
常微分方程(ODE)求解方法总结
常微分(ODE)方程求解方法总结
1 常微分方程(ODE)介绍
1.1 微分方程介绍和分类
举例:假设跳伞人的下落速度v于时间有如下关系:
d v d t = g − c m v \frac{dv}{dt} = g-\frac{c}{m}v dtdv=g−mcv (1.1)
其中g为重力常数,m为质量,c为阻力系数。
被微分的量v因变量,与v有关的变量t称为自变量。
如果函数只有一个自变量,那么方程就称为常微分方程(ordinary differential equation,ODE)。
如果函数含有两个或者多个自变量,则成为偏微分方程(partialdifferential equation,PDE)。
此外,微分方程也可以根据阶数来分类:最高阶导数是一阶导数,则称为一阶微分方程(first-order-equation);最高阶导数是二阶导数,则称为二阶微分方程(second-order-equation)。例如如(1.1)中就是一阶微分方程,下式(1.2)就是一个二阶微分方程。
m d 2 x d t 2 + c d x d t + k x = 0 m\frac{d^2x}{dt^2} +c\frac{dx}{dt} + kx = 0 mdt2d2x+cdtdx+kx=0 (1.2)
高阶微分方程能简化成一阶方程组。考虑上式(1.2),定义新变量y,令
y
=
d
x
d
t
y=\frac{dx}{dt}
y=dtdx (1.3)
对上式取微分得:
d
y
d
t
=
d
2
x
d
t
2
\frac{dy}{dt}=\frac{d^2x}{dt^2}
dtdy=dt2d2x (1.4)
将式(1.3)和(1.4)代入式(1.2)中得到:
m
d
y
d
t
+
c
y
+
k
x
=
0
m\frac{dy}{dt} +cy + kx = 0
mdtdy+cy+kx=0 (1.5)
于是原来的二阶微分方程(1.2)可等价于两个一阶方程组(1.3)和(1.5)。
同样的,其他的n阶微分方程也可以用类似的方式简化。
1.2 常微分方程的非计算机求解方法
常微分方程通常采用解析积分得方法来求解。如对于式(1.1),先乘以dt,在进行积分得到:
v
=
∫
(
g
−
c
m
v
)
d
t
v = \int{(g-\frac{c}{m}v)dt}
v=∫(g−mcv)dt (1.6)
对于上式(1.6),是可以精确的推导出该积分得函数表达式的。因为该方程是线性的。
但在实际中,很多方程(是非线性的)精确解是无法求出的。于是提出了一个方法,就是将方程线性化。
(
n
n
n阶)线性常微分方程的一般形式是:
a
n
(
x
)
y
(
n
)
+
.
.
.
+
a
2
(
x
)
y
(
2
)
+
a
1
(
x
)
y
′
+
+
a
0
(
x
)
y
=
f
(
x
)
a_n(x)y^{(n)}+...+a_2(x)y^{(2)}+a_1(x)y'++a_0(x)y = f(x)
an(x)y(n)+...+a2(x)y(2)+a1(x)y′++a0(x)y=f(x) (1.7)
其中,
y
(
n
)
y^{(n)}
y(n)是y关于x的n阶导数,
a
n
(
x
)
a_n(x)
an(x)和
f
(
x
)
f(x)
f(x)都是关于x的函数。因为该方程中未出现因变量y与其导数的乘积,也没有出现非线性函数。所以认为它是线性的。
如下式(1.8)是一个非线性微分方程:
d
2
x
d
t
2
+
g
l
s
i
n
(
x
)
=
0
\frac{d^2x}{dt^2} +\frac{g}{l} sin(x)= 0
dt2d2x+lgsin(x)=0 (1.8)
由于含有
s
i
n
(
x
)
sin(x)
sin(x)为非线性函数,故该微分方程是非线性的。
线性常微分方程是可以通过解析法求解的。但是,大部分非线性方程无法精确求解。
1.3 线性微分方程求解的推导过程
拿一个简单的方程举例。首先给定函数:
y
=
−
0.5
x
4
+
4
x
3
−
10
x
2
+
8.5
x
+
1
y=-0.5x^4+4x^3-10x^2+8.5x+1
y=−0.5x4+4x3−10x2+8.5x+1 (1.9)
这是一个四次多项式。对其进行微分,就得到一个常微分方程:
d
y
d
x
=
−
2
x
3
+
12
x
2
−
20
x
+
8.5
\frac{dy}{dx}=-2x^3+12x^2-20x+8.5
dxdy=−2x3+12x2−20x+8.5 (1.10)
对式(1.10)乘以dx,在进行积分得到:
y
=
∫
(
−
2
x
3
+
12
x
2
−
20
x
+
8.5
)
d
x
y=\int{(-2x^3+12x^2-20x+8.5)}dx
y=∫(−2x3+12x2−20x+8.5)dx (1.11)
应用积分法则得出解为:
y
=
−
0.5
x
4
+
4
x
3
−
10
x
2
+
8.5
x
+
C
y=-0.5x^4+4x^3-10x^2+8.5x+C
y=−0.5x4+4x3−10x2+8.5x+C (1.12)
除了相差一个C外,其余都与原函数相同。这个C称为积分常数(constant of integration)。
出现一个任意常数C表明,积分的结果并不算是唯一的。无限多个常数C对应无限多个可能的函数,都满足微分方程。下图给出了6个满足条件的函数:

为了将解完全确定下来,微分方程通常伴随有辅助条件(auxiliary conditions)。对于一阶常微分方程,有一类被称为**初值(initial value)**的辅助条件,这类条件用于确定常数值,从而使得解是唯一的。例如,给式(1.11)添加初始条件x=0,y=1。带入式(1.12)中,可推导出C=1。于是就得到了唯一解:
y
=
−
0.5
x
4
+
4
x
3
−
10
x
2
+
8.5
x
+
1
y=-0.5x^4+4x^3-10x^2+8.5x+1
y=−0.5x4+4x3−10x2+8.5x+1
这个解同时满足常微分方程和指定的初始条件。
当处理n阶微分方程时,就需要n个条件来确定唯一解。如果所有的条件都是在自变量同一值处指定的,那么问题就称为初值问题(initial-value problem)。与之相对的,边值问题(boundary-value problems),就是指在自变量的不同值处指定初始条件。
2 一阶常微分方程(ODE)求解方法
2.1 欧拉方法
2.1.1 欧拉方法
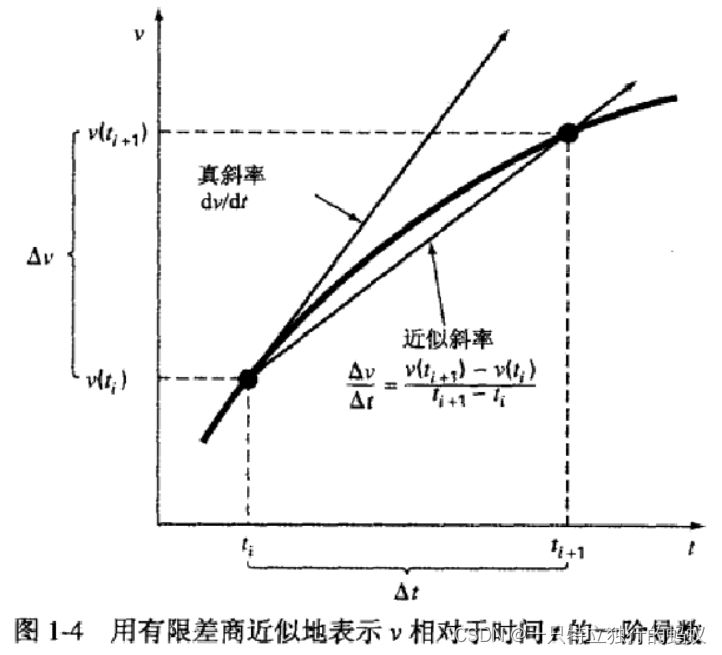
还是拿式(1.1)举例:

d
v
d
t
≈
Δ
v
Δ
t
=
v
(
t
i
+
1
)
−
v
(
t
i
)
t
i
+
1
−
t
i
\frac{dv}{dt} \approx \frac{\Delta v}{\Delta t} = \frac{v(t_{i+1}) - v(t_{i})}{t_{i+1} - t_{i}}
dtdv≈ΔtΔv=ti+1−tiv(ti+1)−v(ti) (2.1)
其中,
Δ
v
\Delta v
Δv和
Δ
t
\Delta t
Δt分别为速度与时间的差分,
v
(
t
i
)
v(t_{i})
v(ti)为初始时刻
t
i
t_i
ti的速度,
v
(
t
i
+
1
)
v(t_{i+1})
v(ti+1)为下一个时刻
t
i
+
1
t_{i+1}
ti+1的速度。注意,
d
v
d
t
≈
Δ
v
Δ
t
\frac{dv}{dt} \approx \frac{\Delta v}{\Delta t}
dtdv≈ΔtΔv 是一个近似计算,因为:
d
v
d
t
=
lim
Δ
t
→
0
Δ
v
Δ
t
\frac{dv}{dt} = \lim_{\Delta t \to 0}\frac{\Delta v}{\Delta t}
dtdv=limΔt→0ΔtΔv
式(2.1)称为在时刻
t
i
t_i
ti处导数的有限差商(finite divided difference)逼近。将其代入式(1.1)中可得:
d
v
d
t
≈
v
(
t
i
+
1
)
−
v
(
t
i
)
t
i
+
1
−
t
i
=
g
−
c
m
v
(
t
i
)
\frac{dv}{dt} \approx\frac{v(t_{i+1}) - v(t_{i})}{t_{i+1} - t_{i}} = g-\frac{c}{m}v(t_i)
dtdv≈ti+1−tiv(ti+1)−v(ti)=g−mcv(ti) (2.2)
对该方程进行整理可得:
v
(
t
i
+
1
)
=
v
(
t
i
)
+
[
g
−
c
m
v
(
t
i
)
]
(
t
i
+
1
−
t
i
)
v(t_{i+1}) = v(t_{i}) + [g-\frac{c}{m}v(t_i)](t_{i+1} - t_{i})
v(ti+1)=v(ti)+[g−mcv(ti)](ti+1−ti) (2.3)
注意1:在式(2.3)的中括号内部分 g − c m v ( t i ) g-\frac{c}{m}v(t_i) g−mcv(ti)其实就是式(1.1)常微分方程的右边 g − c m v g-\frac{c}{m}v g−mcv,是不过这个是一个估计值,是拿 t i t_i ti对刻的速度来估计 t i t_i ti ~ t i + 1 t_{i+1} ti+1这段时间的速度,但只要两个时间点距离越近,这个估值就准确。
根据式(2.3),如果给定了在某一对刻
t
i
t_i
ti的初始值速度
v
i
v_i
vi,就很容易计算出下一时刻
t
i
+
1
t_{i+1}
ti+1的速度
v
i
+
1
v_{i+1}
vi+1。接着又可以用
t
i
+
1
t_{i+1}
ti+1时刻的新速度值来计算
t
i
+
2
t_{i+2}
ti+2的速度,然后依次继续下去。这样,用这种方式就可以计算出任意时刻的速度。
新值
=
旧值
+
斜率
×
步长
新值 = 旧值 + 斜率 \times 步长
新值=旧值+斜率×步长
用数学语言表述为:
v
i
+
1
=
v
i
+
ϕ
×
h
v_{i+1} = v_{i} + \phi \times h
vi+1=vi+ϕ×h(2.4)
这种方法的就命名为欧拉法(Euler’s method)(或欧拉一柯西法(Euler-Cauchy method),或折线法
(point-slope method)。
欧拉方法利用斜率(等于一阶导数在
x
i
x_i
xi处的值),通过线性外推的办法预测出y在前进步长h之后
x
i
+
1
x_{i+1}
xi+1处的新值:

利用上面的方法,取步长为2(也就是每隔2秒,计算一次速度值),于是得到一系列时间t与速度v的值,将这些计算结果与精确解同时画在一个图中:

图5 速度v与时间t的关系的常微分方程的数值解与解析解的对比
上图中,如果我们将步长减小一半,以1秒的步长计算得到的结果,其误差将会更小,从而直线段的轨迹更趋近于真实解。但是步长每减小一半,可以得到更精确的结果,所需要的计算量也会翻一番。
2.1.2 欧拉方法的误差分析
常微分方程数值解的误差包括两种类型:
(1)截断(Truncation)误差或离散误差,是由逼近Y值的方法本身引起的。
(2)舍入(Round-off误差,是由于计算机能保留的有效数字有限而引起的。
截断误差由两部分组成:第一部分是局部截断误差(local truncation error),指方法在一步迭代中所产生的误差。第二部分是传播截断误差(propagated truncation error),它是由前面各步中产生的逼近值引起的,这两部分的和称为整体截断误差或全局截断误差(global truncation error)。
利用泰勒级数展开直接推导欧拉方法,可以同时推出截断误差的大小和属性。假设被积分的微分方程具有一般形式:
y
′
=
f
(
x
,
y
)
y' = f(x, y)
y′=f(x,y)(2.5)
其中,
y
′
=
d
y
/
d
x
y' = dy/dx
y′=dy/dx,x和y分别为自变量和因变量。
如果解(也就是描述y行为的函数)具有连续导数,那么它可以在点(xi, yi)处展开成泰勒级数,即
y
i
+
1
=
y
i
+
y
i
′
∗
h
+
y
i
′
′
2
!
∗
h
2
+
.
.
.
+
y
i
(
n
)
n
!
∗
h
n
+
R
n
y_{i+1}=y_i+y'_i*h+\frac{y''_i}{2!}*h^2+...+\frac{y^{(n)}_i}{n!}*h^n + R_n
yi+1=yi+yi′∗h+2!yi′′∗h2+...+n!yi(n)∗hn+Rn(2.6)
其中,
h
=
(
x
i
+
1
−
x
i
)
h = (x_{i+1}-x_i)
h=(xi+1−xi),
R
n
R_n
Rn为余项,定义为:
R
n
=
y
(
n
+
1
)
(
ξ
)
(
n
+
1
)
!
∗
(
h
)
(
n
+
1
)
R_n = \frac{y^{(n+1)}(\xi)}{(n+1)!}*(h)^{(n+1)}
Rn=(n+1)!y(n+1)(ξ)∗(h)(n+1)(2.7)
其中,
ξ
∈
[
x
i
,
x
i
+
1
]
\xi \in [x_{i}, x_{i+1}]
ξ∈[xi,xi+1]。
由于
y
′
=
f
(
x
,
y
)
y' = f(x, y)
y′=f(x,y),所以
y
′
′
=
f
′
(
x
,
y
)
y'' = f'(x, y)
y′′=f′(x,y),
y
′
′
′
=
f
′
′
(
x
,
y
)
y''' = f''(x, y)
y′′′=f′′(x,y),依此类推,代入式(2.6)右边,同时也加入式(2.7),得到:
y
i
+
1
=
y
i
+
f
(
x
i
,
y
i
)
∗
h
+
f
′
(
x
i
,
y
i
)
2
!
∗
h
2
+
.
.
.
+
f
(
n
−
1
)
(
x
i
,
y
i
)
n
!
∗
h
n
+
O
(
h
n
+
1
)
y_{i+1}=y_i+ f(x_i, y_i)*h+\frac{ f'(x_i, y_i)}{2!}*h^2+...+\frac{f^{(n-1)}(x_i, y_i)}{n!}*h^n + O(h^{n+1})
yi+1=yi+f(xi,yi)∗h+2!f′(xi,yi)∗h2+...+n!f(n−1)(xi,yi)∗hn+O(hn+1)(2.8)
此处
O
(
h
n
+
1
)
O(h^{n+1})
O(hn+1)表示局部截断误差与步长的n+1次幂成正比。
因为我们仅使用了泰勒级数的有限项来逼近真解,所以就产生了截断误差。这样,我们就截断或者略去了一部分真实解。例如,在前面的计算中,我们采用
y
i
+
1
=
y
i
+
f
(
x
i
,
y
i
)
×
h
y_{i+1} = y_{i} + f(x_i, y_i) \times h
yi+1=yi+f(xi,yi)×h来计算下一个点的值,有部分泰勒级数展开项没有被包括在式中,这些剩余项就导致了欧拉方法的截断误差:
E
t
=
f
′
(
x
i
,
y
i
)
2
!
∗
h
2
+
.
.
.
+
f
(
n
−
1
)
(
x
i
,
y
i
)
n
!
∗
(
h
)
n
+
O
(
h
n
+
1
)
E_t = \frac{ f'(x_i, y_i)}{2!}*h^2+...+\frac{f^{(n-1)}(x_i, y_i)}{n!}*(h)^n + O(h^{n+1})
Et=2!f′(xi,yi)∗h2+...+n!f(n−1)(xi,yi)∗(h)n+O(hn+1)(2.9)
E
t
E_t
Et为真实的局部截断误差。
当h足够小时,式(2.9)中各项的误差通常随着阶数的增加而减少。于是常常可以表示为:
E
a
=
f
′
(
x
i
,
y
i
)
2
!
∗
h
2
E_a = \frac{ f'(x_i, y_i)}{2!}*h^2
Ea=2!f′(xi,yi)∗h2(2.10)
或者:
E
a
=
O
(
h
2
)
E_a =O(h^2)
Ea=O(h2)(2.11)
E
t
E_t
Et为近似的局部截断误差。
泰勒级数给出了一种量化欧拉方程误差的方法。不过,这种方法使用时存在局限:
(1)泰勒级数仅能估计局部截断误差一即方法在一步迭代中所产生的误差。它不能估量传播截断误差,因此也不能估量全局截断误差。
(2)实际问题中处理的函数一般比简单多项式复杂。因此,计算泰勃级数展开时,导数值有时很难得到。
尽管这些限制使泰勒级数无法分析人多数实际问题的精确误差,但是它仍然有助于了解欧拉方法的性态。按照式(2.11)可发现局部误差与步长的平方和微分方程的一阶导数成正比。此外已经证明,全局截断误差为O(h),全局截断误差与步长成正比(Carnahan等人,1969)。
结论:
(1)缩短步长可以减少误差。
(2)因为直线的二阶导数为常数,所以如果基本函数(即微分方程的解)是线性的,那么方法能给出无误差的预测值。
由于欧拉方法使用直线段来逼近解,因此,欧拉方法称为一阶方法(first-order method)。
思考:如果使用二次来逼近解,也就是二阶方法,就能给出基本函数(即微分方程的解)是二次的问题的精确。同理,如果基本函数是n次多项式,则使用n阶方法可得出精确解。
2.1.3 欧拉方法的改进思路1——添加高阶项
减小欧拉方法的误差的一种方法是,在公式中加入泰勒级数展开的高阶项。例如,添加二阶项后,得到:
y
i
+
1
=
y
i
+
f
(
x
i
,
y
i
)
∗
h
+
f
′
(
x
i
,
y
i
)
2
!
∗
h
2
y_{i+1}=y_i+ f(x_i, y_i)*h+\frac{ f'(x_i, y_i)}{2!}*h^2
yi+1=yi+f(xi,yi)∗h+2!f′(xi,yi)∗h2(2.12)
于是局部截断误差变为:
E
a
=
f
′
′
(
x
i
,
y
i
)
3
!
∗
h
3
E_a = \frac{ f''(x_i, y_i)}{3!}*h^3
Ea=3!f′′(xi,yi)∗h3(2.13)
尽管添加高阶项对于处理多项式来说十分简单,不过有时候会使常微分方程变得更加复杂。特别地,如果常微分方程同时为自变量和因变量的函数,就需要通过链式法则来计算微分。例如,f(x,y)的一阶导数是:
f
′
(
x
,
y
)
=
∂
f
(
x
i
,
y
i
)
∂
x
+
∂
f
(
x
i
,
y
i
)
∂
y
d
y
d
x
f'(x,y) = \frac{ \partial{f(x_i, y_i)}}{\partial{x}} + \frac{ \partial{f(x_i, y_i)}}{\partial{y}}\frac{dy}{dx}
f′(x,y)=∂x∂f(xi,yi)+∂y∂f(xi,yi)dxdy
二阶导数是:
f
′
′
(
x
,
y
)
=
∂
[
∂
f
/
∂
x
+
(
∂
f
/
∂
y
)
(
d
y
/
d
x
)
]
∂
x
+
∂
[
∂
f
/
∂
x
+
(
∂
f
/
∂
y
)
(
d
y
/
d
x
)
]
∂
y
d
y
d
x
f''(x,y) = \frac{ \partial[\partial{f}/\partial{x} + (\partial{f}/\partial{y})(dy/dx) ]}{\partial{x}} + \frac{ \partial[\partial{f}/\partial{x} + (\partial{f}/\partial{y})(dy/dx) ]}{\partial{y}}\frac{dy}{dx}
f′′(x,y)=∂x∂[∂f/∂x+(∂f/∂y)(dy/dx)]+∂y∂[∂f/∂x+(∂f/∂y)(dy/dx)]dxdy
高阶导数会变得越来越复杂。而综合其计算量,其在性能上其实与一阶泰勒级数方法差不多,而一阶泰勒展开的欧拉方法只需要计算一阶导数,实现起来会简洁很多。因此,添加高阶项的方法其实并不是很实用。
2.1.4 欧拉方法的改进思路2——对斜率采用更好的估值方法
在“注意1”中我们提到,欧拉方法是将区间左端点处的斜率当作斜率在整个区间上平均值的逼近。但估值毕竟是估值,不是精确值,所以这个估值的精确度会严重影响计算的结果。
于是我们思考,有没有什么其他估计斜率的其他方法,能够给出更好的估值,从而得到更精确的预测值。
基于这个想法,下面给出了两种简单的修正方法来克服这个估值不精确的问题:修恩法和中点方法。
(这两种方法其实都属于一个更广泛的类型—龙格一库塔法。)
2.1.4.1 修恩法
改进斜率估计值的一种方法是,在区间上计算两个导数值:一个在区间的起始点处,一个在区间的终点处。然后,将这两个导数的平均值作为斜率在整个区间上的改进估计值。这种方法,称为修恩法(Heun’s method),其示意图如下图所示。

