
HuggingFace的Transformers库Tokenizer和Model使用技巧
Bert模型作为一个强大的双向Transformer模型,已经在NLP领域广泛使用并作为word embeddding 预训练模型深受青睐。Hugging Face的transformers框架包含BERT、GPT、GPT2、ToBERTa、T5等众多模型,同时支持pytorch和tensorflow 2两个框架,本博客主要介绍如何从Hugging Face加载预训练模型及高效使用。
引 言:
Hugging Face作为强大的NLP任务处理工具,包含transformers、datasets、tokenizers、 accelerate四个基础python库。其中的transformers库共享了BERT、GPT系列模型、T5等众多处理能力超强的模型,同时支持模型在pytorch和tensorflow两种框架上使用。Transformers库如此强大作为一个要在深度学习领域遨游的小白,需要对该库的常见使用技巧深谙于心。本博客先简单介绍transformers库,随后着重从技术方面介绍如何从Hugging Face加载预训练模型及常规使用技巧。
目录
3.1 tokenize函数+convert_tokens_to_ids函数
3.2 encode()、encode_plus()和直接调用tokenizer对象
3.3.2 add_tokens([new_vocab])函数
3.3.3 add_special_tokens()函数添加特殊占位符号
一、Transformers库简介
Transformers库提供了多种预训练模型,用户可以按照自身任务需求从Model hub上下载部署模型。创建huggingface账号后还可以上传自身设计的模型和数据集。Transformers库中的每个预训练模型由一个独立文件夹封装,各模型之间解耦相互不受影响。模型的每层功能由一个函数完成方便用户操作。为让初学者更直观地了解transformers库中模型强大的功能列举官方文件展示的一个执行情感分类任务的pipeline。在pycharm软件中使用huggingface库中的这些组件库需用pip或者conda包管理器安装。
#基础包安装命令
pip install transformers datasets tokenizers acceleratefrom transformers import pipeline
# Allocate a pipeline for sentiment-analysis
classifier = pipeline('sentiment-analysis')
classifier('We are very happy to introduce pipeline to the transformers repository.')
[{'label': 'POSITIVE', 'score': 0.9996980428695679}]Transformers库当中的模型按照使用结构及擅长处理的任务划分为以下三类:
- 只包含编码器的模型:常用模型BERT、RoBERTa等,擅长自然语言理解任务(nature language understanding),例如文本分类、命名实体识别、抽取式问答。编码器输入添加噪声的完整文本(随意遮挡部分单词)后模型预测掩盖的单词,这种模型也常称为MLM(mask language model)。
- 只包含解码器的模型:典型代表GPT系列模型,擅长自然语言生成任务,例如文本生成。在解码器中输入给定单词之前所有单词的编码,上一轮生成的文本数据作为新一轮的输入文本数据无需添加额外的标注数据,该类模型常称为自回归模型。
