
Kafka 安装部署、集群启动、命令行操作 与 可视化工具 Kafka Tool
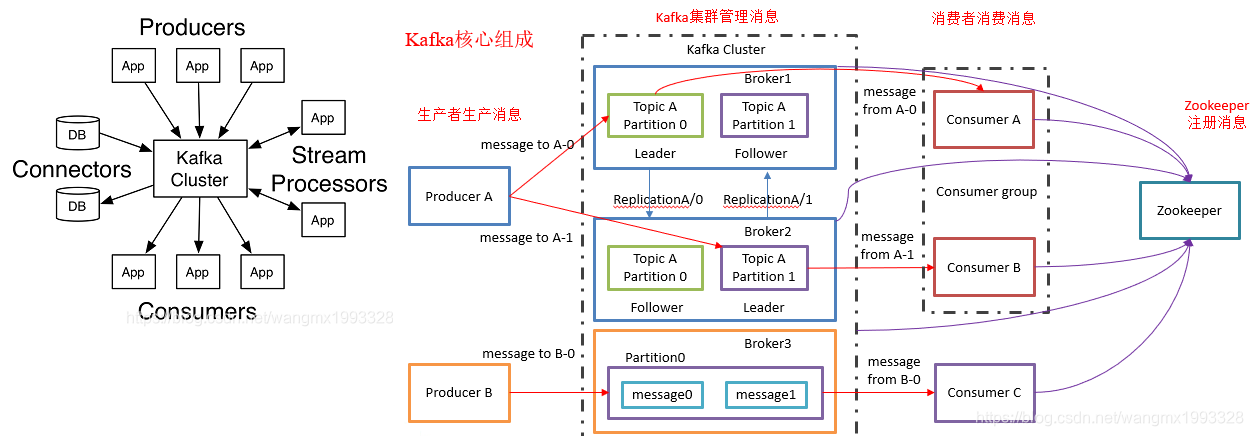
目录Kafka 消息队列概述Kafka 消息队列架构Kafka 消息队列概述1、Apache Kafka 是一个开源分布式消息队列/系统,该项目的目标是为处理实时数据提供一个统一、高通量、低等待的平台2、Kafka 保存消息时根据 Topic(主题) 进行归类,发送消息者称为 Producer(生产者),消息接受者称为 Consumer(消费者),kafka 集群由多个 kafka 实例组成,每个
本文环境:Java jdk 1.8 + zookeeper 3.6.1 + kafka 2.6.0 + CentOS 7.2
Kafka 分布式事件流平台
1、Apache Kafka 是一个开源的分布式事件流平台,被广泛用于高性能数据管道、流分析、数据集成和关键任务应用。
| Kafaka 官网:Apache Kafka |
| Kafka 官网下载地址:Apache Kafka |
| Kafka 官网文档:https://kafka.apache.org/documentation.html#gettingStarted (!强烈推荐多参考官网!) |
| Github 开源地址:https://github.com/apache/kafka |
| Github Kafka 下载地址:Releases · apache/kafka · GitHub |
2、Kafka 通常用于两大类应用:1)构建实时流数据管道,在系统或应用程序之间可靠地获取数据。2)构建对数据流进行转换或响应的实时流式应用程序
| Kafaka 核心能力 | 1)高吞吐量:使用延迟低至 2 毫秒的计算机群集,以网络有限的吞吐量传递消息。 可扩展:将生产集群扩展到1000个代理、每天数万亿条消息、PB级数据、数十万个分区。弹性扩展和压缩存储和处理。 2)永久储存:在分布式、持久、容错的集群中安全地存储数据流。 3)高可用性:在可用区域上有效地扩展集群,或者跨地理区域连接单独的集群。 |
| Kafka 生态系统 | 1)内置流处理:通过连接、聚合、筛选器、转换等方式处理事件流,使用事件时间和精确一次处理。 2)接口丰富:Kafka 的现成连接接口集成了数百个事件源和事件接收器,包括Postgres、JMS、Elasticsearch、AWS S3等. 3)客户端库:用大量的编程语言读、写和处理事件流。 4)大型生态系统开源工具:大型开源工具生态系统:利用大量社区驱动的工具。 |
| Kafka 易用性 | 1)关键任务:支持任务关键型用例,保证排序、零消息丢失和高效的一次性处理。 2)使用广泛:从互联网巨头到汽车制造商再到证券交易所,成千上万的机构都在使用kakfa。超过500万次独特的终身下载. 3)庞大的用户社区:kafka 是阿帕奇软件基金会最活跃的五个项目之一,在世界各地有数百个会议。 4)丰富的在线资源:丰富的文档、在线培训、指导教程、视频、示例项目、堆栈溢出等。 |
3、Kafka 作为集群运行在一个或多个服务器上,可以跨越多个数据中心。Kafka 集群将记录流存储在称为 topics 的主题中。每个记录由一个键、一个值和一个时间戳组成。
4、Kafka 核心 API 有五个:
| Producer API | 生产者:允许应用程序将记录流发布到一个或多个 Kafka 主题。 |
