
【预测模型--常用度量指标】
一、MAE(Mean Absolute Error)平均绝对误差MAE(MeanAbsolute Error),即误差绝对值的平均值,可以准确反映实际预测误差的大小。MAE评估的是真实值和预测值的偏离程度,即预测误差的实际大小。MAE值越小,说明模型质量越好,预测越准确。二、MSE(Mean Squared Error)一般情况下,MSE比较少单独使用,因为不好理解,多数用在方差分析和参数估计等中
一、MAE(Mean Absolute Error)
平均绝对误差MAE(MeanAbsolute Error),即误差绝对值的平均值,可以准确反映实际预测误差的大小。
MAE评估的是真实值和预测值的偏离程度,即预测误差的实际大小。
MAE值越小,说明模型质量越好,预测越准确。

二、MSE(Mean Squared Error)
一般情况下,MSE比较少单独使用,因为不好理解,多数用在方差分析和参数估计等中。
显然,MSE越小,说明模型质量越好,预测越准确。

三、RMSE(Root Mean Squared Error)
均误差平方根RMSE(Root MSE),也称标准误差,是均方误差的算术平方根。
相比MSE,指标RMSE这个指标与原始数据的量纲是一样的,容易理解,反映真实值与预测值的偏离程度。
RMSE越小,说明模型质量越好,预测越准确。
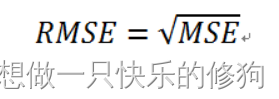
四、EVS(Explained Variance Score)
解释回归模型的方差得分,其值取值范围是[0,1],越接近于1说明自变量越能解释因变量的方差变化,值越小则说明效果越差。
五、R2_score
那如何比较不同量纲下模型的效果好坏呢?这就需要用到回归模型的第四个评价指标:R方值(R2_score)。
它的含义就是,既然不同数据集的量纲不同,很难通过上面的三种方式去比较,那么不妨找一个第三者作为参照,根据参照计算 R方值,就可以比较模型的好坏了。
这个参照是什么呢,就是均值模型。我们知道一份数据集是有均值的,房价数据集有房价均值,学生成绩有成绩均值。现在我们把这个均值当成一个基准参照模型,也叫 baseline model。这个均值模型对任何数据的预测值都是一样的,可以想象该模型效果自然很差。基于此我们才会想从数据集中寻找规律,建立更好的模型。
R2_score 的计算公式是这样的:
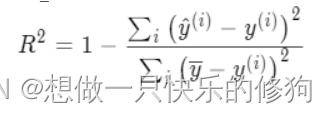
通过它的取值可以更好理解它是如何评价模型好坏的,有这几种取值情况:
R2_score = 1,达到最大值。即分子为 0 ,意味着样本中预测值和真实值完全相等,没有任何误差。也就是说我们建立的模型完美拟合了所有真实数据,是效果最好的模型,R2_score 值也达到了最大。但通常模型不会这么完美,总会有误差存在,当误差很小的时候,分子小于分母,模型会趋近 1,仍然是好的模型,随着误差越来越大,R2_score 也会离最大值 1 越来越远,直到出现第 2 中情况。
R2_score = 0。此时分子等于分母,样本的每项预测值都等于均值。也就是说我们辛苦训练出来的模型和前面说的均值模型完全一样,还不如不训练,直接让模型的预测值全去均值。当误差越来越大的时候就出现了第三种情况。
R2_score < 0 :分子大于分母,训练模型产生的误差比使用均值产生的还要大,也就是训练模型反而不如直接去均值效果好。出现这种情况,通常是模型本身不是线性关系的,而我们误使用了线性模型,导致误差很大。
理解了 R2_score 后,我们可以对它的计算公式作进一步改进,以便后面编程实现。将分子和分母同除以一个 m,就能得到下式:
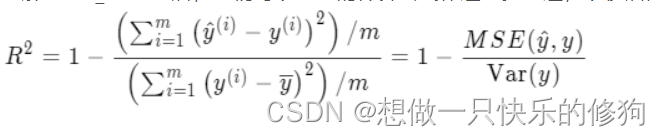
分子是均方误差,分母是方差,都能直接计算得到,从而能快速计算出 R2 值。
总结

- 如果觉得本文对你有所帮助的话,记得点个赞哟~

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 33
33 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)