

JMeter 5.5 使用详解(持续更新中......)
Jmeter核心组件、Jmeter程序设计通用规范、测试计划、线程组、setUP线程组、tearDown线程组、CSV数据文件设置、HTTP信息头管理器、HTTP Cookie管理器、HTTP缓存管理器、HTTP请求默认值、计数器、随机变量、用户定义的变量、Java默认请求、HTTP授权管理器、DNS缓存管理器、FTP默认请求、查看结果树、汇总报告、聚合报告、后端监听器、汇总图、断言结果、生成概要
文章目录
- 引言
- Jmeter 核心组件
- Jmeter 程序设计通用规范
- 测试计划
- 一、线程(用户)
- 二、配置元件
- 2.1、CSV 数据文件设置(CSV Data Set Config)
- 2.2、HTTP信息头管理器
- 2.3、HTTP Cookie管理器(HTTP Cookie Manager)
- 2.4、HTTP缓存管理器
- 2.5、HTTP请求默认值
- 2.6、计数器(Counter)
- 2.7、随机变量(Random Variable)
- 2.8、用户定义的变量(User Defined Variables)
- 2.9、Java默认请求(Java Request Defaults)
- 2.10、HTTP授权管理器(HTTP Authorization Manager)
- 2.11、DNS缓存管理器(DNS Cache Manager)
- 2.12、FTP默认请求(FTP Request Defaults)
- 2.13、JDBC Connection Configuration
- 2.14、总结
- 三、监听器
- 3.1、查看结果树(View Results Tree)
- 3.2、汇总报告(Summary Report)
- 3.3、聚合报告(Aggregate Report)
- 3.4、后端监听器(Backend Listener)
- 3.5、汇总图(Aggregate Graph)
- 3.6、断言结果(Assertion Results)
- 3.7、生成概要结果(Generate Summary Results)
- 3.8、图形结果(Graph Results)
- 3.9、响应时间图(Response Time Graph)
- 3.10、保存响应到文件(Save Responses to a file)
- 3.11、简单数据写入器(Simple Data Writer)
- 3.12、用表格查看结果(View Results in Table)
- 3.13、比较断言可视化器(Comparison Assertion Visualizer)
- 3.14、邮件观察仪(Mailer Visualizer)
- 3.15、总结
- 四、定时器
- 五、前置处理器
- 六、后置处理器
- 6.1、正则表达式提取器(Regular Expression Extractor)
- 6.2、JSON提取器(JSON Extractor)
- 6.3、边界提取器(Boundary Extractor)
- 6.4、JSON JMESPath Extractor
- 6.5、CSS/JQuery提取器(CSS Selector Extractor)
- 6.6、XPath提取器(XPath Extractor)
- 6.7、XPath2 提取器(XPath2 Extractor)
- 6.8、结果状态处理器(Result Status Action Handler)
- 6.9、调试后置处理程序(Debug PostProcessor)
- 6.10、后置处理器小结
- 七、断言
- 7.1、响应断言(Response Assertion)
- 7.2、JSON断言(JSON Assertion)
- 7.3、大小断言(Size Assertion)
- 7.4、XPath2 断言(XPath2 Assertion)
- 7.5、断言持续时间(Duration Assertion)
- 7.6、HTML断言(HTML Assertion)
- 7.7、JSON JMESPath 断言(JSON JMESPath Assertion)
- 7.8、MD5Hex断言(MD5Hex Assertion)
- 7.9 XML断言(XML Assertion)
- 7.10 Xpath断言(XPath Assertion)
- 7.11 总结
- 八、取样器
- 九、逻辑控制器
- 9.1、IF 控制器(If Controller)
- 9.2、事务控制器(Transaction Controller)
- 9.3、循环控制器(Loop Controller)
- 9.4、While 控制器(While Controller)
- 9.5、临界部分控制器(Critical Section Controller)
- 9.6、ForEach控制器(ForEach Controller)
- 9.7、包含控制器(Include Controller)
- 9.8、交替控制器(Interleave Controller)
- 9.9、仅一次控制器(Once Only Controller)
- 9.10、随机控制器(Random Controller)
- 9.11、随机顺序控制器(Random Order Controller)
- 9.12、录制控制器(Recording Controller)
- 9.13、简单控制器(Simple Controller)
- 9.14、运行时间控制器(Runtime Controller)
- 9.15、吞吐量控制器(Throughput Controller)
- 9.16、模块控制器(Module Controller)
- 9.17、开关控制器(Switch Controller)
- 十、非测试元件
- 总结
引言
Apache JMeter 是 Apache 组织基于 Java 开发的压力测试工具,用于对软件做压力测试
JMeter官方文档:http://jmeter.apache.org/index.html
如果是小白同学,建议先查看 【P1】Jmeter 准备工作,里面包含了 Jmeter 下载、环境变量配置、设置语言、设置日志级别等等,可以更方便后续学习 Jmeter 准备工作
几个开源的网址:
TP商城: http://www.testingedu.com.cn:8000/
嘟市商城: http://124.223.31.21:8080/index.htm
WebXml: http://www.webxml.com.cn/zh_cn/index.aspx
慕慕生鲜: http://111.231.103.117/#/login
Jmeter 核心组件
取样器: 向服务器发送请求的最小单元
逻辑控制器: 结合取样器实现一些复杂的逻辑
前置处理器: 在请求之前的工作,主要包括参数的设定和传递
后置处理器: 在请求之后的工作,比如判断、参数关联、逻辑处理等,为业务逻辑中的重要环节
定制器: 负责在请求质检的延迟间隔。固定、高斯、随机
配置元件: 配置信息,用于设置一些默认值以供后续范围内的组件使用
断言: 提供成功与否的判断机制,通常用于检查取样器的结果是否正确
监听器: 提供结果检查机制,用于查看、检查、汇总、分析取样结果
执行顺序: 测试计划>>>线程组>>>配置元件>>>前置处理器>>>定时器>>>取样器>>>后置处理器>>>断言>>>监听器
作用域: 辅助组件(除测试计划、线程组、取样器之外的组件)作用于父组件、同级组件,以及同级组件下的所有子组件
Jmeter 程序设计通用规范
(1)、Jmeter 程序遵循易用易懂原则
-
比如配置元件、监听器尽可能往外放
-
尽量少用控制器,尽量减少层次结构
-
在代码逻辑较多时,尽量采用测试片段进行代码公用(方便维护修改)
-
采用简单控制器进行有效的逻辑化
(2)、注意 Jmeter 本身性能,部分性能不佳的组件在运行测试时尽可能屏蔽、少用
-
比如脚本语言中的 BeanShell,尽量用 Groovy 替代
-
比如 Css/Jquery 提取器的高效书写,避开低效的监听器等
-
运行时去掉一些调试组件、打印信息、日志信息等(影响性能测试结果)
(3)、文件路径建议统一采用相关路径,避开迁移的代码修改
(4)、合理设置断言器,保持业务压测的准确性
(5)、容易修改的常量,多处使用的常量,记得进行变量进行参数化
测试计划
测试计划是用来描述一个性能测试的顺序与动作,它包含了若干测试组件以及若干个线程组

-
独立运行每个线程组(例如在一个组运行结束后启动下一个):存在多个线程组时,勾选则串行执行。默认不勾选,并发执行
-
函数测试模式:如果选择,它将使 JMeter 记录每个样本从服务器返回的数据。如果在测试侦听器中选择了文件,则此数据将被写入文件。如果要进行少量运行以确保正确配置 JMeter 并确保服务器返回预期结果,这将很有用。结果是文件将快速增长,JMeter 的性能将受到影响。如果要进行压力测试,则应禁用此选项(默认情况下处于禁用状态)
脚本示例:【P2】Jmeter 线程组的并行与串行
一、线程(用户)
1.1、线程组
线程组元件可以理解为一个测试计划的开始(Jmeter 其它的元件都要放在线程组下)
右击测试计划 >>> 添加 >>> 线程(用户) >>> 线程组

在取样器错误后要执行的动作
-
继续:继续执行接下来的操作
-
启动下一进程循环: 开始下一次循环
-
停止线程:退出该线程,不在执行此线程的操作
-
停止测试:等待当前执行的取样器结束后,结束整个测试
-
立即停止测试:立刻停止测试
线程属性
-
线程数:相当于模拟的用户数量,一个用户占一个线程,模拟200个用户就是200个线程
-
Ramp-Up Period (in seconds):线程加速时间,设置多长时间内启动全部线程。例如线程数为100,时间设定为10s,那么就是10s加载 100个线程,每秒启动的线程数=100/10=10
-
循环次数: 如果填具体的数值,就是循环对应的次数,例如线程数为200,循环次数为10,则每个线程发10次请求;如果选择“永远”,则一直执行下去,直到手动停止
-
Same user on each iteration:相同用户迭代,一般用在有 Cookie 的场景时生效
-
Delay Thread creation until needed:延迟创建线程直到需要,默认不勾选,测试开始时,所有的线程就被创建完。勾选此项,延迟线程创建,直到需要才创建
注:进行参数化时,需配置对应的线程数量
调度器配置
-
持续时间(秒): 脚本持续运行的时间,如果同时设置有循环次数(循环次数 * 线程加速时间),则谁先到达则谁先生效
-
启动延迟(秒):脚本延迟启动的时间
1.2、setUP 线程组
setUP 线程组在测试任务普通线程组运行前先被运行。通常用在运行测试任务前,做初始化工作。例如建立数据库连接初始分化工作、用户登录
右击测试计划 >>> 添加 >>> 线程(用户) >>> setUP 线程组

参数说明参考:1.1 线程组
1.3、tearDown 线程组
tearDown 线程组在测试任务线程组运行结束后被运行。通常用来做清理测试脏数据、登出、关闭资源等工作。例如关闭数据库连接
右击测试计划 >>> 添加 >>> 线程(用户) >>> tearDown 线程组

参数说明参考:1.1 线程组
二、配置元件
配置元件主要用于设置一些默认值以供后续范围内的组件使用
执行顺序:
(1)、配置元件优先执行
(2)、按深度优先算法,依次寻找取样器,找到取样器后,逐个执行,遵循第3条规则
(3)、组件执行顺序:前置处理器 -> 定时器 -> 取样器 -> 后置处理器 -> 断言器 -> 监听器
(4)、执行多个同类型配置元件组件时,在范围内按照广度优先策略依次执行(先外后内,反向执行)
(5)、配置元件无子元素
(6)、配置元件的执行是相互独立的,谁先执行谁后执行,一般意义不大

2.1、CSV 数据文件设置(CSV Data Set Config)
CSV 数据文件变量是指从外部 csv 文件读取数据出来作为变量
选择请求 >>> 添加 >>> 配置元件 >>> CSV Data Set Config

设置 CSV 数据文件(Configure the CSV Data Source)
(1)、文件名(Filename):csv 文件路径,可以是绝对路径或者相对路径
建议设置成相对路径,填写相对于脚本的路径,后续远程压测或迁移时,可以更好的找个文件
(2)、文件编码(File encoding):编码格式,与所选文件编码格式保持一致
(3)、变量名称(西文逗号间隔)(Variable Names (comma-delimited)):如果文件中只有一个变量,直接写变量名,如果有多个变量,用英语的逗号隔开。例:var1,var2
(4)、忽略首行(只在设置了变量名称后才生效)(Ignore first line (only used if Variable Names is not empty)):
-
True:设置为 True 时,从文件第二行开始读取,此时文件第一行为变量名,例:var1,var2;设置为 True,变量名称可以不用设置,在文件第一行设置即可
-
False:一般设置为 False,文件从第一行开始设置变量数据,在变量名称中设置名称
(5)、分隔符(用 ‘\t’ 代替制表符)( Delimiter (use ‘\t’ for tab)):根据文件中的分隔符进行填写,默认:,
(6)、是否允许带引号?(Allow quoted data?):
-
True:参数文件包含引号时,实际的数据为引号中的数据。比如参数文件中的数据为"1,2",当使用该参数时,实际取得值为1,2
-
False:参数文件包含引号时,实际取得值为全部的值。比如参数文件中的数据为"1,2",当使用该参数时,实际取得值为"1,2"会取成两个参数
(7)、遇到文件结束符再次循环?(Recycle on EOF?):
-
True:参数文件中的数据循环使用,测试按照线程组中的设置执行。比如csv 文件共有 10 条记录,但线程数有 15 个,循环 10 次后,重头开始循环取值
-
False:参数文件不再循环遍历取值
(8)、遇到文件结束符停止线程(Stop thread on EOF?):
-
True:当执行完参数文件中所有参数后,直接停止线程
-
False:不停止
(9)、线程共享模式(Sharing mode):
-
所有线程(All threads):参数文件对所有线程共享,这包括同一测试计划中的不同线程组(测试计划下的所有线程组下的所有线程共享参数文件,所有线程之前参数取值互相影响,线程在同一次迭代下取值相同)
-
当前线程组(Current thread group): 只对当前线程组中的线程共享(当前线程组下的所有线程公用一个参数文件,同一个线程组下的线程之前取值相互影响,线程在同一次迭代下取值相同)
-
当前线程(Current thread): 仅当前线程获取(即每个线程获取一个参数文件,各个线程之间参数取值互不影响,线程在同一次迭代下取值相同)
当参数文件的位置与线程组在同级下,线程组下存在循环控制器时,循环控制器下的参数取值相同
线程组下存在循环控制器时,当参数文件在循环控制器下,循环控制器下每次迭代时重新取值
线程组下存在仅一次控制器,参数文件在仅一次控制器下,当参数在仅一次控制器下取值一次之后,之后无论哪次迭代参数取值都不变,类似于unique once
注:创建 CSV 文件最好用 notepad 创建,编码格式为 UTF-8
脚本示例:【P5】JMeter CSV Data Set Config(CSV 数据文件设置)
2.2、HTTP信息头管理器
设置 Jmeter 发送的 HTTP请求头所包含的信息;可抓包或通过浏览器开发模式查看
右键 >>> 添加 >>> 配置元件 >>> HTTP信息头管理器

- 信息头,也就是请求头,会跟随 HTTP 请求一起发送到服务器。比如需要传输 User-Agent 、cookie、token 或其他某些信息,或是需要伪造请求头的时候
脚本示例:【P3】HTTP 接口设计
2.3、HTTP Cookie管理器(HTTP Cookie Manager)
如果你有一个 HTTP 请求,其返回结果里包含一个 cookie,那么 Cookie 管理器会自动将该 cookie 保存起来,而且以后所有的对该网站的请求都使用同一个 cookie
右键 >>> 添加 >>> 配置元件 >>> HTTP Cookie管理器

