
NHANES数据库的介绍及使用(一)
一、数据库概况NHANES(National Health and Nutrition Examination Survey)是一项旨在评估美国成人和儿童健康和营养状况的研究计划,计划始于20世纪60年代初期,是一项针对不同人群或健康主题的调查。1999年该调查成为一项持续计划,涉及各种健康和营养测量,项目每年调查一个全国代表性的样本,约5000人,这些人群位于全国各县,每年对其中15个县进行访问
目录
一、数据库概况
NHANES(National Health and Nutrition Examination Survey)是一项旨在评估美国成人和儿童健康和营养状况的研究计划,计划始于20世纪60年代初期,是一项针对不同人群或健康主题的调查。
1999年该调查成为一项持续计划,涉及各种健康和营养测量,项目每年调查一个全国代表性的样本,约5000人,这些人群位于全国各县,每年对其中15个县进行访问。
NHANES访谈部分包括人口统计学、社会经济学、饮食和健康相关问题。体检部分包括生理测量、实验室检查等内容。调查结果将用于确定主要疾病的患病率和疾病的风险因素,也是身高、体重和血压等国家标准的基础。
(每两年进行一次调查,两年称为一个cycle year)
数据类型
主要分为Demographic data, dietary data, Examination Data, Laboratory Data, Questionnaire Data及Limited Access Data,除了Limited Access Data外,其余数据类型都可以免费使用。Limited Access Data则包括了一些地址信息及敏感信息,详细信息可通过Research Data Center中申请。
涵盖疾病类型
各个疾病类型,如下

研究设计
NHANES采用分层多阶段抽样设计,以获得美国居民的代表性样本,抽样计划由四个阶段组成:
- PSU 县(counties)
- PSU内的城市街区(segments)
- DU住户、家庭(households)
- SP个人(individuals)

权重
衡量特定参与者所代表的目标人群中人数的参数,反应了不平等的选择概率,对纳入人员不响应的调整,以及对最终样本和基于独立人口控制总数的总人口之间差异的调整。
基本公式:

但实际情况并非随机采样,对某些具有特殊公共卫生利益的亚群体,如:非西班牙裔黑人;西班牙裔的性别年龄组等,进行过采样(Oversampling),即进行更多的抽样调查。过度采样是为了增加特定亚群的样本数量,从而提高这些人口亚群健康状况指标估计值的可靠性和精确度。
过采样会导致各个人群抽样概率的不均等,如对美国人群种族分布的频率图中,未加权的一组人群中,除了Non-Hispanic white and other,其他种族的人均存在oversampling,会导致抽样人群与总体人群分布的差异。

如果直接对抽样人群进行疾病患病率的估计,则会歪曲患病率的结果。如对年龄超过18岁的成年人进行高血压患病率的估计,未加权的人群中高血压患病率显著高于加权人群,可能是由于不同种族人群高血压患病率不同,非西班牙裔黑人的高血压患病率显著高于其他种族,对此类人群进行过采样导致整体高血压患病率的升高。

因此,有必要对NHANES数据库中的人群进行加权。
二、加权
权重类别
分为四个类别,主要为wtint2yr,wtmec2yr,subsample weights及24小时饮食召回。
- The interview weight (wtint2yr)
- The MEC exam weight (wtmec2yr)
- Several subsample weights
- 24-hour dietary recall
权重选择
(1)所有变量都在in-home interview中收集,采用wtint2yr;(2)一些变量是在MEC中收集,采用wtmec2yr;(3)一些变量是调查子样本的一部分,采用相应子样本的权重,如研究变量中有空腹甘油三酯(接受检测的人大约是接受MEC检查的样本的一半,采用wtsaf2yr,多周期的话要注意使用合并权重;(4)一些变量来自24小时饮食召回(24-hour dietary recall):变量来自第一天的recall,采用wtdrd1;使用两天的recall进行分析,采用wtdr2d,多周期的话要注意使用合并权重
选择原则:“the least common denominator“ 选择样本数量最少的变量对应的权重进行校正。选择之前,你需要找出你感兴趣的变量包括在调查的哪个部分中。
接下来举几个示例:
例一:所有感兴趣变量都在居家访谈时纳入,选择的权重为wtint4yr.(两个cycle的权重)

