

【图像分类】CNN + Transformer 结合系列.1
介绍三篇结合使用CNN+Transformer进行学习的论文:CvT(ICCV2021),Mobile-Former(CVPR2022),SegNetr(arXiv2307).
介绍三篇结合使用CNN+Transformer进行学习的论文:CvT(ICCV2021),Mobile-Former(CVPR2022),SegNetr(arXiv2307).
CvT: Introducing Convolutions to Vision Transformers, ICCV2021
论文:https://arxiv.org/abs/2103.15808
代码:https://github.com/leoxiaobin/CvT
解读:CvT | CNN+Vision Transformer会有什么样的火花呢? - 知乎 (zhihu.com)
读论文之transformer系列-CvT:将卷积引入transformer_卷积transformer_dear_queen的博客-CSDN博客
简介
提出了一种新的架构,名为卷积视觉转换器(Convolutional vision Transformer,CvT),通过在视觉转换器(ViT)中引入卷积,以产生两种设计的最佳效果,从而提高了性能和效率。这是通过两个主要修改来实现的:包含新的卷积令牌嵌入的Transformer层次结构,以及利用卷积投影的卷积Transformer块。这些变化将卷积神经网络(cnn)的理想特性引入到ViT架构中(即移动、缩放和失真不变性),同时保持了transformer的优点(即动态关注、全局上下文和更好的泛化)。
做法
CvT设计在ViT架构的2个核心部分引入了卷积:
首先,将Transformer划分为多个阶段,形成一个分层结构的Transformer。每个阶段的开始由一个卷积Token嵌入组成,该卷积Token嵌入在一个二维重塑的Token映射上进行卷积操作(即,将Flattened的Token序列重塑回空间网格),然后是Layer Normalization。这个操作使得模型不仅可以捕获局部信息,而且还可以逐步减少序列长度,同时在不同阶段增加Token特征的维数,实现空间下采样,同时增加特征映射的数量。
其次,将Transformer模块中每个Self-Attention Block之前的线性投影替换为卷积投影,该卷积投影在二维重塑的Token映射上采用s×s深度可分卷积。这使得该模型在注意力机制中能够进一步捕获局部空间语义信息,减少语义歧义。它还允许管理计算复杂度,因为卷积的Stride可以用于对键和值矩阵进行子采样,以提高4倍或更多的效率,同时最小化性能的损失。
相关工作
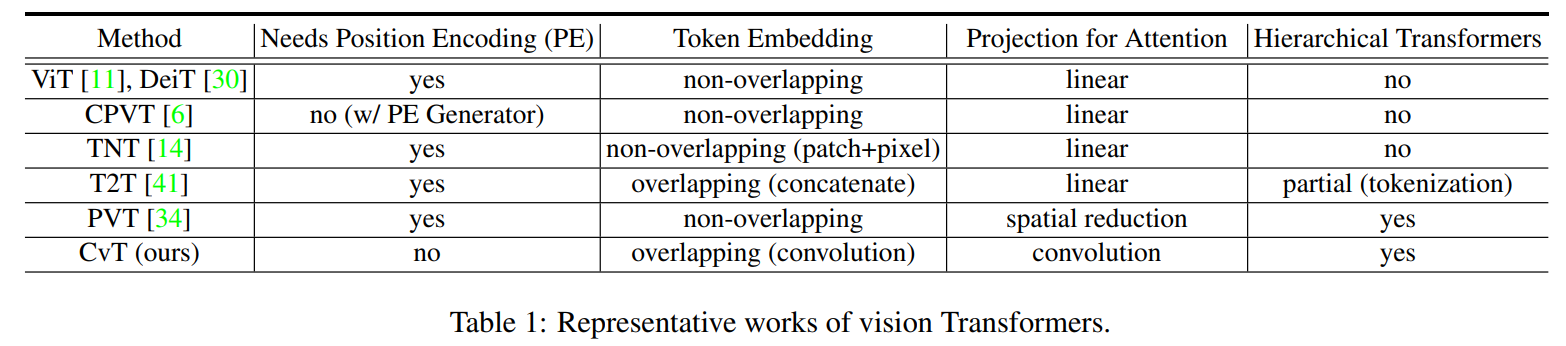
与现有工作相比,本文工作的目标是通过引入卷积,在图像域特定的归纳偏差,以达到最好的Transformer结构。表1显示了上述具有代表性作品和本文CvT在位置编码的必要性、Token嵌入类型、映射类型和Backbone中的Transformer结构方面的主要区别。