选项(Options)
(1)、每次反复清除Cookies?(Clear cookies each iteration?):每次迭代时,都将 Cookies 清空
(2)、Use Thread Group configuration to control cookie clearing:用户线程组去配置清空 Cookie
(3)、Cookie 格式
-
standard:标准格式
-
standard-strict:严格格式
-
ignoreCookies:此规格忽略所有 Cookie。被用来防止 HttpClient 接受和发送的 Cookie
-
netscape:是最原始的 Cookies 规范,同时也是 RFC2109 的基础。尽管如此,还是在很多重要的方面与 RFC2109 不同,可能需要特定服务器才可以兼容
-
default:默认
-
rfc2109:是 HttpClient 使用的默认 Cookies 协议
-
rfc2965:定义了版本2并且尝试去弥补在版本1中 Cookie 的 rfc2109 标准的缺点。规定 rfc2965 最终取代 rfc2109 发送 rfc2965 标准 Cookies 的服务端,将会使用 Set-Cookie2 header 添加到 Set-Cookie Header 信心中,rfc2965 Cookies 是区分端口的
-
compatibility:推荐选择此种策略。这种兼容性设计要求是适应尽可能多的不同的服务器,尽管不是完全按照标准来实现的。如果你遇到了解析 Cookies 的问题,你就可能要用到这一个规范。有太多的 web 站点是用 CGI 脚本去实现的,而导致只有将所有的 Cookies 都放入 Request header 才可以正常的工作。这种情况下最好设置 http.protocol.single-cookie-header 参数为 true
存储在Cookie管理器中的Cookie(User-Defined Cookies)
- 自定义 Cookie,可以手动添加
脚本示例:【P6】JMeter HTTP Cookie管理器
2.4、HTTP缓存管理器
模拟浏览器缓存功能,静态缓存(图片等)。动态缓存(json,xml)等不在范围内。
注意:开启缓存时,我们要注意 JVM 内存大小,防止内存溢出,高并发时启步 4G
HTTP缓存管理器使用较少,大部分性能压测都是针对于动态资源 json,xml等请求,很少压测图片等静态资源
右键 >>> 添加 >>> 配置元件 >>> HTTP 缓存管理器

-
在每次迭代中清除缓存?: 如果选中此项,则在线程每次迭代时清除缓存。去Server请求资源
-
Use Thread Group configuration to control cache clearing:如果选择该项,使用线程组配置去控制缓存清空;线程组勾选 Same user on each iteration 相同用户迭代,则缓存不会清空,不勾选则会清空
-
Use Cache-Control/Expires header when processing GET request :规则与浏览器类似,检测修改时间和 Etag 变化,判断是否对静态资源进行缓存;如果勾选,则会对照当前时间检查“Cache-Control/Expires”值。如果请求是GET请求,并且时间戳记在缓存之后,则取样器将立即返回,而无需从远程服务器请求URL。这旨在模拟浏览器的行为。如果Cache-Control标头为“ no-cache ”,则响应将在过期时存储在缓存中,再次进行GET请求时将重新请求远程服务器;如果时间戳是将来的,并且请求是Get,那么Sampler会立即返回,而不需要从Server请求URL
-
缓存中元素最大数量: Jmeter保存所有缓存资源在RAM。默认情况下,缓存管理器在每个虚拟用户的缓存中最多存储5000个条目。如果增加这个值,Jmeter将相应地消耗更多的内存。它会导致“OutOfMemory”异常。为了避免这种行为,你应该在jmeter.bat\sh中调整JVM-Xmx选项
缓存执行规则:
-
无配置元件时(HTTP缓存管理器),不会缓存(与线程组设置无关)
-
有配置元件(HTTP缓存管理器),选上清空策略时,优先取配置元件(每一次迭代会清空缓存,与线程组设置(Same user on each iteration)无关)
-
有配置元件(HTTP缓存管理器),选择参考线程组时,看线程组设置(是否勾选 Same user on each iteration ;勾选则保留缓存;不勾选则不保存缓存信息)(分2种情况)
-
最后一种规则与浏览器类似,检测修改时间和 Etag 变化
2.5、HTTP请求默认值
管理公用的 HTTP 请求配置数据
右键 >>> 添加 >>> 配置元件 >>> HTTP 请求默认值

配置线程组下所有【HTTP请求】的请求行和请求体的默认值,与【HTTP请求】放在同级目录。配置后,每个【HTTP请求】无需重复配置,特殊的请求也可以单独配置,单独配置的优先级更高
参数说明参考:8.1 HTTP请求
脚本示例:【P3】HTTP 接口设计
2.6、计数器(Counter)
在迭代过程中增加计数器,一般用于统计和模拟序列等
右键 >>> 添加 >>> 配置元件 >>> 计算器

-
开始值(Starting value):给定计数器的起始值、初始值,第一次迭代时,会把该值赋给计数器
-
递增(Increment):每次迭代后,给计数器增加的值
-
最大值(Maximum value):达到最大值时,自动重置初始值;默认的最大值为2^63-1 Long.MAX_VALUE
-
数字格式(Number format):可选格式,比如000,格式化为001,002…三位,不足补0;默认格式为Long.toString(),但是默认格式下,还是可以当作数字使用
-
引用名称(Exported Variable Name):用于控制在其它元素中引用该值,比如:变量名称为 reference_name,形式:${reference_name}
-
与每用户独立的跟踪计数器(Track Counter Independently for each User):全局的计数器,如果不勾选,即全局的,比如用户#1 获取值为1,用户#2获取值还是为1;
如果勾选,即独立的,则每个用户有自己的值:比如用户#1 获取值为1,用户#2获取值为2。 -
在每个线程组迭代上重置计算器(Reset counter on each Thread Group Iteration):可选,仅勾选与每用户独立的跟踪计数器时可用
脚本示例:【P7】JMeter 计数器
2.7、随机变量(Random Variable)
模拟一些随机数字变量,模拟数据
右键 >>> 添加 >>> 配置元件 >>> 随机变量(Random Variable)

输出变量(Output variable)
-
变量名称(Variable Name):用于控制在其它元素中引用该值。例如:variable_name,形式:$(variable_name},必填
-
输出格式(Output Format):要使用的java.text.DecimalFormat格式字符串。例如,“000”将生成至少3位数的数字,或“USER_000”将生成USER_nnn形式的输出。如果未指定,则默认使用Long.toString()生成数字。非必填
配置随机发生器(Configure the Random generator)
-
最小值(Minimum Value):最小值设置。必填
-
最大值(Maximum Value):最大值设置。必填
-
随机种子(Seed for Random function):随机数生成器的种子。如果将每线程设置为true使用相同的种子值,则每个线程将获得与每个Random类相同的值。如果未设置种子,则将使用Random的默认构造函数。非必填
选项(Options)
- 每线程(用户)?(Per Thread(User)?):如果为False,则生成器在线程组中的所有线程之间共享。如果为True,则每个线程都有自己的随机生成器。必填
脚本示例:【P8】JMeter 随机变量(Random Variable)
2.8、用户定义的变量(User Defined Variables)
可以新增一些用户自定义变量,通常为简单字符串类
右键 >>> 添加 >>> 配置元件 >>> 用户定义的变量

引用变量的格式为:${变量名}
优先级:
-
线程组下的用户自定义变量 优先级高于 测试计划里的用户定义的变量
-
HTTP 请求下的用户自定义变量 优先级高于 线程组下的用户定义的变量
注意点:
-
定义的所有参数的值在测试计划的执行过程中不能发生取值的改变。即使变量的值是随机数(Random),不同用户数循环多次,拿到的用户自定义变量值都是一样的
-
一般仅将测试计划中不需要随迭代发生改变的参数(只取一次值的参数)设置在此处
脚本示例:【P9】JMeter 用户定义的变量(User Defined Variables)
2.9、Java默认请求(Java Request Defaults)
可以开发一些个 java 自定义组件;该元件结合 Java取样器,可以实现其它一些 Jmeter 原生支持不了的协议,如 redis,kafka 等
右键 >>> 添加 >>> 配置元件 >>> Java默认请求(Java Request Defaults)

2.10、HTTP授权管理器(HTTP Authorization Manager)
使用不同的认证方式来登陆网页;一般这种业务场景比较少,现在互联网都是通过自有的登陆来实现,并结合 HTTPS加密
右键 >>> 添加 >>> 配置元件 >>> HTTP授权管理器(HTTP Authorization Manager)

选项(Options)
-
在每次迭代中清除认证?(Clear auth on each iteration?):勾选后每次请求都会清理掉之前的认证,需要重新认证
-
使用线程组配置控制清除(Use Thread Group configuration to control clearing):线程组是否勾选 Same user on each iteration
存储在授权管理器中的授权(Authorizations Stored in the Authorization Manager)
(1)、基础URL(Base URL):需要使用认证页面的URL
(2)、用户名(Username):用于认证和登录的用户名
(3)、密码(Password):用于认证和登录的密码
(4)、域(Domain):身份认证页面的域名
(5)、Realm:Realm字串,一般不填
(6)、Mechanism:jmeter的http授权管理器提供的认证机制:
-
BASIC_DIGEST:HTTP协议并没有定义相关的安全认证方面的标准,而BASIC_DIGEST是一套基于http服务端的认证机制,保护相关资源避免被非法用户访问,如果你要访问被保护的资源,则必需要提供合法的用户名和密码。它和HTTPS没有任何关系(前者为用户认证机制,后者为信息通道加密)
-
KERBEROS:一个基于共享秘钥对称加密的安全网络认证系统,其避免了密码在网上传输,将密码作为对称加密的秘钥,通过能否解密来验证用户身份
2.11、DNS缓存管理器(DNS Cache Manager)
可以增加域名和IP的解析关系
右键 >>> 添加 >>> 配置元件 >>> DNS缓存管理器(DNS Cache Manager)

选项
-
在每次迭代中清除缓存(Clear cache each iteration):如果选择此选项,则每次启动新迭代时,都会清除每个线程的DNS缓存
-
使用系统DNS解析器(Use system DNS resolver):将使用系统DNS解析器。为了正确工作,请编辑 $ JAVA_HOME / jre / lib / security / java.security并添加networkaddress.cache.ttl = 0
-
使用自定义DNS解析器(Use custom DNS resolver):将使用自定义DNS解析器(来自dnsjava库)
DNS服务器(DNS Servers)
- 勾选 Use custom DNS resolver:添加配置主机名或IP地址
静态主机表(Static Host Table)
- 勾选 Use custom DNS resolver:添加静态主机
2.12、FTP默认请求(FTP Request Defaults)
可以增加域名和IP的解析关系
右键 >>> 添加 >>> 配置元件 >>> FTP默认请求(FTP Request Defaults)

-
服务器名称或IP(Server Name or IP):上传或者用来下载的服务器地址(即被测对象)
-
端口号(Port Number):指定的FTP传输端口号
-
远程文件(Remote File):远程FTP服务器文件路径
-
本地文件(Local File):本地文件路径
-
本地文件内容(Local File Contents):本地文件内容
-
get(RETR):下载文件选项
-
put(STOR):上传文件选项
-
使用二进制模式?(Use Binary mode ?):是否以二进制方式传输(默认ASCII)
-
保存文件响应?(Save File in Response ?):文件内容是否保存到响应中,如果选择了,且运行FTP请求成功后,我们可以再“查看结果树----响应数据”中看到内容
2.13、JDBC Connection Configuration
可以给数据源配置不同的连接池,供后续 JDBC 采样器使用;使用前请将对应的数据库驱动复制到 $JMETER_HOME/lib/ 或者 $JMETER_HOME/liblext/ 下;Jmeter 默认采用 DBCP 连接池
使用场景:该元件配置通常与 JDBC 取样器一同使用
右键 >>> 添加 >>> 配置元件 >>> JDBC Connection Configuration

Variable Name Bound to Pool
- Variable Name for created pool:数据库连接池的名称,可以设置多个 jdbc connection configuration,命名不同,在 jdbc request 请求中可以通过这个名称选择对应的连接池进行使用
Connection Pool Configuration:连接池参数配置,基本保持默认就行了,可根据需要进行修改
-
Max Number of Connections:最大连接数;做性能测试时,建议填 0 ;如果填了10,则最大连接10个线程
-
Max Wait (ms):在连接池中取回连接最大等待时间,单位毫秒;连接时超过最大等待时间,则连接失败
-
Time Between Eviction Runs (ms):线程可空闲时间,单位毫秒;如果当前连接池中某个连接在空闲了 Time Between Eviction Runs Millis 时间后任然没有使用,则被物理性的关闭掉
-
Auto Commit:自动提交 sql 语句,如:修改数据库时,自动 commit
-
Transaction Isolation:事务隔离级别(一般默认即可)
-
Pool Prepared Statements:
-
Preinit Pool:立即初始化连接池;如果为 False,则第一个 JDBC 请求的响应时间会较长,因为包含了连接池建立的时间
-
:数据库初始化参数,连接执行时执行,只执行一次
Connection Validation by Pool:验证连接池是否可响应
-
Test While Idle:当连接空闲时是否断开
-
Soft Min Evictable Idle Time(ms):连接在池中处于空闲状态的最短时间
-
Validation Query:一个简单的查询,用于确定数据库是否仍在响应;默认为 jdbc 驱动程序的 isValid() 方法,适用于许多数据库(Test While Idle 需配置为 True)
Database Connection Configuration:数据库连接配置
-
Database URL:数据库连接 URL(格式:jdbc:mysql://IP:端口号/数据库名称);如 consult-service 服务连接池:jdbc:mysql://{ip}:{port}/{dbname}
?allowMultiQueries=true&characterEncoding=utf8。添加 ?allowMultiQueries=true,是为了能够一次执行多条语句 -
JDBC Driver class:数据库驱动(选择对应的数据库驱动)
| 数据库 | 驱动 | URL |
|---|---|---|
| MySQL | com.mysql.jdbc.Driver | jdbc:mysql://host:port/{dbname} |
| PostgreSQL | org.postgresql.Driver | jdbc:postgresql:{dbname} |
| Oracle | oracle.jdbc.driver.OracleDriver | jdbc:oracle:thin:user/pass@//host:port/service |
| sqlServer | com.microsoft.sqlserver.jdbc.SQLServerDriver | jdbc:sqlserver://host:port;databaseName=databaseName |
2.14、总结
2.13.1、Jmeter 变量作用域和规则
(1)、前一个组件定义的变量,在后续所有组件的执行过程中有效
- 例如在取样器 JSR223 Sampler中定义一个变量:vars.put(“var”,“我是变量”),在后续组件中都可以引用
(2)、变量分为线程变量、线程组变量、全局共享变量
-
线程变量的修改一般只对本线程有效,只会影响本线程的下一次迭代,不会跨线程
-
例如修改A线程,只影响A线程的之后迭代(设置线程循环),但不会影响B线程
-
线程组变量的修改会对整个线程组生效,在线程组内跨线程(比如像 csv配置元件中的线程组共享)
-
全局的变量的修改会对所有线程组生效(比如像 csv配置元件中的全局共享,全局 Counter 计数器等)
(3)、变量的定义尽量往外层放置,最好不要放置在业务逻辑中,理解起来比较反常(动态变量(设置一些后置处理器)除外)
2.13.2、配置元件使用小结
| 配置元件 | 使用频率 | 使用场景 |
|---|---|---|
| CSV 配置元件 | 非常高 | 针对某一个变量能够加载大量数据,多用于复杂业务条件的构造 |
| HTTP 请求默认值 | 非常高 | 用于 http 取样器 |
| HTTP 头部管理器 | 非常高 | 用于 http 取样器 |
| HTTP Cookie管理 | 高 | 用于 http 取样器 |
| HTTP 缓存管理 | 一般 | 用于 http 取样器 |
| Counter 计数器 | 高 | 计数统计,序列等场景 |
| Random 随机变量 | 一般 | 构建业务条件 |
| 自定义变量 | 非常高 | 处理少量数据,将脚本进行参数化 |
三、监听器
监听器主要为 Jmeter 持续大量的取样结果提供分析机制,比如查看、统计、汇总、分析取样结果,进而用来分析性能结果
执行顺序:
(1)、配置元件优先执行(非控制器内),用户自定义配置元件优先执行(无论是否在控制器内)
(2)、按深度优先算法,依次寻找取样器,找到取样器后,逐个执行,遵循第3条规则
(3)、执行总体顺序:控制器(父类)-> 配置元件(控制器内)-> 前置处理器 -> 定时器 -> 取样器 -> 后置处理器 -> 断言器 -> 监听器
(4)、监听器不可以添加子元素
(5)、同一个取样器有多个监听组件时,在范围内按照广度优先策略依次执行

