
【Simulink】粒子群算法(PSO)整定PID参数(附代码和讲解)
目录
阅读前必看:
- 本代码基于MATLAB2017a版本,如果版本不同可能会报错
- 请从set_para.m文件开始运行,其他M文件(+下载的资源包里面的slx文件)放在一个文件夹
- 每次迭代都会打印出来,如果运行时间过长怀疑程序死机可以观察迭代次数是否有变化
- 最后会输出3幅图(figure)
- slx文件下载链接:https://download.csdn.net/download/weixin_44044411/11609837
混合粒子群算法链接:https://blog.csdn.net/weixin_44044411/article/details/103638611?spm=1001.2014.3001.5502
MATALB的自带的粒子群优化器来了:particleswarm
0.背景
\qquad
调整PID参数时,我们常常需要按照各种方法查各种表,还要根据建立的数学模型和之前的结果做人工调整。这个过程常常是漫长的,而且最终得到的很可能也不是最优的参数。若系统的参数有改动,又要人工再调一次。而3个参数6个方向的调整,如果输入的变量很多,那么调节的可能性组合就更多了,这个工作常常不是非专业人士所能胜任的。
\qquad
现在我给大家介绍一种不需要知道内部原理也可以调整PID参数的方法,而且调整的思路是所需即所得——你需要的参数是什么样子的,这个算法就会往这个方向调整PID参数。如果这个系统是多输入多输出的,我需要让A输出的超调小一些,而B输出的调节时间可以尽量大一些,只需要调整我们的评价函数就可以让算法自动调参以满足客户需求了。那这样的算法使用起来是不是很容易呢?
1.粒子群算法
##1.1.算法简介
\qquad
粒子群算法(PSO)于1995年提出,和遗传算法一样,也是一种群体迭代算法,不同的是,粒子群算法需要整定的参数更少,不存在交叉和变异过程,所以收敛速度更快。
\qquad
由于是群体迭代算法,因此该算法一般做成并行的。如果做成串行的,也是可以运行的,就是会随着种群规模的增大越来越慢。对于Python运用熟练的朋友可以利用Python做成并行的,对于不熟悉并行算法的朋友,直接使用MATLAB就好了,因为MATLAB的矩阵运算已经集成了并行算法。
\qquad
为了让大家理解,我们做一个很形象的比喻。将我们的粒子群比作一群可以互相通讯的鸟,每只鸟不知道食物的具体位置,但是可以根据嗅觉知道离食物的距离和自己在地图中的位置。种群中的任意2只鸟均可以知道对方离食物的距离和对方的具体位置。假设每只鸟的飞行都是有惯性的,而每只鸟都会根据自己距离食物的距离和位置及其他鸟距离食物的距离和位置选择下一次的飞行方向。最终,所有鸟都会在信息交换的基础上,汇聚在食物地点。
\qquad
这只是对粒子群算法的一个形象的比喻,不必过多计较该模型的现实性,闲言少叙,让我们进入
算法步骤
\color{red}算法步骤
算法步骤。
1.2.算法步骤
【step1】确定参数维度
N
\color{blue}{N}
N、参数范围(即每只鸟的初始位置),确定惯性系数
c
1
,
c
2
,
w
c_1,c_2,w
c1,c2,w,确定种群规模m,迭代次数n。
每个粒子的初始位置是随机的,设输入向量
x
=
(
x
1
,
x
2
,
.
.
.
,
x
N
)
T
x=(x_1,x_2,...,x_N)^T
x=(x1,x2,...,xN)T必须满足参数范围限制为:
{
x
m
i
n
(
1
)
<
x
1
<
x
m
a
x
(
1
)
x
m
i
n
(
2
)
<
x
2
<
x
m
a
x
(
2
)
.
.
.
x
m
i
n
(
N
)
<
x
1
<
x
m
a
x
(
N
)
\begin{cases}x_{min}^{(1)}<x_1<x_{max}^{(1)} \\x_{min}^{(2)}<x_2<x_{max}^{(2)} \\... \\x_{min}^{(N)}<x_1<x_{max}^{(N)} \end{cases}
⎩
⎨
⎧xmin(1)<x1<xmax(1)xmin(2)<x2<xmax(2)...xmin(N)<x1<xmax(N)
记
X
m
i
n
=
(
x
m
i
n
(
1
)
,
x
m
i
n
(
2
)
,
.
.
.
x
m
i
n
(
N
)
)
,
X
m
a
x
=
(
x
m
a
x
(
1
)
,
x
m
a
x
(
2
)
,
.
.
.
