
数据集 | 基于语音(Speech)/多模态(Multimodal)的情绪识别数据集,格式及下载
本文主要介绍了一些常用的语音🗣识别数据集,文件格式以及下载地址:
目录
1.IEMOCAP Emotion Speech Database(English)
3.Ryerson Audio-Visual Database of Emotional Speech and Song (English)RAVDESS
4.Korean Emotional Speech Dataset
1.IEMOCAP Emotion Speech Database(English)
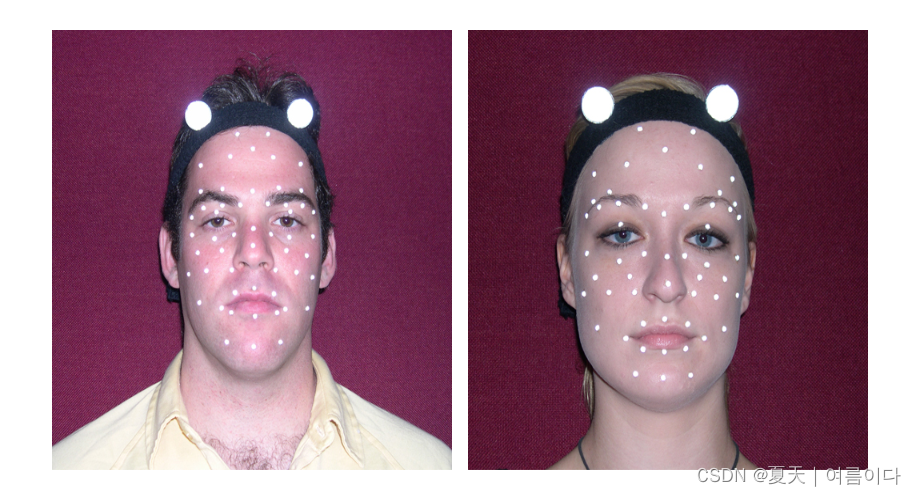
Interactive Emotional Dyadic Motion Capture (IEMOCAP) 数据库是一个表演的、多模态和多说话者数据库,最近在南加州大学的SAIL实验室收集. 它包含大约 12 小时的视听数据,包括视频、语音、面部动作捕捉、文本转录。它由二元会话组成,演员在这些会话中进行即兴表演或脚本化场景,这些场景是专门为引发情感表达而选择的。IEMOCAP 数据库被多个标注者标注为分类标签,如愤怒、快乐、悲伤、中性,以及维度标签,如效价、激活和支配。详细的动作捕捉信息、引发真实情绪的交互设置以及数据库的大小使该语料库成为社区现有数据库的宝贵补充,可用于研究和建模多模式和表达性人类交流。更多可查看:https://sail.usc.edu/iemocap/
数据库范围
-
情绪表达的识别与分析
-
人类二元相互作用分析
-
情感敏感人机界面和虚拟代理的设计
-
...
一般信息
-
关键词:情感的、多模式的、行动的、二元的
-
英语语言
-
10名演员:5男5女
-
情绪激发技巧:即兴创作和剧本
可用方式
-
动作捕捉人脸信息
-
演讲
-
影片
-
头部运动和头部角度信息
-
对话转录
-
词级、音节级和音素级对齐
注释
-
会话被手动分割成话语
-
每个话语至少由 3 位人工注释者注释
-
分类属性:
-
愤怒、快乐、兴奋、悲伤、沮丧、恐惧、惊讶、其他和中性状态
-
-
维度属性:
-
程度(valence)、激活(activation)、优势(dominance)
-
下载地址:
2.Emo-DB Database(German)
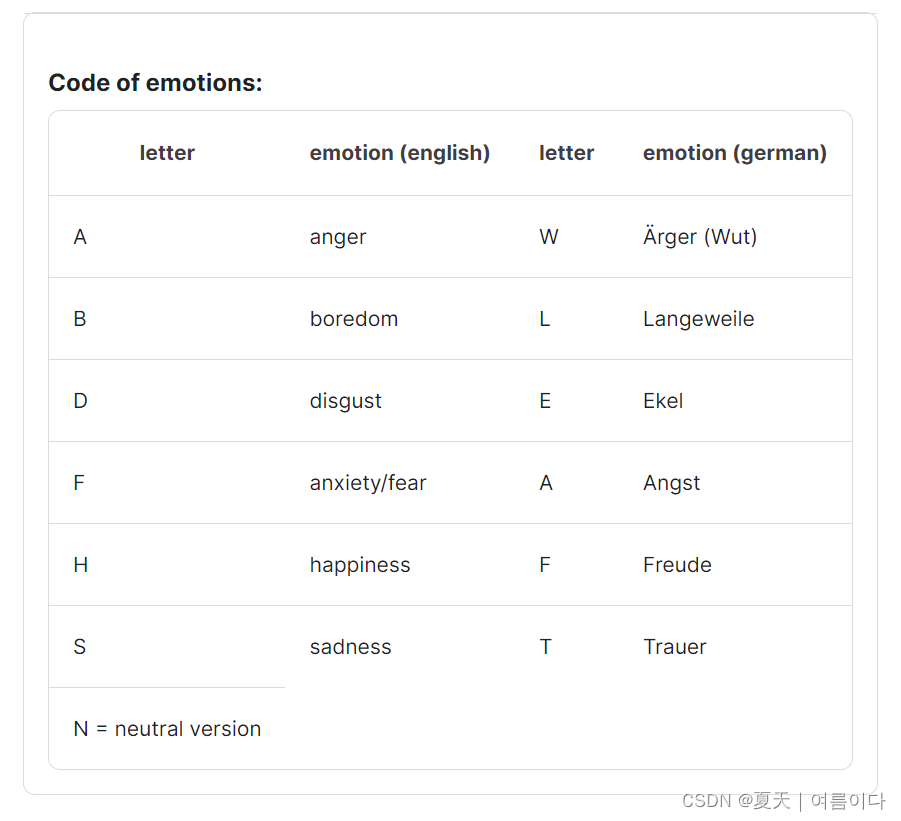
EMODB 数据库是免费提供的德国情感数据库。该数据库由德国柏林技术大学通信科学研究所创建。十名专业演讲者(五男五女)参与了数据记录。该数据库总共包含 535 条话语。EMODB 数据库包含七种情绪
1) 愤怒
2) 无聊
3) 焦虑
4) 快乐
5) 悲伤
6) 厌恶
7)中性
数据是以48kHz的采样率记录的,然后下采样到16kHz。
文件命名
每个话语都根据相同的方案命名:
- 位置 1-2:发言者人数
- 位置 3-5:文本代码
- 位置6:情感(抱歉,字母代表德语情感词)
- 位置 7:如果有两个以上的版本,则编号为 a、b、c ....
示例:03a01Fa.wav 是 Speaker 03 以“Freude”(幸福)的情绪朗读文本 a01 的音频文件。
对象
- 03——男,31岁
- 08 - 女性,34 岁
- 09 - 女,21 岁
- 10 - 男性,32 岁
- 11 - 男性,26 岁
- 12 - 男性,30 岁
- 13 - 女性,32 岁
- 14 - 女性,35 岁
- 15 - 男性,25 岁
- 16 - 女性,31 岁
3.Ryerson Audio-Visual Database of Emotional Speech and Song (English)RAVDESS
瑞尔森情感语音和歌曲视听数据库(RAVDESS):来自 RAVDESS 的语音纯音频文件(16 位,48kHz .wav)。Zenodo提供的语音和歌曲、音频和视频的完整数据集 (24.8 GB) 。RAVDESS 的构建和感知验证在PLoS ONE 的开放获取论文中有所描述。
文件
RAVDESS 的这一部分包含 1440 个文件:每个演员 60 次试验 x 24 名演员 = 1440。RAVDESS 包含 24 名专业演员(12 名女性,12 名男性),用中性的北美口音说出两个词汇匹配的陈述。言语情绪包括平静、快乐、悲伤、愤怒、恐惧、惊讶和厌恶的表情。每种表情都在两种情绪强度(正常、强烈)和一种额外的中性表情下产生。
文件命名