3.1、查看结果树(View Results Tree)
可以查看取样器的请求参数、返回结果
使用场景:一般在调试测试计划期间用来查看取样器结果,负载期间使用会消耗大量资源,慎用
使用频率:极高
查看结果树可以放在线程组下或者某个配置下,右键 >>> 添加>>> 监听器 >>> 查看结果树(View Results Tree)

所有数据写入一个文件(Write results to file / Read from file)
(1)、文件名(Filename):可以通过浏览,选择一个文件,这样jmeter在执行的过程中,会将所有的信息输出到文件,也支持打开一个结果文件进行浏览
(2)、显示日志内容(Log/Display Only):
-
仅日志错误:表示只输入报错的日志信息
-
仅成功日志(Successes):表示只输出正常响应的日志信息
-
不勾选:表示输出所有的信息
(3)、配置(Configuer):配置需要输出的内容(建议默认。后续如果加载进此保存的文件可能会不知道啥格式)
查找(Search)
- 在输入框中输入想查询的信息,点击查找(Search),可以在请求列表中进行查询,并在查询出的数据上加上红色的边框
结束数显示类型切换: 通过结果树上面的下来看可以进行切换,包含多种显示方式,默认Text
取样器结果: 取样器的详细结果,可以切换取样器的显示方式Raw/Parsed
请求: 显示当前取样器发送的详细请求内容,支持查找
响应数据: 显示请求得到的响应内容,支持查找
Scroll automaticlly?: 当执行的取样器较多,设置是否滚屏显示
脚本示例:【P49】JMeter 查看结果树(View Results Tree)
3.2、汇总报告(Summary Report)
可以查看事务或者取样器在某个时间范围内执行的汇总结果
使用场景:用于评估测试结果
使用频率:极高
汇总报告可以放在线程组下或者某个配置下,右键 >>> 添加>>> 监听器 >>> 汇总报告(Summary Report)

所有数据写入一个文件(Write results to file / Read from file)参数参考 3.1
参数
-
样本(Samples):取样器请求的数量
-
平均值(Average):请求(事务)的平均响应时间
-
最小值(Min):请求的最小响应时间
-
最大值(Max):请求的最大响应时间
-
标准偏差(Std.Dev): 响应时间的标准方差
-
异常 %(Error):请求(事务)错误的数量
-
吞吐量(Throughput):每秒取样器执行的数量,相当于 TPS
-
接收 KB/sec(Received KB/sec):每秒接收的千字节数
-
发送 KB/sec(Sent KB/sec):每秒发送的千字节数
-
平均字节数(Avg.Bytes):取样结果返回的平均大小
脚本示例:【P50】JMeter 汇总报告(Summary Report)
3.3、聚合报告(Aggregate Report)
可以查看事务或者取样器在某个时间范围内执行的汇总结果
使用场景:用于评估测试结果
使用频率:极高
右键 >>> 添加 >>> 监听器 >>> 聚合报告(Aggregate Report)

所有数据写入一个文件(Write results to file / Read from file)参数参考 3.1
参数
-
Label:请求的名称,就是我们在进行测试的HTTP请求取样器的名称
-
样本(Samples):总共发给服务器的请求数量,如果模拟10个用户,每个用户迭代10次,那么总的请求数为:10*10 =100次
-
平均值(Average):平均响应时间,所有请求的平均响应时间,单位是毫秒
-
中位数:50%的用户响应时间不超过这个值
-
90% 百分位:90%的用户响应时间不超过这个值
-
95% 百分位:95%的用户响应时间不超过这个值
-
99% 百分位:99%的用户响应时间不超过这个值
-
最小值:请求的最小响应时间
-
最大值(Max):请求的最大响应时间
-
异常 %(Error):异常百分比。(错误请求的数量/请求的总数)
-
吞吐量(Throughput):每秒取样器执行的数量,相当于 TPS
-
接收 KB/sec(Received KB/sec):每秒接收的千字节数
-
发送 KB/sec(Sent KB/sec):每秒发送的千字节数
脚本示例:【P51 】JMeter 聚合报告(Aggregate Report)
3.4、后端监听器(Backend Listener)
可以将事务或者取样器在某个时间范围内执行的结果发送给 graphite、infludb
使用场景:用于评估测试结果,一般配合图形界面使用,该方式更直接和可视化
使用频率:极少
右键 >>> 添加 >>> 监听器 >>> 后端监听器(Backend Listener)

(1)、Backend Listener implementation(后端监听器实现):BackendListenerClient类的实现,使用的influxdb作为持久存储
(2)、Async Queue size(异步队列大小):队列值包含异步处理时的度量标准。除非有一些特定的性能问题,否则最好不要从默认的5000
参数(Parameters)
-
summaryOnly:true/false,true只发送summary;false,发送summary和detail
-
percentiles:响应时间百分比
3.5、汇总图(Aggregate Graph)
可以以图形的方式查看事务或者取样器的汇总报告
使用场景:用于评估测试结果
使用频率:较少
右键 >>> 添加 >>> 监听器 >>> 汇总图(Aggregate Graph)

3.6、断言结果(Assertion Results)
可以查看断言的成功和失败数
使用场景:一般在调试测试计划期间用来查看断言的成功和失败数,负载期间使用会消耗大量资源,慎用
使用频率:一般
右键 >>> 添加 >>> 监听器 >>> 断言结果(Assertion Results)

所有数据写入一个文件(Write results to file / Read from file)参数参考 3.1
断言成功的话只显示HTTP请求的name;断言失败才会显示详细的失败信息
3.7、生成概要结果(Generate Summary Results)
可以将测试结果在客户端模式下输出,同时能美化压测输出的结果
使用场景:采用汇总报告方式,将测试结果在客户端模式下的输出结果
使用频率:一般
右键 >>> 添加 >>> 监听器 >>> 生成概要结果(Generate Summary Results)

3.8、图形结果(Graph Results)
可以以图形的方式查看和分析相关指标
使用场景:一般在调试测试计划期间用来查看相关指标,负载期间使用会消耗大量资源,慎用
使用频率:少
右键 >>> 添加 >>> 监听器 >>> 图形结果(Graph Results)

所有数据写入一个文件(Write results to file / Read from file)参数参考 3.1
3.9、响应时间图(Response Time Graph)
可以以图形的方式查看和分析各事务和取样器的响应时间
使用场景:用于评估测试结果
使用频率:高
右键 >>> 添加 >>> 监听器 >>> 响应时间图(Response Time Graph)

所有数据写入一个文件(Write results to file / Read from file)参数参考 3.1
设置(Settings)
(1)、显示图表(Display Graph)
(2)、保存图表(Save Graph):可以很方便的保存图表
设置(Settings)_图设置(Graph settings)
-
时间间隔(ms)(Interval (ms)):时间间隔,默认单位毫秒。样本根据此值进行分组。在显示图表之前,单击 Apply interval(应用区间)按钮以刷新内部数据;多长时间刷新一次
-
取样器标签选择(Sampler label selection):取样器标签选择,勾选之后,可以选择区分大小写,正则表达式。在显示图表之前,单击 Apply filter(应用过滤器)按钮以刷新内部数据
-
应用区间(Apply interval)
-
区分大小写(Case sensitive)
-
正则表达式(Regular exp.)
设置(Settings)_标题(Title):在图表的头部定义图表的标题
-
图标题(Graph title ):图形标题
-
同步名称(Synchronize with name)
-
字体(Font):字体。默认Sans Serif(无衬线字体),可选Serif(衬线体)
-
尺寸(Size):大小
-
样式(Style):样式。默认Bold(粗体),可选Normal(普通),ltalic(斜体)
设置(Settings)_线设置(Line settings):定义线条的宽度
-
描边宽度(Stroke width)
-
形状(Shape point)
设置(Settings)_图表大小(Graph size)
-
动态图大小(Dynamic graph size) :动态图表大小,默认勾选,根据当前JMeter窗口大小的宽度和高度计算图形大小。取消勾选之后,可以自定义大小。单位是像素
-
宽(Width):取消勾选动态图大小(Dynamic graph size),自定义宽度,单位像素
-
高度(Height):取消勾选动态图大小(Dynamic graph size),自定义高度,单位像素
设置(Settings)_X轴(X Ais):自定义X轴标签的日期格式
- 时间格式(SimpleDateFormat)(Time format(SimpleDateFormat)):时间格式。默认格式HH:mm:ss
设置(Settings)_Y轴(毫秒)(Y Axis(milli-seconds)):为Y轴定义自定义最大值(以毫秒为单位)
-
最大值(Scale maximum value):注:如图图形出不来,设置下这个最大值,比如 100 ms
-
增量比例(Increment scale)
-
显示号码分组?(Show number grouping?)
设置(Settings)_图例(Legend):定义图表图例的放置和字体设置
-
放置(Placement):放置,默认Bottom(底部),可以选Right(右),Left(左),Top(上)
-
字体(Font):字体。默认Sans Serif(无衬线字体),可选Serif(衬线体)
-
尺寸(Size):大小
-
样式(Style):样式。默认Normal(普通),可选Bold(粗体),ltalic(斜体)
3.10、保存响应到文件(Save Responses to a file)
可以将结果树保存到文件
使用场景:当结果太大,使用结果树监听器影响图形模式时,我们可以采用响应保存监听器来处理
使用频率:一般
右键 >>> 添加 >>> 监听器 >>> 保存响应到文件(Save Responses to a file)

Save conditions
-
Save Successful Responses only:仅保存成功响应
-
Save Failed Responses only:仅保存失败响应
-
Don’t save Transaction Controller SampleResult:不保存事务控制器样本结果
Save details
-
文件名称前缀(Filename prefix (can include folders)):文件路径 + 文件前缀
-
Don’t add number to prefix:不添加数字到文件前缀
-
Don’t add content type suffix:不添加文件的后缀类型
-
Add timestamp:添加时间戳到文件前缀
-
Minimum Length of sequence number:设置文件名称最小的序列号;例如4,文件序号为0001…
3.11、简单数据写入器(Simple Data Writer)
可以将原始数据直接保存到文件
使用场景:一般与 HTML 报告配合使用
使用频率:一般
右键 >>> 添加 >>> 监听器 >>> 简单数据写入器(Simple Data Writer)

所有数据写入一个文件(Write results to file / Read from file)参数参考 3.1
3.12、用表格查看结果(View Results in Table)
可以将取样器请求以表格的方式分析展示
使用场景:一般在调试测试计划期间用来查看取样器结果,负载期间使用会消耗大量资源,慎用
使用频率:一般
右键 >>> 添加 >>> 监听器 >>> 用表格查看结果(View Results in Table)

所有数据写入一个文件(Write results to file / Read from file)参数参考 3.1
参数
-
Sample #:每个请求的序号
-
Start Time:每个请求开始时间。(时:分:秒.毫秒)
-
Thread Name:每个线程的名称(线程序号-第N次循环次数)
-
Label:每个请求的自定义名称(无修改时默认显示请求类型,如Http,FTP等请求)
-
Sample Time(ms):每个请求的响应时间。(单位:毫秒)
-
Status:请求状态,如果为勾则表示成功,如果为叉表示失败
-
Bytes:响应的字节数,请求的字节数
-
Sent Bytes:发送的字节数
-
Latency:延迟的时间,等待时长。(单位:毫秒)
-
Connect Time(ms):连接服务器的时间。(单位:毫秒)
(1)、样本数目:所有请求个数,样本数目 = 线程数(请求用户数)* 请求次数 。(单位:个)
(2)、最新样本:最新样本响应时间,表示服务器响应最后一个请求的时间。(单位:毫秒)
(3)、平均:所有请求的平均响应时间。(单位:毫秒)
(4)、偏离:服务器响应时间变化、离散程度测量值的大小,或者,换句话说,就是数据的分布
3.13、比较断言可视化器(Comparison Assertion Visualizer)
使用场景:一般和 比较断言 组件配合使用;本身有性能问题,慎用
使用频率:极少
右键 >>> 添加 >>> 监听器 >>> 比较断言可视化器(Comparison Assertion Visualizer)

所有数据写入一个文件(Write results to file / Read from file)参数参考 3.1
3.14、邮件观察仪(Mailer Visualizer)
可以使监听结果通过邮件发送出去
使用场景:发送邮件
使用频率:较少
右键 >>> 添加 >>> 监听器 >>> 邮件观察仪(Mailer Visualizer)

所有数据写入一个文件(Write results to file / Read from file)参数参考 3.1
注:它不会将此文件已附件的形式在邮件中,只是将测试结果写入到了定的此目录文件中,如果你运行完脚本,直接在此路径下打开此文件就可以看到运行结果
Mailer setting_Message
-
From:发件人,添加多个收件人邮箱时,中间用逗号隔开,如:lucky@iberhk.com,bob@iberhk.com
-
Addressee(s):接收人
-
Success Subject:成功发送邮件的标题
-
Success Limit:代表成功次数大于X时发送邮件
-
Failure Subject:失败发送邮件的标题
-
Failure Limit:大代表失败事务大于X时,发送邮件(于给定的数值,不是等于。比如写的1,则失败2次后将发送邮件通知我,当测试结果100%成功时则不会发送邮件)
Mailer setting_SMTP server
-
Host:查看SMTP,从自己邮箱中获取到(填写邮件服务器名称)
-
Port:查看SMTP,从自己邮箱中获取到
-
Login:登录的邮箱,填写自己的邮箱即可
-
Password:16位的授权密码(将smtp服务开启,生成授权码当作密码)
登录自己的邮箱,获取16位的授权码
-
Connection security:选择协议,默认选SSL
-
Test Mail:点击TestMail 测试下是否可以发送成功
Failures:失败数
3.15、总结
3.15.1、主要监听器的场景使用比较
(1)、开发调试:是指我们编写脚本或者脚本还在调试阶段,这一阶段我们对 Jmeter 的性能没有要求
(2)、轻量级压测:我们的脚本已经初步完成,并想通过多线程和多次迭代简单的验证一下脚本
(3)、负载压测:脚本已经完成,准备对业务系统进行长时间压测
(4)、UI 模式下结果输出两大常用组件:结果树监听器 + 总结报告监听器,采用这两种监听器,我们可以处理90%以上的场景
| 结果监听器 | 开发调试/UI模式 | 轻量级压测/UI模式 | 负载压测 |
|---|---|---|---|
| 结果树监听器 | √ | √ | |
| 总结报告监听器 | √ | √ | |
| 汇总报告监听器 | √ | √ | |
| 汇总图形监听器 | √ | √ | |
| 断言结果监听器 | √ | √ | |
| 图表结果监听器 | √ | ||
| 响应时间监听器 | √ | √ | |
| 响应保存监听器 | √ | √ | |
| 简单数据监听器 | √ | √ | |
| 数据表格化监听器 | √ | √ |
3.15.2、监听器输出 Jtl 文件详解
(1)、Jtl 文件为 Jmeter 结果输出格式,同时也是各个监听件之间的统一交换格式协议
(2)、针对有输出的结果监听器,它们的输出遵循统一的 jtl 输出格式
(3)、针对有输入的结果监听器,它们的输入遵循统一的 jtl 输入格式
(4)、Jtl 同时可以输出为 hml 形式报告
(5)、Jtl 文件可以跨主机识别