x
m
a
x
(
N
)
)
\color{blue}X_{min}=(x_{min}^{(1)},x_{min}^{(2)},...x_{min}^{(N)}),X_{max}=(x_{max}^{(1)},x_{max}^{(2)},...x_{max}^{(N)})
Xmin=(xmin(1),xmin(2),...xmin(N)),Xmax=(xmax(1),xmax(2),...xmax(N))
则输入向量
x
x
x应满足
X
m
i
n
<
x
<
X
m
a
x
X_{min}<x<X_{max}
Xmin<x<Xmax
每个粒子的初速度定为0,即
v
0
=
0
v_0=0
v0=0,第
j
j
j个粒子(
1
≤
j
≤
m
1≤j≤m
1≤j≤m)的下一次迭代的速度
v
(
j
)
v^{(j)}
v(j)由三部分组成:
v
(
j
)
=
w
⋅
v
0
+
c
1
⋅
r
a
n
d
⋅
(
P
(
j
)
−
X
(
j
)
)
+
c
2
⋅
r
a
n
d
⋅
(
P
G
−
X
(
j
)
)
v^{(j)}=w\cdot v_0+c_1\cdot rand\cdot (P^{(j)}-X^{(j)})+c_2\cdot rand\cdot(P_G-X^{(j)})
v(j)=w⋅v0+c1⋅rand⋅(P(j)−X(j))+c2⋅rand⋅(PG−X(j))
注:rand是(0,1)的随机数,
v
0
v_0
v0代表上一次粒子的速度。
第一部分为自身惯性因子,因为下一次的迭代次数保留了上一次的速度信息;
第二个部分为自身最优因子,
P
(
j
)
\color{blue}{P^{(j)}}
P(j)为第
j
j
j个因子在之前所有迭代次数中自适应度最高的位置,可以理解为历史上自身离食物最近的位置。
第三部分为社会因子,
P
G
\color{blue}{P_G}
PG为种群在之前所有迭代次数中自适应度最高的位置,可以理解为历史上所有粒子离食物最近的位置中的最近的一个。
一般情况下,取
w
=
1
,
c
1
=
c
2
=
2
w=1,c_1=c_2=2
w=1,c1=c2=2,当种群规模较大时,可以让
w
w
w的值随迭代次数减小以增加收敛速度。
【step2】按照step1的速度公式计算下一次的速度,并计算下一次的粒子位置。对于第
j
j
j个粒子,第
k
+
1
k+1
k+1次迭代(第
k
+
1
k+1
k+1代)的位置
X
k
+
1
(
j
)
\color{blue}{X_{k+1}^{(j)}}
Xk+1(j)与第
k
k
k次迭代的位置
X
K
(
j
)
\color{blue}{X_K^{(j)}}
XK(j)与速度
v
k
(
k
+
1
)
\color{blue}{v_k^{(k+1)}}
vk(k+1)关系为:
X
k
+
1
(
j
)
=
X
k
(
j
)
+
v
k
(
j
+
1
)
⋅
d
t
X^{(j)}_{k+1}=X^{(j)}_{k}+v_k^{(j+1)}\cdot dt
Xk+1(j)=Xk(j)+vk(j+1)⋅dt
其中
d
t
\color{blue}{dt}
dt是仿真间隔,一般情况下可以取1,如果希望仿真得慢一点,搜索平滑一点,可以适当减小
d
t
\color{blue}{dt}
dt。
【step3】计算每个粒子的自适应度
F
k
+
1
(
j
)
\color{blue}{F^{(j)}_{k+1}}
Fk+1(j),为了计算出step1公式中的
P
(
j
)
和
P
G
\color{blue}{P^{(j)}和P_G}
P(j)和PG。为了方便起见,我们记前k次计算得到了的
P
G
P_G
PG为
P
G
(
k
)
P_G^{(k)}
PG(k),则第k+1次迭代中我们将适应度最高的粒子位置记为
P
G
(
k
+
1
)
P_G^{(k+1)}
PG(k+1),则最终的
P
G
P_G
PG为:
P
G
=
{
P
G
(
k
)
,
F
(
P
G
(
k
)
)
>
F
(
P
G
(
k
+
1
)
)
P
G
(
k
+
1
)
,
F
(
P
G
(
k
)
)
<
F
(
P
G
(
k
+
1
)
)
P_G=\begin{cases}P_G^{(k)},\qquad F(P_G^{(k)})>F(P_G^{(k+1)}) \\[2ex]P_G^{(k+1)},\quad F(P_G^{(k)})<F(P_G^{(k+1)}) \end{cases}
PG=⎩
⎨
⎧PG(k),F(PG(k))>F(PG(k+1))PG(k+1),F(PG(k))<F(PG(k+1))
同样,我们记前k次计算得到的第
j
j
j个粒子的位置为
P
k
(
j
)
P^{(j)}_{k}
Pk(j),第k+1次计算得到的第
j
j
j个粒子的位置为
P
k
+
1
(
j
)
P^{(j)}_{k+1}
Pk+1(j),则最终的第
j
j
j个粒子的历史最优解
P
(
j
)
P^{(j)}
P(j)为:
P
(
j
)
=
{
P
k
(
j
)
,
F
(
P
k
(
j
)
)
>
F
(
P
k
+
1
(
j
)
)
P
k
+
1
(
j
)
,
F
(
P
k
(
j
)
)
<
F
(
P
k
+
1
(
j
)
)
P^{(j)}=\begin{cases}P_{k}^{(j)},\quad F(P_{k}^{(j)})>F(P_{k+1}^{(j)}) \\[2ex]P_{k+1}^{(j)},\quad F(P_{k}^{(j)})<F(P_{k+1}^{(j)}) \end{cases}
P(j)=⎩
⎨
⎧Pk(j),F(Pk(j))>F(Pk+1(j))Pk+1(j),F(Pk(j))<F(Pk+1(j))
【step4】更新每个粒子的信息。
由于我们在step2的位置迭代中已经更新过粒子的位置信息,在step1中的速度迭代中已经更新过粒子的速度信息,而在step3中又更新了每个粒子的历史最优位置
P
(
j
)
P^{(j)}
P(j)及种群最优位置
P
G
P_G
PG,因此实际上如果仅需要知道最优解的情况下我们不需要做这一步。
但如果需要作出参数随迭代次数的改变的图的话,每次迭代产生最优解
P
G
(
k
)
P_G^{(k)}
PG(k)及最优适应度
F
(
P
G
(
k
)
)
F(P_G^{(k)})
