

【已解决】TypeError: can‘t convert cuda:0 device type tensor to numpy. Use Tensor.cpu() to copy the tenso
但不操作还是报错:TypeError: can't convert cuda:0 device type tensor to numpy. Use Tensor.cpu() to copy the tensor to host memory first.这是因为,我们要操作有两个,第一次在cpu我们是清楚的,但是我们不清楚另外一个啊,所以;对另外一个操作还是很有必要的,具体来说其实另外一个是在GP
问题描述
在训练Pytorch模型的时候,报错
Traceback (most recent call last):
File "/home/visionx/nickle/temp/SimCLR/linear_evaluation.py", line 304, in <module>
loss_epoch, accuracy_epoch = train(
^^^^^^
File "/home/visionx/nickle/temp/SimCLR/linear_evaluation.py", line 124, in train
plt.scatter(t_sne_embeddings[ node_labels == class_id, 0],
~~~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/visionx/anaconda3/envs/simclr-pt/lib/python3.11/site-packages/torch/_tensor.py", line 970, in __array__
return self.numpy()
^^^^^^^^^^^^
TypeError: can't convert cuda:0 device type tensor to numpy. Use Tensor.cpu() to copy the tensor to host memory first.
看见别人也有类似的问题
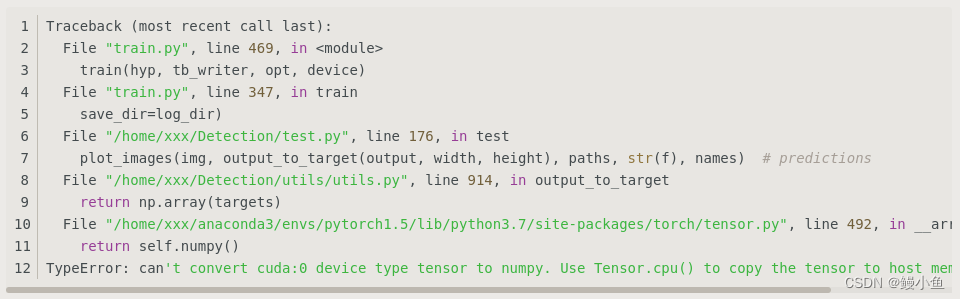
遇到的坑的出错地方
# 将 t_sne_embeddings 和 node_labels 移到 CPU 上
t_sne_embeddings_cpu = t_sne_embeddings.cpu().numpy()
node_labels_cpu = node_labels.cpu().numpy()为什么错了?
第一步、问题分析
如果想把CUDA tensor格式的数据改成numpy时,需要先将其转换成cpu float-tensor随后再转到numpy格式。 numpy不能读取CUDA tensor 需要将它转化为 CPU tensor
那t_sne_embeddings本身就在cpu了,再放cpu什么意思?所以会有这样的解决建议: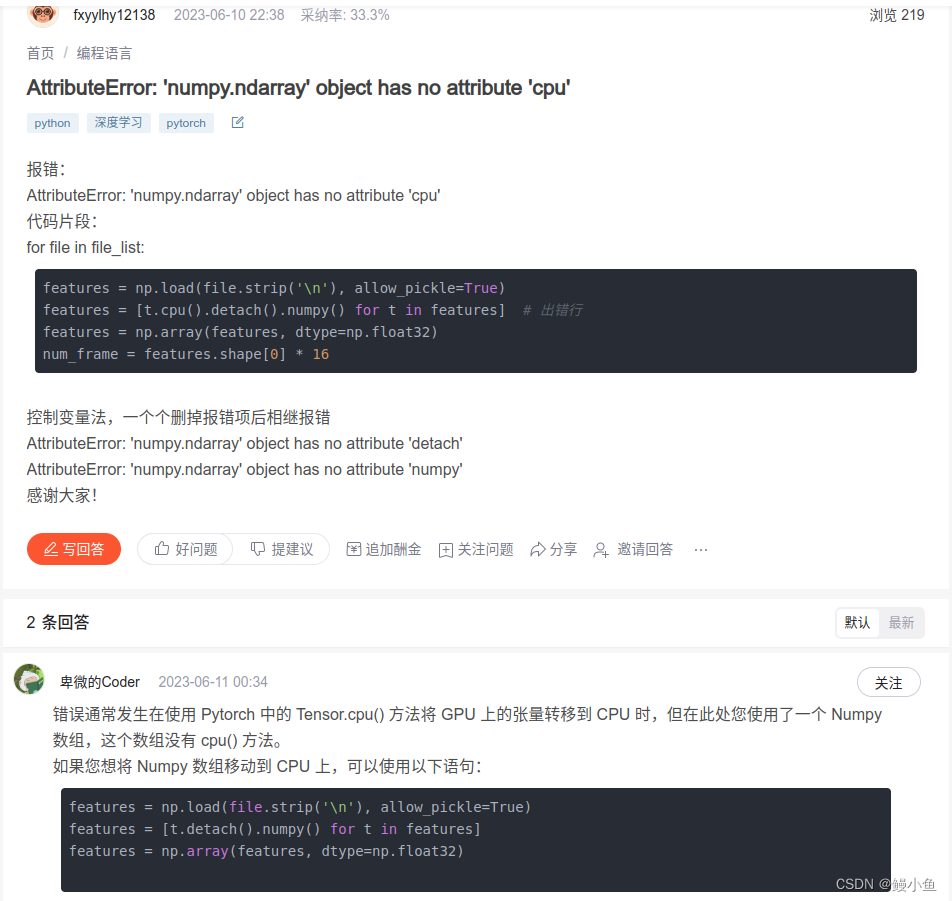
第二步、上手解决
可能有人没看懂,这个其实就是把.cpu()方法给去掉了,因为已经在上面了就没必要再放一次了
但不操作还是报错:TypeError: can't convert cuda:0 device type tensor to numpy. Use Tensor.cpu() to copy the tensor to host memory first.
