

生成对抗网络GAN论文总结+复现代码(已完成28篇,未完待续。。。)
GAN论文总结
GAN论文学习心得
- 写在前面
- (GAN)Generative Adversarial Networks
- (CGAN)Conditional Generative Adversarial Nets
- (DCGAN)UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS
- (GAN训练提升)Improved Techniques for Training GANs
- (Pix2Pix)Image-to-Image Translation with Conditional Adversarial Networks
- (CycleGAN)Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
- (Pix2PixHD)High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs
- (U-GAT-IT)U-GAT-IT UNSUPERVISED GENERATIVE ATTENTIONAL NETWORKS WITH ADAPTIVE LAYER- INSTANCE NORMALIZATION FOR IMAGE-TO-IMAGE TRANSLATION
- (CAM)Learning Deep Features for Discriminative Localization
- (Hourglass)Stacked Hourglass Networks for Human Pose Estimation
- (photo2cartoon)Few-shot Knowledge Transfer for Fine-grained Cartoon Face Generation
- (ViT)AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
- (PVT)Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions
- (AdaIN)Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization
- (TransGAN)TransGAN Two Pure Transformers Can Make One Strong GAN, and That Can Scale Up
- (Perceptual Loss)Perceptual Losses for Real-Time Style Transfer and Super-Resolution
- (Pix2PixHD改进)采用pix2pixHD的高分辨率皮肤镜图像合成方法
- (FusionGAN)Generating a Fusion Image One’s Identity and Another’s Shape
- (StyleGAN)A Style-Based Generator Architecture for Generative Adversarial Networks
