
Hadoop安装教程 Linux版
Hadoop安装教程 Linux版一、Linux虚拟机安装方法一:使用Windows下Linux子系统(大佬可选)方法二:使用VMware安装Linux虚拟机(小白可选)方法三:安装双系统(不怕麻烦的可以试试)Note:安装虚拟机时选定你想要安装的Linux系统映像文件,该教程采用Ubuntu20.04版本。a. 在VMware中新建虚拟机,选择程序光盘映像文件b. 输入你的Linux名称,用户名
Hadoop安装教程 Linux版
一、Linux虚拟机安装
方法一:使用Windows下Linux子系统(大佬可选)
方法二:使用VMware安装Linux虚拟机(小白可选)
方法三:安装双系统(不怕麻烦的可以试试)
Note:安装虚拟机时选定你想要安装的Linux系统映像文件,该教程采用Ubuntu20.04版本。
a. 在VMware中新建虚拟机,选择程序光盘映像文件
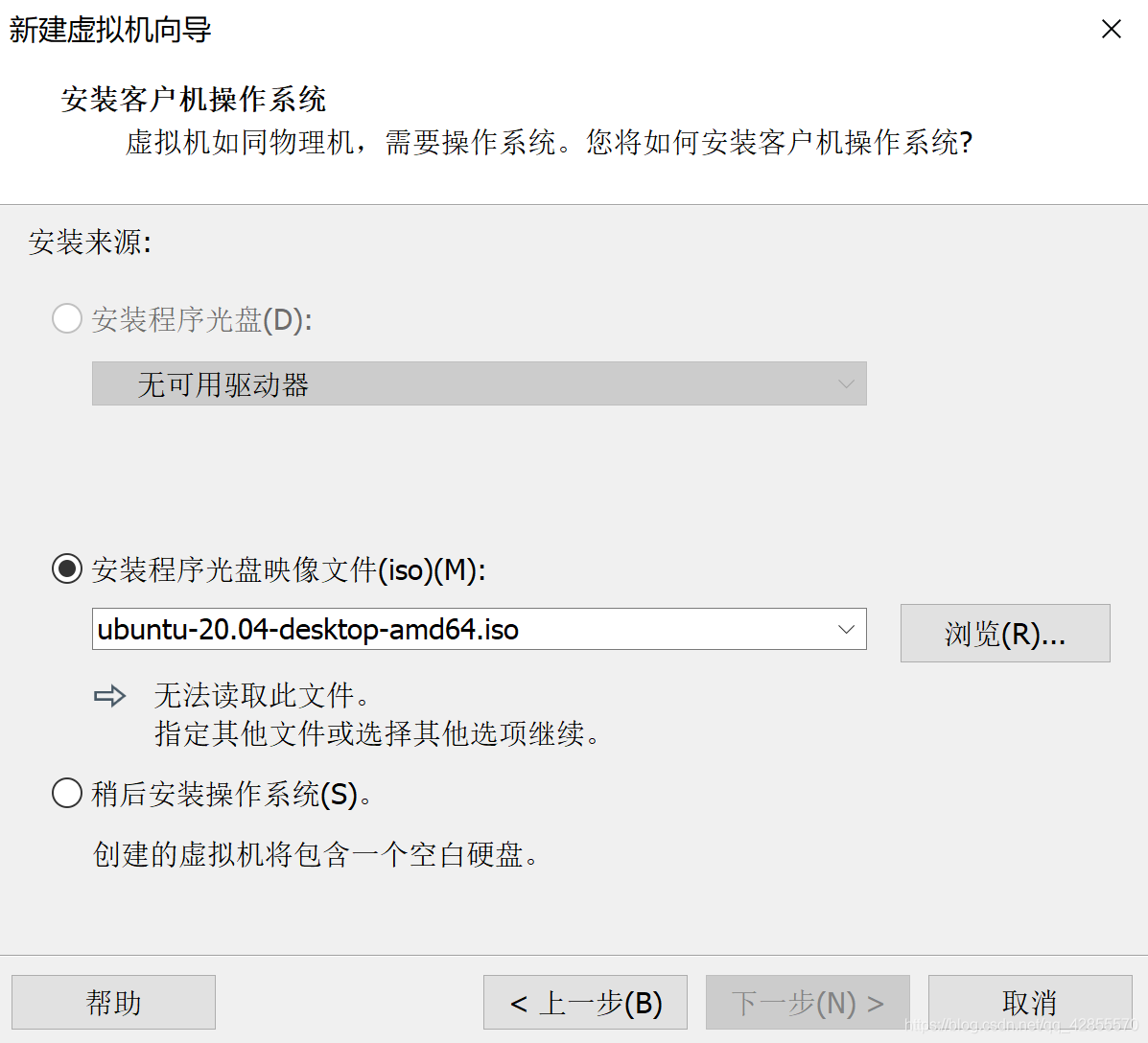
b. 输入你的Linux名称,用户名和密码
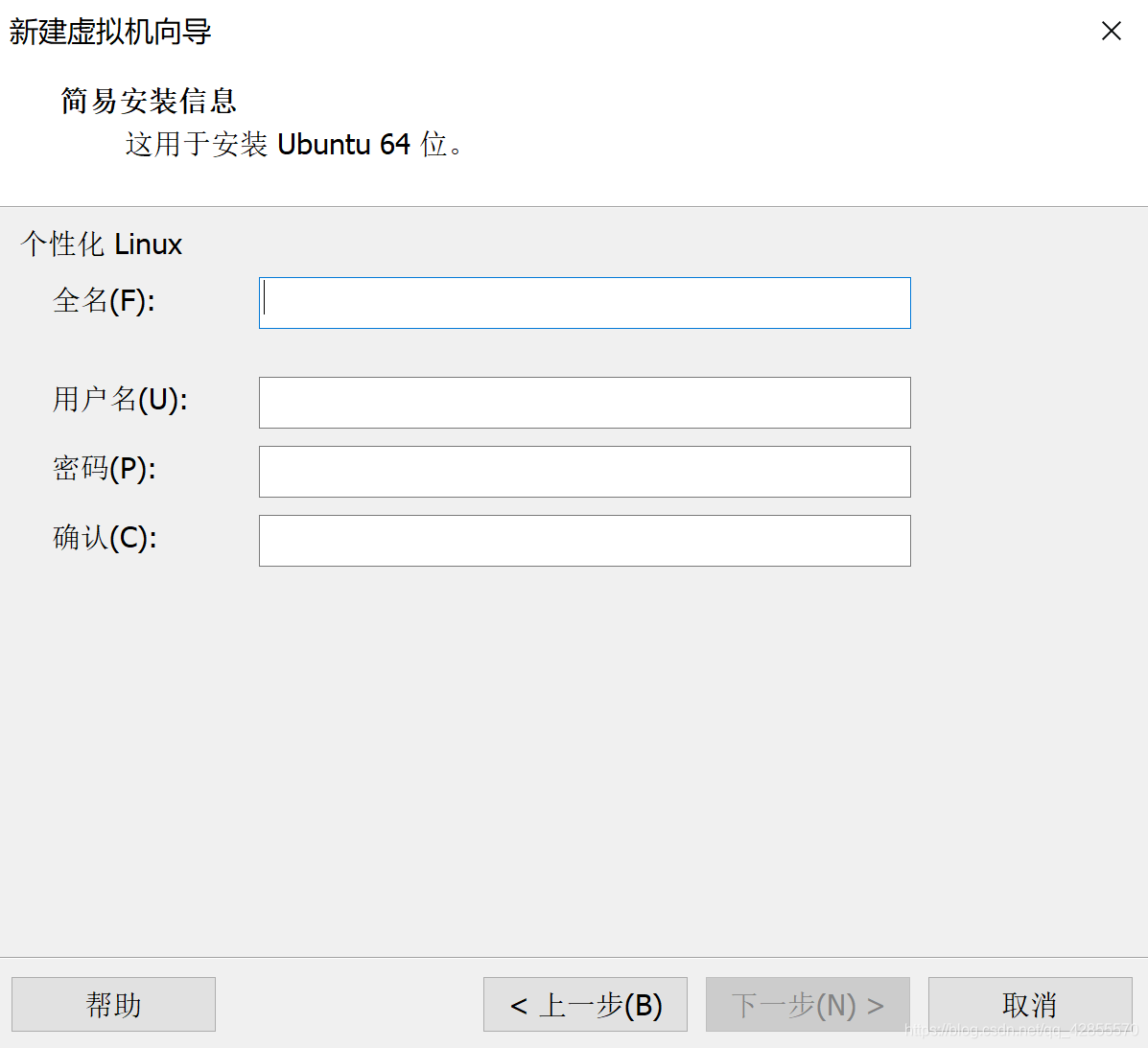
c. 根据向导提示完成安装
Note:安装时,虚拟机会自动下载文件,这一过程可以跳过以加速安装。
d. 启动虚拟机
二、JDK环境安装
1. 下载JDK1.8
方法一:apt-get install openjdk-8-jdk
方法二:Oracle官网下载JDK1.8版本
方法三:百度网盘下载(链接: https://pan.baidu.com/s/19JoUU_GTxBlqpEvaB51nyA 提取码: 74vc)
Note:将文件下载到桌面上,以便操作
2. 配置JDK环境变量
将JDK文件解压并移动到 /usr/local/java 文件夹下
cd ~/Desktop
tar -zxvf jdk-8u281-linux-x64.tar.gz
sudo mv jdk1.8.0_281/ /usr/local/java
在terminal中输入 sudo vi /etc/profile ,按 i 进入编辑模式:
JAVA_HOME=/usr/local/java
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
按 esc 退出编辑,输入 :wq 保存并退出。
在terminal中输入 source /etc/profile ,使配置的环境变量生效。
Linux下vi中使用方向键乱码解决办法
在Linux下,初始使用Vi的时候有两个典型的问题:
- 在编辑模式下使用方向键的时候,并不会使光标移动,而是在命令行中出现A、B、C、D四个字母;
- 当编辑出现错误,想要删除时,发现Backspace键不起作用,只能用Delete键来删除。
解决方法:
- 打开终端,输入命令 sudo gedit /etc/vim/vimrc.tiny ,进入vimrc.tiny文件的编辑状态
- 修改倒数第二行set compatible,将其改为set nocompatible;在set nocompatible下面添加一行:set backspace=2
- 保存,退出编辑。再使用vi时,已经可以正常使用方向键和Backspace。

二、Hadoop安装
1. 设置ssh免密码登录
因为Hadoop是分布式平台,需要多个机器之间协作,设置ssh免密码登录可以减少每次登陆主机输入密码的繁琐流程。
1) 安装SSH
