
IEMOCAP数据集分析
IEMOCAP数据集分析论文:IEMOCAP: Interactive emotional dyadic motion capture database作者:Carlos Busso, Murtaza Bulut, Chi-Chun Lee, Abe Kazemzadeh,Emily Mower, Samuel Kim, Jeannette N. Chang, Sungbok Lee and Sh
IEMOCAP数据集分析
论文:IEMOCAP: Interactive emotional dyadic motion capture database
作者:Carlos Busso, Murtaza Bulut, Chi-Chun Lee, Abe Kazemzadeh,
Emily Mower, Samuel Kim, Jeannette N. Chang, Sungbok Lee and Shrikanth S. Narayanan
实验室:Speech Analysis and Interpretation Laboratory (SAIL)
University of Southern California, Los Angeles, CA 90089
发布时间:2008年
论文链接:https://sail.usc.edu/iemocap/Busso_2008_iemocap.pdf
数据集链接:需要填写申请https://sail.usc.edu/iemocap/iemocap_release.htm
论文框架:

论文解读:
- 参考论文?官网?建库团队?
参考论文:IEMOCAP: Interactive emotional dyadic motion capture database
官网:https://sail.usc.edu/iemocap/
建库团队:南加州大学(USC)的语音分析和解释实验室(SAIL) - 有几种模态?分别是哪些?给出示例图?模态间的对齐关系?
模态数量:3
模态:视频、语音、面部动作捕捉、文本转录 - 哪些标签?如何标注的?
分类标签:中立状态,幸福,悲伤,愤怒,惊讶,恐惧,厌恶,挫败感,兴奋,其他
维度标签,如效价、激活和支配
标注方式:人工标注者 - 如何得到这些数据集的?
选择来自南加州大学戏剧系的五名女演员和五名男演员作为受试者,设定使用戏剧(有脚本的会议)和基于即兴创作的假设场景(自发会议)的双重会话模式。
受试者被记录在五个双重记录会话中,每个会话持续大约六个小时。在会话一中受试者表演三个具有清晰情感内容的选定剧本;会话二中受试者即兴创作了旨在引发特定类型情感(快乐、愤怒、悲伤、沮丧和中性状态)的假设场景。在每次互动期间,两人中的一名参与者一次被捕捉到动作。53 个面部标记被附加到被运动捕捉的对象上,实验团队通过受试佩戴的腕带和带有标记的头带,捕捉手部和头部运动 - 数据集大小?单个视频时长?
数据集大小:16.4G
包含大约 12 小时的视听数据
语料库总共包含一万零三十九轮(脚本会话:5255 轮;自发会话:4784 轮)。平均持续时间为4.5 秒。每轮单词的平均值为11.4。 - 数据集内容topic
数据集一共包含10个主题(中立状态,幸福,悲伤,愤怒,惊讶,恐惧,厌恶,挫败感,兴奋,其他) - 建库年代?
2008年 - 被试
被引用1524次
论文翻译:
摘要
由于情感是通过语言和非语言渠道的组合来表达的,因此需要对语音和手势进行联合分析才能理解富有表现力的人类交流。 为了促进此类调查,本文描述了一个名为\交互式情感二元运动捕捉数据库(IEMOCAP)的新语料库,由南加州大学(USC)的语音分析和解释实验室(SAIL)收集。该数据库被记录来自 10 位演员的面部、头部和手部标记,在脚本化和自发的口语交流场景中提供有关他们面部表情和手部动作的详细信息。演员们表演了选定的情感剧本,并即兴创作了旨在引发特定类型情感(快乐、愤怒、悲伤、沮丧和中性状态)的假设场景。 语料库包含大约十二个小时的数据。 详细的动作捕捉信息、引发真实情感的交互设置以及数据库的大小使该语料库成为社区现有数据库的宝贵补充,用于研究和建模多模态和富有表现力的人类交流。
关键词:视听数据库,二元交互,情感,情感评估,动作捕捉系统
1. 介绍
人类互动过程中表达的最有趣的副语言信息之一就是主体的情绪状态,它通过言语和手势来传达。 说话的语气和能量、面部表情、躯干姿势、头部位置、手势和凝视都以一种非平凡的方式结合在一起,在人类自然交流中展现出来。 如果要开发和实施强大的情感模型,就需要共同研究这些交流渠道。
在这种情况下,情感表达研究的主要限制之一是缺乏包含来自大多数这些渠道的综合信息的真正交互的数据库。 Douglas-Cowie等分析了一些现有的情感数据库 [28]得出的结论是:在大多数语料库中,受试者被要求模拟 (“表演") 特定情绪。虽然从提供受控启发的角度来看是可取的,但是数据收集中的这些简化丢弃了在现实生活场景中观察到的重要信息 [29]。因此,当这些数据库开发的自动识别模型用于现实生活应用程序时,情感识别的性能显着降低 [6],其中观察到情绪的混合 [29, 27](即“基本情绪”的组合[31])。现有语料库的另一个限制是,记录的材料通常由几轮孤立的话语或对话组成 [28]。 这种设置忽略了情境化的重要影响,它在我们如何感知 [19] 和表达情绪 [29] 中起着至关重要的作用。 同样,大多数现有数据库仅包含声学语音通道。因此,这些语料库不能用于研究通过其他通信渠道传达的信息。 当前情绪数据库的其他局限性是受试者数量有限,以及数据库规模较小 [29]。 Ververidis 和 Kotropoulos [54] 发表的评论中也提出了类似的观察结果。
