
伯努利分布、二项分布、多项分布、贝塔分布、狄利克雷分布(似然与概率)
瑞士数学家雅克·伯努利(Jacques Bernoulli,1654~1705)首次研究独立重复试验(每次成功率为p)。在他去世后的第8年(1713年),他侄子尼克拉斯出版了伯努利的著作《推测术》。在书中,伯努利指出了如果这样的试验次数足够大,那么成功次数所占的比例以概率1接近p。 雅克·伯努利是这个最著名的数学家庭的第一代。在后来的三代里,一共有8到12个伯努利,在概率论、统计学和数学上做出了杰
瑞士数学家雅克·伯努利(Jacques Bernoulli,1654~1705)首次研究独立重复试验(每次成功率为p)。在他去世后的第8年(1713年),他侄子尼克拉斯出版了伯努利的著作《推测术》。在书中,伯努利指出了如果这样的试验次数足够大,那么成功次数所占的比例以概率1接近p。 雅克·伯努利是这个最著名的数学家庭的第一代。在后来的三代里,一共有8到12个伯努利,在概率论、统计学和数学上做出了杰出的基础性贡献。

1. 伯努利分布
伯努利分布(Bernoulli distribution)又名两点分布或0-1分布,介绍伯努利分布前首先需要引入伯努利试验(Bernoulli trial)。
伯努利试验是只有两种可能结果的单次随机试验,即对于一个随机变量X而言:

伯努利试验都可以表达为“是或否”的问题。例如,抛一次硬币是正面向上吗?刚出生的小孩是个女孩吗?等等
- 如果试验E是一个伯努利试验,将E独立重复地进行n次,则称这一串重复的独立试验为n重伯努利试验。
- 进行一次伯努利试验,成功(X=1)概率为p(0<=p<=1),失败(X=0)概率为1-p,则称随机变量X服从伯努利分布。伯努利分布是离散型概率分布,其概率质量函数为:
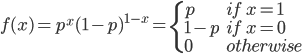
2. 二项分布
二项分布(Binomial distribution)是n重伯努利试验成功次数的离散概率分布。
二项分布是指在只有两个结果的n次独立的伯努利试验中,所期望的结果出现次数的概率。在单次试验中,结果A出现的概率为p,结果B出现的概率为q,p+q=1。那么在n=10,即10次试验中,结果A出现0次、1次、……、10次的概率各是多少呢?这样的概率分布呈现出什么特征呢?这就是二项分布所研究的内容。
如果试验E是一个n重伯努利试验,每次伯努利试验的成功概率为p,X代表成功的次数,则X的概率分布是二项分布,记为X~B(n,p),其概率质量函数为
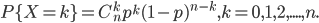
显然,