向CNN引入Self-Attention :Non-Local Network的设计是为了通过全局Attention来捕捉长期依赖关系。Local Relation Networks 根据local windows内像素/特征之间的组成关系(相似度)来进行权值聚合,而卷积层则在空间相邻的输入特征上采用固定的权值聚合。这种自适应权值聚合将几何先验引入到网络中,这对识别任务很重要。
本文则是向Transformer引入CNN:卷积被用来修改Transformer Block,或者用卷积层代替Multi-Head Attentions,亦或是以并行或顺序的方式增加额外的卷积层,以捕获局部关系。
本文推荐在Vision Transformer的2个主要部分引入卷积:
- 首先,使用卷积投影操作取代现有的Position-wise线性投影;
- 其次,类似于CNN,使用分层多级结构和不同分辨率的2D Reshaped Token Maps。
CvT 方法
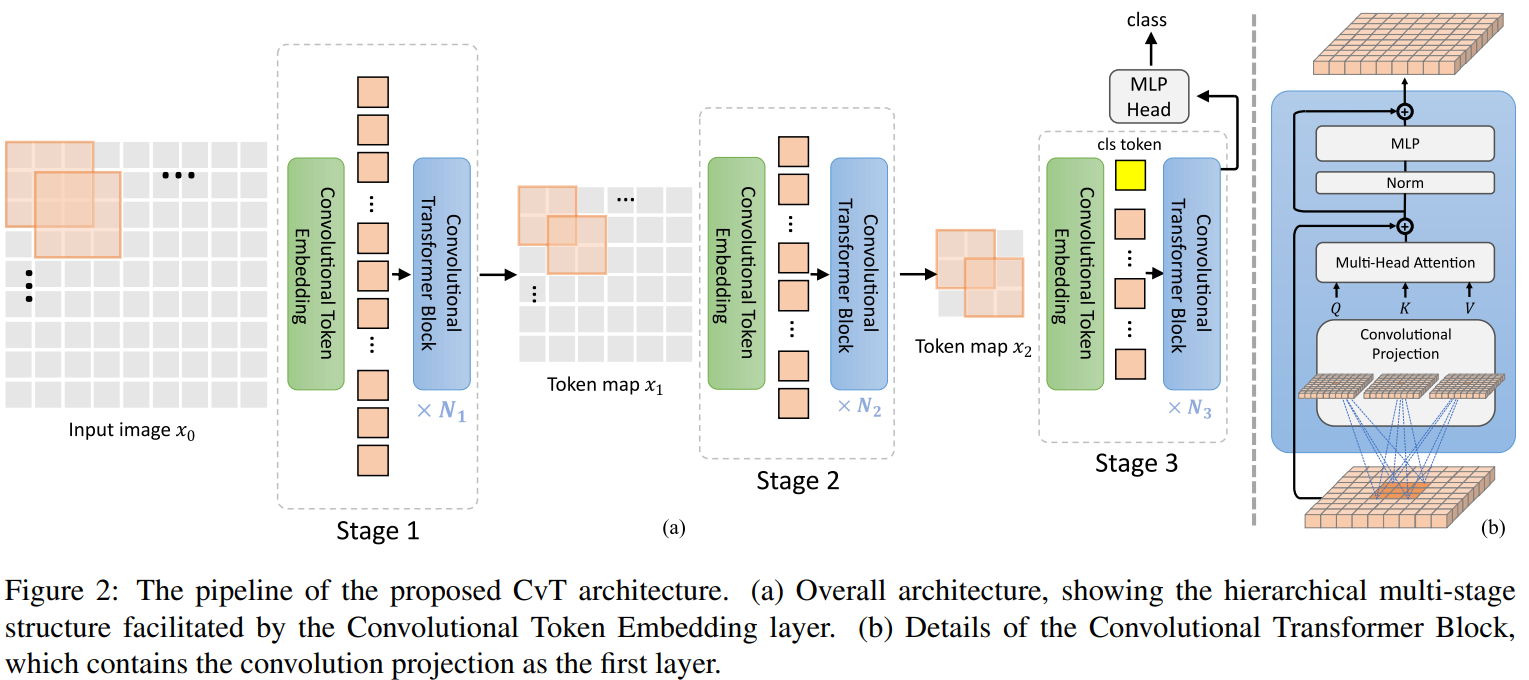
在ViT架构中引入了2种基于卷积的操作,即卷积令牌嵌入(Convolutional Token Embedding)和卷积投影( Convolutional Projection)。如图2(a)所示,本文借鉴了CNN的多阶段层次设计,共采用了3个阶段:
- 首先,输入图像经过卷积Token嵌入层,卷积层是将重构Token的重叠块卷积到二维空间网格作为输入(重叠程度可通过步长来控制)。对Token应用额外的LN(层归一化)。这允许每个阶段逐步减少Token的数量(即特征分辨率),同时增加Token的宽度(即特征维度),从而实现空间下采样和增加R的丰富度。
- 然后,叠加一些卷积Transformer Block组成每个阶段的残差部分。图2(b)展示了卷积Transformer Block的架构,其中使用深度可分离的卷积运算,称为卷积映射,分别用于查询、键和值的嵌入,而不是ViT中标准的位置线性映射。
- 最后,在最后阶段输出的分类标记上使用MLP来预测结果。
卷积令牌嵌入(Convolutional Token Embedding)
CvT中的卷积操作旨在通过一种类似CNNs的多级层次方法从Low-level到High-Semantic模拟局部空间Context。

卷积Token嵌入层允许通过改变卷积运算的参数来调整每个阶段的Token特征维数和数量。通过这种方式,在每个阶段逐步减少Token序列长度,同时增加Token特征维数。这使得Token能够在越来越大的空间上表示越来越复杂的视觉模式,类似于CNN的特征层。
卷积投影( Convolutional Projection)
卷积投影层的目标是实现对局部空间Context的额外建模,并通过允许K和V矩阵的欠采样来提高效率。

本文提出的Transformer块具有卷积映射是对原Transformer块的推广。用具有深度可分离卷积的Multi-Head Self-Attention(MHSA)代替原来的位置线性映射进而形成卷积映射层。

