

数据结构--哈希(Hash)和代码实现(详解)
哈希一.哈希的概念二.哈希函数三.哈希冲突四.哈希的代码实现(1)哈希的创建(2)哈希的初始化(3)哈希函数(4)哈希的元素添加(5)哈希的显示(6)哈希的查找(7)哈希的删除五.总代码一.哈希的概念线性表、树结构的查找方式都是以关键字的比较为基础,查找效率比较低。如果能在元素的存储位置和其关键字之间建立某种联系,那么在进行查找时,可以通过很少的比较找到该元素,这个就是哈希的思想二.哈希函数哈希函
哈希
前言😀😀
大家好呀,😀😀😀,之前在算法课听过哈希这个词,知道它的查找效率非常高,今天学了哈希,也对哈希有了一些认识,就赶快记录下🙈🙈🙈,今天写的博客相对之前,有一点点真正博客的样子勒(添加了目录和Emoji)。好啦,一起来学习哈希咯😉😉
一.🔥🔥哈希的概念
线性表、树结构的查找方式都是以关键字的比较为基础,
查找效率比较低。如果能在元素的存储位置和其关键字之间建立某种联系,那么在进行查找时,可以通过很少的比较找到该元素,这个就是哈希的思想
二.🔥🔥哈希函数
哈希函数可以将一个元素的访问过程更加迅速更加有效,通过哈希函数,数据元素可以很快被定位。这篇文章将采用除留余数法建立哈希函数。
除留余数法是拿需要存储的元素摸(%)上一个数P得到新的值。
一般P取一个素数,是离元素个数最近的素数且大于P;
例如一组关键数是{19,14,23,01,68,20,84,27,55,11,10,79},可以知道该元素个数为12,那么P就可以取13。
三.🔥🔥哈希冲突
哈希冲突是指几个元素通过哈希函数得到新的值都存储在一个地址,比如1%13=1,14%13=1,1和14的得到新值都为1,那么地址为1的位置存储是存1还是14呢,这样就起冲突了。那么如何才能解决这种冲突勒,我们可以采用链地址法----元素类型用链表的形式。
四.🔥🔥哈希的代码实现
(1)❤️哈希的创建
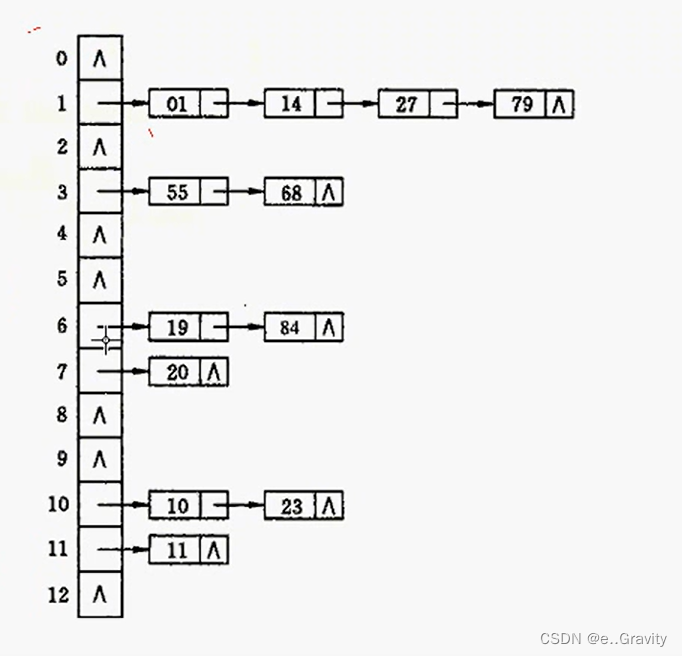
以上面的一组关键数为例:{19,14,23,01,68,20,84,27,55,11,10,79}
我们可以把这些关键数存储在一个数组中,将每个关键数通过哈希函数得到的新值存储在和数组下标相等的位置。比如关键字55%13=3,就将该关键字存储在数组下标为3的位置。如果有冲突,就用链表的方式指向有冲突的关键字。我们想要的结果也就是下图的样子。