F(PG(k))需要用数组保存下来。
1.3.算法举例
\qquad 根据以上的算法步骤,本人编写了一段粒子群算法的MATLAB代码,这个代码很简单,是无约束问题下的全局粒子群算法。全局粒子群算法收敛速度快,占用内存小,但是容易陷入局部最优解,每次迭代的最优解可能存在细微差异,当然如果这个无约束问题本身是单解的话,这个差异会随着种群规模的扩大和迭代次数增加而逐渐消除。
function [Pg,fmin]=PSO(f,dimension,n,m,xmax,xmin,vmax,vmin)
%全局粒子群算法,f为目标函数,dimension为维度,n为代数,m为种群规模
%位置限幅为[xmin,xmax],速度限幅为[vmin,vmax]
Savef=zeros(n+1,1);
SaveData=zeros(m,dimension,10);%记录11代种群的位置
w=1;c1=2;c2=2;%速度惯性系数
dt=0.3;%位移仿真间隔
v=zeros(m,dimension);%初始速度为0
X=(xmax-xmin)*rand(m,dimension)+xmin;%初始位置满足(-xmax,xmax)内均匀分布
P=X;%P为每个粒子每代的最优位置
last_f=f(X);
[fmin,min_i]=min(last_f);%Pg为所有代中的最优位置
Pg=X(min_i,:);
Savef(1)=fmin;
N=0;
for i=1:n
v=w*v+c1*rand*(P-X)+c2*rand*(ones(m,1)*Pg-X);
v=(v>vmax).*vmax+(v>=vmin & v<=vmax).*v+(v<vmin).*vmin;
X=X+v*dt;
X=(X>xmax).*xmax+(X>=xmin & X<=xmax).*X+(X<xmin).*xmin;
new_f=f(X);%新的目标函数值
update_j=find(new_f<last_f);
P(update_j,:)=X(update_j,:);%修正每个粒子的历史最优值
[new_fmin,min_i]=min(new_f);
new_Pg=X(min_i,:);
Pg=(new_fmin<fmin)*new_Pg+(new_fmin>=fmin)*Pg;
last_f=new_f;%保存当前的函数值
fmin=min(new_fmin,fmin);%更新函数最小值
Savef(i)=fmin;
if mod(i,floor(n/10))==0%每10代记录一次种群参数
N=N+1;
SaveData(:,:,N)=X;
end
% w=w-i/n*0.7*w;
end
for j=1:10
figure(j)
plot(SaveData(:,1,j),SaveData(:,2,j),'o');
xlim([-xmax,xmax])
ylim([-xmax,xmax])
axis tight
end
figure
plot(Savef','b-')
disp(Pg)
disp(fmin)
end
这是一个粒子群算法的函数,可以求函数在一定范围内的极小值,下面我们来定义一个测试函数测试一下:
f
=
(
1
−
x
1
)
2
+
(
x
1
2
−
2
x
2
)
2
f=(1-x_1)^2+(x_1^2-2x_2)^2
f=(1−x1)2+(x12−2x2)2
我们很容易知道这个函数的极小值为
x
∗
=
(
1
,
0.5
)
T
x^*=(1,0.5)^T
x∗=(1,0.5)T
我们将X和Y方向上的限制都设定为[-40,40],种群规模200,仿真代数100次
f=@(x)(1-x(:,1)).^2+(x(:,1).^2-2*x(:,2)).^2;
[Pg,fmin]=PSO(f,2,100,200,40,-40,40,-40)
运行结果为:

| 序号 | 粒子群位置随迭代次数的变化 |
|---|---|
| 1 |  |
| 2 |  |
| 3 |  |
| 4 |  |
| 5 |  |
| 6 |  |
\qquad
读者们可以发现粒子群算法在迭代的过程中部分粒子甚至有反向运动的趋势,这是由于粒子的惯性速度过大导致的,在迭代点附近,惯性因子过大,会导致很长时间无法收敛到一个点,同时也很难找到相比上一次迭代更优的解。
\qquad
我们只需要随着迭代次数增加减少我们的惯性因子
w
w
w即可,在这里作者给出的表达式为
w
k
+
1
=
w
k
−
i
/
n
∗
0.7
w
k
w_{k+1}=w_k-i/n*0.7w_k
wk+1=wk−i/n∗0.7wk
i
i
i为当前迭代代数,
n
n
n为总代数。
调用同样的测试函数,种群规模、迭代次数及其他参数不变,我们得到结果如下:

和上一次对比我们可以发现fmin小了很多,即在相同的计算规模下我们的最优解更加接近于极小值,可谓一个突破性的改变,我们再看看粒子随迭代次数的分布:
| 序号 | 粒子群位置随迭代次数的变化 |
|---|---|
| 1 |  |
| 2 |  |
| 3 |  |
\qquad 可以发现粒子群的分布相比之前稳定得多,几乎全部收敛到了中心点,这便是减小惯性因子的作用。
2.PID自整定
2.1.基于M文件编写的PID参数自整定
\qquad
利用M文件可以制作一个简单的PID引擎,用于测试我们的PSO算法是否有效,书写简单PID引擎的代码可以参考如下链接:
【MATLAB】仿真PID控制
\qquad
我们仅需要在此基础上做一些改变并做成并行算法即可,当然,我们还需要设置一个自适应度函数,在自适应度函数的作用下,PSO算法会选择到我们满意的参数。在调整PID参数时,我们通常会关注响应曲线的超调、上升时间、调节时间、峰值时间等等。利用这些参数组合为评价函数,让评价函数越小,仿真得到的参数越好,以此作为解的好坏的对比依据(相当于鸟离食物的距离)为了简便起见,我们只选取了调节时间
t
s
t_s
ts和超调量
σ
\sigma
σ作为我们的比较依据,我们将评价函数设定为:
f
a
c
c
e
s
s
=
l
n
(
t
s
5
⋅
1
0
−
2
+
1
)
+
l
n
(
σ
1
0
−
4
+
1
)
f_{access}=ln(\frac{t_s}{5\cdot 10^{-2}}+1)+ln(\frac{\sigma}{10^{-4}}+1)
