
彻底解决 UnicodeEncodeError: ‘gbk‘ codec can‘t encode character ‘\xe5‘ in position 13
·
学习python数据分析课程时,遇到的问题,打印个数据,总是报错:
UnicodeEncodeError: 'gbk' codec can't encode character '\xe5' in position 167: illegal multibyte sequence
代码如下:
import io
import sys
from bs4 import BeautifulSoup
import requests
# sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf8') #改变标准输出的默认编码
# 例子 http://www.XXX.com/example.html
url = 'http://www.XXX.com/example.html'
page = requests.get(url)
data = BeautifulSoup(page.text, 'lxml')
print(data)
# 知识点:str转bytes叫encode,bytes转str叫decode1. 打开网站源码,查看编码方式。结果是:charset="utf-8"。尝试写:
print(data.decode('utf-8'))结果还是 报上面那个错。
2. 立刻去网上查,说是改变标准输出的默认编码,于是加入了一句:
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf8') #改变标准输出的默认编码结果:运行成功,没有报错,但是打印的数据是乱码
于是 print(data.decode('utf-8')),试了所有编码,打印结果居然是繁体字。
编码名称 用途 utf8 所有语言 gbk 简体中文 gb2312 简体中文 gb18030 简体中文 big5 繁体中文 big5hkscs 繁体中文
3. 于是试了另一种方法,才彻底解决问题,注释2中加入的代码,设置pycharm的编码,如下图
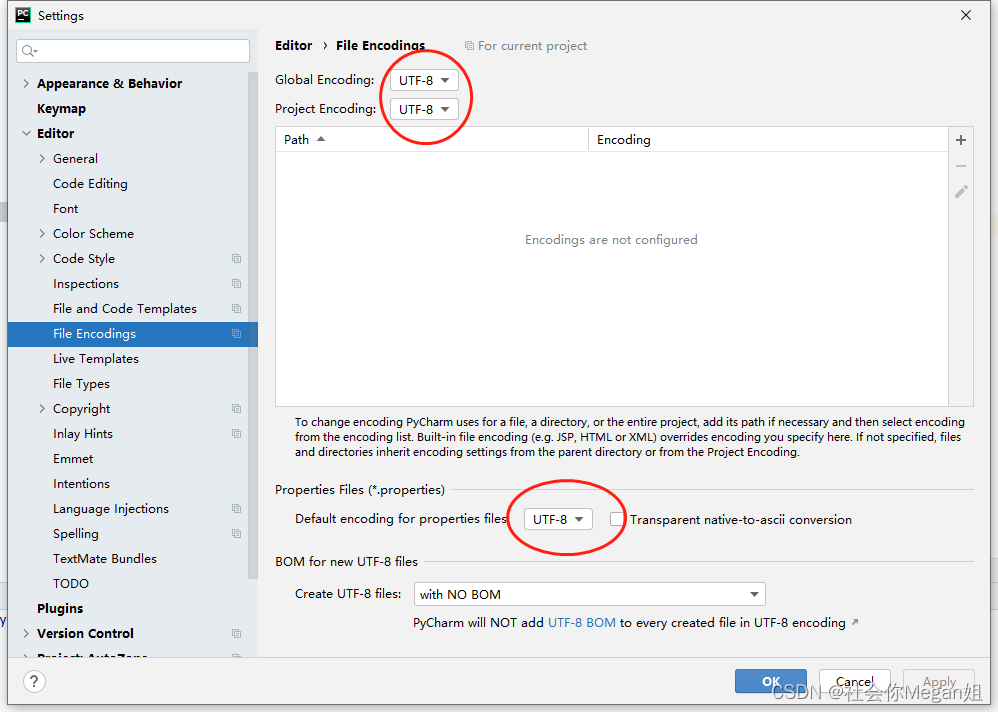
结果:运行成功,不报错,但是还是乱码。
加入代码:
page.encoding='utf-8'结果:运行成功,显示的简体中文。搞定!!!
最后代码:
import io
import sys
from bs4 import BeautifulSoup
import requests
# sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf8') #改变标准输出的默认编码
# 例子 http://www.XXX.com/example.html
url = 'http://www.XXX.com/example.html'
page = requests.get(url)
page.encoding='utf-8'
data = BeautifulSoup(page.text, 'lxml')
print(data)
# 知识点:str转bytes叫encode,bytes转str叫decode
旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐

 59
59 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)