
Python: sklearn库中数据预处理函数fit_transform()和transform()的区别
敲《Python机器学习及实践》上的code的时候,对于数据预处理中涉及到的fit_transform()函数和transform()函数之间的区别很模糊,查阅了很多资料,这里整理一下:涉及到这两个函数的代码如下:# 从sklearn.preprocessing导入StandardScalerfrom sklearn.preprocessing import StandardScaler# 标..
敲《Python机器学习及实践》上的code的时候,对于数据预处理中涉及到的fit_transform()函数和transform()函数之间的区别很模糊,查阅了很多资料,这里整理一下:
涉及到这两个函数的代码如下:
# 从sklearn.preprocessing导入StandardScaler
from sklearn.preprocessing import StandardScaler
# 标准化数据,保证每个维度的特征数据方差为1,均值为0,使得预测结果不会被某些维度过大的特征值而主导
ss = StandardScaler()
# fit_transform()先拟合数据,再标准化
X_train = ss.fit_transform(X_train)
# transform()数据标准化
X_test = ss.transform(X_test)我们先来看一下这两个函数的API以及参数含义:
1、fit_transform()函数
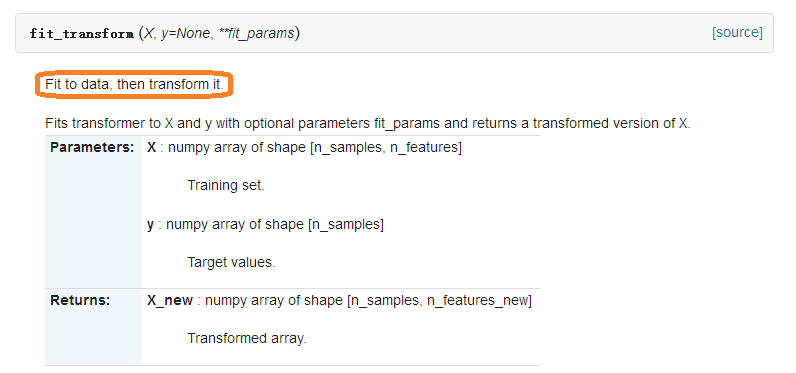
即fit_transform()的作用就是先拟合数据,然后转化它将其转化为标准形式
2、transform()函数
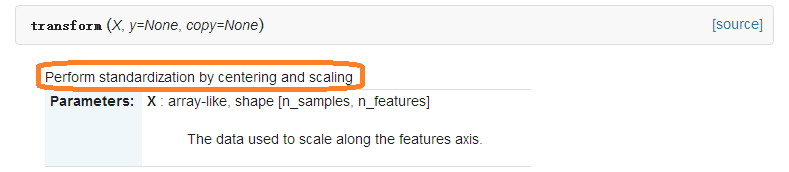
即tranform()的作用是通过找中心和缩放等实现标准化
到了这里,我们似乎知道了两者的一些差别,就像名字上的不同,前者多了一个fit数据的步骤,那为什么在标准化数据的时候不使用fit_transform()函数呢?
原因如下:
为了数据归一化(使特征数据方差为1,均值为0),我们需要计算特征数据的均值μ和方差σ^2,再使用下面的公式进行归一化:

我们在训练集上调用fit_transform(),其实找到了均值μ和方差σ^2,即我们已经找到了转换规则,我们把这个规则利用在训练集上,同样,我们可以直接将其运用到测试集上(甚至交叉验证集),所以在测试集上的处理,我们只需要标准化数据而不需要再次拟合数据。用一幅图展示如下:
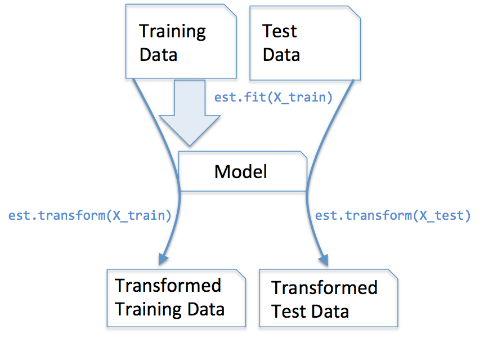
(图片来源:点击打开链接)

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 124
124 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)