- 包含编码器和解码器模型(序列到序列seq2seq):常用模型BART、T5等,擅长给定输入条件的文本生成任务,例如翻译、摘要、生成式问答。
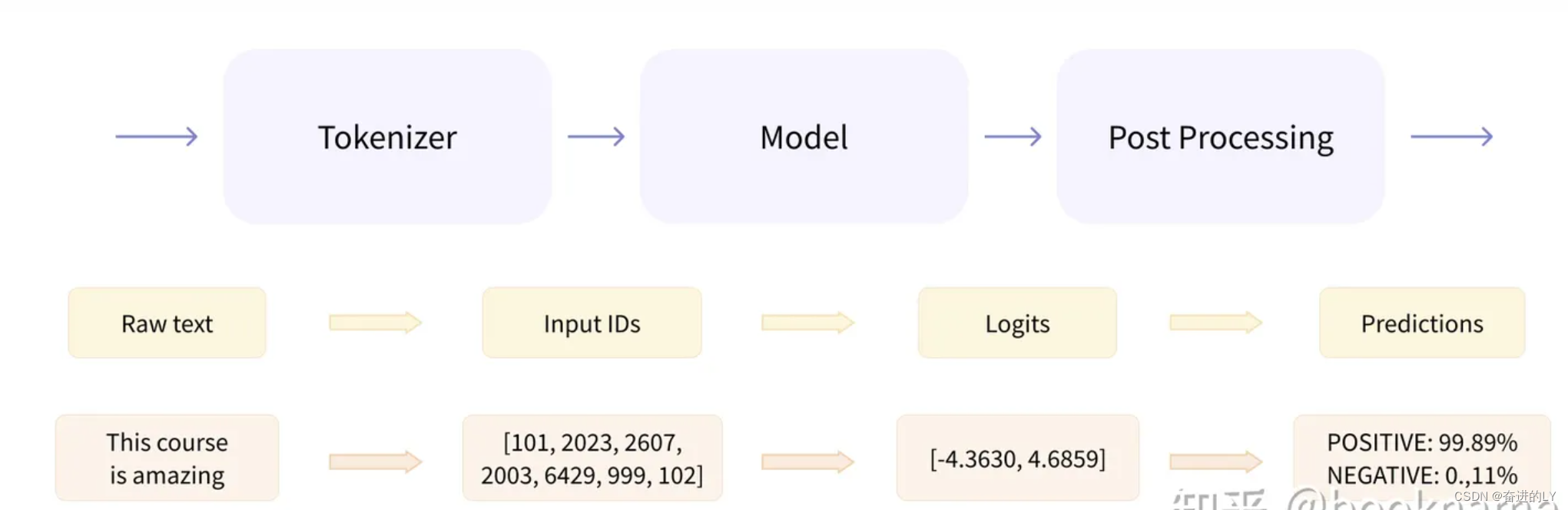
上文代码展示的pipeline其实已经将数据预处理、模型训练输出和后处理等过程进行封装。Tokenizer就是把输入的文本做切分然后变成向量,Model负责根据输入向量提取语义信息,输出logits,Post Processing利用模型输出的结果执行具体的nlp任务比如情感分析等。要想得心应手的使用huggingface库需要了解各组成部分处理流程和常用API接口,处理流程图展示如下(来源链接)。下文将逐步介绍每一部分处理流程。
二、 加载分词器和预训练模型
2.1 模型checkpoint名称加载
在Hugging Face网站上查找需下载模型对应的checkpoint名称,在 from_pretrained() 函数中指定checkpoint名称,函数运行时根据checkpoint自动实现预训练tokenizer和model的加载,不足之处是下载速度较慢甚至无法下载,使用者要学会科学上网。Modal和Tokenizer相当于框架类需与函数传入的检查点名称类型匹配,分词器前缀与模型类前缀必须一致如xxxTokenizer和xxxModel。也可使用AutoTokenizer和AutoModel加载预训练权重,系统会根据传入的检查点动态绑定加载的具体模型类和分词器类。
from transformers import BertTokenizer,BertModel
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
2.2 模型文件路径加载
直接从Hugging Face网站将预训练模型需要的相关文件下载到本地文件夹,利用from_pretrained()函数完成模型加载工作。具体操作流程展示虽然繁琐但方便日后回顾。
首先,在网站链接的搜索栏中输入需要加载的模型名称。
https://huggingface.co/![]() https://huggingface.co/
https://huggingface.co/
其次,点击Files and versions将config.json和vocab.txt文件和模型文件(若是pytorch框架选择pytorch_model.bin文件,若是tensorflow2.0选择tf_model.h5)下载到本地计算机需放入同一个文件夹中。
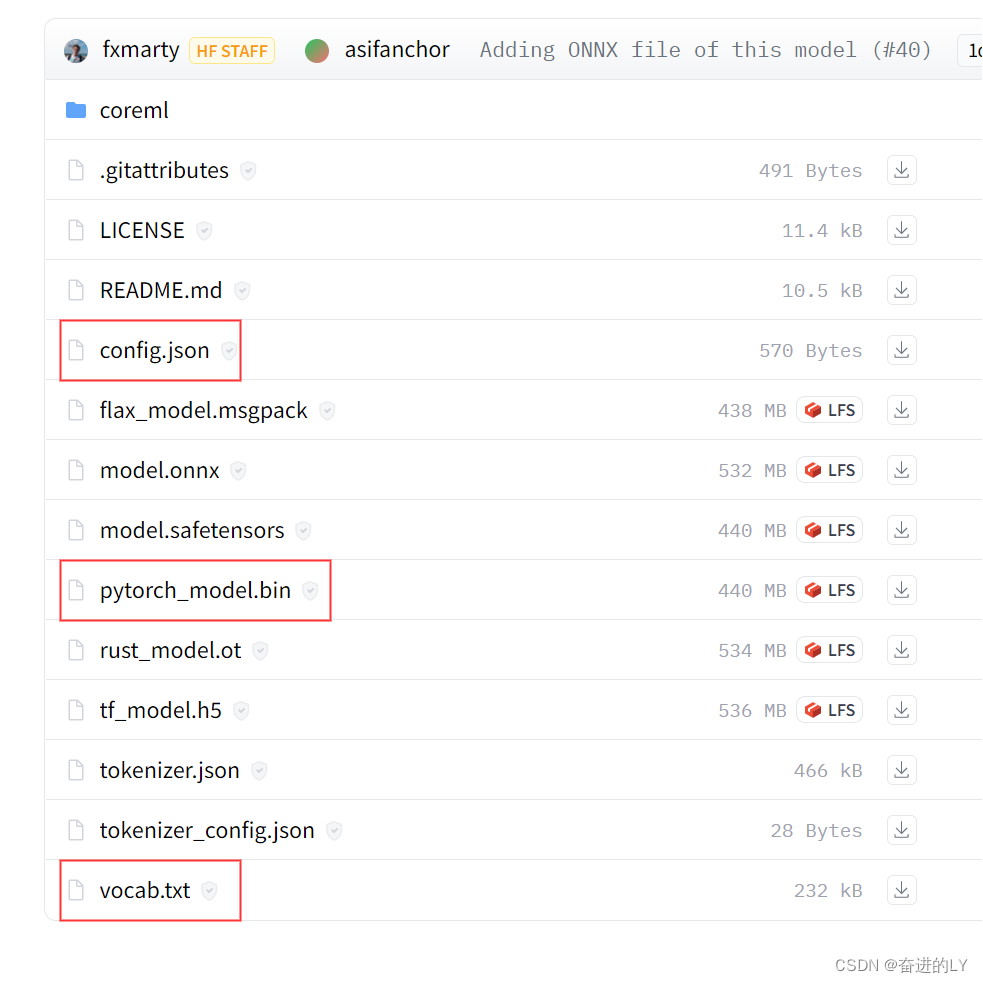
最后,文件夹的绝对路径或相对路径作为实参传递给函数from_pretrained(),于此同时可以在from_pretrained函数中设置参数cache_dir指向模型缓存路径。(只会下载一次,后续再执行from_pretrained()函数都会直接加载缓存的模型)
from transformers import BertTokenizer,BertModel
path = './bert-base-uncased'
tokenizer =BertTokenizer.from_pretrained(path)
model = BertModel.from_pretrained(path)三、 BertTokenizer的使用
BertTokenizer主要实现文本分词和把分词后的token编码成符合模型输入要求的整数索引功能。 为满足不同预训练模型对文本序列的要求,BertTokenizer还会自动在文本序列中添加一些额外符号([CLS]、[SEP]、[PAD])等。
BertTokenizer类包含三个文件:vocab.txt,tokenizer.json和tokenizer_config.json
