
Mybatis-Plus入门系列(13)- MybatisPlus之自定义ID生成器
数据库ID生成策略在数据库表设计时,主键ID是必不可少的字段,如何优雅的设计数据库ID,适应当前业务场景,需要根据需求选取合适高效的策略,在复杂分布式系统中,往往需要对大量的数据和消息进行唯一标识,下面介绍下常用的几种ID生成策略。Sequence ID(数据库自增)数据库自增长序列或字段,最常见的方式。由数据库维护,数据库表唯一。优点:简单,代码方便,性能可以接受。数字ID天然排序,对分页或者需
数据库ID生成策略
在数据库表设计时,主键ID是必不可少的字段,如何优雅的设计数据库ID,适应当前业务场景,需要根据需求选取合适高效的策略,在复杂分布式系统中,往往需要对大量的数据和消息进行唯一标识,下面介绍下常用的几种ID生成策略。
Sequence ID(数据库自增)
数据库自增长序列或字段,最常见的方式。由数据库维护,数据库表唯一。
优点:
- 简单,代码方便,性能可以接受。
- 数字ID天然排序,对分页或者需要排序的结果很有帮助。
缺点:
- 不同数据库语法和实现不同,数据库迁移的时候或多数据库版本支持的时候需要处理。
- 在单个数据库或读写分离或一主多从的情况下,只有一个主库可以生成。有单点故障的风险。
- 在性能达不到要求的情况下,比较难于扩展。
- 如果遇见多个系统需要合并或者涉及到数据迁移会相当痛苦。
- 分表分库的时候会有麻烦。
UUID
UUID(Universally Unique Identifier)的标准型式包含32个16进制数字,以连字号分为五段,形式为8-4-4-4-12的36个字符。
它通过MAC地址、时间戳、命名空间、随机数、伪随机数来保证生成ID的唯一性。
使用JAVA代码生成:
String uuid = UUID.randomUUID().toString();
System.err.println(uuid); // a299d6ef-9f82-475e-b3d5-f16df808fea1
System.err.println(uuid.length());
使用Mysql函数生成:
UUID()
UUID主要有五个算法:
- uuid1()
基于时间戳。由MAC地址、当前时间戳、随机数生成。可以保证全球范围内的唯一性,但MAC的使用同时带来安全性问题,局域网中可以使用IP来代替MAC。 - uuid2()
基于分布式计算环境DCE(Python中没有这个函数)。算法与uuid1相同,不同的是把时间戳的前4位置换为POSIX的UID。实际中很少用到该方法。 - uuid3()
基于名字的MD5散列值。通过计算名字和命名空间的MD5散列值得到,保证了同一命名空间中不同名字的唯一性,和不同命名空间的唯一性,但同一命名空间的同一名字生成相同的uuid。 - uuid4()
基于随机数。由伪随机数得到,有一定的重复概率,该概率可以计算出来。 - uuid5()
基于名字的SHA-1散列值。算法与uuid3相同,不同的是使用 Secure Hash Algorithm 1 算法。
优点:
- 简单,代码方便。
- 全球唯一,在遇见数据迁移,系统数据合并,或者数据库变更等情况下,可以从容应对。
- 本地生成,没有网络消耗。
缺点: - 不易于存储:UUID太长,16字节128位,通常以36长度的字符串表示,很多场景不适用。
- 信息不安全:基于MAC地址生成UUID的算法可能会造成MAC地址泄露,这个漏洞曾被用于寻找梅丽莎病毒的制作者位置。
- MySQL官方有明确的建议主键要尽量越短越好[4],36个字符长度的UUID不符合要求。
- 对MySQL索引不利:如果作为数据库主键,在InnoDB引擎下,UUID的无序性可能会引起数据位置频繁变动,严重影响性能。
雪花算法
snowflake是Twitter开源的分布式ID生成算法,结果是一个long型的ID。其核心思想是:使用41bit作为毫秒数,10bit作为机器的ID(5个bit是数据中心,5个bit的机器ID),12bit作为毫秒内的流水号(意味着每个节点在每毫秒可以产生 4096 个 ID),最后还有一个符号位,永远是0。snowflake算法可以根据自身项目的需要进行一定的修改。比如估算未来的数据中心个数,每个数据中心的机器数以及统一毫秒可以能的并发数来调整在算法中所需要的bit数。
//参数1为终端ID
//参数2为数据中心ID
Snowflake snowflake = IdUtil.getSnowflake(1, 1);
long id = snowflake.nextId();
System.err.println(id); // 1383969099293528064
优点:
- 毫秒数在高位,自增序列在低位,整个ID都是趋势递增的。
- 不依赖数据库等第三方系统,以服务的方式部署,稳定性更高,生成ID的性能也是非常高的。
- 可以根据自身业务特性分配bit位,非常灵活。
缺点: - 强依赖机器时钟,如果机器上时钟回拨,会导致发号重复或者服务会处于不可用状态。
开源的分布式ID生成器
百度uid-generator
地址
UidGenerator是Java实现的,基于Snowflake的唯一ID生成器。它用作组件,并允许用户覆盖workId位和初始化策略。因此,它更适合于虚拟化环境,例如docker。除此之外,它通过消耗将来的时间克服了Snowflake算法的并发限制。通过使用RingBuffer缓存UID来并行化UID产生和使用;通过填充消除了来自RingBuffer的CacheLine伪共享。最后,每个实例可以提供超过600万个QPS。
滴滴Tinyid
地址
Tinyid是ID生成器服务。它提供了一个REST API和一个用于获取ID的Java客户端。使用Java客户端时,每个单个实例超过1000万个QPS。
美团Leaf
地址
Leaf指的是行业中一些常见的ID生成方案,包括redis,UUID,snowflare等。以上每种方法都有其自身的问题,因此我们决定实施一套分布式ID生成服务以满足要求。目前,Leaf负责美团点评公司的内部财务,餐饮,外卖,酒店旅行,猫眼电影和许多其他业务。在4C8G VM的基础上,通过公司的RPC方法,QPS压力测试结果接近5w / s,TP999为1ms。
MybatisPlus的ID生成器
MybatisPlus提供了多种ID生成策略。
IdType
生成ID类型枚举类:
public enum IdType {
/**
* 数据库ID自增
* <p>该类型请确保数据库设置了 ID自增 否则无效</p>
*/
AUTO(0),
/**
* 该类型为未设置主键类型(注解里等于跟随全局,全局里约等于 INPUT)
*/
NONE(1),
/**
* 用户输入ID
* <p>该类型可以通过自己注册自动填充插件进行填充</p>
*/
INPUT(2),
/* 以下3种类型、只有当插入对象ID 为空,才自动填充。 */
/**
* 分配ID (主键类型为number或string),
* 默认实现类 {@link com.baomidou.mybatisplus.core.incrementer.DefaultIdentifierGenerator}(雪花算法)
*
* @since 3.3.0
*/
ASSIGN_ID(3),
/**
* 分配UUID (主键类型为 string)
* 默认实现类 {@link com.baomidou.mybatisplus.core.incrementer.DefaultIdentifierGenerator}(UUID.replace("-",""))
*/
ASSIGN_UUID(4),
/**
* @deprecated 3.3.0 please use {@link #ASSIGN_ID}
*/
@Deprecated
ID_WORKER(3),
/**
* @deprecated 3.3.0 please use {@link #ASSIGN_ID}
*/
@Deprecated
ID_WORKER_STR(3),
/**
* @deprecated 3.3.0 please use {@link #ASSIGN_UUID}
*/
@Deprecated
UUID(4);
private final int key;
IdType(int key) {
this.key = key;
}
}
AUTO
数据库ID自增,该类型请确保数据库设置了ID自增, 否则无效。
-
设置数据库表ID自增
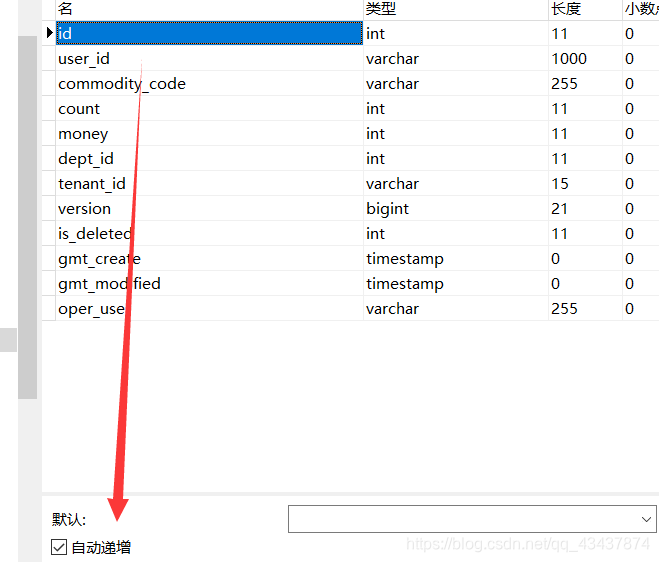
-
设置实体类IdType为AUTO
@TableId(value = "id", type = IdType.AUTO)
private Integer id;
- 插入数据测试
OrderTbl orderTbl = new OrderTbl().setMoney(100).setUserId("123").setCommodityCode("PHONE");
orderTblMapper.insert(orderTbl);
NONE
该类型为未设置主键类型(注解里等于跟随全局,全局里约等于 INPUT)。
- 取消数据库表ID自增
- 设置实体类IdType为NONE
@TableId(value = "id", type = IdType.NONE)
private Integer id;
- 插入数据测试
public void insertTest() {
OrderTbl orderTbl = new OrderTbl().setId(11111).setMoney(100).setUserId("123").setCommodityCode("PHONE");
orderTblMapper.insert(orderTbl);
}