考虑到这些限制,我们设计了一个新的视听数据库,其中特别包括直接和详细的动作捕捉信息,而不是由视频处理的现有技术水平所要求的,这将有助于访问详细的手势信息。 在这个数据库中,这里将被称为交互式情感二元运动捕捉数据库 (IEMOCAP),十个演员被记录在二元会话中(5 个会话,每个会话有 2 个对象)。 他们被要求表演三个具有清晰情感内容的选定剧本。 除了剧本之外,受试者还被要求在假设场景中即兴对话,旨在引发特定的情绪(快乐、愤怒、悲伤、沮丧和中性状态)。 在每次互动期间,两人中的一名参与者一次被捕捉到动作。 53 个面部标记被附加到被运动捕捉的对象上,他们还戴着腕带和带有标记的头带,分别用于捕捉手部和头部运动(见图 1)。 使用此设置,可以在适当的上下文中引发情绪,从而提高所捕获情绪数据的真实性。 此外,从十个不同的主题收集数据增加了在更一般的水平上有效分析该数据库中观察到的趋势的合理性。 该数据库总共包含大约 12 小时的数据。
 图 1. 标记布局——在录音中,五十三个标记被贴在受试者的脸上。 他们还戴着腕带(两个标记)和头带(两个标记)。每只手上还附有一个额外的标记。
图 1. 标记布局——在录音中,五十三个标记被贴在受试者的脸上。 他们还戴着腕带(两个标记)和头带(两个标记)。每只手上还附有一个额外的标记。
这个语料库花了大约 20 个月的时间收集(从设计到后期处理阶段),希望能增加资源,帮助推进研究,了解如何对表达性人类交流进行建模。 有了这个数据库,我们希望能够扩展和概括我们之前关于关系的结果——在富有表现力的演讲和对话互动中,语音、面部表情、头部运动和手势之间的传递和相互作用 [9, 11, 12, 13]。 同样,我们希望使用统一的框架对人类行为的不同方面进行建模和综合,该框架适当地考虑了面部表情和语音之间的潜在关系(例如,由语音韵律驱动的头部运动 [7, 8])。
本文的其余部分安排如下。
- 第 2 节回顾了用于研究情绪的视听数据库。
- 第 3 节描述了本文提出的语料库的设计。
- 第 4 节解释了数据库的记录程序。
- 第 5 节介绍了各种后处理步骤,例如标记数据的重建、分割和情感评估。
- 第 6 节讨论 IEMOCAP 数据库如何克服当前最先进的情感数据库中的一些主要限制。 它还评论了可以使用这些数据研究的一些研究问题。
- 最后,第 7 节给出了结论和最后评论。
2. 视听数据库的简要回顾
情感表达研究取得重大进展所需的关键改进之一是收集克服当前情感语料库中存在的局限性的新数据库。 Douglas-Cowie等人讨论了最先进的情感数据库 [28],重点关注四个主要领域:范围(说话者的数量、情感类别、语言等)、自然性(行为与自发)、上下文(孤立与上下文)和 描述符(语言和情感描述)。 他们强调了在交互过程中记录自然情绪的合适数据库的重要性,而不是独白。 一个好的数据库的其他要求是多个说话者、多模态信息捕获和语料库中包含的情绪的足够描述。
考虑到情绪研究中考虑的多个变量,预计将需要一组数据库而不是单个语料库来解决这个多学科领域的许多开放性问题。 不幸的是,目前满足这些核心要求的情感数据库很少。 迄今为止,收集新情感数据库的一些最成功的努力都是基于广播电视节目。 其中一些例子是Belfast自然数据库 [28, 29]、VAM 数据库 [37, 38] 和 EmoTV1 数据库 [1]。 同样,对于情感语料库,尤其是对于极端情绪(例如,SAFE 语料库 [20])也提出了具有表达内容的电影节选。 然而,这些方法的一个重要限制是版权和隐私问题,阻碍了语料库的广泛分发 [23, 28]。 此外,麦克风和摄像头的位置、词汇和情感内容以及视觉和听觉背景都无法控制,这对数据的处理提出了挑战[23]。 其他收集自然数据库的尝试是基于原位录音(热那亚机场丢失行李数据库 [48]),记录来自真实呼叫中心的语音对话(CEMO [56] 和 CCD [44] 语料库),要求受试者回忆 情感体验 [2],使用人机界面(例如 SmartKom 数据库 [50])在解决问题的环境中使用绿野仙踪方法诱导情感,使用专门设计来吸引用户的游戏(例如 EmoTaboo 语料库) [57]),并通过精心设计的人机交互(即 SAL [17, 23])诱发情感。 在 Humaine 项目门户中,提供了一些现有情感数据库的进一步描述 [41]。
在受控条件下录制专业演员可以克服上述录制技术的许多限制。我们在之前的工作中已经声称,当使用合适的表演方法从有经验的演员那里引发情感认识时,可以记录高质量的表演数据库,参与对话而不是独白 [15]。 Geneva多模态情感描述 (GEMEP) [5] 就是一个很好的例子。 Enos 和 Hirschberg 认为,情绪的产生是预期和最终实现的结果 [32]。 他们建议,如果这种以目标为导向的方法适当地结合到录音中,表演数据库可以产生更真实的情感。