- (数据增强)Differentiable Augmentation for Data-Efficient GAN Training
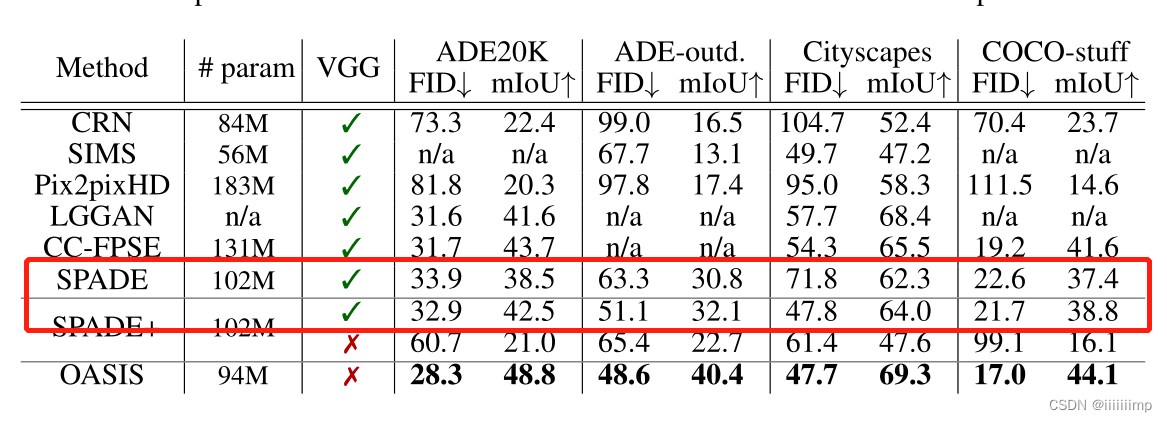
- (SPADE)Semantic Image Synthesis with Spatially-Adaptive Normalization
- (MSG-GAN用于图像翻译)Efficient High-Resolution Image-to-Image Translation using Multi-Scale Gradient U-Net
- (CC-FPSE)Learning to Predict Layout-to-image Conditional Convolutions for Semantic Image Synthesis
- (超声合成)Sketch guided and progressive growing GAN for realistic and editable ultrasound image synthesis
- (OASIS)YOU ONLY NEED ADVERSARIAL SUPERVISION FORSEMANTIC IMAGE SYNTHESIS
- (StyleGAN2)Analyzing and Improving the Image Quality of StyleGAN
- (Pixel2Style2Pixel)Encoding in Style: a StyleGAN Encoder for Image-to-Image Translation
- (SEAN)SEAN: Image Synthesis with Semantic Region-Adaptive Normalization
- 写在后面
写在前面
这学期上图像识别课,老师提到怎么读论文,其中两点就是:
1、将每篇论文所用到的方法和创新点总结出来,看作者的方法或者创新能不能用到其他地方,这样一篇论文就出来了。
2、去读作者的源码,因为有些东西作者论文并不会细讲,在代码中才会体会得更深刻。
鉴于老师期末给我打了高分,再加上我也比较赞同老师得观点,因此打算自己总结一下读过的论文以及复现的代码,由于本人研究方向是GAN,所以GAN会偏多一点。复现的代码为了让大家看清楚网络结构,所以我尽量把网络模型代码写在一个函数里省去了函数跳转以及降低for循环使用,并且注释了特征图经过每一层后的大小,这样能帮助大家理解网络结构。
复现代码见:https://github.com/hahahappyboy/GAN-Thesis-Retrieval
以下言论仅为个人观点,如果相同,那纯属巧合,如果不同,那太正常不过了~欢迎大家讨论
(GAN)Generative Adversarial Networks
1、生成器捕捉数据集得分布,鉴别器判断输入是来自数据集还是生成器。最终生成器拟合真实数据集得分布,鉴别器输出为1/2(表示无法判断数据来源)。
2、生成器和鉴别器都是用多层感知机做的。生成器输入得是随机噪声,鉴别器输出是一个标量。生成器用了relu和sigmoid,鉴别器用了maxout和dropout。maxout现在已被弃用,但是当时maxout和dropout经常被一起使用。