3.15.3、Jtl 文件的 html 格式输出
四、定时器
定时器主要作用于线程延迟,用来达到业务上更真实的模拟,底层采用 Thread.sleep(毫秒) 来实现
执行顺序:
(1)、配置元件优先执行
(2)、按深度优先算法,依次寻找取样器,找到取样器后,逐个执行,遵循第3条规则
(3)、组件执行顺序:前置处理器 -> 定时器 -> 取样器 -> 后置处理器 -> 断言器 -> 监听器
(4)、同一个取样器有多个定时器组件时,在范围内按照广度优先策略依次执行
(5)、定时器无子元素

4.1、固定定时器(Constant Timer)
可以对每一个线程延迟固定时间;对比 BeanShell 中的 Thread.slepp(n) 功能
右键 >>> 添加 >>> 定时器 >>> 固定定时器(Constant Timer)

- 线程延迟(毫秒)(Thread Delay (in milliseconds)):默认300;1000毫秒大概1秒
脚本示例:【P10】JMeter 固定定时器(Constant Timer)
4.2、统一随机定时器(Uniform Random Timer)
可以对每一个线程随机延迟一定时间;总体延迟时间 = 随机时间 + 常量时间
右键 >>> 添加 >>> 定时器 >>> 统一随机定时器(Uniform Random Timer)

-
Random Delay Maximum (in milliseconds):随机延迟最大值(毫秒)
-
Constant Delay Offset (in milliseconds):常量延迟设置(毫秒)
脚本示例:【P11】JMeter 统一随机定时器(Uniform Random Timer)
4.3、准确的吞吐量定时器(Precise Throughput Timer)
可以让线程以一个目标吞吐量去运行
右键 >>> 添加 >>> 定时器 >>> 准确的吞吐量定时器(Precise Throughput Timer)

延迟线程以确保目标吞吐量(Delay threads to ensure target throughput)
-
目标吞吐量(每个“吞吐期”的样本)(Target throughput (in samples per “throughput period”)):期望测试的TPS,可以精确到多位小数(不过最终报告只会有1位小数)
-
吞吐量周期(秒)(Throughput period (seconds)):在多少秒内执行测试的TPS(因为TPS单位是秒,这里固定使用1秒即可)
-
测试持续时间(秒)(Test duration (seconds)):测试时长,与前面线程组的数值保持一致即可
批处理离开
-批处理中的线程数(线程)(Number of threads in the batch (threads)):是指准备好了多少个线程后一起发起请求(即集合点),取与TPS保持一致的数值(如果TPS是小数,则这里向上取整)
-批处理中的线程之间的延迟(ms)(Delay between threads in the batch (ms)):第一批与第二批处理之间的延迟时间;默认即可
设置以确保可重复的顺序
-随机种子(从0变为随机)(Random seed (change from 0 to random)):非0随机种子可以重复;0不可重复,默认即可
脚本示例:【P12】JMeter 准确的吞吐量定时器(Precise Throughput Timer)
4.4、常数吞吐量定时器(Constant Throughput Timer)
可以让线程以一个目标吞吐量去运行
右键 >>> 添加 >>> 定时器 >>> 常数吞吐量定时器(Constant Throughput Timer)

(1)、目标吞吐量(每分钟的样本量)(Target throughput (in samples per minute)):每分钟的吞吐量
(2)、基于计算吞吐量(Calculate Throughput based on):
-
只有此线程(this thread only):控制每个线程的吞吐量,选择这种模式时,总的吞吐量为设置的target Throughput 乘以该线程的数量
-
所有活动线程(all active threads):设置的target Throughput 将分配在每个活跃线程上,每个活跃线程在上一次运行结束后等待合理的时间后再次运行。活跃线程指同一时刻同时运行的线程
-
当前线程组中的所有活动线程(all active threads in current thread group):设置的target Throughput 将分配在当前线程组的每一个活跃线程上,当测试计划中只有一个线程组时,该选项和all active threads 选项的效果完全相同
-
所有活动线程(共享)(all avtive threads (shared)):与all active threads的选项基本相同。唯一区别是,每个活跃线程都会在所有活跃线程上一次运行结束后等待合理的时间后再次运行
-
当前线程组中的所有活动线程(共享)(all active threads in current thread group (shared)):与all active threads in current thread group 基本相同,唯一的区别是,每个活跃线程都会在所有活跃线程的上一次运行结束后等待合理的时间后再次运行
脚本示例:【P13】JMeter 常数吞吐量定时器(Constant Throughput Timer)
4.5、高斯随机定时器(Gaussian Random Timer)
可以对每一个线程随机延迟和固定延时时间,进而模拟真实场景
使用较少,可以使用 统一随机定时器(Uniform Random Timer)替代;区别:算法不同
右键 >>> 添加 >>> 定时器 >>> 高斯随机定时器(Gaussian Random Timer)

-
偏差(毫秒)(Deviation (in milliseconds)):偏差值,是一个浮动范围
-
固定延迟偏移(毫秒)(Constant Delay Offset (in milliseconds)):固定延迟时间
总的延时 = 高斯分布值(平均0.0和标准差1.0)* 指定的偏差值 + 固定延迟偏移
4.6、泊松随机定时器(Poisson Random Timer)
可以对每一个线程随机延迟和固定延时时间,进而模拟真实场景
使用较少,可以使用 统一随机定时器(Uniform Random Timer)替代;区别:算法不同
右键 >>> 添加 >>> 定时器 >>> 泊松随机定时器(Poisson Random Timer)

-
Lambda (in milliseconds):泊松分布值,大部分时间位于该区间
-
Constant Delay Offset (in milliseconds):固定延迟毫秒数
请求的延迟时间将在【固定延迟 , 固定延迟 + 泊松分布值】区间
4.7、同步定时器(Synchronized Timer)
可以在某一逻辑点模拟创建最大负载量进行测试;Synchronizing Timer 的技术原理是通过在某一点阻塞线程,直到 X 个线程被阻塞,然后同时释放
右键 >>> 添加 >>> 定时器 >>> 同步定时器(Synchronized Timer)

- 模拟用户组的数量(Number of Simulated Users to Group by):设置多少用户进行同步操作。设置为0表示执行线程组的线程数,设置为3只会执行三个线程数(假设同步线程组数设置为5)4,5线程执行到这一步会停止
注:设置的值不能大于它所在线程组中设置的线程数;0表示 all 无穷大,最大
- 超时时间(Timeout in milliseconds):以第一个到达同步定时器的用户开始,如果在设置的时间内所有用户都达到了,就立即释放后续操作,如果在设置的时间内还没达到,则目前到达集合点的用户先进行释放做后续操作。 设置为0则一直等待,(以第一个到达为准,到多少走多少),如果设置为3,线程设置为永远循环,每凑够三个就会执行释放
脚本示例:【P14】JMeter 同步定时器(Synchronized Timer)
五、前置处理器
前置处理器主要用于执行取样器的预处理逻辑,主要包括参数的设定和传递
jmeter支持的变量类型:用户自定义变量;函数生成变量;BeanShell 变量;数据文件变量
函数生成变量:内置的函数
点击菜单栏工具 >>> 函数助手对话框 >>> 下拉选择 >>> 选择对应函数

执行顺序:
(1)、配置元件优先执行
(2)、按深度优先算法,依次寻找取样器,找到取样器后,逐个执行,遵循第3条规则
(3)、组件执行顺序:前置处理器 -> 定时器 -> 取样器 -> 后置处理器 -> 断言器 -> 监听器
(4)、同一个取样器有多个预处理组件时,在范围内按照广度优先策略依次执行
(5)、前置处理器无子元素

5.1、用户参数(User Parameters)
可以为每一个线程的用户变量指定不同值;在用户参数数据不多时,我们可以用该前置处理器处理,更多时我们采用 CSV 配置元件
右键 >>> 添加 >>> 前置处理器 >>> 用户参数(User Parameters)

-
每次迭代更新一次(Update Once Per Iteration):控制参数取值的变化规则,如果选中该选项,则参数的值在每个迭代中保持不变,在新的迭代开始时取下一个可用值; 如果取消取中该选项,则参数的值在每个其作用域内的Sampler发出请求时取下一个可用值
-
添加变量(Add Variable):横着添加一行变量信息,此变量会应用于每个用户
-
向上(Up):向上移动所选中变量的位置
-
删除变量(Delete Variable):删除所选中的一行数据
-
添加用户(Add User):竖着添加一个用户信息,一个用户就是一组测试数据
-
删除用户(Delete User):删除所选中的一列数据
-
向下(Down):向下移动所选中变量的位置
变量引用格式为:${user}
脚本示例:【P23】JMeter 用户参数(User Parameters)
5.2、正则表达式用户参数(RegEx User Parameters)
可以从返回报文中以正则表达式的方式获取用户变量
注:该处理器必须配合正则表达式后置处理器一起使用
右键 >>> 添加 >>> 前置处理器 >>> 正则表达式用户参数(RegEx User Parameters)

-
Regular Expression Reference Name:正则表达式的引用名称(必须与正则表达式中的 Key 保持一致)
-
Parameter names regexp group number:用于提取参数名称的正则表达式的组编号(例如 1:正则中组1的值作为参数名,当前请求中参数名和它一样)
-
Parameter values regex group number:用于提取参数值的正则表达式的组编号(例如 2:正则中组2的值作为参数值,当前请求中就会直接使用)
脚本示例:【P24】JMeter 正则表达式用户参数(RegEx User Parameters)
5.3、取样器超时(Sample Timeout)
可以对采器设置最大超时时间
右键 >>> 添加 >>> 前置处理器 >>> 取样器超时(Sample Timeout)

- Sample timeout (in milliseconds):超时时间,默认时间为10s秒
注:当设置为0时,0是个特殊值,相当于无限大,永不超时
脚本示例:【P25】JMeter 取样器超时(Sample Timeout)
六、后置处理器
后置处理器主要用于取样器之后的业务处理,比如参数提取、参数关联、逻辑处理等,它是业务逻辑中非常重要的环节
执行顺序:
(1)、配置元件优先执行
(2)、按深度优先算法,依次寻找取样器,找到取样器后,逐个执行,遵循第 3 条规则
(3)、组件执行顺序:前置处理器 -> 定时器 -> 取样器 -> 后置处理器 -> 断言器 -> 监听器
(4)、同一个取样器有多个后置处理组件时,在范围内按照广度优先策略依次执行
(5)、后置处理器无子元素

6.1、正则表达式提取器(Regular Expression Extractor)
接口需要关联时,可以通过正则表达式提取所需要的值
右键 >>> 添加 >>> 后置处理器 >>> 正则表达式提取器(Regular Expression Extractor)

Apply to
-
Main sample and sub-samples:匹配范围包括当前父取样器并覆盖子取样器
-
Main sample only:默认;匹配范围是当前父取样器
-
Sub-samples only :仅匹配子取样器
-
JMeter Variable Name to use:支持对 Jemter变量值进行匹配(输入框内可输入jmeter的变量名称)
要检查的响应字段(Filed to check)
-
主体(Body):响应数据的主体部分
-
Body(unescaped):针对替换了的响应码部分
-
Body as a Document:返回内容作为一个文档进行匹配
-
Response Headers:响应头部分
-
Request Headers:请求头部分
-
URL:URL链接
-
响应代码(Response Code):响应码。如HTTP返回码200代表成功
-
响应信息(Resopnse Message):响应信息。比如处理成功返回“成功”字样,或者“OK”字样
(1)、引用名称(Name of created variable):请求要引用的变量名称,如填写 result_num
(2)、正则表达式(Regular Expression):业务对应的正则表达式
"id":"(.*?)","name":(.\*?)"
(3)、模板(Template):对应正则表达式的组号,从1开始;比如:$1$ 表示取 id 的值,$2$ 表示取 name 的值,也就是对应到表达式中的第几个括号
(4)、匹配数字(0代表随机)(Match No. (0 for Random):0 代表随机取值,n取第几个匹配值,-1匹配所有;比如:取1表示报文中的第1个对象匹配,取2表示报文中的第2个对象匹配
(5)、缺省值(Default Value):如果参数没有取得到值,那默认给一个值让它取
脚本示例:【P15】JMeter 正则表达式提取器(Regular Expression Extractor)
6.2、JSON提取器(JSON Extractor)
可以通过 JsonPath 提取所需要的值,功能非常强大(注意取样器返回必须为 Json);底层采用 jackson 实现
右键 >>> 添加 >>> 后置处理器 >>> JSON提取器(JSON Extractor)

Apply to
-
Main sample and sub-samples:匹配范围包括当前父取样器并覆盖子取样器
-
Main sample only:默认;匹配范围是当前父取样器
-
Sub-samples only :仅匹配子取样器
-
JMeter Variable Name to use:支持对 Jemter变量值进行匹配
(1)、引用名称(Name of created variable):请求要引用的变量名称,如填写 result_num;自定义,多个变量用分号分隔
(2)、JSON路径表达式(JSON Path expressions): json path表达式,也是用分号分隔
(3)、匹配数字(0代表随机)(Match No. (0 for Random)):0 代表随机取值,n取第几个匹配值,-1匹配所有;比如:取1表示报文中的第1个对象匹配,取2表示报文中的第2个对象匹配
(4)、计算连接变量(Compute concatenation var (suffix _ALL)):如果找到许多结果,则插件将使用’,‘分隔符将它们连接起来,并将其存储在名为 _ALL的var中
(5)、缺省值(Default Value):如果参数没有取得到值,那默认给一个值让它取
脚本示例:【P16】JMeter JSON提取器(JSON Extractor)
6.3、边界提取器(Boundary Extractor)
可以通过边界匹配提取所需要的值,功能非常简单实用
右键 >>> 添加 >>> 后置处理器 >>> 边界提取器(Boundary Extractor)

Apply to:参数参考 6.1
要检查的响应字段(Filed to check):参数参考 6.1
(1)、引用名称(Name of created variables):请求要引用的变量名称,如填写 result_num
(2)、左边界(Left Boundary):要匹配的左边界值
(3)、右边界(Right Boundary):要匹配的右边界值
(4)、匹配数字(0代表随机)(Match No. (0 for Random)):0 代表随机取值,n取第几个匹配值,-1匹配所有;比如:取1表示报文中的第1个对象匹配,取2表示报文中的第2个对象匹配
(5)、缺省值(Default Value):如果参数没有取得到值,那默认给一个值让它取
脚本示例:【P17】JMeter 边界提取器(Boundary Extractor)
6.4、JSON JMESPath Extractor
可以通过 JmesPath 语法提取所需要的值,功能非常强大(注意取样器返回必须为 Json);底层采用 JmesPath 的 java 版实现 [https://github.com/burtcorp/jmespath-java],具体语法可以参考:https://jmespath.org/tutorial.html
右键 >>> 添加 >>> 后置处理器 >>> JSON JMESPath Extractor