图3(b)显示了本文提出的s×s卷积投影。如图3(b)所示,首先将Token重塑为2D Token Map。接下来,使用核大小为s的深度可分离卷积层来实现卷积映射。最后,映射后的Token被平展为1D以供后续处理。
![]()
其中x是第i层Q/K/V矩阵的Token输入,x_i是卷积投影之前的未扰动Token,Conv2d是深度可分离卷积,其实现方式为:Depth-wise Conv2d—>BatchNorm2d—>Point-wise Conv2d,s为卷积核大小。
效率考虑
本文设计的卷积投影层有2个效率上的好处:
- 首先,利用了有效的卷积。直接使用标准的s×s卷积进行卷积映射需要
个参数和
的FLOPs,其中C是Token通道维数,T是要处理的Token数量。相反,将标准的s×s卷积分解为深度可分离的卷积。这样,与原始的位置线性映射相比每个卷积映射只会引入额外的
个参数和
的FLOPs,相对于模型的总参数和FLOPs,这些都可以忽略。
- 其次,利用提出的卷积投影来减少MHSA操作的计算成本。s×s卷积投影允许通过使用大于1的步长来减少Token的数量。图3(c)显示了卷积投影,其中的key和value投影是通过步长大于1的卷积进行下采样的,文章对key和value投影使用步长2,而对query保持不变使用步长1。这样,key和value的token数量减少了4倍,以后的MHSA操作计算成本减少了4倍。这带来了最小的性能损失,因为图像中的邻近像素/补丁往往在外观/语义上有冗余。另外,所提出的卷积投影的局部Context建模可以弥补分辨率降低所带来的信息损失。
删除位置嵌入
对每个Transformer块引入卷积映射结合卷积Token嵌入能够通过网络建模局部空间关系。这个内置属性允许在不影响性能的情况下删除网络中嵌入的位置,从而简化了具有可变输入分辨率的视觉任务的设计。
模型架构

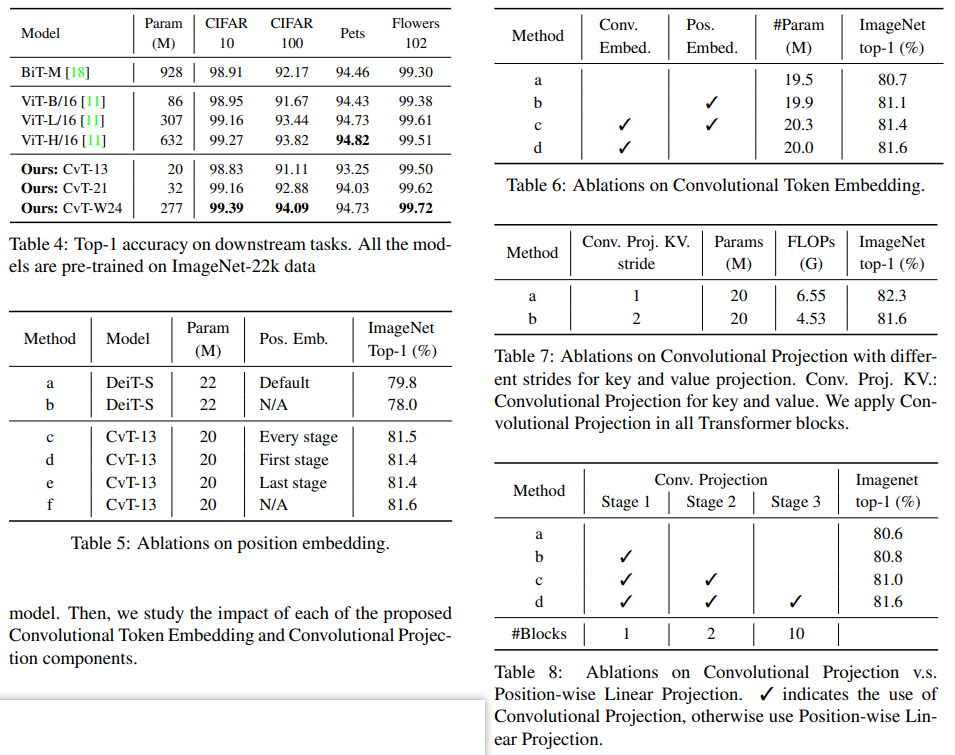
实验

Mobile-Former: Bridging MobileNet and Transformer, CVPR2022
论文:https://arxiv.org/abs/2108.05895
代码:https://github.com/AAboys/MobileFormer
CVPR 2022 | Mobile-Former来了!微软提出:MobileNet+Transformer轻量化并行网络 - 知乎 (zhihu.com)
CVPR2022 | Mobile-Former:连接MobileNet和Transformer(微软&中科大提出) - 知乎 (zhihu.com)
简介
提出Mobile-Former,一种通过双线桥将MobileNet和Transformer并行的结构。这种方式融合了MobileNet局部性表达能力和Transformer全局表达能力的优点,这个桥能将局部性和全局性双向融合。和现有Transformer不同,Mobile-Former使用很少的tokens(例如6个或者更少)随机初始化学习全局先验,计算量更小。