| Consumer API | 消费者:I允许应用程序订阅一个或多个主题,并处理为它们生成的记录流。 |
| Streams API | 允许应用程序充当流处理器,使用来自一个或多个主题的输入流并生成一个或多个输出主题的输出流,从而有效地将输入流转换为输出流。 |
| Connector API | 连接器:允许构建和运行可重用的生产者或消费者,将Kafka主题连接到现有的应用程序或数据系统。例如,到关系数据库的连接器可能会捕获对表的每个更改。 |
| Admin API | 管理API允许管理和检查主题、代理和其他 Kafka 对象。 |
CentOS 安装部署 Kafka
特别提醒:kafka 服务器是依赖 zookeeper 服务器做集群的,所以使用 kafka 得先安装启动 zookeeper 。
一:kafka 下载
1、从 Kafka 官网下载压缩文件,当前最新的是 2020年3月发布的 Kafka 2.6.0,点击如下任意一个链接都可以下载到文件。
2、从后缀名 .tgz 可以看出这是用于 Linux 系统安装的,所以我选择在 CentOS 7.2 上安装,因为压缩文件并不大(如下所示为 63M),所以使用 wget 命令直接将文件下载到 linux 系统中:
[root@localhost home]# wget https://mirrors.bfsu.edu.cn/apache/kafka/2.6.0/kafka_2.13-2.6.0.tgz
--2020-08-17 09:56:58-- https://mirrors.bfsu.edu.cn/apache/kafka/2.6.0/kafka_2.13-2.6.0.tgz
正在解析主机 mirrors.bfsu.edu.cn (mirrors.bfsu.edu.cn)... 39.155.141.16, 2001:da8:20f:4435:4adf:37ff:fe55:2840
正在连接 mirrors.bfsu.edu.cn (mirrors.bfsu.edu.cn)|39.155.141.16|:443... 已连接。
已发出 HTTP 请求,正在等待回应... 200 OK
长度:65537909 (63M) [application/octet-stream]
正在保存至: “kafka_2.13-2.6.0.tgz”
100%[===============================================================>] 65,537,909 4.54MB/s 用时 19s
2020-08-17 09:57:18 (3.26 MB/s) - 已保存 “kafka_2.13-2.6.0.tgz” [65537909/65537909])
[root@localhost home]# ls
apache-zookeeper-3.6.1-bin jdk1.8.0_172 kafka_2.13-2.6.0.tgz redis5 redis-5.0.4
[root@localhost home]# du -sh kafka_2.13-2.6.0.tgz
63M kafka_2.13-2.6.0.tgz
[root@localhost home]# 二:kafka 解压
[root@localhost home]# tar -xzvf kafka_2.13-2.6.0.tgz
......