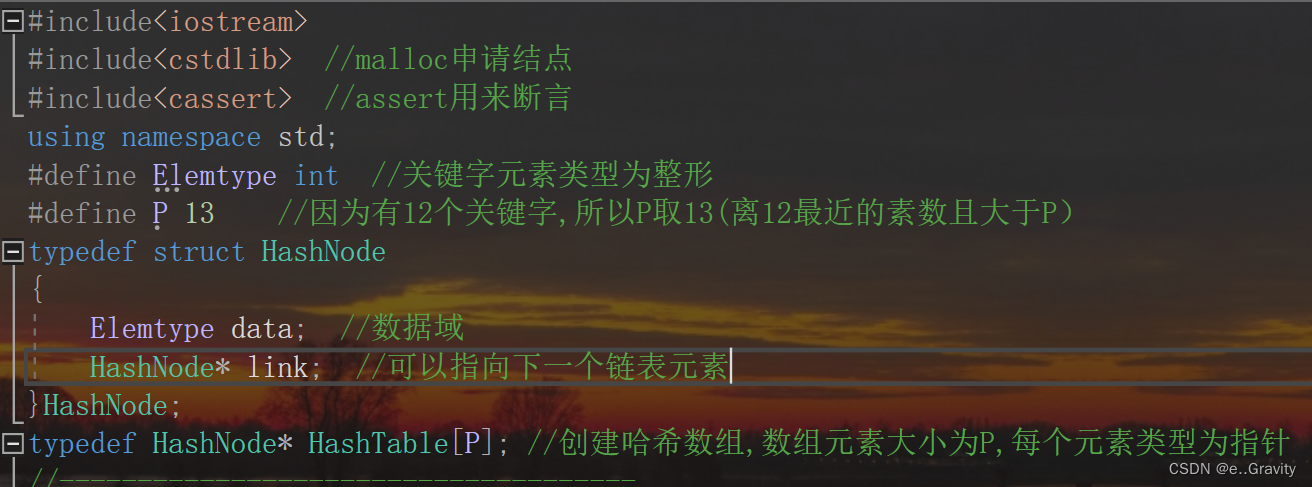
#include<iostream>
#include<cstdlib> //malloc申请结点
#include<cassert> //assert用来断言
using namespace std;
#define Elemtype int //关键字元素类型为整形
#define P 13 //因为有12个关键字,所以P取13(离12最近的素数且大于P)
typedef struct HashNode
{
Elemtype data; //数据域
HashNode* link; //可以指向下一个链表元素
}HashNode;
typedef HashNode* HashTable[P]; //创建哈希数组,数组元素大小为P,每个元素类型为指针
然后在main函数中创建哈希数组ht

(2)❤️哈希的初始化
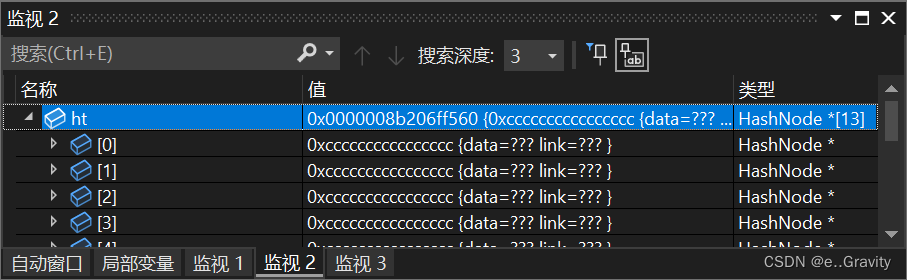
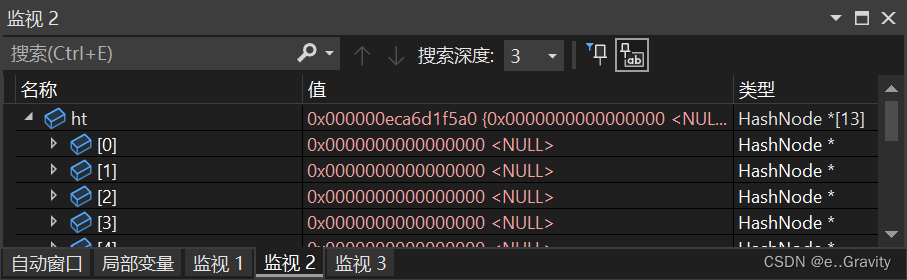
创建好哈希数组后,通过监视我们可以看到每个数组元素还是未知数。
所以我们需要初始化数组。
初始化函数(将数组元素类型赋空):
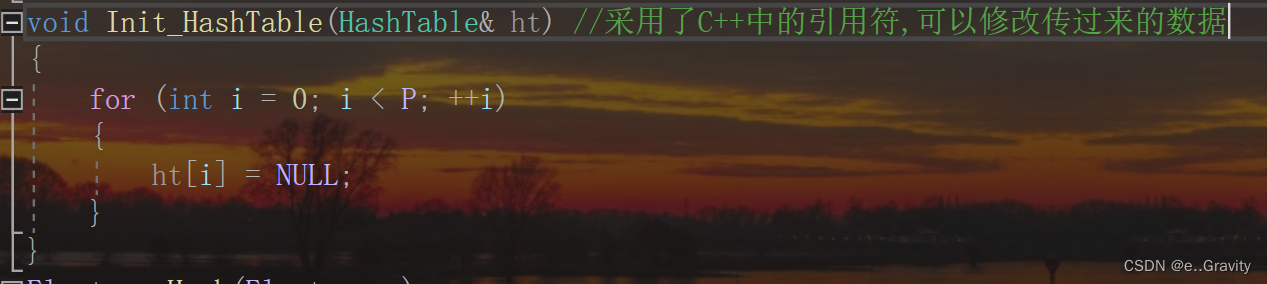
void Init_HashTable(HashTable& ht) //采用了C++中的引用符,可以修改传过来的数据
{
for (int i = 0; i < P; ++i)
{
ht[i] = NULL;
}
}
初始化后:
(3)❤️哈希函数
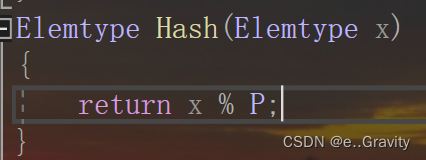
Elemtype Hash(Elemtype x)
{
return x % P;
}
(4)❤️哈希的元素增加
增加结点采用头插法
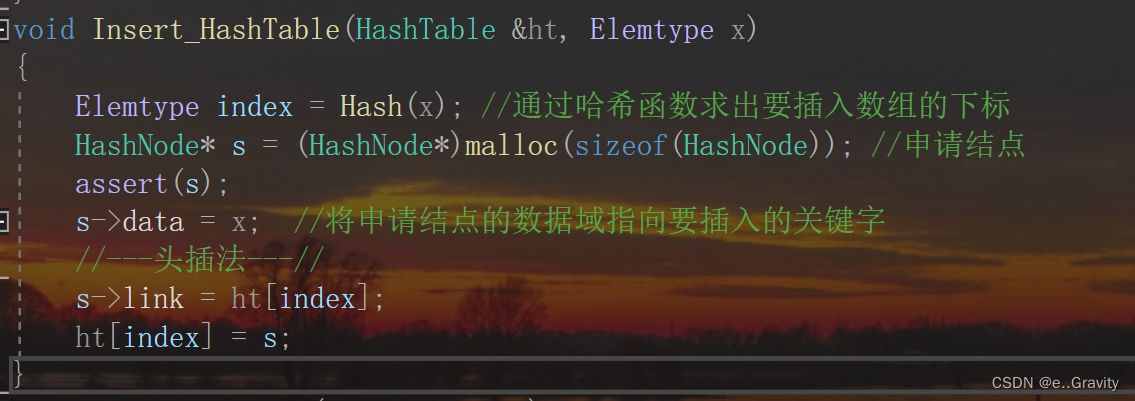
void Insert_HashTable(HashTable &ht, Elemtype x)
{
Elemtype index = Hash(x); //通过哈希函数求出要插入数组的下标
HashNode* s = (HashNode*)malloc(sizeof(HashNode)); //申请结点
assert(s);