Apply to:参数参考 6.1
(1)、引用名称(Name of created variables):请求要引用的变量名称,如填写 result_num
(2)、JMESPath expressions:JMESPath表达式
(3)、匹配数字(0代表随机)(Match No. (0 for Random)):0 代表随机取值,n取第几个匹配值,-1匹配所有;比如:取1表示报文中的第1个对象匹配,取2表示报文中的第2个对象匹配
(4)、缺省值(Default Value):如果参数没有取得到值,那默认给一个值让它取
脚本示例:【P18】JMeter JSON JMESPath Extractor
6.5、CSS/JQuery提取器(CSS Selector Extractor)
可以采用 CSS/JQUERY 语法提取所需要的值,功能非常强大(注意取样器返回必须为 htmI/xml);底层采用 jsoup 实现,具体语法可以参考 https://jsoup.org/cookbook/extracting-data/selector-syntax
右键 >>> 添加 >>> 后置处理器 >>> CSS/JQuery提取器(CSS Selector Extractor)

Apply to:参数参考 6.1
CSS 选择器提取器实现(CSS Selector Extractor Implementation)
-
JSOUP:默认采用JSOUP;不选时默认也为JSOUP
-
JODD:JODD格式
(1)、引用名称(Name of created variables):请求要引用的变量名称,如填写 result_num
(2)、CSS选择器表达式(CSS Selector expression):CSS选择器表达式 CSS表达式
(3)、属性(Attribute):要提取的元素的属性;提取内容可以不填。示例:<input type="checkbox" name="colors" value="blue" id="blue">蓝色<br>,那么这里的属性就是value,因为我们要提取blue
(4)、匹配数字(0代表随机)(Match No. (0 for Random)):0 代表随机取值,n取第几个匹配值,-1匹配所有;比如:取1表示报文中的第1个对象匹配,取2表示报文中的第2个对象匹配
(5)、缺省值(Default Value):如果参数没有取得到值,那默认给一个值让它取
脚本示例:【P19】JMeter CSS/JQuery提取器(CSS Selector Extractor)
6.6、XPath提取器(XPath Extractor)
可以采用 Xpath 语法提取所需要的值,功能非常强大(注意取样器返回必须为xml);底层采用 saxon-he 实现,语法参考 https://www.w3school.com.cn/xpath/index.asp 函数:http://saxon.sourceforge.net/saxon7.9.1/functions.html
右键 >>> 添加 >>> 后置处理器 >>> XPath提取器(XPath Extractor)

Apply to:参数参考 6.1
XML Parsing Options(要解析的XML参数)
-
Use Tidy (tolerant parser):当需要处理的页面是HTML格式时,必须选中该选项;如果是XML或XHTML格式(例如RSS返回),则取消选中
-
Quiet:表示只显示需要的HTML页面
-
报告异常:表示显示响应报错
-
显示警告:表示显示警告
-
Use Namespaces:如果启用该选项,后续的XML解析器将使用命名空间来分辨
-
Validate XML:根据页面元素模式进行检查解析
-
Ignore Whitespace:忽略空白内容
-
Fetch external DTDs:如果选中该项,外部将使用DTD规则来获取页面内容
(1)、Return entire XPath fragment instead of text content?:返回文本内容的整个XPath片段
(2)、引用名称(Name of created variables):请求要引用的变量名称,如填写 result_num
(3)、XPath query:用于提取值的XPath表达式
(4)、匹配数字(0代表随机)(Match No. (0 for Random)):0 代表随机取值,n取第几个匹配值,-1匹配所有;比如:取1表示报文中的第1个对象匹配,取2表示报文中的第2个对象匹配
(5)、缺省值(Default Value):如果参数没有取得到值,那默认给一个值让它取
脚本示例:【P20】JMeter XPath提取器(XPath Extractor)
6.7、XPath2 提取器(XPath2 Extractor)
可以采用 Xpath 语法提取所需要的值,功能非常强大(注意取样器返回必须为xml);底层采用 saxon-he 实现,语法参考:https://www.w3school.com.cn/xpath/index.asp 函数:http://saxon.sourceforge.net/saxon7.9.1/functions.html
右键 >>> 添加 >>> 后置处理器 >>> XPath2 提取器(XPath2 Extractor)

Apply to:参数参考 6.1
Extraction properties
-
引用名称(Name of created variables):请求要引用的变量名称,如填写 result_num
-
XPath query:用于提取值的XPath表达式
-
匹配数字(0代表随机)(Match No. (0 for Random)):0 代表随机取值,n取第几个匹配值,-1匹配所有;比如:取1表示报文中的第1个对象匹配,取2表示报文中的第2个对象匹配
-
缺省值(Default Value):如果参数没有取得到值,那默认给一个值让它取
-
Namespaces aliases list (prefix=full namespace, 1 per line):命名空间别名列表。就是这个功能,能让使用命名空间比使用旧的XPath提取器更方便。关于命名空间含义,可以看官方文档:XML 命名空间,但是写的不够详细,详细的参考这里:XML 命名空间(XML Namespaces)介绍以及节点读取方法。由于XPath2对于表达式的要求比较严格,对于带命名空间的XML(包括默认的命名空间),使用不带命名空间前缀的表达式是查询不到结果的;每行一个
-
Return entire XPath fragment instead of text content?:返回文本内容的整个XPath片段
脚本示例:【P21】JMeter XPath2 提取器(XPath2 Extractor)
6.8、结果状态处理器(Result Status Action Handler)
可以对异常流程进行快速控制
右键 >>> 添加 >>> 后置处理器 >>> 结果状态处理器(Result Status Action Handler)

-
继续处理(Continue):报错后按实际情况进行处理
-
跳出当前迭代(Break Current Loop):当某一个线程报错后,不管本次迭代是否还有内容要执行,都跳出
-
开启下一个线程的迭代(Start Next Thread Loop):报错时,本次线程不执行,开始执行下一个线程迭代
-
继续当前线程的下一个迭代(Go to the next iteration of Current Loop):报错后,本次迭代不执行,执行本线程的下一个迭代
-
停止测试(Stop Test):停止时,会检测是否存在正在迭代的内容,如果有,会执行完本次迭代,再停止测试
-
立刻停止测试(Stop Test Now):不存是否存在正在执行的内容,都立刻停止线程组
-
停止当前线程(Stop Thread):比如有8个线程在运行,当某一个线程异常时,移出线程组,继续执行其它7个线程
6.9、调试后置处理程序(Debug PostProcessor)
可以对 Jmeter 中的过程值(变量、参数、系统设置)进行输出;该组件用于调试,功能强大,与 Debug Sampler 功能类似
右键 >>> 添加 >>> 后置处理器 >>> 调试后置处理程序(Debug PostProcessor)

-
JMeter 属性(JMeter properties):jmeter.properties定义的系统级的属性变量。因其变化不大,所以脚本调试时通常不显示,默认False(不显示)
-
JMeter 变量(JMeter variables):JMeter中定义的变量。常用的四种变量定义可参考文章:JMeter常见四种变量简介,默认为True(显示)
-
取样器属性(Sampler properties):样本属性及变量信息。默认为True(显示)
-
系统属性(System properties):系统配置的环境变量等。若系统环境变量在当前脚本中有用到,可以设置为True(显示),默认为False(不显示)
脚本示例:【P22】JMeter 调试后置处理程序(Debug PostProcessor)
6.10、后置处理器小结
| 后置处理器 | 应用场景 |
|---|---|
| 正则表达式提取器、边界提取器 | 无论返回协议,均可以使用 |
| JSON 提取器、JMESPath 提取器 | JSON |
| css/Jquery 提取器 | html |
| Xpath/Xpath2 | xml |
七、断言
断言器主要为 Jmeter 取样器提供成功与否的判断机制,通常用于检查取样器的结果是否正确,类似 LR 中的事务结果检查
执行顺序:
(1)、配置元件优先执行(非控制器内),用户自定义配置元件优先执行(无论是否在控制器内)
(2)、按深度优先算法,依次寻找取样器,找到取样器后,逐个执行,遵循第3条规则
(3)、执行总体顺序:控制器(父类)-> 配置元件(控制器内)-> 前置处理器 -> 定时器 -> 取样器 -> 后置处理器 -> 断言器 -> 监听器
(4)、断言器不可以添加子元素
(5)、同一个取样器有多个断言组件时,在范围内按照广度优先策略依次执行

7.1、响应断言(Response Assertion)
可以对 Jmeter 取样器的响应消息进行检查
使用场景:当响应中有明显的业务标志时,我们可以采用该断言器检测响应报文返回的特征值,进而判断在业务上是否确定
使用频率:非常高,大部分场景均可以使用该断言器
右键 >>> 添加 >>> 断言 >>> 响应断言(Response Assertion)

断言成功,查看结果为绿标;断言失败,查看结果为红标
Apply to
-
Main sample and sub-samples:作用于父节点取样器及对应子节点取样器;对所有取样器进行断言
-
Main sample only:只作用于父节点取样器;只对主取样器进行断言
-
Sub-samples only:只作用于子节点取样器;只对子取样器进行断言(子取样器:原始取样器,通过后置处理器处理后,获取的请求结果)
-
JMeter Variable Name to use:作用于jmeter变量;针对某一个变量进行断言(输入框内输入变量名称)
测试字段(Field to Test)
-
响应文本(Text Response):从服务器返回的响应文本,比如body,包含 HTTP 头(请求的响应数据——Response Body)
-
响应代码(Response Code):比如 200、404(请求的取样器结果中的 Response code)
-
响应消息(Response Message):比如 OK(请求的取样器结果中的 Response message)
-
响应头(Response Headers):比如 Set-Cookie 头(请求的响应数据——Response headers)
-
请求头(Request Headers):(请求的请求——Request Headers)
-
URL样本(URL Sample):请求的地址(请求的请求——Request Body 中的地址)
-
文档(文本)(Document(text)):通过 Apache Tika 追踪的各种类型文档的文本(比如返回的是HTML格式,其中的文本信息)
-
忽略状态(lonore Status):指示 JMeter 设置 sampler status 的初始状态为 success。sample status 是否成功,由已 Response status 和断言结果决定,当选中 Ignore Status 时,Response status 被强制设置为 success,不执行进一步的断言判断。仅第一次断言时使用
-
请求数据(Request Data):(请求的请求——Request Body)
模式匹配规则(Pattern Matching Rules)
-
包括(Contains):响应内容包括需要匹配的内容即代表响应成功,支持正则表达式
-
匹配(Matches):响应内容要完全匹配需要匹配的内容即代表响应成功,大小写不敏感,支持正则表达式。
-
Equals:响应内容要完全等于需要匹配的内容才代表成功,大小写敏感,需要匹配的内容是字符串正则表达式
-
Substring:返回结果包含指定结果的字串,但是 subString 不支持正则字符串
-
否(Not):不进行匹配
测试模式(Patterns Matching Rules): 与模式匹配规则一同使用,可以直接写值也可以使用正则表达式
自定义失败消息(Custom failure message): 自定义失败消息
脚本示例:【P46】JMeter 响应断言(Response Assertion)
7.2、JSON断言(JSON Assertion)
可以对 Jmeter 取样器的响应消息以 JSON 方式进行检查
使用场景:当返回为 JSON 时,利用 JSON 断言,我们可以快速检测响应报文返回的特征值,进而判断取样器在业务上是否正确
使用频率:比较高,尤其是返回为 JSON 时,为首先断言器
右键 >>> 添加 >>> 断言 >>> JSON断言(JSON Assertion)

-
Assert JSON Path exists:用于断言的JSON元素的路径(JSONPath);检测JSONPath是否存在;使用XPATH语法书写
-
Additionally assert value:是否额外验证根据JSONPath提取的值。不勾选,验证JSONPath能否在JSON文档中找到路径;勾选,验证根据JSONPath提取值是否预期
-
Match as regular expression:预期值是否可以使用正则表达式。不勾选,预期值不能使用正则表达式表示;勾选,预期值可以使用正则表达式表示
-
Expected Value:预期值;支持脚本语言写法
-
Expect null:若验证提取的值为null,则勾选此项;验证null值,还是需要勾选“Additionally assert value”,否则验证的是JSONPath能否找到路径;预期值不填表示空字符,与null不等价
-
Invert assertion (will fail if above conditions met):若勾选,表示对断言结果取反
注意:除了 null 外,还有一种特殊的值,就是空数组,预期值不能不填,需要设置为:[]。其中 [] 表示空数组
脚本示例:【P47】JMeter JSON断言(JSON Assertion)
7.3、大小断言(Size Assertion)
可以对 Jmeter 取样器的响应消息的大小进行检查
使用场景:当返回报文为固定长度,而且没有明显业务特征值,比如固定长度的编码
使用频率:极少
右键 >>> 添加 >>> 断言 >>> 大小断言(Size Assertion)

Apply to:参数参考 7.1
Response Size Field to Test
-
完整响应(Full Response):全部响应
-
响应头(Response Headers):响应头,包括Set-Cookie 头,如果有的话
-
响应的消息体(Response Body):从服务器返回的响应体
-
响应代码(Response Code):响应报文相关的代码。比如 200
-
响应信息(Response Message):响应报文的信息。比如 OK
Size to Assert
-
字节大小(Size in bytes):字节大小
-
比较类型(Type of Comparison):输入的字节大小符合所选的比较类型即表示断言通过
7.4、XPath2 断言(XPath2 Assertion)
可以对 Jmeter 取样器的响应消息以 Xpath2 方式进行检查
使用场景:当返回报文为 Xml 时,利用响应断言,我们可以快速检测响应报文返回的特征值,进而判断样器在业务上是否正确
使用频率:比较高,尤其是返回为 Xml 时,为首先断言器
右键 >>> 添加 >>> 断言 >>> XPath2 断言(XPath2 Assertion)

Apply to:参数参考 7.1
XPath2 Assertion
-
Invert assertion(will fail if XPath expression matches):取反
-
Namespaces aliases list(prefix=full namespace,1 per line):命名空间列表。如果使用了额外的命名空间,使用此窗口引入,一行一个
-
书写xpath2表达式
例如:/GETLOG 检测此路径是否存在

7.5、断言持续时间(Duration Assertion)
可以控制取样器的执行是否超过某个时间,如果超时则报错,持续时间断言器也叫超时断言器
使用场景:我们一般用超时断言器来检测业务是否达到某个超时时间
使用频率:一般
右键 >>> 添加 >>> 断言 >>> 断言持续时间(Duration Assertion)

Apply to:参数参考 7.1
Duration to Assert(断言持续时间)
- Duration in milliseconds(持续时间(毫秒)):断言执行时间
脚本示例:【P48】JMeter 断言持续时间(Duration Assertion)
7.6、HTML断言(HTML Assertion)
可以判断取样器的返回是否为 Html 格式,仅做格式校验
使用场景:利用响应断言,我们一般用来检测业务的返回格式是否为 Html
使用频率:极少
右键 >>> 添加 >>> 断言 >>> HTML断言(HTML Assertion)