为了对受试者的言语和非言语行为进行统一分析,数据库应包括视觉通道,捕捉手势和面部表情,并结合听觉通道。 尽管有使用图像跟踪面部显着特征的自动平台(例如,[21]),但使用视频处理中的最新技术目前无法实现由运动捕捉数据提供的详细面部信息的水平。 这在没有显着特征点的脸颊区域尤其显着。据我们所知,很少有动作捕捉数据库可用于研究情绪表达。 Kapur等人提出了一个情绪动作捕捉数据库,但他们只针对身体姿势(没有面部表情)[42]。USC Facial Motion Capture Database (FMCD),我们之前的视听数据库,是另一个例子[9]。这个数据库是从一位脸上贴着标记的女演员那里记录下来的,她被要求阅读表达特定情绪的语义中立的句子。 该语料库的两个主要限制是情绪是在孤立的句子中引发的,并且只记录了一个说话者。 本文中描述的 IEMOCAP 数据库旨在克服其中一些基本限制。 下面列出了设计 IEMOCAP 数据库时考虑的要求。
- 数据库必须包含情感的真实实现。
- 数据库应该包含自然的对话,而不是独白和孤立的句子,在对话中,情感被恰当地、自然地引出。
- 应该记录很多有经验的演员。
- 数据库的记录应该在情感和语言内容方面尽可能控制。
- 除了用于捕捉语言行为的音频通道外,数据库还应具有详细的视觉信息以同步捕捉非语言信息。
- 情感标签应根据人类主观评价进行分配。
请注意,其中一些要求之间存在固有的权衡(例如,自然性与表达内容的控制)。 接下来的部分描述了如何在 IEMOCAP 数据库集合中满足这些要求。
3. 数据库的设计
IEMOCAP 数据库旨在扩展我们在表达性人类交流方面的研究。 在我们之前的工作中,我们分析了手势和语音之间的关系 [12],以及这些交流渠道中语言目标和有效目标之间的相互作用 [10, 11]。 我们的结果表明,手势和语音呈现出高度的相关性和协调性,并且在不同的交流渠道中观察到的情绪调制并不是均匀分布的。 事实上,我们的结果表明,当一种模态受到语音清晰度的限制时,会使用具有更多自由度的其他渠道来传达情感 [13]。 作为分析的结果,我们展示了在自动机器识别和表达人类行为的综合方面的应用。 例如,我们在虚拟角色中对人类行为的各个方面进行建模和合成。 特别是,我们提出了一个基于 HMM 的框架来合成由声学韵律特征驱动的自然头部运动 [7, 8]。 在所有这些研究中,都使用了 FMCD 数据库。由于这个数据库是从单个主题记录的,这个新的语料库将使我们能够验证和扩展我们的研究。 第 6.2 节详细介绍了我们计划使用该数据库探索的新方向。
在我们之前的工作中,我们主要关注快乐、愤怒、悲伤和中性状态 [9, 11, 12, 13]。 这些类别是文献中最常见的情绪描述词 [47]。 对于这个数据库,我们决定还包括挫折,因为从应用程序的角度来看,它也是一种重要的情绪。 因此,语料库的内容旨在涵盖这五种情绪。 正如将在第 5 节中讨论的,在情绪评估期间,情绪类别被扩展为包括厌恶、恐惧、兴奋和惊讶。 这样做的目的是更好地描述语料库中的情绪,特别是在自发/无脚本的启发场景中。
在设计这个数据库时,最重要的考虑是要有一个庞大的情感语料库,其中包含许多能够表达真实情感的主体。 为了实现这些目标,语料库的内容和主题都经过精心挑选。
3.1. 材料选择
与提供不能保证在录音过程中真实表达情感的阅读材料不同,我们选择了两个不同的方法:使用戏剧(有脚本的会议)和基于即兴创作的假设场景(自发会议)。
第一种方法基于一组脚本,要求受试者记住和排练。 戏剧的使用提供了一种限制语料库语义和情感内容的方法。 看了一百多部10分钟的剧本,选出了三个剧本。 鉴于戏剧应传达==目标情绪(快乐、愤怒、悲伤、沮丧和中性状态)==的要求,戏剧专业人士监督了选择。 此外,这些戏剧的选择使它们每个都由一个女性和一个男性角色组成。强加这一要求是为了平衡性别方面的数据。由于这些情绪是在合适的上下文中表达的,与简单的孤立句子的录音相比,它们更有可能以真实的方式传达。
在第二种方法中,受试者被要求根据旨在引发特定情绪的假设场景即兴创作(见表 I)。 自发场景的主题是按照 Scherer 等人提供的指南选择的。[49]。 正如他们在书中所报道的那样,作者对那些被要求记住过去引发某些情绪的情况的人进行了调查。 假设情景基于一些常见情况(例如,失去朋友、分离)。 在这种情况下,被试可以自由地用自己的话来表达自己。 通过给予演员相当大的表达情感的自由,我们期望结果将提供情感的真正实现。
 表 1. 用于在数据库集合中引发无脚本/未经演练的交互的场景。——每个主题的目标情绪在括号中给出(Fru = 沮丧,Sad = 悲伤,Hap = 幸福,Ang = 愤怒,Neu = 中性)。
表 1. 用于在数据库集合中引发无脚本/未经演练的交互的场景。——每个主题的目标情绪在括号中给出(Fru = 沮丧,Sad = 悲伤,Hap = 幸福,Ang = 愤怒,Neu = 中性)。
我们之前的工作[16]比较了这两种启发方法的优缺点。
3.2. 演员选择
正如 [28] 所建议的,在人际交往剧中扮演角色的熟练演员可能会提供更自然的情绪表现。 因此,这个数据库依赖于来自南加州大学戏剧系的 7 名专业演员和 3 名高年级学生。 在审查了他们的试镜课程后,选出了五名女演员和五名男演员。 他们被要求在经验丰富的专业人士(担任导演)的监督下排练剧本,确保剧本被记住并真实表达预期的情绪,避免情绪的夸大或讽刺。