Ubuntu 默认已安装了 SSH client,此外还需要安装 SSH server。
sudo apt-get install openssh-server
2) 设置免密登录
生成密钥对 ssh-keygen -t rsa ,回车到底
将公钥的内容写入到authorized_keys文件中 cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
3) 免密登录
ssh localhost
若能免密登录,即设置成功。
2. Hadoop下载与配置
1) 下载Hadoop
方法一:Hadoop官网下载
方法二:百度网盘下载(链接: https://pan.baidu.com/s/19JoUU_GTxBlqpEvaB51nyA 提取码: 74vc)
2) 配置Hadoop环境变量
将Hadoop文件解压并移动到 /usr/local/hadoop 文件夹下
cd ~/Desktop
tar -zxvf hadoop-3.2.2.tar.gz
sudo mv hadoop-3.2.2 /usr/local/hadoop
在terminal中输入 sudo vi /etc/profile ,按 i 进入编辑模式:
HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
按 esc 退出编辑,输入 :wq 保存并退出。
在terminal输入 source /etc/profile ,使配置的环境变量生效。
3) 修改Hadoop配置文件
打开 /usr/local/hadoop/etc/hadoop/ 文件夹:
o. 配置 hadoop-env.sh 文件
# 显式声明java路径
export JAVA_HOME=/usr/local/java
a. 配置 core-site.xml 文件
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储路径 -->
<property>
<name>hadoop.tmp.dir</name>
<!-- 配置到hadoop目录下temp文件夹 -->
<value>file:/usr/local/hadoop/tmp</value>
</property>
</configuration>
b. 配置 hdfs-site.xml 文件
<configuration>
<property>
<!--指定hdfs保存数据副本的数量,包括自己,默认为3-->
<!--伪分布式模式,此值必须为1-->
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<!-- name node 存放 name table 的目录 -->
<value>file:/usr/local/hadoop/tmp/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<!-- data node 存放数据 block 的目录 -->
<value>file:/usr/local/hadoop/tmp/hdfs/data</value>
</property>
</configuration>
c. 配置 mapred-site.xml 文件
<configuration>
<property>
<!--指定mapreduce运行在yarn上-->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