Tidy Settings:Tidy 环境(Tidy是一个HTML语法检查器和打印工具,可以将HTML转换为XML类型的文件)
(1)、Doctype:文档类型。可通过下拉框选择不同文档类型
-
omit:疏忽遗漏的
-
auto:动态的
-
strict:严格的
-
loose:宽泛的
(2)、Format:文件格式。可选择HTML/XHTML/XML三种不同类型的文件格式来检查返回内容
(3)、Errors only:误差校正(能接受的最大值);例如:10,解析时,10个错误以下都断言成功
(4)、Error threshold:误差/错误范围(可选择误差/错误数量的范围,最大值)
(5)、Warning threshold:警告范围(可选择误差警告的数量范围,最大值)
- 如果勾选 “Error only” 这里忽略 Warning,只对误差作统计检查;如果对返回内容的检查结果不超过指定结果,则断言通过,否则失败
(6)、将 JTidy 报告写入文件(Write JTidy report to file):写入JTidy报告的文件(JTidy是Tidy的一个java移植,可以将它当成一个处理HTML文件的DOM解析器)
7.7、JSON JMESPath 断言(JSON JMESPath Assertion)
可以采 JMESPath 语法方式方式进行检查
使用场景:当返回为 JSON 时,利用 JSON 断言,我们可以快速检测响应报文返回的特征值,进而判断取样器在业务上是否正确
使用频率:比较高,尤其是返回为 JSON 时,为首先断言器
右键 >>> 添加 >>> 断言 >>> JSON JMESPath 断言(JSON JMESPath Assertion)

-
Assert JMESPath exists:用于断言的 JMESPath 元素的路径(JMESPath )
-
Additionally assert value:是否额外验证根据JSONPath提取的值。不勾选,验证JSONPath能否在JSON文档中找到路径;勾选,验证根据JSONPath提取值是否预期
-
Match as regular expression:预期值是否可以使用正则表达式。不勾选,预期值不能使用正则表达式表示;勾选,预期值可以使用正则表达式表示
-
Expected Value:预期值(支持脚本语言)
-
Expect null:若验证提取的值为null,则勾选此项;验证null值,还是需要勾选“Additionally assert value”,否则验证的是JSONPath能否找到路径;预期值不填表示空字符,与null不等价
-
Invert assertion (will fail if above conditions met):若勾选,表示对断言结果取反
脚本类似:JSON断言(JSON Assertion)
7.8、MD5Hex断言(MD5Hex Assertion)
可以对返回内容进行检查
使用场景:当返回报文为固定长度且返回值不变,而且没有明显业务特征值,比如固定长度的编码,而且报文内容比较大;一般用于常量判断,而且返回的值很大,不易于比较
使用频率:较少
右键 >>> 添加 >>> 断言 >>> MD5Hex断言(MD5Hex Assertion)

要断言的MD5Hex(MD5Hex to Assert)
- MD5Hex:输入预期的响应MD5哈希值(一般用于常量判断,而且返回的值很大,不易于比较)
7.9 XML断言(XML Assertion)
可以判断采样器的返回是否为Xml格式
使用场景:利用响应断言,我们一般用来检测业务的返回格式是否为XML
使用频率:极少
右键 >>> 添加 >>> 断言 >>> XML断言(XML Assertion)

7.10 Xpath断言(XPath Assertion)
可以对 Jmeter 采样器的响应消息以 Xpath 方式进行检查
使用场景:返回为 Xml 时,我们可以用 Xpath 方式进行语法检查,进而判断采样器在业务上是否正确
使用频率:比较高,尤其是返回为 Xml 时,为首先断言器
右键 >>> 添加 >>> 断言 >>> Xpath断言(XPath Assertion)

Apply to:参数参考 7.1
XML解析选项(XML Parsing Options)
-
Use Tidy (tolerant parser):当需要处理的页面是 HTML 格式时,必须选中该选项;如果是 XML 或 XHTML 格式(例如 RSS 返回),则取消选中
-
Quiet:表示只显示需要的 HTML 页面
-
报告异常(Report errors):表示显示响应报错
-
显示警告(Show warnings):表示显示警告
-
Use Namespaces:如果启用该选项,后续的XML解析器将使用命名空间来分辨
-
Validate XML:根据页面元素模式进行检查解析
-
Ignore Whitespace:忽略空白内容
-
Fetch external DTDs:如果选中该项,外部将使用 DTD 规则来获取页面内容。引用名称:下一个请求要引用的参数名称,如填写title,则可用 ${ var_regexp2} 引用它(一些 XML 元素具有属性,属性包含应用程序使用的信息,属性仅在程序对元素进行读、写操作时,提供元素的额外信息,这时候需要在 DTDs 中声明)
XPath断言(XPath Assertion)
-
Invert assertion(will fail if XPath expression matches):取反
-
验证(Validate):点击验证,可验证输入框中写入的 xpath 断言的正确性
-
书写xpath表达式
例如:/GETLOG 检测此路径是否存在
7.11 总结
| 断言器 | 应用场景 |
|---|---|
| 响应断言器 | 无论返回协议,均可以使用 |
| JSON 断言器、JMESPath 断言器 | JSON |
| Xpath/Xpath2 断言器 | xml |
| 超时断言器 | 超时判断 |
八、取样器
取样器为 Jmeter 测试的真正工作者,用来采集测试程序的数据,大部分取样器都会返回数据,生成取样结果
执行顺序:
(1)、配置元件优先执行
(2)、按深度优先算法,依次寻找取样器,找到取样器后,逐个执行,遵循第3条规则
(3)、组件执行顺序:前置处理器 -> 定时器 -> 取样器 -> 后置处理器 -> 断言器 -> 监听器
(4)、同一个取样器在处理前后同类型组件时,在范围内按照广度优先策略依次执行
(5)、取样器可以添加除控制器外的其它6大组件作为子元素

注意:
-
一个没有取样器的测试计划是没有意义
-
Jmeter 测试计划的执行是以取样器为核心驱动
8.1、HTTP请求(HTTP Request)
选择线程组右键 >>> 添加 >>> 取样器 >>> HTTP请求(HTTP Request)

基本(Basic)_Web服务器(Web Server)
-
协议(Protocol [http]):向目标服务器发送 http 请求时的协议,http/https,大小写不敏感,默认 http
-
服务器名称或IP(Server Name or IP): http请求发送的目标服务器名称或者IP地址,比如 www.baidu.com
-
端口号(Port Number):目标服务器的端口号,默认值为80
基本(Basic)_HTTP请求(HTTP Request)
-
方法:发送 http 请求的方法,例:GET\POST
-
路径(Path):目标的URL路径(不包括服务器地址和端口)
-
内容编码(Content encoding):内容的编码方式(Content-Type=application/json;charset=utf-8)
-
自动重定向(Redirect Automatically):如果选中该项,发出的http请求得到响应是301/302,jmeter会重定向到新的界面;直接请求到目标地址,不会记录中间的重定向请求,不可以进行内容提取或参数关联
-
跟随重定向(Follow Redirects):跟自动重定向相反,会记录重定向的请求内容
-
使用 keepAlive(Use keepAlive):Jmeter 和目标服务器之间使用 Keep-Alive方式进行 HTTP 通信(默认选中)
-
对POST使用multipart / from-data(Use multipart/from-data):当发送HTTP POST 请求时,使用
-
与浏览器兼容的头(Browser-compatible headers):浏览器兼容的头部
-
参数(parameter): 请求 URL 中添加参数,函数定义中参数,而argument指的是函数调用时的实际参数,简略描述为:parameter=形参(formal parameter),
-
消息体数据(Body Data): 实体数据,就是请求报文里面主体实体的内容,一般我们向服务器发送请求,携带的实体主体参数,可以写入这里(一般 POST 使用;参数长度无限制)
-
文件上传(Files Upload): 从 HTML 文件获取所有有内含的资源:被选中时,发出 HTTP 请求并获得响应的 HTML 文件内容后还对该 HTML(可以上传文件,对文件进行性能测试)
高级(Advanced)_客户端实现(Client implementation)
- 实现(Implementation):发送 http 请求的方式,可选项为 java 和 HttpClient4,默认为 HttpClient4
一般不选,如果请求报错,可以试着换一下
高级(Advanced)_超时(毫秒)(Timeouts(milliseconds))
-
连接(Connect):连接超时时间,单位为毫秒;HTTP 连接建立时的最大超时时间,如果超过,则请求失败
;一般5s -
响应(Response):响应等待超时时间,单位为毫秒;一般10s
高级(Advanced)_从HTML文件嵌入资源(Embedded Resources from HTML Files)
-
从HTML文件获取所有内含的资源(Retrieve All Embedded Resources):当该选项被选中时,Jmeter 在发出 HTTP 请求并获得响应的 HTML 文件内容后,还对该 HTML 进行解析,并获取 HTML 中包含的所有资源(图片、flash 等),默认不选中,如果用户只希望获取页面中的特定资源,可以在下方的嵌入URL必须匹配(Embedded URLs must match)文本框中填入需要下载的特定资源表达式,这样,只有能匹配指定正则表达式的URL指向资源会被下载
-
并行下载(Parallel downloads):是否使用自设资源池,勾选后可设置大小;设置线程数
-
数量(Number):资源池大小,默认为6。例:有多数图片,开6个线程去依次下载
-
网址必须匹配(URLs must match):URL 匹配过滤,填写此项则只会下载与此内容项匹配的 url 的资源,例如要获取 http://example.com/ 下的所有资源,使用正则表达式 http://example.com/.*
-
网址必须不匹配(URLs must not match):与 网址必须匹配 参数相反
高级(Advanced)_源地址(Source address)
只用于 http 协议且 Implementation 为 HttpClient4 的情况
此属性用于启用IP欺骗。会重写了这个 http 请求使用的默认本地 IP 地址。用于 Jmeter 主机具有多个 IP 地址(即 IP 别名、网络接口、设备)的情况。该值可以是主机名、IP 地址或网络接口设备,如 “ey0” 或 “l0” 或 “wlan0”
-
IP/主机名(IP/Hostname):IP/主机名以使用特定的 IP 地址或(本地)主机名
-
设备(Device):选择设备以选择该接口的第一个可用地址,该设备可以是 IPv4 或 IPv6
-
设备IPV4(Device IPV4):选择 IPv4 设备来选择名称设备的 IPv4 地址(如eth0, lo, em0)
-
设备IPV6(Device IPV6):选择 IPv6 设备来选择名称设备的 IPv4 地址(如eth0, lo, em0);
高级(Advanced)_代理服务器(Proxy Server)
比如不想用本机的地址来发送Http请求而想使用代理服务器则填写这部分
-
Scheme:计划
-
服务器名称或IP(Server Name or IP):代理服务器的名称或者IP地址
-
端口号(Port Number):该代理的端口号
-
用户名(Username):使用该代理的用户名
-
密码(Password):用户密码
高级(Advanced)_其他任务
- 保存响应为MD5哈希(Save response as MD5 hash):选中该项,在执行时仅记录服务端响应数据的 MD5 值,而不记录完整的响应数据。在需要进行数据量非常大的测试时,建议选中该项以减少取样器记录响应数据的开销
注:HTTP请求 组件一般配置 HTTP信息头管理器、HTTP请求默认值、HTTP Cookie管理器、HTTP缓存管理器 这四个组件一同使用
脚本示例:【P3】HTTP 接口设计
8.2、调试取样器(Debug Sampler)
可以对 Jmeter 中的过程值(变量、参数、系统设置)进行输出;该组件用于调试,功能强大,与 Debug PostProcessor 功能类似
选择线程组右键 >>> 添加 >>> 取样器 >>> 调试取样器(Debug Sampler)

-
JMeter 属性(JMeter properties):是否查看JMeter属性,默认为False
-
JMeter 变量(JMeter variables):是否查看运行时变量,默认为True
-
系统属性(System properties):是否查看系统属性,默认为False
脚本示例:【P27】JMeter 调试取样器(Debug Sampler)
8.3、JSR223 Sampler
用于在性能测试脚本中执行脚本。它可以使用多种脚本语言(如 Java、JavaScript、Groovy 等)来执行脚本;使用时需要安装对应的脚本引擎。
JSR223 Sampler 常用于测试动态内容、复杂的业务逻辑、复杂的数据操作等。它可以方便地与其他 JMeter 元素(如 HTTP 请求、JDBC 请求等)配合使用,以达到更好的性能测试效果
选择线程组右键 >>> 添加 >>> 取样器 >>> JSR223 Sampler

Script language
- 语言(Language):要使用的JSR223脚本代码语言的类型
将参数传递给脚本(String 与 String [])(Parameters passed to script(exposed as ‘Parameters’ (type String) and ‘args’ (type String[]))
-
参数(Parameters):传递参数,可将GUI脚本中创建的Parameters参数传递至Beanshell脚本中。在Beanshell脚本中引用是使用bsh.args【x】进行实例化
-
浏览(Browse):选择文件位置
脚本文件(覆盖脚本)(Script file(overrides script))
- 文件名(File Name):导入Beanshell脚本运行文件。文件名存储在脚本变量名中。
脚本(Script)
编写脚本处。(Beanshell语法)
-
内置变量vars:提供了对JMeter中的变量的读/写方法
-
内置变量ctx:拿到有上下文context的权限,ctx可以访问很多对象。比如:获取前一个取样器执行结果、获取当前线程所有变量等
用法:
-
JSR223 Sampler 可以获取上一个元素的返回结果,并在脚本中使用。例如,如果在 JSR223 Sampler 前面的元素是 HTTP 请求,则可以在脚本中使用 prev.getResponseDataAsString() 方法来获取 HTTP 请求的响应数据。
-
JSR223 Sampler 还可以设置变量,用于在其他 JMeter 元素中使用。例如,可以在脚本中使用 vars.put(“variableName”, “variableValue”) 方法来设置变量,然后在其他元素中使用 ${variableName} 变量来引用这个变量的值
-
此外,JSR223 Sampler 还可以通过设置「缓存脚本」选项来优化性能,使脚本在多次运行时不必每次都编译
8.4、WebSocket Sampler
可以进行 Websocket 采样测试
该组件并非 Jmeter 原生组件,需要在插件管理中进行二次安装;安装方法可查看【P26】JMeter WebSocket Sampler
选择线程组右键 >>> 添加 >>> 取样器 >>> WebSocket Sampler

