
【hadoop】hbase的安装部署以及相关操作(图文详解)
HBase是一个基于Hadoop的分布式非关系型数据库,其数据模型类似于Google的Bigtable。在HV(Hadoop+Hive)环境中安装和部署HBase需要进行一系列的配置和操作,以确保HBase能够正常工作。以下是我在学习时的收获:***1. 环境确认:***在安装和部署HBase之前,需要确认Hadoop和Hive已经正确安装和配置,并且集群中的所有节点都能够相互通信。***2. 下
引言
HBase是一种基于列存储的分布式数据库系统,它能够快速地存储和处理大规模数据。与传统的关系型数据库不同,HBase采用了分布式的架构,能够实现数据的高可靠性、高可扩展性和高性能。在实际应用中,正确地安装和部署HBase集群是非常重要的。
1、准备环节
1.1设备基本要求
在安装hbase之前,需要虚拟机满足以下几个条件:
1.HBase集群需要依赖Hadoop和Zookeeper,所以 必须保证自己的集群装好了hadoop和zookeeper。在Hadoop中,需要配置HDFS和YARN,以支持HBase的分布式部署和资源管理。在Zookeeper中,需要配置Zookeeper集群,以支持HBase的分布式环境下的协调和管理。
2.存储:HBase需要大量的内存来存储数据,建议虚拟机的磁盘空间不少于100GB。如果虚拟机的存储空间不足,可能会导致HBase无法存储数据或者出现存储空间不足的错误。3.虚拟化技术:HBase可以在虚拟机中运行,需要选择支持硬件虚拟化的虚拟化技术,例如Hyper-V、VMware等,如图1所示。

- 图1·更新后的VMware
1.2安装包
在安装和部署HBase时,需要注意Hadoop与HBase的版本兼容性问题。因为HBase依赖于Hadoop的分布式文件系统HDFS和资源管理框架YARN,而且HBase的各个版本都会对Hadoop的版本有一定的要求。如果选用了不兼容的版本,可能会导致HBase无法正常工作或者出现各种错误。
想要快速了解自己使用的hadoop版本与hbase版本是否兼容,可参考下图。
下图没有的,可以打开该网址进行查看:hadoop与hbase版本兼容性查看
本文使用的hadoop版本与hbase版本分别是hadoop-2.7.1,hbase-1.4.8。
需要下载hbase安装包的可以去以下网址:hbase安装包下载

2、修改相关信息
本文所使用的虚拟机来自于队友,与队友使用的机器不是同一台,所以需要修改IP和IP映射。假如你也是从其他渠道取到别人配置好的hadoop与zookeeper环境的虚拟机,记得修改哦,否则导致无法连接网络等一系列问题。
2.1修改ip
输入一下命令,进入ifcfg-ens33这个文件修改ip,所有集群都要改。
进入后按以下说明修改:
1.设置IP,要和你电脑的VMnet8的IP在同一个网段。假设VMnet8的IP是192.168.233.1,子网掩码是255.255.255.0,那么你的IP就可以设置192.168.233.3 ~ 192.168.233.254中的任意一个IP。
2.设置子网掩码,和你电脑VMnet8的子网掩码一致
3.设置网关,默认xxx.XXX.XXx.2,网段和VMnet8一致
vi /etc/sysconfig/network-scripts/ifcfg-ens33

修改完后输入以下命令重启网卡,重启后ping一下外网,能ping通的话就说明成功了。
systemctl restart network

2.2修改ip映射
输入以下命令,编辑/etc/hosts文件,修改ip映射,所有集群都要改,与前面修改好的ip一致。
vi /etc/hosts

3、安装与部署
3.1.上传安装包
将hbase-1.4.8.tar.gz上传到虚拟机的/usr/local路径。

3.2.解压安装包
解压hhbase-1.4.8.tar.gz到当前路径。
tar -xzvf hbase-1.4.8.tar.gz

3.3.配置HBASE_HOME
3.3.1修改hbase-env.sh
进入hbase-1.4.8/conf/路径下,输入以下命令编辑hbase-env.sh文件,配置JAVA环境变量。
vi hbase-env.sh

