
异常监测②——lstm时间序列预测&lstm简易原理
lstm的原理,三个门是怎样作用的,对应的公式是什么
目录
1、Mean Squared Error Loss(MSE)
2、Mean Squared Logarithmic Error Loss(MSLE)
3、Mean Absolute Error Loss (MAE)
4、Binary Classification Loss Functions
8、Multi-Class Classification Loss Functions
利用LSTM进行时间序列预测流程
在用统计学方法(3σ原则、四分位距法)等对异常数据进行监测后 (异常监测①——统计学方法判断)
由于业务特点,导致时序数据的规律趋势会变化。下方为举例:
| 时间点 | 原来的count | 现在的count |
| 2020-01-01 13:00:00 | 267 | 1000 |
| 2020-01-01 13:10:00 | 300 | 0 |
| 2020-01-01 13:20:00 | 261 | 0 |
| 2020-01-01 13:30:00 | 289 | 1023 |
| 2020-01-01 13:40:00 | 235 | 0 |
| 2020-01-01 13:50:00 | 273 | 0 |
| 2020-01-01 14:00:00 | 309 | 1014 |
此时原统计学方法可能不再适用,可以重新观察新的数据分布规律,手动修改代码逻辑。
但考虑到后续规律仍可能发生变动,为避免后续需要继续改异常监测逻辑,选择使用深度学习模型——lstm 对时序数据的分布进行预测。并且增添 模型更新 逻辑,使得模型不需要再人工更改。
参考以下资料:
确定逻辑:
1、原始数据存储
mongodb
2、数据预处理
去除节假日数据,异常点替换、缺失值填充
3、模型设计及训练
训练集:近十天数据(不含近三天)。 预测集:近三天
多轮超参优化,确定最优超参,及预测范围(用历史多长数据预测未来多长)
保存模型
4、异常判断
①https://www.slideshare.net/ssuserbefd12/ss-164777085 异常边界取90%分位数,持续几次异常产生告警(邮件、微信)
② 3σ原则
5、模型更新
数据监控:通过均值、标准差、中位数、IQR等统计指标以天为粒度监控数据漂移,数据漂移超过阈值
模型监控:每天自动统计模型输出的全部异常点占比的概率,概率分布变化超出阈值后模型自动提取最新数据重新训练
注:关于训练集和测试集 该一起归一化还是分开归一化参考:
待补充:
捕捉过多的非异常 VS 漏掉真正的异常,怎么权衡
为什么选择lstm而不是别的算法?
lstm原理理解(各超参数的定义)
算法如何调参(看什么指标https://www.cnblogs.com/kamekin/p/10163743.html)
lstm滞后性
1、摘自stackoverflow ——预测值滞后问题是过拟合现象,那么就按过拟合的解决方法来尝试,例如:增加dropout 层等。

2、摘自CSDN——“滞后性”的原因是LSTM过于重视时间步长中最后一个t-1时刻的数据,导致预测结果就是t-1时刻数据的复现。
理解lstm原理
参考的文章以及油管视频:(这个文章所在的网站似乎没了,视频还可以看)
递归神经网路和长短期记忆模型 RNN & LSTM · 資料科學・機器・人
Recurrent Neural Networks (RNN) and Long Short-Term Memory (LSTM)
下面是我的总结以及理解:
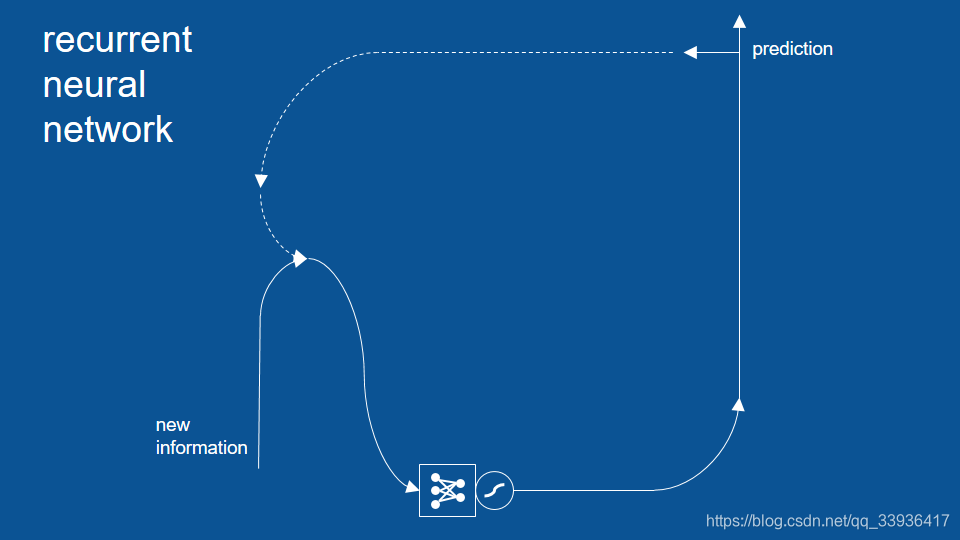
模型包含 预测、忽视、遗忘、筛选 四条路径。
注释:激活函数在本示例中的符号表示 (见下图右上角:
双曲正切函数tanh 逻辑函数sigmoid(和双曲正切函数类似,只是它的输出值介于0和1之间)
逻辑函数sigmoid(和双曲正切函数类似,只是它的输出值介于0和1之间)
一、预测
二、遗忘

