

时间序列模型(五):时间序列案例_实现销售额预测
本文主要讲述了如何使用ARIMA和SARIMA模型对Perrin Freres香槟公司的销售数据进行时间序列预测。通过对1964年到1972年的数据进行分析,我们处理了缺失值,进行了单位根检验和差分,然后利用ACF和PACF确定模型参数。通过超参数搜索,我们选择了最优的模型进行预测。最后,我们保存了训练好的模型,并使用它进行未来的销售预测。
全文共17000余字,预计阅读时间约35~60分钟 | 满满干货(附代码),建议收藏!

一. 项目概述
1.1 项目背景
Perrin Freres香槟公司是一家历史悠久的酒类生产商,其产品在全球范围内都享有较高的知名度。本项目使用的数据集包含了该公司从1964年到1972年每月的销售额。这份数据集展示了公司销售额的季节性变化和趋势,这种特性使其成为使用ARIMA和SARIMA模型进行时间序列预测的理想案例。
我们将使用ARIMA(自回归积分移动平均模型)和SARIMA(季节性自回归积分移动平均模型)进行预测。ARIMA模型是处理时间序列数据的一种经典方法,它能够捕捉到数据中的趋势、季节性以及其他结构信息。然而,对于具有强烈季节性变化的数据,我们还会使用SARIMA模型,该模型在ARIMA的基础上增加了季节性差分和季节性自回归以及移动平均项,能够更好地处理季节性时间序列。
1.2 项目目的
该项目旨在使用Perrin Freres月度香槟销售数据集(1964年至1972年)来实践并教授时间序列分析方法,具体包括ARIMA和SARIMA模型。我们将探索这两种模型在预测时间序列数据上的表现,并在实战中讲解和学习它们的使用方法和原理。
在实战中,我们将详细介绍如何选择ARIMA和SARIMA模型的参数,如何训练模型,以及如何评估模型的预测性能。此外,我们还将探讨这两种模型的优点和缺点,以及在实际应用中应如何权衡这些因素。希望通过这个项目,读者能够对时间序列预测有更深入的理解,并能够熟练地应用ARIMA和SARIMA模型解决实际问题。
通过这个项目,我们希望提供一个具体的实践案例,帮助大家更好地理解和掌握时间序列分析的相关知识和技巧。同时,通过对比ARIMA和SARIMA模型的预测结果,我们也可以进一步理解这两种模型在处理不同类型的时间序列数据时的优势和不足。
1.3 数据集下载
这个数据集记录了Perrin Freres香槟公司从1964年到1972年每月的销售额。它包含两列数据,一列是月份,另一列是当月的销售额。这个数据集可以用来进行时间序列分析和预测。
您可以在Kaggle上找到这个数据集。
二、Statsmodels库
statsmodels是一个Python库,它提供了许多用于统计数据分析的类和函数。它包括描述性统计、统计模型估计和推断等功能。可以用来进行回归分析、时间序列分析、假设检验等,如线性回归模型、广义线性模型等。
对于时间序列模型,statsmodels包含许多时间序列分析工具,如AR、ARMA、ARIMA、VAR、SARIMA等。此外,它还包含对时间序列进行分解和测试的工具,并且提供了一系列统计测试,例如t测试,F测试,方差分析等。
如需更多的了解,您可以在statsmodels的官方文档中了解更多关于这个库的信息。
本项目就使用上述数据,来实现statsmodel下的ARIMA和SARIMA模型建模。
三、数据处理
3.1 数据导入
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv("perrin-freres-monthly-champagne.csv")
df.head()
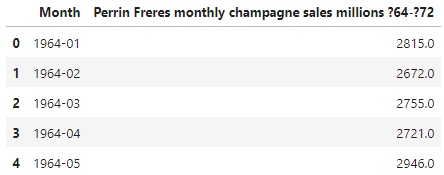
可以看到:数据集包含两列:‘Month’和’Perrin Freres monthly champagne sales millions ?64-?72’。'Month’列表示的是日期,格式为年-月,例如’1964-01’代表1964年1月。'Perrin Freres monthly champagne sales millions ?64-?72’列表示的是Perrin Freres香槟公司在对应月份的销售额。
首两行数据表示在1964年1月和2月,公司的销售额分别为2815.0和2672.0(单位可能是百万或者千万,具体单位应在数据集的描述中有所说明)。
接下来,我们 需要对数据进行进一步的清洗和预处理,以准备进行时间序列分析。
3.2 数据预处理
在开始时间序列分析之前,可能需要进行的数据清洗和预处理步骤:
- 处理缺失值:首先需要检查是否存在缺失值。如果存在,需要根据具体情况来处理,比如填补缺失值(使用前一个月的数据,或者使用相邻月份的平均值),或者删除含有缺失值的行。
- 数据类型转换:确保’Month’列是日期类型,这对于时间序列分析是必要的。如果’Month’列当前不是日期类型,可以使用pandas的
to_datetime函数进行转换。 - 设定索引:对于时间序列分析,需要将时间列(在这个案例中是’Month’列)设为索引。
- 检查数据排序:确认数据是按照时间顺序排列的。如果不是,需要进行排序。
3.2.1 处理缺失值