3.3.2修改core-site.xml
输入以下命令编辑hbase-site.xml文件, 配置文件如下,可直接复制。然后根据实际情况进行修改。
以下是几个比较重要的配置信息说明:
hbase.rootdir
这个目录是region server的共享目录,用来持久化HBase。URL需要是’完全正确’的。例如,要表示hdfs中的’/hbase’目录,namenode 运行在namenode.example.org的9090端口。则需要设置为hdfs://namenode.example.org:9000/hbase。默认情况下HBase是写到/tmp的。不改这个配置,数据会在重启的时候丢失。
默认: file:///tmp/hbase-${user.name}/hbase
hbase.master.port
HBase的Master的端口.
默认: 60000hbase.master.info.port
HBase Master web 界面端口. 设置为-1 意味着你不想让他运行。
0.98 版本以后默认: 16010 以前是 60010hbase.cluster.distributed
HBase的运行模式。false是单机模式,true是分布式模式。若为false,HBase和Zookeeper会运行在同一个JVM里面。hbase.zookeeper.quorum
Zookeeper集群的地址列表,用逗号分割。例如:“host1.mydomain.com,host2.mydomain.com,host3.mydomain.com”.默认是localhost,是给伪分布式用的。要修改才能在完全分布式的情况下使用。如果在hbase-env.sh设置了HBASE_MANAGES_ZK,这些ZooKeeper节点就会和HBase一起启动。
<configuration>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase:zookeeper.property.dataDir</name>
<value></value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>master,slave1,slave2</value>
</property>
<property>
<name>hbase.master.maxclockskew</name>
<value>180000</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:8020/hbase</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>flase</value>
</property>
<property>
<name>hbase.master.info.port</name>
<value>16010</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
</configuration>
3.3.3修改/etc/profile
用以下命令进入/etc/profile文件,编辑hbase的环境变量,然后使用source方法使profile文件生效。
vi /etc/profile
source /etc/profile

3.3.4拷贝文件
使用scp方法,拷贝hbase-1.4.8文件到其他两个集群的/us/local/下。其中,@后面的参数是集群的名称,冒号后面的参数是目标路径。
scp -r hbase-1.4.8 root@slave1:/usr/local

4、启动
启动habse时,由于hbase依赖于hdfs和zookeeper,所以要先启动hadoop和zookeeper,然后再启动hbase。
4.1启动zookeeper
先使用以下命令对所有集群启动zookeeper,然后使用catjps查看所有集群的进程。看到QuorumPeerMain进程表示启动成功了。
zkServer.sh start

4.2启动hdfs
使用以下两条命令启动hdfs进程和yarn服务。
start-dfs.sh
start-yarn.sh
启动hadoop后,进入web端查看是否启动成功,顺便检查HV有无问题。

4.3启动hbase
以上操作都没问题后,我们就来启动hbase。输入以下命令启动。
然后我们使用catjps查看进程时发现,没有相关的进程在,并没有启动成功,先别急,看下一个章节。(假如是把我的配置文件全部复制去配置,也许到这一步可以启动成功了)
start-hbase.sh

5、问题详情及解决方式
5.1.启动报错
进入hbase配置文件路径,编辑hbase-env.sh配置文件,然后把以下圈起来的两行给注释掉,就不会报错了。

5.2.启动后只有一个相关进程
启动成功后,HMater进程却不在,这个进程非常重要,不可以忽视。
需要在配置文件hbase-site.xml中添加以下信息。需要添加的信息在3.3.2步骤中,已经给出了,可直接复制。


5.3.启动成功了,但是HMster掉线了
好不容易搭好了,启动hbase后,发现进程也都在了。

迫不及待的去web端查看详情,然后发现打不开,被拒绝连接了。

然后又回去查看进程,发现HMaster掉线了

出现这样的问题有很多种情况,这里主要介绍以下三种可能,可查看日志(hbase的日志文件在安装路径的log文件夹下),可根据实际情况逐一排查。
5.3.1.防火墙设置
可输入以下命令进行查看防火墙状态,假如未关闭则需要设置成关闭的状态。
systemctl start firewalld#开启
systemctl stop firewalld#关闭
想要方便一点的可以输入一下命令,防止防火墙自开启,这样就不需要每次都查看防火墙的状态了。
systemctl disable firewalld
5.3.2.时间同步
假如说防火墙是关闭的,但问题暂时没有解决。可根据以下方法继续修改。
1.安装ntpdate工具,网上同步时间
2.设置系统时间与网络时间同步
sudo apt-get install ntpdate
sudo apt-get install ntpdate
5.3.3.hdfs与hbase端口号一致
如果按照步骤做了以上两个步骤还是没有解决,就继续跟着排查吧。在配置文件hbase-site.xml中hbase.rootdir这一项需要和core-site.xml中的fs.defaultFS的地址保持一致,因为这一步是去hdfs上创建hbase的指定文件夹,8020是namenode节点active状态下的端口号,9000端口是fileSystem默认的端口号。由于hdfs的队友搭建的,我们之间缺乏沟通,我的core-site.xml里写的9000,hdfs的端口号是8202,所以启动成功后又挂掉了,导致web端打不开。经过沟通处理后,终于成功了,这就是分组的意义吧,合作沟通。
如以下两张图所示,我们启动后进程都在,也不会自己挂掉了,web端也能打开看到相关信息了,启动成功。