1440 个文件中的每一个都有一个唯一的文件名。文件名由 7 部分数字标识符组成(例如,03-01-06-01-02-01-12.wav)。这些标识符定义了刺激特征:
文件名标识符
-
模态(01 = 全 AV,02 = 仅视频,03 = 仅音频)。
-
人声通道(01 = 语音,02 = 歌曲)。
-
情绪(01 = 中性,02 = 平静,03 = 快乐,04 = 悲伤,05 = 愤怒,06 = 恐惧,07 = 厌恶,08 = 惊讶)。
-
情绪强度(01 = 正常,02 = 强烈)。注意:“中性”情绪没有强烈的强度。
-
声明(01 =“孩子们在门口说话”,02 =“狗坐在门口”)。
-
重复(01 = 第一次重复,02 = 第二次重复)。
-
演员(01 到 24。奇数为男性,偶数为女性)。
文件名示例:03-01-06-01-02-01-12.wav
- 纯音频 (03)
- 演讲(01)
- 恐惧 (06)
- 正常强度 (01)
- 声明“狗” (02)
- 第一次重复 (01)
- 第十二男演员(12)
女,演员身份证号为偶数。
下载地址:RAVDESS Emotional speech audio | Kaggle
jupyter notebook 下载命令
![ -f Audio_Speech_Actors_01-24.zip ] && echo "File existed" || wget "https://zenodo.org/record/1188976/files/Audio_Speech_Actors_01-24.zip?download=1" -O Audio_Speech_Actors_01-24.zip
解压命令
![ -f "./Audio_Speech_Actors_01-24/Actor_01/03-01-01-01-01-01-01.wav" ] && echo "File existed" || unzip Audio_Speech_Actors_01-24.zip -d "./Audio_Speech_Actors_01-24/"4.Korean Emotional Speech Dataset
https://nanum.etri.re.kr/share/list?lang=ko_KR
5.SAVEE(English)