faccess=ln(5⋅10−2ts+1)+ln(10−4σ+1)
如果对该函数求导就可以发现:
∂
f
∂
t
s
∣
t
s
=
5
⋅
1
0
−
2
=
1
2
⋅
5
⋅
1
0
−
2
\frac{\partial f}{\partial t_s}_{|t_s=5\cdot 10^{-2}}=\frac{1}{2}\cdot 5\cdot 10^{-2}
∂ts∂f∣ts=5⋅10−2=21⋅5⋅10−2
∂
f
∂
σ
∣
σ
=
1
0
−
4
=
1
2
⋅
1
0
−
4
\frac{\partial f}{\partial \sigma}_{|\sigma=10^{-4}}=\frac{1}{2}\cdot 10^{-4}
∂σ∂f∣σ=10−4=21⋅10−4
\qquad
因此
f
a
c
c
e
s
s
f_{access}
faccess在
t
s
=
5
⋅
1
0
−
2
t_s=5\cdot 10^{-2}
ts=5⋅10−2的调整率为
2.5
×
1
0
−
2
2.5×10^{-2}
2.5×10−2,在
σ
=
1
0
−
4
\sigma=10^{-4}
σ=10−4时的调整率为
0.5
×
1
0
−
4
0.5×10^{-4}
0.5×10−4如果将期望参数定为
t
s
∗
=
5
⋅
1
0
−
2
,
σ
∗
=
1
0
−
4
t_s^*=5\cdot 10^{-2},\sigma ^*=10^{-4}
ts∗=5⋅10−2,σ∗=10−4则评价函数在小于任意一个参数的情况下就会下降,但是下降的速度会越来越大,而大于任意一个参数就会上升,但上升速率会越来越慢。由于两个参数均为正数,因此下降的速率不会大于
∂
f
∂
t
s
∣
t
s
=
0
=
1
\frac{\partial f}{\partial t_s}_{|t_s=0}=1
∂ts∂f∣ts=0=1和
∂
f
∂
σ
∣
σ
=
0
=
1
\frac{\partial f}{\partial \sigma}_{|\sigma=0}=1
∂σ∂f∣σ=0=1,而上升的速率可以无限小。若将评价函数小视为自适应度高,则调整过后的系统参数总是在期望值附近调整,并尽量满足$所有参数都小于期望值的情况。因为在期望值附近上升速率是越来越慢而下降速率是越来越快的,而参数最小只能取到0。因此,有多个参数大于期望值而有少个参数小于期望值的和会比有少个参数大于期望值而多个参数小于期望值的和要大得多。
\qquad
写好评价函数之后,我们可以设自适应度函数
F
=
−
f
a
c
c
e
s
s
F=-f_{access}
F=−faccess,因为我们的评价函数是越小越好的,而自适应度是越高越好。
\qquad
根据1.2的算法步骤我们可以编写出粒子群算法,而PID并行仿真引擎的编写需要参考上文提供的连接。(simulink的PID仿真请参考下一小节2.2.)粒子群算法每迭代出一代的参数(PSO.m),就把这一代里面最好的参数
P
G
P_G
PG返还给PID引擎进行仿真(PID_sim.m),再编写一个参数自识别的程序(parameter_cal.m),将需要识别的指标(调节时间、超调)计算出来,传递给
f
a
c
c
e
s
s
f_{access}
faccess进行计算(PID_access.m),将计算得到的参数
【PID_sim.m】(PID并行仿真引擎)
function [f_infty,tp,ts,sigma]=PID_sim(kp,ki,kd,debug)
%kp,ki,kd为PID参数,T0为采样时间,total_t为仿真时间
Tt=5e-4;%仿真采样周期
T0=1e-2;%控制采样周期
Tf=1e-3;%微分环节的滤波器系数
alp=Tf/(Tt+Tf);
total_t=1;
N=floor(total_t/Tt);%样本总数
M=numel(kp);%仿真序列数
kp=reshape(kp,M,1);
ki=reshape(ki,M,1);
kd=reshape(kd,M,1);
sys=tf(0.998,[0.021,1]); %建立被控对象传递函数,即式4.1
dsys=c2d(sys,Tt,'z'); %离散化
[num,den]=tfdata(dsys,'v'); %
e_1=zeros(M,1); %前一时刻的偏差
Ee=zeros(M,1); %累积偏差
u_1=zeros(M,1); %前一时刻的控制量
y_1=zeros(M,1); %前一时刻的输出
ud_1=zeros(M,1); %前一时刻的微分输出
%预分配内存
r=1500;
y=zeros(M,N);
u=zeros(M,N);
for k=1:1:N
y(:,k)=-1*den(2).*y_1+num(2)*u_1+num(1).*u(:,k);%系统响应输出序列
e0=r-y(:,k); %误差信号
ud=alp.*ud_1+(1-alp)/T0.*kd.*(e0-e_1);
u(:,k)=kp.*e0+T0*ki.*Ee+ud; %系统PID控制器输出序列
Ee=Ee+e0; %误差的累加和
u_1=u(:,k); %前一个的控制器输出值
y_1=y(:,k); %前一个的系统响应输出值
e_1=e0; %前一个误差信号的值
ud_1=ud;
end
if debug %非调试模式下不显示也不打印图像
plot(linspace(0,total_t,N),y)
end
[f_infty,tp,ts,sigma]=parameter_cal(y,Tt,2e-2,debug);%取得阶跃响应指标
end
【parameter_cal.m】(计算仿真曲线参数)
function [f_infty,tp,ts,sigma]=parameter_cal(y,T0,delt_err,debug)
%y是系统输出序列
%T0是采样时间,可以结合时间序列点序号算出实际时间
%delt_err是调节时间的误差精度
M=size(y,1);N=size(y,2);%M为运算维度,N为时间序列长度
f_infty=y(:,N);%稳态值序列
err=y-f_infty*ones(1,N);%通过稳态值计算误差序列
ferr=fliplr(abs(err));%倒序并取绝对值
[~,ts_i]=max(ferr>delt_err*f_infty,[],2);
ts_i=N*ones(M,1)-ts_i;