print(df.isnull().sum()) # 返回每一列中的缺失值(NaN)的数量
print(df.isnull().any(axis=1)) # 返回一个布尔序列,标识每一行是否含有缺失值
print(df.iloc[105]) # 查看具体某一行的值,可以通过索引或者iloc属性来实现
print(df.iloc[106])

从数据情况上看,仅有2行存在缺失,所以我们可以直接删除这两行
3.2.2 处理日期类型
df.columns=["Month","Sales"]
df = df.dropna() # 删除含有缺失值的行
# 2. 数据类型转换
df['Month'] = pd.to_datetime(df['Month'])
# 3. 设定索引
df = df.set_index('Month')
# 4. 检查数据排序
df = df.sort_index()
df.head()
至此,我们完成了数据预处理,现在开始对数据进行分析
四、数据分析
4.1 探索性数据分析(EDA)
首先,我们可以对数据进行初步的分析。可以绘制时间序列图来观察销售额的走势,查看是否有明显的趋势、季节性或者异常点。
import matplotlib.pyplot as plt
plt.figure(figsize=(10,6))
plt.plot(df['Sales'])
plt.xlabel('Month')
plt.ylabel('Sales')
plt.title('Perrin Freres monthly champagne sales')
plt.show()
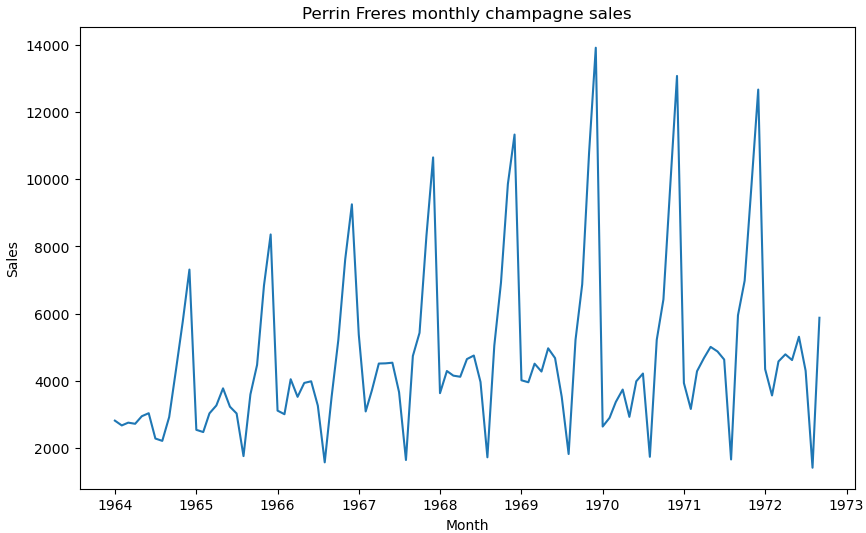
可以很明显的数据具有周期性,谷底出现在每年的第三季度,峰值出现在每年的第四季度,其他时间的销售额相对均匀。
注:平稳性是时间序列模型(如ARIMA模型)的关键假设之一。对于平稳时间序列,其基本统计特性(如均值和方差)不会随时间变化。这意味着无论我们选择哪个时间点来观察,该序列的性质都是相同的。这种性质极大地简化了模型的建立和预测过程。
如果数据不平稳,例如存在明显的趋势或季节性,那么模型可能会被这些因素影响,导致预测结果不准确。例如,如果数据中存在上升的趋势,模型可能会高估未来的低值并低估未来的高值。此外,不平稳数据中的噪声可能会被模型误认为是信号,导致预测结果过度拟合历史数据。
从图像来看,数据基本上是无法满足平稳性条件的,接下来我们在平稳性检验上验证这一结论。
4.2 ADF单位根检验
平稳性检验可以帮助我们更加准确地确定数据是否平稳。一个常用的平稳性检验方法是Augmented Dickey-Fuller (ADF)检验。我们使用statsmodels库中的adfuller函数进行ADF检验。
from statsmodels.tsa.stattools import adfuller
result = adfuller(df['Sales'])
print('ADF Statistic: %f' % result[0])
print('p-value: %f' % result[1])
print('Critical Values:')
for key, value in result[4].items():
print('\t%s: %.3f' % (key, value))
结果如下:
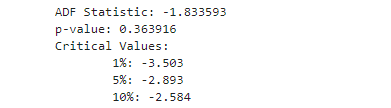
结果中:Augmented Dickey-Fuller (ADF)检验结果显示,测试统计量(ADF Statistic)为-1.833593,这个值大于所有的临界值(在1%,5%和10%的显著性水平下,临界值分别为-3.503,-2.893和-2.584)。这表示我们不能拒绝原假设,即我们不能断定数据是平稳的。
此外,p值为0.363916,这个值大于通常的显著性水平(如0.05或0.01)。这也表明我们没有足够的证据拒绝原假设,即我们不能认为数据是平稳的。
补充一下知识点:
在统计检验中,p值是一种用于决定假设检验结果的指标。它的数值范围在0到1之间。更具体地,p值是在原假设成立的情况下,观察到当前样本数据或更极端情况的概率。
如果p值很小(通常小于0.05或0.01),那么我们就有理由拒绝原假设,即认为我们的数据提供了足够的证据表明原假设不成立。如果p值较大,那么我们就不能拒绝原假设。
关于原假设和备择假设:
- 原假设(Null Hypothesis)是我们想要检验的假设,通常表示为当前观察到的现象是偶然发生的,或者没有发生显著的变化或差异。在Augmented Dickey-Fuller (ADF)检验中,原假设是时间序列是非平稳的。
- 备择假设(Alternative Hypothesis)是与原假设相对立的假设,即我们认为观察到的现象不是偶然发生的,或者存在显著的变化或差异。在ADF检验中,备择假设是时间序列是平稳的。
在进行假设检验时,我们首先假设原假设是正确的,然后通过计算p值来判断是否有足够的证据拒绝原假设。如果有足够的证据(即p值足够小),那么我们就拒绝原假设,接受备择假设。