d. 配置 yarn-site.xml 文件
<configuration>
<property>
<!--NodeManager获取数据的方式-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
3. 启动Hadoop
1) 初始化
在terminal中输入 hdfs namenode -format
(只初次启动需要)
2) 启动Hadoop集群
在terminal中输入 start-all.sh (或者分别输入 start-dfs.sh 和 start-yarn.sh)
使用 jps (JavaVirtualMachineProcessStatus) 命令查看Hadoop是否已启动,运行的java进程中应包含以下几种:
4050 Jps
3956 NodeManager
3653 SecondaryNameNode
3414 NameNode
3852 ResourceManager
3518 DataNode
3) 查看NameNode和Yarn
访问 http://localhost:9870/dfshealth.html#tab-overview

访问 http://localhost:8088/cluster
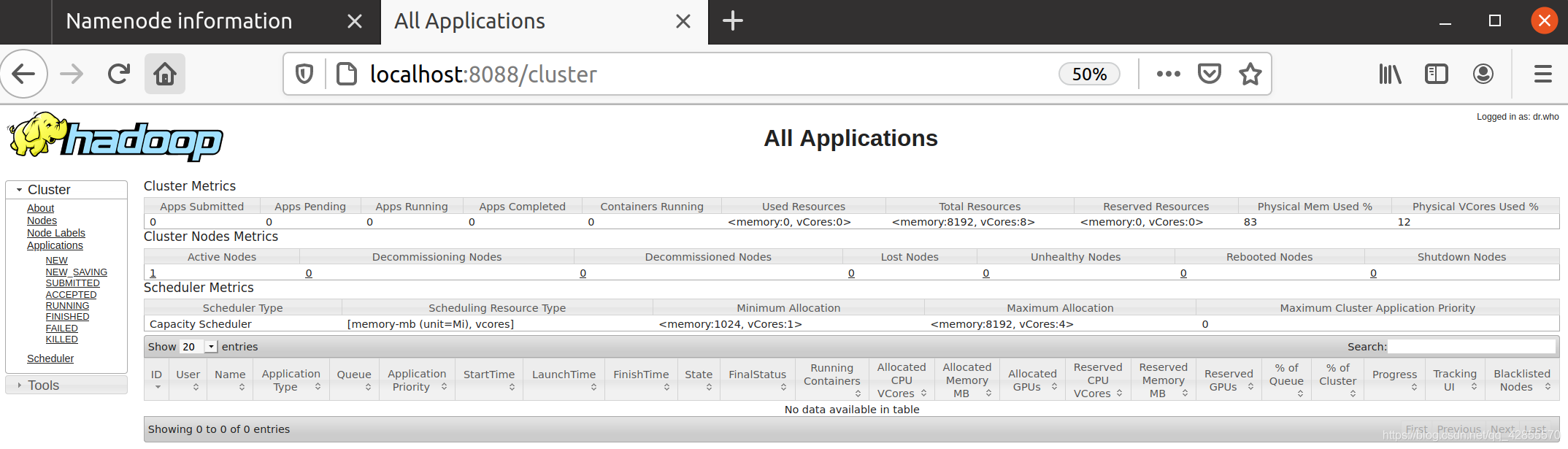
4) 运行Hadoop自带的wordcount程序
a. 新建一个 words.txt 文件并输入几个单词
b. 在hdfs文件系统上创建input文件夹 hdfs dfs -mkdir /input
c. 将word.txt放入input文件夹 hdfs dfs -put words.txt /input
d. 查看是否已放入文件 hdfs dfs -ls /input
e. 运行wordcount程序 hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar wordcount /input /output
(Note:输出目录必须是一个不存在的目录,输出结果无法存放在已有目录中)
f. 查看程序输出 hdfs dfs -ls /output
g. 打开输出文件 hdfs dfs -cat /output/part-r-00000
若报错 Error: Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster
则在terminal中输入 hadoop classpath ,查看输出结果:
(/usr/local/hadoop/etc/hadoop:/usr/local/hadoop/share/hadoop/common/lib/:/usr/local/hadoop/share/hadoop/common/:/usr/local/hadoop/share/hadoop/hdfs:/usr/local/hadoop/share/hadoop/hdfs/lib/:/usr/local/hadoop/share/hadoop/hdfs/:/usr/local/hadoop/share/hadoop/mapreduce/lib/:/usr/local/hadoop/share/hadoop/mapreduce/:/usr/local/hadoop/share/hadoop/yarn:/usr/local/hadoop/share/hadoop/yarn/lib/:/usr/local/hadoop/share/hadoop/yarn/)