vocab.txt是词表文件(文件中是保留符号和单个汉字索引,字符),每个token在词表中都有唯一的ID号。不同模型的词表文件会因为设置的规则不同导致内容不同,所以相同的文本序列调用不同模型的tokenizer会产生不同的整数索引。预训练模型与tokenizer必须使用相同的vocab文件和配置文件才能使输入文本序列满足模型的输入要求。
tokenizer.json和tokenizer_config.json是分词的配置文件,根据设置文件把vocab词表中的词按顺序生成索引号(行号-1就是索引号),模型根据词对应的索引号编码生成one-hot向量与Bert中的nn.embeding训练权重矩阵相乘获得该字符的随机词向量。(简单说就是token根据词表中单词对应的索引编号查找Embedding.weight的随机初始化的词向量表生成模型可训练的词向量。Bert与word2vec、glove等词嵌入向量获取方式不同,word2vec、glove属于静态查表法,输入一个单词就输出一个token向量,不考虑语义相似性,e.g.,热狗和养条狗虽然都有汉字狗但语义不同,Bert则需要输入完整语句后,结合上下文信息生成具有语义信息的狗字。)
BertTokenizer模块会生成mask码和token_type_ids码用于不同预训练模型的不同任务。mask码确定文本序列中有效token位置,避免注意力计算时填充字符地参与,实际存在token位置标记为1,填充位置标记为0。下文会有单独部分演示注意力掩码的作用。生成的token_type_ids确定成对输入句子中token字符分别隶属于那个句子,第一句话的token为0第二句话的token为1,主要用于句子拼接任务,e.g.,文本蕴含任务。BertTokenizer使用方式很多,主要介绍几种常见方式,结合函数运行解释分词器的使用机理。
tokenizer主要完成的工作:
1.分词:将文本数据分词为字或者字符;
2.构建词典:根据数据集分词的结果,构建词典。(这一步并不绝对,如果采用预训练词向量,词典映射要根据词向量文件进行处理)。
3.数据转换:根据构建好的词典,将分词处理后的数据做映射,将文本序列转换为数字序列。数字序列还要变成符合模型需求的tensor格式。
4.数据填充与截断:在以batch输入到模型的方式中,需要对过短的数据进行填充,过长的数据进行截断,保证数据长度符合模型能接受的范围,同时batch内的数据维度大小一致,否则无法成批次变成tensor张量。
3.1 tokenize函数+convert_tokens_to_ids函数
BertTokenizer的tokenize()函数只是对文本简单分词没有实现整数编码功能,Tokenizer的分词方式分为基于单词、基于字符和基于子词的方式。
基于单词的分词器会根据空格或标点符号将文本分割为一个个单词也成为token或者标记,分词后会形成一个体量庞大的词表(语料库中所有单词构成的集合)。词表中单词之间缺乏相关性,例如run和runs在词表中会被认为是两个语义不相关词语。庞大的词表会增加softmax()函数的计算复杂度。对于词表中没有的词语使用[UNK]或""来表示。如果编码序列中有多个[UNK]会影响文本特征的表达。 (模型的词表就是加载预训练model和tokenizer文件夹下的vocab.txt文件)
基于字符的分词方式所需词表虽然小,生成的编码序列中[UNK]数量少,但是分割后的序列中token数量太多。基于字符的分词方式每个token表达的语义信息不足。
基于子词的分词方式将单词分割为多个子词,例如tokenization”被分割成“token”和“ization”,两个token可以很好地表示“tokenization”的语义(仅仅两个token就可以表示一个较长的单词)。这种方法即可以得到较小尺寸的词典,同时[UNK]数量也相对更少。