因此,根据这个ADF检验的结果,销售数据可能是非平稳的,可能存在趋势或者季节性等非平稳性。在进行时间序列分析之前,需要先对数据进行差分或者其他转换,使其平稳。
4.3 差分
我们使用pandas的diff()函数进行差分。这个函数会计算每一行与其前一行的差值。
自定义一个calculate_diff函数,遍历不同的差分步数,并对每个步数的结果进行Augmented Dickey-Fuller (ADF)检验。函数将打印出每个阶数的ADF检验统计量、p值、标准差和方程,帮助选择最佳的差分步数。代码如下:
# 首先导入了所需要的库和函数
from statsmodels.tsa.stattools import adfuller
# 定义一个名为calculate_diff的函数,接收三个参数:df是要处理的DataFrame,max_diff是最大的差分步数,significance_level是判定平稳性的显著性水平
def calculate_diff(df, max_diff, significance_level=0.05):
# 初始化最佳差分阶数和最小p值
best_diff = None
min_pvalue = 1.0
min_variance = float('inf') # 初始化最小方差
min_adf_stat = float('inf') # 初始化最小ADF统计量
# 循环,差分阶数从1到max_diff
for i in range(1, max_diff+1):
# 对数据进行差分,并去除NA值
df_diff = df['Sales'].diff(i).dropna()
# 对差分后的数据进行ADF单位根检验
result = adfuller(df_diff)
# 打印出差分阶数,ADF统计量,p值,标准差和方差
print(f'{i}步差分')
print('ADF统计量: %f' % result[0])
print('p值: %.10e' % result[1])
print('标准差: %f' % df_diff.std())
print('方差: %f' % df_diff.var())
# 判断p值是否小于显著性水平,如果小于则认为差分后的数据可能是平稳的
if result[1] < significance_level:
print('=> 根据这个差分阶数,序列可能是平稳的')
# 判断当前的p值是否小于最小p值,如果小于则更新最小p值和最佳差分阶数
if result[1] < min_pvalue:
min_pvalue = result[1]
best_diff = i
min_variance = df_diff.var() # 更新最小方差
min_adf_stat = result[0] # 更新最小ADF统计量
else:
print('=> 根据这个差分阶数,序列可能是非平稳的')
print('--------------------------------')
# 如果找到了使数据平稳的差分阶数,打印出最佳差分阶数和其对应的p值
if best_diff is not None:
print(f'最佳差分阶数是: {best_diff},p值为: {min_pvalue},方差为: {min_variance},ADF统计量为: {min_adf_stat}')
# 使用函数对数据进行差分并测试其平稳性
calculate_diff(df, max_diff=24)
这段代码的主要目的是对时间序列进行差分并测试差分后的数据是否平稳。它首先在一个循环中对数据进行不同步数的差分,并对差分后的数据进行ADF(Augmented Dickey-Fuller)单位根检验。然后在所有使数据平稳的差分阶数中,选择p值最小的作为最佳差分步数。部分输出如下:

如果许多差分都能够满足单位根检验,我们通常选择ADF值最小、或差分后数据方差最小的步数
- ADF统计量:ADF统计量越小(越负),说明数据越可能是平稳的。所以在满足平稳性的情况下,可以选择ADF统计量最小的差分阶数。
- p值:p值要低于预定的显著性水平(如0.05),才能认定该序列是平稳的。如果多个差分阶数的p值都低于显著性水平,可以选择ADF统计量最小的差分阶数。
- 标准差和方差:理想的平稳序列,其标准差和方差应该维持在一定范围,不应有大的波动。可以考虑选择使标准差和方差最小的差分阶数。
但需要注意的是,上述指标并不能保证选择出的差分阶数就是最优的。在实际操作中,可能还需要考虑到模型的预测性能等因素。在满足平稳性的前提下,可能还需要多试几种差分阶数,看看哪个差分阶数下的模型能给出最好的预测结果。
4.4 绘制差分后的图像
我们可以绘制差分后的图像和原始图像作对比,来查看数据的平稳性。
如上:我们选择的最佳差分步数是12步,所以我们就选择12步差分的数据进行绘制
import matplotlib.pyplot as plt
# 设置12步差分
diff_steps = 12
df_diff = df['Sales'].diff(diff_steps).dropna()
plt.figure(figsize=(12,6))