三、筛选

四、忽视

202305补充:从公式角度理解,
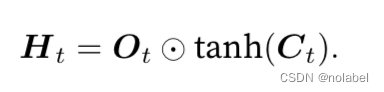
遗忘门控制上一时间步的记忆细胞中的信息是否传递到当前时间步;
输入门控制当前时间步的输入通过
如何流入当前时间步的记忆细胞
总结:下图给出整个LSTM中,三个门的工作流程。(原图见李沐书的P245 )sigmoid函数输出值在0,1之间,可以被用作一种控制阀门。、
、
都是由sigmoid函数得出,
中留下多少,所以叫遗忘门。
,实质是控制
有多少信息流入当前时间步记忆细胞,所以叫输入门(因为本质控制的是输入数据X。
中有多少信息输出到
,所以叫输出门。
而决定3个门输出值的权重参数W是在训练中学到的,即LSTM能自适应地调整参数,从而不断优化3个门的策略,学习到序列规律。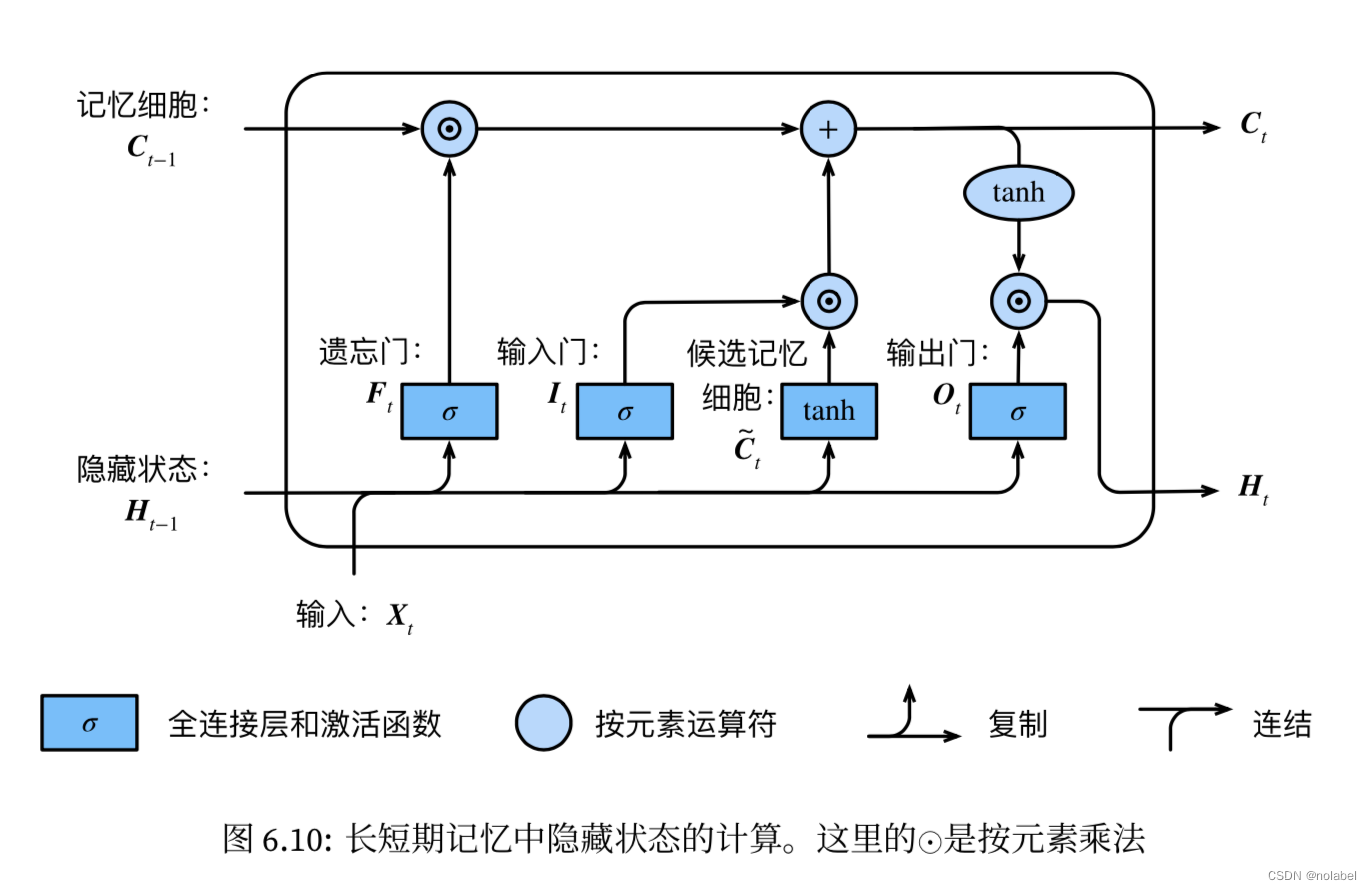
原理示例