如何设计有效的网络来有效地编码局部处理和全局交互?一个简单的想法是将卷积和Vision Transformer结合起来。最近的研究表明,将卷积和Vision Transformer串联在一起,无论是在开始时使用卷积,还是将卷积插入到每个Transformer块中都是有益的。


本文将设计范式从串联向并联转变,提出了一种新的MobileNet和Transformer并行化,并在两者之间建立双向桥接,命名为Mobile-Former,其中Mobile指MobileNet, Former指transformer。Mobile以图像为输入堆叠mobile block(或inverted bottleneck)。它利用高效的depthwise和pointwise卷积来提取像素级的局部特征。前者以一些可学习的token作为输入,叠加multi-head attention和前馈网络(FFN)。这些token用于对图像的全局特征进行编码。
Mobile-Former是MobileNet和Transformer的并行设计,中间有一个双向桥接。这种结构利用了MobileNet在局部处理和Transformer在全局交互方面的优势。 并且该桥接可以实现局部和全局特征的双向融合。
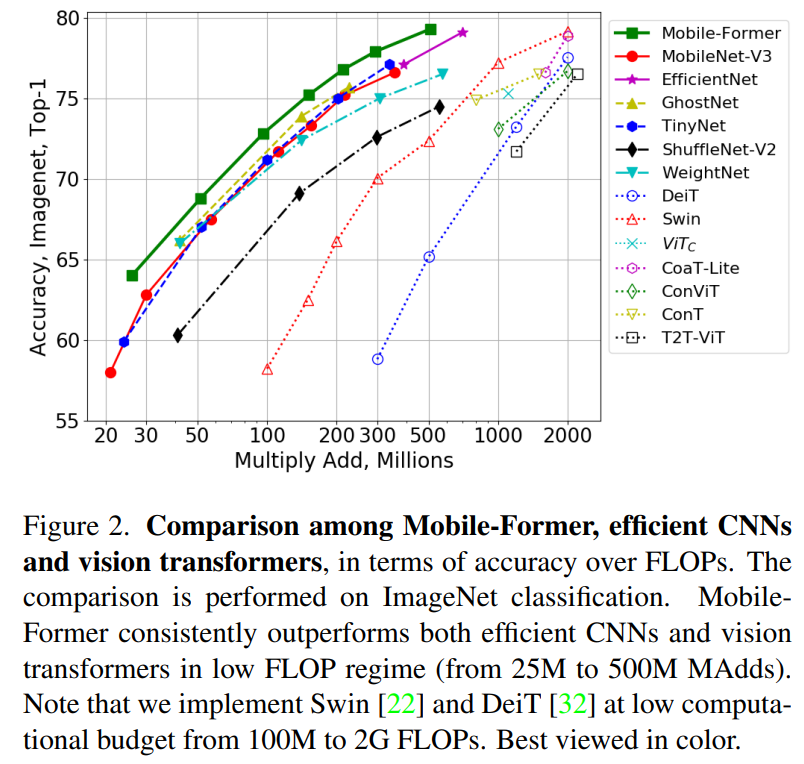
结合提出的轻量级交叉注意力对桥接进行建模,Mobile-Former不仅计算效率高,而且具有更强的表示能力,在ImageNet分类上从25M到500MFLOPs的低 FLOPs机制下优于MobileNetV3。
Mobile-Former方法
Mobile-Former将MobileNet和transformer并行化,并通过双向交叉注意力将两者连接起来(见图1)。Mobile-former中,Mobile(简称MobileNet)以一幅图像作为输入(),采用inverted bottleneck block提取局部特征。前者(指transformer)以可学习参数(或token)作为输入,记为
,其中d和M分别为token的维数和数量。这些token被随机初始化,每个token表示图像的全局先验。这与Vision Transformer(ViT)不同,在ViT中,token线性地投射局部图像patch。这种差异非常重要,因为它显著减少了token的数量从而产生了高效的Former。
低成本双线桥(Low Cost Two-Way Bridge)
Mobile和Former通过双线桥将局部和全局特征双向融合。这两个方向分别表示为Mobile→Former和Mobile←Former。利用cross attention的优势融合局部特性(来自Mobile)和全局token(来自Former)。这里为了降低计算成本介绍了2个标准cross attention计算:
- 在channel数较低的MobileNet Bottlneck处计算cross attention;
