程执行时重新回到正确的位置。
-
Java 虚拟机栈:每个线程都有一个虚拟机栈。虚拟机栈保存着方法执行期间的局部变量、操作数栈、方法出口等信息。线程每调用一个 Java 方法时,会创建一个栈帧(Stack Frame),栈帧包含着该方法的局部变量、操作数栈、方法返回地址等信息。栈帧在方法执行结束后会被弹出。
-
本地方法栈:与 Java 虚拟机栈类似,但是为本地方法服务。
-
Java 堆:Java 堆是 Java 虚拟机中最大的一块内存区域,用于存储各种类型的对象实例,也是垃圾收集器的主要工作区域,Java 堆根据对象存活时间的不同,Java 堆还被分为年轻代、老年代两个区域,年轻代还被进一步划分为 Eden 区、From Survivor 0、To Survivor 1 区。
-
方法区:方法区也是所有线程共享的部分,它用于存储类的加载信息、静态变量、常量池、方法字节码等数据。在 Java 8 及以前的版本中,方法区被实现为永久代(Permanent Generation),在 Java 8 中被改为元空间(Metaspace)。
垃圾回收算法有哪些?
-
标记-清除算法:标记-清除算法分为“标记”和“清除”两个阶段,首先通过可达性分析,标记出所有需要回收的对象,然后统一回收所有被标记的对象。标记-清除算法有两个缺陷,一个是效率问题,标记和清除的过程效率都不高,另外一个就是,清除结束后会造成大量的碎片空间。有可能会造成在申请大块内存的时候因为没有足够的连续空间导致再次 GC。
-
复制算法:为了解决碎片空间的问题,出现了“复制算法”。复制算法的原理是,将内存分成两块,每次申请内存时都使用其中的一块,当内存不够时,将这一块内存中所有存活的复制到另一块上。然后将然后再把已使用的内存整个清理掉。复制算法解决了空间碎片的问题。但是也带来了新的问题。因为每次在申请内存时,都只能使用一半的内存空间。内存利用率严重不足。
-
标记-整理算法:复制算法在 GC 之后存活对象较少的情况下效率比较高,但如果存活对象比较多时,会执行较多的复制操作,效率就会下降。而老年代的对象在 GC 之后的存活率就比较高,所以就有人提出了“标记-整理算法”。标记-整理算法的“标记”过程与“标记-清除算法”的标记过程一致,但标记之后不会直接清理。而是将所有存活对象都移动到内存的一端。移动结束后直接清理掉剩余部分。
-
分代回收算法:分代收集是将内存划分成了新生代和老年代。分配的依据是对象的生存周期,或者说经历过的 GC 次数。对象创建时,一般在新生代申请内存,当经历一次 GC 之后如果对还存活,那么对象的年龄 +1。当年龄超过一定值(默认是 15,可以通过参数 -XX:MaxTenuringThreshold 来设定)后,如果对象还存活,那么该对象会进入老年代。
新生代用的垃圾回收算法呢?
主要使用的是“复制算法”。这个算法的基本思想是将新生代分为一个较大的Eden空间和两个较小的Survivor空间(分别称为From和To),初始时对象首先分配在Eden区。
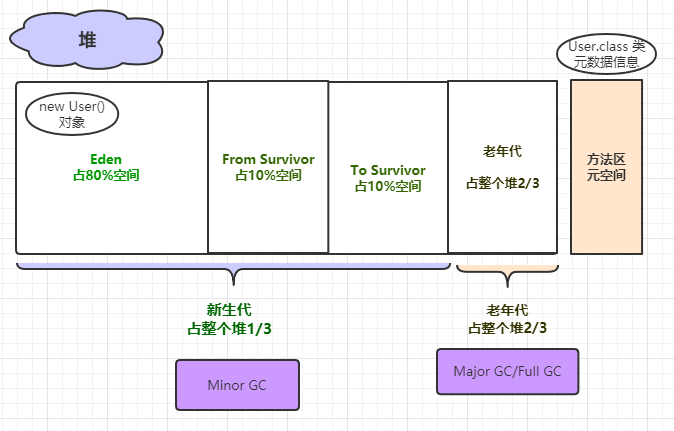
当进行垃圾回收时,存活的对象会从Eden区和一个Survivor区(From)复制到另一个Survivor区(To),同时清理掉Eden区和From区内的所有对象,包括已经死亡的对象。在复制过程中,还会进行对象的年龄判定,当对象的年龄达到一定阈值后,会被晋升到老年代。每次垃圾回收后,From区和To区会交换角色,以保持算法的持续进行。
复制算法的优点是实现简单,运行高效,特别适用于新生代中对象生命周期短、死亡率高的场景。不过,它的缺点是需要额外的空间作为复制的目标区域,因此空间利用率相对较低。不过,在新生代中,由于每次回收都会有大量对象被清理,这种空间利用率的损失是可以接受的。
强引用,软引用,弱引用,虚引用的区别是什么?
