
(精确度,召回率,真阳性,假阳性)ACC、敏感性、特异性等 ROC指标
1、概念
| 金标准(标准集) | ||||
| 预测算法(预测集) | 验证存在(T) | 验证不存在(F) | 合计 | |
| 预测存在(P) | 预测为正,真实为正(TP) | 预测为正,真实为负(FP) | P(预测为正样本) | |
| 预测不存在(N) | 预测为负,真实为正(FN) | 预测为负,真实为负(TN) | N(预测为负样本) | |
| 合计 | T(验证为正样本) | F(验证为负样本) | 所有样本数(P+N或者T+F) | |
简化后:
| 标准集 | ||||
| 测试集 | 正样本 | 负样本 | 合计 | |
| 预测正样本 | TP | FP | P | |
| 预测负样本 | FN | TN | N | |
| 合计 | T | F | P+N或者T+F | |
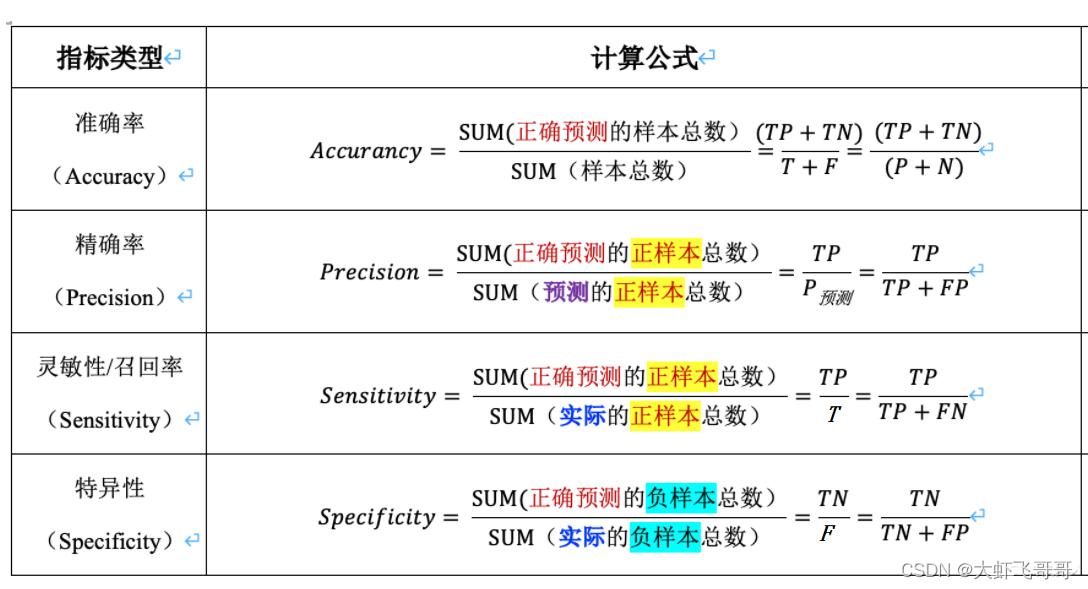
准确率(Accuracy):Acc = ( TP + TN ) / ( P +N )
精确率( precision )/(查准率):TP / ( TP+FP ) = TP / P
敏感性(Sensitivity)/召回率(recall)/(查全率):TP / (TP + FN ) = TP / T

真阳性率(True positive rate):TPR = TP / ( TP+FN ) = TP / T (敏感性 sensitivity)
真阴性率(TNR:true negative rate):TNR= TN / (TN+FP) = TN/F(特异性:specificity),描述识别出的负例占所有负例的比例
假阳性率(False positive rate):FPR = FP / ( FP + TN ) = FP / F
假阴性率 (False Negative Rate):FNR = FN /(TP + FN)= FN / T
F-measure:2*recall*precision / ( recall + precision )
ROC曲线:FPR为横坐标,TPR为纵坐标
PR曲线:recall为横坐标,precision 为纵坐标
=====概念解释=============
敏感性 Sensitivity
敏感性又称真阳性率,就是发病之后,你的诊断方法对疾病的敏感程度(识别能力)。
敏感性越高,漏诊概率越低。
特异性 Specificity
特异性又称真阴性率,不发病(我们这里称之为健康)的特征是有别于发病的特征的,我们利用这些差异避免误诊,那么诊断标准对于这些差异利用的如何就用特异性来表示。
特异性越高,确诊概率越高。
========================
从这个表格中可以引出一些其它的评价指标:
- ACC:classification accuracy,描述分类器的分类准确率
计算公式为:ACC=(TP+TN)/(TP+FP+FN+TN)
- BER:balanced error rate
计算公式为:BER=1/2*(FPR+FN/(FN+TP))
- TPR:true positive rate,描述识别出的所有正例占所有正例的比例
计算公式为:TPR=TP/ (TP+ FN)
- FPR:false positive rate,描述将负例识别为正例的情况占所有负例的比例
计算公式为:FPR= FP / (FP + TN)
- TNR:true negative rate,描述识别出的负例占所有负例的比例
计算公式为:TNR= TN / (FP + TN)
- PPV:Positive predictive value
计算公式为:PPV=TP / (TP + FP)
- NPV:Negative predictive value
计算公式:NPV=TN / (FN + TN)
其中TPR即为敏感度(sensitivity),TNR即为特异度(specificity)。
2、测试例子
十次十折后计算的预测标签