lstm参数
各参数的定义解释:
model.add(LSTM(neurons,input_shape=(None,1))) #输入数据的形状
model.add(Dropout(dropout_value)) #dropout层
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam') # 编译(损失函数、优化器)
model.fit(train_x, train_y, epochs=epochs, batch_size=batch_size,verbose=verbose)
参数解释:
batch_size
如何选择batch_size的大小:
epoch
预测滞后问题
(1)损失函数现在使用的是mean_squared_error,可以调成别的
(2)优化器是 adam ,也可以调,甚至对优化器内的参数进行调整(比如学习率)(3)训练次数是50,可以调低点(因为我看后面模型的损失不下降了)(4)基于历史多少数据的参数 look_back 可调,你可以设置为3,5.....
损失函数的选择
1、Mean Squared Error Loss(MSE)
2、Mean Squared Logarithmic Error Loss(MSLE)
3、Mean Absolute Error Loss (MAE)
4、Binary Classification Loss Functions
5、Binary Cross-Entropy Loss
6、Hinge Loss
7、Squared HInge Loss
8、Multi-Class Classification Loss Functions
如何选择优化器Optimizer
dropout层
1、什么时候应该加dropout层?
过拟合的表现:
在训练集下的表现过于优越,导致在验证集(测试集)上的表现不佳。
在神经网络中,有一个普遍现象可以说明是出现了过拟合,验证集的准确率回载训练了多个epoch后达到当val_loss达到一个最低值的时候突然回升,val_loss又不断升高。
过拟合原因:模型复杂度过高,模型将训练数据中的噪声或随机误差视为真实模式,可以理解为模型只是死记硬背住了训练数据,而不能很好地泛化到新数据上。而模型复杂度由模型中的 参数数量 和 参数值大小 决定。
过拟合的解决方法:dropout 或 L1/L2正则化
简单理解:L1、L2正则化是在损失函数中加入正则化项,相当于加入了约束条件,从而可以约束参数w的大小。而dropout是在训练时按一定概率弃用某些隐藏层神经元,减少神经元之间的相互依赖性,从而降低模型复杂度。
判断过拟合的代码:
通过model.evaluate计算测试精度判断 模型是否在训练集上性能过优:
train_acc = model.evaluate(trainX, trainy, verbose=0) test_acc = model.evaluate(testX, testy, verbose=0) print('Train: %.3f, Test: %.3f' % (train_acc, test_acc))模型在训练数据集上的性能优于测试数据集,这是过度拟合的一个可能标志。
如:Train: 1.000, Test: 0.757 ,则可能为过拟合
2、放在哪几个层之间?
可以放任意层之间,但在不同位置,选取的dropout_value值应该采用不同的大小。
经验法则是,当dropout应用于全连接层时,将保留概率(1 - drop概率)设置为0.5,而当应用于卷积层时,将其设置为更大的数字(通常为0.8、0.9),即(1-dropout_value)=0.8或0.9 (dropout_value=0.1或0.2)。


旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)