ts=ts_i*T0;%调节时间
[fp,tp]=max(y,[],2);%峰值和函数峰值
tp=tp*T0;
tp(abs(fp-f_infty)<1e-5)=NaN; %过阻尼无超调,没有峰值时间
sigma=(fp-f_infty)./f_infty;
if debug && M==1 %非调试模式下不显示
disp(['系统稳态值为',num2str(f_infty)])
disp(['系统超调量为',num2str(sigma*100),'%'])
if isnan(tp)
disp('系统不存在峰值时间')
else
disp(['系统峰值时间为',num2str(tp),'s'])
end
disp(['系统的调节时间为',num2str(ts),'s'])
end
end
【PID_access.m】(根据参数得出评价度的函数,程序中为评价度越低越好)
function y=PID_access(para)
%PID调节性能的指标参数
kp=para(:,1);ki=para(:,2);kd=para(:,3);
[~,~,ts,sigma]=PID_sim(kp,ki,kd,false);
y=log(ts/5e-2+1)+log(sigma/1e-2+1);
end
【PSO.m】(PSO算法优化函数)
function [Pg,fmin]=PSO(dimension,n,m)
%全局粒子群算法,f为目标函数,dimension为维度,n为代数,m为种群规模
w=1;c1=2;c2=2;%速度惯性系数
sigma_data=zeros(1,n);
ts_data=zeros(1,n);
dt=0.3;%位移仿真间隔
vmax=1;%速度限幅
xmax=[15,50,2];%位置限幅
xmin=[0.2,0,0];
v=zeros(m,dimension);%初始速度为0
X=(xmax-xmin).*rand(m,dimension)+xmin;%初始位置满足(xmin,xmax)内均匀分布
P=X;%P为每个粒子每代的最优位置
last_f=PID_access(X);
[fmin,min_i]=min(last_f);%Pg为所有代中的最优位置
Pg=X(min_i,:);
N=0;
for i=1:n
v=w*v+c1*rand*(P-X)+c2*rand*(ones(m,1)*Pg-X);
v=(v>vmax).*vmax+(v>=-vmax & v<=vmax).*v+(v<-vmax).*(-vmax);
X=X+v*dt;
X=(X>xmax).*xmax+(X>=xmin & X<=xmax).*X+(X<xmin).*(xmin);
new_f=PID_access(X);%新的目标函数值
update_j=find(new_f<last_f);
P(update_j,:)=X(update_j,:);%修正每个粒子的历史最优值
[new_fmin,min_i]=min(new_f);
new_Pg=X(min_i,:);
Pg=(new_fmin<fmin)*new_Pg+(new_fmin>=fmin)*Pg;
last_f=new_f;%保存当前的函数值
fmin=min(new_fmin,fmin);%更新函数最小值
[~,~,ts,sigma]=PID_sim(Pg(1),Pg(2),Pg(3),true)
sigma_data(1,i)=sigma;
ts_data(1,i)=ts;
hold on
end
legend('1','2','3','4','5','6','7','8','9','10','11','12','13','14','15')
title('响应曲线随迭代次数的变化')
figure
plot(ts_data)
title('调节时间随迭代次数的变化')
figure
plot(sigma_data)
title('超调量随迭代次数的变化')
end
【main.m】(主函数,从这里开始)
dimension=3;n=20;m=200;%PID为3位参数,n是迭代次数,m为种群规模
[Pg,fmin]=PSO(dimension,n,m)
仿真结果如下:

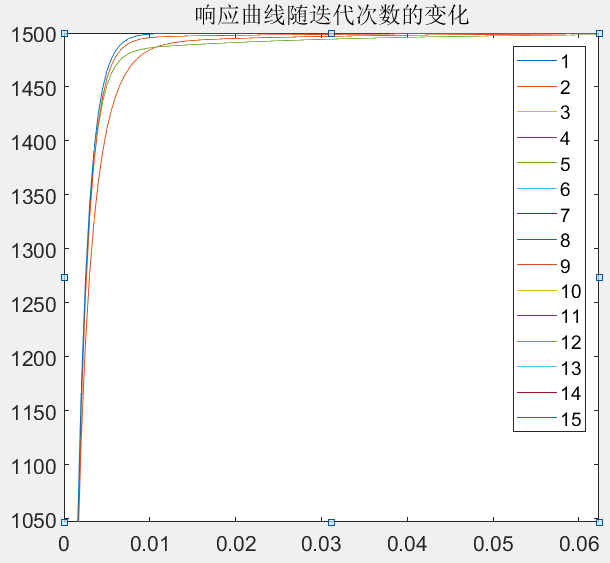
注:响应曲线可能要在左上角局部放大才能获得该图像。


\qquad
这是一个简单的一阶惯性系统的PID调参仿真,用于模拟直流电机的转速模型,可以看出直流电机的转速响应是越来越快的(调节时间越来越小),超调量在第一次就达到了0,因此系统不存在超调。
*2.2.复杂系统的PID自整定(基于simulink仿真)
\qquad 我们以双闭环直流调速系统为例来说明PSO对PID自整定参数的作用。直流调速系统由外环(转速环)和内环(电流环)构成,转速环是一个PI调节器,调节转速为期望转速,用于抵抗负载扰动、电机参数变化带来的扰动;电流环也是一个PI调节器,与转速环不同的是,电流调节器的目的是在于让电流快速跟随给定值,以获得更好的动态特性。我们以电机的启动过程为例仿真这个系统,直流电机启动时,电流首先达到容许最大值,电机以最大加速度进行加速,到达期望转速时让电流迅速减小并达到负载转矩所需电流,电机维持期望转速不变。
2.2.1.PSO优化PID的过程详解
\qquad
下面我们设定我们需要达成的调节指标——由于启动时的电机电流会迅速上升到过载电流(允许的最大值),是一个恒定值,故会有一个电流平台,记上升到电流平台产生的超调为电流超调
σ
i
\sigma_i
σi,从超调回到电流平台所需的时间为电流的调节时间
t
s
i
t_{si}
tsi,最终转速稳定前的超调记为转速超调
σ
n
\sigma_n
σn,转速到达稳定值区域的时间为调节时间
t
s
n
t_{sn}
tsn。
【搭建simulink模型】
双闭环调速系统的结构框图如下:

搭建simulink仿真模型如下:

注:上图可能不够清楚,根据以下参数搭建simulink模型,并且命名为double_circle.slx(和PSO的所有程序同名)
电机的参数如下:
- 额定电压/电流/功率:800V/2164A 1500KW
- 额定转速:44r/min
- 过载系数: λ i = 1.5 \lambda_i=1.5 λi=1.5
- 励磁:110V/191A
- 电枢电阻 R a R_a Ra:0.1 Ω \Omega Ω