从定义可以看出,伯努利分布是二项分布在n=1时的特例

二项分布的典型例子是扔硬币,硬币正面朝上概率为p, 重复扔n次硬币,k次为正面的概率即为一个二项分布概率。
举个例子

https://zhuanlan.zhihu.com/p/24692791
3. 多项分布
多项式分布(Multinomial Distribution)是二项式分布的推广。二项式做n次伯努利实验,规定了每次试验的结果只有两个,如果现在还是做n次试验,只不过每次试验的结果可以有多m个,且m个结果发生的概率互斥且和为1,则发生其中一个结果X次的概率就是多项式分布。
扔骰子是典型的多项式分布。扔骰子,不同于扔硬币,骰子有6个面对应6个不同的点数,这样单次每个点数朝上的概率都是1/6(对应p1~p6,它们的值不一定都是1/6,只要和为1且互斥即可,比如一个形状不规则的骰子),重复扔n次,如果问有k次都是点数6朝上的概率就是
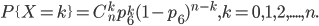
多项式分布一般的概率质量函数为:
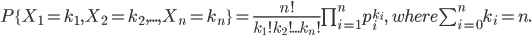
4. 贝塔分布
在介绍贝塔分布(Beta distribution)之前,需要先明确一下先验概率、后验概率、似然函数以及共轭分布的概念。
先验概率
先验概率就是事情尚未发生前,我们对该事发生概率的估计。利用过去历史资料计算得到的先验概率,称为客观先验概率; 当历史资料无从取得或资料不完全时,凭人们的主观经验来判断而得到的先验概率,称为主观先验概率。例如抛一枚硬币头向上的概率为0.5,这就是主观先验概率。
后验概率
后验概率是指通过调查或其它方式获取新的附加信息,利用贝叶斯公式对先验概率进行修正,而后得到的概率。
先验概率和后验概率的关系
关系
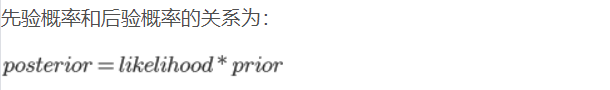
区别
一种表述:
- 先验概率不是根据有关自然状态的全部资料测定的,而只是利用现有的材料(主要是历史资料)计算的;
- 后验概率使用了有关自然状态更加全面的资料,既有先验概率资料,也有补充资料。
另外一种表述:
- 先验概率是在缺乏某个事实的情况下描述一个变量;
- 后验概率(Probability of outcomes of an experiment after it has been performed and a certain event has occured.)是在考虑了一个事实之后的条件概率。
似然函数
似然与概率的概念
在频率推论中,似然函数(常常简称为似然)是一个在给定了数据以及模型中关于参数的函数。在非正式情况下,“似然”通常被用作“概率”的同义词。
在数理统计中,两个术语则有不同的意思。“概率”描述了给定模型参数后,描述结果的合理性,而不涉及任何观察到的数据。而“似然”则描述了给定了特定观测值后,描述模型参数是否合理。
Suppose you have a probability model with parameters θ.
p(x | θ) has two names.
It can be called the probability of x (given θ),
or the likelihood of θ (given that x was observed).
The likelihood is a function of θ. Here are a couple of simple uses:
If you observe x and want to estimate the θ that gave rise to it, the maximum-likelihood principle says to choose the maximum-likelihood θ – in other words, the θ that maximizes p(x | θ).
This contrasts with the maximum-a-posteriori or MAP estimate, which is the θ that maximizes p(θ | x). Since x is fixed, this is equivalent to maximizing p(θ) p(x | θ), the product of the prior probability of θ with the likelihood of θ.