convert_tokens_to_ids()函数对分词后的token进行整数编码。为什么要进行整数编码?文本序列分词后的每个token还是人可以识别的单词或者字符而模型是无法识别的,只有通过nn.Embedding层将token变成一维词向量后才能被模型使用,Embedding层的输入要求必须为整数索引号。
这种方法运行结果的文本编码序列没有分类符号[CLS]和语句分割符号[SEP]的编码101和102。要想满足BERT模型输入要求还需在输入文本部分人为拼接模型所要求的特殊符号。
txt = '这是一个美丽的城市'
ckpt = r'.\ConvAdapter\vocab\bert\chinese_roberta_wwm_base_ext_pytorch'
tokenizer =BertTokenizer.from_pretrained(ckpt)
token_ids = tokenizer.tokenize(txt)
print(token_ids)
#['这', '是', '一', '个', '美', '丽', '的', '城', '市']
input_ids = tokenizer.convert_tokens_to_ids(token_ids)
print(input_ids)
#[6821, 3221, 671, 702, 5401, 714, 4638, 1814, 2356]
#txt = '[CLS]'+txt+'[SEP]' 手动添加分类符号和间隔符号,然后调用以上程序
#[101, 6821, 3221, 671, 702, 5401, 714, 4638, 1814, 2356, 102]
#生成mask
mask = [1]*len(input_ids)+[0]*(20-len(input_ids))
print(mask)
#[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0]3.2 encode()、encode_plus()和直接调用tokenizer对象
BertTokenizer中的encode()方法完成分词和整数编码的同时,系统对文本序列自动添加分类符和间隔符。如果想要编码输出不携带[CLS]和[SEP],可以设置add_special_tokens=False。方法默认返回的是一个整数索引号列表,而模型的输入必须是张量,所以编码序列在输入模型前需变成pytorch框架或tensorflow框架的张量。encode()函数提供了设置输出张量的return_tensors属性。在函数实参传递过程中不设置return_tensors属性时函数返回值为列表,设置return_tensors='pt'返回值为pytorch的tensor张量,设置为'tf'返回tensorflow张量。encode()不会生成mask和token_type_ids,使用时需编写函数生成对应码。
txt = '这是一个美丽的城市'
ckpt = r'.\ConvAdapter\vocab\bert\chinese_roberta_wwm_base_ext_pytorch'
tokenizer =BertTokenizer.from_pretrained(ckpt)
######encode函数######
input_ids = tokenizer.encode(txt,max_length=20,add_special_tokens=True,
padding='max_length', truncation=True)
print(input_ids)
#返回一个list