- 主回路电阻R:0.1014 Ω \Omega Ω
- 电枢(主回路)电感L:3.25mH
- 变流器放大倍数 K s K_s Ks=80
- 变流器通态压降:3V
- 系统飞轮惯量: 8.6 × 1 0 5 N ⋅ m 2 8.6×10^5N\cdot m^2 8.6×105N⋅m2
\qquad
根据工程设计方法当然可以得到一套电流和转速的PI参数,计算的相关参数为:
[
K
n
p
,
K
n
I
,
K
i
p
,
K
i
I
]
E
N
=
[
7.3660
,
1.5658
,
0.8257
,
30.2773
]
[K_{np},K_{nI},K_{ip},K_{iI}]_{EN}=[7.3660 ,1.5658 ,0.8257, 30.2773]
[Knp,KnI,Kip,KiI]EN=[7.3660,1.5658,0.8257,30.2773]
通过仿真,我们得到的转速和电流曲线如下:
| 额定负载启动 | 空载启动 |
|---|---|
 |  |
调用我们的参数计算程序计算一下参数可以得到:
σ
n
=
4.07
×
1
0
−
4
%
,
t
s
n
=
0.7875
,
σ
i
=
20.38
%
,
t
s
i
=
0.0172
\sigma_n=4.07×10^{-4}\%,t_{sn}=0.7875,\sigma_i=20.38\%,t_{si}=0.0172
σn=4.07×10−4%,tsn=0.7875,σi=20.38%,tsi=0.0172
\qquad
这个参数当然是比较理想的参数,如果我们不知道工程设计方法或者说工程设计方法不适用于我们的模型时,那么就可以使用PSO整定PID参数的方法。
【修改simulink模型以适应PSO的M文件调用】
\qquad
这里需要调整的参数为转速调节器ASR的
K
n
p
,
K
n
I
K_{np},K_{nI}
Knp,KnI和电流调节器ACR的
K
i
p
,
K
i
I
K_{ip},K_{iI}
Kip,KiI,如果我们希望能实时调整simulink的参数进行动态仿真,我们需要直接将图中的几个比例环节依次设为符号(
K
n
p
,
K
n
I
,
K
i
p
,
K
i
I
K_{np},K_{nI},K_{ip},K_{iI}
Knp,KnI,Kip,KiI),并在工作区实时修改这4个参数再进行仿真。如果我们要将实时调整PI参数的代码写在M文件中仿真,必须要将变量声明为全局(global),此时变量会在工作区里面,simulink就可以调用了。另存为PSO_double_circle.slx
【编写辅助的M文件】
cal_n.m:单组PID参数仿真结果的参数计算
function [n_sigma,ts_n,I_sigma,ts_transient_i,n_err]=cal_n(parameters)
global Kpn KIn Kpi KIi
%将simulink所需参数导入工作区,以便仿真使用
obj_slx='PSO_double_circle.slx';
Kpn=parameters(1);
KIn=parameters(2);
Kpi=parameters(3);
KIi=parameters(4);
sim(obj_slx);
I_data=I.signals.values;n_data=n.signals.values;time=I.time;
n_infty=mean(n_data(numel(n_data)-10:numel(n_data)));
n_err=abs(n_infty-10/0.227);%期望与输出的转速误差
[i_max,tr_index]=max(I_data);
diffI=[0;diff(I_data)];%电流微分
pos=find(abs(diffI)<1);%找到电流波动较小的部分
pos=pos(pos>tr_index);%排除启动时电流不变的情况
min_pos=min(pos);
I_transient=mean(I_data(min_pos+10:min_pos+20));%恒流升速阶段的暂稳态电流值
I_sigma=(i_max-I_transient)/I_transient;
ts_transient_i=time(min_pos-tr_index);%电流暂稳态的调节时间
n_max=max(n_data);
n_sigma=(n_max-n_infty)/n_infty;
ts_n_index=numel(n_data)-find(abs(flip(n_data)-n_infty)/n_infty>2e-2,1);
ts_n=time(ts_n_index);
end
PID_n_access.m:PID参数的仿真,以代为单位的
function [y,ts_n,n_sigma,ts_transient_i,I_sigma]=PID_n_access(parameters_list)
M=size(parameters_list,1);%计算需要仿真的组数(simulink无法并行仿真)
ts_n0=0.8;n_sigma0=1e-2;I_sigma0=0.02;ts_i0=1e-4;%期望值
%将simulink所需参数导入工作区,以便仿真使用
y=zeros(M,1);
n_sigma=zeros(M,1);ts_n=zeros(M,1);
for sim_i=1:M
parameters=parameters_list(sim_i,:);
[n_sigma,ts_n,I_sigma,ts_transient_i,n_err]=cal_n(parameters);
y(sim_i)=log(ts_n./ts_n0+1)+log(n_sigma./n_sigma0+1)+log(I_sigma/I_sigma0+1)+log(ts_transient_i/ts_i0+1)+exp(n_err*10);
end
end
para_cal.m:参数计算,以代为单位的
obj_slx='double_circle.slx';
sim(obj_slx);
I_data=I.signals.values;n_data=n.signals.values;time=I.time;
I_infty=mean(I_data(numel(I_data)-10:numel(I_data)));
