Python爬虫——爬取网站多页数据
·
1.利用“固定网址”+“下页”方法
同样使用豆瓣电影的网页来进行分析,https://movie.douban.com 豆瓣电影网站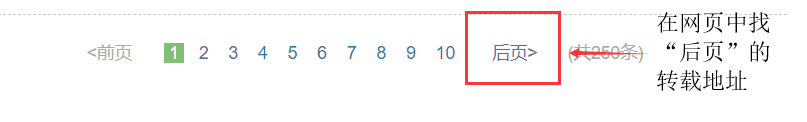

#获取下一页地址
#获取下一页地址
try:
next_url = list.xpath('//span[@class="next"]/a/@href')[0] #@href是获取href的地址
if next_url:
url = "https://movie.douban.com/top250"+ next_url
except:
flag = False
完整代码为:
import requests
from lxml import etree
import re
url="https://movie.douban.com/top250"
header = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36"}
allMovieList=[]
flag = True
while flag:
html = requests.get(url, headers=header).text
list = etree.HTML(html)
lis = list.xpath('//ol[@class="grid_view"]/li')
for oneSelector in lis:
name = oneSelector.xpath("div/div[2]/div[1]/a/span[1]/text()")[0]
score = oneSelector.xpath("div/div[2]/div[2]/div/span[2]/text()")[0]
people = oneSelector.xpath("div/div[2]/div[2]/div/span[4]/text()")[0]
people = re.findall("(.*?)人评价",people)[0]
oneMovieList = [name,score,people]
allMovieList.append(oneMovieList)
#获取下一页地址
try:
next_url = list.xpath('//span[@class="next"]/a/@href')[0]
if next_url:
url = "https://movie.douban.com/top250"+ next_url
except:
flag = False
print(allMovieList)
2.利用“固定网址”+“不同数字码”方法



import requests
from lxml import etree
import re
allMovieList=[]
for page in range(3):
url = "https://movie.douban.com/top250?start=%s" % (page*25)
print(url)
header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36"}
html = requests.get(url, headers=header).text
list = etree.HTML(html)
lis = list.xpath('//ol[@class="grid_view"]/li')
for oneSelector in lis:
name = oneSelector.xpath("div/div[2]/div[1]/a/span[1]/text()")[0]
score = oneSelector.xpath("div/div[2]/div[2]/div/span[2]/text()")[0]
people = oneSelector.xpath("div/div[2]/div[2]/div/span[4]/text()")[0]
people = re.findall("(.*?)人评价",people)[0]
oneMovieList = [name,score,people]
allMovieList.append(oneMovieList)
print(allMovieList)
运行结果为: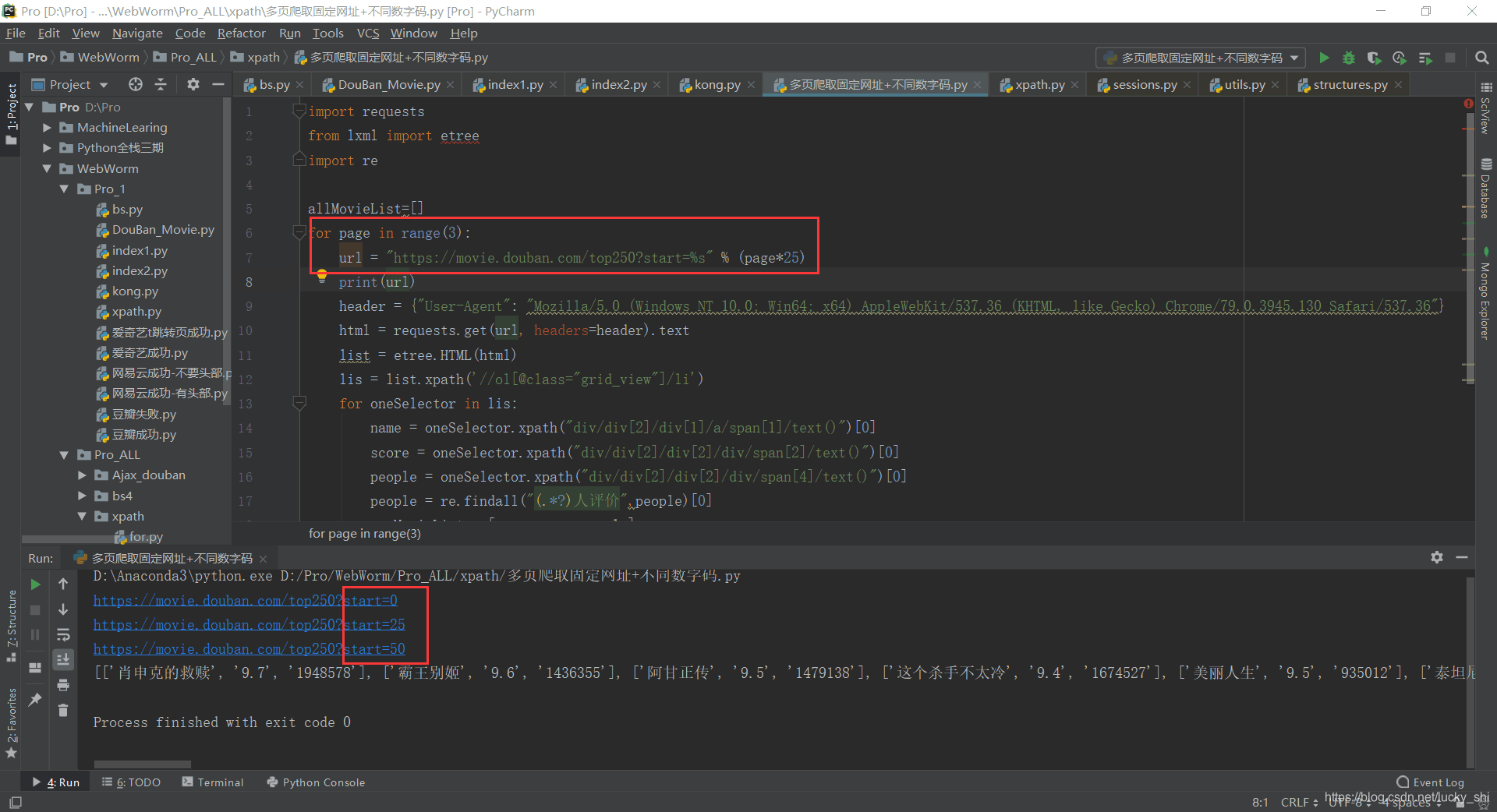


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 44
44 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)