# 绘制原始数据
plt.plot(df['Sales'], label='Original Data')
# 绘制12步差分后的数据
plt.plot(df_diff, label=f'Data after {diff_steps}-step differencing', color='orange')
# 设置标题和标签
plt.title('Original Data vs Differenced Data')
plt.xlabel('Time')
plt.ylabel('Sales')
plt.legend()
plt.show()
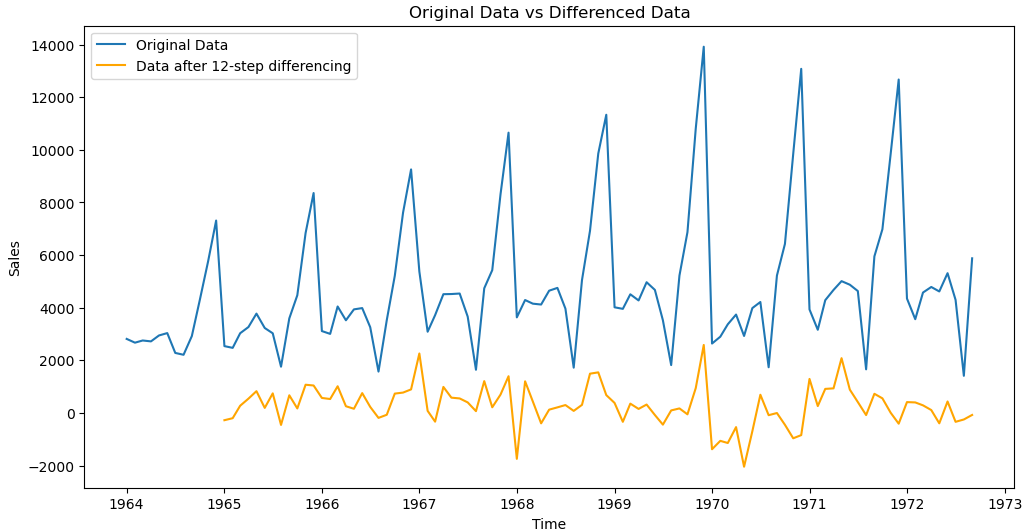
在原始数据和差分后的数据中,数值的范围可能有很大的不同。原始数据可能包含趋势,其数值可能会随时间不断增加或减少,导致数据的范围较大。而差分是用来消除这种趋势的一种方法,差分后的数据主要表示相邻观测值之间的变化量,这个变化量可能相对较小,导致差分后的数据范围较小。因此,原始数据和差分后的数据在同一张图中展示时,如果共享同一y轴,可能会使差分后的数据的变化不明显。
差分后的数据(黄线)主要表示相邻观测值之间的变化量,所以我们观察这个变化量的模式。变化量在0附近随机波动,没有明显的趋势和季节性,那么可以认为差分后的数据是平稳的。
所以我们选择12步差分的数据作为后续的建模数据
df['Sales_Diff_12'] = df['Sales'].diff(12)
五、模型选择
5.1 分析ACF及PACF
ACF和PACF图有助于你确定时间序列模型(例如ARIMA模型)的参数。这两种图形分别反映了时间序列的自相关性和偏自相关性。我们通过图像来分析
import matplotlib.pyplot as plt
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
# 绘制ACF图
plt.figure(figsize=(12,8))
plot_acf(df['Sales_Diff_12'].dropna(), lags=45, ax=plt.gca())
plt.title('Autocorrelation for Sales with 12 lags Difference')
plt.show()
# 绘制PACF图
plt.figure(figsize=(12,8))
plot_pacf(df['Sales_Diff_12'].dropna(), lags=45, ax=plt.gca())
plt.title('Partial Autocorrelation for Sales with 12 lags Difference')
plt.show()
在这段代码中,我们用到了plot_acf和plot_pacf函数来绘制ACF和PACF图。lags参数用于设定我们想要观察的滞后阶数,ax=plt.gca()用于将图形绘制在当前的Axes对象上。
请注意,因为在计算差分时会引入NaN值,所以在绘制图形之前,我们需要用dropna()函数来去掉这些值。

从ACF和PACF的图像可以看出,两个自相关系数都没有呈现拖尾的情况,因此p和q都不为0,此时我们需要的至少是一个ARIMA(p,d,q)模型。
5.2 使用多阶差分确定d值
当我们确定ARIMA模型的p和q参数都不为0后,我们需要找到一个适合的d值,也就是使序列平稳的最小差分阶数。我们通常会尝试从0到3的阶数,并从中选择一个合适的。我们的目标是找到一个可以消除数据中的趋势和季节性,同时使差分后的序列方差最小、噪声最小的d值。
一种有效的策略是绘制不同阶差分后的自相关函数(ACF)图。如果ACF图中的第一个滞后值是负的,那么我们可能会怀疑数据存在过差分问题,也就是我们对数据做了过多的差分。另外,我们还需要注意的是,我们应该选择能使差分后的序列方差最小的d值。因此,我们将打印出0到3阶差分的序列方差和ACF图,以便进行比较和选择。
为什么此处不再绘制PACF图了呢?因为我们的数据已经是经过12步差分后的数据,是一个平稳数据了,当尝试对一个已经是平稳的序列再次进行差分操作,特别是当序列中有大量的0时,这会导致计算偏自相关函数(PACF)时出现问题。
from statsmodels.graphics.tsaplots import plot_acf
import matplotlib.pyplot as plt
import numpy as np
def diff(data, order):
if order == 0:
return data
else:
return diff(data.diff().dropna(), order - 1)
# 循环不同的d值
for d in range(1, 4):
# 创建新的图形
plt.figure(figsize=(12, 4))
plt.suptitle(f'Order {d} Difference', fontsize=16)
# 绘制ACF图
plot_acf(diff(df['Sales_Diff_12'], d), ax=plt.gca(), title='Autocorrelation')
plt.show()