[root@localhost home]# ls
apache-zookeeper-3.6.1-bin jdk1.8.0_172 kafka_2.13-2.6.0 kafka_2.13-2.6.0.tgz redis5 redis-5.0.4
[root@localhost home]# cd kafka_2.13-2.6.0
[root@localhost kafka_2.13-2.6.0]# ls
bin config libs LICENSE NOTICE site-docs
[root@localhost kafka_2.13-2.6.0]# 三:创建日志目录
1、事先创建一个存放日志/数据的目录,用于 kafa 存放日志信息/数数据,后续会配置此路径(注意这个目录就是 kafka 的数据存放目录,kafka 以日志的形式存储数据)。
[root@localhost kafka_2.13-2.6.0]# mkdir logs
[root@localhost kafka_2.13-2.6.0]# ls
bin config libs LICENSE logs NOTICE site-docs
[root@localhost kafka_2.13-2.6.0]# 四:kafka 核心文件 server.properties 配置
1、%KAFKA_HOME%/config 目录下有 15 个属性配置文件,其中 server.properties 是 kafka 服务器核心配置文件,其中主要配置项说明如下,可根据实际需要进行配置。
| broker.id=0 | #broker 的全局唯一id值,用于集群下每个 kafka 的唯一标识,可以是任意的整数值,默认为 0。 |
| delete.topic.enable=true | 删除 topic 时是否物理删除。默认为 false 或者无此配置项(此时手动添加即可) 1、如果没有配置 delete.topic.enable,或者值为 false,则删除 topic 时是标记删除,不是真正的物理删除,在 log.dirs 配置的目录下仍然能看到数据,以及在 zk 服务器的 /brokers/topics 路径也能看到数据。 2、想要删除 topic 时真正的物理删除,此必须配置为 true. |
| num.network.threads=3 | #处理网络请求与响应的线程数量,默认为 3 |
| num.io.threads=8 | #服务器用于处理请求的线程数,可能包括磁盘I/O,默认为 8 |
| socket.send.buffer.bytes=102400 | #发送套接字的缓冲区大小,默认为 102400,100 kb |
| socket.receive.buffer.bytes=102400 | #接收套接字的缓冲区大小,默认为 102400,100 kb |
| socket.request.max.bytes=104857600 | #请求套接字的缓冲区大小,默认为 104857600,100M |
| log.dirs=/home/kafka_2.13-2.6.0/logs | #kafka 运行日志存放的路径,改成自定义的即可,kafka 以日志的形式存储数据,这个路径不能随意删除。 |
| num.partitions=1 | #topic在当前broker上的分区个数,默认为 1 |
| num.recovery.threads.per.data.dir=1 | #用来恢复和清理data下数据的线程数量,默认为 1 |
| log.retention.hours=168 | #日志文件保留的最长时间,超时将被删除,默认 168 小时,7 天 |
| log.segment.bytes=1073741824 | #日志文件最大大小,超过时会新建 |
| log.retention.bytes=1073741824 | #基于大小的日志(数据)保留策略,当存储的数据量超过此大小时,就删除旧数据。默认为 1G。此配置默认是被注释的。 |
| log.retention.check.interval.ms=300000 | #检查日志段以查看是否可以根据保留策略删除日志段的间隔 |
| zookeeper.connect=193.234.2.100:2181,193.234.2.101:2181 | #配置连接 Zookeeper 集群地址,默认为 localhost:2181 |
| zookeeper.connection.timeout.ms=18000 | 连接到zookeeper的超时(毫秒),默认 18 秒 |
更详细的配置选项可以参考官网:Apache Kafka
五:Kafka 环境变量
1、编辑 /etc/profile 配置文件,追加下面内容,其中 KAFKA_HOME 的值根据实际地址写。
| [root@localhost ~]# vim /etc/profile export KAFKA_HOME=/home/kafka_2.13-2.6.0 [root@localhost ~]# source /etc/profile //刷新配置文件,使用配置生效 [root@localhost ~]# echo $KAFKA_HOME //获取环境变量的值,查看 kafka 环境变量配置是否配置成功 |
Kafka 集群启动与停止
1、在上面安装部署 kafka 之后,就可以启动 kafka 服务器了,当然还得先 zookeeper 服务器,生产中通常都会使用公共的独立的 zookeeper 服务器,但是开发测试时,也可以直接使用 Kafka 内置的 zookeeper 服务器。