这是因为,我们要操作有两个,第一次在cpu我们是清楚的,但是我们不清楚另外一个啊,所以;对另外一个操作还是很有必要的,具体来说其实另外一个是在GPU的,所以进行以下操作
node_labels = node_labels.cpu().numpy()第三步、补充说明(常用python版本3.6和3.8)
之前报错的代码是在101服务器上,创建的虚拟环境中Python=3.7,在跑实验的时候出现报错;今天在100服务器上跑同样的实验没有报错,经查在100服务器上创建的虚拟环境中Python=3.8;目测是Python版本的缘故,看来还是python3.8好用一些。
其他细节
情况1、一般来说需要在你转换的变量后面加上.cpu()
1.1、这是一种非常常见的情况
但是看了我上面的分析会发现,这种解决办法是不可行的,对吧
![]()
情况2、好像也没其他情况了
从网上搜到的都是.cpu(),如果有其他的再来补充
2.1 补充说明
本文部分图片和描述来自
原文链接:https://blog.csdn.net/SpadgerZ/article/details/115584829
延展知识阅读
1、CPU和GPU的区别
CPU (Central Processing Unit) 即中央处理器
GPU (Graphics Processing Unit) 即图形处理器
GPGPU全称General Purpose GPU,即通用计算图形处理器。其中第一个“GP”通用目的(GeneralPurpose)而第二个“GP”则表示图形处理(GraphicProcess)
CPU虽然有多核,但总数没有超过两位数,每个核都有足够大的缓存和足够多的数字和逻辑运算单元,并辅助有很多加速分支判断甚至更复杂的逻辑判断的硬件;
GPU的核数远超CPU,被称为众核(NVIDIA Fermi有512个核)。每个核拥有的缓存大小相对小,数字逻辑运算单元也少而简单(GPU初始时在浮点计算上一直弱于CPU)。
从结果上导致CPU擅长处理具有复杂计算步骤和复杂数据依赖的计算任务,如分布式计算,数据压缩,人工智能,物理模拟,以及其他很多很多计算任务等。
GPU由于历史原因,是为了视频游戏而产生的(至今其主要驱动力还是不断增长的视频游戏市场),在三维游戏中常常出现的一类操作是对海量数据进行相同的操作,如:对每一个顶点进行同样的坐标变换,对每一个顶点按照同样的光照模型计算颜色值。GPU的众核架构非常适合把同样的指令流并行发送到众核上,采用不同的输入数据执行
当程序员为CPU编写程序时,他们倾向于利用复杂的逻辑结构优化算法从而减少计算任务的运行时间,即Latency。
当程序员为GPU编写程序时,则利用其处理海量数据的优势,通过提高总的数据吞吐量(Throughput)来掩盖Lantency
2、图示说明
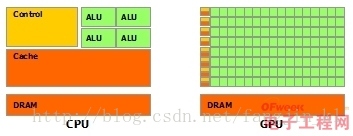
其中绿色的是计算单元,橙红色的是存储单元,橙黄色的是控制单元。
GPU采用了数量众多的计算单元和超长的流水线,但只有非常简单的控制逻辑并省去了Cache。而CPU不仅被Cache占据了大量空间,而且还有有复杂的控制逻辑和诸多优化电路,相比之下计算能力只是CPU很小的一部分
————————————————
版权声明:本文为CSDN博主「FrankJingle」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/fangjin_kl/article/details/53906874
完结撒花
所有不切实际的想法都会变成利刃,刺向远方或者刺向自己

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 11
11 0
0- 0



 已为社区贡献41条内容
已为社区贡献41条内容

所有评论(0)