
学习笔记之——Event Camera(事件相机)调研
概述Event Camera是一种bio-inspired sensor,对应的领域为bio-inspired vision。对于传统的相机,从某种程度上,是捕获一个静态/静止的空间,而Event Camera的目的是:敏感地捕捉运动的物体。对于传统RGB-camera,相机传回的信息是同步的,所谓同步,就是在某一时刻t,相机会进行曝光,把这一时刻所有的像素填在一个矩阵里回传,一张照片就诞生了。一
本博文是本人调研Event Camera写下的学习记录,本博文的内容来源于网络、paper以及本人学习调研过程的心得,仅供本人学习记录用,不作商业用途。
我们团队在事件相机方面的工作请见:
 https://github.com/arclab-hku/Event_based_VO-VIO-SLAM
https://github.com/arclab-hku/Event_based_VO-VIO-SLAM目录
基于event camera的SLAM/VO及sensor fusion
Low-Latency Event-Based Visual Odometry
Simultaneous Localization and Mapping for event-based Vision Systems
EMVS: Event-Based Multi-View Stereo
Event-based, 6-DOF Camera Tracking from Photometric Depth Maps
EVO: A Geometric Approach to Event-Based 6-DOF Parallel Tracking and Mapping in Real-time
Event-based Stereo Visual Odometry
Real-Time 3D Reconstruction and 6-DoF Tracking with an Event Camera
Low-Latency Visual Odometry using Event-based Feature Tracks
Fast Image Reconstruction with an Event Camera
Joint Filtering of Intensity Images and Neuromorphic Events for High-Resolution Noise-Robust Imaging
Learning to Super Resolve Intensity Images from Events
Accurate Angular Velocity Estimation With an Event Camera
Low-latency localization by Active LED Markers tracking using a Dynamic Vision Sensor
Event-based, 6-DOF Pose Tracking for High-Speed Maneuvers
Event-based Camera Pose Tracking using a Generative Event Model
Continuous-Time Trajectory Estimation for Event-based Vision Sensors
Lifetime Estimation of Events from Dynamic Vision Sensors
EventCap: Monocular 3D Capture of High-Speed Human Motions using an Event Camera
概述
传统的相机(就是现在最常见RGB相机,如手机上的相机)我们称之为Standard Cameras,早期的图像处理(其实现在更多也是)都是基于传统相机来做的,然而传统相机在应用中有两个很明显的问题(如下图所示)。一个是运动模糊,当场景中的运动速度超过相机的采样速率之后,就会产生运动模糊,虽然可以通过算法弥补运动模糊,但是计算开销很大,不满足实时需求。另一个问题是由于光线的问题造成曝光不足或者过曝的动态范围问题,强烈的阳光可能会使传统相机无法看清视野物体。

vision-based method在robotic领域具有举足轻重的地位。然而,传统的camera所捕获的data存在是实现差、数据量大、高速运动时存在模糊、对处理器的要求高等缺陷。并且,对于机器人,特别是Quadrotor,快速、灵敏的pose estimation是非常关键的。近年来,基于pixel-level输出的event camera以其低延时(1us)深受robotic researcher的欢迎。
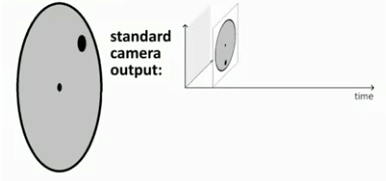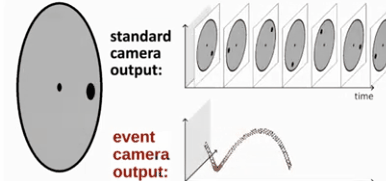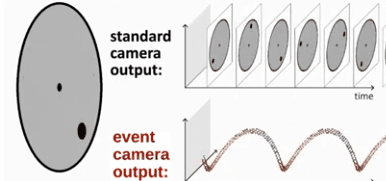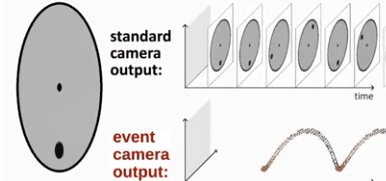
Event camera (DVS)从传感器层面解决传统相机的缺点。同传统相机不同,事件相机只观测场景中的“运动”,确切地说是观察场景中的“亮度的变化”。event camera只会在有亮度变化时,输出对应pixel的亮度变化(1或0),具有响应快、动态范围宽、无motion blur等优势。Event Camera(也有称为DVS,dynamic vision sensor)是一种bio-inspired sensor,对应的领域为bio-inspired vision。对于传统的相机,从某种程度上,是捕获一个静态/静止的空间,而Event Camera的目的是:敏感地捕捉运动的物体。 对于单个像素点,Event Camera只有接收的光强产生变化时,该像素点才会输出。比如亮度增加并超过的一个阈值,那么对应像素点将输出一个亮度增加的事件。Event Camera没有帧的概念,当场景变化时,就产生一系列的像素级(pixel-level)的输出。其理论时间分辨率高达1us,因此产生的延迟非常低,低于常见场景中的绝大多数的运动速率,因此就不会出现运动模糊问题。除此之外,事件相机的每个像素点是独立异步工作的,所以动态范围很大。事件相机还有能耗低的优势。 总结就是,传统相机以固定的帧率对场景进行全帧拍摄,所有像素同步工作。事件相机是每个像素独立异步工作,采样率高达一百万hz,且仅对亮度变化(event)进行输出,一个事件(event,亮度变化)包括发生的时刻、发生的像素坐标和事件发生的极性。 所谓事件发生的极性表示的是亮度相比于前一次采样是增加还是减少,如下图所示,红点表示为正极性,蓝色表示为负极性。

而对于传统RGB-camera,相机传回的信息是同步的,所谓同步,就是在某一时刻t,相机会进行曝光,把这一时刻所有的像素填在一个矩阵里回传,一张照片就诞生了。一张照片上所有的像素都对应着同一时刻。至于视频,不过是很多帧的图片,相邻图片间的时间间隔可大可小,这便是我们常说的帧率(frame rate),也称为时延(time latency)。
下图为event camera跟传统相机的对比。