s->data = x; //将申请结点的数据域指向要插入的关键字
//---头插法---//
s->link = ht[index];
ht[index] = s;
}
(5)❤️哈希的显示
每个关键字插入成功后,我们可以来显示一下
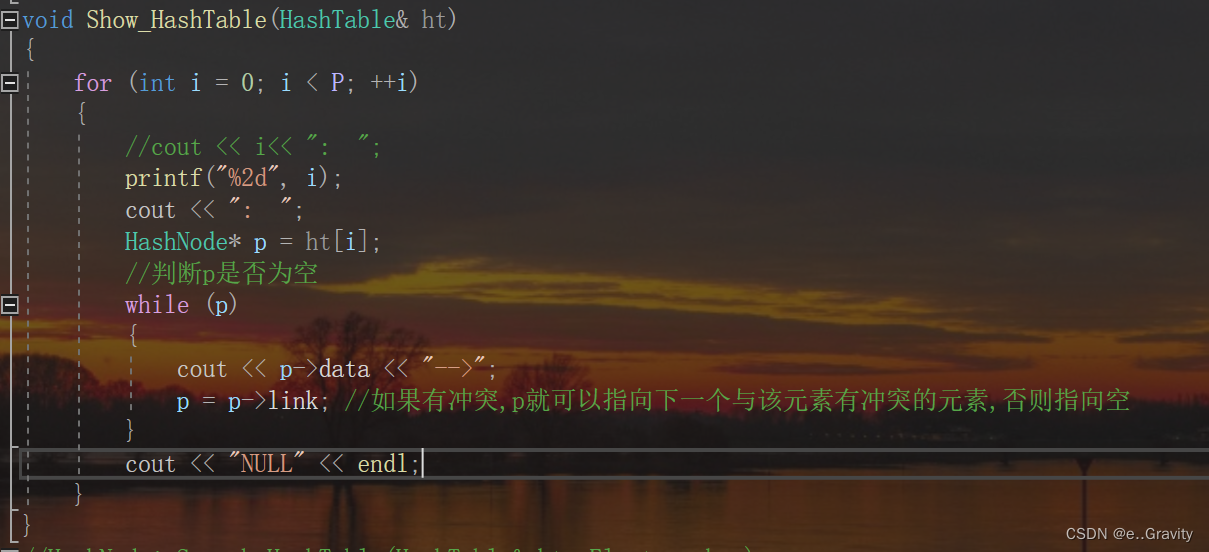
void Show_HashTable(HashTable& ht)
{
for (int i = 0; i < P; ++i)
{
//cout << i<< ": ";
printf("%2d", i);
cout << ": ";
HashNode* p = ht[i];
//判断p是否为空
while (p)
{
cout << p->data << "-->";
p = p->link; //如果有冲突,p就可以指向下一个与该元素有冲突的元素,否则指向空
}
cout << "NULL" << endl;
}
}
显示:

这样就得到了我们想要的哈希表😉😉,如果想要对哈希表进行查找和删除操作,请往下看哈~
(6)❤️哈希的查找
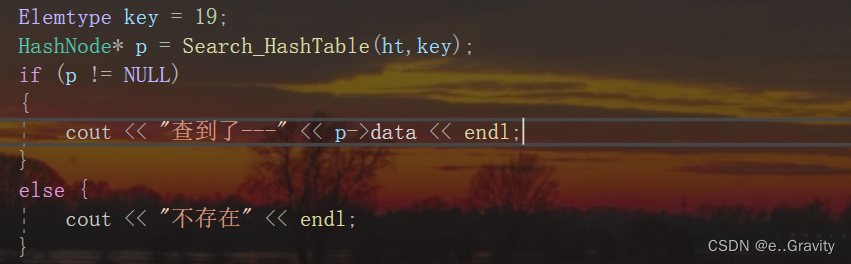
我们假如要查找19这个关键字,将哈希表和关键字19传入查找函数,并返回该关键字的结点地址
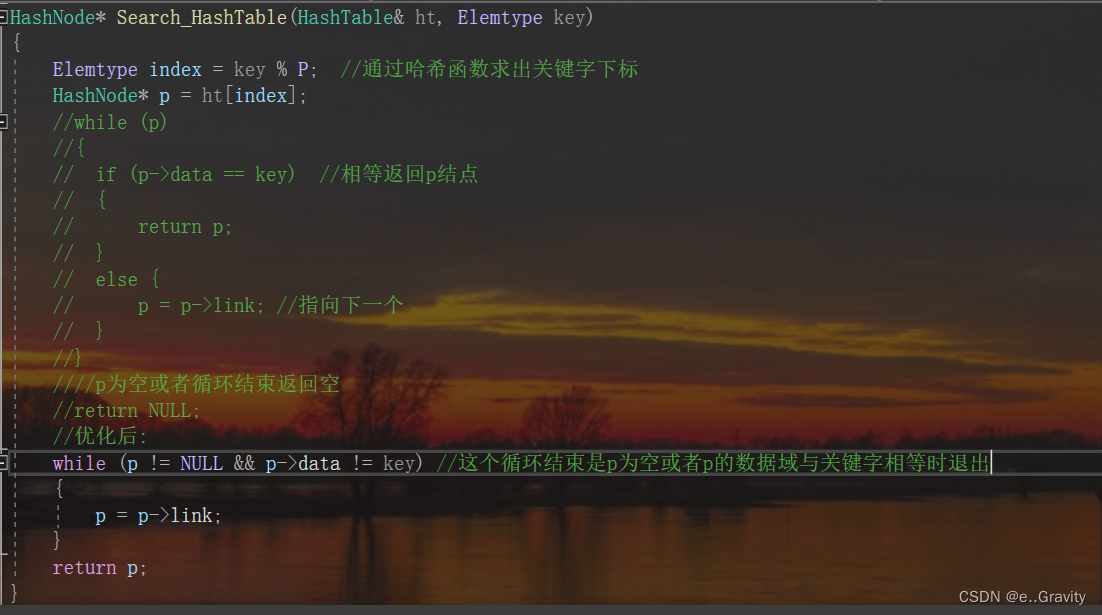
这里其实可以优化,循环条件可以是p为空或者p的数据域与关键字相等时退出,这样直接可以返回p
(7)❤️哈希的删除
在删除之前我们先查找要删除的元素,如果没找到,直接返回false,否则进入下一步,这里要判断该位置有冲突和没有冲突俩种情况讨论。如果没有冲突,将p删除即可。如果有冲突,处理办法就是链表的删除了(这里应该难不到大家吧):假设要删除p结点,可以先找到p的前驱结点q,然后用q的指针域指向p的指针域,再free掉p结点。
bool Remove_HashTable(HashTable &ht, Elemtype key1)
{
HashNode* p = Search_HashTable(ht, key1);
if (!p)
{
return false;
}
HashNode* q;//要删除的前驱结点
Elemtype index = Hash(key1);
q = ht[index];
if (q == p)
{
ht[index] = q->link;