图5 修恩法的示意图:(a)预估和(b)校正
前面介绍过,在欧拉方法中,区间起始点处的斜率为:
y
i
′
=
f
(
x
i
,
y
i
)
y_i' = f(x_i, y_i)
yi′=f(xi,yi) (2.15)
利用这个值线性外推出
y
i
+
1
y_{i+1}
yi+1:
y
i
+
1
0
=
y
i
+
f
(
x
i
,
y
i
)
h
y^0_{i+1} = y_i + f(x_i, y_i)h
yi+10=yi+f(xi,yi)h (2.16)
标准的欧拉方法算到这一步就停止了。然而,在修恩法中,由式(2.16)得出的
y
i
+
1
0
y^0_{i+1}
yi+10并不是最终结果,而是一个中间的预测值。式(2.16)称为预估表达式(predictor equation)。该式给出了
y
i
+
1
y_{i+1}
yi+1的一个估计值,利用这个估计值又可以计算区间终点处的斜率(形式如式(2.15)):
y
i
+
1
′
=
f
(
x
i
+
1
,
y
i
+
1
0
)
y_{i+1}' = f(x_{i+1}, y^0_{i+1})
yi+1′=f(xi+1,yi+10) (2.17)
我们得到两个斜率估计值
y
i
′
y_{i}'
yi′和
y
i
+
1
′
y_{i+1}'
yi+1′(式(2.15)和式(2.17)),于是可以计算斜率的区间平均值:
y
i
ˉ
′
=
y
i
′
+
y
i
+
1
′
2
=
f
(
x
i
,
y
i
)
+
f
(
x
i
+
1
,
y
i
+
1
0
)
2
\bar{y_i}' = \frac{y_i' + y_{i+1}'}{2} = \frac{ f(x_i, y_i) + f(x_{i+1}, y^0_{i+1})}{2}
yiˉ′=2yi′+yi+1′=2f(xi,yi)+f(xi+1,yi+10) (2.18)
然后,按照欧拉方法,利用这个平均斜率由
y
i
y_i
yi线性外推出
y
i
+
1
y_{i+1}
yi+1:
y
i
+
1
=
y
i
+
f
(
x
i
,
y
i
)
+
f
(
x
i
+
1
,
y
i
+
1
0
)
2
h
y_{i+1} = y_i + \frac{ f(x_i, y_i) + f(x_{i+1}, y^0_{i+1})}{2} h
yi+1=yi+2f(xi,yi)+f(xi+1,yi+10)h (2.19)
此式称为校正表达式((corrector equation)。
修恩法是一种预估一校正方法{predictor-corrector approach)。
修恩法可简洁地表示为:
预估:
y
i
+
1
0
=
y
i
+
f
(
x
i
,
y
i
)
h
y^0_{i+1} = y_i + f(x_i, y_i)h
yi+10=yi+f(xi,yi)h (2.16)
校正:
y
i
+
1
=
y
i
+
f
(
x
i
,
y
i
)
+
f
(
x
i
+
1
,
y
i
+
1
0
)
2
h
y_{i+1} = y_i + \frac{ f(x_i, y_i) + f(x_{i+1}, y^0_{i+1})}{2} h
yi+1=yi+2f(xi,yi)+f(xi+1,yi+10)h (2.19)
迭代修恩法:
因为式(2.19)的等号两边都含有
y
i
+
1
y_{i+1}
yi+1,所以该式可以按迭代方式计算,可以反复使用旧的估计值计算出改进后的
y
i
+
1
y_{i+1}
yi+1值。// 需要注意的是,这个迭代过程并不一定能收敛到真实解,不过它将收敛到一个截断误差有限的估计值。
校正过程收敛的终止条件为:
∣
ε
a
∣
=
∣
y
i
+
1
j
−
y
i
+
1
j
−
1
y
i
+
1
j
∣
100
%
|\varepsilon_a| = |\frac{y^j_{i+1} - y^{j-1}_{i+1}}{y^j_{i+1}}|100\%
∣εa∣=∣yi+1jyi+1j−yi+1j−1∣100%
其中,
y
i
+
1
j
−
1
y^{j-1}_{i+1}
yi+1j−1和
y
i
+
1
j
y^j_{i+1}
yi+1j分别为上一校正步的结果和当前校正步的结果。
// 前面没有迭代校正的修恩法,可称为简单修恩法;经过迭代计算校正的修恩法,可以称为迭代修恩法。
特殊情况:
在前面的例子中,导数
d
y
/
d
x
dy/dx
dy/dx同时为因变量y和自变量x的函数(
d
y
/
d
x
=
f
(
x
,
y
)
dy/dx = f(x,y)
dy/dx=f(x,y))。对于常微分方程仅与自变量有关的情况(
d
y
/
d
x
=
f
(
x
)
dy/dx = f(x)
dy/dx=f(x)),求解过程中并不需要预估步(式(2.16)),而且每次迭代中也只需一次校正。在这种情况下,方法简化为
y
i
+
1
=
y
i
+
f
(
x
i
)
+
f
(
x
i
+
1
)
2
h
y_{i+1} = y_i + \frac{ f(x_i) + f(x_{i+1})}{2} h
yi+1=yi+2f(xi)+f(xi+1)h (2.19)
该式与“数值积分方法的总结”第1.1.1节 梯形法则(2点积分)其实是等价的。相应的截断误差也与梯形法则一样为:
E
t
=
−
f
′
′
(
ξ
)
12
h
3
E_t = - \frac{f''(\xi)}{12}h^3
Et=−12f′′(ξ)h3
由于真解是二次多项式时,常微分方程的二阶导数为0,所以方法是二阶精度的。另外,局部和全局误差分别为 O ( h 3 ) O(h^3) O(h3)和 O ( h 2 ) O(h^2) O(h2),因此,减小步长时,误差减小的速度比欧拉方法快。
2.1.4.2 中点方法
图5和式(2.16)( y i + 1 0 = y i + f ( x i , y i ) h y^0_{i+1} = y_i + f(x_i, y_i)h yi+10=yi+f(xi,yi)h )使用了端点处的值 y i + 1 y_{i+1} yi+1 来修正斜率的。
那么是不是也可以考虑用中点处的值来修正斜率??
于是产生了另一种简单的欧拉方法的修正方法(如图6所示)。该方法称为中点方法(midpoint method)(或改进的多边形法(improved polygon),或修正的欧拉方法(modified Euler)),利用欧拉方法预测区间中点处的y值(图6(a)):
y
i
+
1
/
2
=
y
i
+
f
(
x
i
,
y
i
)
h
/
2
y_{i+1/2} = y_i + f(x_i, y_i)h/2
yi+1/2=yi+f(xi,yi)h/2 (2.20)
然后用这个值来计算中点处的斜率:
y
i
+
1
/
2
′
=
f
(
x
i
+
1
/
2
,
y
i
+
1
/
2
)
y_{i+1/2}' = f(x_{i+1/2}, y_{i+1/2})
yi+1/2′=f(xi+1/2,yi+1/2) (2.21)
假设这个值是对整个区间的斜率平均值的有效近似,那么由
x
i
x_i
xi线性外推出
x
i
+
1
x_{i+1}
xi+1处的值为:
y
i
+
1
=
y
i
+
f
(
x
i
+
1
/
2
,
y
i
+
1
/
2
)
h
y_{i+1} = y_i + f(x_{i+1/2}, y_{i+1/2}) h
yi+1=yi+f(xi+1/2,yi+1/2)h (2.22)
// 注意对比式(2.20)、(2.20)、(2.20)与 (2.16)、 (2.17)、 (2.19),就可以清晰地看出中点法和修恩法的区别。