- 在Mobile position数量很大的地方移除预测
,但在Former中保留。


Mobile-Former块
Mobile-Former由Mobile-Former块组成(见图1)。每个块包含四部分:Mobile子块、Former子块以及双向交叉注意力Mobile←Former和Mobile→Former(如图3所示)。
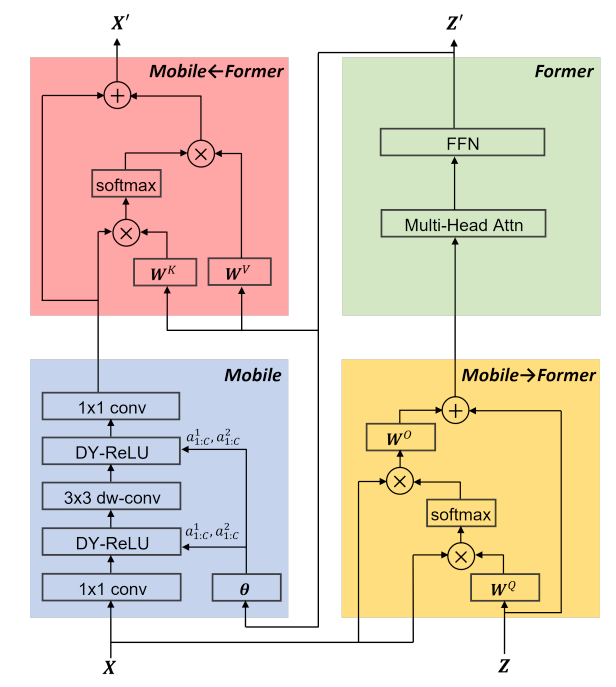

输入和输出: Mobile-Former块有2个输入:
- 局部特征图
,具有C通道和L空间位置(L=hw,其中h和w为特征图的高度和宽度);
- 全局token
,其中M和d分别是token的数量和维数。
Mobile-Former块输出更新后的局部特征映射为和全局token
,用作下一个(i+1)块的输入。注意,全局token的数量和维度在所有块中都是相同的。
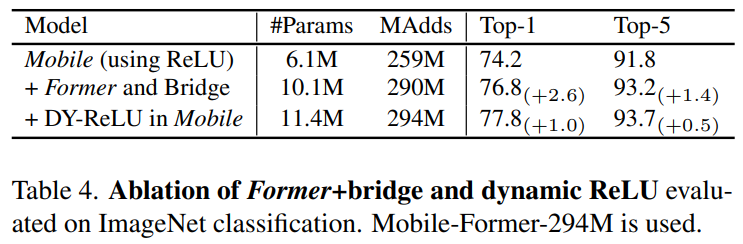
Mobile sub-block: Mobile子块以feature map 为输入。与MobileNet中的inverted bottleneck block略有不同,在第一次pointwise卷积和3×3深度卷积后用dynamic ReLU代替ReLU作为激活函数。
与原来的dynamic ReLU不同,在平均池化特征上使用两个MLP层生成参数,而在前者输出的第一个全局token上使用2个MLP层(图3中的θ)保存平均池化。注意,对于所有块,深度卷积的核大小是3×3。将Mobile sub-block的输出表示为,作为Mobile Former的输入(见图3),其计算复杂度为O(2LEC^2 + 9LEC),其中L为空间位置数,E为通道展开比,C为展开前通道数。
Former sub-block: Former子块是一个标准的Transformer块,包括一个多头注意力(MHA)和一个前馈网络(FFN)。在FFN中,膨胀率为2(代替4)。使用post层归一化。Former在Mobile→Former和Mobile←Former之间处理(见图3)。其复杂性为O(M^2d + Md^2)。
Mobile→Former:文章提出的轻量级交叉注意力(式1)用于将局部特征X融合到全局特征 tokens Z。与标准注意力相比,映射矩阵的键和值
(在局部特征X上)被移除以节省计算(见图3)。
Mobile←Former:这里的交叉注意力(式2) 与Mobile→Former的方向相反,其将全局tokens融入本地特征。局部特征是查询,全局tokens是键和值。因此,我们保留键和值
中的映射矩阵,但移除查询
的映射矩阵以节省计算,如图3所示。
计算复杂度:Mobile-Former块的四个核心部分具有不同的计算成本。给定输入大小为HW×C的特征图,以及尺寸为d的M个全局tokens,Mobile占据了大部分的计算量。Former和双线桥是重量级的,占据不到总计算成本的20%。具体而言,Former的自注意力和FFN具有复杂度