n_infty=mean(n_data(numel(n_data)-10:numel(n_data)));
[i_max,tr_index]=max(I_data);
diffI=[0;diff(I_data)];%电流微分
pos=find(abs(diffI)<1);%找到电流波动较小的部分
pos=pos(pos>tr_index);%排除启动时电流不变的情况
min_pos=min(pos);
I_transient=mean(I_data(min_pos+10:min_pos+20));%恒流升速阶段的暂稳态电流值
I_sigma=(i_max-I_transient)/I_transient;
if I_sigma<1e-4
tr_i=NaN;
else
tr_i=time(tr_index);%电流的上升时间
end
ts_transient_i=time(min_pos-tr_index);%电流暂稳态的调节时间
ts_i_index=numel(I_data)-find(abs(flip(I_data)-I_infty)/I_infty>2e-2,1);
ts_i=time(ts_i_index);%转速稳态时电流的调节时间
[n_max,tr_index]=max(n_data);
n_sigma=(n_max-n_infty)/n_infty;
%参数展示
%转速参数展示
if n_sigma<1e-4
tr_n=NaN;
else
tr_n=time(tr_index);
end
ts_n_index=numel(n_data)-find(abs(flip(n_data)-n_infty)/n_infty>2e-2,1);
ts_n=time(ts_n_index);
if isnan(tr_n)
disp('转速无超调')
else
disp(['转速上升时间为',num2str(tr_n),'s'])
disp(['转速超调量为',num2str(100*n_sigma),'%'])
end
disp(['转速调节时间为',num2str(ts_n),'s'])
%电流参数展示
if isnan(tr_i)
disp('电流无超调')
else
disp(['电流上升时间为',num2str(tr_i),'s'])
disp(['电流超调量为',num2str(100*I_sigma),'%'])
disp(['电流暂稳态调节时间为',num2str(ts_transient_i),'s'])
end
disp(['电流的最终调节时间为',num2str(ts_i),'s'])
draw.m:仅根据一组PID参数画出转速波形图
function draw(parameters)
global Kpn Kin KpI KiI
Kpn=parameters(1);
Kin=parameters(2);
KpI=parameters(3);
KiI=parameters(4);
sim('PSO_double_circle')
n_data=n.signals.values;time=n.time;%获取转速序列及对应时刻
plot(time,n_data)
draw_n_I.m:根据一组PID参数绘制电流和转速曲线
function draw_n_I(parameters)
global Kpn KIn Kpi KIi
Kpn=parameters(1);
KIn=parameters(2);
Kpi=parameters(3);
KIi=parameters(4);
sim('PSO_double_circle')
n_data=n.signals.values;time=n.time;%获取转速序列及对应时刻
I_data=I.signals.values;
figure
subplot(211)
plot(time,I_data,'r-','LineWidth',1.5)
title('电流波形')
subplot(212)
plot(time,n_data,'b-','LineWidth',1.5)
title('转速波形')
end
PSO.m:PSO优化程序
function [Pg,fmin]=PSO(n,m,xmax,xmin,cal_f,f)
%全局粒子群算法,f为目标函数,dimension为维度,n为代数,m为种群规模
dimension=numel(xmax);
w=1;c1=2;c2=2;%速度惯性系数
sigma_data=zeros(1,n);
ts_data=zeros(1,n);
dt=0.3;%位移仿真间隔
vmax=0.1*(xmax-xmin);%速度限幅
v=zeros(m,dimension);%初始速度为0
X=(xmax-xmin).*rand(m,dimension)+xmin;%初始位置满足(xmin,xmax)内均匀分布
P=X;%P为每个粒子每代的最优位置
last_f=f(X);
[fmin,min_i]=min(last_f);%Pg为所有代中的最优位置
Pg=X(min_i,:);
last_Pg=Pg;
legend_str=cell(0);
legend_i=1;
figure(1)
legend_str{legend_i}=num2str(1);
draw(Pg)
for i=1:n
v=w*v+c1*rand*(P-X)+c2*rand*(ones(m,1)*Pg-X);
v=(v>vmax).*vmax+(v>=-vmax & v<=vmax).*v+(v<-vmax).*(-vmax);
X=X+v*dt;
X=(X>xmax).*xmax+(X>=xmin & X<=xmax).*X+(X<xmin).*(xmin);
new_f=f(X);%新的目标函数值
update_j=find(new_f<last_f);
P(update_j,:)=X(update_j,:);%修正每个粒子的历史最优值
[new_fmin,min_i]=min(new_f);
new_Pg=X(min_i,:);
Pg=(new_fmin<fmin)*new_Pg+(new_fmin>=fmin)*Pg;
last_f=new_f;%保存当前的函数值
fmin=min(new_fmin,fmin);%更新函数最小值
[sigma,ts,~,~]=cal_f(Pg);
