
差分隐私(Differential Privacy)
二、差分隐私三、实现机制1、拉普拉斯机制(常用于数值输出的函数)2、高斯机制四、差分隐私分类(1)本地化差分隐私(2)中心化差分隐私(3)分布式差分隐私(4)混合差分隐私
目录
差分隐私(Differential privacy)最早于2008年由Dwork 提出,通过严格的数学证明,使用随机应答(Randomized Response)方法确保数据集在输出信息时受单条记录的影响始终低于某个阈值,从而使第三方无法根据输出的变化判断单条记录的更改或增删,被认为是目前基于扰动的隐私保护方法中安全级别最高的方法。
差分隐私保护的是数据源中一点微小的改动导致的隐私泄露问题。差分隐私,顾名思义就是用来防范差分攻击的。
举个简单的例子,假设现在有一个婚恋数据库,2个单身8个已婚,只能查有多少人单身。刚开始的时候查询发现,2个人单身;现在张三跑去登记了自己婚姻状况,再一查,发现3个人单身。所以张三单身。这里张三作为一个样本的的出现,使得攻击者获得了奇怪的知识。而差分隐私需要做到的就是使得攻击者获得的知识不会因为这些新样本的出现而发生变化。
一、涉及知识点
1、查询
对数据集的各种映射函数被定义为查询(Query),用
={
,
, ......}来表示一组查询。
2、邻近数据集(兄弟数据集)
为了更形式化地描述差分隐私,我们需要先定义相邻数据集。现给定两个数据集D和D’, 若它们有且仅有一条数据不一样,那我们就称此二者为相邻数据集。
或者:设数据集与
,具有相同的属性结构,两者对称差记作
,|
|表示对称差的数量。若|
|=1,则称
和
为邻近数据集(又称兄弟数据集 )。

以上面数据集为例:假定有 n 个人,他们是否是单身狗,形成一个集合 ![]() (其中
(其中 ![]() =0或1),那么另一个集合当中只有一个人改变了单身状态,形成另一个集合
=0或1),那么另一个集合当中只有一个人改变了单身状态,形成另一个集合![]() ,也就是只存在一个 i 使得
,也就是只存在一个 i 使得![]() ,那么这两个集合便是相邻集合。
,那么这两个集合便是相邻集合。
3、敏感度
4、概率单纯形

5、随机算法

所谓随机化算法,是指对于特定输入,该算法的输出不是固定值,而是服从某一分布,如拉普拉斯分布。

二、差分隐私
对于一个随机化算法 A (所谓随机化算法,是指对于特定输入,该算法的输出不是固定值,而是服从某一分布),其分别作用于两个相邻数据集得到的两个输出分布难以区分。差分隐私形式化的定义为:

通常情况下,值取很小,
接近于1,即对于只有一条记录差别的两个数据集,如果查询它们的概率非常非常的接近,那么它们满足差分隐私保护(通俗的说法,不太严谨)。
也就是说,如果该算法作用于任何相邻数据集,得到一个特定输出 O 的概率应差不多,那么我们就说这个算法能达到差分隐私的效果。也就是说,观察者通过观察输出结果很难察觉出数据集一点微小的变化,从而达到保护隐私的目的。
注:a.
越小,隐私保密度越高;
b.
c.
针对
与
的输出概率完全相同。
For example:医院发布信息有10个人患AIDS,现在攻击者知道其中9个人的信息,通过和医院发布的信息进行比对就可以知道最后一个人是否患AIDS,这就是差分隐私攻击。如果查询9个人的信息和查询10个人的信息结果一致,那么攻击者就没有办法确定第10个人的信息,这就是差分隐私保护。
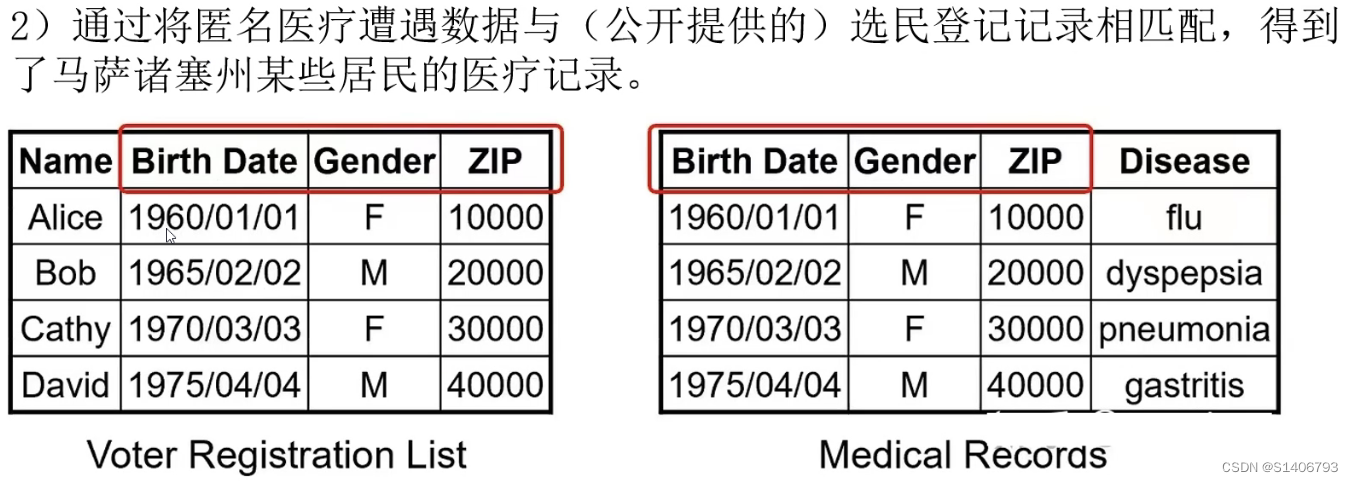
三、实现机制
如何才能得到差分隐私呢?最简单的方法是加噪音,也就是在输入或输出上加入随机化的噪音,以期将真实数据掩盖掉。
比较常用的是加拉普拉斯噪音。由于拉普拉斯分布的数学性质正好与差分隐私的定义相契合,因此很多研究和应用都采用了此种噪音。还是以前面那个数据集为例,假设我们想要知道到底有多少人是单身狗,我们只需要计算![]() ,那么为了掩盖具体数值,实际输出值应为
,那么为了掩盖具体数值,实际输出值应为 ![]() ,相应地,另一个数据集输出的是
,相应地,另一个数据集输出的是![]() 。这使得观察者分不清最终的输出是由哪个数据集产生的。
。这使得观察者分不清最终的输出是由哪个数据集产生的。
前面描述的是差分隐私的严格定义。还有一种稍微放宽一点的定义为:
![]()
其中 δ是一个比较小的常数。
1、拉普拉斯机制(常用于数值输出的函数)
(1)Laplace机制的敏感度:
给定一个函数集,X和Y为邻近数据集,其敏感度定义如下:

(2)期望为a,方差为2的Laplace分布,其概率密度函数为:

在差分隐私使用的拉普拉斯分布中,a取0,其中 =
,
为敏感度。
(3)Laplace机制-差分隐私:
给定一个函数
,若隐私保护算法
满足
-差分隐私,当且仅当下述表达式成立:
=
+
![]()
具体公式推导证明可参考:
差分隐私若干基本知识点介绍(一)_MathThinker的博客-CSDN博客_差分隐私