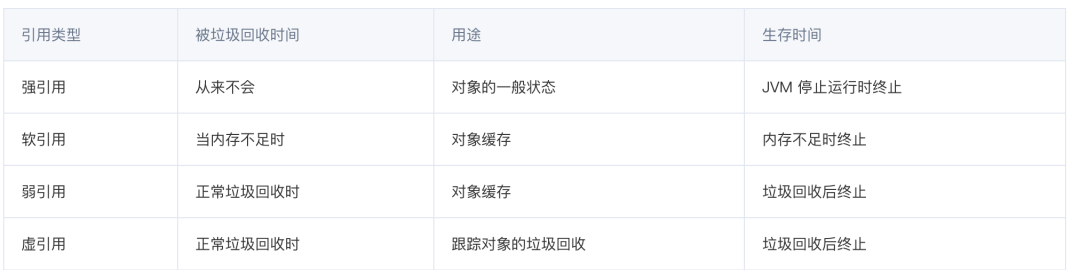
不同的引用类型,主要体现的是对象的不同的可达性(reachable)状态和对垃圾收集的影响。
-
强引用:就是我们常见的普通对象引用,只要还有强引用指向一个对象,就能表明对象还活着,垃圾回收不回收这种对象。
-
软引用:是一种相对强引用弱化一些的引用,只有当 JVM 认为内存不足时,才会试图回收软引用指向的对象。JVM 会确保在排除 OutOfMemoryError 之前,清理软引用指向的对象,软引用通常用来实现内存敏感的缓存,如果还有空闲内存,就可以暂时保留缓存,当内存不足时,清理掉,这样就保证了使用缓存的同时,不会耗尽内存。
-
弱引用:比软引用拥有更短的生命周期,在垃圾回收线程扫码所管辖的内存区域的过程中,一大发现了只具有弱引用的对象,不管当前内存空间是否足够,都会回收它的内存,由于垃圾回收器是一个优先级,因此不一定很快发现那些只有弱引用的对象。
-
虚引用:形同虚设 ,虚引用不会决定对象的生命周期,如果一个对象仅持有虚引用,其实就和没有任何引用一样。在任何时候都可能被垃圾回收器回收。虚引用和软引用的一个区别是,虚引用必须和引用队列(ReferenceQueue)联合使用。当垃圾回收器准备回收一个对象时,如果发现它还有虚引用,就会在回收对象的内存之前,把这个虚引用加入到与之关联的引用队列中。
redis持久化机制有哪些?
Redis 的读写操作都是在内存中,所以 Redis 性能才会高,但是当 Redis 重启后,内存中的数据就会丢失,那为了保证内存中的数据不会丢失,Redis 实现了数据持久化的机制,这个机制会把数据存储到磁盘,这样在 Redis 重启就能够从磁盘中恢复原有的数据。Redis 共有三种数据持久化的方式:
-
AOF 日志:每执行一条写操作命令,就把该命令以追加的方式写入到一个文件里;
-
RDB 快照:将某一时刻的内存数据,以二进制的方式写入磁盘;
-
混合持久化方式:Redis 4.0 新增的方式,集成了 AOF 和 RBD 的优点;
redis的分布式锁实现怎么实现?