。 Mobile→Former和Mobile←Former共享交叉注意力的复杂度
。
架构
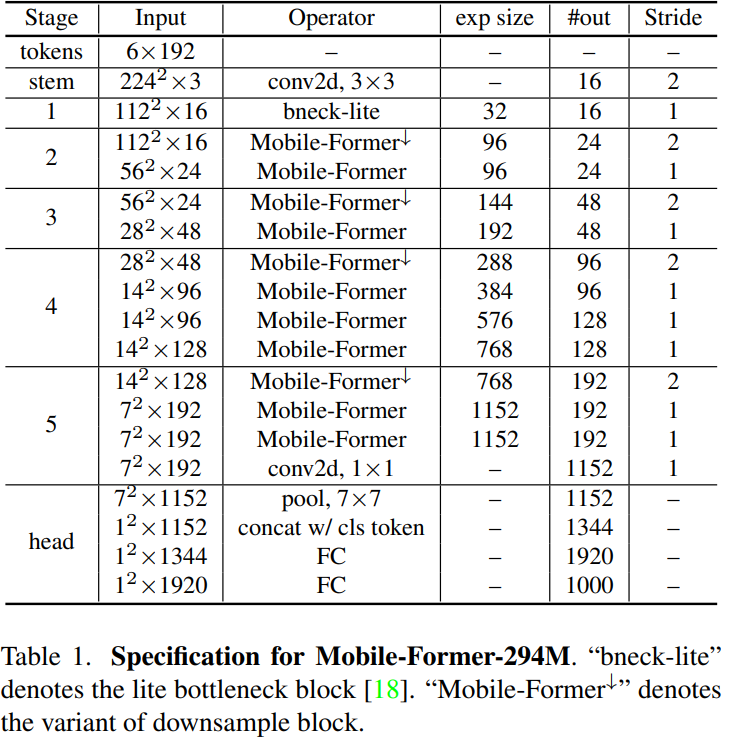
表1显示了一个Mobile-Former架构,图像大小为224×224,294M FLOPs,以不同的输入分辨率堆叠11个Mobile-Former块。所有块都有6个维度为192的全局tokens。它以一个3×3的卷积作为stem和第一阶段的轻量瓶颈块,首先膨胀,然后通过3×3 depth-wise卷积和point-wise卷积压缩通道数。第2-5阶段包括 Mobile-Former块。每个阶段的下采样,表示为↓ 。分类头在局部特征应用平均池化,首先和全局tokens concat到一起,然后经过两个全连接层,中间是h-swish激活函数
Mobile-Former用于目标检测:

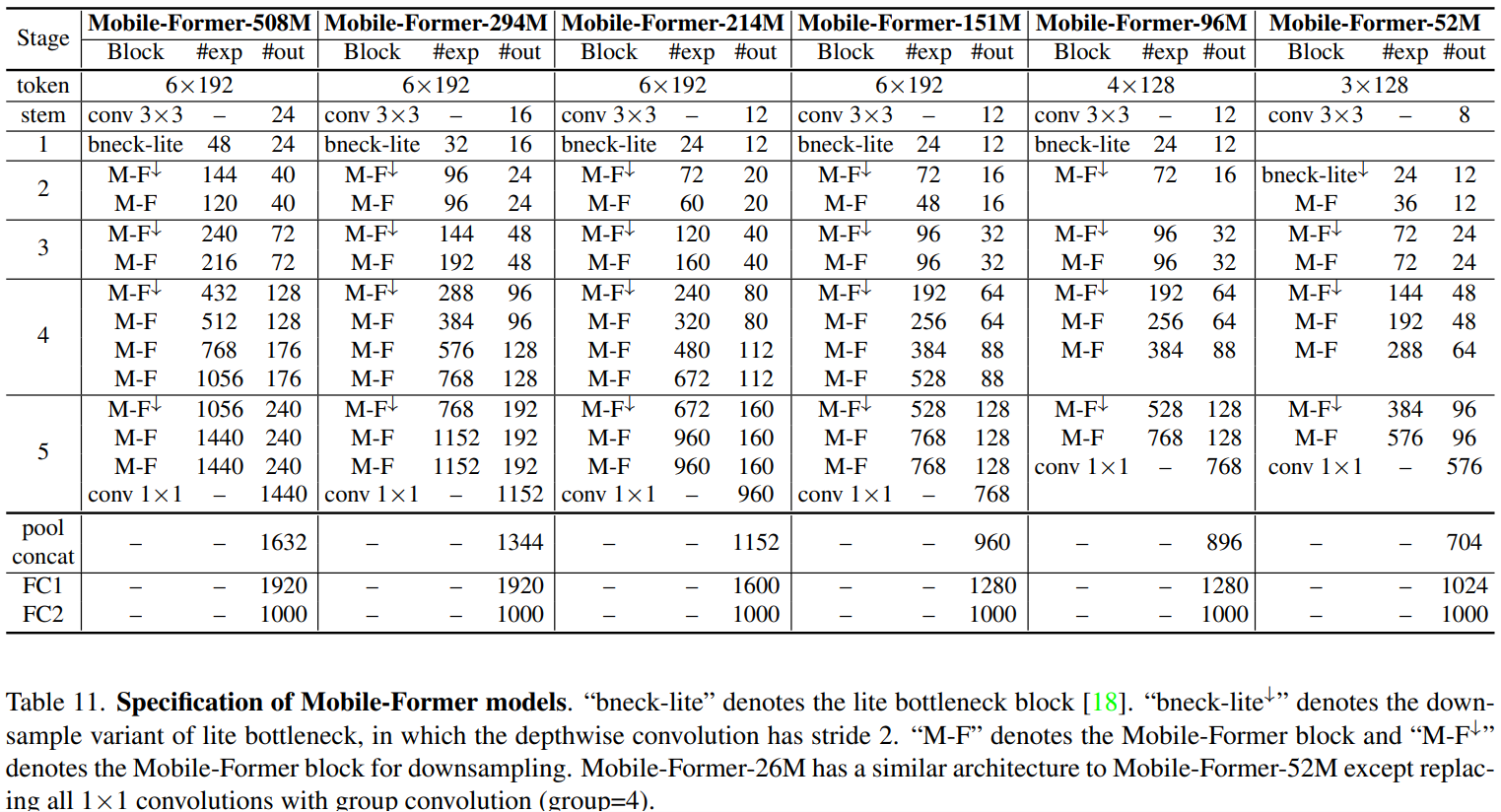
Mobile-Former变体:
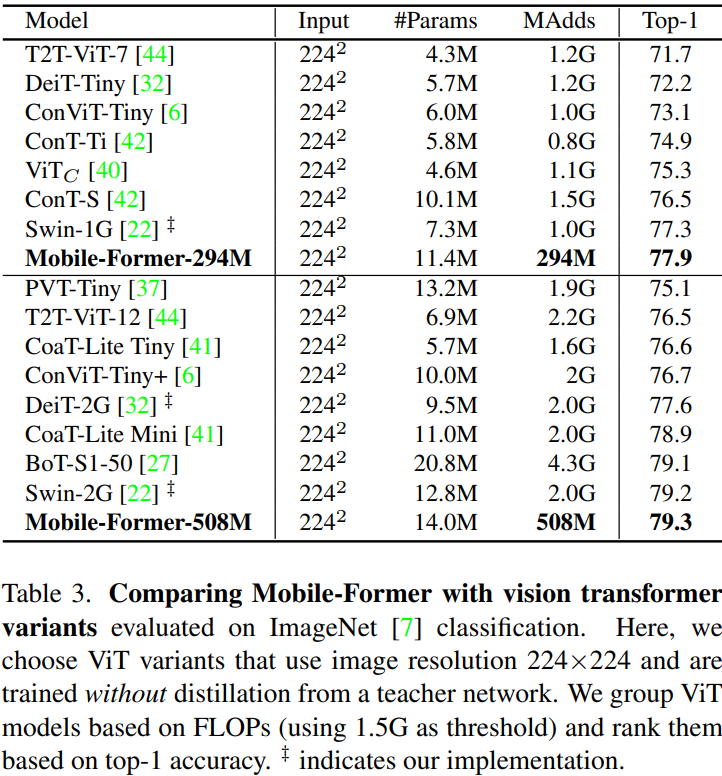
实验


SegNetr: Rethinking the local-global interactions and skip connections in U-shaped networks, arXiv2307
论文:https://arxiv.org/abs/2307.02953
代码:暂未开源
解读:SegNetr来啦 | 超越UNeXit/U-Net/U-Net++/SegNet,精度更高模型更小的UNet家族 - 知乎 (zhihu.com)
简介
近年来,U型网络因其结构简单、易于调整而在医学图像分割领域占据主导地位。然而,现有的U形分割网络
- 多集中于设计复杂的自注意模块来弥补基于卷积运算的长期依赖性的不足,这增加了网络整体的参数数量和计算复杂度;
- 简单地融合编码器和解码器的特征,忽略了它们空间位置之间的联系。
论文对上述问题进行了反思,构建了一种轻量级医学图像分割网络SegNetr,具体来说,
- 作者引入了一种新型的SegNetr块,它可以在任何阶段动态地执行局部-全局交互,并且只需线性复杂度。
- 同时,作者设计了一种通用的信息保留远跳连接Information Retention Skip Connection(IRSC),以保留编码器特征的空间位置信息并实现与解码器特征的精确融合。
在四个主流医学图像分割数据集上验证了SegNetr的有效性,其参数和GFLOPs分别比普通U-Net少59%和76%,同时获得了与最先进方法相当的分割性能。
作者重新设计了基于窗口的局部全局交互,并将其插入到纯卷积框架中,以弥补卷积在捕捉全局特征方面的不足,并降低自注意力操作产生的高计算成本。
通过改进以下两个方面来提高U-shaped网络的效率和性能:
- 局部-全局交互。网络通常需要处理医学图像中不同大小的目标,而局部全局交互可以帮助网络更准确地理解图像的内容。