图6 中点公式的示意图。(a)式(2.20)}和(b)式(2.22)
因为式(2.22)只有等式的一边含 y i + 1 y_{i+1} yi+1,所以这种方法的结果无法像修恩法一样采用迭代校正的办法来改进。
(本方法也可同牛顿一柯特斯开型公式的中点公式结合起来理解。)
因为中点方法利用区间中点处的斜率估计值,它理论上比端点(起点)处的斜率估计值要更好(//关于数值微分的讨论知,中心有限差分逼近导数的效果比前向或后向差分都要好),所以中点方法优于欧拉方法。中点方法的局部和全局误差分别为 O ( h 3 ) O(h^3) O(h3)和 O ( h 2 ) O(h^2) O(h2)。
2.1.5 欧拉方法的改进思路3
思考:上一节提到的中点法,就类似计算积分的时候,取中点计算估值(1点积分);修恩法,就类似于梯形法计算积分(2点积分)。回想在“数值积分方法的总结”积分计算中,除了梯形法则(2点积分),我们还讲到了3点积分和4点积分,区别就在于用二次曲线和三次曲线来逼近使积分结果更加接近真实值。那么,这个地方,如果我们能计算或者估算出三个点或者四个点,是否也能用类似的方法,使求解的结果更接近真实值?
2.2 龙格-库塔法
龙格一库塔法(Range-Kutta)(RK)无需计算高阶导数,也可以达到与泰勒级数方法同样的精度。龙格一库塔法存在许多不同版本,但它们都可以写成式(25.1)的一般形式
y
i
+
1
=
y
i
+
ϕ
(
x
i
,
y
i
,
h
)
h
y_{i+1} = y_i + \phi(x_i, y_i, h)h
yi+1=yi+ϕ(xi,yi,h)h (2.23)
其中,
ϕ
(
x
i
,
y
i
,
h
)
\phi(x_i, y_i, h)
ϕ(xi,yi,h)称为增量函数((increment function),它表示整个区间上的斜率。增量函数的一般形式是