free(q);
return true;
}
while (p != NULL && p -> data != key1)
{
p = p->link;
}
q->link = p->link;
free(p);
return true;
}
五.🔥🔥总代码
#include<iostream>
#include<cstdlib> //malloc申请结点
#include<cassert> //assert用来断言
using namespace std;
#define Elemtype int //关键字元素类型为整形
#define P 13 //因为有12个关键字,所以P取13(离12最近的素数且大于P)
typedef struct HashNode
{
Elemtype data; //数据域
HashNode* link; //可以指向下一个链表元素
}HashNode;
typedef HashNode* HashTable[P]; //创建哈希数组,数组元素大小为P,每个元素类型为指针
//-------------------------------------
//-------------------------------------
//-------------------------------------
void Init_HashTable(HashTable& ht) //采用了C++中的引用符,可以修改传过来的数据
{
for (int i = 0; i < P; ++i)
{
ht[i] = NULL;
}
}
Elemtype Hash(Elemtype x)
{
return x % P;
}
void Insert_HashTable(HashTable &ht, Elemtype x)
{
Elemtype index = Hash(x); //通过哈希函数求出要插入数组的下标
HashNode* s = (HashNode*)malloc(sizeof(HashNode)); //申请结点
assert(s);
s->data = x; //将申请结点的数据域指向要插入的关键字
//---头插法---//
s->link = ht[index];
ht[index] = s;
}
void Show_HashTable(HashTable& ht)
{
