
Pytorch_lstm详细讲解
1.详细讲解官方文档的例子:这里有个老哥先带你回顾一下lstm的理论知识:pytorch中lstm参数与案例理解。_wangwangstone的博客-CSDN博客_torch.lstmRNN_了不起的赵队-CSDN博客_rnn这里主要要领清楚堆叠lstm层,使用的hidden state从lstm1着一层传到lstm2着一层,而不是一行中的几个lstm1单元连在一块的意思。这个图就可以理解为3个l
这里有个老哥先带你回顾一下lstm的理论知识:
pytorch中lstm参数与案例理解。_wangwangstone的博客-CSDN博客_torch.lstm
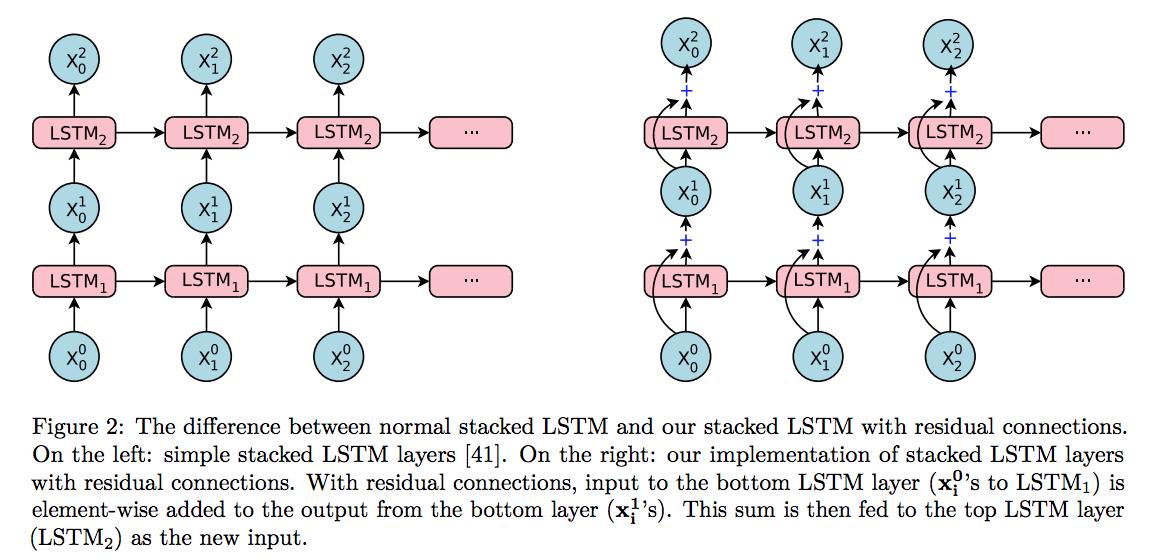
这里主要要领清楚堆叠lstm层,使用的hidden state从lstm1着一层传到lstm2着一层,而不是一行中的几个lstm1单元连在一块的意思。
这个图就可以理解为3个lstm1连在一块了,为第一张图里面的一行。
import torch
import torch.nn as nn # 神经网络模块
input = torch.randn(5, 3, 10)
# 输入的input为,序列长度seq_len=5, 每次取的minibatch大小,batch_size=3, 数据向量维数=10(仍然为x的维度)。每次运行时取3个含有5个字的句子(且句子中每个字的维度为10进行运行)
rnn = nn.LSTM(10, 20, 2)
# 输入数据x的向量维数10, 设定lstm隐藏层的特征维度20, 此model用2个lstm层。如果是1,可以省略,默认为1)
# 初始化的隐藏元和记忆元,通常它们的维度是一样的
# 2个LSTM层,batch_size=3, 隐藏层的特征维度20
h_0 = torch.randn(2, 3, 20)
c_0 = torch.randn(2, 3, 20)
# 这里有2层lstm,output是最后一层lstm的每个词向量对应隐藏层的输出,其与层数无关,只与序列长度相关
# hn,cn是所有层最后一个隐藏元和记忆元的输出
output, (h_n, c_n)= rnn(input, (h_0, c_0))
##模型的三个输入与三个输出。三个输入与输出的理解见上三输入,三输出
print(output.size(),h_n.size(),c_n.size())输出:torch.Size([5, 3, 20]) torch.Size([2, 3, 20]) torch.Size([2, 3, 20])2.来一个用循环神经网络lstm单元训练的mnist数据集分类案例
这里其实和之前用cnn训练mnist数据集差不多,这里也讲了使用rnn分类图像的可能性,可以去这里看看。
使用RNN进行图像分类_GavinZhou的博客-CSDN博客_rnn图像分类
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
# Device configuration
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# Hyper-parameters
sequence_length = 28
input_size = 28
hidden_size = 128
num_layers = 2
num_classes = 10
batch_size = 100
num_epochs = 2
learning_rate = 0.01
# MNIST dataset
train_dataset = torchvision.datasets.MNIST(root='../../data/',
train=True,
transform=transforms.ToTensor(),
download=True)
test_dataset = torchvision.datasets.MNIST(root='../../data/',
train=False,
transform=transforms.ToTensor())
# Data loader
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=False)
# Recurrent neural network (many-to-one)
class RNN(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, num_classes):
super(RNN, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, num_classes)