那么从数学的角度上讲,到底什么是event呢?所谓的event也是pixel-level的。一个事件所具有的格式是一个向量,如下:
![]()
事件相机便是这样异步地回传如上所示的事件。何为异步?就是不同于传统相机同时地回传所有像素值,事件相机不同事件回传的时刻是不同的,可以看到上述事件中有一个值ti,便是这个事件发生的时间。事件相机的工作机制是,当某个像素所处位置的亮度值发生变化时,相机就会回传一个上述格式的事件,其中前两项为事件的像素坐标,第三项为事件发生的时间戳,最后一项取值为极性(polarity)0、1,(或者-1、1)代表亮度是由低到高还是由高到低,也常被称作Positive or Negtive Event,又被称作On or Off Event。就这样,在整个相机视野内,只要有一个像素值变化,就会回传一个事件,这些所有的事件都是异步发生的(再小的时间间隔也不可能完全同时),所以事件的时间戳均不相同,由于回传很简单,所以和传统相机相比,它具有低时延的特性,可以捕获很短时间间隔内的像素变化。如下所示:
当转速较慢时:

当转速交快时:

可以说,传统相机获取的是场景的静态画面,而事件相机捕捉的是场景中的运动画面,可想而知,如果场景中没有运动物体,那么事件相机就什么都看不到了。而在这点上,其实更符合人眼的实际情况。有些说法是人眼是看不到相对于人眼绝对静止的物体的,就算物体本身静止不动,但是我们人眼微小的颤动以此来捕获信息。而DVS也可以通过微小的颤动来捕获静止物体的信息甚至可以观测物体的深度信息。如下图,在运动过程中,传统相机和事件相机获取的画面的不同 (注意:对于event camera,由于其响应太快了,有时只会有很少的信息量,故此在处理中,会把某个时间段检查到的所有event都叠加到一起。进而获得一张类似“frame”的图,但却包含了某个时间段下的像素变化的feature,下图的DVS输出其实就是这个道理)。

优缺点
优点
- low time latency and high dynamic range,低时延,高动态范围,相邻Event之间的时间可以小于1微秒(~1us)。
- 由于低时延,在拍摄高速物体时传统相机会发生模糊(由于会有一段曝光时间),而事件相机几乎不会(no motion blur)。下图是在汽车大灯前跑过去的行人照片对比。传统相机捕获的行人图像已经糊成一坨。

- 由于事件相机的特质,在光强较强或较弱的环境下(高曝光和低曝光),传统相机均会“失明”,但像素变化仍然存在,所以事件相机仍能看清眼前的东西。这就能引申到很多方面,比如自动驾驶,在黑夜里行走,可能传统相机已经几乎看不到前方黑暗中的人,但事件相机看得一清二楚。(high dynamic range 140dB)。如下图所示

- 对数据存储喝计算资源的需求都比较小。相比起传统的相机,以深度学习为例,传统的vision task都需要昂贵的硬件GPU等设备来支撑。
缺点
- event camera仅输出运动的pixel。传统的视觉方法不适用(这对于researcher来说应该是好事hhh)。对于event camera而言,其输出只有正负,而没有intensity

- No intensity information (only binary intensity changes)
- 噪声大、分辨率低、信号质量差
- expensive
- Event camera是asynchronously operating pixels的,既没有办法确定什么时候下一个信号到来,也没有办法保证捕获到的信号是属于同一个时间戳的(传统的相机起码可以保证一张图片的信息来源同一个时间戳)。这样可能会在sensor fusion的时候,对信息同步处理产生一些难度。
Paper Survey
基于event camera的SLAM/VO及sensor fusion
基于传统相机的VO问题是解决mapping和tracking两个子问题,工程实践中两个子问题一般放在独立线程处理,一般mapping相比于tracking要占用较多的运算资源,因为mapping要处理大量的3D点深度估计问题。而基于事件相机的SLAM/VO也是要处理这两个子问题。
Low-Latency Event-Based Visual Odometry
VO算是比较成熟、研究比较多的方向了。但是VO的问题并没有得到真正的解决,主要是以下几点的缺陷:high-latency、motion blur、low dynamic range、high power or computing consumption。本文presented a visual-odometry pipeline using a DVS in combination with a standard CMOS camera. We used a probabilistic framework that updates the pose likelihood relative to the previous CMOS frame by processing each event individually as soon as it arrives.
The agility of a robotic system is ultimately limited by the speed of its processing pipeline.为此,作者提出采用DVS来提取信号。但是对于DVS存在如下的缺点:1、仅仅提供像素的变化,而没有像素值。2、DVS输出的是event数据,没有frame的概念,因此传统的frame-based VO的方法不再适用。为此这篇论文,作者采用的DVS+normal camera的方法。通过DVS提取低延时的events,同时通过普通的相机提供绝对的像素强度.
DVS用于感知motion(这个motion是相对的,故此既包括了camera的运动或者场景中物体的运动)

对于DVS+camera,关键点1在于外部校准。本文提出了一种unsupervised spatiotemporal calibration方法。
除此之外,作者也提到,可以通过accumulating events in a slice of time and then use it as a “frame” 又或者将DVS检测到的event作为feature tracking也是DVS的一个应用的方向,但是本文是尽可能的利用DVS的low latency的特性,所以所提出的unsupervised spatiotemporal calibration方法是用于创建一个virtual sensor来同时体现DVS与camera的数据。
由于本博文先以调研为主,具体的算法实现,先不细看。看看其实验效果吧哈~

Simultaneous Localization and Mapping for event-based Vision Systems
该文章提出了一种基于DVS的visual-SLAM,通过在individual pixel event的处理来构建高质量的2D环境地图。
DVS向着天花板。算法的流程如下图所示:

实验效果

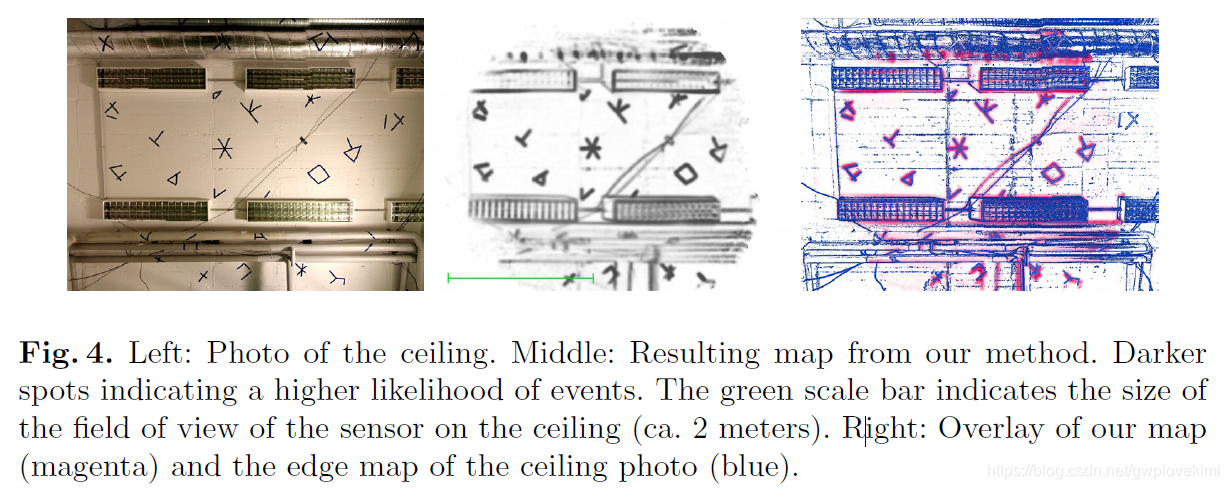
精度与实时性也取得不错的效果

Top to bottom: Three typical examples out of a total of 40 from the dataset. Left: Map and path as created by our method. Middle: Trajectories resulting from our method (red) and the external tracking system (blue). The trajectory starting point is marked with a X. Right: Positional and rotational error over number of resamples.

EMVS: Event-Based Multi-View Stereo
可参考:EMVS: Event-Based Multi-View Stereo 论文详细分析_larry_dongy的博客-CSDN博客
Event-based, 6-DOF Camera Tracking from Photometric Depth Maps
本文提出从已有的photometric depth map(例如强度+深度信息)来跟踪6 DOF的event camera的pose。先通过RGB-D sensor来构建室内空间的地图,然后通过event camera来估算6DOF的姿态。那么对应的技术难点则是:如何将event-camera的6D pose与Photometric Depth Maps相关联。
通过检测event来更新6D pose(基于bayesian filter)。设计了一个sensor likehood function来通过混合模型对事件生成过程与噪声和异常值的存在考虑进来~
这篇论文对event camera的建模以及构建其似然函数,在这方面的理论推导值得后续再深入看看~~~
EVO: A Geometric Approach to Event-Based 6-DOF Parallel Tracking and Mapping in Real-time
本文实现了快速的跟踪camera的motion,同时构建3D环境的半稠密地图。仅仅依靠DVS实现实时SLAM,不需要借助其他的sensor。而且仅仅基于CPU则可实现。下表中,给出了近年来关于事件相机的SLAM相关算法研究。然而在上述研究中只有文献【12】与本文的工作实现了仅依靠事件相机的3DSLAM算法。文献[12]提出的基于贝叶斯滤波与变分法解决3D位姿估计与地图构建。然而这个方法要求对图像的强度估计以及深度的正则化,因此对硬件有着比较高的要求,比如GPU(为了能够实时处理),另外在该论文中没有对该方法进行定量评估。

EVO的架构入选图所示。类似于PTAM,跟踪模块假设3D地图已知, 根据事件流估计相机位姿(6-DOF);地图模块假设位姿信息已知,根据新获取的事件扩展地图。两者并行,且彼此依赖。

Mapping部分
主要用了上文提到的EMVS。EVO所采用的关键帧的创建等也与EMVS一文中的策略基本相同
Tracking部分
Tracking部分的核心是 image-to-model alignment(图像-模型校准的追踪算法),该方法经常用于基于VO中。即通过当前获得的图像,与所对应的3D model进行对齐配准,得到运动参数。具体而言,首先通过事件积累得到2D的积累图。再从Mapping得到的相邻关键帧对应的local map中,选取具有逆深度的地图点,假设当前相机位置将这个local map投影到当前图像平面,再利用LK方法进行对齐。具体采用的是逆增量式LK算法,这种方法可以提前计算一部分矩阵,提高计算速度。
下图示意了tracking的过程。(a)为已知的模型(即通过mapping部分建立的local map),(b)为关键帧看到的图像,将这个图通过warp,与(c)的事件积累图进行对齐,得到(c.)对应的相机位姿。

实验效果如下图所示。可以看到EVO估算出来轨迹(蓝色)跟真实的轨迹(红色)相差不大。

Event-based Stereo Visual Odometry
此文章的主要贡献在于:
-
一个基于双目 Event Camera 的 Visual Odometry,同时实现 semi-dense 的建图。
-
提出一种新的基于优化的方法来实现逆深度的估计,基于 event 的 spatio-temporal 一致性。
-
基于估计出的逆深度的概率分布,提出一种 fusion 的方式,来提升三维重建的密度和精度。
-
通过 3D-2D 进行 registration 来进行 tracking。
Real-Time 3D Reconstruction and 6-DoF Tracking with an Event Camera
通过一个hand-held event camera来实现3D重建。这是第一篇基于单个手持DVS来联合估计3D场景结构、camera的6D位姿。同时也是第一篇通过single DVS来估算3D depth。
本文提出的方法基于三条交错的滤波算法:
- One tracks the global 6-DoF camera motion
- the second estimates the log intensity gradients in a keyframe image|a representation which is also in parallel upgraded into a full image-like intensity map
- the third lter estimates the inverse depths of a keyframe
上面的第二点和第三点实际上是mapping的过程。对于tracking采用的是EKF。关于pose与depth的估计如下图所示。有点像,通过一个位姿的优化来实现检测的event的对准???
感觉对这篇论文看得不是很理解,应该是自己对于VSLAM的一些基础不够扎实导致的,先mark一些,后面再深入解读~~~

第一个模块,Tracks global 6-DoF camera motion。采用的是扩展卡尔曼滤波EKF。在预测阶段使用constant position motion model。观测模型计算了同一个像素在对数域上的亮度变化。更新部分就是正常的EKF的更新。
第二个模块,Estimates the log intensity gradients in a keyframe image。依旧是关注观测模型,两个时域上相邻的坐标一致的event,投射到关键帧,进行计算梯度,并且做了恢复对数域上的超分辨的亮度图。

第三个模块,Estimate the inverse depths of a keyframe,如下图。这里的做法和LSD-SLAM基本一致,不同的是这里是关注的是亮度变化并且是在对数域上衡量的。 最后再加一个regularization操作,目的是让深度图更加平滑,达到降噪的效果。

基于一个关键帧的估算的实验效果如下图所示。从左到右,第一栏是可视化的event stream;第二栏是所估计的关键帧的梯度;第三栏是关键帧所构建的强度图像(做了炒粉处理);第四栏是估计的深度图像;最后一栏是估算的半稠密点云