for (int i = 0; i < P; ++i)
{
//cout << i<< ": ";
printf("%2d", i);
cout << ": ";
HashNode* p = ht[i];
//判断p是否为空
while (p)
{
cout << p->data << "-->";
p = p->link; //如果有冲突,p就可以指向下一个与该元素有冲突的元素,否则指向空
}
cout << "NULL" << endl;
}
}
//HashNode* Search_HashTable(HashTable& ht, Elemtype key)
//{
// for (int i = 0; i < P; ++i)
// {
// HashNode* p = ht[i];
// while (p)
// {
// if (p->data == key)
// {
// return p;
// }
// else {
// p = p->link;
// }
// }
// }
// return NULL;
//}
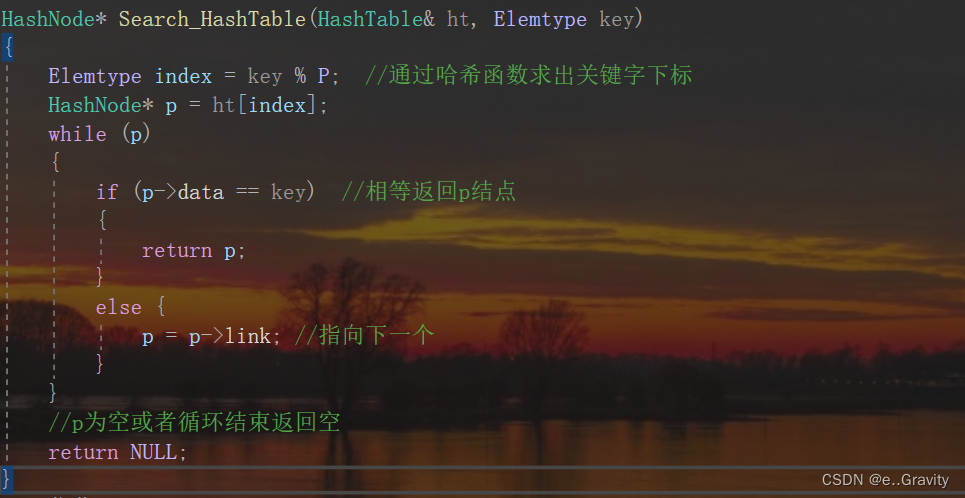
HashNode* Search_HashTable(HashTable& ht, Elemtype key)
{
Elemtype index = key % P; //通过哈希函数求出关键字下标
HashNode* p = ht[index];
//while (p)
//{
// if (p->data == key) //相等返回p结点
// {
// return p;
// }
// else {
// p = p->link; //指向下一个
// }
//}
p为空或者循环结束返回空
//return NULL;
//优化后:
while (p != NULL && p->data != key) //这个循环结束是p为空或者p的数据域与关键字相等时退出
{
p = p->link;
}
return p;
}
bool Remove_HashTable(HashTable &ht, Elemtype key1)
{
HashNode* p = Search_HashTable(ht, key1);
if (!p)
{
return false;
}
HashNode* q;//要删除的前驱结点