受试者被记录在五个双重记录会话中,每个会话持续大约六个小时,包括适当的休息时间。由于选定的剧本有女性和男性角色,因此在 5 个会话中的每个会话中都记录了一个男演员和一个女演员(见图 2)。
 图 2. 参与录制的两名演员,展示面部和头带上的标记
图 2. 参与录制的两名演员,展示面部和头带上的标记
4. 语料库的记录
对于每个会话,将 53 个标记(直径 ≈ \approx ≈ 4 毫米)附着在二元组中的一个受试者的脸上以捕获详细的面部表情信息,同时保持标记彼此远离以提高轨迹重建步骤的准确性。大多数面部标记是根据 MPEG-4 标准 [46, 52] 中定义的特征点放置的。 图 1 和图 2 显示了标记的布局。 受试者戴着一个头带,上面有两个标记(直径 ≈ \approx ≈ 2.5 厘米)。 这些相对于面部运动是静态的标记用于补偿头部旋转。 此外,受试者佩戴的腕带各有两个标记(直径 ≈ \approx ≈ 1 厘米)。每只手上还增加了一个额外的标记。 由于每只手仅使用三个标记,因此不可能有详细的手势(例如,手指)。 然而,这些标记提供的信息可以粗略估计手的运动。 录音中总共使用了 61 个标记(图 1)。 请注意,标记非常小,不会干扰自然语音。 事实上,受试者报告说他们戴着标记感到很舒服,这并没有妨碍他们自然地说话。
脚本和自发场景录制后,将标记附加到另一个主题上,适当休息后再次录制会话。 请注意,最初的想法是在两个扬声器上同时使用标记。 然而,目前的方法是首选,以避免两个独立设置之间的干扰。 VICOM 相机对其视野内的任何反射材料都很敏感。 因此,在不影响动作捕捉记录的情况下(计算机、麦克风、相机)定位房间中的附加设备在技术上是困难的。 此外,在此设置下,所有摄像机都指向一个对象,从而提高了记录的分辨率和质量。
该数据库是使用 USC 的 John C. Hench 动画与数字艺术部(Robert Zemeckis 中心)的设施记录的。 标记数据的轨迹是使用 VICON 运动捕捉系统记录的,该系统具有八个摄像机,这些摄像机放置在距离带有标记的对象大约一米处,因为可以如图 3 所示。运动捕捉系统的采样率为每秒 120 帧。 为了避免在 VICOM 摄像机的共同视野范围内做出手势,要求受试者在录制过程中就座。 然而,他们被指示尽可能自然地做手势,同时避免用手遮住脸。 没有标记的对象坐在 VICON 摄像机的视野之外,以避免可能的干扰。 由于这种物理限制,演员之间的距离大约为三米。 由于参与者在霍尔 [39] 定义的社交距离内,我们预计近距的影响不会影响他们的自然互动。 在每次录制开始时,演员都被要求展示面部的中性姿势大约两秒钟。 该信息可用于定义标记的中性姿态。
 图 3. 带有 8 个摄像头的 VICON 运动捕捉系统——带有标记的对象坐在房间中央,摄像机对准他/她。 没有标记的对象坐在 VICON 摄像机的视野之外,面向有标记的对象。
图 3. 带有 8 个摄像头的 VICON 运动捕捉系统——带有标记的对象坐在房间中央,摄像机对准他/她。 没有标记的对象坐在 VICON 摄像机的视野之外,面向有标记的对象。
音频是使用两个高质量的枪式麦克风 (Schoeps CMIT 5U) 同时录制的,指向每个参与者。 采样率设置为 48KHz。 此外,两个高分辨率数码相机(索尼 DCR-TRV340)用于记录参与者的半正面视图(见图 5)。 这些视频用于情绪评估,将在第 5 节中讨论。
 图 5. 用于情绪评估的 ANVIL 注释工具。—— 这些元素是为转弯手动创建的。 可以根据分类描述词(例如幸福、悲伤)或原始属性(例如激活、效价)来评估转弯的情感内容。
图 5. 用于情绪评估的 ANVIL 注释工具。—— 这些元素是为转弯手动创建的。 可以根据分类描述词(例如幸福、悲伤)或原始属性(例如激活、效价)来评估转弯的情感内容。
通过使用带有连接到其末端的反射标记的隔板来同步录音。 使用隔板,各种模态可以与麦克风收集的声音以及 VICON 和数码相机记录的图像准确同步。 摄像机和麦克风的放置方式使演员可以面对面,这是自然互动的必要条件。 此外,脸在视线内 - 不说话到相机的背面。 事实上,演员们报告说,录音的附带条件并没有影响他们的自然互动。
5. 后处理
5.1. 数据的分割和转录
在会话被记录后,对话在对话轮级(说话者轮流)被手动分割,定义为其中一个演员正在积极发言的连续片段(见图 5,它显示了两个回合) 情绪评价)。 没有分割显示积极倾听的短回合,例如 “mmhh”。多句话语被拆分为单个回合。对于数据的脚本部分(参见第 3.1 节),文本被预先分割成句子并用作参考 拆分对话。此分割仅用作指导,因为我们不需要在跨会话的脚本中进行相同的分割。语料库总共包含一万零三十九轮(脚本会话:5255 轮;自发会话:4784 轮) 平均持续时间为 4.5 秒。每轮单词的平均值为 11.4。脚本和自发会话的每轮单词直方图如图 4 所示。这些值与众所周知的轮次统计数据相似 自发语料库,例如 Switchboard-1 电话语音语料库(第 2 版)和 Fisher 英语培训语音第 1 部分(见表 II)。

图 4. 脚本化和自发会话中每回合字数(百分比)的直方图。

表二。 IEMOCAP 数据库语音的分词统计。——还显示了流行的自发口语对话语料库的比较细节。