6、hbase操作
目的:
(1)理解 HBase 在 Hadoop 体系结构中的角色。
(2)熟练使用 HBase 操作常用的 Shell 命令。
> 目标:
(1)熟悉hbase相关操作,掌握建表、增数据、查表、删除表等操作。
(2)可以自己建一个表,熟悉上述操作,并插入数据,方便理解与掌握。
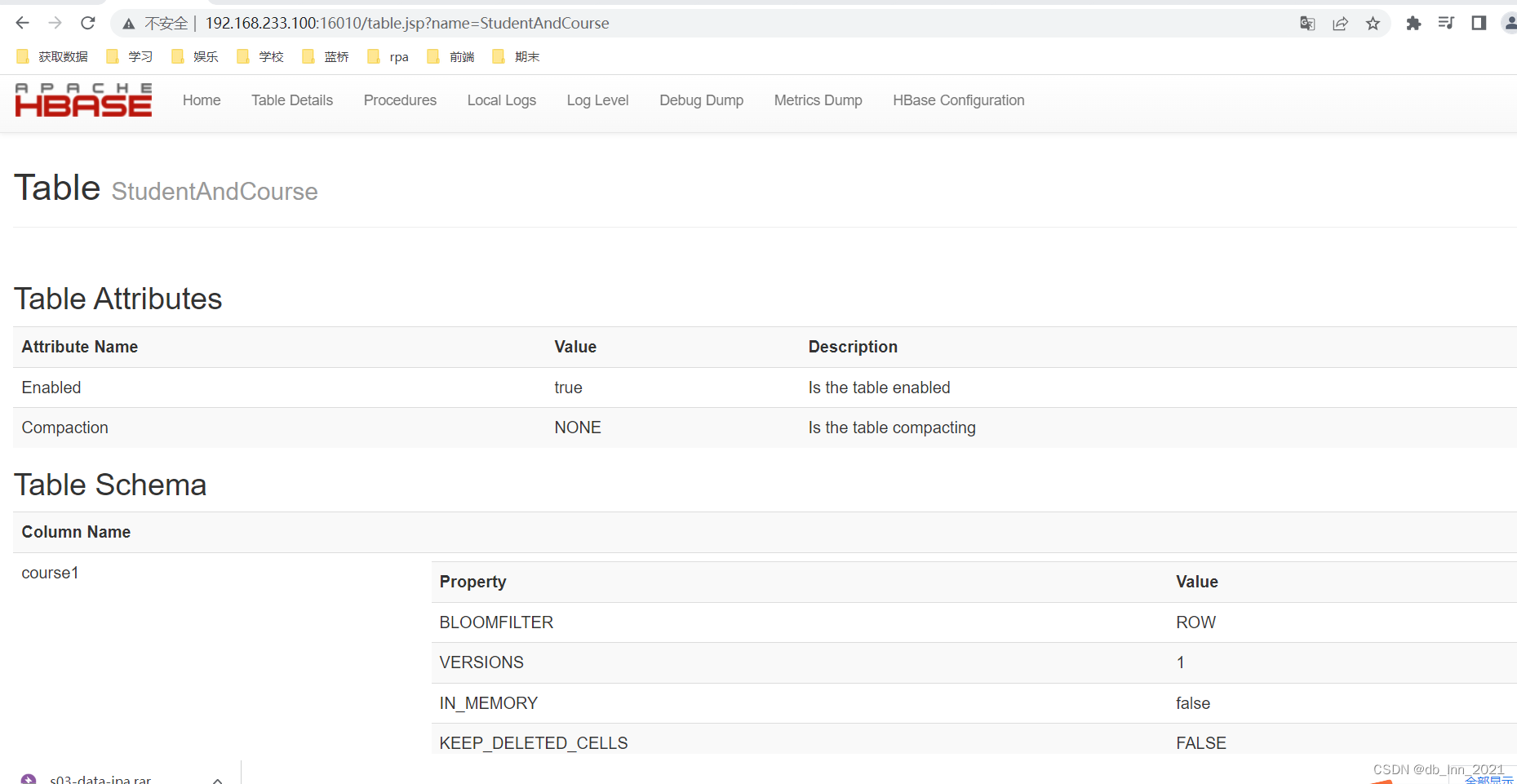
6.1.建表
进行相关操作的步骤:启动zookerper–>启动hadoop–>启动hbase–>打开hbase shell
我用的是以下这种方式建表,需要可直接复制。