基于multiple keyframe的估算的实验效果如下

Low-Latency Visual Odometry using Event-based Feature Tracks
本文采用Dynamic and Active-pixel Vision sensor (DAVIS,it is an integrated sensor comprising a conventional frame-based camera and an asynchronous event sensor.)。Features are first detected in the grayscale frames and then tracked asynchronously using the stream of events. The features are then fed to an event-based visual odometry algorithm that tightly interleaves robust pose optimization and probabilistic mapping.
DAVIS实际上就是把传统的frame-based camera与event camera结合一起。进而结合两者的优点。而本文则是先通过frames检测features,并且通过events来跟踪这些features,进而实现visual odometry。流程如下图所示:

基于event camera的图像复原
近年来,cv的顶会上,有不少的基于event camera成像的图像去噪、去模糊、超分辨率重建。由于本人之前从事过超分方面的研究,为此这里仅仅介绍超分方面的一些工作。对于event camera,其分辨率一般相对较低,基于event camera的超分辨率重建是一个不错的研究方向。
Fast Image Reconstruction with an Event Camera
本文认为,虽然DVS采集的亮度的变化而非传统的像素,但是也可以将event信号通过算法转换为有用的图像表达,来用于某些task(例如classification)We propose a novel neural network architecture for video reconstruction from events
对于这种通过DVS采集的event转化为image的工作,个人想法是实际的意义不是很大~~~故此不深入查看了哈,有兴趣的读者可以看看
Joint Filtering of Intensity Images and Neuromorphic Events for High-Resolution Noise-Robust Imaging
该文章结合普通相机与事件相机的数据,来进行估算运动参数、导向滤波,超分等任务,同时这个框架后续可以用于特征跟踪等任务。

Learning to Super Resolve Intensity Images from Events
本文提出的是,直接由事件相机数据重建超分图像(end to end)

看着恢复的效果也不错~

基于event camera的光流与运动估计、特征跟踪
通过图片及其对应的event camera数据,对图像中的场景进行光流估计或者物体运动估计。进而用于运动分割、物体跟踪、运动姿态捕捉等任务。Event-based camera不能等同于传统相机,因此在一些传统视觉应用上,比如语义理解上,并无优势。然而它的长处应该主要在于运动检测,尤其是高速条件下。
Accurate Angular Velocity Estimation With an Event Camera
本文提出了估算DVS的旋转运动的算法(不需要光流或图像强度)。
The method aligns events corresponding to the same scene edge by maximizing the strength of edges obtained by aggregating motion-warped events.

通过估算运动,来恢复DVS捕获的event信息,从而获得清晰的物体轮廓,而不是直接累积event。因为直接累积event可能会产生blur(在这点上,有点类似基于运动估计的deblur)
Low-latency localization by Active LED Markers tracking using a Dynamic Vision Sensor
DVS fixed to the ground was used to recover the pose of a quadrotor during flight by tracking LEDs mounted on the platform, which were blinking at very high frequencies.
该论文提出一种基于DVS的pose tracking方法。特别的是,其采用了Active LED Markers。通过1~2kHZ的高频信号来控制LED的亮灭(有点类似于可见光通信);而DVS也足够的快,可以响应不同的LED的blinking frequencies,因此可以用不同的频率来区分LED marker(在一点上,其实正是本人后来研究的基于频率调制的VLC-ID识别:IEEE Xplore Full-Text PDF:)
下图显示了不同情况下的直方图:a、静态的相机对应静态的LED marker;b、动态的相机对应静态的LED marker;c、动态的相机(没有LED marker)。由此可以看出,相机的鱼洞会产生大量的events,但其对应的频率都是低频的。因此可以简单的通过图像,既识别出相机的运动,也可以识别出不同LED marker的ID

Event-based, 6-DOF Pose Tracking for High-Speed Maneuvers
基于onboard sensor的low latency的感知对于quadrotors是极其重要的。大部分control-based的研究都是基于精准的external motion capture system。
本文通过DVS来估算quadrotor的6D pose。如下图所示,对于normal camera而言,会产生motion blur;对于DVS而言,可以较为精确检测出运动,并且下图c通过累积一段时间的event,可以较好的把物体轮廓显示出来。但是如果累积一定时间间隔内发生的event,并采用传统的CMOS相机的姿态估计算法处理这些“集成”图像进行位姿估计,那么同样的会出现延时。为此本文作者希望通过single event的信息来估算pose。故此,作者提出的算法,先通过integrating events,直到其pattern被检测出来,然后实时(基于single event)更新lines以及pose (Lines are tracked in an event-based manner)。


Event-based Camera Pose Tracking using a Generative Event Model
本文采用概率生成event model来实现基于DVS的定位。设计基。于likelihood function来处理所观测的event。基于给定的3D稠密地图,通过采用EKF来对DVS进行定位。而本文的贡献在构建观测events的likelihood function
Continuous-Time Trajectory Estimation for Event-based Vision Sensors
本文提出了一种基于DVS的ego-motion estimation,采用continuous-time framework来直接整合相机传递的信息。根据观测的events来估算DVS的位姿轨迹。
但是,由于DVS没有frame的概念,单个event不能提供足够的信息来实现6D的pose estimation,同时,也不可以通过传统的CV的方法,通过简单的考虑几个events来实现pose estimated。其次,DVS每秒可以产生大约个events,难以对所有的events都estimate pose。因此,作者提出continuous-time framework approach

定位的效果还是蛮不错的~
Lifetime Estimation of Events from Dynamic Vision Sensors
本文提出了增强每个event 的lifetime的算法。如下图所示。DVS在建筑物前移动,b为累积30ms;c为1ms的event输出。可以看到,time interval太长会产生一些blur,而time interval太短则看不起物体的轮廓。而作者提出的算法d则可以较好的显示物体的轮廓~
作者实际上做的,就是建立一个model,把event累积到在pixel上可以辨识物体轮廓。因此可以用传统的computer vision的方法来对其进行处理。

EventCap: Monocular 3D Capture of High-Speed Human Motions using an Event Camera
使用event camera捕捉人体3D运动