- 编码器-解码器之间的空间连接。使用编码器-解码器之间的空间信息可以获得语义上更强和位置上更准确的特征。
基于以上分析,本文对U-shaped网络的设计进行了重新思考。具体来说,作者构建了轻量级的SegNetr(带Transformer的分割网络)块,以在non-overlapping的窗口上动态学习局部全局信息,并保持线性复杂性。作者提出了Information Retention Skip Connection(IRSC),它专注于编码器和解码器空间位置之间的连接,保留更多的原始特征,以帮助在上采样阶段恢复特征图的分辨率。
本文的贡献可以总结如下:
- 作者提出了一种计算成本更低、分割性能更好的轻量级U-shaped SegNetr分割网络;
- 作者研究了传统的U-shaped Skip Connection框架的潜在缺陷,并改进了具有信息保留的Skip Connection;
- 当作者将本文提出的分量应用于其他U-shaped方法时,分割性能得到了一致的提高。
SegNetr方法
SegNetr是一个分层的U-shaped网络,其重要组成部分包括SegNetr块和IRSC。SegNetr块通过并行的局部-全局分支进行交互。IRSC保留了编码器特征的位置信息,并实现了与解码器特征的精确融合。

为了使网络更加轻量级,作者使用MBConv作为基础卷积构建模块。SegNetr块在编码器和解码器阶段实现了动态的局部-全局交互。Patch合并用于在不丢失原始图像信息的情况下将分辨率降低两倍。
IRSC用于融合编码器和解码器特征,随着深度的加深减少网络丢失的详细信息。
SegNetr Block
受窗口注意力方法的启发,作者构造了只需要线性复杂性就能实现局部全局交互的SegNetr块。设输入特征图为。作者首先使用MBConv提取特征
,与通常的卷积层相比,它提供了非显式的位置编码。
局部交互可以通过计算non-overlapping的patch的注意力矩阵(P表示patch大小)来实现。
- 首先,作者使用无计算成本的局部分区(LP)操作将
划分为一系列空间连续的Patch
(图1显示了P=2的Patch大小)。
- 然后,作者对通道维度的信息进行平均,并对空间维度进行flatten,以获得
,将其输入到FFN中进行线性计算。由于通道方面的重要性在MBConv中进行了权衡,因此作者在执行局部交互时重点关注空间注意力的计算。
- 最后,作者使用Softamx来获得空间维度的概率分布,并对输入特征
考虑到局部交互是不够的,并且可能存在不足的问题,作者还设计了并行的全局交互分支。首先,作者使用全局分区(GP)操作来聚合空间上的非连续Patch。GP将窗口位移的操作添加到LP中,目的是改变特征在空间中的总体分布(图中的全局分支1显示了位移后Patch空间位置的变化)。对于水平方向上的奇数patch,位移规则为向左一个窗口(对于向右的偶数patch,反之亦然),对于垂直方向上的奇patch,向上一个窗口,向下一个窗口。请注意,patch的位移不具有任何计算成本,并且仅发生内存变化。