import numpy as np
epsilon = 10 #自己定
loc = 0
scale = 2000/epsilon
noise1 = np.random.laplace(loc, scale)
noise2 = np.random.laplace(loc, scale)
noise3 = np.random.laplace(loc, scale)
print(noise1)
print(noise2)
print(noise3)
company_salary = {'张三':5000, '王五':6000, '李四':7000} #真实的人力资源数据
print('真实的数据如下:{}'.format(company_salary) )
noise_salary = {'张三': 5000+noise1, '王五': 6000+noise2 , '李四':7000+noise3}
print('差分隐私后的数据如下:{}'.format(noise_salary))
2、高斯机制
待补充。
当然,对输入或输出加噪音会使得最终的输出结果不准确。而且由于噪音是为了掩盖一条数据,所以很多情况下数据的多少并不影响加的噪音的量。那么在数据量很大的情况下,噪音的影响很小,这时候就可以放心大胆地加噪音了,但数据量很小的情况下,噪音的影响就显得比较大,会使得最终结果偏离准确值较远而变得不可用。也有些算法不需要加噪音就能达到差分隐私的效果,听起来很美好,但这种算法通常要求数据满足一定的分布,这一点在现实中通常很难满足。
由于传统的完全差分隐私(Pure Differential Privacy)基于最严格的假设:最大背景攻击,即假设攻击者拥有除了某一条记录以外的所有背景信息,而这在实际情况中是十分罕见的。因此完全差分隐私对于隐私性的保护过于严苛,极大影响了数据的可用性,目前实际场景中主要采用的是带有松弛机制的近似差分隐私( Approximate Differential Privacy)。
四、差分隐私分类
- 客户端侧采用的差分隐私机制一般被称为本地化(Local)差分隐私
- 通过可信中间节点进行扰动可以被称为分布式( Distributed)差分隐私
- 由服务器完成的扰动被称为中心化(Centralized)差分隐私
- 而融合了上述两种或以上的差分隐私方法则被称为混合( Hybrid )差分隐私
(1)本地化差分隐私
本地化差分隐私意味着对数据的训练以及对隐私的保护过程全部在客户端就可以实现。直觉来看,这种差分隐私机制显然优于其他方案,因为用户可以全权掌握数据的使用与发布,也无需借助中心服务器,最有潜力实现完全意义上的去中心化联邦学习。
谷歌公司的Abadi等于2016年在传统机器学习中实现了差分隐私,并在当时就提出了在手机、平板电脑等小型设备上训练模型的设想,认为该差分隐私机制凭借轻量化的特点,更加适用于本地化、边缘化场景。
但是,本地化差分隐私本身及其在联邦学习的应用中仍然存在着不少问题。首先是它所需求的样本量极其庞大,例如前文所述的Snap公司将本地化差分隐私应用到垃圾邮件分类器的训练中,最终收集了用户数亿份样本才达到较高的准确度。谷歌、苹果、微软公司在用户设备上大量部署了本地化差分隐私,用来收集数据并进行模型训练,相较无噪模型的训练需要更多的数据量,往往多达2个数量级。其次,在高维数据下,本地化差分隐私要取得可用性、隐私性的平衡将会更加困难。
另外,在去中心化的联邦学习场景中,由于没有中心服务器的协调,参与者无法得知来自其他参与者的样本信息,因此很难决定自己所添加随机噪声的大小,噪声的分布不均将会严重降低模型性能。
(2)中心化差分隐私
差分隐私方法最初被提出时大多采用中心化的形式,通过-一个可信的第三方数据收集者汇总数据,并对数据集进行扰动从而实现差分隐私。B2C架构下的联邦学习同样可以在中心服务器上实现这种扰动。在服务器端收集用户更新后的梯度,通过逐个加噪的方式来隐藏各个节点的贡献;并证明了中心化加噪方案可以实现用户级别的差分隐私而不仅仅是本地化方案的数据点级别,这意味着它不会暴露出任何一个曾参与过训练的用户;最后通过实验证实了这种方法的模型训练效果要优于本地化差分隐私。
中心化差分隐私在实际应用中同样存在缺陷,因为它受限于一个可信的中心化服务器,但是很多场景下服务器并不可信。因此,可以采用分布式差分隐私来作为本地化与中心化的折中,或采用混合差分隐私回避这两者的部分缺陷。
(3)分布式差分隐私
分布式差分隐私指的是在若干个可信中间节点上先对部分用户发送的数据进行聚合并实施隐私保护,然后传输加密或扰动后的数据到服务器端,确保服务器端只能得到聚合结果而无法得到数据。该方案需要客户端首先完成计算并进行简单的扰动(例如较高隐私预算的本地化差分隐私)或加密,将结果发送至一个可信任的中间节点,然后借助可信执行环境(TEE)、安全多方计算、安全聚合(Secure Aggregation)或安全混洗(Secure Shuffling)等方法,在中间节点实现进一步的隐私保护,最终将结果发送至服务器端。
Bittau等于2017年提出了一种安全混洗框架Encode- Shuffle-Analyze(ESA),通过在客户端与服务器端额外增加一次匿名化混洗的步骤,允许用户在本地只添加少量噪声就实现较高级别的隐私保护。此后,Erlingsson等、Cheu等均对此框架进行了改进,并考虑了与联邦学习的结合。类似的分布式差分隐私解决方案同样都兼具了本地化与中心化差分隐私的优势,既不需要信任等级极高的服务器,也不需要在本地添加过多噪声。但相对的,分布式差分隐私普遍需要极高的通信成本。本地化、中心化与分布式差分隐私的区别与联系如表所示:
(4)混合差分隐私
混合差分隐私方案由Avent等提出,它通过用户对服务器信任关系的不同对用户进行分类。举例而言,最不信任服务器的用户可以使用最低隐私预算的本地化差分隐私,而最信任服务器的用户甚至可以直接发送原始参数;服务器也将根据用户的信任关系对数据进行不同程度的处理。该方案的问题是同样需要一定的通信成本,并且还需要付出额外的预处理成本以划分信任关系。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 13
13 1
1- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)