

CycleGAN的基本原理以及Pytorch框架实现
CycleGAN的基本原理以及Pytorch框架实现
目录
1.了解CycleGAN
CycleGAN主页:https://junyanz.github.io/CycleGAN/
(1)什么是CycleGAN
- CycleGAN是实现不同图像之间风格的转换,并且样本数据无需配对即可实现转换。
- CycleGAN的创新点在于能够在源域和目标域之间,无须建立训练数据间一对一的映射,就可以实现这种迁移。
- CycleGAN特点:
- CycleGAN特点就是通过一个循环,首先将图像从一个域转换到另一个域,然后,再转回来,如果两次转换都很精准的话,那么,转换后的图像应该与输入的图像基本一致。通过这样的的一个循环,CycleGAN将转换前后图片的配对,类似于有监督学习,提升了转换效果。
比如:下面是斑马和马之间的风格转换,夏天和冬天之间风格的转换。

(2)CycleGAN的应用场景
CycleGAN主要用于Domain Adaption(域迁移)领域,如image style transfer图片风格迁移,物体转换,季节转化,图像增强领域取得了不错的效果。




2 CycleGAN原理
(1)整个模型


(2)优化目标
损失函数包含如下两部分:



(3)训练生成器和判别器
(1)训练生成器

(2)训练判别器

3.CycleGAN的网络结构
(1)生成器模型
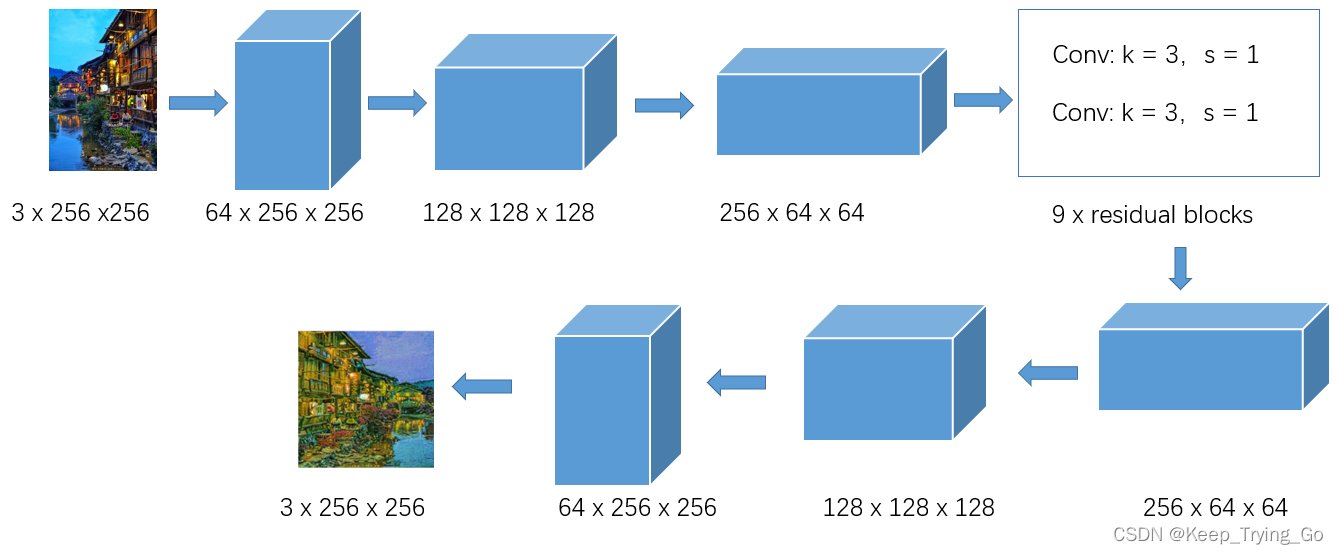
在CycleGAN的原论文中提到,对于生成器,如果输入的图像分辨率为:128 X 128大小的,则在网络中使用6个residual blocks;如果输入的图像分辨率为:256 x 256大小或者更大的,则在网络中使用9个residual blocks。
看一下原论文给出的结构(很重要):
解释其中的术语(如有解释不对的地方,请指出):
- 首先对于输入图像使用的卷积:
- Conv2d: out_channels = k,kernel_size = 7 x 7,stride = 1
- Norm: InstanceNorm(理解深度学习框架中的InstanceNorm)
- 激活函数:ReLU
- 第二个卷积(dk表示进行下采样(downSampling),输出通道数为k):
- Conv2d: out_channels = k, kernel_size = 3 x 3, stride = 2
- Norm: InstanceNorm
- 激活函数:ReLU
- 注意:上面的卷积中的padding_mode = “reflect”(关于padding_mode的方式有哪些)
- residuals blocks(Rk表示使用的残差连接,并且所有的residual blocks的通道数都为k):
- 每个residuals blocks中包含两个3 x 3的卷积,out_channles = k;
- Norm: InstanceNorm
- 激活函数:ReLU
- 最后的卷积输出(uk表示上采样(UpSampling),通道数为k):
- ConvTranspose2d: out_channels = k, kernel_size = 3 x 3, stride = 2
- Norm: InstanceNorm
- 激活函数:ReLU

对于生成模型的结构整体是上面样子的,但是这里网络包含输入的图像分辨率为128 x 128大小的结构和输入为256 x 256或者更大的:
- 对于输入为128 x 128大小图像分辨率的网络结构
对于输入为256 x 256或者更大图像分辨率的网络结构