音频对话的专业转录(即演员所说的话)是从 Ubiqus [53] 获得的(示例见表 III)。然后,使用强制对齐来估计单词和音素边界。 使用 Sphinx-III 语音识别系统(3.0.6 版)[40],使用超过 360 小时的中性语音训练传统声学语音模型。 虽然我们没有严格评估对齐结果,但我们的初步筛选表明边界是准确的,尤其是在没有语音的片段中重叠。 了解话语的词汇内容有助于进一步研究手势和语音在语言单位方面的相互作用 [11, 12, 13]。
 表三。 部分自发会话的注释示例(表 I 中的第三种情况)。 该示例包括转弯分割(以秒为单位)、转录、分类情绪评估(三个主题)和属性情绪评估(效价、激活、优势、两个主题)。
表三。 部分自发会话的注释示例(表 I 中的第三种情况)。 该示例包括转弯分割(以秒为单位)、转录、分类情绪评估(三个主题)和属性情绪评估(效价、激活、优势、两个主题)。
5.2. 数据的情感标注
在之前的大部分情感语料库中,都要求受试者表达给定的情感,然后将其用作情感标签。 这种方法的一个缺点是不能保证记录的话语反映目标情绪。 此外,给定的展示可以引发不同的情绪感知。 为了避免这些问题,这个语料库中的情感标签是根据来自主观情绪评估的协议。 为此,人类评估员被用来评估数据库的情感内容。 评估者是说英语的南加州大学学生。
已经提出了不同的方法和注释方案来捕获数据库的情感内容(即 Feeltrace 工具 [24]、上下文注释方案(MECAS)[27])。 对于该数据库,使用了两种最流行的评估方案:基于离散分类的注释(即幸福、愤怒和悲伤等标签)和基于连续属性的注释(即激活、效价和优势)。 这两种方法提供了语料库中观察到的情绪表现的补充信息。
"annotation of video and speak language"工具 ANVIL [43] 被用来促进对语料库的情感内容的评估(见图 5)。请注意,有些情感可以从音频中更好地感知(例如,悲伤),而其他情感来自视频(例如,愤怒)[26]。此外,表达话语的上下文在识别情绪方面起着重要作用 [19]。因此,要求评估者在观看视频后依次评估转弯。 因此,声音和视觉通道以及对话中的先前轮次可用于情绪评估。
在这个评估中做出的一个假设是,在一个回合内,情感内容没有转变(例如,从沮丧到愤怒)。 这种简化是合理的,因为转弯的平均持续时间仅为 4.5 秒。 因此,情感内容预计将保持不变。 请注意,评估人员每回合被允许标记多个情绪类别,以解释情绪的混合(例如,沮丧和愤怒),这在人类交互中很常见 [27]。
分类情感描述符
要求六名人类评估员根据情感类别评估数据库的情感内容。 评估会议的组织方式是由三个不同的评估者评估每个话语。根本原因是为了最大限度地减少对数据库进行初步分析的评估时间。 评估大约 45 分钟的会议。 评估员被指示在会话之间有适当的休息。
如第 3 节所述,该数据库旨在针对愤怒、悲伤、快乐、沮丧和中立状态。 但是,仅用这些情感标签无法充分描述某些句子。 由于互动旨在尽可能自然,因此实验者希望观察到充满兴奋、恐惧和其他广泛的混合情绪的话语,这些情绪在人类自然互动中很常见。 正如Devillers 等人所描述的,情感表现不仅取决于上下文,还取决于人[27]。 他们还指出,在现实生活场景中经常观察到模棱两可的情绪(非基本情绪)。 因此,描述情感是一个固有的复杂问题。 作为简化情感分类中基本问题的一种可能方法,使用一组扩展的类别进行情感评估。 一方面,如果情感类别的数量太多,评估者之间的一致性就会很低。 另一方面,如果情绪列表是有限的,那么对话语的情绪描述就会很差,而且可能不太准确。 为了平衡权衡,选择用于注释的最终情绪类别是愤怒、悲伤、快乐、厌恶、恐惧和惊讶(称为基本情绪 [31]),以及沮丧、兴奋和中性状态。
图 6 显示了用于标记每个转弯的 Anvil 情绪类别菜单。 尽管评估者最好只选择一个选项,但允许他们选择多个情绪标签来解释混合情绪 [27]。 如果可用的情绪类别都不合适,他们会被指示选择其他情绪类别并写下自己的评论。 为简单起见,如果获得最高票数的情感类别是唯一的(请注意,允许评估者标记多个情感类别),则使用多数投票进行情感类别分配。 在这个标准下,评价者在 74.6% 的回合中达成一致(脚本会议:66.9%;自发会议:83.1%)。 请注意,协调主观评估的其他方法也是可能的(例如,基于熵的方法 [51] 和多个标签 [27])。
 图 6. ANVIL 情感类别菜单呈现给评估者以标记每个回合。 评估者可以选择一种以上的情绪并添加自己的评论。
图 6. ANVIL 情感类别菜单呈现给评估者以标记每个回合。 评估者可以选择一种以上的情绪并添加自己的评论。
图 7 显示了数据中情感内容在达成一致的回合中的分布。 这个数字表明 IEMOCAP 数据库表现出目标情绪(快乐、愤怒、悲伤、沮丧和中性状态)的平衡分布。正如预期的那样,语料库中几乎没有其他情绪类别的示例,例如恐惧和厌恶。
 图 7. 每个情绪类别的数据分布。 该图仅包含投票最高类别唯一的句子(Neu = 中立状态,Hap = 幸福,Sad = 悲伤,Ang = 愤怒,Sur = 惊讶,Fea = 恐惧,Dis = 厌恶,Fru = 挫败感, Exc = 兴奋,Oth = 其他)。
图 7. 每个情绪类别的数据分布。 该图仅包含投票最高类别唯一的句子(Neu = 中立状态,Hap = 幸福,Sad = 悲伤,Ang = 愤怒,Sur = 惊讶,Fea = 恐惧,Dis = 厌恶,Fru = 挫败感, Exc = 兴奋,Oth = 其他)。