运动检测、分割(segmentation)、运动补偿
检测的效果:
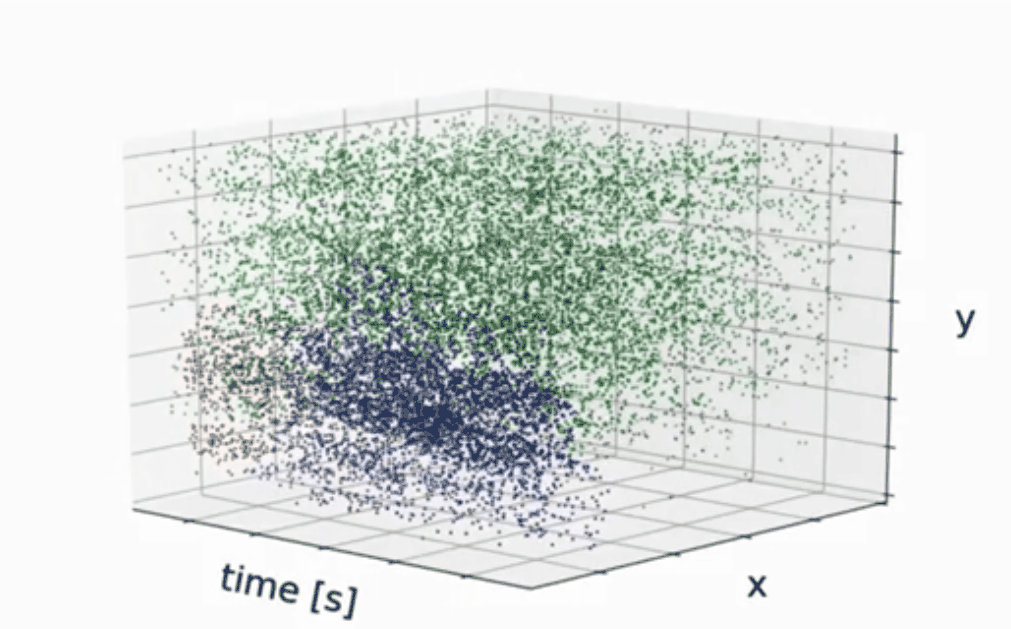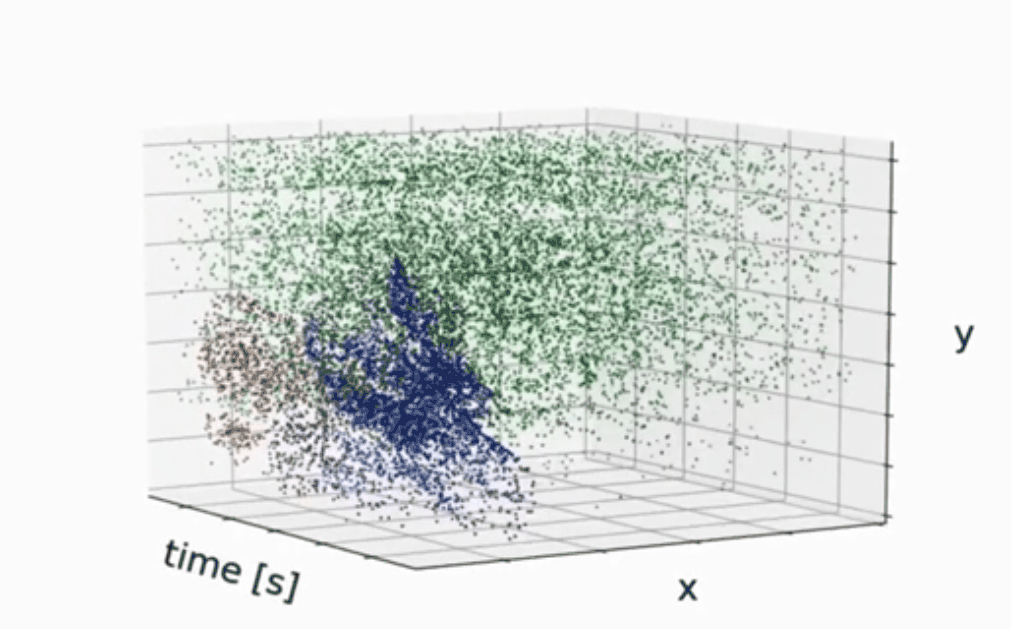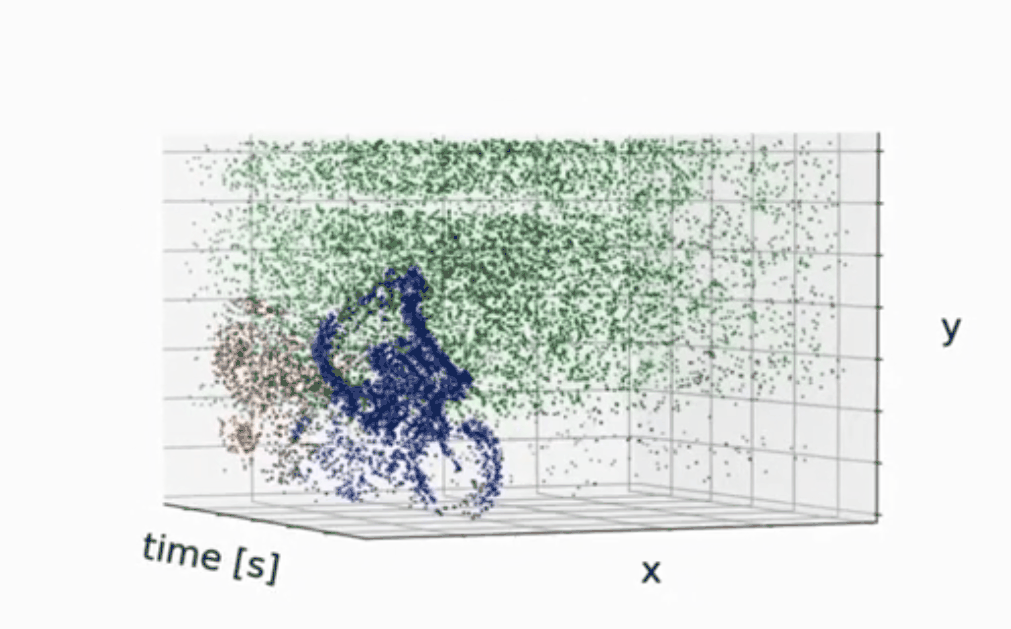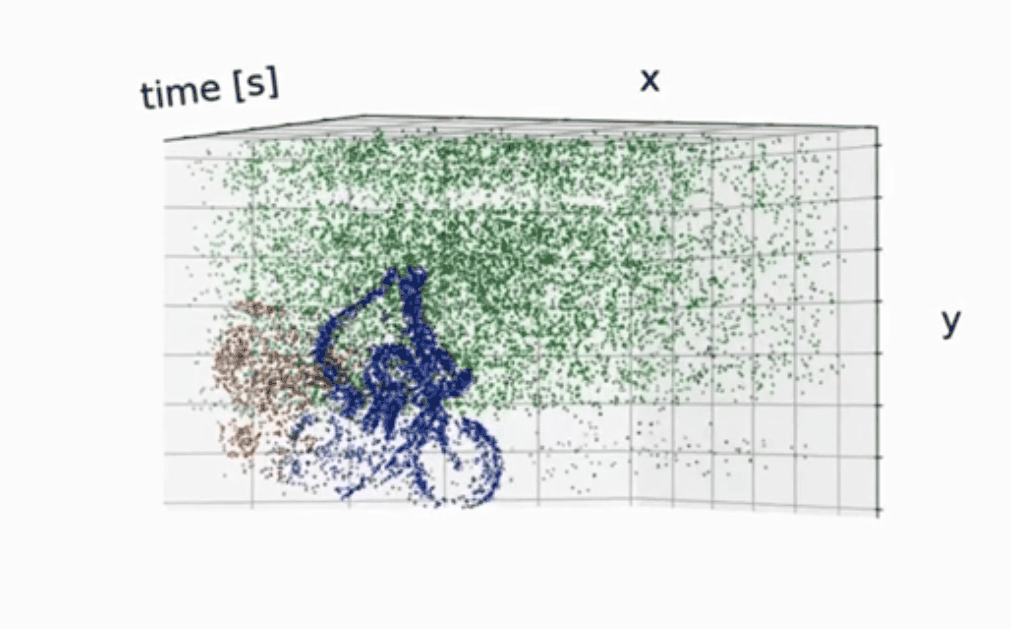
分割的效果:
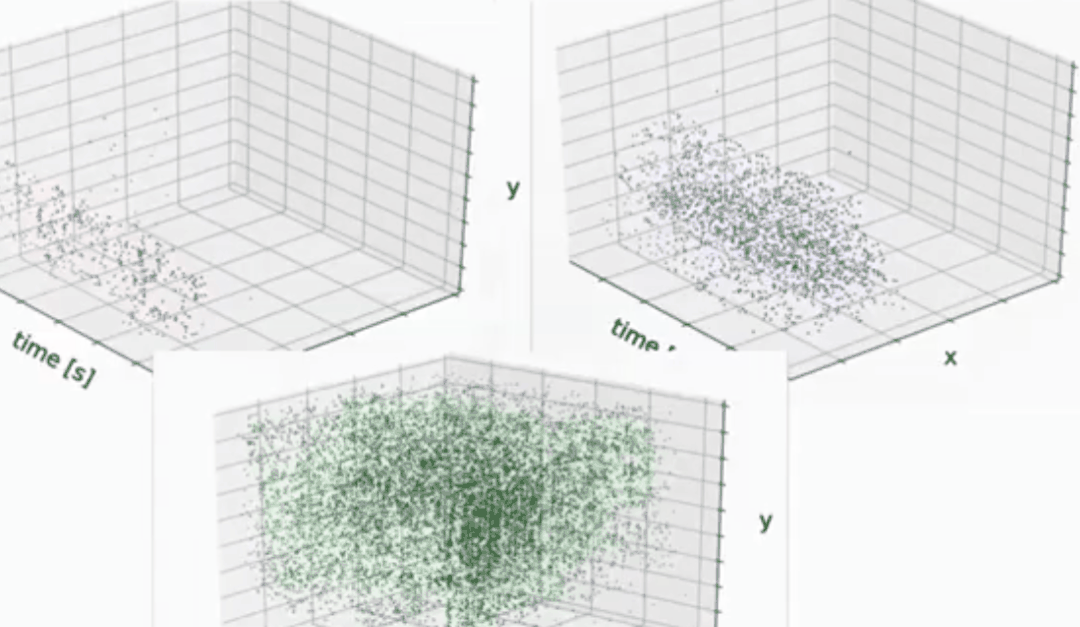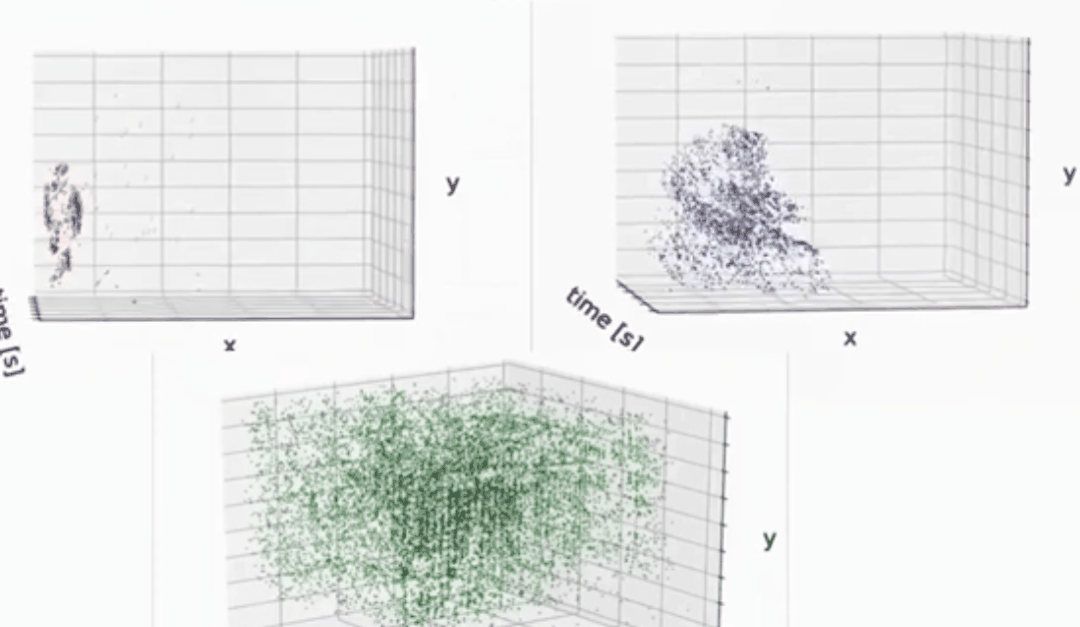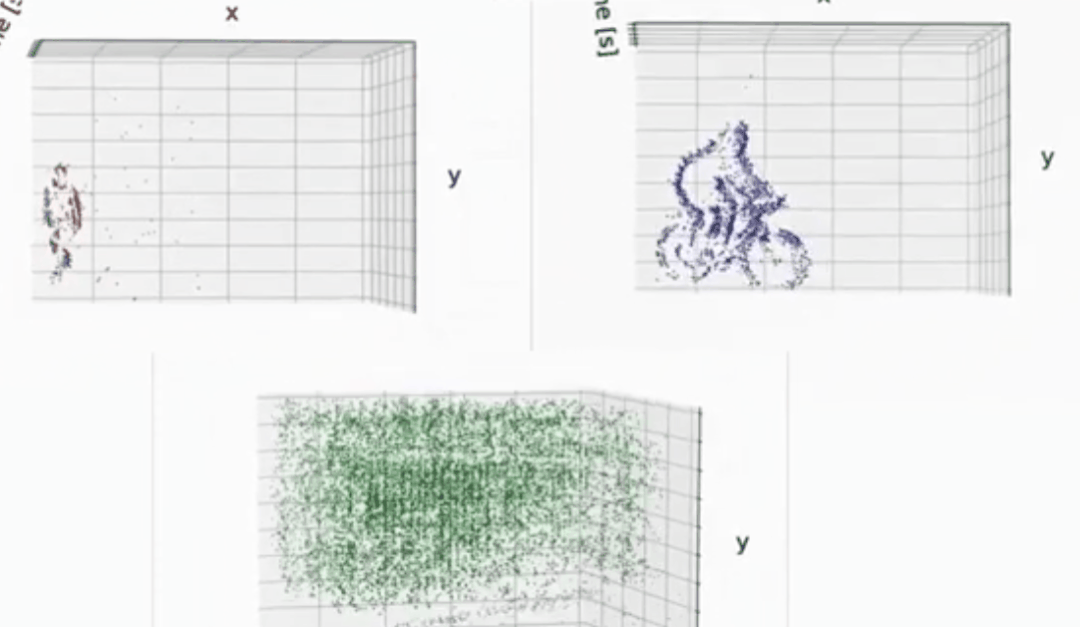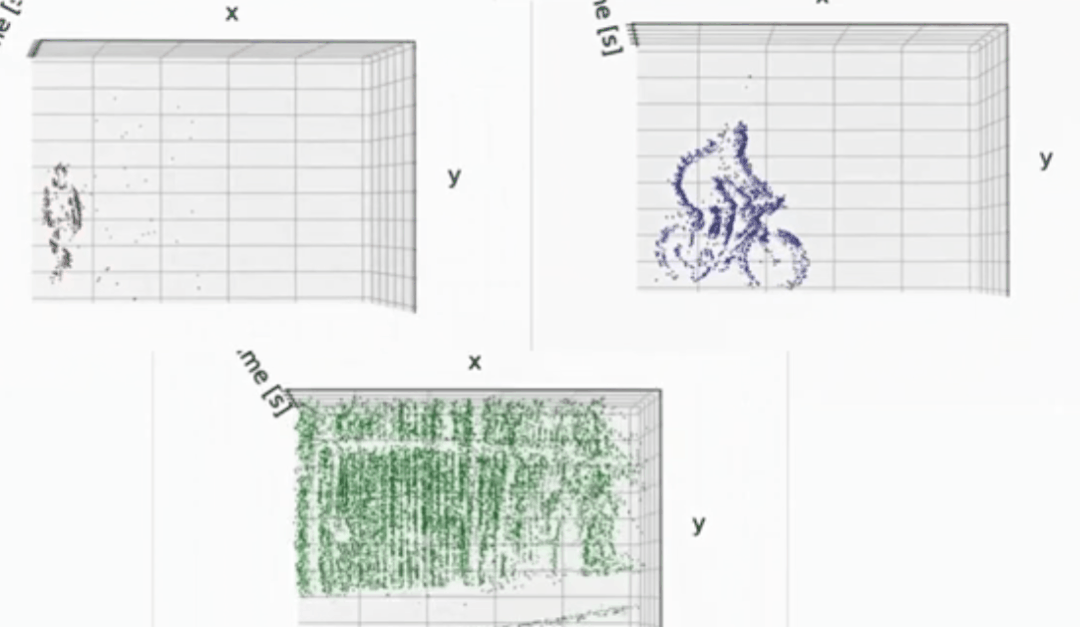
如下动图所示,通过event camera也是可以较好的提取前景,或者捕获运动物体轮廓等
障碍物检测(高速避障)