Web Server
-
Server Name or IP: 需要连接的 websocket 服务器名称或Ip地址
-
Port Number: websocket 监听的端口号(一般是 HTTP 80 端口,可以通过 WireShark 数据包得到)
Timeout (milliseconds)
-
connection:发送一个连接请求后,Jmeter等待连接完成的最长时间,单位是毫秒
-
response:对响应消息的最大等待时间
WebSocket Request
(1)、Implementation:实现方式,只能选择RFC6455(v13)版本,这是websocket协议标准的最新版本
(2)、Protocol [ws/wss]:要使用的 websocket 协议,ws 表示一般 websocket 连接;wss 表示 websocket 安全连接;如果 websocket 协议在 https 下,选 wss;如果在 http 下,选 ws
(3)、Content encoding:设置消息文本编码,一般用UTF-8
(4)、Connection Id:指定一个会话 id,发送消息
(5)、Path:websocket 请求路径
(6)、Ignore SSL certificate errors:是否忽略 SSL 认证报错,只有协议选择 wss 才会生效。这里与 https 协议类似
(7)、Streaming connection:表示连接是否保留。如果选中,则会保存长连接;否则会在第一次响应后立即关闭连接
-
通过实践发现(观察‘查看结果树–取样器结果’中的执行流程execution flow):
-
当勾选了streaming connection,不仅会在请求结束后保留连接,而且当已存在可用连接时,会直接复用已有连接;
-
当没有勾选streaming connection,每次请求都会新建连接,在请求结束后,会立即关闭连接,而且即使存在可用的连接,也会新建连接
-
同请求一起发送参数:按照表单的形式,填写要发送的参数
(8)、同请求一起发送的参数:相当于 HTTP请求组件中的参数设置
(9)、Request data:要发送的请求数据,要跟开发沟通好,这个是什么格式的消息;相当于 HTTP请求组件中的消息体数据
WebSocket Response
-
Response pattern:采样器将等待含有该标识的消息并继续通信(或者直到timeout,该连接关闭);正则表达式
-
Message backlog:打印最近多少条响应
-
Close connection pattern:关闭连接结果样本,当匹配到设置的字段后,会自动关闭 websocket 连接
Proxy Server (currently not supported by Jetty):代理服务器,通过代理服务器像被测websocket服务发起压测请求
- Server Name or IP:需要代理的服务器名称或Ip地址
脚本示例:【P26】JMeter WebSocket Sampler
8.5、测试活动(Flow Control Action)
控制取样器流程
选择线程组右键 >>> 添加 >>> 取样器 >>> 测试活动(Flow Control Action)

Logical Action on Thread
-
Pause:暂停,配合 Duration 一起使用
-
Duration (milliseconds):延迟时间,单位是毫秒
-
Start Next Thread Loop:开始下个线程循环
-
Go to next iteration of Current Loop:转到当前线程的下一个循环迭代
-
Break Current Loop:跳出当前线程的循环
Logical Action on Thread/Test
-
Stop:停止
-
Stop Now:立即停止
-
Target:(Current Thread或All Threads)选择是当前线程还是所有线程,默认当前线程
脚本示例:【P28】JMeter 测试活动(Flow Control Action)
九、逻辑控制器
控制器主要为 Jmeter 提供基本逻辑控制,包括:循环、条件(分支)
执行顺序:
(1)、配置元件优先执行(非控制器内),用户自定义配置元件优先执行(无论是否在控制器内)
(2)、按深度优先算法,依次寻找取样器,找到取样器后,逐个执行,遵循第3条规则
(3)、执行总体顺序:控制器(父类)-> 配置元件(控制器内)-> 前置处理器 -> 定时器 -> 取样器 -> 后置处理器 -> 断言器 -> 监听器
(4)、控制器可以添加任意组件作为子元素
(5)、在按深度优先算法寻找取样器时,控制器总会被执行
(6)、控制器的后代中必须含有取样器为子元素,否则所有后代元素执行时会无效(配置元件除外),但自身总会被执行
(7)、取样器在执行前后组件时,总是先判断父类控制器(控制器内的配置元件在控制器后执行)



9.1、IF 控制器(If Controller)
可以控制其下面的子/后代元素是否执行;如果为 true 则执行;如果为 false 则都不执行
选择线程组右键 >>> 添加 >>> 逻辑控制器 >>> IF 控制器(If Controller)

(1)、Expression (must evaluate to true or false) :表达式(值必须是true或false),也就是说,在右边文本框中输入的条件值必须是true 或 false,(默认情况下)
(2)、Use status of last sample:快捷方式,取上一次取样器结果是否通过,会引用一个变量,点击后,会在 Expression 框中生成:${JMeterThread.last_sample_ok}
(3)、Interpret Condition as Variable Expression?:默认勾选项,将条件解释为变量表达式(需要使用__jexl3 or __groovy 表达式)【选中这一项时表示:判断变量值是否等于字符串true(不区分大小写)】
-
不勾选:直接输入我们需要判断的表达式即可,判断表达式为真时,执行if控制器下的请求,例如“1!=2”,则一定会执行下面的http请求
-
勾选:这个时候,expression中不能直接填写条件表达式,需要借助函数将条件表达式计算为true/false,可以借助的函数有_jexl3和_groovy
(4)、Evaluate for all children?:条件作用于每个子项,执行每个子项,都会判断一次条件。一般不勾选,条件一般只判断一次即可
注:
-
文本框上的黄色感叹号,就是提示你,建议采用__jexl3 or __groovy 表达式,以提高性能,也就是默认的方式
-
IF 控制器 只能作用于其下的子项
-
jexl全称:Jakarta Commons Jexl,是一种表达式语言(Java Expression Language)解释器
在if逻辑控制器的Expression中不能直接填写条件表达式,需要借助函数将条件表达式计算为true/false,可以借助的函数有__jexl3和__groovy函数。
A:变量,比如 ${flag},如果值为 true,则认为通过,否则认为是 fase
B:函数,条件判断同时支持 js、groovy、jexl3 三种脚本语言,出于性能原因,不建议使用 js
-
js 语法举例:KaTeX parse error: Expected '}', got 'EOF' at end of input: …_\_javaScript("{count}" ==“1"”)}
-
groovy 语法举例:${__groovy(vars.get(“count”) !=“1”)}
-
jexl3 语法举例:KaTeX parse error: Expected '}', got 'EOF' at end of input: {\_\_jexl3({count}< 10)}
脚本示例:【P29】JMeter IF 控制器(If Controller)
9.2、事务控制器(Transaction Controller)
可以生成一个额外的样本,这样能够将它的所有子元素作为一个计量单元进行监听;事务控制器本身不包含任何业务逻辑,只是组合出一个新的计量单元
选择线程组右键 >>> 添加 >>> 逻辑控制器 >>> 事务控制器(Transaction Controller)

-
Generate parent sample:选中,事务控制器将作为其他取样器的父级取样器进行展示(聚合报告会将事务控制器及其下的取样器执行情况均统计,最终仅以事务控制器作为结果统计出来);不选,事务控制器仅作为独立的取样器进行展示(所有的取样器(接口、事务控制器)均统计出来)
-
Include duration of timer and pre-post processors in generated sample:是否在生成的取样器中统计包括计时器、预处理以及后置处理的延迟时间。默认是不勾选
脚本示例:【P30】JMeter 事务控制器(Transaction Controller)
9.3、循环控制器(Loop Controller)
可以对部分逻辑按常量进行循环迭代
选择线程组右键 >>> 添加 >>> 逻辑控制器 >>> 循环控制器(Loop Controller)

- Loop Count:设置运行次数,Infinite 勾选为永久运行
脚本示例:【P31】JMeter 循环控制器(Loop Controller)
9.4、While 控制器(While Controller)
可以对部分逻辑按变量条件进行循环迭代;While 循环控制器与常量循环控制器最大的区别在于 While 是计算动态变量来进行控制
选择线程组右键 >>> 添加 >>> 逻辑控制器 >>> While 控制器(While Controller)

While 循环控制器支持通过变量和函数两种方式进行循环
A:变量,比如 ${count},如果值为 10,则循环 10 次
B:函数,条件判断同时支持 js、groovy、jexl3 三种脚本语言,出于性能原因,不建议使用 js
-
js 语法举例:KaTeX parse error: Expected '}', got 'EOF' at end of input: …_\_javaScript("{count}"!=“0”)}
-
groovy 语法举例:${__groovy(vars.get(“count”)!=“0”)}
-
jex13 语法举例:KaTeX parse error: Expected '}', got 'EOF' at end of input: {\_\_jexl3({count}!=0)}
脚本示例:【P32】JMeter While 控制器(While Controller)
9.5、临界部分控制器(Critical Section Controller)
可以对指定代码块增加同步锁,确保此代码块由单线程执行;通过 Java 关键字 synchronized 实现
选择线程组右键 >>> 添加 >>> 逻辑控制器 >>> 临界部分控制器(Critical Section Controller)

- 锁名称(Lock name):锁名为空,认为每个锁为不同的锁;锁名相同,多个锁认为是同一个锁,同一个时间点只能存在一个运行中;锁名为变量,根据变量值来判断是不是属于同一个锁,变量值为相同时,则认为是同一个锁
脚本示例:【P33】JMeter 临界部分控制器(Critical Section Controller)
9.6、ForEach控制器(ForEach Controller)
可以对一个组变量进行循环迭代;该组件通常与后置处理器中的 JSON 提取器、正则提取器、边界提取器等进行联合使用
选择线程组右键 >>> 添加 >>> 逻辑控制器 >>> ForEach控制器(ForEach Controller)
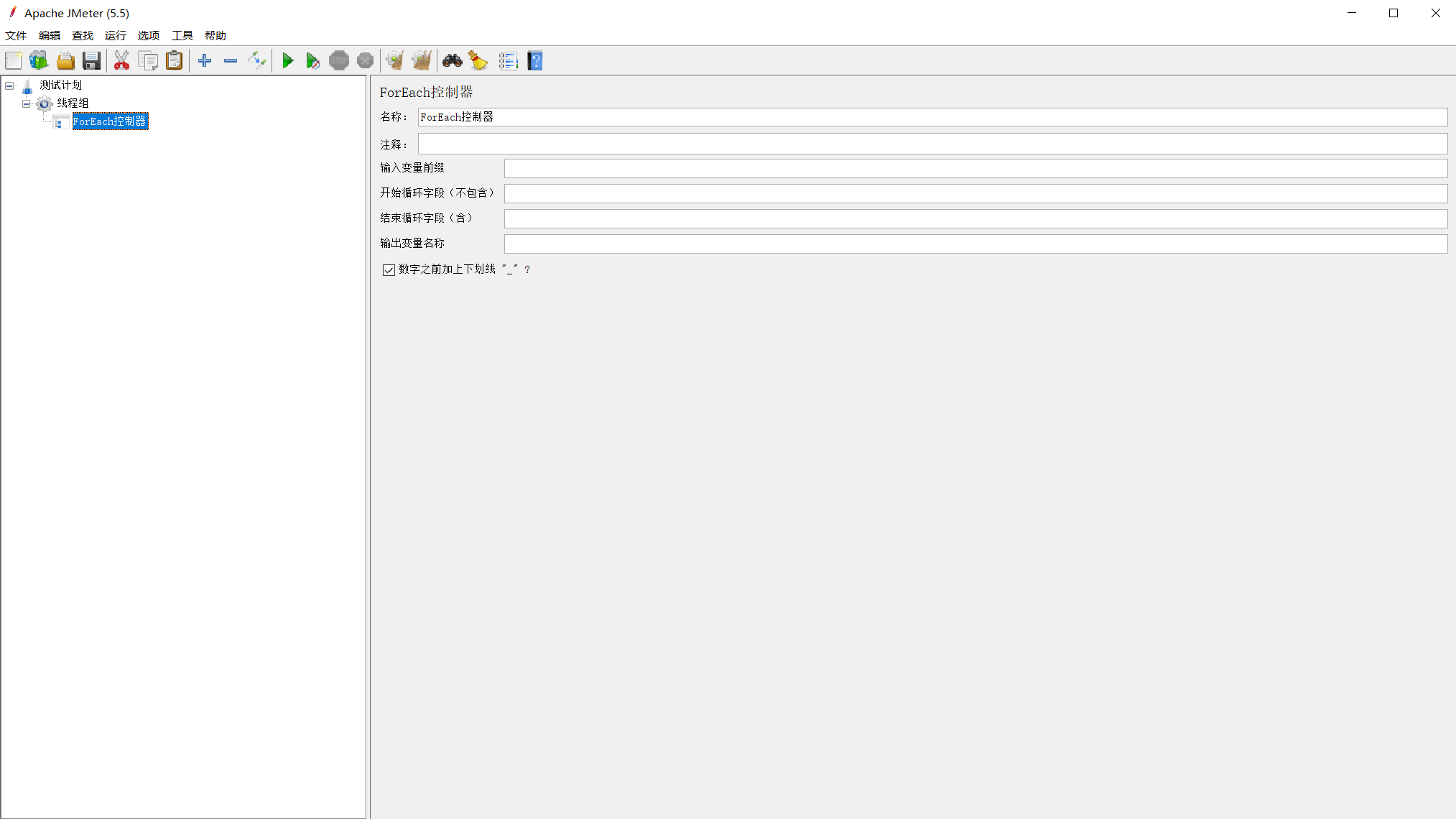
-
输入变量前缀(Input variable prefix):默认为一个空字符串作为前缀
-
开始循环字段(不包含)(Start index for loop(exclusive)):默认从0开始,如果填写是5,实际是从5+1个开始执行
-
结束循环字段(含)(End index for loop(inclusive)):默认从0开始,如果填写是5,实际是从5+1个结束执行
-
输出变量名称(Output variable name):变量名,在后续的操作中可以直接引用。比如,此处填city,那么其他地方引用时可以用 ${city}
-
数字之前加上下划线 “_”?(Add “_” before number ?):勾选,变量名与索引之前有下划线 “_”,比如:city_1。不勾选,变量名与索引之前无下划线 “_”,比如:city1
脚本示例:【P34】JMeter ForEach控制器(ForEach Controller)
9.7、包含控制器(Include Controller)
可以将测试计划的某一部分提取为公用逻辑,这样可以达到不同 jmx 文件进行共享代码片段;通常我们在使用包含控制器时,要先抽取公用部分,设计测试片段
选择线程组右键 >>> 添加 >>> 逻辑控制器 >>> 包含控制器(Include Controller)

- 文件名(Filename):文件的路径一般填写相对路径,否则在测试计划远程压测的时候会报文件不存
脚本示例:【P35】JMeter 包含控制器(Include Controller)
9.8、交替控制器(Interleave Controller)
可以将内部的组件在线程迭代时交替执行;交替控制器内部一般会有多个取样器
选择线程组右键 >>> 添加 >>> 逻辑控制器 >>> 交替控制器(Interleave Controller)

-
忽略子控制器块(Ignore sub-controller blocks):子控制器功能失效,由交替控制器代替
-
Interleave across threads:跨线程交替,线程组在设置了多线程运行时,每一轮循环时,每个线程都在交替控制器中拿到新的请求
脚本示例:【P36】JMeter 交替控制器(Interleave Controller)
9.9、仅一次控制器(Once Only Controller)
可以让控制器内部的逻辑只执行一次;单次的范围是针对某一个线程,无论线程外面迭代多少次或者里面循环多少次,均只执行一次;单次控制器一般可用于登陆,全局参数设置这种只执行一次的逻辑控制
选择线程组右键 >>> 添加 >>> 逻辑控制器 >>> 仅一次控制器(Once Only Controller)