例二:部分变量在MEC过程中获得

blood pressure变量涵盖的样本量为11,062,少于in-home interview的样本量,根据变量最少原则,因此权重应该选择wtmec4yr。
例三:部分变量为调查研究中的子集中的部分

根据变量最少原则,权重应该选择wtsaf4yr。
请注意,有些问卷成分是在MEC检查期间进行的,而不是在家庭访谈期间进行的,因此必须对这些成分使用MEC检查权重。
权重计算
所有访谈和MEC的权重都可以在相应调查周期的人口统计文件中找到,但涉及到多个cycle数据合并时,需要进行权重的计算。由于多个cycle合并时,每个cycle中人群的权重被过高估计,因此应该除以相对应的cycle数目。详细计算如下:
权重计算分为两部分:
(1)1999-2002四年(2 cycles)权重
这两个cycle的数据同时提供了wtint2yr、wtmec2yr及wtint4yr、wtmec4yr,在分析中整合1999-2000年和2001-2002年的调查年份时,必须使用NCHS提供的4年样本加权,以说明两个不同的参考人群。
(2)2001-2002及以后的样本权重
将两年的样本权重除以分析中的两年周期数来计算新的multi-year样本权重。
公式:weight= wtmec2yr/cycle year
示例:
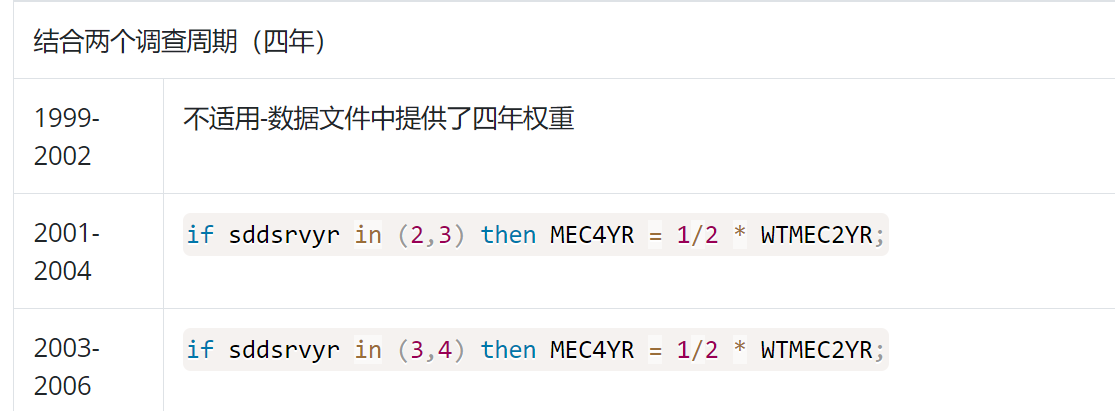
a.结合两个调查周期(4年)
MEC4YR = 1/2 * WTMEC2YR,1999-2002时直接使用MEC4YR
b.结合三个调查周期(6年)
计算1999-2004年六年的权重时,当year在1999-2002时,MEC6YR=2/3* WTMEC4YR,year在2003-2004时,MEC6YR=1/3* WTMEC2YR。2001年以后时,MEC6YR=1/3* WTMEC2YR。

*SDDSRVYR 是调查周期编号, i.e.
1 = 1999-2000
2 = 2001-2002
3 = 2003-2004
c.

d.

三、数据下载
1.登录首页:https://www.cdc.gov/nchs/nhanes/index.htm

2.选择特定年份

3.选择需要的数据集

环境领域中的暴露来源参考Laboratory Data,
健康结局参考Examination Data,
相关协变量参考Demographic Data和Questionnaire Data
4.理解数据变量,下载数据

“NHANES 2017-2018 Demographics Variable List”:所有变量列表;
“DEMO_I Doc”:关于所有变量采集和数据类型的详细说明;
“DEMO_I Data[XPT-3.3 MB]”:数据下载链接。
四、数据库应用
1.验证假设或预测模型
2.数据挖掘
3.构建预测模型

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 21
21 1
1- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)