
Image Caption 2021最新整理:数据集 / 文献 / 代码
文章目录
引言
最近在调研image caption相关文献,这里主要整理下当前主要的数据集,借此了解下这个任务的技术现状。
image caption是指用自然语言描述图像中的视觉内容的任务,通常采用一个视觉理解系统和一个能够生成有意义的、语法正确的句子的语言模型(describing images with syntactically and semantically meaningful sentences.)。常被称为看图说话、图像描述、图像字幕等。
Image caption任务的目标是找到最有效的pipeline来处理输入图像,表示其内容,并通过在保持语言流畅性的同时生成视觉和文本元素之间的连接,将其转换为一组单词序列1。
数据集概览
早期的image caption主要采用Flickr30K和Flickr8K数据集,这个数据集图片来源于Flickr网站。
目前比较常用的数据集是COCO Captions、Conceptual Captions (CC),包含人、动物和普通日常物品之间的复杂场景的图像。
COCO Captions、Conceptual Captions (CC)、VizWiz、TextCaps、Fashion Captioning、CUB-200等数据集的标注样例如下图(a)所示,数据集中语料库的高频词云如下图(b)所示1,可以反映数据集中主要目标类别的分布。

标注方式
COCO Captions、Conceptual Captions (CC)数据集中对图像描述的标注,是基于整幅图像的。Flickr30K Entities标注了Flickr30K中caption里提到的名词,并标注了对应的bbox。Visual Genome数据集提供了描述图像中区域的短语,并使用这些区域来生成一个场景图(scene graph)。Localized Narratives为每个单词都提供了基于其跟踪片段所表示的图像中的一个特定区域,包括名词、动词、形容词、介词等。2


Microsoft COCO Captions
Microsoft COCO Captions: Data Collection and Evaluation Server
[website]
[paper]
[github] 提供评估方法
COCO Captions更关注“描述场景的所有重要部分”,而不描述不重要的细节,这使得COCO Captions对于关注的对象更突出。
- 164,062张图像,包括:
- 82,783个训练图像
- 40,504个验证图像
- 40,775个测试图像
- 995,684个captions,平均每张图片6个captions
- 标注内容:
- 描述这个场景的所有重要部分;
- 不描述不重要的细节。
- 不要描述在未来或过去可能发生的事情。
- 不描述一个人可能会说什么。
- 不提供专有的人名。
- 这些句子应该至少包含8个单词。

SBU Captions
NIPS 2011 | Im2Text: Describing Images Using 1 Million Captioned Photographs
[website]
[paper]
SBU Captions数据集最初将图像字幕作为一个检索任务,包含 100 万个图片网址 + 标题对。

Conceptual Captions (CC) dataset
Conceptual Captions (CC) dataset是一个包含(图像URL、字幕)对的数据集,用于机器学习图像字幕系统的训练和评估。数据集有约330万张图像(CC3M)和1200万张图像(CC12M)两个版本,并通过一个简单的过滤程序从网络自动收集弱相关描述。
与 MS-COCO 图像相比,Conceptual Captions数据集的图像及其原始描述来自网络,因此代表了更广泛的风格。
但是Conceptual Captions 的图像并不总是可用的,因为数据集提供的是图片URL。
| Split | Examples | Uniqe Tokens |
|---|---|---|
| Train | 3,318,333 | 51,201 |
| Valid | 15,840 | 10,900 |
| Test (Hidden) | 12,559 | 9,645 |

TextCaps
这个数据集的特点在于使用包含文字内容的图片。
TextCaps 要求模型阅读和推理图像中的文本以生成有关它们的说明。具体来说,模型需要根据图像中存在的文本形式对其进行推理,并结合图像中的视觉内容以生成图像描述。
- 28,408 张图片,来自 Open Images 数据集
- 142,040 条captions
- 平均每张图片 5 个captions