总结与思考
近年来,vision-based方法在robotic中得到了广泛的研究,而DVS的出现无疑是一个新的研究领域。DVS以其独特的优点(低延时,无blur,计算量少,高动态范围)势必在robotic中引起越来越多的关注。DVS输出的pixel-level的事件信息,虽然跟传统的CV方法所处理的frame数据不一致,但其特有的特性,起到了feature point的意义。个人想法:虽然说传统的图像更加符合人眼所观察到的实际,但是并不代表适合计算机理解。而在vision-based localization中的应用则可以为通过event camera来捕获运动的特征点,进而应用传统的vision-based method来实现robotic的定位等任务。
对于event camera,其具有功耗低、帧率高等特点,非常适合visual SLAM的需求。传统的相机其帧率都是30~60pfs,event camera在发现某处亮度变化时,就会马上输出一个事件,其响应特别快(~1us=HZ,比IMU还要快),可以满足robot localization中的快速响应的要求。而且对于event camera而言,event一般会出现在明暗分界线很明显的地方。而对于feature-based method而言,feature point一般也是出现在明暗分明的地方。故此从某种程度上,event camera可以帮忙过滤掉一些无用的信息,减少计算量,甚至其输出的event就可以当作特征来处理了。
但是event camera相比传统相机一个麻烦的地方在于,其每个event的时间都不一样,而对于传统的pose estimation中,两帧至少需要4个matched points(参考博文《学习笔记之——针孔相机模型及单应性矩阵》),也就是说至少需要4个点出现在同一个时间里,当然啦,由于event camera响应这么快,在极短的时间内的两个event也可以认为是同一时间出现的~
除此以外,在光线特别亮或者特别暗的时候,还是可以有feature的,在这点上,比起传统的camera有更大的优势。对于robotics而言,在特殊场合的建图,如地下矿井、隧道、夜晚等,会存在光线不足而建图的feature point不足的问题。但利用event camera则可以具备很大的优势
而至于sensor fusion,则是在高速event的基础上同时集成了普通相机、IMU等。通过将传统的图像与event结合一起,应该也是有很大的潜力~记得上沈劭劼老师课的时候,老师曾经说“Visual-inertial state estimation已经研究得很成熟了,如果想研究这个领域,请再想想”。那么现在看来,基于传统的Visual-inertial state estimation或者以这些传统的方法作为一个出发点,结合DVS的topic应该会是不错的方向。
但其中一点是,对于Quadrotor而言,一般其最小的单元会是IMU与camera。额外的DVS可能会带来一些问题,同时DVS的价格应该还是比较贵,对于商业化的应用存在一定的阻碍。