使用分配的情感标签作为基本事实,估计人类评估中情感类别之间的混淆矩阵。 结果列于表IV。 平均而言,情感类别的分类率为 72%。 该表显示,一些情绪如中性、愤怒和厌恶与沮丧相混淆。 此外,幸福和兴奋之间存在重叠。
 表四。 根据人类评估估计的情绪类别之间的混淆矩阵(Neu = 中性状态,Hap = 快乐,Sad = 悲伤,Ang = 愤怒,Sur = 惊讶,Fea = 恐惧,Dis = 厌恶,Fru = 沮丧,Exc = 兴奋和 Oth = 其他 )。
表四。 根据人类评估估计的情绪类别之间的混淆矩阵(Neu = 中性状态,Hap = 快乐,Sad = 悲伤,Ang = 愤怒,Sur = 惊讶,Fea = 恐惧,Dis = 厌恶,Fru = 沮丧,Exc = 兴奋和 Oth = 其他 )。
为了分析评估者间的一致性,计算了 Fleiss 的 Kappa 统计量 [34](见表 V)。 整个数据库的结果是
κ
\kappa
κ = 0:27。 Fleiss’ Kappa 统计值对于评估者根据前面提到的标准达成一致的轮次的值为
κ
\kappa
κ = 0:40。 由于数据库的情感内容主要跨越目标情感(见图7),在将情感类别聚类为如下。 首先,快乐和兴奋被合并了,因为它们在激活和价域上很接近。 然后,情绪类别恐惧、厌恶和惊讶被重新标记为其他(仅用于本次评估)。最后,其余类别的标签没有被修改。 使用这个新标签,整个数据库的 Fleiss Kappa 统计量和达成一致的转数分别为 = 0:35 和 = 0:48。由于人们有不同的看法和情绪的解释,这些级别的一致性被认为是公平/适度的一致性。这些值与先前工作中报告的类似任务的一致性水平一致 [27, 37, 51]。此外,日常情绪是复杂的,这可能会导致评估者之间的一致性不佳 [29]。
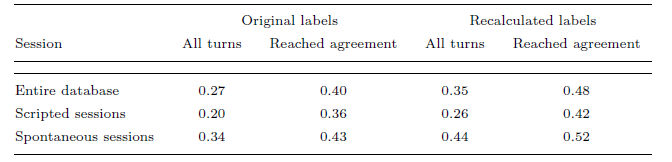
表 V. Fleiss 的 Kappa 统计量来衡量评估者间的一致性。 结果显示为所有轮次和评估者达成一致的轮次
表 V 还提供了脚本化和自发会话的 Fleiss Kappa 统计数据的个别结果。 结果表明,对于自发会议,评估者之间的一致性水平高于脚本会议。 虽然自发会话旨在针对特定的情绪(快乐、愤怒、悲伤、沮丧和中性状态),但脚本会话包括从一种情绪状态到另一种情绪状态的渐进变化,这取决于戏剧的叙事内容。 在会话中,脚本化对话方法通常会引发更广泛的模棱两可的情绪表现。 结果,主观评价的可变性增加,导致评价者间的一致性水平较低。 [16] 中给出了比较脚本化和自发引发方法的进一步分析。
连续情感描述符
描述话语情感内容的另一种方法是使用原始属性,例如效价、激活(或唤醒)和支配地位。 这种方法最近在研究界越来越受欢迎,它提供了对连续空间中受试者的有效状态的更一般的描述。 这种方法对于分析情绪表达的可变性也很有用。 例如,读者可以参考 [22],了解有关如何使用这种方法描述话语的情感内容的更多详细信息。
自我评估模型 (SAM) 用于根据属性效价 [1-阴性,5-阳性]、激活 [1-平静,5-兴奋] 和支配性 [1-弱,5- 强] [33, 37](图 8)。 该方案由每个维度的 5 个数字组成,用于描述属性轴的渐进变化。 评估人员被要求选择更能描述刺激的人体模型,将其映射为 1 到 5 之间的整数(从左到右)。SAMs 系统以前曾用于评估情绪化言语,显示出低标准偏差和高评估者间一致性 [36]。 此外,使用无文本评估方法绕过了每个评估者对他/她对语言情感标签的个人理解的困难。此外,评估简单、快速且直观。
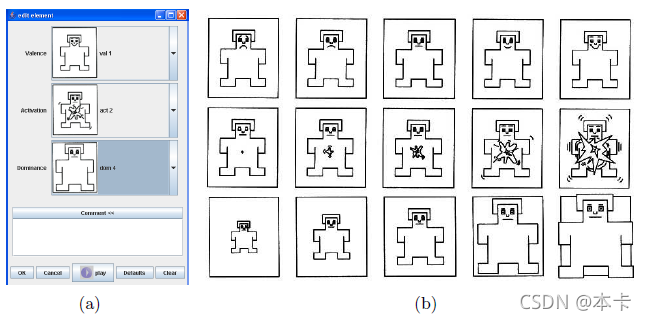 图 8. (a) 向评估者显示的基于 ANVIL 属性的菜单以标记每个转弯。 (b) 自我评估人体模型。 行说明了价(顶部)、激活(中间)和优势(底部)。
图 8. (a) 向评估者显示的基于 ANVIL 属性的菜单以标记每个转弯。 (b) 自我评估人体模型。 行说明了价(顶部)、激活(中间)和优势(底部)。
要求两个不同的评估者使用 SAMs 系统评估语料库的情感内容。 至此,已经评估了大约 85.5% 的数据。 在评分者分配分数后,使用说话人相关的 z 归一化来补偿评估者间的差异。 图 9 显示了 IEMOCAP 数据库的情感内容在效价、激活和支配方面的分布。 直方图类似于在其他自发情绪语料库中观察到的结果 [37])。
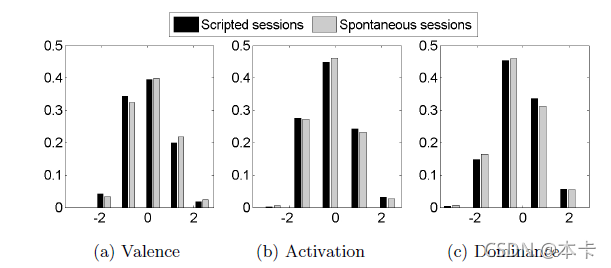 图 9. 语料库情感内容在 (a) 效价、(b) 激活和 © 支配方面的分布。 脚本(黑色)和自发(灰色)会话的结果分别显示。
图 9. 语料库情感内容在 (a) 效价、(b) 激活和 © 支配方面的分布。 脚本(黑色)和自发(灰色)会话的结果分别显示。
计算 Cronbach α 系数以测试两个评估者之间评估的可靠性 [25]。 结果列于表VI中。 该表显示,效价的一致性高于其他属性。
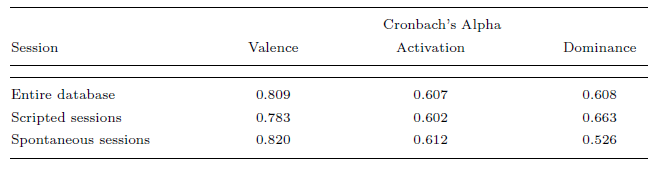
表六:使用 Cronbach α 系数测量的基于属性的评估的评估者间一致性
分类级别不提供有关情绪强度级别的信息。 事实上,标有相同情感类别的情感展示可以呈现截然不同的模式。 因此,拥有两种类型的情感描述提供了关于人们如何表达情感以及如何自动识别或合成这些线索以获得更好的人机界面的互补见解。