k1出现在k2的表达式中,k2又出现在k3的表达式中,等等。因为每个k都是由函数赋值的,所以这种
递归关系提高了龙格-库塔法的计算效率。
将增量函数的项数记为n,n值的不同就对应着不同类型的龙格一库塔法。n=1时,一阶龙格-库塔法,实际上就是欧拉方法。
2.2.1 二阶龙格-库塔法
前面提到,欧拉方法其实是利用了泰勒的一阶展开。那么,如果对应泰勒二阶展开,就是
y
i
+
1
=
y
i
+
f
(
x
i
,
y
i
)
∗
h
+
f
′
(
x
i
,
y
i
)
2
!
∗
h
2
y_{i+1}=y_i+f(x_i,y_i)*h+\frac{f'(x_i,y_i)}{2!}*h^2
yi+1=yi+f(xi,yi)∗h+2!f′(xi,yi)∗h2(2.24)
通过链式微分法则计算
f
′
(
x
,
y
)
f'(x,y)
f′(x,y)
f
′
(
x
i
,
y
i
)
=
∂
f
(
x
i
,
y
i
)
∂
x
+
∂
f
(
x
i
,
y
i
)
∂
y
d
y
d
x
f'(x_i,y_i) = \frac{ \partial{f(x_i, y_i)}}{\partial{x}} + \frac{ \partial{f(x_i, y_i)}}{\partial{y}}\frac{dy}{dx}
f′(xi,yi)=∂x∂f(xi,yi)+∂y∂f(xi,yi)dxdy(2.25)
将式(2.25)代入式(2.24)有
y
i
+
1
=
y
i
+
f
(
x
i
,
y
i
)
∗
h
+
[
∂
f
(
x
i
,
y
i
)
∂
x
+
∂
f
(
x
i
,
y
i
)
∂
y
d
y
d
x
]
∗
h
2
2
!
y_{i+1}=y_i+f(x_i,y_i)*h+[\frac{ \partial{f(x_i, y_i)}}{\partial{x}} + \frac{ \partial{f(x_i, y_i)}}{\partial{y}}\frac{dy}{dx}]*\frac{h^2}{2!}
yi+1=yi+f(xi,yi)∗h+[∂x∂f(xi,yi)+∂y∂f(xi,yi)dxdy]∗2!h2(2.26)
而龙格-库塔法中,当k取2时,即为二阶龙格-库塔法:
y
i
+
1
=
y
i
+
(
a
1
k
1
+
a
2
k
2
)
∗
h
y_{i+1}=y_i + (a_1k_1 + a_2k_2)*h
yi+1=yi+(a1k1+a2k2)∗h(2.27)
k
1
=
f
(
x
i
,
y
i
)
k_1=f(x_i,y_i)
k1=f(xi,yi)(2.27a)
k
2
=
f
(
x
i
+
p
1
h
,
y
i
+
q
11
k
1
h
)
k_2=f(x_i + p_1h, y_i + q_{11}k_1h)
k2=f(xi+p1h,yi+q11k1h)(2.27b)
这个地方,
k
2
k_2
k2写成了
f
(
x
i
+
p
1
h
,
y
i
+
q
11
k
1
h
)
f(x_i + p_1h, y_i + q_{11}k_1h)
f(xi+p1h,yi+q11k1h)的形式,这很自然联想到也可以用泰勒展开表达该式,于是得到:

将k1、k2都带入式2.27中得到:

想要让二阶龙格-库塔法(即式2.27)等价于二阶泰勒展开(2.26),那么就必须满足:
a
1
+
a
2
=
1
a_1+a_2 = 1
a1+a2=1
a
1
p
1
=
1
/
2
a_1p_1=1/2
a1p1=1/2
a
2
q
11
=
1
/
2
a_2q_{11}=1/2
a2q11=1/2
由于有三个方程,四个未知数,所以上述方程组有无穷多个解。
其中,几种典型的解的意义:
如果令a2 = 1/2,那么a1=1/2,p1=q11=1,这时其实就是单步的修恩法;
如果令a2 = 1,那么a1=0,p1=q11=1/2,这时其实就是中点方法。
如果令a2 = 2/3,那么a1=1/3,p1=q11=3/4,这种方法叫罗森方法。
值得注意的是:罗森和Rabinowitz指出,对于二阶龙格一库塔法,在所有取值中,当a2取2/3时对应的截断误差界最小。此时:

二阶龙格-库塔法局部和全局误差分别为 O ( h 3 ) O(h^3) O(h3)和 O ( h 2 ) O(h^2) O(h2)。
2.2.2 三阶龙格-库塔法
对于n=3的情况,公式的推导过程与二阶方法类似。推导的结果是含8个未知数的6个方程。因此,必须事先指定两个未知数的值,才能确定剩下的参数。一类常用的三阶龙格-库塔法是:
y
i
+
1
=
y
i
+
1
6
(
k
1
+
4
k
2
+
k
3
)
∗
h
y_{i+1}=y_i + \frac{1}{6} (k_1 + 4k_2 + k_3)*h
yi+1=yi+61(k1+4k2+k3)∗h(2.28)

