
【数据结构与算法】图遍历算法 ( 深度优先搜索 DFS | 深度优先搜索和广度优先搜索 | 深度优先搜索基本思想 | 深度优先搜索算法步骤 | 深度优先搜索理论示例 )
一、深度优先搜索 DFS1、深度优先搜索和广度优先搜索2、深度优先搜索基本思想3、深度优先搜索算法步骤二、深度优先搜索示例 ( 理论 )1、第一轮递归2、第二轮递归3、第三轮递归4、第四轮递归5、第五轮递归6、第六轮递归7、第七轮递归
文章目录
一、深度优先搜索 DFS
1、深度优先搜索和广度优先搜索
图 的 遍历 就是 对 图 中的 结点 进行遍历 , 遍历 结点 有如下两种策略 :
- 深度优先搜索 DFS
- 广度优先搜索 BFS
2、深度优先搜索基本思想
" 深度优先搜索 " 英文名称是 Depth First Search , 简称 DFS ;
DFS 基本思想 :
- 访问第一个邻接结点 : 从 起始点 出发 , 该 起始点 可能有 若干 邻接结点 , 访问 第一个 邻接结点 , 然后 再访问 第一个 邻接结点 的 第一个邻接结点 , 每次都访问 当前结点 的 第一个邻接结点 ;
- 访问策略 : 优先 向 纵向遍历 , 不是 对 当前结点 的所有 邻接结点 进行 横向遍历 ;
- 递归过程 : 上述 DFS , 每次访问 起始点 的 第一个邻接结点 后 , 又将 该 第一个邻接结点 作为 新的起始点 继续向下访问 , 该过程是一个递归过程 ;
3、深度优先搜索算法步骤
深度优先搜索算法步骤 :
- ① 访问初始结点 : 访问 初始结点 v , 并将该 初始结点 v 标记为 " 已访问 " ;
- ② 查找邻接节点 : 查找 初始结点 v 的 第一个 邻接节点 w ;
- ③ 邻接节点是否存在 :
- 如果 w 结点存在 , 执行 ④ 操作 判断该 结点 是否被访问 ;
- 如果 w 结点 不存在 , 回到 ① 查找 初始结点 v 的下一个 邻接节点 ;
- ④ 邻接节点是否被访问 :
- 如果 w 结点存在 并且 没有被访问 , 那么 对 w 结点 进行 深度优先遍历 , 将 w 结点 作为 新的 初始结点 v , 从 ① 步骤开始执行 ;
- 如果 w 结点存在 但是 被访问了 , 那么 查找 w 结点的 下一个 邻接节点 , 转到步骤 ③ 执行 ;
二、深度优先搜索示例 ( 理论 )
以下图为例 , 说明 DFS 搜索步骤 ; 初始结点 A ;
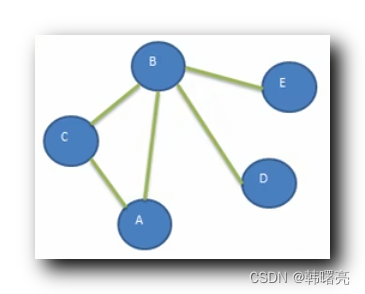
初始结点 为 A , 开始进行 DFS :
1、第一轮递归
访问 初始结点 A , 并将该 初始结点 A 标记为 " 已访问 " ;
查找 初始结点 A 的 第一个 邻接节点 B ;
- 邻接结点选择 : 这里的 第一个邻接节点 选择 , 是在内存数据 邻接表 中排列在首位 0 索引的节点 , 或者 与 邻接矩阵 中 元素位置 有关 , 没有其它意义 ;
- 在下面的 邻接矩阵 中 , 查找 A 的第一个 邻接结点 , 从 A 的那一排 第 0 排开始查找 , 第一个为 1 的元素就是 对应 第一个 邻接结点 )

