
sklearn数据集——iris鸢尾花数据集
鸢尾花(Iris)数据集,是机器学习和统计学中一个经典的数据集。它包含在 scikit-learn 的 datasets 模块中。
参考书籍:Python机器学习基础教程
1、初始数据
鸢尾花(Iris)数据集,是机器学习和统计学中一个经典的数据集。它包含在 scikit-learn 的 datasets 模块中。
我们可以调用 load_iris 函数来加载数据:
from sklearn.datasets import load_iris
iris_dataset = load_iris()load_iris 返回的 iris 对象是一个 Bunch 对象,与字典非常相似,里面包含键和值:
# 查看数据集的keys
print('Keys of iris_dataset: \n{}'.format(iris_dataset.keys()))输出:
Keys of iris_dataset:
dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename', 'data_module'])可以看到,数据集有很多的keys。
DESCR 键对应的值是数据集的简要说明。我们查看前面的部分内容:
print(iris_dataset['DESCR'][:193] + "\n...")输出:
.. _iris_dataset:
Iris plants dataset
--------------------
**Data Set Characteristics:**
:Number of Instances: 150 (50 in each of three classes)
:Number of Attributes: 4 numeric, pre
...通过上面的描述信息,我们可以知道该数据集包含150条数据,每50条数据属于一个类别,即有三个类别,每一条数据有四个特征。
target_names 键对应的值是一个字符串数组,里面包含我们要预测的花的品种:
print("Target names: {}".format(iris_dataset['target_names']))输出:
Target names: ['setosa' 'versicolor' 'virginica']由此,我们可以知道鸢尾花数据集iris包含3类鸢尾花,分别为山鸢尾(Iris-setosa)、杂色鸢尾(Iris-versicolor)和维吉尼亚鸢尾(Iris-virginica)
feature_names 键对应的值是一个字符串列表,对每一个特征进行了说明:
print("Feature names: \n{}".format(iris_dataset['feature_names']))输出:
Feature names:
['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']由此,我们可以知道每条数据包含4个特征:花萼长度(sepal length)、花萼宽度(sepal width)、花瓣长度(petal length)、花瓣宽度(petal width)
数据包含在 target 和 data 字段中。data 里面是花萼长度、花萼宽度、花瓣长度、花瓣宽度的测量数据,格式为 NumPy 数组:
print("Type of data: {}".format(type(iris_dataset['data'])))输出:
Type of data: <class 'numpy.ndarray'>data 数组的每一行对应一朵花,列代表每朵花的四个测量数据:
print("Shape of data: {}".format(iris_dataset['data'].shape))输出:
Shape of data: (150, 4)由此,我们可以知道 data 数组中有150行,对应150条花的测量数据,150个样本,有4列,每一列表示一个特征。
我们查看前5条数据:
print("First five rows of data:\n{}".format(iris_dataset['data'][:5]))输出:
First five rows of data:
[[5.1 3.5 1.4 0.2]
[4.9 3. 1.4 0.2]
[4.7 3.2 1.3 0.2]
[4.6 3.1 1.5 0.2]
[5. 3.6 1.4 0.2]]第一行就代表了第一朵花的花萼长度为5.1cm、花萼宽度为3.5cm、花瓣长度为1.4cm、花瓣宽度为0.2cm。
target 数组包含的是测量过的每朵花的品种,是一个一维的 NumPy数组,每朵花对应其中的一个数据:
print("Shape of target: {}".format(iris_dataset['target'].shape))输出:
Shape of target: (150,)我们从 target_names 键可以知道,鸢尾花数据集有3个品种,这三个品种在 target 数组中被转换为了数字,分别为 0,1,2 :
print("Target:\n{}".format(iris_dataset['target']))输出:
Target:
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]从这里我们也能看出,鸢尾花数据是没有打乱的,即前 50 个数据是一个类别(setosa),中间 50 个数据是一个类别(versicolor),后 50 个数据是一个类别(virginica)
2、划分数据
通常情况下,我们不能将构建模型的数据用于评估模型。因为我们的模型会一直记住整个训练集,所以对于训练集中的任何数据点总会预测正确的标签。这种“记忆”无法告诉我们模型的泛化(generalize)能力如何(换句话说,在新数据上能否正确预测)。所以我们需要用新数据来评估模型的性能,通常的做法就是将我们的数据集划分为训练集和测试集。