create 'StudentAndCourse','student','course1','course2','course3'
6.2.插入数据
插入几条数据测试一下。
put 'StudentAndCourse','2015001','student:S_Name','Zhangsan'
put 'StudentAndCourse','2015001','student:S_Sex','male'
put 'StudentAndCourse','2015001','student:S_Age','23'
put 'StudentAndCourse','2015001','course1:C_No','123001'
put 'StudentAndCourse','2015001','course1:C_Name','Math'
put 'StudentAndCourse','2015001','course1:C_Credit','2.0'
put 'StudentAndCourse','2015001','course1:Score','86'
put 'StudentAndCourse' ,'2015001','course3:C_No','123003'
put 'StudentAndCourse' ,'2015001','course3:C_Name','English'
put 'StudentAndCourse' ,'2015001','course3:C_Credit','3.0'
put 'StudentAndCourse' ,'2015001','course3:Score','69'
6.3.查看数据
scan 'StudentAndCourse'

6.4.删除表
使用drop删除表people,然后使用list方法查看当前数据库现有表发现people库已被删除。

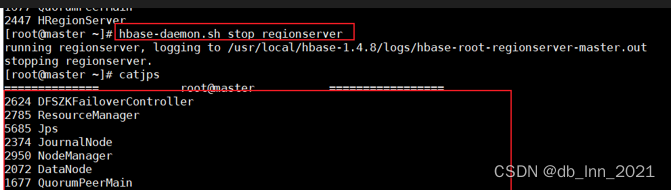
7.停止hbase
使用以下命令停止hbase服务。
stop-hbase.sh
在执行stop-hbase.sh之后.用jps查看进程之后还是发现HRegionServer没有关闭。查看日志并没有报错,经查阅资料发现,执行完操作后,hbase的RegionServer在后台做compact等操作呢,当然关不掉。

对此,分享几个可以单独关闭HRegionServer和HMaster进程的方法,也许在后续学习时,需要单独关掉hbase的某个相关进程,还是很实用的,需要的话可以自取
#单独启动一个HMaster进程:
bin/hbase-daemon.sh start master
#单独停止一个HMaster进程:
bin/hbase-daemon.sh stop master
#单独启动一个HRegionServer进程:
bin/hbase-daemon.sh start regionserver
#单独停止一个HRegionServer进程:
bin/hbase-daemon.sh stop regionserver
单独停止HRegionServer进程后,使用catjps查看所有集群的进程,已经成功关掉了。
收获总结
HBase是一个基于Hadoop的分布式非关系型数据库,其数据模型类似于Google的Bigtable。在HV(Hadoop+Hive)环境中安装和部署HBase需要进行一系列的配置和操作,以确保HBase能够正常工作。以下是我在学习时的收获:
1. 环境确认:在安装和部署HBase之前,需要确认Hadoop和Hive已经正确安装和配置,并且集群中的所有节点都能够相互通信。
2. 下载和解压:从HBase官网下载与hadoop版本对应的HBase,并解压到指定的目录下。
3. 配置文件:修改HBase的配置文件,主要包括hbase-env.sh、hbase-site.xml和/etc/profile等文件。其中,hbase-env.sh文件中需要设置JDK的路径和;hbase-site.xml文件中需要设置HBase的一些参数,比如Zookeeper的地址和端口、HDFS的地址和端口等。
4. 启动HBase:执行start-hbase.sh命令启动HBase。启动成功后,可以使用catjps` 命令查看所有进程HBase进程是否正常运行。
5. 测试HBase:可以使用HBase Shell或Java API等方式测试HBase是否正常工作。在HBase Shell中,可以使用 create 命令创建一个新的表,使用 put 命令向表中插入数据,使用 get 命令查询数据等。
6. 关闭HBase:在HBase的下执行 stop-hbase.sh 命令关闭HBase。
需要注意的是,HBase的配置和使用方法比较复杂,需要根据实际情况进行调整和优化。在实际应用中,还需要考虑HBase的高可用性、负载均衡、数据备份和恢复等问题。因此,在安装和部署HBase之前,需要充分了解HBase的特点和使用方法,同时还需要对Hadoop、Zookeeper等相关技术有一定的了解和掌握。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)