Surrey Audio-Visual Expressed Emotion (SAVEE) 数据库已被记录为开发自动情绪识别系统的先决条件。该数据库由 4 位男演员 7 种不同情绪的录音组成,总共 480 条英式英语话语。这些句子是从标准的 TIMIT 语料库中选出的,并且对每种情绪进行了语音平衡。数据是在配备高质量视听设备的视觉媒体实验室中记录、处理和标记的。为了检查表演质量,录音由 10 名受试者在音频、视觉和视听条件下进行评估。分类系统是使用标准特征和分类器为每个音频、视觉和视听模式构建的,独立于说话者的识别率分别达到 61%、65% 和 84%。
包含六种基本情绪和中性情绪的表达情绪的视听数据库。该数据库由 4 位英语演员说出的语音平衡的 TIMIT 句子组成,总计 480 条语句。该数据库由 10 名受试者针对每个音频、视觉和视听数据的可识别性进行了评估。主观评价结果显示,与音频数据相比,视觉数据的分类准确率更高,并且通过结合两种方式提高了整体性能。在数据库上的说话人相关和说话人无关实验中实现了相当高的分类精度,其遵循与人类评估者相似的情感分类结果模式,即 视觉数据的表现优于音频,并且视听组合的整体性能得到改善。人类评估和机器学习实验结果表明该数据库对情感识别领域研究的有用性。
下载地址:Surrey Audio-Visual Expressed Emotion (SAVEE) Database
6.EMOVO(Italian)
文件名的结构为emotion _ speaker _ act。wav
情感对应的情感代码及其英文翻译如下。
- dis - disgusto (Disgust)
- pau - paura (Fear)
- rab - Rabbia (Anger)
- gio - gioia (Joy/Happy)
- sor - Sorpresa (惊喜)
- tri - triste (悲伤)
- neu - neutro (中性)
7.Multimodal EmotionLines Dataset(MELD)
通过增强和扩展 EmotionLines 数据集创建了多模态 EmotionLines 数据集 (MELD)。MELD 包含与 EmotionLines 中可用的相同对话实例,但它还包含音频和视觉模态以及文本。MELD 有超过 1400 个对话和 13000 个来自 Friends 电视剧的话语。多位发言人参与了对话。对话中的每一句话都被标记为这七种情绪中的任何一种——愤怒、厌恶、悲伤、喜悦、中性、惊讶和恐惧。MELD 还对每个话语进行情绪(正面、负面和中性)注释。