计算例子,比如第10次计算,通过excel筛选器,
筛选预测pda=1,label =1,共TP = 53个病例.
筛选预测pda=1,label =0共FP = 4个病例.
筛选预测pda=0,label =1,共FN = 11个病例.
筛选预测pda=0,label =0,共TN = 44个病例.
| 金标准(标准集) | ||||
| 预测算法(预测集) | 验证存在(T) | 验证不存在(F) | 合计 | |
| 预测存在(P) | 预测为正,真实为正(TP=53) | 预测为正,真实为负(FP=4) | P=57(预测为正样本) | |
| 预测不存在(N) | 预测为负,真实为正(FN=11) | 预测为负,真实为负(TN=44) | N=55(预测为负样本) | |
| 合计 | T=64(验证为正样本) | F=48(验证为负样本) | 所有样本数(P+N或者T+F=112) | |
敏感性 (sensitivity) TPR = TP / ( TP+FN ) = TP / T =0.828125
特异性(specificity) TNR= TN / (FP + TN) = 44/48 = 0.9166666666666667
准确率(Accuracy):Acc = ( TP + TN ) / ( P +N ) = (53+44 )/112 = 0.8660714285714286
ROC 曲线TPR,FPR计算例子:


2、目标检测Object Detection下的P-R曲线,AP,mAP,AUC,ROC曲线详解_喵喵扫描仪的博客-CSDN博客_目标检测roc曲线

4、ROC曲线、P-R曲线以及mAP_Mr_health的博客-CSDN博客_roc曲线使用场景
5、P-R曲线深入理解_keep_forward的博客-CSDN博客_p-r曲线
6、计算P-R曲线的代码:
sklearn.metrics.precision_recall_curve(y_true, probas_pred, pos_label=None, sample_weight=None)
sklearn.metrics.average_precision_score则计算预测值的平均准确率(AP: average precision)
python画PR曲线(precision-recall曲线)_Mr.Jcak的博客-CSDN博客_precision_recall_curve
7、用sklearn库自动计算tp,fp,tn,fn,计算acc,sen,spe,f1-score,precision指标。
参考文章:
1)sklearn中混淆矩阵(confusion_matrix函数)的理解与使用_秃头崽崽的博客-CSDN博客_sklearn 混淆矩阵
2)Python sklearn.metrics.confusion_matrix实例讲解 - 码农教程
3)机器学习笔记--classification_report&精确度/召回率/F1值_阿卡蒂奥的博客-CSDN博客_classification report
具体代码如下:
# aip指标
fpr_aip, tpr_aip, thresholds = metrics.roc_curve(roc_aip_gt_labels, roc_aip_pre_scores, drop_intermediate=False)
auc = metrics.auc(fpr_aip, tpr_aip)
all_indicators_aip["auc"].append(auc)
y_pred = np.where(np.array(roc_aip_pre_scores) > 0.5, 1, 0)
tn, fp, fn, tp = metrics.confusion_matrix(roc_aip_gt_labels, y_pred, labels=[0, 1]).ravel()
print(metrics.classification_report(roc_aip_gt_labels, y_pred, target_names=['BG', 'AIP'],
digits=4)) # target_names和上面的labels对上
sen = tp / (tp + fn)
all_indicators_aip["sen"].append(sen)
spe = tn / (tn + fp)
all_indicators_aip["spe"].append(spe)
precision = tp / (tp + fp)
all_indicators_aip["precision"].append(precision)
acc = (tp + tn) / (tp + fp + tn + fn)
all_indicators_aip["acc"].append(acc)
f1_score = 2 * precision * sen / (precision + sen)
all_indicators_aip["f1_score"].append(f1_score)
旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐
 16
16 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)