def forward(self, x):
# Set initial hidden and cell states
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(device)
c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(device)
# Forward propagate LSTM
out, _ = self.lstm(x, (h0, c0)) # out: tensor of shape (batch_size, seq_length, hidden_size)
# Decode the hidden state of the last time step
out = self.fc(out[:, -1, :])# 此处的-1说明我们只取RNN最后输出的那个hn
return out
model = RNN(input_size, hidden_size, num_layers, num_classes).to(device)
# Loss and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
# Train the model
total_step = len(train_loader)
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
images = images.reshape(-1, sequence_length, input_size).to(device)
labels = labels.to(device)
# Forward pass
outputs = model(images)
loss = criterion(outputs, labels)
# Backward and optimize
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i+1) % 100 == 0:
print ('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'
.format(epoch+1, num_epochs, i+1, total_step, loss.item()))
# Test the model
model.eval()
with torch.no_grad():
correct = 0
total = 0
for images, labels in test_loader:
images = images.reshape(-1, sequence_length, input_size).to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Test Accuracy of the model on the 10000 test images: {} %'.format(100 * correct / total))
# Save the model checkpoint
torch.save(model.state_dict(), 'model.ckpt')输出:Test Accuracy of the model on the 10000 test images: 97.95 %
首先是输入,在这里我解释一下我当时疑惑的地方,首先就是这个images.reshape,
images = images.reshape(-1, sequence_length, input_size).to(device)我通过试验对这个问题进行了解释:CSDN
然后看文档怎么说的,关于输入
并且这个lstm类使用的是动态传参,这下就不难理解为什么可以输入这样传了。
正好sequence_length = 28,input_size = 28,并且使用了batch_first=True,所以传的输入格式为(batch_size,sequence_length,input_size),这样就满足dataloader的image的size了,说得通了。

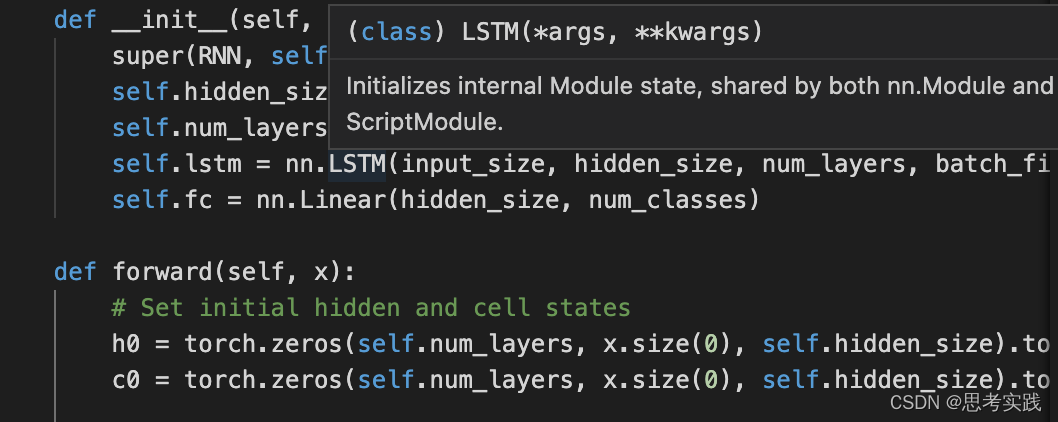
关于输出
完整代码中有一段,意思是我用不着hn,cn这里。
