MongoDB数据去重(单字段和多字段去重)(百万级数据)
·
1、打开Mongo数据库,查询是否有数据重复
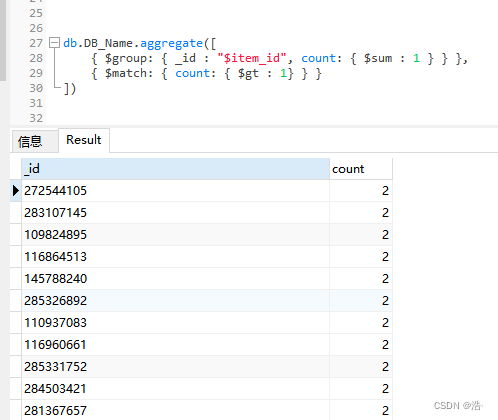
①、查询DB_Name数据库中的item_id字段重复数据(单字段):
db.DB_Name.aggregate([
{ $group: { _id : '$item_id', count: { $sum : 1 } } },
{ $match: { count: { $gt : 1} } }
],{allowDiskUse:true}) // 允许利用磁盘空间,防止出现内存不足运行输出结果:
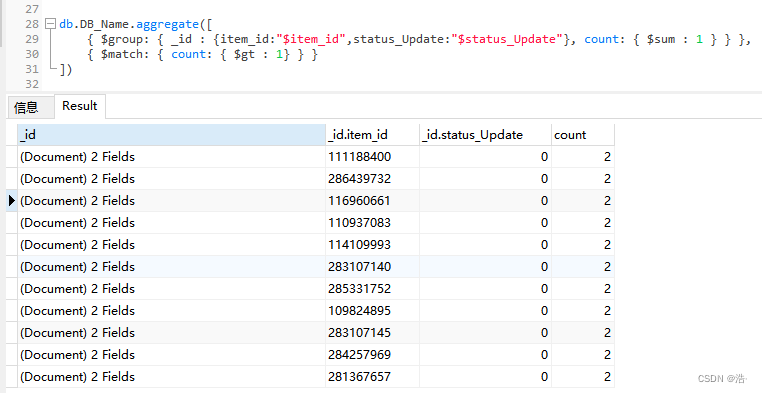
②、多字段查询:
跟只需要将单字段的 _id : '$item_id' 后面的 item_id 改成字典格式,即
_id : {item_id:"$item_id",status_Update:"$status_Update"}
// 若是需要多字段的话:
db.DB_Name.aggregate([
{ $group: { _id : {item_id:"$item_id",status_Update:"$status_Update"}, count: { $sum : 1 } } },
{ $match: { count: { $gt : 1} } }
],{allowDiskUse:true}) // 允许利用磁盘空间,防止出现内存不足运行输出结果:
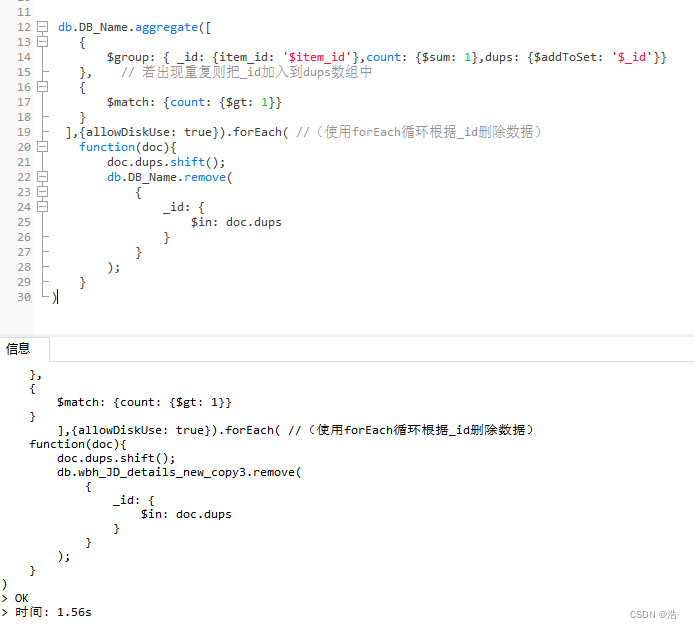
2、数据去重处理
原理:先将重复的数据加入到一个数组dups中,然后再利用forEach循环将dups数组的数据全部删除
db.DB_Name.aggregate([
{
$group: { _id: {item_id: '$item_id'},count: {$sum: 1},dups: {$addToSet: '$_id'}}
}, // 若出现重复则把_id加入到dups数组中
{
$match: {count: {$gt: 1}}
}
],{allowDiskUse: true}).forEach( //(使用forEach循环根据_id删除数据)
function(doc){
doc.dups.shift();
db.DB_Name.remove(
{
_id: {
$in: doc.dups
}
}
);
}
)运行结果:
上面代码为单字段去重,多字段的话同查询一样将 _id后的值改为一个字典的格式,即:
_id : {item_id:"$item_id",status_Update:"$status_Update"} 即可
其中要注意的一点是:
如果数据量过大,可能需要加上allowDiskUse:true 允许其利用磁盘空间,防止出现内存不足的情况
字段备注:
$group中是查询条件;
$count用来统计重复出现的次数, $match来过滤没有重复的数据;
$addToSet将聚合的数据id放入到dups数组中方便后面使用;

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 8
8 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)