如果导数仅为x的函数,那么这个三阶方法退化为辛普森1/3法则。
三阶龙格一库塔法,其局部和全局误差分别为 O ( h 4 ) O(h^4) O(h4)和 O ( h 3 ) O(h^3) O(h3)。并且能精确地求出三次多项式解。
2.2.2+ 牛顿积分公式
这个地方,有必要将牛顿-科特斯积分公式的系数拿出来和龙格-库塔法的系数做一下对比:

2.2.3 四阶龙格-库塔法
龙格-库塔法中,最流行的是四阶方法。与二阶方法一样,四阶方法也有无限多个版木。下面是最常用到的形式,称为经典四阶龙格-库塔法(classical fourth-order RK method):
y
i
+
1
=
y
i
+
1
6
(
k
1
+
2
k
2
+
2
k
3
+
k
4
)
∗
h
y_{i+1}=y_i + \frac{1}{6} (k_1 + 2k_2 + 2k_3 + k_4)*h
yi+1=yi+61(k1+2k2+2k3+k4)∗h(2.29)
其中,

四阶龙格一库塔法,其局部和全局误差分别为
O
(
h
5
)
O(h^5)
O(h5)和
O
(
h
4
)
O(h^4)
O(h4)。并且能精确地求出四次多项式解。
注意:对于前面的二阶、三阶龙格一库塔法,其系数都与牛顿-科特斯积分公式的系数相同。但是对于牛顿积分公式,对应的辛普森3/8法则的系数为1/8、3/8、3/8、1/8,而这个地方为1/6、2/6、2/6、1/6,读者可以下去自己尝试一下如果四阶龙格-库塔法系数用1/8、3/8、3/8、1/8,计算会不会有什么不同??
2.2.4 高阶龙格-库塔法
对于精度要求更高的情况,建议使用巴特切五阶龙格-库塔法。
y
i
+
1
=
y
i
+
1
90
(
7
k
1
+
32
k
3
+
12
k
4
+
32
k
5
+
7
k
6
)
∗
h
y_{i+1}=y_i + \frac{1}{90} (7k_1 + 32k_3 + 12k_4 + 32k_5+ 7k_6)*h
yi+1=yi+901(7k1+32k3+12k4+32k5+7k6)∗h(2.30)
其中,

请注意,巴特切五阶方法中需要计算6次函数值。
尽管存在许多高阶龙格-库塔法,但是,一般地,对于四阶以上公式来说,精度的提高会被计算量和复杂度的增加而抵消。
2.2.5 龙格-库塔法分析
从上面的一到五阶龙格-库塔法公式可以看出,当阶数<=4时,需要计算函数值的次数等于方法的阶数。当n为5或者大于5的时候,计算函数值的次数或大于方法的阶数。所以,四阶龙格-库塔法是一个比较经典的阶数。
如果分别利用欧拉方法、非迭代修恩法、三阶龙格-库塔法、经典四阶龙格-库塔法和巴特切五阶龙格一库塔法进行计算。各方法的百分比相对误差的绝对值与计算开销的关系如图25-16所示。这里,计算开销等于求解过程中需要计算的函数值的个数,即
开销
=
n
f
b
−
a
h
开销 = n_f \frac{b-a}{h}
开销=nfhb−a(2.31)
其中,
n
f
n_f
nf为特定的龙格一库塔法中需计算的函数值个数。(b - a)/h为整个积分区间长度除以步长,也就是说,它表示计算过程中需要应用龙格-库塔方法的次数。这样,因为函数值计算一般占去了单步迭代中的大部分时间,所以式2.31给出了计算时间的一个粗略估计。

从上面的分析中,可以得出一些结论:首先,在同样的计算开销下,高阶方法的结果更精确;其次,在某点之后,随着计算开销的增加,精度的提高开始变慢(注意曲线起初下降得很快,然后趋于平缓)。在应用中应该优先选择高阶龙格一库塔法。//不过,在选择求解方法时,还有许多其他因素需要考虑,比如编程的代价和问题的精度要求。
3 一阶常微分方程组
在本文第1.1节中讲到,高阶微分方程可以分解成多个一阶方程组的形式。
许多实际问题往往也需要求解几个联立的常微分方程组成的方程组。
方程组的一般表示形式为:
d
y
1
d
x
=
f
(
x
,
y
1
,
y
2
,
.
.
.
,
y
n
)
\frac{dy_1}{dx} = f(x, y_1, y_2, ..., y_n)
dxdy1=f(x,y1,y2,...,yn)
d
y
2
d
x
=
f
(
x
,
y
1
,
y
2
,
.
.
.
,
y
n
)
\frac{dy_2}{dx} = f(x, y_1, y_2, ..., y_n)
dxdy2=f(x,y1,y2,...,yn)
…
d
y
n
d
x
=
f
(
x
,
y
1
,
y
2
,
.
.
.
,
y
n
)
\frac{dy_n}{dx} = f(x, y_1, y_2, ..., y_n)
dxdyn=f(x,y1,y2,...,yn)(3.1)
要求解这样的一个方程组,必须知道x的起始点处的n个初始条件。
3.1 欧拉方法
上一节中所讲的关于单个方程数值解法的讨论,都可以推广到上面给出的方程组。
每个方程组的求解过程为,在开始下一步迭代之前,对当前步中的每个方程应用单步法求解。