特别提醒:kafka 的集群启动很简单,只要准备多份 kafka ,然后注册到同一个 zookeeper 服务器或者 zk 集群即可,修改配置文件 server.properties 中的 zookeeper.connect 指向 zookeeper 地址(zk可单机可集群)即可, kafka 的 broker.id 的值在集群下必须唯一。换句话说就是:kafka 是通过 zookeeper 进行集群管理的,只需要大家指向同一个 zk 即可。
2、%KAFKA_HOME%/bin/ 目录下有很多的的可执行脚本,kafka 服务器的启动与关闭使用的是 kafka-server-start.sh 与 kafka-server-stop.sh。
| [root@wangmaoxiong001 bin]# ./kafka-server-start.sh ../config/server.properties | 前台启动 kafka 服务器,需要指定配置文件 |
| [root@wangmaoxiong001 bin]# nohup ./kafka-server-start.sh ../config/server.properties & | 后台启动 kafka 服务器,需要指定配置文件。此时启动日志在当前目录下的 nohup.out 文件中。 |
| [root@wangmaoxiong001 config]# jps #启动之后可以看到 kafka 进程 4144 Kafka | |
| [root@wangmaoxiong001 bin]# ./kafka-server-stop.sh | 关闭启动 kafka 服务器 |
3、kafka 运行的所有日志信息存储在 %KAFKA_HOME%/logs/ 目录下。
4、kafka 启动之后,会在 zookeeper 服务器上新建许多节点。
5、如下动图演示了两台机器的 kafka 机器,分别为 192.168.116.128、192.168.116.129,先对 Zookeeper 进行了集群,然后对 kafka 进行了集群。
images/Kafka 集群启动.gif · 汪少棠/material - Gitee.com
如果想要单机启动 kafka ,则也只需要准备一台 zookeeper 服务器,然后将单台 的 kafka 注册到此 zk 服务器即可。
kafka 内置 zookeeper 服务器
1、生产中通常都会部署公共的独立 zookeeper 服务器,但是开发测试时,也可以直接使用 Kafka 内置的 zookeeper 服务器。
2、使用 Kafka 内置的 zookeeper 服务器也很简单,步骤如下:
| 1)修改 %KAFKA_HOME/conf% 目录下的 zookeeper.properties 配置文件,修改zk数据存储目录,如: dataDir=/home/kafka_2.13-2.6.0/data/zk-data,zk 服务器默认数据存储目录为:#dataDir=/tmp/zookeeper。zk 服务器默认监听客户端端口为 clientPort=2181。 |
| 2)通过 %KAFKA_HOME/bin% 目录下的: zookeeper-server-start.sh 脚本:启动zk服务器,指定配置文件,如后台启动:nohup ./bin/zookeeper-server-start.sh ./config/zookeeper.properties &。此时启动日志在当前目录下的 nohup.out 文件中。 zookeeper-server-stop.sh 脚本:关闭 zk 服务器 zookeeper-shell.sh 脚本:连接 zk 服务器,比如 zookeeper-shell.sh 127.0.0.1:2181,连接上之后就可以使用 zk 命令行,比如: ls / |
3、下面通过动图演示一下启动 kafka 内置的 zk 服务器,然后 kafka 连接此内置的 zk 服务器:

4、如果启动 kafka 报错如下,则删除配置文件 server.properties 中参数 log.dirs目录下的全部文件,重启 Kafka 即可解决。比如我之前使用 kafka 连接的独立部署的 zk 服务器,后面连接内置的 zk 服务器时,启动就报错如下,删除日志文件后就启动成功。
(特别提醒:server.properties 中参数 log.dirs 目录是 kafka 的数据存放目录,一旦删除,则数据也没有了,必须慎重!)
[2020-08-24 19:18:55,917] ERROR Fatal error during KafkaServer startup. Prepare to shutdown (kafka.server.KafkaServer)
kafka.common.InconsistentClusterIdException: The Cluster ID M-r5t-8hRSetuxp4HsZQzg doesn't match stored clusterId Some(GFE8zS5ORd6ad--KbhG28A) in meta.properties. The broker is trying to join the wrong cluster. Configured zookeeper.connect may be wrong.