分布式锁是用于分布式环境下并发控制的一种机制,用于控制某个资源在同一时刻只能被一个应用所使用。如下图所示:
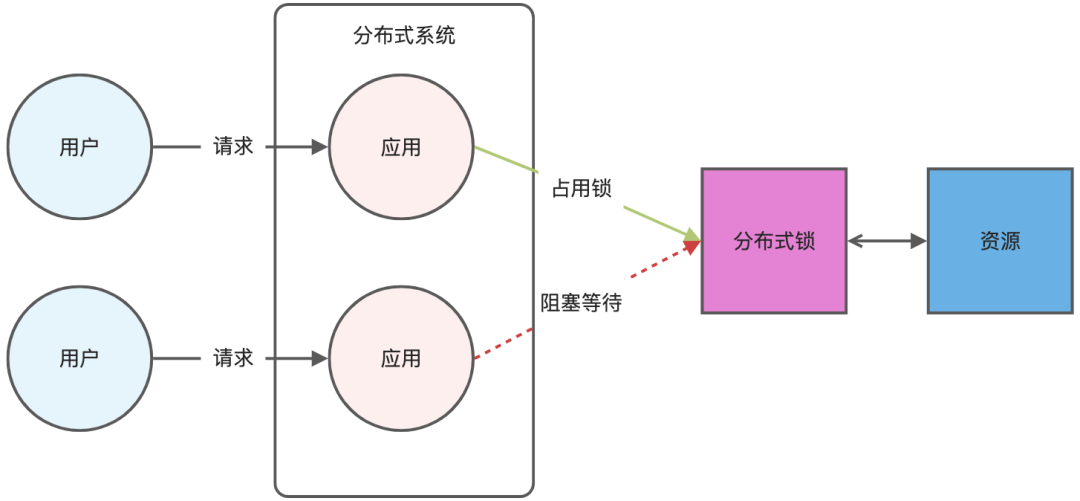
Redis 本身可以被多个客户端共享访问,正好就是一个共享存储系统,可以用来保存分布式锁,而且 Redis 的读写性能高,可以应对高并发的锁操作场景。Redis 的 SET 命令有个 NX 参数可以实现「key不存在才插入」,所以可以用它来实现分布式锁:
-
如果 key 不存在,则显示插入成功,可以用来表示加锁成功;
-
如果 key 存在,则会显示插入失败,可以用来表示加锁失败。
基于 Redis 节点实现分布式锁时,对于加锁操作,我们需要满足三个条件。
-
加锁包括了读取锁变量、检查锁变量值和设置锁变量值三个操作,但需要以原子操作的方式完成,所以,我们使用 SET 命令带上 NX 选项来实现加锁;
-
锁变量需要设置过期时间,以免客户端拿到锁后发生异常,导致锁一直无法释放,所以,我们在 SET 命令执行时加上 EX/PX 选项,设置其过期时间;
-
锁变量的值需要能区分来自不同客户端的加锁操作,以免在释放锁时,出现误释放操作,所以,我们使用 SET 命令设置锁变量值时,每个客户端设置的值是一个唯一值,用于标识客户端;
满足这三个条件的分布式命令如下:
SET lock_key unique_value NX PX 10000
-
lock_key 就是 key 键;
-
unique_value 是客户端生成的唯一的标识,区分来自不同客户端的锁操作;
-
NX 代表只在 lock_key 不存在时,才对 lock_key 进行设置操作;
-
PX 10000 表示设置 lock_key 的过期时间为 10s,这是为了避免客户端发生异常而无法释放锁。
而解锁的过程就是将 lock_key 键删除(del lock_key),但不能乱删,要保证执行操作的客户端就是加锁的客户端。所以,解锁的时候,我们要先判断锁的 unique_value 是否为加锁客户端,是的话,才将 lock_key 键删除。
可以看到,解锁是有两个操作,这时就需要 Lua 脚本来保证解锁的原子性,因为 Redis 在执行 Lua 脚本时,可以以原子性的方式执行,保证了锁释放操作的原子性。
// 释放锁时,先比较 unique_value 是否相等,避免锁的误释放
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
这样一来,就通过使用 SET 命令和 Lua 脚本在 Redis 单节点上完成了分布式锁的加锁和解锁。
你认为小米汽车的发布对车界的影响怎么样?
文章来源: 小林coding

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 43
43 0
0- 0



 已为社区贡献101条内容
已为社区贡献101条内容

所有评论(0)