查询邻接节点 B 是否存在 ; 邻接节点 B 结点存在 ;
查询邻接节点 B 是否被访问 ; 邻接节点 B 结点存在 并且 没有被访问 , 那么 对 邻接节点 B 结点 进行 深度优先遍历 , 将 邻接节点 B 结点 作为 新的 初始结点 , 从 ① 步骤开始执行 ;
2、第二轮递归
访问 初始结点 B , 并将该 初始结点 B 标记为 " 已访问 " ;
查找 初始结点 B 的 第一个 邻接节点 A ;
- 邻接结点选择 : 这里的 第一个邻接节点 选择 , 是在内存数据 邻接表 中排列在首位 0 索引的节点 , 或者 与 邻接矩阵 中 元素位置 有关 , 没有其它意义 ;
- 在下面的 邻接矩阵 中 , 查找 B 的第一个 邻接结点 , 从 B 的那一排 第 1 排开始查找 , 第一个为 1 的元素 对应的 是 A 节点 ;
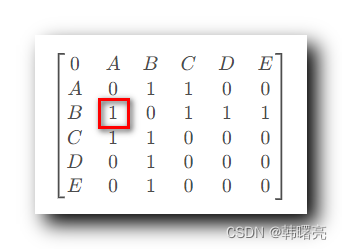
查询邻接节点 A 是否存在 ; 邻接节点 A 结点存在 ;
查询邻接节点 A 是否被访问 ; 邻接节点 A 结点 存在 但是 被访问了 , 那么 查找 B 结点的 下一个 邻接节点 , 转到步骤 ③ 执行 ;
查找 结点 B 的 第二个 邻接节点 C ;
- 邻接结点选择 : 这里的 第一个邻接节点 选择 , 是在内存数据 邻接表 中排列在首位 0 索引的节点 , 或者 与 邻接矩阵 中 元素位置 有关 , 没有其它意义 ;
- 在下面的 邻接矩阵 中 , 查找 B 的第二个 邻接结点 , 从 B 的那一排 第 1 排开始查找 , 第二个为 1 的元素 对应的 是 C 节点 ;
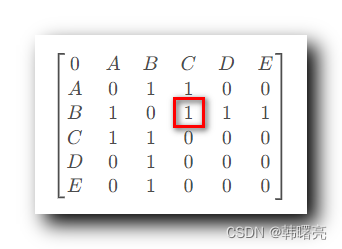
查询邻接节点 C 是否存在 ; 邻接节点 C 结点存在 ;
查询邻接节点 C 是否被访问 ; 邻接节点 C 结点存在 并且 没有被访问 , 那么 对 邻接节点 C 结点 进行 深度优先遍历 , 将 邻接节点 C 结点 作为 新的 初始结点 , 从 ① 步骤开始执行 ;
3、第三轮递归
访问 初始结点 C , 并将该 初始结点 C 标记为 " 已访问 " ;
查找 初始结点 C 的 第一个 邻接节点 A ;
- 邻接结点选择 : 这里的 第一个邻接节点 选择 , 是在内存数据 邻接表 中排列在首位 0 索引的节点 , 或者 与 邻接矩阵 中 元素位置 有关 , 没有其它意义 ;
- 在下面的 邻接矩阵 中 , 查找 C 的第一个 邻接结点 , 从 C 的那一排 第 2 排开始查找 , 第一个为 1 的元素就是 对应 第一个 邻接结点 ;

查询邻接节点 A 是否存在 ; 邻接节点 A 结点存在 ;
查询邻接节点 A 是否被访问 ; 邻接节点 A 结点 存在 但是 被访问了 , 那么 查找 C 结点的 下一个 邻接节点 , 转到步骤 ③ 执行 ;
查找 结点 C 的 第二个 邻接节点 B ;
- 邻接结点选择 : 这里的 第一个邻接节点 选择 , 是在内存数据 邻接表 中排列在首位 0 索引的节点 , 或者 与 邻接矩阵 中 元素位置 有关 , 没有其它意义 ;
- 在下面的 邻接矩阵 中 , 查找 C 的第二个 邻接结点 , 从 C 的那一排 第 2 排开始查找 , 第二个为 1 的元素就是 对应 第二个 邻接结点 ;

查询邻接节点 B 是否存在 ; 邻接节点 B 结点存在 ;
查询邻接节点 B 是否被访问 ; 邻接节点 B 结点 存在 但是 被访问了 , 那么 查找 C 结点的 下一个 邻接节点 , 转到步骤 ③ 执行 ;
查找 结点 C 的 第三个 邻接节点 ;
- 邻接结点选择 : 这里的 第一个邻接节点 选择 , 是在内存数据 邻接表 中排列在首位 0 索引的节点 , 或者 与 邻接矩阵 中 元素位置 有关 , 没有其它意义 ;
- 在下面的 邻接矩阵 中 , 查找 C 的第三个 邻接结点 , 从 C 的那一排 第 2 排开始查找 , 第三个为 1 的元素就是 对应 第三个 邻接结点 ;
C 的第三个 邻接结点 不存在 , 回到 ① 查找 初始结点 B 的下一个 邻接节点 ;