提示:关于在搭建网络模型过程中卷积所使用的通道数,还是根据实际的 情况来,不一定一定要像论文中给出的:64->128->256->256->256->256->256->256->256->256->256->256->128->64->3。但是一定要保证最后输出的通道数为3,因为我们就是输出一张转换之后的图像。(在下面给出的代码中,还是按论文给定的来)。

开始使用Pytorch搭建模型结构……

(2)判别器模型
对于判别模型,我们这里输入的图像分辨率大小为256 x 256 ,
判别模型的网络结构简洁很多,原论文给出的判别模型结构说明如下:
解释其中的术语(如有解释不对的地方,请指出):
- 首先是输入(Ck表示进行卷积,通道数为k):
- Conv2d: kernel_size = 4 x 4,stride = 2
- 这里并没有使用InstanceNorm;
- 激活函数:LeakReLU(negative_slope=0.2)
- 中间层使用的通道数:128 -> 256 -> 512
- 最后输出:
- 由于判别模型是判别一张图像的真假,所以使用二分类激活函数作为输出:
- Sigmoid()

开始搭建网络模型结构……


4.CycleGAN代码实现
提示:代码放在了Github上,本文的代码是参考下面这位博主写的,但是自己其中只是做了一下修改,并且其中加了一个mainWindows界面代码,方便后面训练的模型进行图像风格的转换。
参考博主的代码:https://b23.tv/QUc0CNb
本文的代码下载:https://github.com/KeepTryingTo/Pytorch-GAN
提示:从自然景转换到梵高风格的图像,还不错,但是在从梵高风格的图像转换为自然景时,不是很好(只训练了一个epoch) 。

5.mainWindow窗口显示转换之后风格图
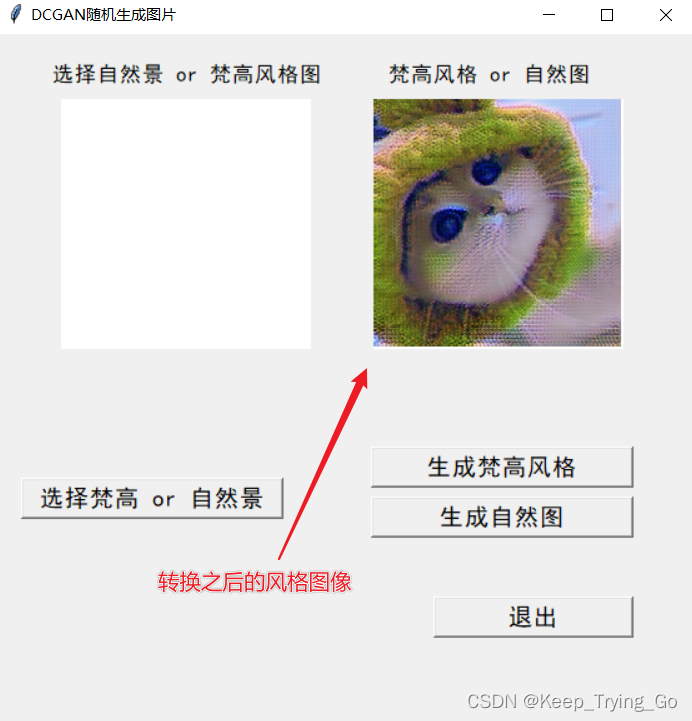
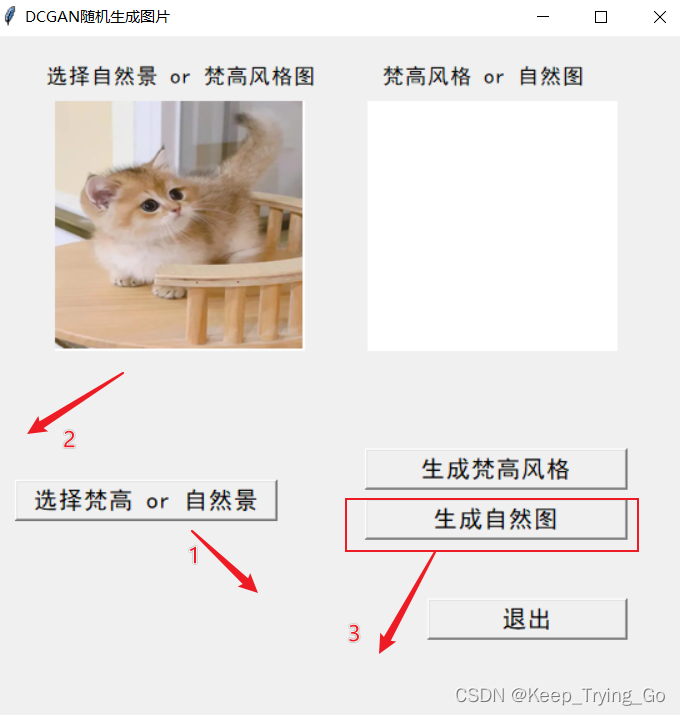
提示:这里编写了一个显示生成器显示图片的程序(mainWindow.py),加载之前训练之后保存的生成器模型,点击要生成的风格图像按钮,之后即可使用该模型进行风格转换,如下:
(1)运行mainWindow.py 初始界面如下
(2)转换风格过程


6.数据集下载和官方代码
CycleGAN数据集下载:https://people.eecs.berkeley.edu/~taesung_park/CycleGAN/datasets/
本文训练的CycleGAN生成模型下载:
链接:https://pan.baidu.com/s/18S81Uje87fSeWnz2q_FXTQ
提取码:sg00
CycleGAN官方代码:https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 22
22 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)