重复上述过程,直到x=2。
3.2 龙格-库塔法
上一节中所讲的任何高阶龙格-库塔法都可以应用于方程组的求解。// 方法与欧拉法类似。
4 自适应龙格·库塔法
到目前为止,我们讨论了步长取常数的常微分方程数值解法。
但实际中,方程的曲线在有的地方变化缓慢,有的地方变化剧烈。在变化缓慢的地方可以用大一点的步长,在变化剧烈的地方可以取小一点的步长。于是就有了自动调整步长的算法。
自动调整步长的算法可以避免保证计算精度的同时提高效率。
自适应步长控制((adaptive step-sixe control)的方法在执行过程中需要估计每一步的局部截断误差。然后,根据该误差估计值确定步长应该变大还是缩小。
4.1 步长控制中的误差估计方法
在单步法中加入自适应步长控制主要有两种方式:
第一种方式是,计算同阶龙格-库塔法在两个不同步长F的预测值,将这两个值之差作为误差的估计值;
第二种方式是,算出两个不同阶龙格-库塔法的预测值,将它们的差作为局部截断误差的估计值。
4.1.1 自适应龙格-库塔法或步长——对分法
步长控制的第一种方式,就是先用步长h计算一个
y
h
y_h
yh,然后再用步长为h/2分两步计算
y
h
y_h
yh,比较这两个计算结果的差值,将这个差值作为局部截断误差的估计值。
若记
y
1
y_1
y1为单步预测值,
y
2
y_2
y2为两个半步所得到的预侧值,则误差
Δ
\Delta
Δ可表示为:
Δ
=
y
2
−
y
1
\Delta = y_2-y_1
Δ=y2−y1(3.2)
这个 Δ \Delta Δ就可用于作为控制步长的标准。
此外,
Δ
\Delta
Δ还可以用于校正
y
2
y_2
y2的预测值。譬如说,对于四阶龙格-库塔法,其估值原本具有四阶精度。如果用式(3.3)校正后,可达到五阶精度。// 具体原因,可以结合“龙贝格积分的递推思路”?
y
2
←
y
2
+
Δ
/
15
y_2 \gets y_2 + \Delta / 15
y2←y2+Δ/15(3.3)
4.1.2 龙格-库塔-费尔贝格法
步长控制的第二种方式,先用四阶龙格-库塔法计算一个预测值 y 1 y_1 y1,再用五阶龙格-库塔法计算一个预测值 y 2 y_2 y2,(当然,也可以考虑用一个二阶+一个三阶;也或者用一个二阶+一个四阶,都是可以的。)然后比较这两个计算结果的差值。
该方法的一个缺点是,计算开销增长过大。例如,若使用四阶和五阶格式作为预测步,则每步总共要计算10次函数值(四阶4次,五阶6次)。
有没有什么方法可以客服上述问题呢??
于是我们就思考,如何重复利用计算过的函数值。譬如说,如果在五阶龙格-库塔法中能使用所有四阶龙格-库塔法所计算的函数值,这样只需要计算6次函数值,就得到一个误差估计。
沿着这个思路,因为四阶和五阶的龙格-库塔法都有很多种不同的系数组合方式,如果使用下列的四阶和五阶公式:
y
i
+
1
=
y
i
+
(
37
378
k
1
+
250
621
k
3
+
125
594
k
4
+
512
1771
k
6
)
∗
h
y_{i+1}=y_i + (\frac{37}{378}k_1 + \frac{250}{621}k_3 + \frac{125}{594}k_4 + \frac{512}{1771}k_6)*h
yi+1=yi+(37837k1+621250k3+594125k4+1771512k6)∗h(3.4)
y
i
+
1
=
y
i
+
(
2825
27648
k
1
+
18575
48384
k
3
+
13525
55296
k
4
+
277
14336
k
5
+
1
4
k
6
)
∗
h
y_{i+1}=y_i + (\frac{2825}{27648}k_1 + \frac{18575}{48384}k_3 + \frac{13525}{55296}k_4 + \frac{277}{14336}k_5 + \frac{1}{4}k_6)*h
yi+1=yi+(276482825k1+4838418575k3+5529613525k4+14336277k5+41k6)∗h(3.5)
其中,

利用式(3.4)和式(3.5)计算2个预测值,然后用两个预测值之差作为误差的估计值。
4.1.3 其他改进思路
思考,在自适应龙格-库塔法或步长——对分法,因为一阶和二阶是从一个点到两个点来计算预测值,然后用两个预测值只差计算出误差估计值。然后误差估计值又可用于改进预测值,能提高一阶精度。
思路一:是不是也可以用二阶和四阶的两个预测值来计算估计值,然后用该估计值来改进预测值,会不会带来更好的效果??
思路二:因为之前提到过,五阶是不太划算的,因为五阶要计算六次函数值。那么是否可以考虑用三阶和四阶搭配来计算两次预测值?或者二阶和四阶搭配?能否在各种搭配中找出更高效的方法。
4.2 步长控制
上一节介绍了估计局部截断误差的方法,利用它可以调整步长。若误差很小,则增大步长;若误差很大,则减小步长。为此,Press等人提出了下面的标准:
h
n
e
w
=
h
p
r
e
s
e
n
t
∣
Δ
n
e
w
Δ
p
r
e
s
e
n
t
∣
α
h_{new} = h_{present}|\frac{\Delta_{new}}{\Delta_{present}}|^{\alpha}
hnew=hpresent∣ΔpresentΔnew∣α(3.6)

为啥
α
\alpha
α取0.2或0.25?因为四阶和五阶开4次方和开5次方正好是1/4和1/5?
式(3.6)中的关键参数是 Δ n e w \Delta_{new} Δnew,因为它可用于指定期望精度。
一种方法是,将
Δ
n
e
w
\Delta_{new}
Δnew与一个相对误差水平联系起来。但是当解越过零点时,会产生一些问题。处理这种情况的一个更通用的方法是,将
Δ
n
e
w
\Delta_{new}
Δnew定义为
Δ
n
e
w
=
ε
y
s
c
a
l
e
\Delta_{new} = \varepsilon y_{scale}
Δnew=εyscale (3.7)
其中,
ε
\varepsilon
ε为整体容许水平。
y
s
c
a
l
e
y_{scale}
yscale的选取将决定误差的尺度。其中常见
y
s
c
a
l
e
y_{scale}
yscale采用下式:
y
s
c
a
l
e
=
∣
y
∣
+
∣
h
d
y
d
x
∣
y_{scale} = |y|+|h\frac{d_y}{d_x}|
yscale=∣y∣+∣hdxdy∣

图中的点表示由自适应步长例程得出的预测值

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐
 19
19 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)