Elemtype index = Hash(key1);
q = ht[index];
if (q == p)
{
ht[index] = q->link;
free(q);
return true;
}
while (p != NULL && p -> data != key1)
{
p = p->link;
}
q->link = p->link;
free(p);
return true;
}
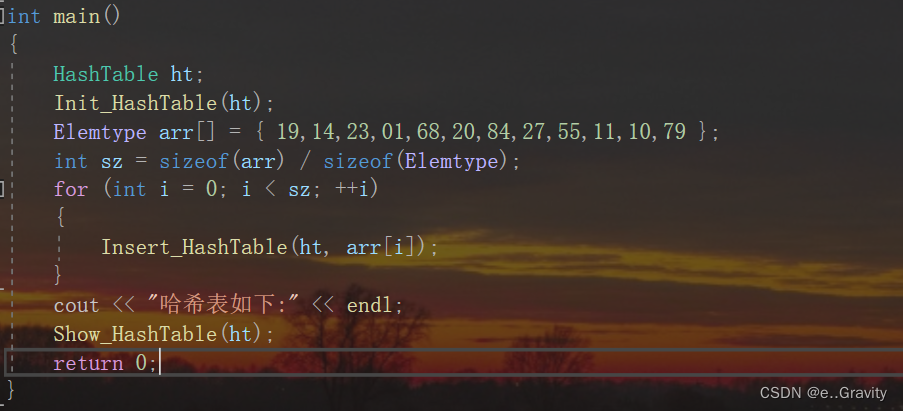
int main()
{
HashTable ht;
Init_HashTable(ht);
Elemtype arr[] = { 19,14,23,01,68,20,84,27,55,11,10,79 };
int sz = sizeof(arr) / sizeof(Elemtype);
for (int i = 0; i < sz; ++i)
{
Insert_HashTable(ht, arr[i]);
}
cout << "哈希表如下:" << endl;
Show_HashTable(ht);
Elemtype key = 19;
HashNode* p = Search_HashTable(ht,key);
if (p != NULL)
{
cout << "查到了---" << p->data << endl;
}
else {
cout << "不存在" << endl;
}
//删除结点
Elemtype key1 = 27;
if (Remove_HashTable(ht, key1))
{
cout << "删除成功" << endl;
}
else {
cout << "删除失败" << endl;
}
Show_HashTable(ht);
return 0;
}
六.最后想说的话
这篇博客到此就要结束啦,从上晚自习开始写,现在马上下课了。
我很享受现在这个过程😃😃😃,身旁的同学们都在认真学习and写博客期间的心静、思考、学习新知识的愉悦。感觉very very nice 😍😍
我们一起加油!!
”长风破浪会有时,直挂云帆济沧海"

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 37
37 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)