脚本示例:【P37】JMeter 仅一次控制器(Once Only Controller)
9.10、随机控制器(Random Controller)
可以让控制器内部的逻辑随机执行一个,一般用来模拟业务的不确定性;随机控制器在线程迭代或者控制器循环的时候均会触发
选择线程组右键 >>> 添加 >>> 逻辑控制器 >>> 随机控制器(Random Controller)
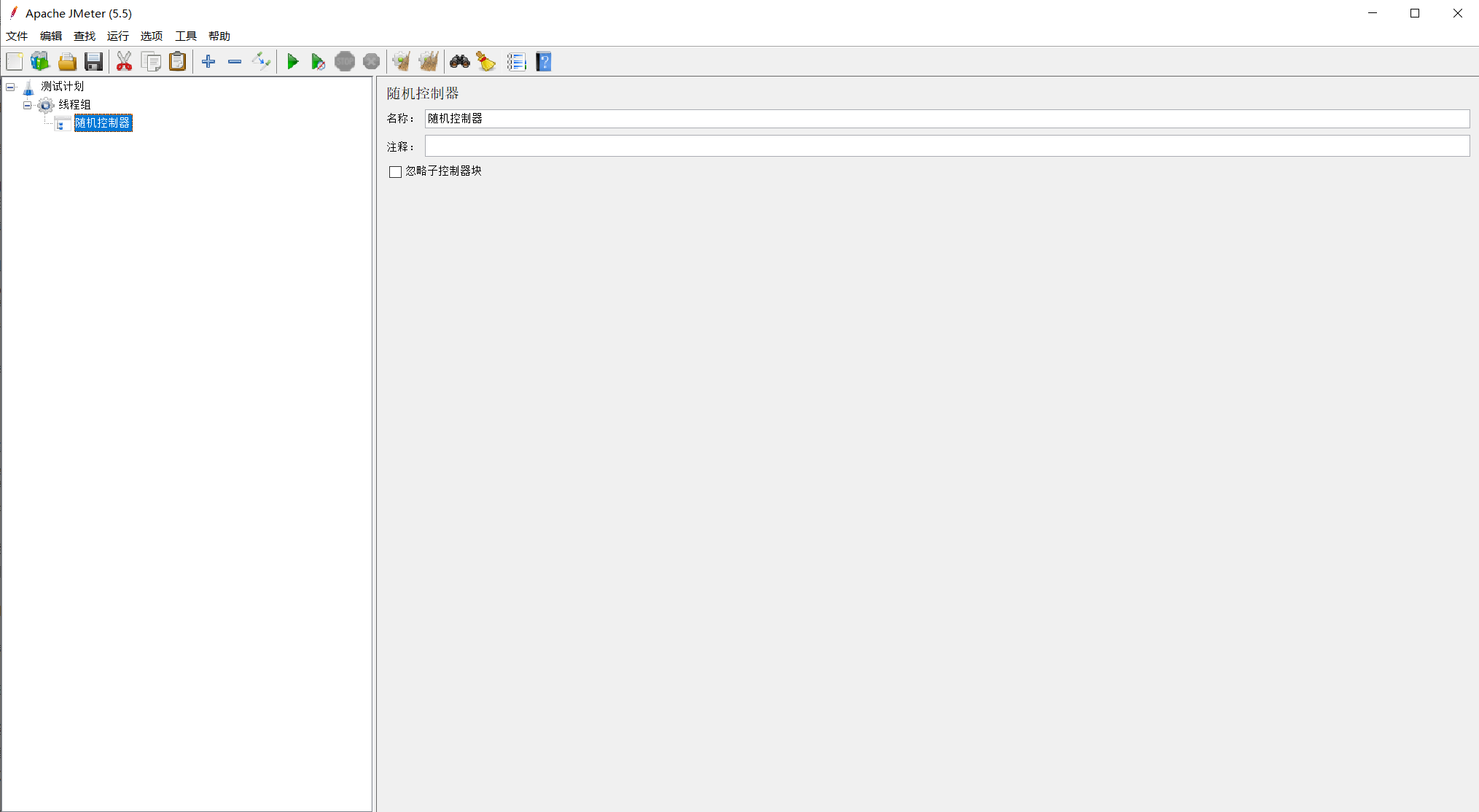
- 忽略子控制器块(Ignore sub-controller blocks):子控制器功能失效,由交替控制器代替
脚本示例:【P38】JMeter 随机控制器(Random Controller)
9.11、随机顺序控制器(Random Order Controller)
可以让控制器内部的组件按随机顺序执行(内部组件全部执行,每次顺序不一定一样),一般用来模拟业务的不确定性;随机顺序控制器在线程迭代或者控制器循环的时候均会触发
选择线程组右键 >>> 添加 >>> 逻辑控制器 >>> 随机顺序控制器(Random Order Controller)

脚本示例:【P39】JMeter 随机顺序控制器(Random Order Controller)
9.12、录制控制器(Recording Controller)
可以理解为一个占位符,用来告诉代理服务器将脚本录制到何处,本身无任何逻辑作用;该组件在录制脚本的时候会用到,用来记录录制脚本作为一个临时的保存位置
选择线程组右键 >>> 添加 >>> 逻辑控制器 >>> 录制控制器(Recording Controller)

脚本示例:【P40】JMeter 录制控制器(Recording Controller)
9.13、简单控制器(Simple Controller)
该组件,是一个占位符,用于脚本模块化管理,无任何逻辑作用,也不对其它组件造成任何影响;用来管理脚本使用,使测试计划更容易理解
选择线程组右键 >>> 添加 >>> 逻辑控制器 >>> 简单控制器(Simple Controller)

脚本示例:【P41】JMeter 简单控制器(Simple Controller)
9.14、运行时间控制器(Runtime Controller)
可以通过时间来确定其后代元素运行多长时间,在时间范围内,后代元素会一直运行,直到超过配置的运行时间;运行控制器下的子元素可能会运行多次
选择线程组右键 >>> 添加 >>> 逻辑控制器 >>> 运行时间控制器(Runtime Controller)

- 运行时间(秒)(Runtime (seconds)):默认为1,去掉1则默认为0。此时不执行其节点下的元件;和线程组的循环次数也有关系,如果是指定次数的话,总的运行时间 = 循环次数 * runtime;如果循环次数是永远,那么 Runtime 控制器下的子项也会永远运行
脚本示例:【P42】JMeter 运行时间控制器(Runtime Controller)
9.15、吞吐量控制器(Throughput Controller)
允许用户控制后代元素的执行的次数。有两种模式:执行百分比和指定总数;吞吐量控制器不会影响取样器的 TPS,但会控制其内部逻辑的执行次数
选择线程组右键 >>> 添加 >>> 逻辑控制器 >>> 吞吐量控制器(Throughput Controller)

(1)、Based on(基于总迭代次数):
-
Total Executions:按照次数来执行;当小于或者等于0时,则不执行,且勾选Per User对该模式有影响
-
Percent Executions:按照百分比来执行;Per User勾选或不勾选都不会影响该模式
(2)、吞吐量(Throughput):
-
对于 percent execution:0-100,代表执行次数的百分比,比如填 50,代表一半迭代中执行
-
对于 total executions:代表执行的总次数
(3)、Per User:
-
勾选:每个线程会单独计算执行频率
-
不勾选(默认):所有线程统一计算执行频率
脚本示例:【P43】JMeter 吞吐量控制器(Throughput Controller)
9.16、模块控制器(Module Controller)
提供了一种在运行时将测试计划片段替换为当前测试计划的机制;模块控制器的目标是为增加脚本的复用性,更好的管理和维护脚本
选择线程组右键 >>> 添加 >>> 逻辑控制器 >>> 模块控制器(Module Controller)

脚本示例:【P44】JMeter 模块控制器(Module Controller)
9.17、开关控制器(Switch Controller)
Switch 控制器的作用类似于 Interleave 控制器,因为它在每次迭代时运行其中一个指定元素,元素索引参考 Switch Value
选择线程组右键 >>> 添加 >>> 逻辑控制器 >>> 开关控制器(Switch Controller)

开关值(Switch Value):既可以是下标值,也可以是名称
-
如果是下标值,则从 0 开始
-
如果下标值超出范围,它将运行第 0 个元素,因此它是数字情况的默认值
-
如果下标值值是空字符串,它还将运行第零个元素
-
如果该值是非数字(非空),则 Switch 控制器将查找具有相同名称的子项(区分大小写)
-
如果两个名称都不匹配,则选择名为 default(大小写无关)的元素
-
如果没有默认值 default,则不会选择任何元素,并且控制器将不会运行任何内容
脚本示例:【P45】JMeter 开关控制器(Switch Controller)
十、非测试元件
10.1、HTTP代理服务器(HTTP(S) Test Script Recorder)
HTTP代理服务器允许JMeter在使用常规浏览器,浏览Web应用程序时拦截并记录操作。JMeter将创建测试样本对象,并将其直接存储到的测试计划中。录制脚本时,最好使用无痕浏览模式,这可以确保浏览器没有存储的Cookie信息,并防止保存某些更改。例如:Firefox不允许永久保存证书替代
测试计划右键 >>> 添加 >>> 非测试元件 >>> HTTP代理服务器

State
-
启动(Start):启动代理服务器。一旦代理服务器启动并准备接受请求,JMeter 就向控制台写入消息:“代理启动并运行!”
-
停止(Stop):停止代理服务器
-
重启(Restart):停止并重新启动代理服务器。当你操作(改变、添加、删除)包含、排除过滤器时,这个按钮很有用
Global Settings
- 端口(Port):设置 JMeter 代理服务器所要用的端口,不能被占用,否则 JMeter 无法使用。默认启用8888端口。
可以在 cmd 中使用 netstat -ano|findstr "8888" 查看端口是否被占用
- HTTPS Domains:编写代理主机的域名或者主机 IP 地址,可以对指定地址进行请求录制。
例:* .baidu.com,*.subdomain.example.com
Test Plan Creation_Test Plan content
(1)、目标控制器(Target Controller):选择录制的脚本所保存的位置
-
使用录制控制器:需要在线程组中添加录制控制器组件(在逻辑控制器元件中添加)否则在开启 HTTP代理服务器的时候会提示报错
-
测试计划 > 线程组:录制的脚本保存到目标线程组(只有在测试计划中添加了线程组,才能看到该选项)
-
测试计划 > HTTP代理服务器:录制的脚本保存到HTTP代理服务器组件下
-
Test Plan > 线程组 > 控制器:录制的脚本保存在线程组中的目标控制器下(只有在测试计划中添加了控制器,才能看到该选项)
(2)、分组(Grouping):是否将录制的单个“点击”请求进行分组,以及如何在录制中表示该分组
-
不对样本分组:就是请求什么就记录什么,对所有录制的取样器不分组
-
在组间添加分隔:每一个 Sampler 结束都会有分隔符间隔开。即:在取样器分组之间添加以名为----------的控制器
-
每个组放入一个新的控制器:每一个 Sampler 请求开始时,都会有一个简单控制器生成。即:每个分组放到一个新的简单控制器下
-
只存储每个组的第一个样本:每个 Sampler 请求时,如果有子请求,那子请求是不会被记录的,只记录第一个 URL请求的样本,而这些取样器的 Follow Redirects 和 Retrieve All Embedded Resources…等选项将被设置上。这种情况虽然很多人说比较推荐,但是个人觉得会丢失许多重要的请求,建议大家还是视情况选择。
-
将每个组放入一个新的控制器中(Put each group in a new transaction controller):每个 Sampler 请求开始时,都会生成一个事务控制器,分组的所有取样器都保存在控制器下
(3)、记录HTTP信息头(Capture HTTP Headers):如果勾选,则将向每个HTTP取样器,添加HTTP信息头管理器
(4)、添加断言(Add Assertions):为每个空的取样器添加一个断言(一般手动断言,自动会有问题)
(5)、Regex matching:指定在替换变量时,是否使用正则表达式匹配。如果勾选,则将取样器中的信息,使用正则表达式来匹配用户定义变量值,替换为变量名 ${变量名},进行替换。匹配时,它只接受整个词匹配,不接受匹配单词一部分
Test Plan Creation_HTTP Sampler settings
(1)、Transaction name:配置事务名称,配合 Naming scheme 参数一起使用
(2)、Naming scheme
-
prefix:在录制时,在取样器名称前添加指定的前缀,自带编号
-
Transaction name:使用用户指定的事务名称,替换取样器名称,自带编号
-Suffix:后缀
- Use format string:自定义设置格式,可以自己定义,如 #{counter,number,000} - #{path} - 登录
默认格式:#{counter,number,000} - #{path} (#{name})
对应:012 - /product/list (测试)
#{counter,number,000}:内容编号,000代表三位,可以在
Counter start value 中设置从几开始
#{path}:路径,如 /product/list
(#{name}):事务名,在 Transaction name 中设置
(3)、Counter start value:设置编号从几开始
(4)、Create new transaction after request (ms):在多少毫秒之后,自动创建一个事务,此选项基本不用
(5)、Recording‘s default encoding:编号,一般设置为 utf-8,防止录制时出现中文乱码
(6)、从HTML文件获取所有资源(Retrieve All Embedded Resources):在生成的取样器中,设置获取所有嵌入式资源
(7)、自动重定向(Redirect Automatically):录制的取样器是否要设置自动重定向
(8)、跟随重定向(Follow Redirects):录制的取样器是否要设置跟随重定向
(9)、使用keepAlive(Use keep Alive):录制的取样器是否要设置为keep Alive状态,保持连接,一般都勾选上
(10)、Type:要生成哪种类型的取样器,HTTPclient4 或 Java,默认 HTTPclient4
Test Plan Creation_GraphQL HTTP Sampler settings
- Detect GraphQL Request:自动生成 GraphQL,很少用

Requests Filtering_Content Type filter
- Include:根据请求头中的 content-type 属性过滤请求,例如 "text/html [;charset=utf-8 ]”
该字段为正则表达式,它会检查 content-type属性中,是否包含了指定字符串[不必匹配整个字段]
顺序是:先检查 content-type 的包含过滤器,再检查排除过滤器,过滤掉的取样器将不会被储存
Requests Filtering_包含模式(URL Patterns to Include)
- 使用它可以过滤 URL 路径,只有取样器的完整 URL 匹配通过,该正则表达式才会被记录
如果在包含模式中至少有一个条目,则只记录匹配一个或多个包含模式的请求
如果我们要录制某个网站的请求,可以添加一个 URL过滤,防止录制不必要的请求
Requests Filtering_排除模式(URL Patterns to Exclude)
- 使用它可以过滤 URL,满足该条件的请求不会被录制
Requests Filtering_将过滤过的取样器通知子监听器(Notify Child Listeners of filtered samplers)
- 通知子监听器被过滤的取样器
包含和排除模式使用正则表达式匹配。它们将与每个浏览器请求的主机名,端口,路径和查询(如果有)进行匹配
如果有任何包含模式,则 URL 必须至少与这些模式之一匹配,否则将不会被记录。如果存在任何排除模式,则 URL 不得与任何模式匹配,否则它将不会被记录。通过使用包含和排除的组合,可以筛选记录实际需要记录的测试样本
注意:由正则表达式匹配的字符串必须与整个 host + path 字符串相同
如果要记录录制过程中样本的响应数据,需要将查看结果树,添加为 HTTP代理服务器的子代组件。即可通过查看结果树,查看录制的请求响应数据
脚本示例:【P4】JMeter 原生录制方式——HTTP代理服务器
总结
持续更新中。。。。。。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 80
80 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)