INPUT
用户输入ID,该类型可以通过自己注册自动填充插件进行填充(经测试MetaObjectHandler并不能实现主键ID自动填充,因为自动填充时是获取TableInfo字段信息循环字段并填充,但是TableInfo字段中不包含主键,所以无法填充)。应该可以使用mybatis插件实现(未测试)。
方式一:
- 取消数据库表ID自增
- 设置实体类IdType为INPUT
@TableId(value = "id", type = IdType.INPUT)
private Integer id;
- 插入数据测试同NONE步骤
ASSIGN_ID
分配ID (主键类型为number或string),默认实现类 DefaultIdentifierGenerator(雪花算法)。
方式一使用默认生成器:
- 取消数据库表ID自增
- 设置实体类IdType为ASSIGN_ID,字段类型为Long
@TableId(value = "id", type = IdType.ASSIGN_ID)
private Long id;
- 插入数据测试同NONE步骤

方式二使用自定义ID生成器: - 取消数据库表ID自增
- 设置实体类IdType为ASSIGN_ID,字段类型为Long
@TableId(value = "id", type = IdType.ASSIGN_ID)
private Long id;
- 添加自定义ID生成器
@Component
public class CustomIdGenerator implements IdentifierGenerator {
@Override
public Long nextId(Object entity) {
//使用 hutools 雪花算法生成分布式ID
//参数1为终端ID
//参数2为数据中心ID
Snowflake snowflake = IdUtil.getSnowflake(1, 1);
return snowflake.nextId();
}
}
- 插入数据测试同NONE步骤


旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 8
8 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)