思考1:Visual Odometry based on Event Camera
对于基于传统camera的visual odometry,存在以下缺点:
- high-latency
- motion blur
- low dynamic range
- high power or computing consumption
针对传统相机的这些缺点,基于event camera的视觉里程计会有较好的研究前景。且本身event camera就会输出pixel-level的event,降低了冗余的信息提取。换句话说,传统的图像,通过提取特征点,来实现VO。而特征点的位置则是像素变化明显的角点的位置。而event camera则输出像素变化的信息,从某种程度上,event camera输出的就可以认为是传统意义的feature points了,只是可能需要再进一步提取与描述,即可。
思考2:Visual-inertial state estimation for event-based camera
思考3:Visual-Lidar Fusion based on event-based camera
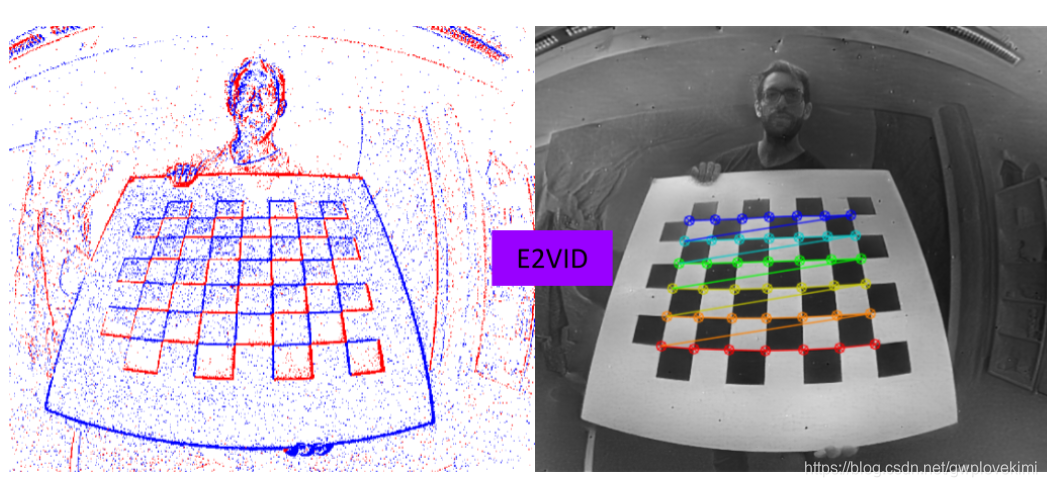
思考4:event-based camera的calibration
对于perception与localization而言,sensor modeling是极其重要的。为此event camera的model与calibration也是不容忽视的。但是由于成像方式不一样,传统的camera calibration的方法应该是不适用于DVS的?但毕竟作为规则的相机,应该都是可以使用pinhole camera model来决定内参。但是对于DVS,需要将校正的pattern移动并且integrate events to ”see“。