这个函数每次它被调用,它会对数据进行一阶差分,然后将差分后的数据和阶数减一的值作为新的参数再次调用自身,直到阶数降到0为止。然后对每个d值,它都会绘制对应的ACF图。

除了原始数据,其他阶差分都出现了“过差分”的情况(滞后为1的ACF值为负),因此我们可以判断对ARIMA模型而言最佳的d取值为0。
5.3 ARIMA模型实现
5.3.1 设置时间索引
df.index = pd.DatetimeIndex(df.index.values, freq=df.index.inferred_freq)
freq=df.index.inferred_freq指定了新的DateTimeIndex的频率。
df.index.inferred_freq 会自动推断原来索引的频率。例如,如果原来的索引是每天的日期,那么inferred_freq就会是’D’,代表每日。在此案例中,最小的时间日期是MS,频率为月份
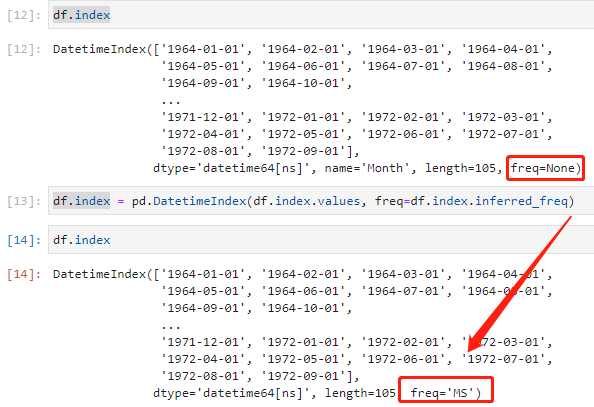
这个操作在处理时间序列数据时常常需要,因为一些像ARIMA这样的时间序列模型需要知道数据的频率(如每日、每月、每年等)。而默认情况下,pandas读入的数据索引并没有指定频率。通过这段代码,我们就能指定好索引的频率,使之满足这些模型的要求。
5.3.2 获取不同的p、d、q组合
我们上面已经确定了,d=0,所以我们此处做一下pdq组合,一般p和q不会取很大的值,此处取1~4
#定义p, d和q参数,取0到4之间的任意值
p = q = range(0, 4)
# 生成p, d和q三元组的所有不同组合
pdq = [(x[0], 0, x[1]) for x in list(itertools.product(p, q))]
输出就是不同的参数组合
[(0, 0, 0), (0, 0, 1), (0, 0, 2), (0, 0, 3), (1, 0, 0), (1, 0, 1), (1, 0, 2), (1, 0, 3), (2, 0, 0), (2, 0, 1), (2, 0, 2), (2, 0, 3), (3, 0, 0), (3, 0, 1), (3, 0, 2), (3, 0, 3)]
5.3.3 超参数搜索
我们的目标是找到能够最大化模型性能的p和q值。我们可以通过遍历不同的p和q值,并使用每个值组合来拟合模型,然后比较每个模型的性能,来找到最优的p和q值。模型性能可以使用AIC(Akaike Information Criterion)来评估,AIC越小,模型的性能越好。
以下是对p和q值进行调优的代码,此处我们先选择MSE作为评估标准
import warnings
warnings.filterwarnings("ignore")
from sklearn.metrics import mean_squared_error
import matplotlib.pyplot as plt
from statsmodels.tsa.arima.model import ARIMA
import itertools
#定义p, d和q参数,取0到4之间的任意值
p = q = range(0, 4)
# 生成p, d和q三元组的所有不同组合
pdq = [(x[0], 0, x[1]) for x in list(itertools.product(p, q))]
# 将数据分为训练集和测试集
train_data = df['Sales_Diff_12'].iloc[:-20]
test_data = df['Sales_Diff_12'].iloc[-20:]
# 初始化最佳模型及其参数和MSE值
best_model = None
best_param = None
best_mse = float('inf')
# 对每一种参数组合进行迭代
for param in pdq:
try:
# 实例化ARIMA模型
model = ARIMA(train_data, order=param)
model_fit = model.fit()
# 进行预测
predictions = model_fit.predict(start=len(train_data), end=len(train_data) + len(test_data) - 1)
# 计算MSE
mse = mean_squared_error(test_data, predictions)
# 如果当前模型的MSE比最佳MSE小,更新最佳模型、参数和MSE
if mse < best_mse:
best_model = model_fit
best_param = param
best_mse = mse
# 绘制真实值和预测值
plt.figure(figsize=(6, 4))
plt.plot(df.index, df['Sales_Diff_12'], label='Actual')
plt.plot(df.index[-20:], predictions, color='red', label='Predicted')
# 添加标题和标签
plt.title('Actual vs Predicted Sales for ARIMA{}'.format(param))
