

深度学习入门——深度卷积神经网络模型(Deep Convolution Neural Network,DCNN)概述
机器学习是实现人工智能的方法和手段,其专门研究计算机如何模拟或实现人类的学习行为,以获取新的知识和技能,重新组织已有的知识结构使之不断改善自身性能的方法。计算机视觉技术作为人工智能的一个研究方向,其随着机器学习的发展而进步,尤其近10年来,以深度学习为代表的机器学习技术掀起了一场计算机视觉革命。本文将针对典型的深度学习技术——深度卷积神经网络进行介绍,主要介绍深度卷积神经网络的基础知识。
本文主要对自己以前所学进行总结。最新技术还在研究中......
1 引言
机器学习是实现人工智能的方法和手段,其专门研究计算机如何模拟或实现人类的学习行为,以获取新的知识和技能,重新组织已有的知识结构使之不断改善自身性能的方法。计算机视觉技术作为人工智能的一个研究方向,其随着机器学习的发展而进步,尤其近10年来,以深度学习为代表的机器学习技术掀起了一场计算机视觉革命。本文将针对典型的深度学习技术——深度卷积神经网络进行介绍,主要介绍深度卷积神经网络的基础知识。
2 深度卷积神经网络基础
随着信息技术的不断发展,各类视频图像数据量急剧增长,从大量视频图像数据中提取隐含的信息、并挖掘其潜在的价值具有非常重大的意义。
随着人工智能的发展,计算机视觉技术得到了愈发广泛的应用。例如视频监控中人脸识别和身份分析、医疗诊断中各种医学图像的分析与识别、细粒度视觉分类、人脸图像属性识别、指纹识别、场景识别等,计算机视觉技术逐渐渗透到人们的日常生活与应用中。然而传统的手动提取图像特征,再进行机器学习的计算机视觉方法在应对这些应用时越来越显得力不从心。从2006年开始,深度学习进入了人们的视野,尤其2012年AlexNet赢得ImageNet大规模视觉识别挑战赛的冠军之后,深度学习在人工智能领域取得了令人瞩目的发展,它在计算机视觉、语音识别、自然语言处理、多媒体等诸多领域都取得了巨大成功。深度学习与传统模式识别方法的最大不同在于它是从大数据中自动学习特征,而非采用手工设计的特征,而好的特征可以极大提高模式识别系统的性能。在计算机视觉领域中,深度卷积神经网络成为了研究的热点,其在图像分类、目标检测和图像分割等计算机视觉任务中都起到了至关重要的作用。本节将对深度卷积神经网络的基础知识进行介绍。
2.1 人工神经网络
人类的神经系统由几千亿个神经元组成,每个神经元的组成都包括树突、轴突、细胞体。人类每天接受无数的视觉、听觉信息等,这些信息的处理都是由神经系统来完成的,树突接受信息并将其传给细胞体,轴突接受信息将信息传出。人工神经网络模拟人的神经系统的结构和功能,是一种信息处理系统。
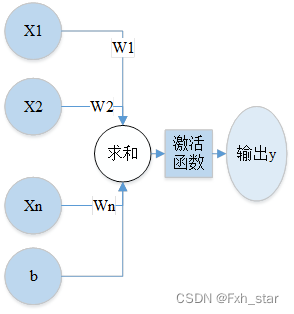
图2-1 人工神经元结构
如图2-1所示为单个人工神经元的结构,该神经元有n个输入,分别为 ,连接线上的值为每个输入的权重(weight),分别为
,激活函数(activation function)为
,偏置项(bias)为
,神经元的输出为:
。
人工神经网络是一种运算模型,它由大量的人工神经元(也称为节点)相互连接组成,每两个相互连接的神经元都代表对通过的信号加权值。前向神经网络为一种简单的人工神经网络模型,包括输入层、隐藏层和输出层,输入层有一层,输出层有一层,隐藏层有多层,每层都有数个节点,每层之间的节点没有连接,层与层之间节点的关系靠权重来衡量。前向神经网络也可称为全连接层,它的网络结构较单个神经元更复杂,但是输出仍然满足输入与权重相乘再过激活函数的关系。
人工神经网络的输出受很多方面的影响,如网络结构、输入 、权重
和激活函数等。神经网络构建完成,其网络结构、激活函数就固定了,若要改变输出就要改变权重