5.3. 语料库的自我情绪评估
除了对初级评估者的情绪评估之外,我们还要求参与数据收集的 6 名演员使用分类(即悲伤、快乐)对他们会话的情绪内容进行自我评估 ) 和属性(即激活、效价)方法。 这种自我情绪评估仅在自发/无脚本场景中进行(见第 3.1 节)。 表 VII 将自我评价 (“self”) 的结果与从其他评价者 (“others”) 获得的评价进行了比较。 对于这个表,从多数投票中获得的情感标签被假定为基本事实。 不考虑评估者未达成一致的轮次。结果以分类百分比表示。令人惊讶的是,结果显示,天真的评估者和演员之间的情感感知存在显着差异。 尽管情感标签仅在原始评估者之间达成一致的情况下进行估计 - 因此识别率预计为更高 - 该表表明两种评估之间存在显着差异。

表七。 对自发/无脚本场景(分类评估)的自我评估与他人评估之间的识别率的百分比比较。
结果显示为六位演员(例如,F03 = 第 3 节中的女女演员)。
在我们最近的工作中,我们更详细地研究了评估者之间的评估与评估者之间达成一致的自我评估之间的差异 [14]。 我们通过估计每个评估者被排除在评估之外时可靠性度量的差异,分析了参与者和初级评估者的交叉评估结果。 结果还揭示了情绪的表达和感知之间的不匹配。 例如,发现演员在为他们的回合分配情感标签时更有选择性。 事实上,当自我评价包含在估计中时,kappa 值会下降。 请注意,演员熟悉他们通常如何传达不同的情绪。 与初级评估者不同,他们还了解记录数据库的底层协议。 需要对自我和他人的评估进行进一步分析,以阐明我们表达和感知情绪的方式之间的潜在差异。
5.4. 标记数据的重建
使用VICON iQ 2.5 软件[55] 重建标记的轨迹。 重建过程是半自动的,因为具有标记位置的模板必须手动分配给标记。 此外,当软件无法跟踪标记时,需要监督重建以纠正数据。 当每个标记的连续丢失帧数小于 30 帧(0.25 秒)时,使用三次插值来消除间隙。
不幸的是,一些标记在录制过程中丢失了,主要是因为拍摄对象的突然移动和摄像机的位置。 由于鼓励自然互动,因此当演员进行突然动作时,录制不会停止。相机距离拍摄对象大约一米 成功捕捉录音中的手势。 如果只记录面部表情,则相机必须靠近拍摄对象的面部以提高分辨率。 图 10 显示了标记,其中丢失帧的百分比高于语料库的 1%。 百分比较高的标记与眼睑和手有关。 原因是当受试者睁开眼睛时,眼睑的标记有时会被遮挡。 由于这些标记的目的是推断眨眼,因此缺失的标记也是推断受试者眨眼时间的有用信息。 手标记的主要问题是手之间的自我遮挡。
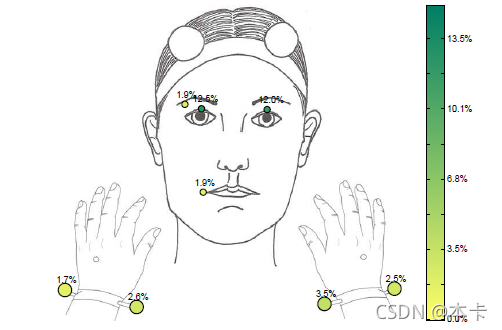 图 10. 记录过程中丢失的标记百分比。 该图仅显示缺失值超过 1% 的标记。 深色表示更高的百分比。
图 10. 记录过程中丢失的标记百分比。 该图仅显示缺失值超过 1% 的标记。 深色表示更高的百分比。
在捕捉到运动数据后,所有的面部标记都被平移,在每一帧的局部坐标中心做一个鼻子标记,消除任何平移效应。 之后,帧乘以旋转矩阵,以补偿旋转效应。 该技术基于奇异值分解 (SVD),最初由 Arun 等人提出[3]。 这种方法的主要优点是每个标记的 3D 几何形状用于估计帧和参考帧之间的最佳对齐。 它对标记的噪声具有鲁棒性,其性能克服了使用少量“静态”标记来补偿头部运动的方法。
在该技术中,为每一帧构建旋转矩阵如下:选择每个对象的中性面部姿势作为参考帧,用于创建 53*3 矩阵 Mref ,其中
M
r
e
f
M_{ref}
Mref 的行具有 标记的 3D 位置。 对于帧
M
t
M_{t}
Mt,通过遵循相同的标记创建了一个类似的矩阵
M
r
e
f
M_{ref}
Mref订单作为参考。 之后,计算矩阵
M
r
e
f
T
∗
M
t
M^T_{ref}* M_t
MrefT∗Mt 的SVD,
U
D
V
T
UDV^T
UDVT 。 最后,
V
U
T
VU^T
VUT 的乘积给出了框架
t
t
t [3] 的旋转矩阵
R
t
R_t
Rt。
M
r
e
f
T
M
˙
t
=
U
D
V
T
M_{ref}^T\dot M_t = UDV^T
MrefTM˙t=UDVT
R
t
=
V
U
T
R_t = VU^T
Rt=VUT
来自头带的标记用于确保头部运动估计的良好准确性。 在补偿了平移和旋转效应之后,帧之间的剩余运动对应于标记的局部位移,这在很大程度上定义了主体的面部表情。
6. 讨论
6.1. IEMOCAP 数据库:优点和局限性
如第 2 节所述,Douglas-Cowie 等定义了在数据库设计中需要考虑的四个主要问题:范围、自然性、上下文和描述符 [29]。 在本节中,IEMOCAP 数据库将根据这些问题进行讨论。
范围:尽管 Douglas-Cowie 等人建议的主题数量大于 10 [28],但该数据库中使用的数字可能是得出有关人际差异的有用结论的充分初始步骤。 拥有来自十个发言者的这种综合数据标志着人类表达性交流(例如设备、标记、模态数量)研究中的一小步,但希望是重要的一步。 详细的动作捕捉信息对于更好地理解人类交流方式中的联合作用非常重要,例如面部表情、头部运动和手部运动以及语言行为。 此外,十二小时的多模态数据将为训练强大的分类器和情感模型提供合适的起点。