#[101, 6821, 3221, 671, 702, 5401, 714, 4638, 1814, 2356, 102, 0, 0, 0, 0, 0, 0, 0, 0, 0]
#将input_ids从列表变成符合模型输入需求的tensor
input_ids = torch.LongTensor(input_ids)
print(input_ids)
#tensor([[ 101,6821,3221,671,702,5401,714,4638,1814,2356,102,0,0, 0, 0, 0, 0, 0, 0, 0]])
##直接设置函数属性值return_tensor,返回值为pytorch的tensor
input_ids = tokenizer.encode(txt,max_length=20,add_special_tokens=True,
padding='max_length', truncation=True,return_tensors='pt')
#tensor([[ 101,6821,3221,671,702,5401,714,4638,1814,2356,102,0,0, 0, 0, 0, 0, 0, 0, 0]])
encode_plus()方法返回的是一个字典包括input_ids(整数编码), attention_mask(有单词对应为1,无单词对应为0)和 token_type_ids(属于同一句话的单词下标相同)。输入模型前也需要像encode()函数设置return_tensors属性将文本序列变成张量。
txt = '这是一个美丽的城市'
ckpt = r'.\ConvAdapter\vocab\bert\chinese_roberta_wwm_base_ext_pytorch'
tokenizer =BertTokenizer.from_pretrained(ckpt)
######encode_plus函数######
results = tokenizer.encode_plus(txt,max_length=20,add_special_tokens=True,
padding='max_length', truncation=True)
print(results)
#返回一个字典
#{'input_ids': [101, 6821, 3221, 671, 702, 5401, 714, 4638, 1814, 2356, 102, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0]}
######直接使用tokenizer######
results = tokenizer(txt,max_length=20,add_special_tokens=True,
padding='max_length', truncation=True)
print(results)
#返回一个字典
#{'input_ids': [101, 6821, 3221, 671, 702, 5401, 714, 4638, 1814, 2356, 102, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0]}
其实上面讲解的encode函数内部调用的也是encode_plus函数,函数返回值取字典的input_ids部分,可以用Tab键+鼠标左键点击encode函数名进入源码文件查看源码,源码展示如下。
def encode(
self,
text: Union[TextInput, PreTokenizedInput, EncodedInput],
...
) -> List[int]:
encoded_inputs = self.encode_plus(
text,
...