与Swin Transformer的滑动窗口操作相比,作者的方法在本质上更具全局性。然后,作者将空间移位的特征图分解为2P块,并执行全局注意力计算(类似于局部交互分支)。尽管相对于局部交互操作,全局交互在更大的窗口上计算注意力矩阵,但所需的计算量远小于标准自注意力模型的计算量。
局部和全局分支最终通过加权求和进行融合,在此之前,需要通过LP和GP反转操作(即局部反转(LR)和全局反转(GR))来恢复特征图形状。此外,作者的方法还采用了 Transformer 的有效设计,如范数、前馈网络(FFN)和残差连接。
大多数Transformer模型使用固定大小的Patch,但这种方法限制了它们在早期阶段关注更广泛的区域。本文通过应用动态大小的Patch来缓解这个问题。在编码器阶段,作者依次使用(8,4,2,1)的Patch来计算局部注意力,全局分支将Patch扩展到(16,8,4、2)的大小。为了减少超参数设置,解码器的Patch与相应级的编码器Patch具有相同的大小。
Information Retention Skip Connection (IRSC)
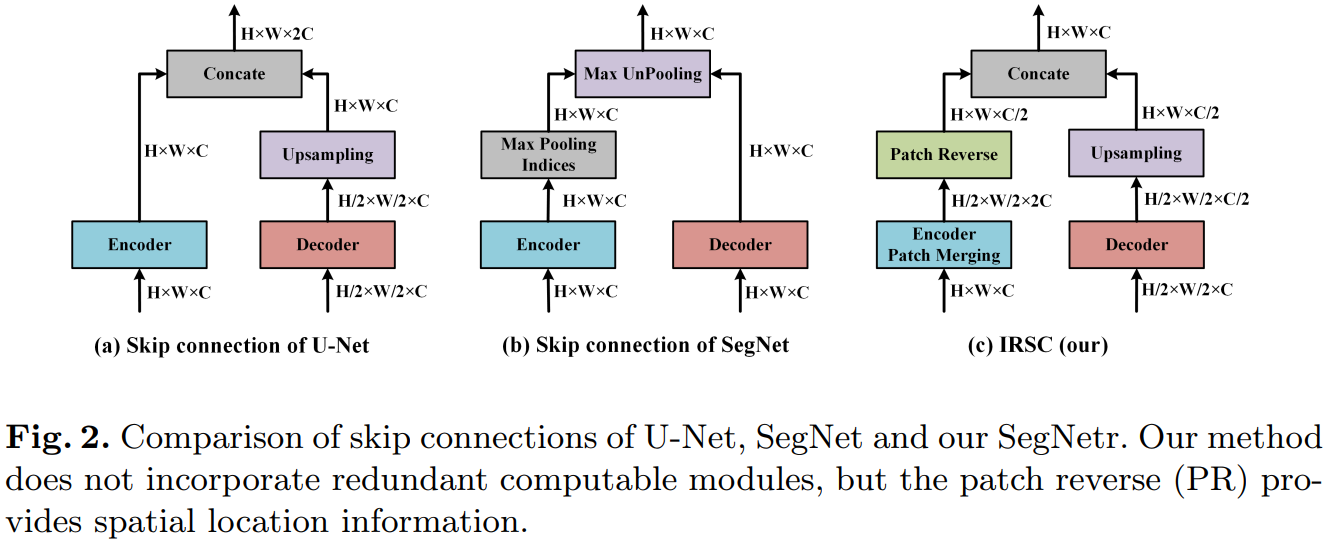
图2显示了3种不同类型的Skip Connection。U-Net在编码器和解码器的相应阶段拼接通道维度,允许解码器在执行上采样时保留更高分辨率的细节信息。SegNet通过在编码器中保留下采样过程的位置信息来帮助解码器恢复特征图分辨率。
作者设计IRSC以考虑这两个特征,即在实现浅特征和深特征融合的同时保留编码器特征的位置信息。具体地说,编码器中的Patch合并(PM)操作将输入特征图的分辨率降低到原始分辨率的2倍,而通道维度扩展到原始维度的4倍,以获得
。PM操作的本质是在没有任何计算成本的情况下将空间维度上的信息转换为通道表示,并保留输入特征的所有信息。
IRSC中的Patch反向(PR)用于恢复编码器的空间分辨率,它是与PM的倒数运算。作者交替选择XPM的一半通道数(即)作为PR的输入,一方面可以减少编码器中的冗余特征,另一方面可以对齐解码器中的特征通道数。与传统的上采样方法相比,PR在很大程度上减少了信息丢失的问题,同时提供了准确的位置信息。最后,将PR的输出特征
与解码器的上采样特征融合,用于下一阶段的学习。
实验
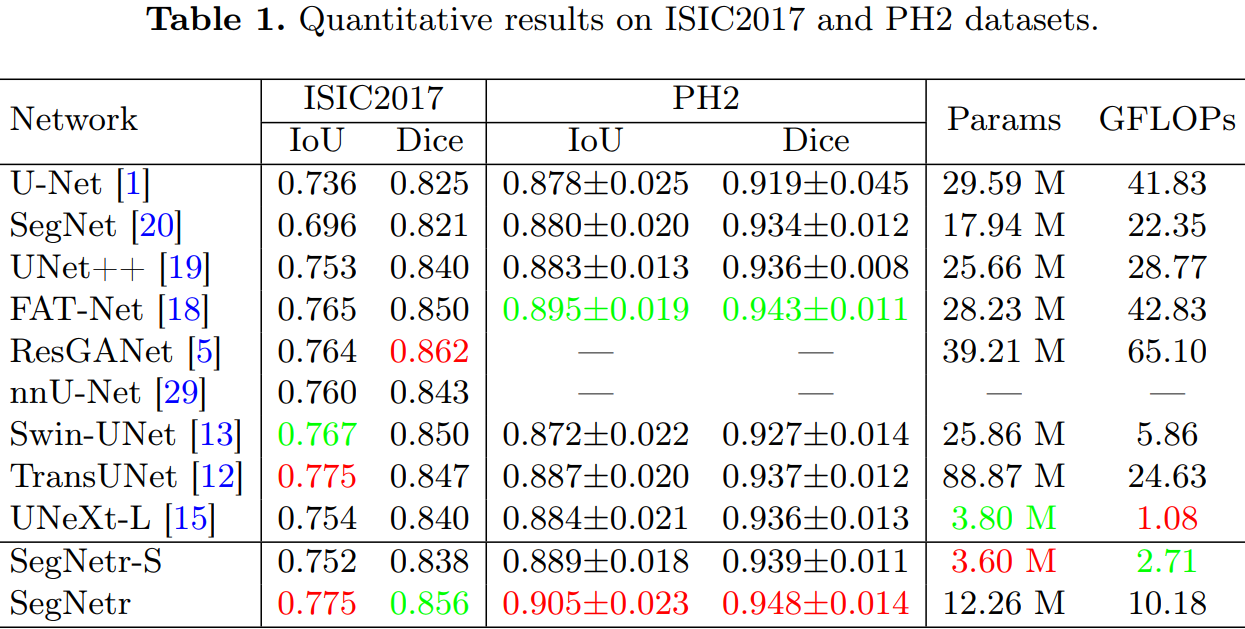
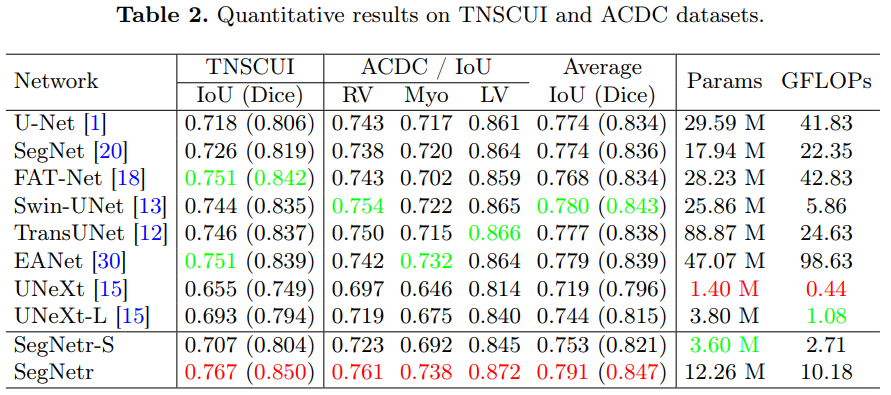

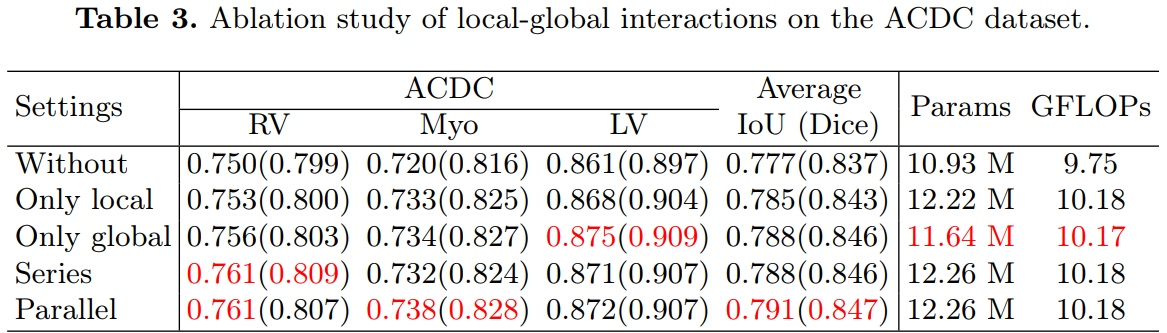
局部-全局交互作用的影响:通过添加局部或全局交互,提高了网络对不同类别的分割性能。
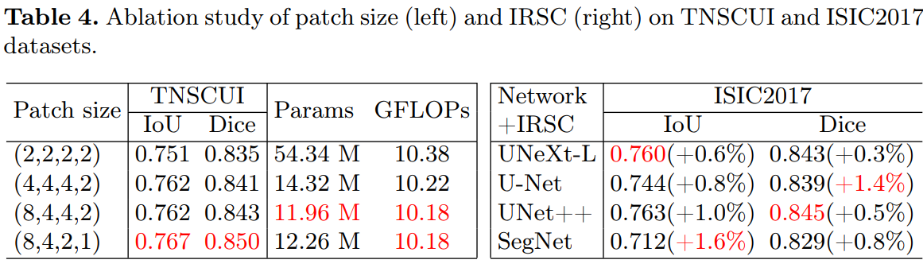
patch size的影响 和 IRSC的影响:

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 7
7 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)