at kafka.server.KafkaServer.startup(KafkaServer.scala:235)
at kafka.server.KafkaServerStartable.startup(KafkaServerStartable.scala:44)
at kafka.Kafka$.main(Kafka.scala:82)
at kafka.Kafka.main(Kafka.scala)
[2020-08-24 19:18:55,920] INFO shutting down (kafka.server.KafkaServer)kafka 命令行脚本操作
1、%KAFKA_HOME%/bin/ 目录下有很多的的可执行脚本,kafka 服务器的启动与关闭使用的是 kafka-server-start.sh 与 kafka-server-stop.sh。现在练习其它可执行脚本,比如查看主题、创建主题、上传主题、发生消息、消费消息等等。
2、操作这些脚本之前,必须先启动 Kafka 服务器。
| Tip1:命令行的所有参数都是两个横杠开头 Tip2:kafka 默认使用 9092 端口进行消息传送,所以集群下的每个 kafka 服务器所在的机器都需要开启 9092 访问端口,否则发送消息、接收消息会失败。 firewall-cmd --zone=public --add-port=9092/tcp --permanent #开启 9092 端口 firewall-cmd --reload #重启防火墙 firewall-cmd --zone=public --list-ports #查看对外成功开放的端口 Tip3:如下所有脚本参数都可以通过 ./xxx.sh --help 来进行查看 | |
| ./kafka-topics.sh --list --bootstrap-server 192.168.116.128:9092,192.168.116.129:9092 | 查看当前服务器中的所有 topic(主题) --list:表示查询 --bootstrap-server :kafka 集群地址,格式 host1:port1,host2:port2...,也可以只写单个地址,多个地址的目的是防止服务器故障。 |
| ./kafka-topics.sh --describe --bootstrap-server 192.168.116.128:9092,192.168.116.129:9092 -topic helloWorld | 查看指定 topic 详细信息 1、比如分区个数,自己所属分区,副本个数,领导者机器id等等 |
