
全网最详细的机器学习——下采样(under-sampling)
·
目录
一、什么是下采样?
1.查看样本数据
creditcard.csv(点击此处可下载所需数据)
#导入所需的库
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
#用pandas库的read_csv函数读取名为"creditcard.csv"的CSV文件,并将文件内容存储在data变量中
data = pd.read_csv("creditcard.csv")
#这行代码调用data的head()方法,显示data数据集的前几行内容
data.head()
显示结果如下:

- 这个数据,并不是最原始数据,而是通过降维操作把数据进行特征压缩。我们可以根据这些特征进行建模。
- 这些数据有一列Class标签,用来标注是否正常,
0表示正常,1表示异常。 - 这是经典的二分类问题。
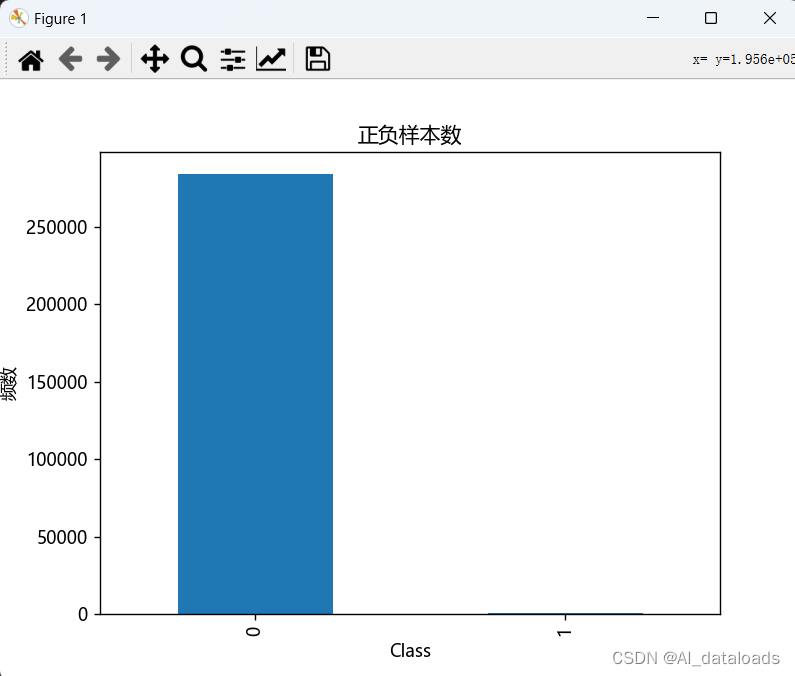
- 首先查看当前数据的正负样本的比例:
# 通过统计每个类别的数量,并按类别排序
count_classes = pd.value_counts(data['Class'], sort=True).sort_index()
# 使用柱状图展示类别频率
count_classes.plot(kind='bar')
# 设置图表标题
plt.title("正负样本数")
# 设置 x 轴标签
plt.xlabel("Class")
# 设置 y 轴标签
plt.ylabel("频数")
plt.show()
显示结果如下:可以看出数据比例非常的不均匀