将输出结果配置到 yarn-site.xml 文件
<property>
<name>yarn.application.classpath</name>
<value>/usr/local/hadoop/etc/hadoop:/usr/local/hadoop/share/hadoop/common/lib/*:/usr/local/hadoop/share/hadoop/common/*:/usr/local/hadoop/share/hadoop/hdfs:/usr/local/hadoop/share/hadoop/hdfs/lib/*:/usr/local/hadoop/share/hadoop/hdfs/*:/usr/local/hadoop/share/hadoop/mapreduce/lib/*:/usr/local/hadoop/share/hadoop/mapreduce/*:/usr/local/hadoop/share/hadoop/yarn:/usr/local/hadoop/share/hadoop/yarn/lib/*:/usr/local/hadoop/share/hadoop/yarn/*</value>
</property>
5) 关闭Hadoop集群
在terminal中输入 stop-all.sh (或 stop-yarn.sh + stop-dfs.sh)
三、Spark安装
1. 安装Scala
1) 下载Scala
方法一:apt-get install scala
方法一:Scala官网下载
方法二:百度网盘下载(链接: https://pan.baidu.com/s/19JoUU_GTxBlqpEvaB51nyA 提取码: 74vc)
2) 配置Scala环境变量
将Scala文件解压,并移动到 /usr/local/scala 文件夹下
cd ~/Downloads/
tar -zxvf scala-2.12.13.tgz
sudo mv scala-2.12.13 /usr/local/scala
在terminal中输入 sudo vi /etc/profile ,按 i 进入编辑模式:
SCALA_HOME=/usr/local/scala
export PATH=$PATH:$SCALA_HOME/bin
按 esc 退出编辑,输入 :wq 保存并退出。
在terminal中输入 source /etc/profile ,使配置的环境变量生效。
2. Spark下载与配置
1) 下载Spark
方法一:Spark官网下载
方法二:百度网盘下载(链接: https://pan.baidu.com/s/19JoUU_GTxBlqpEvaB51nyA 提取码: 74vc)
2) 配置Spark环境变量
将Spark文件解压,并移动到 /usr/local/spark 文件夹下
cd ~/Downloads/
tar -zxvf spark-3.1.1-bin-hadoop3.2.tgz
sudo mv spark-3.1.1-bin-hadoop3.2 /usr/local/spark
在terminal中输入 sudo vi /etc/profile ,按 i 进入编辑模式:
SPARK_HOME=/usr/local/spark
export PATH=$PATH:$SPARK_HOME/bin
按 esc 退出编辑,输入 :wq 保存并退出。
在terminal中输入 source /etc/profile ,使配置的环境变量生效。
3) 修改Spark配置文件