plt.xlabel('Time')
plt.ylabel('Sales')
plt.legend()
# 显示图形
plt.show()
except Exception as e:
print('Error:', e)
continue
# 打印出最优模型的参数及其MSE
print(f'The best model is ARIMA{best_param}, MSE = {best_mse}')
# 打印最优模型的摘要
print(best_model.summary(alpha=0.05))
这段代码的主要目的是找到最优的ARIMA模型以预测销售数据。通过迭代所有可能的参数组合,为每个模型拟合数据并进行预测,计算预测的均方误差,同时绘制出预测结果与真实数据的对比图。最后,代码会选出表现最好(均方误差最小)的模型及其参数,并展示其详细信息。

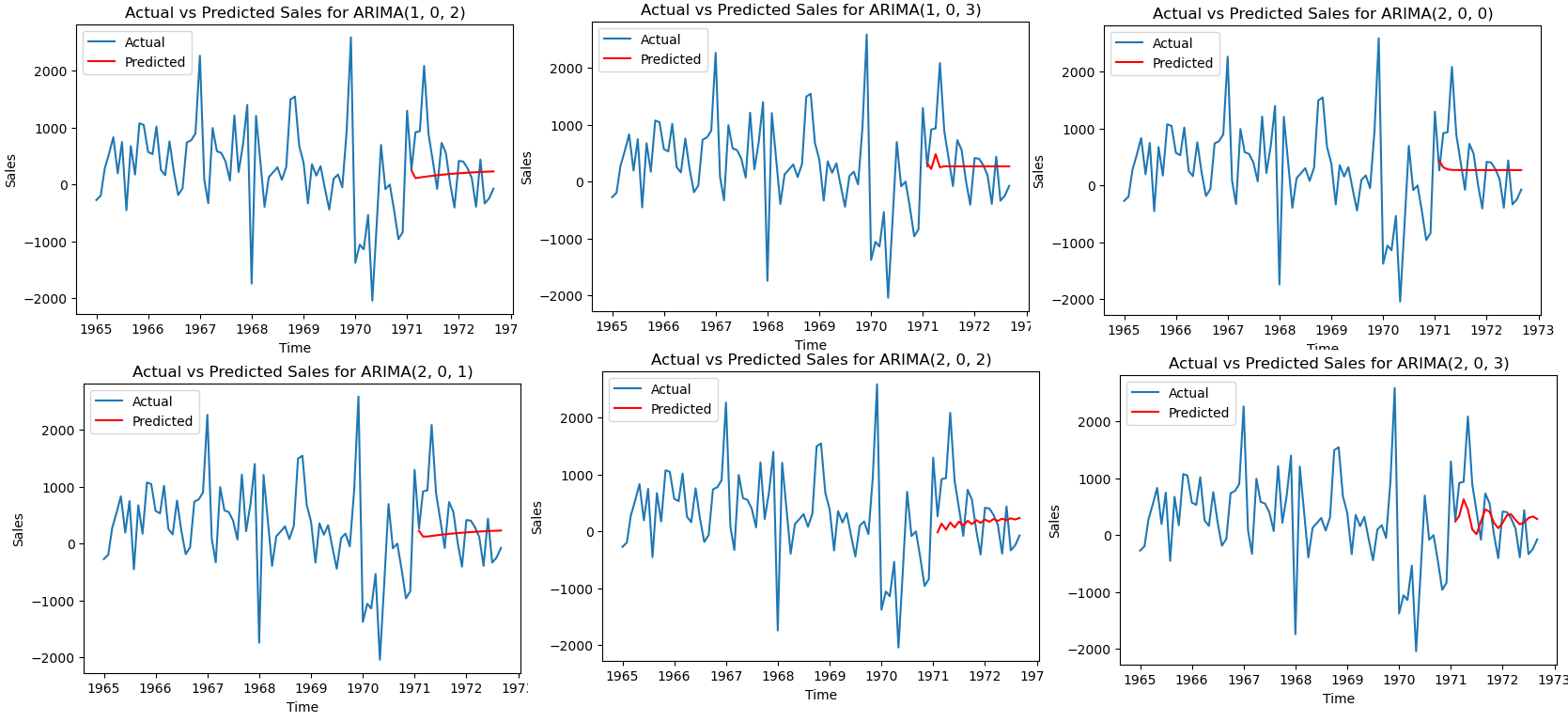
5.3.4 解读summary结果
上述代码输出,选择了MSE最好的模型ARIMA(2, 0, 3)
# 打印出最优模型的参数及其MSE
print(f'The best model is ARIMA{best_param}, MSE = {best_mse}')
# 打印最优模型的摘要
print(best_model.summary(alpha=0.05))
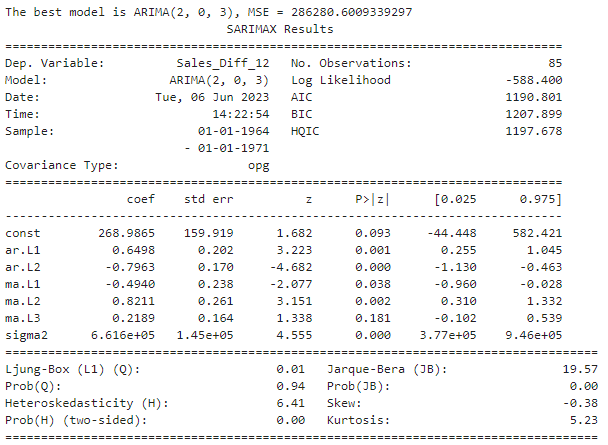
我们详细的来解读一下这个结果,分成三部分来进行,
第一部分是模型基本的信息和评估指标。我们需要关注的是模型评估指标部分,这里的四个指标分别是对数似然估计、AIC、BIC和HQIC四个评估指标,通常来说我们会直接关注AIC的指标,优先选出AIC最低的模型进行进一步的研究和观察。

再来看第二部分:这一部分是模型诊断统计信息的总结,比较重要,

在读表格的这一部分的时候,我们首先会观察p值,确定是否有任何项的p值大于我们设置的显著性水平 α \alpha α。如果存在这样的项,那我们大概率就不会关注当前的模型了。在ARIMA模型选择过程中,我们选出的模型应当是所有项的p值都小于显著性水平的模型。
从我们的结果来看,“ar.L1”、“ar.L2”、"ma.L1"和"ma.L2"的P值都小于0.05,因此这些参数在统计上显著不为0,对模型有显著的贡献。另一方面,"const"和"ma.L3"的P值大于0.05,所以我们不能确信这些参数在统计上显著不为0。
最后来看第三部分:一般来说,当我们看了上面两部分,检验模型的图像AIC值较小、且第二部分的p值没有任何大于0.05的项目时,我们才开始关注这最后一部分

在实际应用ARIMA模型的过程中,我们期望所有的统计检验都无法拒绝原假设,也就是说模型的残差表现得像白噪声,数据符合正态分布,且不存在异方差性然而,这种理想情况往往难以达成。如果遇到这种情况,我们可以考虑选择那些使得不满足检验的p值最大的参数组合,因为这意味着拒绝原假设的证据相对较弱。
5.4 SARIMA模型实现
在我们完成了ARIMA模型的构建过程后,我们发现最优的ARIMA(2,0,3)模型的预测效果并不理想。因此,我们考虑引入更强大的模型:季节性自回归积分移动平均模型(SARIMA)。
SARIMA模型在原有ARIMA模型的基础上,增加了对季节性因素的处理,因此,对于存在周期性的数据,其预测能力往往优于ARIMA模型。SARIMA模型中的前三个参数与ARIMA模型相同,而最后一个参数s代表季节性差分的周期长度。因此,SARIMA模型具备多步差分和高阶差分的能力。
在之前的数据平稳性检验中,我们发现当前时间序列呈现出明显的周期性,并且选择进行12步差分能使序列达到平稳。根据SARIMA模型的理论,当原始序列具有明显的周期性时,d的值至少应设为1。因此,我们可以先行设定SARIMA模型的d值为1,先建模试试看。
import warnings
warnings.filterwarnings("ignore")
import matplotlib.pyplot as plt
from statsmodels.tsa.arima.model import ARIMA
import itertools
# 定义季节性参数 P 和 Q,取0到2之间的任意值
P = Q = range(0, 3) # D固定为1
s = 12 # 季节性周期,这里设置为12,表示年度季节性
# 生成P和Q的组合,并创建季节性参数列表
seasonal_pdq = [(x[0], 1, x[1], s) for x in list(itertools.product(P, Q))]
# 将数据分为训练集和测试集
train_data = df['Sales'][:-20]
test_data = df['Sales'].iloc[-20:]
best_model = None # 初始化最优模型
best_seasonal_param = None # 初始化最优季节性参数
best_aic = float('inf') # 初始化最优模型的AIC值,初始值设置为无穷大