自然性:正如 Douglas-Cowie 等人所提到的,自然性的代价是缺乏控制 [28]。 动作捕捉系统的使用对自然人类交互的记录施加了更大的限制。 在这个语料库中,试图通过选择合适的材料来在二元交互中引发情绪来平衡这种权衡。 一方面,语言和情感内容是通过使用脚本(用于戏剧)来控制的。 另一方面,预计在这种社会环境下,真正的认识可以观察到在独白或阅读语音语料库中未观察到的情绪。 根据[28],这个数据库将被标记为半自然,因为演员被用于录音,他们可能会夸大情绪的表达。 然而,基于用于引发情绪的设置和所取得的结果,我们认为该数据库的情绪质量比先前引发设置的情绪质量更接近自然。 正如 Cowie 等人所建议的,我们计划通过进行主观评估来评估语料库的自然性 [23]。
上下文:许多现有情感数据库的问题之一是它们只包含孤立的句子或简短的对话 [28]。 这些设置删除了话语上下文,这是众所周知的重要组成部分 [19]。 在这个语料库中,对话的平均持续时间约为 5 分钟,以便将情绪的迹象和流向情境化。 由于材料是从对话的角度适当设计的,情绪是在适当的背景下引发的。 情感评价也是在上下文中观看句子后进行的,以便评价者可以根据对话的顺序发展来判断情感内容。
描述符:语料库中考虑的情绪类别提供了数据库中观察到的情绪内容的合理近似值。 这些情绪是以前数据库中最常见的类别。 此外,添加基于原始的注释(效价、激活和优势)通过捕获情感表现的补充方面(即强度和可变性)改进了对收集的语料库的情感描述。 最后,通过数据库音频部分的详细语言转录,可以结合非语言线索从各种语言层面分析情感内容。
总之,IEMOCAP 是精心设计的,以满足第 2 节中提出的关键要求。因此,该数据库解决了现有情感数据库的一些核心限制。
6.2. 适合使用IEMOCAP数据库查询的开放式问题
IEMOCAP 语料库可以在表达性人类交流的研究中发挥重要作用。 在本节中,将讨论可以使用该语料库解决的一些开放性问题。
使用 IEMOCAP 数据库,可以分析来自不同主题的手势和语音,以建立个人风格。 例如,通过学习人际相似性,可以设计独立于说话者的情绪识别系统(例如,为在说话者之间情感上显着的特征 [10])。 通过使用基于人际差异的模型,可以生成具有特定个性的类人面部动画[4]。
该语料库适用于研究情绪的动态进展(尤其是自发场景)。 由于每个句子都经过情感评估,因此研究受试者何时从一种情感转变为另一种情感以及此类视听指标的性质将很有趣。 从应用的角度来看,这是一个有趣的问题,因为检测用户何时改变他/她的有效状态可以用来改进人机界面。
该语料库可以研究高级语言功能和手势之间的关系。 例如,可以对作为话语功能生成的手势进行建模(例如,点头表示“是”)以改善面部动画 [18]。这些基于话语的模型可以与我们的自然头部运动框架结合以合成头部运动序列 响应所讲内容的潜在语义内容 [8, 7]。由于数据包含自发对话和详细的标记信息,因此该语料库适合解决此类问题。
该数据库还可用*于研究面部哪些区域用于以动态方式调节说话者的有效状态 *[9, 11]。 虽然面部信息是从动作捕捉系统中获得的,但我们希望分析这些数据的结果可以指导自动多模态情感识别系统的设计。
IEMOCAP 数据库是为两人对话而设计的。因此,适合扩展二元相互作用的分析。积极的听众会以非语言手势做出回应,这是互动的重要组成部分。 这些手势出现在说话者的话的特定结构中 [30]。 这意味着主动说话者的语音与听者的手势相关联,可以利用它来改进人机界面(例如,Virtual Rapport [35])。 我们也有兴趣分析一个主体的手势对另一个主体的行为的影响。 例如,该语料库对于分析在竞争和合作中断期间观察到的多模态线索特别有用 [45]。 随着人机界面的进步,这些研究将在对话理解和用户建模方面发挥重要作用。
这些是我们计划在以 IEMOCAP 数据库为基石资源的未来研究中探索的一些问题。
7. 结论
本文提出了交互式情感二元动作捕捉数据库(IEMOCAP)作为扩展人类表达交流领域研究的潜在资源。 该语料库为头部、面部以及在某种程度上提供二元交互中的手的详细动作捕捉信息。 总共有 10 位演员录制了三个选定的剧本,以及旨在引发特定情绪(幸福、悲伤、愤怒和沮丧)的虚构场景中的对话。 由于情绪是在话语上下文中引发的,与之前的行为语料库引发技术相比,该数据库提供了更自然的表达交互的实现。 该数据库可以在理解和建模表达性人类交流中使用的不同交流渠道之间的关系方面发挥重要作用,并有助于开发更好的人机界面。
致谢
这项工作得到了美国国家科学基金会 (NSF)(通过综合媒体系统中心、NSF 工程研究中心、第 EEC9529152 号合作协议和 CAREER 奖)、陆军部和一个 CAREER 奖的部分资金支持。 海军研究办公室 MURI 奖。 本文中表达的任何意见、发现和结论或建议均为作者的观点,并不一定反映资助机构的观点。 作者感谢 Joshua Izumigawa、Gabriel Campa、Zhigang Deng、Eric Furie、Karen Liu、Oliver Mayer 和 May-chen Kuo 的帮助和支持。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 27
27 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)