| ./kafka-topics.sh --create --bootstrap-server 192.168.116.128:9092,192.168.116.129:9092 --replication-factor 2 --partitions 2 --topic helloWorld | 创建 topic。 --replication-factor:指定副本数,不能大于集群下的 kafka 节点数,通常与节点数一致即可,这样就保证每个kafka上都复制有一份相同的数据,防止宕机。 --partitions:定义分区数,topic 的分区是提供 kafka 吞吐量的方式之一,数量没有强制要求,比如执行左侧命令后在 log.dirs 目录下可以看到 helloWorld 的两个分区:helloWorld-0,helloWorld-1,当副本数小于 kafka 节点数时,分区也可能分散位于多个 kafka 上。 提醒:创建成功之后,可以在 log.dirs 配置的目录下看到数据,以及在 zk 服务器的 /brokers/topics 路径也能看到数据。 |
| ./kafka-topics.sh --delete --bootstrap-server 192.168.116.128:9092,192.168.116.129:9092 --topic helloWorld | 删除 topic 提醒:如果 server.properties 没有配置 delete.topic.enable,或者值为 false,则删除 topic 时是标记删除,不是真正的物理删除,在 log.dirs 配置的目录下仍然能看到数据,以及在 zk 服务器的 /brokers/topics 路径也能看到数据。 |
| ./kafka-console-producer.sh --bootstrap-server 192.168.116.128:9092,192.168.116.129:9092 --topic helloWorld | 启动生产者 --bootstrap-server :kafka 集群地址,格式 host1:port1,host2:port2... --topic:表示将消息发送到哪个topic(主题)上,topic 需要已经存在。 提醒1:回车之后就会进入生产者命令行,返回即可发送消息 提醒2:9092 是默认端口,可以自己修改 conf 下的配置文件为需要的端口。 |
| ./kafka-console-consumer.sh --bootstrap-server 192.168.116.128:9092,192.168.116.129:9092 --from-beginning --topic hello-world | 启动消费者 --bootstrap-server :kafka 集群地址,格式 host1:port1,host2:port2...,也可以只写单个地址,多个地址的目的是防止服务器故障。 --from-beginning:是否从起始位置接收消息,比如生产者发送消息的时候,消费者还未启动,此时加上此参数就会从起始位置全部接收,否则只会接收消费者自己启动后监听到的数据。根据实际情况决定是否需要读取历史消息。 --topic:接收哪个主题的消息 提醒:回车之后就会进入消费者命令行,此时生产者只要发送消息,这里就会显示。 |