- 可以看出
0样本占了大多数,1样本占了很少的数量。 - 因此两个数据量并不均衡,如何进行调整?
- 例如
0样本数据量有几十万,而1样本数据量大约几百个。可以让0样本采集几百个,跟1样本的数量同样少。这样两个数据就会趋于平衡。
2.特征分布
从creditcard.csv数据中可以看到,Amount列的数据与其他特征的数据值差异较大,一些算法会误以为数据大则重要程度高,所以为了使得每个特征的重要程度是相当的,需要对Amount的数据进行归一化。
我们可以通过sklearn进行处理:
"""数据标准化:Z标准化"""
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
data['Amount'] = scaler.fit_transform(data[['Amount']])
data = data.drop(['Time'],axis=1) #删除无用列
3.使用下采样进行调整
positive_eg = data[data['Class'] == 0]#获取到了所有标签(class)为0的数据
negative_eg = data[data['Class'] == 1]#获取到了所有标签(class)为1的数据
np.random.seed(seed=2) #随机种子,是保证每次你执行这个代码,随机抽选的结果都是一样
positive_eg = positive_eg.sample(len(negative_eg))#随机从参数里面选择数据
#拼接数据
data_c = pd.concat([positive_eg, negative_eg])# 是把两个pandas数据组合为一个
print(data_c)
运行结果:
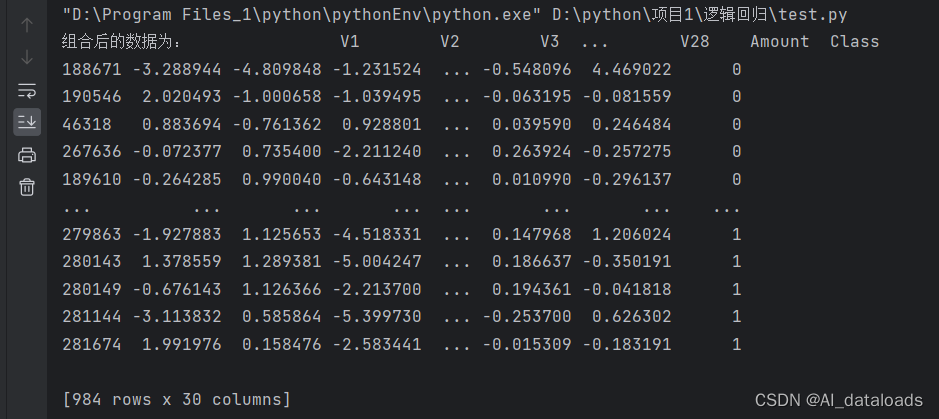
这样我们便会得到每个特征的重要程度是相当的数据。
4.进一步实验
训练集使用下采样数据,测试集使用原始数据进行预测:
from sklearn.model_selection import train_test_split
#对下采样数据划分
X = data_c.drop('Class', axis=1) #对data_c数据进行划分。
y = data_c.Class
x_train, x_test, y_train, y_test = \
train_test_split(X, y, test_size = 0.2, random_state = 0)
对原始数据集进行切分,用于后期的测试
X_whole = data.drop('Class', axis=1)
y_whole = data.Class
x_train_w, x_test_w, y_train_w, y_test_w = \
train_test_split(X_whole, y_whole, test_size = 0.2, random_state = 0)
5.执行交叉实验操作
目的:其主要目的是通过将数据集进行多次划分,每次划分中将一部分数据作为训练集,另一部分数据作为验证集,从而进行多次训练和验证,综合评估模型的性能。
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score
#交叉验证选择较优惩罚因子
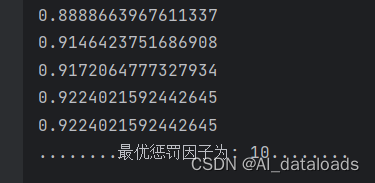
scores = []
c_param_range = [0.01,0.1,1,10,100]
for i in c_param_range:#第1词循环的时候C=0.01,5个逻辑回归模型
lr = LogisticRegression(C = i, penalty = 'l2', solver='lbfgs', max_iter=1000)
score = cross_val_score(lr, x_train, y_train, cv=10,scoring='recall')#
score_mean = sum(score)/len(score) # 交叉验证后的值召回率
scores.append(score_mean) #里面保存了所有的交叉验证召回率
print(score_mean)
#
best_c = c_param_range[np.argmax(scores)]
print("........最优惩罚因子为: {}........".format(best_c)) #
#
# """建立最优模型"""
lr = LogisticRegression(C = best_c, penalty = 'l2', max_iter = 1000)
lr.fit(x_train, y_train)
运行结果:
6.进行预测
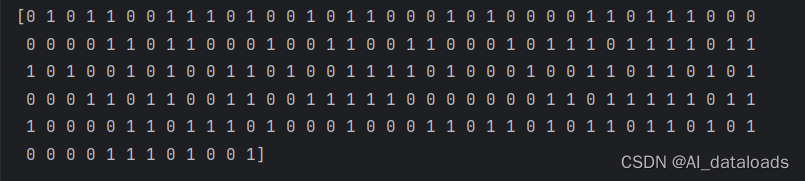
使用测试集数据进行测试【小测试集】
#预测结果
test_predicted = lr.predict(x_test)
print(test_predicted)
输出小测试集的预测结果:
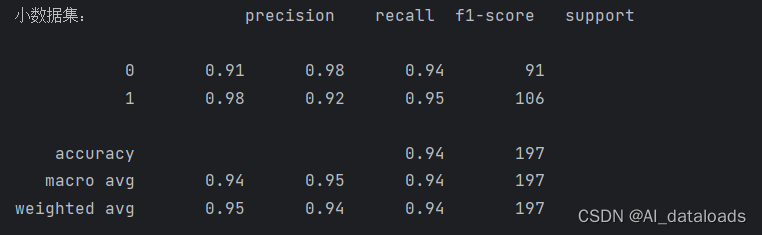
7.绘制混淆矩阵
作用:在逻辑回归中,混淆矩阵(Confusion Matrix)是一种用于衡量分类模型性能的常见工具。它通过将实际类别与预测类别进行组合,展示了分类模型在不同类别上的预测结果。
from sklearn import metrics
#绘制混淆矩阵
print(metrics.classification_report(y_test, test_predicted))
【小测试集】绘制结果:
使用【大数据集测试】
# """使用测试集数据进行测试【大测试集】"""
test_predicted = lr.predict(x_test_w)
#绘制混淆矩阵
print(metrics.classification_report(y_test_w, test_predicted))
测试结果:

二、下采样的优缺点
1.优点
- 解决不均衡问题: 下采样可以有效地解决不均衡数据集的问题,特别是当多数类别样本数量远大于少数类别样本数量时。通过减少多数类别样本的数量,使得多数类别和少数类别之间的样本分布更加平衡,提高了模型学习少数类别的能力。
- 降低计算成本: 下采样可以减少数据集的规模,从而降低了训练模型的计算成本。较小的数据集可以使模型的训练时间更短,加快模型的训练速度。
2.缺点
- 信息损失: 下采样会丢失多数类别的部分信息,可能导致模型在进行分类时丧失对多数类别的辨别能力。由于减少了多数类别的样本数量,模型可能无法很好地学习多数类别的特征和变化。
- 不适用于小型数据集: 当初始数据集本身非常小的时候,使用下采样可能会造成信息的严重损失。如果少数类别的样本数量已经较小,进一步减少可能会使得模型学习不到少数类别的特征。
- 随机性影响: 下采样通常是根据随机抽样的方式减少多数类别的样本数量。不同的随机抽样可能会导致不同的数据集,并且模型性能可能对样本选择非常敏感,引入了随机性的影响。
推荐内容
阅读全文
AI总结

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 6
6 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容
相关推荐
查看更多
FramePack
高效压缩打包视频帧的工具,优化存储与传输效率
public-apis
这个项目收集了大量公开可用的API接口,适合开发者查找和利用各类公开API来快速构建应用程序或获取所需数据,覆盖范围广泛,从社交、新闻到天气、地图等各种领域。
Tutorial-Codebase-Knowledge
Turns Codebase into Easy Tutorial with AI
热门开源项目
运营活动

活动日历
查看更多
直播时间 2025-04-09 14:34:18


樱花限定季|G-Star校园行&华中师范大学专场

直播时间 2025-04-07 14:51:20

樱花限定季|G-Star校园行&华中农业大学专场
直播时间 2025-03-26 14:30:09

开源工业物联实战!
直播时间 2025-03-25 14:30:17

Heygem.ai数字人超4000颗星火燎原!
直播时间 2025-03-13 18:32:35

全栈自研企业级AI平台:Java核心技术×私有化部署实战
目录

所有评论(0)