ROS已经提供了一些包来做校正处理,同时也有不少的paper对这方便进行了研究,后面如果真的开始DVS的topic,应该从calibration以及data perception两方面入手会比较合适~
参考资料 or 推荐资料
The Event Camera Dataset and Simulator(ETH的event camera数据集)
GitHub - uzh-rpg/rpg_esim: ESIM: an Open Event Camera Simulator(事件相机的仿真器)
GitHub - uzh-rpg/event-based_vision_resources(学习资源)
DSEC – A Stereo Event Camera Dataset for Driving Scenarios(A Stereo Event Camera Dataset for Driving Scenarios自动驾驶场景的event camera的数据集)
Event Cameras, Event camera SLAM, Event-based Vision, Event-based Camera, Event SLAM(ETH event camera的研究汇总)
https://www.rit.edu/kgcoe/iros15workshop/papers/IROS2015-WASRoP-Invited-04-slides.pdf(event camera的turtorial)
GitHub - uzh-rpg/rpg_dvs_ros: ROS packages for DVS(ROS DVS driver以及内参+外参立体校正)
GitHub - uzh-rpg/event-based_vision_resources(相关的github资源,整理了event camera的一些资源)
Tutorialonevent-basedvision.pdf-互联网文档类资源-CSDN下载 (event camera的turtorial)
事件相机(Event Camera)及相关研究简介——新一代相机?新的计算机视觉领域?_CyrilSterling的博客-CSDN博客_事件相机
http://rpg.ifi.uzh.ch/docs/EventVisionSurvey.pdf(一个不错的综述)
https://en.wikipedia.org/wiki/Event_camera(wiki)
一些视频:
相机跟踪:Event-based, 6-DOF Pose Tracking for High-Speed Maneuvers using a Dynamic Vision Sensor:
https://www.youtube.com/watch?v=LauQ6LWTkxM
相机跟踪:Event-based, 6-DOF Camera Tracking from Photometric Depth Maps:
https://www.youtube.com/watch?v=iZZ77F-hwzs
相机跟踪:Event-based, Direct Camera Tracking from a Photometric 3D Map using Nonlinear Optimization (ICRA’19):
https://www.youtube.com/watch?v=ISgXVgCR-lE
校准:Event-Based Camera Calibration
https://www.youtube.com/watch?v=OK_m6OobntE
三维重建:3D Reconstruction Experiments from a Train using an Event Camera
https://www.youtube.com/watch?v=fA4MiSzYHWA
EVO:第一篇事件相机实时SLAM的论文_larry_dongy的博客-CSDN博客_事件相机slam
EMVS: Event-Based Multi-View Stereo 论文详细分析_larry_dongy的博客-CSDN博客
EMVS: Event-Based Multi-View Stereo 论文详细分析_larry_dongy的博客-CSDN博客

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 63
63 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)