kafka 配置参数
1、Kafka 使用属性文件格式中的键值对进行配置,这些值可以从文件或以编程方式提供。如下所示为官网配置:
| 3.1 Broker Configs :broker 配置。所以配置项可以通过 server.properties 文件配置 3.2 Topic Configs :主题配置 3.3 Producer Configs :生成者配置 3.4 Consumer Configs :消费者配置 3.5 Kafka Connect Configs :连接配置 3.6 Kafka Streams Configs :流配置 3.7 AdminClient Configs :Kafka管理客户端库的配置。 |
Kafka 可视化工具 Kafka Tool
1、Kafka 工具是一个 GUI 应用程序,用于管理和使用 Apache Kafka 群集,它提供了一个直观的用户界面,允许用户快速查看Kafka 集群中的对象以及存储在集群主题中的消息。它包含面向开发人员和管理员的特性。
2、Kafka Tool 主要包括以下关键功能:
| 快速查看您的所有卡夫卡集群,包括他们的经纪人,主题和消费者 |
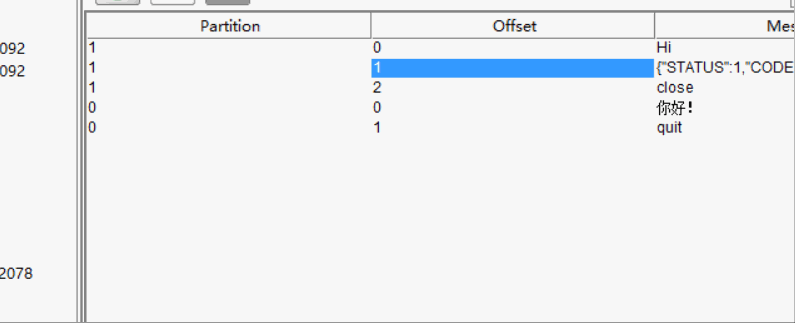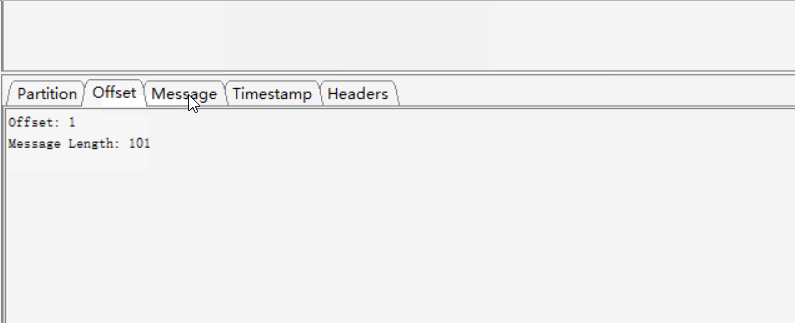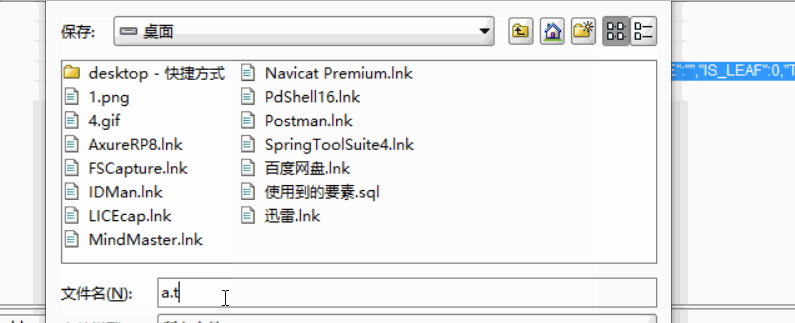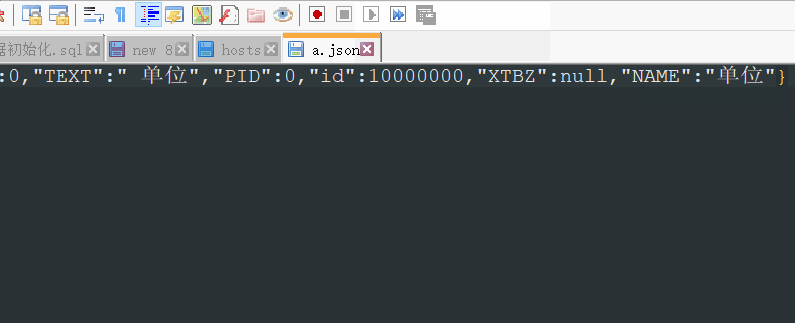
| 查看分区中消息的内容并添加新消息 |
| 查看消费者的补偿,包括阿帕奇风暴卡夫卡消息偏移量 |
| 以漂亮的打印格式显示 JSON 和 XML 消息 |
| 添加和删除主题以及其他管理功能 |
| 将分区中的单个消息保存到本地硬盘 |
| 编写自己的插件,允许您查看自定义数据格式 |
| Kafka 工具可以运行在 Windows、Linux 和 Mac 操作系统上 |
3、Kafka Tool 仅供个人使用,未经许可,任何非个人用途,包括商业、教育和非盈利工作,均不得使用,下载 Kafka Tool 后 30 天内,允许非个人使用,之后您必须购买有效许可证或删除软件。
| kafka Tool 主页:Offset Explorer Kafka Tool 下载页:Offset Explorer |