sigma_data(1,i)=sigma;
ts_data(1,i)=ts;
if last_Pg~=Pg
legend_i=legend_i+1;
figure(1)
legend_str{legend_i}=num2str(i);
draw(Pg)
hold on
end
last_Pg=Pg;
disp(['迭代次数:',num2str(i)])
end
figure(1)
legend(legend_str)
title('响应曲线随迭代次数的变化')
figure(2)
plot(ts_data)
title('调节时间随迭代次数的变化')
figure(3)
plot(sigma_data)
title('超调量随迭代次数的变化')
end
set_para.m(设置参数程序,从这里开始)
clear
best_parameters=[8.4725,97,72,1.794,56.06];
global Kpn KIn Kpi KIi
Kpn=0;KIn=0;Kpi=0;KIi=0;
n=10;m=100;xmax=[20,120,10,60];xmin=[0,0,0,0];cal_f=@cal_n;f=@PID_n_access;
[Pg,fmin]=PSO(n,m,xmax,xmin,cal_f,f);
我们将期望的参数设定为
σ
n
∗
=
0
,
1
%
,
t
s
n
∗
=
1
,
σ
i
∗
=
20
%
,
t
s
i
∗
=
0.005
\sigma_n^*=0,1\%,t_{sn}^*=1,\sigma_i^*=20\%,t_{si}^*=0.005
σn∗=0,1%,tsn∗=1,σi∗=20%,tsi∗=0.005利用PSO算法构造的评价函数为
f
a
c
c
e
s
s
=
l
n
(
t
s
n
1
+
1
)
+
l
n
(
σ
n
0.001
+
1
)
+
l
n
(
σ
i
0.2
+
1
)
+
l
n
(
t
s
i
0.005
+
1
)
;
f_{access}=ln(\frac{ts_n}{1}+1)+ln(\frac{\sigma_n}{0.001}+1)+ln(\frac{\sigma_i}{0.2}+1)+ln(\frac{ts_i}{0.005}+1);
faccess=ln(1tsn+1)+ln(0.001σn+1)+ln(0.2σi+1)+ln(0.005tsi+1);
得到的最佳参数为:
[
K
n
p
,
K
n
I
,
K
i
p
,
K
i
I
]
P
S
O
=
[
18.2613
,
73.0965
,
1.6843
,
16.5703
]
P
S
O
[K_{np},K_{nI},K_{ip},K_{iI}]_{PSO}=[18.2613,73.0965 ,1.6843,16.5703]_{PSO}
[Knp,KnI,Kip,KiI]PSO=[18.2613,73.0965,1.6843,16.5703]PSO
下的仿真曲线如下:
超调量和调节时间随迭代次数变化


PSO与工程设计方法电机启动曲线对比(额定负载启动)
| 工程设计方法 | PSO方法 |
|---|---|
 |  |
通过计算程序得到的参数为:
σ
n
=
6.7556
×
1
0
−
4
%
,
t
s
n
=
0.7862
,
σ
i
=
18.83
%
,
t
s
i
=
0.01341
\sigma_n=6.7556×10^{-4}\%,t_{sn}=0.7862,\sigma_i=18.83\%,t_{si}=0.01341
σn=6.7556×10−4%,tsn=0.7862,σi=18.83%,tsi=0.01341
工程设计方法的参数为:
σ
n
=
4.07
×
1
0
−
4
%
,
t
s
n
=
0.7875
,
σ
i
=
20.38
%
,
t
s
i
=
0.0172
\sigma_n=4.07×10^{-4}\%,t_{sn}=0.7875,\sigma_i=20.38\%,t_{si}=0.0172
σn=4.07×10−4%,tsn=0.7875,σi=20.38%,tsi=0.0172
\qquad
可以发现除了最后一项指标之外,其余指标均达到了期望值要求,并且和工程设计方法得出的指标相比甚至还略优于它。
2.2.2.在PSO优化过程中修改参数价值权重
\qquad
转速的超调和调节时间,电流的超调和调节时间,我们最后评估的指标除了转速无静差的基本要求外,这4项指标就是我们的评价标准,如果我们更希望牺牲某一个或多个参数去优化另一个或另一些参数时,该怎么调节我们的算法呢?
\qquad
答案也非常简单,调节的方法有2个,一个是期望值,一个是评价函数的各项系数。这里我们用调节期望值的方法做一个示范:
\qquad
之前的期望值为:
σ
n
∗
=
0.1
%
,
t
s
n
∗
=
1
,
σ
i
∗
=
20
%
,
t
s
i
∗
=
0.005
\sigma_n^*=0.1\%,t_{sn}^*=1,\sigma_i^*=20\%,t_{si}^*=0.005
σn∗=0.1%,tsn∗=1,σi∗=20%,tsi∗=0.005
修改期望值为:
σ
n
∗
=
10
%
,
t
s
n
∗
=
0.8
,
σ
i
∗
=
2
%
,
t
s
i
∗
=
0.0001
\sigma_n^*=10\%,t_{sn}^*=0.8,\sigma_i^*=2\%,t_{si}^*=0.0001
σn∗=10%,tsn∗=0.8,σi∗=2%,tsi∗=0.0001
重新仿真,对比二者的结果如下:
| PSO1 | PSO2 |
|---|---|
 |  |
\qquad
可以看出转速超调量略微增大了一些,但是转速和电流的调节时间明显缩短,电流的超调量基本不变。这一点也表明多项优化指标是相互耦合的,可以牺牲一者满足另一者,只要参数在这方面是可调的。
\qquad
需要注意的是,simulink中无法使用串行的算法,因此代码中使用时是串行的,可能仿真比较慢,请大家耐心等待(每迭代一次都会打印一次)
\qquad
希望本文对您有帮助,谢谢阅读!

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 256
256 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)