数据集下载命令
wget https://web.eecs.umich.edu/~mihalcea/downloads/MELD.Raw.tar.gz或者
wget https://huggingface.co/datasets/declare-lab/MELD/resolve/main/MELD.Raw.tar.gz下载后如图
解压命令
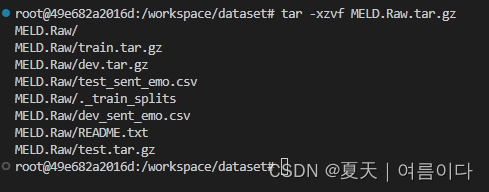
tar -xzvf MELD.Raw.tar.gz 解压后格式
其中
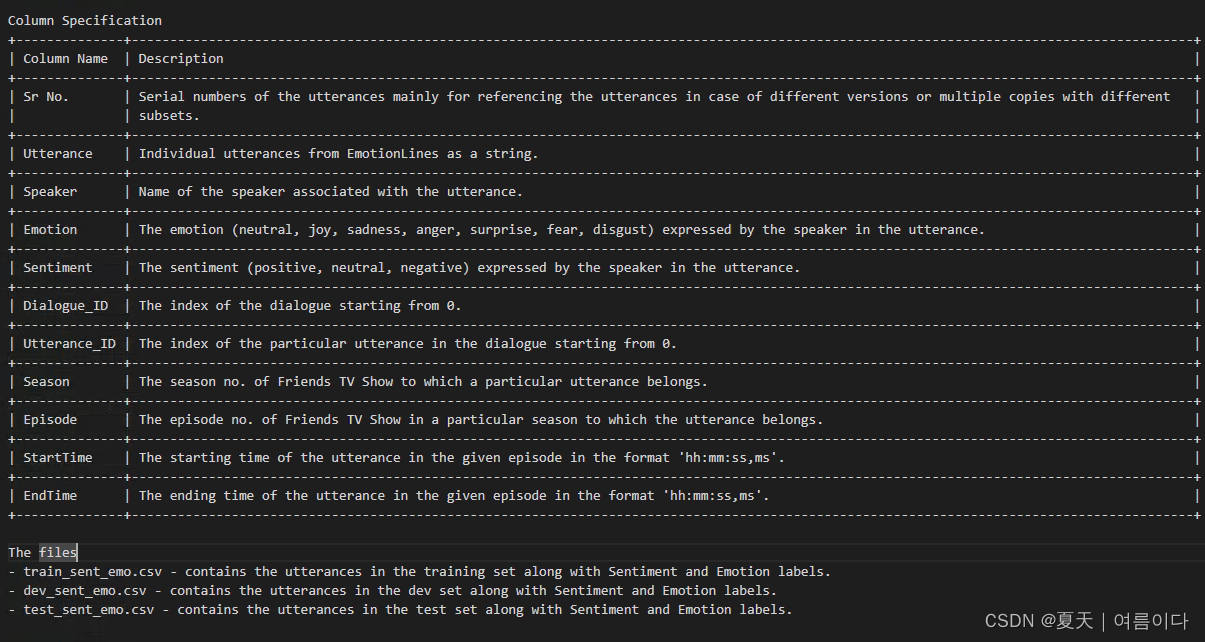
Sr No.: 语料的序列号,主要是为了在不同的版本或多个副本有不同的子集的情况下参考语料。
Utterance : 来自EmotionLines的单个语料作为一个字符串。
Speaker :与话语相关的说话人的名字。
Emotion :说话人在话语中所表达的情绪(中性、喜悦、悲伤、愤怒、惊讶、恐惧、厌恶)。
Sentiment :说话人在话语中所表达的情绪(积极、中性、消极)。
Dialogue_ID:对话的指数,从0开始。
Utterance_ID:对话中特定语词的索引,从0开始。
Season:某句话所属的《老友记》电视节目的季节号。
Episode:某句话所属的Friends TV Show某一季的集数
StartTime:在给定的情节中,话语的开始时间,格式为 "hh:mm:ss,ms"。
EndTime:在给定的情节中,说话的结束时间,格式为 "hh:mm:ss,ms"。
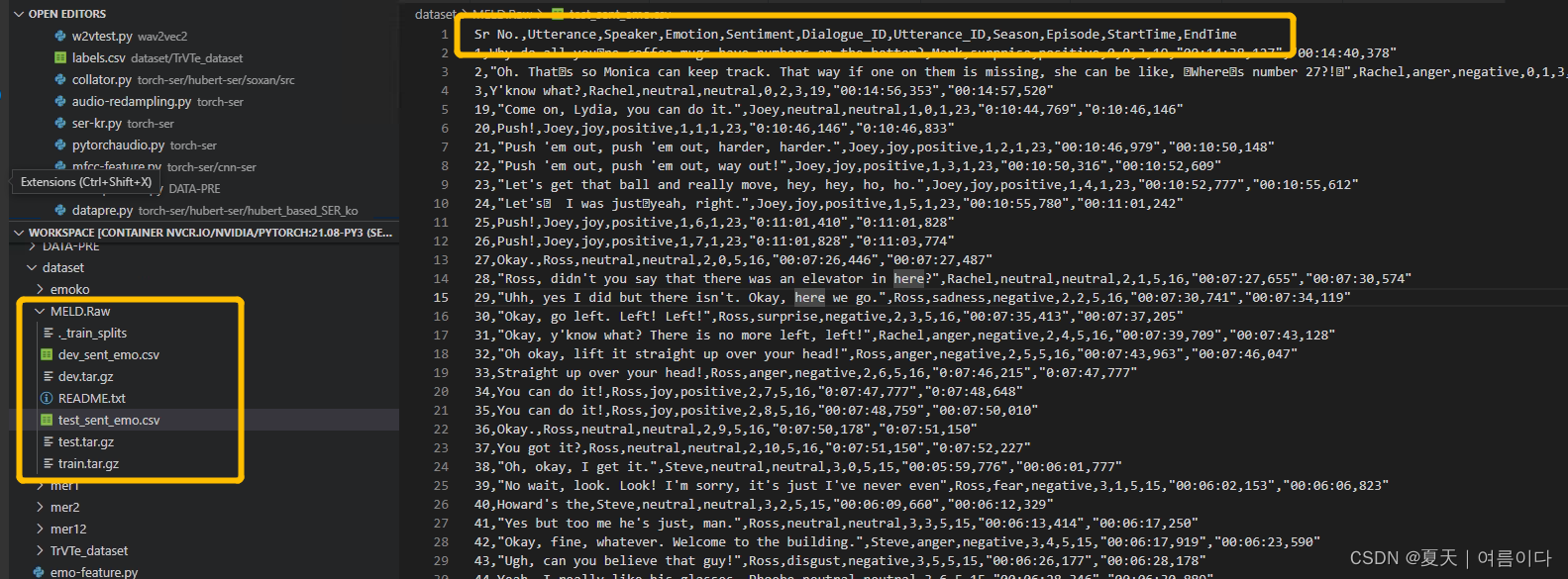
示例对话
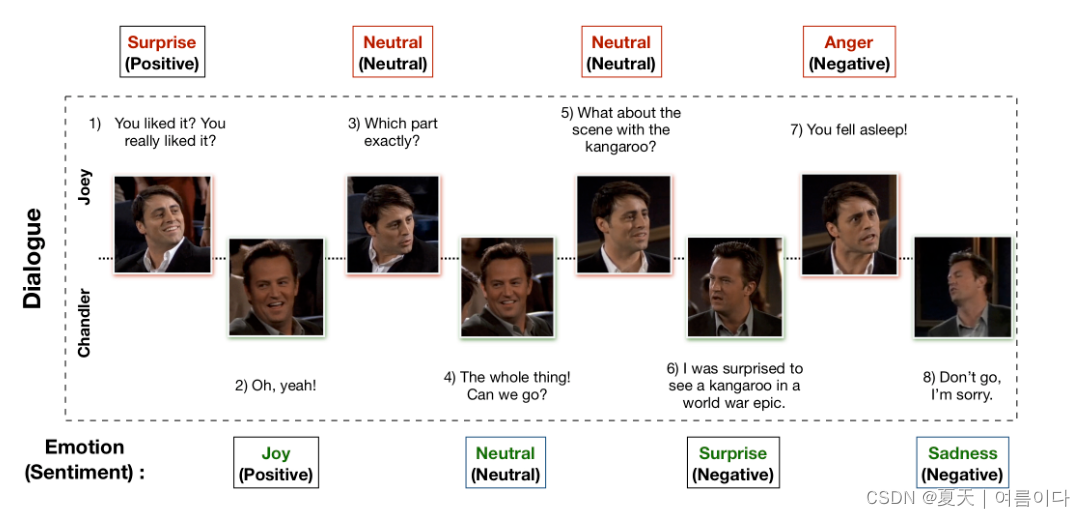
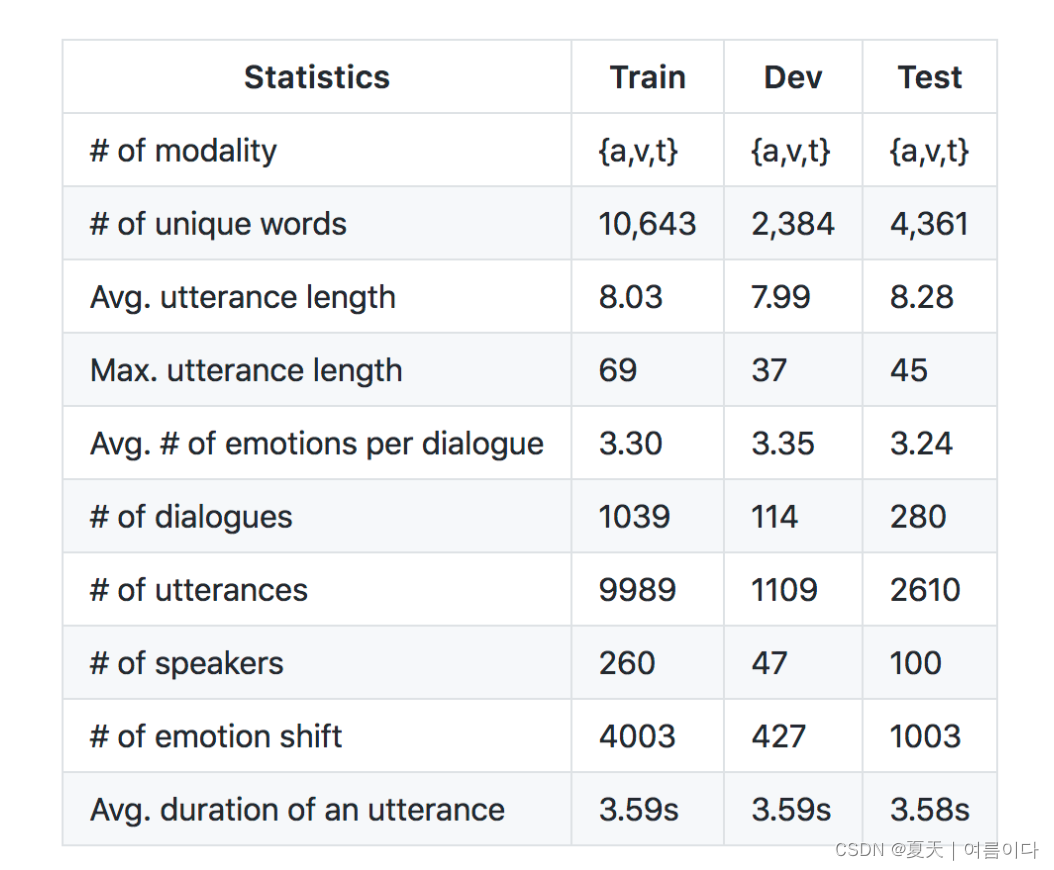
数据集统计
更多信息请参考MELD
8.CMU-MOSEI 数据集