# 对所有的季节性参数组合进行遍历
for seasonal_param in seasonal_pdq:
try:
# 建立季节性ARIMA模型
model = ARIMA(endog = train_data, seasonal_order=seasonal_param)
model_fit = model.fit() # 拟合模型
aic = model_fit.aic # 获取当前模型的AIC值
# 如果当前模型的AIC小于最优AIC,则更新最优模型、最优季节性参数和最优AIC
if aic < best_aic:
best_model = model_fit
best_seasonal_param = seasonal_param
best_aic = aic
print(f'ARIMA{seasonal_param} - AIC:{aic}')
# 生成预测结果的开始时间和结束时间
start = len(train_data)
end = start + len(test_data) - 1
# 使用当前模型进行预测
predictions = model_fit.predict(start=start, end=end, dynamic=True)
# 画图展示真实值和预测值
plt.figure(figsize=(12, 2))
plt.plot(df.index[:end + 1], df['Sales'].iloc[:end + 1], label='Actual')
plt.plot(df.index[start:end + 1], predictions, color='red', label='Predicted')
plt.title(f'ARIMA{seasonal_param} - AIC:{aic}')
plt.xlabel('Time')
plt.ylabel('Sales')
plt.legend()
plt.show()
except Exception as e:
# 如果建立模型或者拟合模型出错,打印出错误信息
print('Error:', e)
continue
# 打印出最优模型的季节性参数和AIC
print(f'\nThe best model is ARIMA{best_seasonal_param}, AIC = {best_aic}')
# 打印最优模型的摘要信息
print(best_model.summary(alpha=0.01))
这段代码跟ARIMA建模过程基本一致,但做了几处小改动:
1. 在ARIMA模型中,我们使用的是12步差分后的数据建模,即df[‘Sales_Diff_12’]。这是因为ARIMA模型假设数据是平稳的,也就是说,数据的统计性质(如均值和方差)在时间上是不变的。如果数据存在趋势或季节性,那么这个假设就不成立,需要通过差分操作来移除趋势和季节性,使数据平稳。
SARIMA模型我们使用的原始数据建模,即:df[‘Sales’],这是因为SARIMA是ARIMA模型的一种扩展,它在模型中直接考虑了季节性因素。具体来说,SARIMA模型有一个额外的季节差分部分,用来处理季节性变化。因此,在使用SARIMA模型时,我们不需要事先对数据进行季节差分,模型会自动处理季节性因素。如果再使用12步差分的数据建模,可能会过度差分,导致模型效果不佳。
2. 采用了最小的AIC作为评估指标选择最优的模型,而不再是MSE,但是需要注意的是,使用AIC自动帮我们选择最优的参数组合只是其中的一个手段,我们需要人工的再去判别模型的好坏,因为确定一个好的SARIMA模型并不是只能通过某一个评估值就能确定的,我们还要观察其他指标的情况,比如要看它是否能通过异方差检验假设、LBQ假设等。
我们截取部分图像,根据AIC值自动帮我选出来最优模型参数是:
SARIMA(2, 1, 2, 12), AIC = 1182.4033278160791

我们再来看一下summary:
分析一下这个结果:

虽然我们选取了AIC最小的参数组合,但这个模型还是存在一些问题,这些问题主要表现在可能的过拟合上:一部分系数的显著性检验并未通过,这意味着模型可能引入了与目标变量无关的解释变量,这表明模型的复杂度可能超过了数据本身的复杂性。同时,我们注意到残差的白噪声假设检验全部通过,这说明我们的模型已经从数据中提取了尽可能多的信息,模型的学习能力没有问题。因此,根据我们的分析结果,这个模型可能存在过拟合的问题。
5.5 手动调优SARIMA模型
我们在SARIMA(2, 1, 2, 12)的基础上进行一些参数的调整试试。我们可以尝试的方法无非就是p、d、q,甚至去修改s,具体怎么修改要看我们的分析结果,如上,我们认为SARIMA(2, 1, 2, 12)是存在过拟合的,尝试降低p来试一下:
def sarima_model(data, seasonal_order):
model = ARIMA(endog=data, seasonal_order=seasonal_order)
model_fit = model.fit()
df_plot = pd.DataFrame()
df_plot["Actual"] = data