)
return encoded_inputs["input_ids"]直接调用tokenizer对象结果与encode_plus相同,生成的编码序列通过解码函数变成字符后,我们可以发现两个句子拼接格式为[CLS]句子1[SEP]句子2[SEP],token_type_ids的表示将两个句子分成“[CLS]句子1[SEP]”和“句子2[SEP]”两部分。 在问答、多选和句子相似性判断等双语句任务中token_type_ids字段在任务处理过程中有着非常重要的作用。decode函数和convert_ids_to_tokens函数都是将编码转换成字符,区别是decode函数返回值是字符串,convert_ids_to_tokens函数返回值是字符列表。变成字符串时想去掉系统添加的符号可以设置skip_special_tokens=True。批量文本编码变成字符串要调用batch_decode函数。
####输入文本序列为两句话####
sent1 = '这是一个美丽的城市'
sent2 = '我们在城市中幸福的生活'
inputs = tokenizer(sent1,sent2)
print(inputs)
###token_type_ids:第一句话对应的token位置标志为0,第二句话为1
{'input_ids': [[101, 6821, 3221, 671, 702, 5401, 714, 4638, 1814, 2356, 102, 2769, 812, 1762, 1814, 2356, 704, 2401, 4886, 4638, 4495, 3833, 102]],
'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]],
'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]}
###convert_ids_to_tokens函数返回字符列表
output_tokens = tokenizer.convert_ids_to_tokens(inputs['input_ids'])
print(output_tokens)
['[CLS]', '这', '是', '一', '个', '美', '丽', '的', '城', '市', '[SEP]', '我', '们', '在', '城', '市', '中', '幸', '福', '的', '生', '活', '[SEP]']
###decode解码返回字符串
out = tokenizer.decode(inputs.input_ids)
print(out)
[CLS] 这 是 一 个 美 丽 的 城 市 [SEP] 我 们 在 城 市 中 幸 福 的 生 活 [SEP]
###decode解码设置不显示系统添加特殊符号
out = tokenizer.decode(inputs.input_ids,skip_special_tokens=True)
print(out)
这 是 一 个 美 丽 的 城 市 我 们 在 城 市 中 幸 福 的 生 活
3.3 添加未知词或未知符号
3.3.1 直接修改词表
tokenizer分词时遇到一些生僻词会造成分词错误例如covid,通过观察发现该分词器采用的是基于子词的分词方式,将生僻词拆解的主要原因是词表中没有该词语,要想分词正确,需要将陌生词添加到词表中。找到加载预训练模型ckpt所在文件夹下的vocab.txt文件,修改前100行[unused]当中的某一行,直接将陌生词添加即可,缺点是添加词语数量有限。
result = tokenizer.tokenize('COVID')
print(result)
#['co', '##vi', '##d']
3.3.2 add_tokens([new_vocab])函数
调用add_tokens()函数添加新词,函数返回值为新添加词数量。
num_added_toks = tokenizer.add_tokens('COVID')
print(num_added_toks)
# num_added_toks表示新添加词汇数量
result = tokenizer.tokenize('COVID')
print(result)3.3.3 add_special_tokens()函数添加特殊占位符号
文本中添加特殊占位符后,tokenizer分词时经常将特殊符号拆解,程序展示如下将<doc>拆解为三部分。要想不拆解自己构建的特殊符号,需调用add_special_tokens()添加特殊占位符字典。
txt = '这是一个美丽的城市<doc>'
tokens = tokenizer.tokenize(txt)
print(tokens)
#['这', '是', '一', '个', '美', '丽', '的', '城', '市', '<', 'doc', '>']add_special_tokens()函数中传递的实参是一个字典,字典的key值必须是函数注释文档中所列举的有效关键字。
txt = '这是一个美丽的城市<doc>'
special_tokens_dict={'additional_special_tokens':['<doc>']}
num_added_toks = tokenizer.add_special_tokens(special_tokens_dict)
tokens = tokenizer.tokenize(txt)
print(tokens)
#['这', '是', '一', '个', '美', '丽', '的', '城', '市', '<doc>']本章节最后对tokenizer主要流程总结如下:批量文本序列分词,token查词表结合模型规则变成整数id,对多个token序列进行补齐或截断,结果列表转换成框架张量。
四、BertModel的使用
BertModel模型的输入必须为三维张量[batch_size,sen_length,hidden_dim]
- batch_size:表示批量输入文本句子个数,例如,输入三句话batch_size=3,即使输入一句话在pytorch学习框架中也需要设置batch_size=1。