You can do more with these functions of θ than just maximize them. Much is known about their typical shape as the size of the dataset x increases.
L(θ|x)=f(x|θ)
这个等式表示的是对于事件发生的两种角度的看法。其实等式两边都是表示的这个事件发生的概率或者说可能性。
在给定一个样本x后,我们去想这个样本出现的可能性到底是多大。
统计学的观点始终是认为样本的出现是基于一个分布的。那么我们去假设这个分布为f,里面有参数 θ \theta θ。对于不同的 θ \theta θ,样本的分布不一样。
f(x|θ)表示的就是在给定参数 θ \theta θ的情况下,x出现的可能性多大。
L(θ|x)表示的是在给定样本x的时候,哪个参数 θ \theta θ使得x出现的可能性多大。
所以其实这个等式要表示的核心意思都是在给一个 θ \theta θ和一个样本x的时候,整个事件发生的可能性多大。
概率(probability)和似然(likelihood),都是指可能性,都可以被称为概率,但在统计应用中有所区别。
概率是给定某一参数值,求某一结果的可能性。
例如,抛一枚匀质硬币,抛10次,6次正面向上的可能性多大?
解读:“匀质硬币”,表明参数值是0.5,“抛10次,六次正面向上”这是一个结果,概率(probability)是求这一结果的可能性。
用公式算,结果是:
概率(probability)、似然(likelihood)、极大似然法
n=10,P=0.5,Q=0.5,计算得:0.205
即,匀质硬币,抛10次,6次向上的概率是0.205.
似然是给定某一结果,求某一参数值的可能性。
例如,抛一枚硬币,抛10次,结果是6次正面向上,其是匀质的可能性多大?
解读:“抛10次,结果是6次正面向上”,这是一个给定的结果,问“匀质”的可能性,即求参数值=0.5的可能性。
计算公式与上面相同。结果相同,只是视角不同。
与此相联系的是最大似然法,就本例说事,问题就变成:“抛10次,结果是6次正面朝上,那么,参数P的最大可能值是什么?”当然,一切都有可能,但可能性不同。怎么求出可能性最大的(即最像的)的呢?最基本的办法是一个一个试,先求参数值为0.01的可能性(即概率),再算参数值为0.02的概率,依此类推,直到0.99的概率,看看哪个参数值的概率最大,就把它作为参数的估计值,这就是最大似然法。
R软件实现:
“抛10次,结果是6次正面向上”,参数值为0.01的概率是:
dbinom(6,10,0.01)
[1] 2.017252e-10
“抛10次,结果是6次正面向上”,参数值为0.02的概率是:
dbinom(6,10,0.02)
[1] 1.239663e-08
……
“抛10次,结果是6次正面向上”,参数值为0.2的概率是
dbinom(6,10,0.2)
[1] 0.005505024
“抛10次,结果是6次正面向上”,参数值为0.3的概率是
dbinom(6,10,0.3)
[1] 0.03675691
“抛10次,结果是6次正面向上”,参数值为0.4的概率是
dbinom(6,10,0.4)
[1] 0.1114767
“抛10次,结果是6次正面向上”,参数值为0.5的概率是
dbinom(6,10,0.5)
[1] 0.2050781
“抛10次,结果是6次正面向上”,参数值为0.6的概率是
dbinom(6,10,0.6)
[1] 0.2508227
“抛10次,结果是6次正面向上”,参数值为0.7的概率是
dbinom(6,10,0.7)
[1] 0.2001209
不用再试了,结果出来了,参数值为0.6的概率最大,因此0.6就是用极大似然法求出的参数估计值。
上面是给了二项分布的一个结果,求参数p的最大似然估计的过程。如果给了多个结果,即给出一个二项分布的样本,为x1,x2,……,xn,那么就可以推导极大似然法的公式了。公式为p=(ΣX)/(N*n),
证明过程:

下面举一个例子
有一个硬币,它有θ的概率会正面向上,有1-θ的概率反面向上。θ是存在的,但是你不知道它是多少。为了获得θ的值,你做了一个实验:将硬币抛10次,得到了一个正反序列:x=HHTTHTHHHH。
无论θ的值是多少,这个序列的概率值为 θ⋅θ⋅(1-θ)⋅(1-θ)⋅θ⋅(1-θ)⋅θ⋅θ⋅θ⋅θ = θ⁷ (1-θ)³
比如,如果θ值为0,则得到这个序列的概率值为0。
如果θ值为1/2,概率值为1/1024。
但是,我们应该得到一个更大的概率值,所以我们尝试了所有θ可取的值,画出了下图:
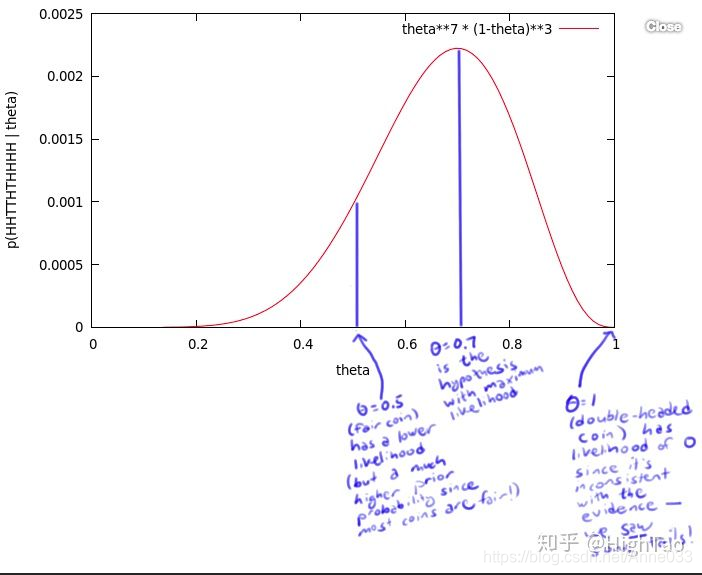
这个曲线就是θ的似然函数,通过了解在某一假设下,已知数据发生的可能性,来评价哪一个假设更接近θ的真实值。
如图所示,最有可能的假设是在θ=0.7的时候取到。但是,你无须得出最终的结论θ=0.7。事实上,根据贝叶斯法则,0.7是一个不太可能的取值(如果你知道几乎所有的硬币都是均质的,那么这个实验并没有提供足够的证据来说服你,它是均质的)。但是,0.7却是最大似然估计的取值。
因为这里仅仅试验了一次,得到的样本太少,所以最终求出的最大似然值偏差较大,如果经过多次试验,扩充样本空间,则最终求得的最大似然估计将接近真实值0.5。
从离散随机变量角度看待“似然”与“概率”
当我们在处理离散型随机变量时候(例如,掷10硬币的结果这样的数据时候),我们可以根据观测到的结果计算这种结果出现的概率概率,当然这有一个前提是硬币是均匀的,和掷硬币的事件都是独立的。
这时我们想要计算的就是“概率”用
P
(
O
∣
θ
)
P(O | \theta)
P(O∣θ)来表示。换个角度可以理解为,当给定了特定的参数
θ
\theta
θ时候,
P
(
O
∣
θ
)
P(O | \theta)
P(O∣θ)就是我们观测到
O
O
O观测值时候的概率。
但是,当我们想来刻画一个实际的随机过程时候,我们常常并不知道
θ
\theta
θ参数是什么。我们只有观测值
O
O
O,基于这个观测值我们往往想得到一个关于
θ
\theta
θ的估计值
θ
^
\hat{\theta}
θ^。当给定
θ
\theta
θ 时候我们可以得到观测值
O
O
O是
P
(
O
∣
θ
)
P (O | \theta)
P(O∣θ)。当然反过来,对于估计过程是在选择一个
θ
^
\hat{\theta}
θ^最大值,这个值就等价于真实观测值
O
O
O的概率。换而言之,是在寻找一个值
θ
^
\hat{\theta}
θ^的最大化使得
这个 L ( θ ∣ O ) L(\theta | O) L(θ∣O)就叫做似然函数。 很明显这是一个在已知观测值 O O O为条件关于未知参数 θ \theta θ的似然函数。
从连续型随机变量角度看待“似然”与“概率”
对于连续型随机变量与离散随机变量有一个非常重要的区别,就是人们不会去关注给定 θ \theta θ后观测值 O O O得概率。 因为,连续型随机变量存在无限多的结果(无限可分),这些结果是无法被穷尽的。 我们给出某一个结果对应的概率是没有意义的(连续型随机变量产生的结果是无限的, 落在任何一个“可能的结果”上的概率几乎都为0,也就是 P ( O ∣ θ ) = 0 ) P(O | \theta) = 0 ) P(O∣θ)=0)。 当然,可以变换一种方式既给出落在结果区间范围上的概率,而非给出单个结果的概率,来解决这个问题。 对于观测值 O O O,可以用概率密度函数(PDF:probability density function)来表示为: f ( O ∣ θ ) f(O|\theta) f(O∣θ)。 因此,在连续的情况下,我们通过最大化以下函数来估计观察到的结果 O O O:
在这种情况下,我们不能在技术上断言我们找到最大化观察 O O O的概率的参数值,因为我们最大化的是与观察结果 O O O相关的PDF。
“似然”和“概率”是站在两个角度看待问题
对于这个函数:
输入有两个: O O O表示某一个具体的数据; θ \theta θ表示模型的参数。
- 如果 θ \theta θ是已知确定的, O O O是变量,这个函数叫做概率函数(probability function),它描述对于不同的样本 O O O,其出现概率是多少。
- 如果 O O O是已知确定的, θ \theta θ是变量,这个函数叫做似然函数(likelihood function), 它描述对于不同的模型参数,出现x这个样本点的概率是多少。
似然与概率的区别与联系
1、似然与概率的区别
在英语语境里,likelihood 和 probability 的日常使用是可以互换的,都表示对机会 (chance) 的同义替代。但在数学中,probability 这一指代是有严格的定义的,即符合柯尔莫果洛夫公理 (Kolmogorov axioms) 的一种数学对象(换句话说,不是所有的可以用0到1之间的数所表示的对象都能称为概率),而 likelihood (function) 这一概念是由Fisher提出,他采用这个词,也是为了凸显他所要表述的数学对象既和 probability 有千丝万缕的联系,但又不完全一样的这一感觉。中文把它们一个翻译为概率一个翻译为似然也是独具匠心。