out, _ = self.lstm(x, (h0, c0)) # out: tensor of shape (batch_size, seq_length, hidden_size) #这里还有个输出_是代表不重要的意思,python程序员约定俗成的一种写法。也就是hn与cn最后lstm层的hiddenstate 与Cellstate # Decode the hidden state of the last time step然后关于out = self.fc(out[:, -1, :]),需要图文并茂才能解释的清清楚楚,感兴趣,可以去看这个链接pytorch 训练过程acc_PyTorch练习(一)循环神经网络(RNN)_亲123456的博客-CSDN博客
然后剩下的也就和普通的cnn分类mnist一样了。
细节补充
输入的参数列表包括:
input_size: 输入数据的特征维数,通常就是embedding_dim(词向量的维度)
hidden_size: LSTM中隐层的维度
num_layers: 循环神经网络的层数
bias: 用不用偏置,default=True
batch_first: 这个要注意,通常我们输入的数据shape=(batch_size,seq_length,embedding_dim),而batch_first默认是False,所以我们的输入数据最好送进LSTM之前将batch_size与seq_length这两个维度调换
dropout: 默认是0,代表不用dropout
bidirectional: 默认是false,代表不用双向LSTM
输入数据包括input, (h_0, c_0):input: shape = [seq_length, batch_size, input_size]的张量
h_0: shape = [num_layers * num_directions, batch, hidden_size]的张量,它包含了在当前这个batch_size中每个句子的初始隐藏状态,num_layers就是LSTM的层数,如果bidirectional = True,则num_directions = 2,否则就是1,表示只有一个方向
c_0: 与h_0的形状相同,它包含的是在当前这个batch_size中的每个句子的初始细胞状态。h_0,c_0如果不提供,那么默认是0
输出数据包括output, (h_t, c_t):output.shape = [seq_length, batch_size, num_directions * hidden_size]
它包含的LSTM的最后一层的输出特征(h_t),t是batch_size中每个句子的长度.
h_t.shape = [num_directions * num_layers, batch, hidden_size]
c_t.shape = h_t.shape
h_n包含的是句子的最后一个单词的隐藏状态,c_t包含的是句子的最后一个单词的细胞状态,所以它们都与句子的长度seq_length无关。
output[-1]与h_t是相等的,因为output[-1]包含的正是batch_size个句子中每一个句子的最后一个单词的隐藏状态,注意LSTM中的隐藏状态其实就是输出,cell state细胞状态才是LSTM中一直隐藏的,记录着信息,这也就是博主本文想说的一个事情,output与h_t的关系。
————————————————
版权声明:本文为CSDN博主「Mr.Ygg」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_44201449/article/details/111129248
大家有什么疑惑的地方欢迎讨论。
参考资料
pytorch实现rnn并且对mnist进行分类
pytorch实现rnn并且对mnist进行分类_weixin_30410119的博客-CSDN博客
pytorch中lstm参数与案例理解//很细了
pytorch中lstm参数与案例理解。_wangwangstone的博客-CSDN博客_torch.lstm
pytorch nn.LSTM()参数详解//上手极快
pytorch nn.LSTM()参数详解_向阳争渡-CSDN博客_nn.lstm参数
lstm_pytorch官方文档//里面可以让你对细节恍然大悟
LSTM — PyTorch master documentation
torch.nn.lstm//整理得真的很好
如何理解LSTM的输入输出格式//补充
如何理解LSTM的输入输出格式_comli_cn的博客-CSDN博客_lstm输入格式
LSTM细节分析理解(pytorch版)//补充

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 47
47 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)