df_plot["Predicted"] = model_fit.predict(start=90, end=104, dynamic=True)
df_plot[['Actual','Predicted']].plot(figsize=(12,2))
plt.show()
print(model_fit.summary(alpha=0.01))
sarima_model(df['Sales'], (1,1,1,12))
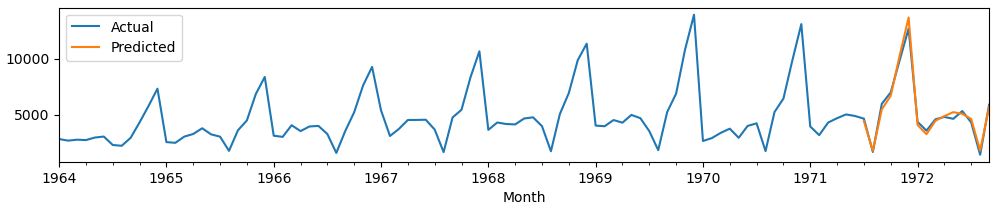
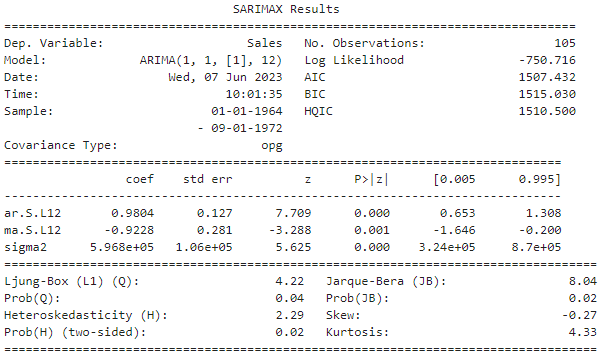
可以看到,这个模型在比较的低的AIC值下通过了所有检验。所以我们更多要依据数据的实时反馈来进行人工的调参,大家可以再进行尝试,还会得到更好的模型。
六、模型应用
在第五节我们确定了最优的模型为SARIMA(1, 1, 1, 12),那么怎么应用训练好的模型到实际的业务中呢?
首先,我们可以使用pickle库或者joblib库实现模型的保存和加载,首先添加模型保存代码:
import pickle
def sarima_model(data, seasonal_order):
# 训练模型
model = ARIMA(endog=data, seasonal_order=seasonal_order)
model_fit = model.fit()
# 保存模型到文件
pickle.dump(model_fit, open("model.pkl","wb"))
df_plot = pd.DataFrame()
df_plot["Actual"] = data
df_plot["Predicted"] = model_fit.predict(start=90, end=104, dynamic=True)
df_plot[['Actual','Predicted']].plot(figsize=(12,2))
plt.show()
print(model_fit.summary(alpha=0.01))
sarima_model(df['Sales'], (1,1,1,12))
实现加载并预测:
# 加载模型
loaded_model = pickle.load(open("model.pkl","rb"))
# 使用加载的模型进行预测
forecast = loaded_model.predict(start=len(df), end=len(df)+11, dynamic=True)
# 创建新的日期索引
forecast_index = pd.date_range(start=df.index[-1] + pd.DateOffset(months=1), periods=12, freq='MS')
# 创建预测结果的DataFrame,并将新的日期索引赋给它
forecast_df = pd.DataFrame(forecast.values, index=forecast_index, columns=['Forecast'])
# 将原始数据与预测数据拼接在一起
df_plot = pd.concat([df['Sales'], forecast_df], axis=1)
plt.figure(figsize=(12, 2))
# 绘制原始销售数据
plt.plot(df['Sales'], label='Actual Sales')
# 绘制预测销售数据
plt.plot(forecast_df, label='Forecasted Sales')
plt.title('Actual Sales vs Forecasted Sales')
plt.xlabel('Time')
plt.ylabel('Sales')
plt.legend()
plt.show()
我们通过训练的模型 ,预测了未来12个月的销售额,通过可视化直观的感受一下:
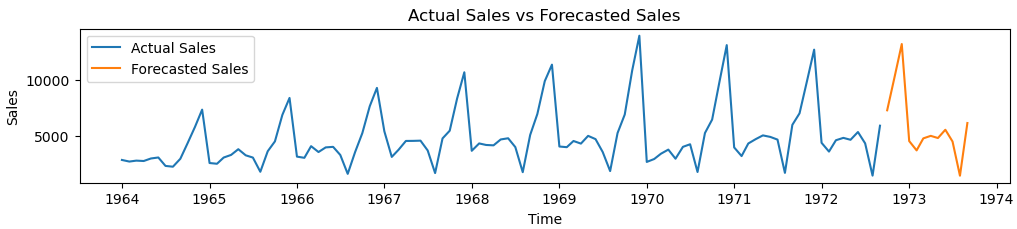
黄色部分就是我们预测的未来一年(12)个 月的值,可以看到,我们训练的模型已经能够捕捉这个数据的趋势了。更多的探索,留给你们啦!
七. 总结
在这个项目中,从一个实际问题出发,针对Perrin Freres香槟公司1964年到1972年每月的销售额数据完成时序模型的建模,并精准预测了未来一年(12个月)的销售额,这个过程包含了数据的清理、探索性分析、模型选择、参数调优和模型的保存与应用等关键步骤,提供了一种标准的时间序列分析工作流程。
最后,感谢您阅读这篇文章!如果您觉得有所收获,别忘了点赞、收藏并关注我,这是我持续创作的动力。您有任何问题或建议,都可以在评论区留言,我会尽力回答并接受您的反馈。如果您希望了解某个特定主题,也欢迎告诉我,我会乐于创作与之相关的文章。谢谢您的支持,期待与您共同成长!
期待与您在未来的学习中共同成长。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 35
35 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)