,因此,神经网络的训练过程就是不断优化参数 的过程。训练包括两个过程:前向传播和反向传播。首先,构建神经网络并输入被训练的数据,神经网络计算输出结果,这就是前向传播;然后,计算输出结果和输入数据的真实标签之间的差值(即损失函数),网络根据这个差值来更新参数
的值,这是反向传播。神经网络的训练过程就是循环进行前向传播和反向传播,对每个神经元进行权重参数的调整、非线性关系的拟合,最终得到比较好的模型精度。
模型拟合程度的好坏与激活函数有很大的关系。神经网络激活函数的作用是对输入信号进行非线性计算,并将其输出传递给下一个节点。常见的激活函数有三种:Sigmoid激活函数、Tanh激活函数、ReLU激活函数。Sigmoid激活函数如图2-2所示,输入较大或较小时,函数的梯度很小,由于在反向传播算法中使用链式求导法则计算参数的梯度,当模型使用Sigmoid函数时,容易产生梯度消失的问题。Tanh函数与Sigmoid函数比较相似,输入较大或者较小时函数梯度较小,容易产生梯度消失的问题,不利于权重的更新。ReLU函数有更多的优势:输入为正数时,梯度恒定,不会为零;计算速度快。但它也有致命的缺点:输入为负时,梯度完全消失,所以激活函数的使用需要根据实际需求来确定。


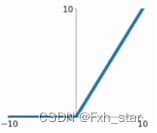
图2-2 Sigmoid激活函数 图2-3 Tanh激活函数 图2-4 Relu激活函数
在反向传播中,损失函数(loss)很重要。常用的损失函数有均方误差损失函数(mean squared error_loss,mse_loss)、自定义损失函数和交叉熵损失函数(cross entropy),其中在图像分类中最常用的是交叉熵损失函数。在分类问题中,假设共有n种类别,分类器的输出就是输入分别被预测为这n个类别的概率,即输出n个概率。如公式(1),交叉熵描述的是两个概率分布之间的差,差越小,这两个概率越相近,差越大,两个概率之间差异越大。 代表真实标签,
代表的是预测值。
(1)
2.2 卷积神经网络(Convolutional Neural Networks,CNNs)
卷积神经网络是人工神经网络的一种改进,增加了卷积层(Convolutional Layer)和池化层(Pooling Layer),卷积神经网络的训练过程与人工神经网络相同,包含前向传播和反向传播。下面详细介绍卷积层和池化层。
(1) 卷积层
卷积神经网络是一种权值共享网络,相比于普通的神经网络,其模型复杂度降低,参数量大大减少,这得益于卷积的两个重要特征:局部感受野和参数共享(Parameter Sharing)。
传统的神经网络每个输入神经元与输出神经元是全连接的,每个输入神经元和输出神经元之间由一个参数来描述。而卷积神经网络的卷积核滤波器尺寸远远小于输入大小,其连接是稀疏的。图像的局部像素联系比较紧密,相隔较远的像素相关性较弱,神经元没有必要对全局图像进行感知,只需要对局部图像进行感知,在高层将局部信息结合得到全局信息。使用卷积核处理一幅图像,检测到局部有意义的特征,与卷积核大小相同的空间上的连接范围被称为感受野(receptive field),卷积层的层数越高,感受野越大,感受野对应的原始图像区域越大。局部感受野大大减少了参数量,下面举例说明。若输入图像大小为1000 1000,隐藏层神经元个数为100万,如果它们全连接,则有1000
1000 =1000000=
个连接,有
个参数;若卷积核大小为10
10,那么局部感受野大小为10
10,隐藏层的每个神经元只需和10
10大小的区域相连接,共有10
10 1000000=
个连接,即有
个参数。
上例中,利用局部感受野大大减少了参数量,但数量仍然很庞大。每个神经元都连接10 10大小的图像区域,故每个神经元都有10