除此之外,统计学中的另一常见概念"置信(区间)"(confidence interval)中的置信度(confidence level) 或者称为置信系数 (confidence coefficient) 也不是概率。换句话说,"构建关于总体均值的95%的置信区间"里的"95%"不是概率意义下的0.95(即使它也是0到1之间的代表机会chance的一个度量): Neyman的原话是
… in the long run he will be correct in 99% (the assumed value of ) of all cases … Hence the frequency of actually correct statements will approach
更常见的
p
p
p-值(
p
p
p-value)严格来说其本身是一个(恰好位于0到1之间的)统计量(即样本随机变量的函数),所以
p
p
p-值也不是概率。一种方便区别是概率还是似然的方法是,根据定义,"谁谁谁的概率"中谁谁谁只能是概率空间中的事件,换句话说,我们只能说,事件(发生)的概率是多少多少(因为事件具有概率结构从而刻画随机性,所以才能谈概率);而"谁谁谁的似然"中的谁谁谁只能是参数,比如说,参数等于
θ
\theta
θ时的似然是多少。

所以从定义上,似然函数和密度函数是完全不同的两个数学对象:前者是关于
θ
\theta
θ的函数,后者是关于x的函数。所以这里的等号 理解为函数值形式的相等,而不是两个函数本身是同一函数(根据函数相等的定义,函数相等当且仅当定义域相等并且对应关系相等)。
2、似然与概率的联系


后验概率分布函数与先验概率分布函数具有相同形式
好了,有了以上先验知识后,终于可以引入贝塔分布啦!!首先,考虑一点,在试验数据比较少的情况下,直接用最大似然法估计二项分布的参数可能会出现过拟合的现象(比如,扔硬币三次都是正面,那么最大似然法预测以后的所有抛硬币结果都是正面)。为了避免这种情况的发生,可以考虑引入先验概率分布
p
(
u
)
p(u)
p(u)来控制参数
u
u
u,防止出现过拟合现象。那么,问题现在转为如何选择
p
(
u
)
p(u)
p(u)!
二项分布的似然函数为(就是二项分布除归一化参数之外的后面那部分,似然函数之所以不是pdf,是因为它不需要归一化):
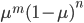

5. 狄利克雷分布
狄利克雷分布(Dirichlet distribution)是多项分布的共轭分布,也就是它与多项分布具有相同形式的分布函数。
概率分布函数为:
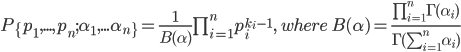
6. 后记
本篇博文只是将伯努利分布、二项分布、多项分布、贝塔分布和狄利克雷分布做了简单的介绍,其中涉及到大量的概率基础和高等数学的知识,文中的介绍只是粗浅的把这些分布的概念作了大概介绍,没有对这些分布的产生历史做介绍。我想,更好的介绍方式,应是从数学史的角度,将这几项分布的发现按照历史规律来展现,这样会更直观、形象。后续再补吧!
https://blog.csdn.net/kingzone_2008/article/details/80584743
https://zhuanlan.zhihu.com/p/24692791
似然 https://www.zhihu.com/question/54082000/answer/145495695
https://www.zhihu.com/question/54082000/answer/138115757

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 6
6 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)