- sen_length:表示句子中token数量。批量文本中每条文本token数量不同,例如一句话有10个token,另一句话有5个token,这两句话的文本编码数据由列表格式变成tensor格式时,tensor()函数有个要求就是批量数据各维度数据长度相同,所以要对每条文本序列截断或者补齐到某个给定值。tokenizer分词器的默认序列长度为本批次文本中最长文本的token数量,也可以调用tokenizer对象时设定padding和truncation属性的数值。
batched_ids = [
[10, 20, 30],
[10, 20]
]
batched_ids = torch.tensor(batched_ids)
#报错长度不匹配,第一句话3个token编码,第二句话2个token编码。
#ValueError: expected sequence of length 3 at dim 1 (got 2)
#正确格式为:
batched_ids = [
[10, 20, 30],
[10, 20,tokenizer.pad_token_id]
]
batched_ids = torch.tensor(batched_ids)- hidden_dim:表示每个token整数编码变成模型可识别的一维词向量的长度。在word2vec静态词向量编码方式中,nn.Embedding(vocab_size,hidden_dim)函数的Embedding.weight权重值就是token查找的词向量表。在Bert模型中,Embedding的词向量表是动态训练生成的。
input_ids整数编码变成tensor后可直接传入model模型进行训练而不需要变成词向量,主要原因是model模型类已经将nn.Embedding词嵌入层封装在模型内部的第一层。通过查看Bert模型的中间隐藏层输出结果就会发现显示的不是bertlayer的十二层而是十三层。模型输出结果为一个元组,要想查看输出结果中的元组名,可通过调用vars()函数反射机制将变量名变成字典的关键字。'last_hidden_state':输出最后 一层的结果, 'pooler_output':输出经过线性变换的[CLS]结果,'hidden_states':输出bert中间隐藏层的每层结果,默认值为None。若想要获得每个中间隐藏层的结果需要设置from_pretrained()函数中的参数output_hidden_states为True。要调用模型的最后一个隐藏层的输出结果进行后处理可通过关键字方式out.last_hidden_state和out['last_hidden_state'],也可通过元组索引序号调用out[0],使用索引号调用的前提是需要知道想使用部分在元组中的准确位置。
##########方法一完整代码###########
ckpt = r'.\chinese_roberta_wwm_base_ext_pytorch'
tokenizer =BertTokenizer.from_pretrained(ckpt)
model = BertModel.from_pretrained(ckpt,output_hidden_states=True)
txt = '这是一个美丽的城市'
input_ids = tokenizer.encode(txt,max_length=20,add_special_tokens=True, padding='max_length',truncation=True)
# input_ids convert list to tensor
# pytorch使用的时候需要增加批次维度
input_ids = torch.LongTensor(input_ids).unsqueeze(0)
#创建mask
mask=torch.zeros_like(input_ids)
for i,token in enumerate(input_ids):
mask[i] = token != tokenizer.pad_token_id
print('mask:',mask)
# mask: tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0]])
out = model(input_ids,attention_mask=mask)
##########方法二完整代码###########
ckpt = r'.\chinese_roberta_wwm_base_ext_pytorch'
tokenizer =BertTokenizer.from_pretrained(ckpt)
model = BertModel.from_pretrained(ckpt,output_hidden_states=True)
##模型加载的另外一种方式
##config=BertConfig.from_pretrained(r'.\chinese_roberta_wwm_base_ext_pytorch')
##config.update({'output_hidden_states':True})
##model=BertModel.from_pretrained(r'.\chinese_roberta_wwm_base_ext_pytorch',\
config=config)
txt = '这是一个美丽的城市'
input_ids = tokenizer(txt,max_length=20,add_special_tokens=True, padding='max_length',truncation=True,return_tensors='pt')
##input_ids是一个包含多个字典的列表,**input_ids传参传的是可变关键字列表,根据模型形参名称将实参传入
out = model(**input_ids)
##查看模型输出结果的关键字
print(vars(out).keys())
#dict_keys(['last_hidden_state', 'pooler_output', 'hidden_states', 'past_key_values', 'attentions', 'cross_attentions'])