打开 /usr/local/spark/sbin/ 文件夹:
o. 配置 spark-config.sh 文件
# 显式声明java路径
export JAVA_HOME=/usr/local/java
3. 启动Spark
首先启动Hadoop集群 start-all.sh
1) 启动master
在terminal输入 cd $SPARK_HOME 进入Spark文件夹
./sbin/start-master.sh
访问 http://localhost:8080 ,获取master的URL信息。

2) 启动slave
复制上图红线标出的URL,替换下面命令的URL部分(spark://—)
./sbin/start-worker.sh spark://—
3) 同时启动master和slave
使用以下命令可以同时启动master和slave
./sbin/start-all.sh
(替代 ./sbin/start-master.sh + ./sbin/start-worker.sh)
使用 jps 命令查看Spark是否已启动,运行的java进程中应包含以下几种:
7968 SecondaryNameNode
8177 ResourceManager
8313 NodeManager
7641 NameNode
7770 DataNode
93021 Jps
92911 Worker
92398 Master
4) 关闭Spark
在terminal中输入 ./sbin/stop-all.sh (或者分别输入 ./sbin/stop-worker 和 ./sbin/stop-master)
三、Flink安装
1. Flink下载与配置
1) 下载Flink
方法一:Flink官网下载
方法二:百度网盘下载(链接: https://pan.baidu.com/s/19JoUU_GTxBlqpEvaB51nyA 提取码: 74vc)
2) 配置Flink环境变量
将Flink文件解压,并移动到 /usr/local/flink 文件夹下
cd ~/Downloads/
tar -zxvf flink-1.12.2-bin-scala_2.12.tgz
sudo mv flink-1.12.2 /usr/local/flink
在terminal中输入 sudo vi /etc/profile ,按 i 进入编辑模式:
FLINK_HOME=/usr/local/flink
export PATH=$PATH:$FLINK_HOME/bin
按 esc 退出编辑,输入 :wq 保存并退出。
在terminal中输入 source /etc/profile ,使配置的环境变量生效。
2. 启动Flink
1) 启动Flink
在terminal中输入 start-cluster.sh
使用 jps 命令查看Flink是否已启动,运行的java进程中应包含以下几种:
100580 StandaloneSessionClusterEntrypoint
100838 TaskManagerRunner
100888 Jps
访问 http://localhost:8081,查看管理界面
2) 关闭Flink
在terminal中输入 stop-cluster.sh

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 28
28 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)