
深入理解dropout(原理+手动实现+实战)
在这篇博客中你可以学到什么是dropoutdropout为什么有用dropout中的多模型原理手动实现dropout在pytorch中使用dropout当训练一个深度神经网络时, 我们可以随机丢弃一部分神经元(同时丢弃其对应的连接边)来避免过拟合,这种方法就称为dropout(丢弃法)。每次选择丢弃的神经元是随机的.最简单的方法是设置一个固定的概率 p.对每一个神经元都以概率 p 随机丢弃(即置0
在这篇博客中你可以学到
- 什么是dropout
- dropout为什么有用
- dropout中的多模型原理
- 手动实现dropout
- 在pytorch中使用dropout
当训练一个深度神经网络时, 我们可以随机丢弃一部分神经元(同时丢弃其对应的连接边)来避免过拟合,这种方法就称为dropout(丢弃法)。
每次选择丢弃的神经元是随机的.最简单的方法是设置一个固定的概率 p.对每一个神经元都以概率 p 随机丢弃(即置0),其原理如下:

上图,Bernoulli是概率p的伯努利分布,取值为0或1,即该分布中的每一个元素取值为0的概率是p,
y
(
l
)
y_{}^{\left( l \right)}
y(l)表示第
l
l
l 个全连接层(或卷积层),x是特征向量
在没有使用dropout的情况下,第 l l l 层的神经元的值经过线性(或卷积)运算后,通过激活函数输出。
如果使用了dropout,第 l l l 层的神经元的值乘上概率为p的Bernoulli分布,假如第 l l l 层有10个神经元,那么产生的Bernoulli分布可能是 [ 0 , 1 , 1 , 0 , 0 , 1 , 0 , 0 , 0 , 1 ] T [0,1,1,0,0,1,0,0,0,1]^T [0,1,1,0,0,1,0,0,0,1]T(相当于以概率p=0.6随机将 l l l 层的神经元置0),然后第 l l l 层神经元的输出在第 l + 1 l+1 l+1 层经过线性(或卷积)运算后,再通过激活函数输出
在train阶段,dropout的本质通过在学习过程中随机删除神经元,从而每一次都让不同的模型进行学习。比如,以概率 p=0.6 随机将神经元置0,就相当于在10个神经元选4个神经元输出(4个神经元在工作,另外6神经元置0),这时我们就相当于训练了 C 10 4 C_{10}^4 C104 个模型,只是每个模型的参数量更少了(这也就是集成学习的思想)。使用了dropout的神经网络如下图所示:

左图是一般的神经网络,右图是应用了Dropout的网络,Dropout通过随机选择并删除神经元,停止向前传递信号
机器学习中经常使用集成学习。所谓集成学习,就是让多个模型单独进行学习,推理时再取多个模型的输出的平均值。用神经网络的语境来说,比如,准备5个结构相同(或者类似)的网络,分别进行学习,测试时,以这 5 个网络的输出的平均值作为答案。实验告诉们,通过进行集成学习,神经网络的识别精度可以提高好几个百分点,这个集成学习与Dropout 有密切的关系。这是因为可以将Dropout理解为,通过在学习过程中随机删除神经元,从而每一次都让不同的模型进行学习。并且,推理时,通过对神经元的输出乘以删除比例(比如,0.5 等),可以取得模型的平均值。
由于在测试时, 所有的神经元都是可以激活的, 这会造成训练和测试时网络的输出不一致,那么,测试的时候该怎么办呢?
答案是测试的时候让每个模型投票来得到结果。
比如,训练的时候,10个神经元置中6个置为0(p=0.6,相当于训练时随机删除了6个神经元,只有4个神经元在工作),测试的时候是用10个神经元来投票,那么每个神经元的权重是0.4( 1 − p = 0.4 1- p = 0.4 1−p=0.4),操作的方法是将dropout层这10个神经元的值加起来乘以0.4,即每个神经元的值都乘以0.4。
注意,是所有神经元输出的值乘以0.4,比如 10个神经元每次只选一个神经元工作(以概率p=0.9将神经元置0),就相当于训练了10个模型,最后这10个神经元的结果都要输出,做法是把这10个神经元的值加起来乘以0.1(测试时),即相当于投票得出了结果。但是输出的个数不能少,该输出几个数还是几个数。
有的教材设定保留神经元的概率为p(保留率),即神经元有效的概率是p,那么,测试的时候将dropout层的神经元乘以 p 输出,而这里神经元无效的概率是p(废弃率),因此,测试的时候将dropout层的神经元乘以 1-p 输出
总的来说,对于一个神经网络层 y = f ( W ⋅ X + b ) y = f\left( {W \cdot X + b} \right) y=f(W⋅X+b),我们可以引入一个掩蔽函数mask使得 y = f ( W ⋅ m a s k ( X ) + b ) y = f\left( {W \cdot ma{\rm{s}}k(X) + b} \right) y=f(W⋅mask(X)+b) ,设神经元废弃率为 p ,掩蔽函数mask可表示为:
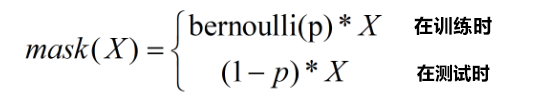
一般来讲, 对于隐藏层的神经元, 其废弃率 p = 0.5 时效果最好, 这对大部分的网络和任务都比较有效. 当 p = 0.5 时, 在训练时有一半的神经元被丢弃, 只剩余一半的神经元是可以激活的, 随机生成的网络结构最具多样性,比如10个神经元随机删除5个,则可训练的模型有 C 10 5 C_{10}^5 C105,相当于取了最大值。 对于输入层的神经元, 其保留率通常设为更接近 1 的数, 使得输入变化不会太大。 对输入层神经元进行丢弃时, 相当于给数据增加噪声, 以此来提高网络的鲁棒性。
下面我们就来实现dropout吧
手动实现dropout:
import numpy as np
class Dropout:
def __init__(self, dropout_ratio=0.5):
self.dropout_ratio = dropout_ratio
self.mask = None
def forward(self, x, train_flg=True):
if train_flg:
# *为序列解包
self.mask = np.random.rand(*x.shape) > self.dropout_ratio
return x * self.mask
else:
return x * (1.0 - self.dropout_ratio)
def backward(self, dout):
return dout * self.mask
这里的要点是,每次正向传播时,掩蔽函数self.mask中都会以False的形式保存要删除的神经元(相当于概率p的伯努利分布)。self.mask会随机生成和x形状相同的数组,并将值比dropout_ratio大的元素设为True。反向传播时的行为和ReLU相同。也就是说,正向传播时传递了信号的神经元,反向传播时按原样传递信号;正向传播时没有传递信号的神经元,反向传播时信号将停在那里。
在pytorch中使用dropout,只需要一行torch.nn.Dropout(p=0.5)即可,如下所示


旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 29
29 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)