scikit-learn 中的 train_test_split 函数可以打乱数据集并进行拆分:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
iris_dataset['data'], iris_dataset['target'], test_size=0.25, random_state=0)train_test_split 函数的第一个参数为要划分的数据,第二个参数为要划分数据的标签,参数 test_size 表示划分出测试集的大小,默认为0.25,random_state 是随机种子,如果指定了这个值,那么每次分割都会生成相同的结果。train_test_split 函数在划分前会默认将数据进行打乱。函数返回 4 个数组,分别为训练数据、测试数据、训练标签、测试标签。
我们可以看一下训练和测试集的形状:
print("X_train shape: {}".format(X_train.shape))
print("y_train shape: {}".format(y_train.shape))
print("X_test shape: {}".format(X_test.shape))
print("y_test shape: {}".format(y_test.shape))输出:
X_train shape: (112, 4)
y_train shape: (112,)
X_test shape: (38, 4)
y_test shape: (38,)3、可视化数据
pandas 的 DataFrame 格式可以使用类似 Excel 表格形式查看数据,我们可以将 numpy 格式的鸢尾花数据转换为 pandas DataFrame:
import pandas as pd
# columns 表示使用鸢尾花的特征名作为每一列的列名
df = pd.DataFrame(iris_dataset.data, columns=iris_dataset.feature_names)
# 添加一列,列名为 label ,数据为标签数据
df['label'] = iris_dataset.target
df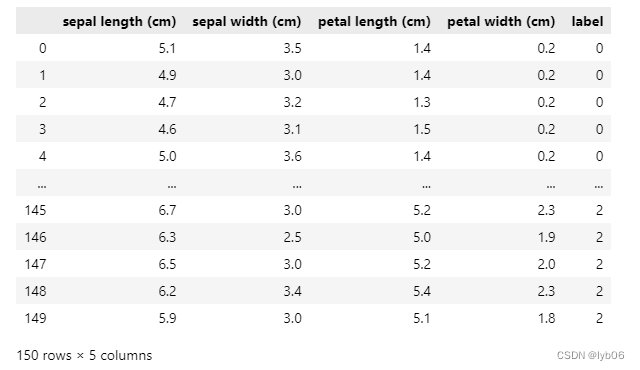
接下来,使用图的方式可视化数据,但这里有一个问题。一条鸢尾花数据包含四个特征,而我们在电脑上难以对多于 3 个特征的数据集作图。解决这个问题的一种方法是绘制散点图矩阵(pair plot),从而可以两两查看所有的特征。
pandas 有一个绘制散点图矩阵的函数,叫作 scatter_matrix。矩阵的对角线是每个特征的直方图,其他位置为通过两两特征绘制的散点图:
# 将数据data转换为DataFrame格式
# 利用iris_dataset.feature_names中的字符串对数据列进行标记
iris_dataframe = pd.DataFrame(iris_dataset.data, columns=iris_dataset.feature_names)
# 利用DataFrame创建散点图矩阵,按标签target着色
grr = pd.plotting.scatter_matrix(iris_dataframe, c=iris_dataset.target, figsize=(10, 10), marker='o',hist_kwds={'bins': 50}, s=50, alpha=.8)参数 c 表示按照标签对数据点着色,即属于不同类别的数据点的颜色不同,figsize 表示图的大小为 10×10 ,marker 表示使用大圆点表示每一个数据点,hist_kwds 是与hist相关的字典参数,s 表示每个点的面积,alpha 表示点的透明度。

4、补充(其他的数据集)
从以上的内容我们可以知道,鸢尾花数据集是一个三分类数据集,sklearn 还提供了一些常用的数据集:
威斯康星州乳腺癌数据集
威斯康星州乳腺癌数据集(简称 cancer),里面记录了乳腺癌肿瘤的临床测量数据。
每个肿瘤都被标记为“良性”(benign,表示无害肿瘤)或“恶性”(malignant,表示癌性肿瘤),其任务是基于人体组织的测量数据来学习预测肿瘤是否为恶性。
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
print("cancer.keys(): \n{}".format(cancer.keys()))输出:
cancer.keys():
dict_keys(['feature_names', 'data', 'DESCR', 'target', 'target_names'])包含在 scikit-learn 中的数据集通常被保存为 Bunch 对象,里面包含真实数据以及一些数据集信息。关于 Bunch 对象,你只需要知道它与字典很相似,而且还有一个额外的好处,就是你可以用点操作符来访问对象的值(比如用 bunch.key 来代替 bunch['key'])。
数据集信息:
- 这是一个二分类数据集
- 这个数据集共包含 569 个数据点,每个数据点有 30 个特征
- 在 569 个数据点中,212 个被标记为恶性,357 个被标记为良性
波士顿房价数据集
与这个数据集相关的任务是,利用犯罪率、是否邻近查尔斯河、公路可达性等信息,来预测 20 世纪 70 年代波士顿地区房屋价格的中位数。
from sklearn.datasets import load_boston
boston = load_boston()数据集信息:
- 这是一个回归数据集
- 这个数据集包含 506 个数据点和 13 个特征

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 10
10 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)