last_hidden_states = out.last_hidden_state
print("last hidden state:",out['last_hidden_state'].shape) #torch.Size([1, 20, 768])
print("pooler_output of classification token:",out['pooler_output'].shape) #获得[CLS]维度
print("all hidden_states:", len(out.hidden_states)) #13层,首层为nn.Embedding层五、 用于不同任务的模型
tranformers库还对基础模型的输出部分添加不同的头部模块head封装成适用于不同功能的类。用户可根据任务需要直接调用对应的任务类。下面案例模型输出的结果是没有归一化的数据并不是概率值,要想变成概率需要调用softmax函数。softmax函数用于概率转换,经过softmax函授处理后输出结果每行的总和为1属于类别概率,在训练的时候不需要显示调用函数,因为损失函数已经将softmax函数与损失函数合并封装,但是在做测试时候需要手动调用该函数。
from transformers import AutoTokenizer,AutoModelForSequenceClassification
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
raw_inputs = [
"I've been waiting for a HuggingFace course my whole life.",
"I hate this so much!",
]
inputs = tokenizer(raw_inputs, padding=True, truncation=True, return_tensors="pt")
outputs = model(**inputs)
print(outputs.logits)
#tensor([[-1.5607, 1.6123],
[ 4.1692, -3.3464]], grad_fn=<AddmmBackward>)
predictions = torch.nn.functional.softmax(outputs.logits, dim=-1)
print(predictions)
tensor([[4.0195e-02, 9.5980e-01],
[9.9946e-01, 5.4418e-04]], grad_fn=<SoftmaxBackward>)六、mask掩码的作用
补齐的文本和没有任何填充的相同文本经过模型处理后输出结果不同,主要是注意力计算没有使用mask的缘故。Attention masks是一个张量,与input_ids形状相同,二维矩阵由数字0和数字1构成。这些1和0与input_ids中的token对应。1表示对应的token参与注意力计算,0表示对应的token不参与注意力计算。减轻softmax的计算量。
下面案例中第二句话没有填充pad_token_id,经过模型处理输出结果为tensor([[ 0.5803, -0.4125]]),文本填充pad_token_id后的输出结果为[ 1.3373, -1.2163]。同一句话模型输出结果不同。模型在输入填充文本的同时输入文本对应的attention_mask后模型输出结果就变得相同。主要原因在于获得attention_score后,需要使用attention_mask确定有效token位置,减少无效token参与softmax函数的概率计算。attention mask作用的具体剖析请看我写的另外一篇关于mask的博文链接。
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
sequence1_ids = [[200, 200, 200]]
sequence2_ids = [[200, 200]]
batched_ids = [
[200, 200, 200],
[200, 200, tokenizer.pad_token_id],
]
print(model(torch.tensor(sequence1_ids)).logits)
print(model(torch.tensor(sequence2_ids)).logits)
print(model(torch.tensor(batched_ids)).logits)
tensor([[ 1.5694, -1.3895]], grad_fn=<AddmmBackward>)
tensor([[ 0.5803, -0.4125]], grad_fn=<AddmmBackward>)##结果不同
tensor([[ 1.5694, -1.3895],
[ 1.3373, -1.2163]], grad_fn=<AddmmBackward>)##结果不同
#模型输入添加掩码后输出结果相同
attention_mask = [
[1, 1, 1],
[1, 1, 0],
]
outputs = model(torch.tensor(batched_ids), attention_mask=torch.tensor(attention_mask))
print(outputs.logits)
tensor([[ 1.5694, -1.3895],
[ 0.5803, -0.4125]], grad_fn=<AddmmBackward>)与sequence2_ids的模型输出结果相同。Reference
2.【NLP】手动下载、本地加载BERT预训练权重_bert权重文件下载_sunflower_sara的博客-CSDN博客

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 13
13 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)