VizWiz-Captions
ECCV 2020 | Captioning Images Taken by People Who Are Blind.
[paper]
[website]
这个数据集中的图像是由视力受损的人使用手机拍摄的,图像质量不高,涉及各种各样的日常活动,其中大多数需要阅读一些文本。数据集旨在让更多人了解盲人的需求,并开发辅助技术,解决盲人日常生活中的视觉挑战,回答盲人的视觉问题。
数据集引入了视力受损的人采集的39,181张真实图像用例,每张图像都配有5个captions。
VizWiz-Captions 数据集包括:
- 训练集:23,431 张图像,117,155 个captions
- 验证集:7,750 张图像,38,750 个captions
- 测试集:8,000 张图像,40,000 个captions

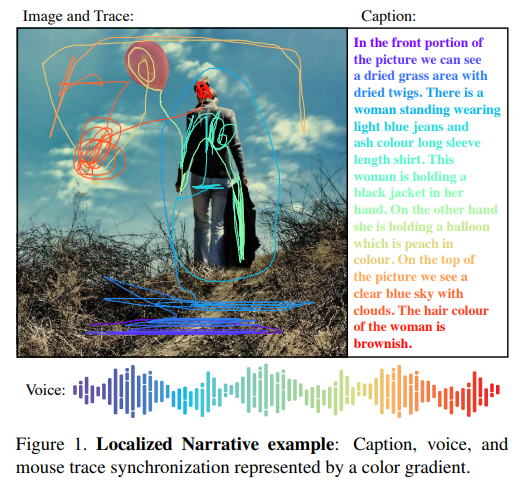
Localized Narratives
ECCV 2020 | Connecting Vision and Language with Localized Narratives
[website]
[paper]
[code]
Localized Narratives提供了一种连接视觉和语言的多模态图像注释的新形式。这个数据集是通过记录人们自由地叙述他们在图片中看到的内容而收集起来的。
注释者被要求用他们的声音描述图像,同时将鼠标悬停在他们描述的区域上。由于语音和鼠标指针是同步的,我们可以定位描述中的每个单词。这种密集的视觉基础采用每个单词的鼠标轨迹段的形式。
Localized Narratives为每个单词都提供了基于其跟踪片段所表示的图像中的一个特定区域,包括名词、动词、形容词、介词等。

Localized Narratives 注释了 849,000张图像:包括整个 COCO、Flickr30k 和 ADE20K 数据集,以及 671,000 的Open Images图像。
Localized Narratives支持的任务不局限于image caption,还可以支撑其他多模态任务:

Nocaps
ICCV 2019 | nocaps: novel object captioning at scale
[website]
[paper]
[github]
nocaps旨在评估在没有对应的训练数据的情况下,模型能否准确描述测试图像中新出现类别的物体。
为了让模型能够学习更多种类的视觉概念,最好是从较少的监督中学习。所以,nocaps利用一些替代数据源(如目标检测),使模型能够描述在训练集的标题语料中不存在的对象。这些具有目标检测标注、但没有标题语料的对象,就被称为新对象(novel object),描述那些包含新对象的图像就被称为novel object captioning。
对于人类来说,在学习了一个新物体的类别后,我们可以立即描述它的属性和关系,但是当前的算法模型无法描述未在语料库中出现过的目标。nocaps的主要目标是将“如何识别物体”与“如何谈论物体”分离出来。利用COCO的图像标题数据来学习生成语法上正确的标题,同时利用大量的开放图像检测数据集来学习更多的视觉概念。
- 训练集由 COCO 图像-标题对(118,000张图像,80个目标类别)、Open Images V4 目标检测训练集(1,700,000张带有bbox的图像,600个目标类别)组成。
- 验证集包含4,500张图像,平均每张图片10个captions,源自 Open Images V4验证集
- 测试集包含10,600张图像,平均每张图片10个captions ,源自 Open Images V4测试集
- 由于 Open Images 包含的类比 COCO 多得多,因此在测试图像中看到的近 400 个目标类没有对应的训练caption(所以这个数据集取名为nocaps)。
- 为了提供更细粒度的分析,nocaps的评估分为域内、近域和域外三个子集,域描述了对象与COCO中类别的相似性。

小结
当前caption任务的数据集正在向多种领域进行扩展,更多的开放式图像、目标类别,较少的监督信息,对image caption任务提出了更高要求。
在具体实际应用中,既需要特定领域的语料库,也需要模型具备更好的可解释性。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐
 46
46 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)