4、因为本人使用的是 Kafka 2.6 版本,所以下载的也是 kafka Tool 的最新版 Kafka Tool 2.0.8

如上所示安装和普通软件一样,选择安装路径安装即可,没有特殊的地方。
连接方式一
一:演示环境说明
本文演示在 Win10 上安装 kafka Tool,然后连接虚拟机中的 kafka 集群。
因为平时学习的需要,所以本人是两台 CentOS 7.2 虚拟机,ip 分别为 192.168.116.128、192.168.116.129,主机名称分别为 wangmaoxiong001、wangmaoxiong002,两台机器上都已经安装并集群启动了 Zookeeper 与 Kafka。zookeeper 使用默认的 2181 监听端口,以及 kafka 使用默认的 9092 端口,并都对外开放了防火墙。

二:配置 kafka 机器域名
1、修改 windows 系统中 C:\Windows\System32\drivers\etc 目录下的 hosts 文件,添加 kafka 集群的域名信息,如下所示,根据实际情况填写,ip 空格 主机名称。
2、如果不配置这一步,那么后期启动 kafka Tool 连接成功之后,会打不开 Topics 与 Consumers 菜单,会提示连接不上,如果后期打开没问题,则这一步省略也没关系。
192.168.116.128 wangmaoxiong001
192.168.116.129 wangmaoxiong002
三:启动 Kafka Tool
1、找到 kafka tool 安装目录,双击 kafkatool.exe 即可运行。然后就是配置连接信息:


工具比较简洁,多点一点,熟练一下,操作基本没什么难度,下面再演示一下保存消息到本地,其余不再累述。
连接方式二
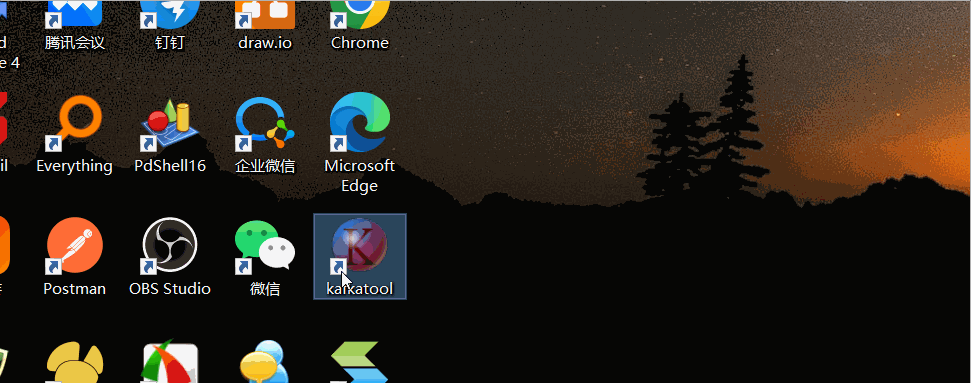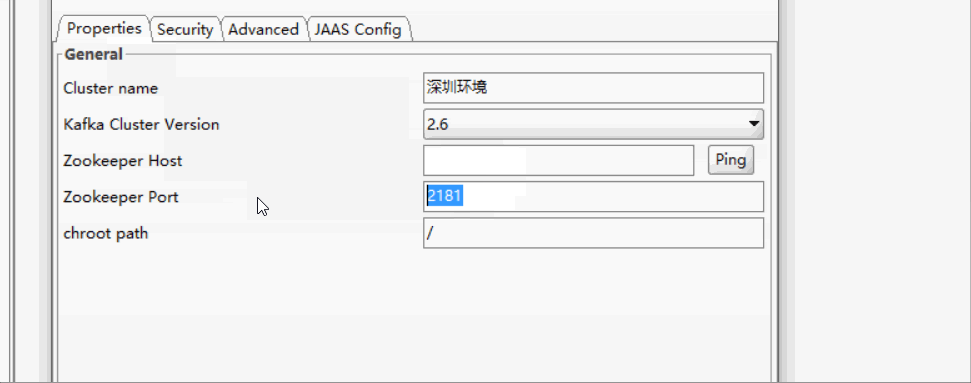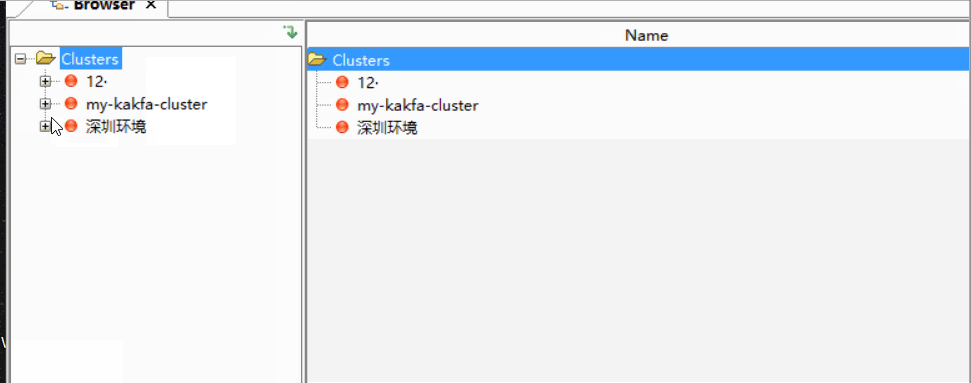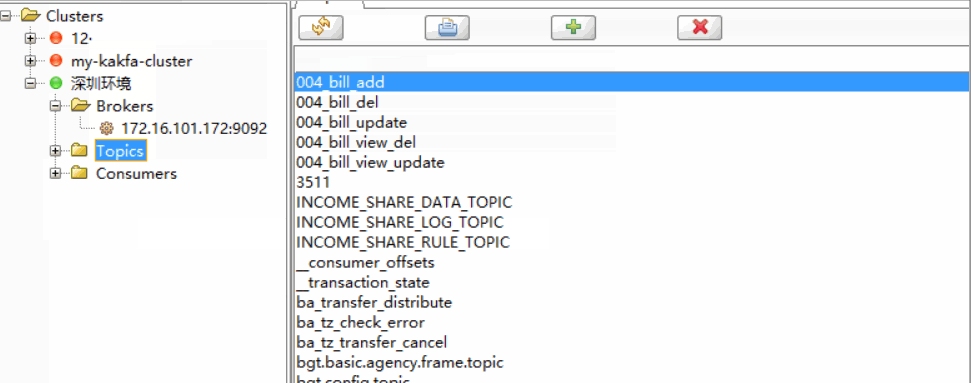
1、除了配置 Zookeeper 地址,直接配置 kafka 地址也是可以的,因为有时候我们只知道 kafka 地址,并不知道 zookpeeper 地址,因为代码里面收发消息只配置 kafka 地址就可以了。
2、配置 kafka 地址同样可以,集群时使用逗号隔开。
创建主题 & 发送消息
1、支持手动创建主题。
2、支持向指定主题发送消息。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 20
20 0
0- 0



 已为社区贡献38条内容
已为社区贡献38条内容

{kind=link}
所有评论(0)