10=100个参数,若令每个神经元的参数都相同,即每个神经元都用同一个卷积核去卷积,那么共只需要100个参数,这就是参数共享。但是一种卷积核只能提取一种特征,故卷积时使用多个卷积核,每个卷积核滤波器的参数不同,表示提取输入图像的不同特征。有几个卷积核,就能提取出几种特征,将这些特征排列起来,组成特征图(feature map)。局部感受野和参数共享大大减少了模型参数量,节省了内存空间的同时模型的性能也不会下降。
(2)池化层
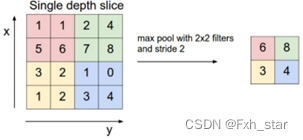
图2-5 最大池化示意图
池化层也称为下采样(downsampling)层,一般来说,池化对每个特征图操作,目的是减小特征图的大小。池化分为最大池化(Max Pooling)和平均池化(Average Pooling)两种,图2-5所示为最大池化,池化核大小为22,步长为2
2,通俗来讲最大池化操作是找到2
2池化核与某一深度特征图的重合部分,然后取重合区域最大值,得到下采样值。按步长移动池化核位置,得到输出特征图。平均池化的操作与最大池化类似,不同的是取重合区域像素点的平均值。
2.3深度卷积神经网络的优化
为了达到更好地性能,卷积神经网络的层数越来越深,深度卷积神经网络的层数越深,需要学习的参数越多,网络越难优化。若没有良好的优化方法,会出现过拟合或者欠拟合的问题。
过拟合即模型的泛化能力差,在训练集上拟合性好,但是在验证集上拟合性不好。通俗地讲,就是模型对训练数据的学习太强了,模型能很好地识别训练集中的图像,非训练集的图像却识别不出。原因有二,一是训练集的数据太少,二是训练迭代次数太多。缓解过拟合的方法主要有四种,如下:
(1) early stopping。每次迭代(epoch)结束后,计算验证集的错误率(validation error),如果错误率不再下降,则终止训练。这是一种及时止损的方法,模型的泛化能力不再提高,继续训练也是浪费时间。但只依据一次迭代后的错误率是不科学的,因为本次迭代之后的错误率有可能上升,也有可能下降。因此,可以依据10次、20次等多次迭代后的验证集错误率来判断是否终止训练。
(2)数据集扩增。这是减轻过拟合最直接有效的方法。没有质量好、数量多的数据,就无法训练出好的模型。可以从两个方面进行数据集的扩增:从源头上增加数据,比如图像分类时,直接增加训练集的图像,但是此方法实行起来困难大,因为不知道增加多少数据;将原始数据做改动,从而获得更多的数据,比如将原始图片旋转、在原始数据中加噪声、截取原始数据的一部分等。
(3)正则化。正则化包括L0正则化、L1正则化和L2正则化,机器学习中常用的是L2正则化。L2正则项起到使参数 变小加剧的效果,更小的参数 意味着模型的复杂度更低,从而模型对训练数据的拟合刚刚好,以提高模型的泛化能力。
(4)drop out。dropout作为模型融合的一种,使神经元以一定的概率不工作,有效地降低了测试误差。给定一个输入,网络便采样出不同的结构,这些结构共享一套参数。由于一个神经元不依赖某些特定的神经元,dropout降低了神经元间复杂的共适性,增强了网络的鲁棒性。
模型在训练集上拟合性不好,在验证集上拟合性好,这是欠拟合。究其原因,欠拟合就是模型对训练数据的学习还不够,特征学习不充分,表征能力差。可以通过下面的方法缓解欠拟合:
(1)添加其他的特征项。特征项不够就会导致欠拟合。特征项不够导致的欠拟合就可以通过添加特征项很好地解决。增加特征项的手段有组合、泛化、相关性等,这些手段在很多场景都适用。
(2)添加多项式特征。比如在一个线性模型里添加二次项或者三次项,这样就增强了模型的泛化能力。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 12
12 1
1- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)