CMU Multimodal Opinion Sentiment and Emotion Intensity (CMU-MOSEI) 数据集是迄今为止最大的多模态情感分析和情感识别数据集。该数据集包含来自 1000 多个在线 YouTube 演讲者的 23,500 多个句子话语视频。数据集是性别平衡的。所有的句子话语都是从各种主题和独白视频中随机选择的。视频被转录并正确标点符号。该数据集可通过CMU Multimodal Data SDK GitHub下载: https: //github.com/A2Zadeh/CMU-MultimodalDataSDK。

更多信息请参考
9. CREMA-D 数据集
GitHub - CheyneyComputerScience/CREMA-D: Crowd Sourced Emotional Multimodal Actors Dataset (CREMA-D)
CREMA-D 是一个包含来自 91 个演员的 7,442 个原始剪辑的数据集。这些剪辑来自 48 名男性演员和 43 名女性演员,年龄在 20 到 74 岁之间,来自不同的种族和民族(非裔美国人、亚洲人、高加索人、西班牙裔和未指明的人)。
演员们从 12 个句子中选择发言。这些句子是使用六种不同情绪(愤怒、厌恶、恐惧、快乐、中性和悲伤)和四种不同情绪水平(低、中、高和未指定)中的一种呈现的。
参与者根据组合的视听演示、单独的视频和单独的音频对情绪和情绪水平进行评分。由于需要大量的评级,这项工作是众包的,共有 2443 名参与者,每人对 90 个独特的剪辑、30 个音频、30 个视觉和 30 个视听进行了评级。95% 的剪辑有超过 7 个评分。
其中
下载数据集命令
git lfs clone https://github.com/CheyneyComputerScience/CREMA-D.git
基于计算机视觉的情绪识别数据集请参考https://blog.csdn.net/weixin_44649780/article/details/124030692#comments_26431971

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐

 4
4 1
1- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)