4、第四轮递归
在 第二轮递归 中 , 已经查找了 B 的 2 个邻接结点了 , 开始查找 B 的 第 3 个邻接结点 ;
查找 结点 B 的 第三个 邻接节点 D ;
- 邻接结点选择 : 这里的 第一个邻接节点 选择 , 是在内存数据 邻接表 中排列在首位 0 索引的节点 , 或者 与 邻接矩阵 中 元素位置 有关 , 没有其它意义 ;
- 在下面的 邻接矩阵 中 , 查找 B 的第三个 邻接结点 , 从 B 的那一排 第 1 排开始查找 , 第三个为 1 的元素 对应的 是 D 节点 ;
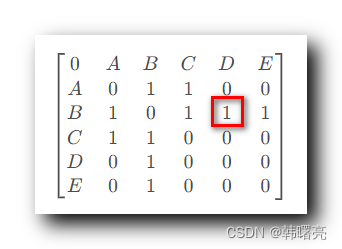
查询邻接节点 D 是否存在 ; 邻接节点 D 结点存在 ;
查询邻接节点 D 是否被访问 ; 邻接节点 D 结点存在 并且 没有被访问 , 那么 对 邻接节点 D 结点 进行 深度优先遍历 , 将 邻接节点 D 结点 作为 新的 初始结点 , 从 ① 步骤开始执行 ;
5、第五轮递归
访问 初始结点 D , 并将该 初始结点 D 标记为 " 已访问 " ;
查找 初始结点 D 的 第一个 邻接节点 B ;
- 邻接结点选择 : 这里的 第一个邻接节点 选择 , 是在内存数据 邻接表 中排列在首位 0 索引的节点 , 或者 与 邻接矩阵 中 元素位置 有关 , 没有其它意义 ;
- 在下面的 邻接矩阵 中 , 查找 D 的第一个 邻接结点 , 从 D 的那一排 第 3 排开始查找 , 第一个为 1 的元素就是 对应 第一个 邻接结点 B ;

查询邻接节点 B 是否存在 ; 邻接节点 B 结点存在 ;
查询邻接节点 B 是否被访问 ; 邻接节点 B 结点 存在 但是 被访问了 , 那么 查找 D 结点的 下一个 邻接节点 , 转到步骤 ③ 执行 ;
查找 结点 D 的 第二个 邻接节点 ;
- 邻接结点选择 : 这里的 第一个邻接节点 选择 , 是在内存数据 邻接表 中排列在首位 0 索引的节点 , 或者 与 邻接矩阵 中 元素位置 有关 , 没有其它意义 ;
- 在下面的 邻接矩阵 中 , 查找 D 的第二个 邻接结点 , 从 D 的那一排 第 3 排开始查找 , 第二个为 1 的元素就是 对应 第二个 邻接结点 ;
D 的第三个 邻接结点 不存在 , 回到 ① 查找 初始结点 B 的下一个 邻接节点 ;

6、第六轮递归
在 第四轮递归 中 , 已经查找了 B 的 3 个邻接结点了 , 开始查找 B 的 第 4 个邻接结点 ;
查找 结点 B 的 第四个 邻接节点 E ;
- 邻接结点选择 : 这里的 第一个邻接节点 选择 , 是在内存数据 邻接表 中排列在首位 0 索引的节点 , 或者 与 邻接矩阵 中 元素位置 有关 , 没有其它意义 ;
- 在下面的 邻接矩阵 中 , 查找 B 的第四个 邻接结点 , 从 B 的那一排 第 1 排开始查找 , 第四个为 1 的元素 对应的 是 E 节点 ;

查询邻接节点 E 是否存在 ; 邻接节点 E 结点存在 ;
查询邻接节点 E 是否被访问 ; 邻接节点 E 结点存在 并且 没有被访问 , 那么 对 邻接节点 E 结点 进行 深度优先遍历 , 将 邻接节点 E 结点 作为 新的 初始结点 , 从 ① 步骤开始执行 ;
7、第七轮递归
访问 初始结点 E , 并将该 初始结点 E 标记为 " 已访问 " ;
查找 初始结点 E 的 第一个 邻接节点 B ;
- 邻接结点选择 : 这里的 第一个邻接节点 选择 , 是在内存数据 邻接表 中排列在首位 0 索引的节点 , 或者 与 邻接矩阵 中 元素位置 有关 , 没有其它意义 ;
- 在下面的 邻接矩阵 中 , 查找 E 的第一个 邻接结点 , 从 E 的那一排 第 4 排开始查找 , 第一个为 1 的元素就是 对应 第一个 邻接结点 B ;
查询邻接节点 B 是否存在 ; 邻接节点 B 结点存在 ;
查询邻接节点 B 是否被访问 ; 邻接节点 B 结点 存在 但是 被访问了 , 那么 查找 D 结点的 下一个 邻接节点 , 转到步骤 ③ 执行 ;
查找 结点 B 的 第五个 邻接节点 ;
- 邻接结点选择 : 这里的 第一个邻接节点 选择 , 是在内存数据 邻接表 中排列在首位 0 索引的节点 , 或者 与 邻接矩阵 中 元素位置 有关 , 没有其它意义 ;
- 在下面的 邻接矩阵 中 , 查找 B 的第五个 邻接结点 , 从 B 的那一排 第 3 排开始查找 , 第五个为 1 的元素就是 对应 第二个 邻接结点 ;
B 的第五个 邻接结点 不存在 , 回到 ① 查找 初始结点 A 的下一个 邻接节点 ;

继续回溯到 A 结点 , 查找 A 结点的 第二个 邻接结点 C , 然后 以 C 为初始结点继续进行遍历 , 进行回溯 , 所有的结点都已经遍历 , 递归结束 ;

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 32
32 0
0- 0



 已为社区贡献139条内容
已为社区贡献139条内容

所有评论(0)