3、

这句话我不太明白是什么意思,我猜测作者想说直接优化D让其达到最优再优化G的话容易造成过拟合。因此要D和G交替训练,训练K次鉴别器再训练1次生成器能让鉴别器接近最优解。换句话说只要生成器G变化的足够慢,鉴别器D就会长时间维持在最优解附近。
4、
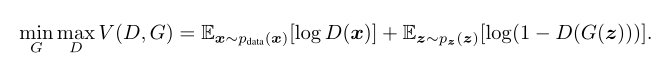
作者认为最小化log(1-D(G(z)))在刚开始训练得时候并不能给G提供很好的梯度(logD(x)的值不由G决定所以不用考虑),因为一开始D(G(z))基本为0,log(1-x)在0点的导数很小,所以G更新很慢,为了解决这个问题作者将最小化log(1-D(G(z)))改为了最大化D(G(z)),这样当D(G(z))最开始接近0的时候logx的导数就足够大,可以为G提供足够的梯度。
5、

作者取k=1。先训练鉴别器再训练生成器。个人认为之所以要先训练D是因为只有D先达到最优解D*训练的G才能达到Pg=Pdata。
6、
作者证明了这个式子是可以解出来的,这是为了证明作者提出的GAN模型是可行的
当判别器达到最优解
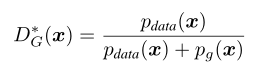
时,生成器的最优解就是Pg=Pdata时,此时结果为-log4。
具体证明可以去B站看李宏毅老师的GAN视频
7、
代码:https://github.com/hahahappyboy/GAN-Thesis-Retrieval/tree/main/GAN
(1)用了GAN和MLP来生成Mnist,可以看到GAN确实要清晰很多,而MLP生成的很模糊,这是因为MLP的loss会导致平均的效果。

(2)更新鉴别器的时候不需要计算生成器的梯度,因此可以加个detach,当然不加也没事
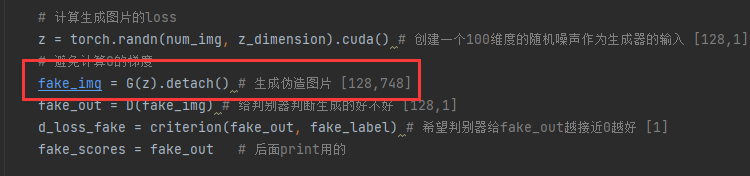
(3)更新鉴别器时用鉴别器的优化器,更新生成器时用生成器的优化器,不要搞错了。
(CGAN)Conditional Generative Adversarial Nets
1、之前的GAN无法控制输出什么图片,因此作者想通过往输入加入额外的信息来控制模型的输出。
2、就是将额外信息y也作为生成器和鉴别器的输入。y可以是类别标签也可以是其他形式的数据。
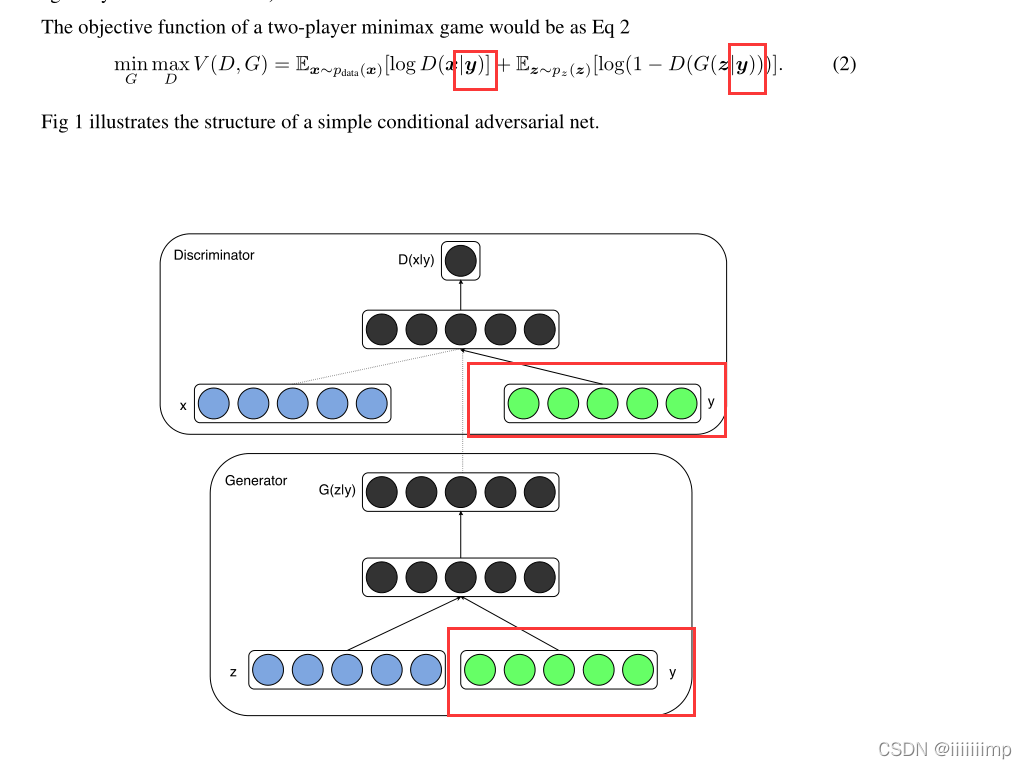
3、在Minist数据集上,作者作者将label的one-hot编码与100维均与分布的随机噪声concat后作为生成器的输入,输出为784维(28*18)
4、
代码:https://github.com/hahahappyboy/GAN-Thesis-Retrieval/blob/main/CGAN/README.md
参考了
(https://blog.csdn.net/qq_37937847/article/details/114443651?utm_medium=distribute.pc_relevant.none-task-blog-2defaultbaidujs_baidulandingword~default-0.no_search_link&spm=1001.2101.3001.4242.1&utm_relevant_index=3)
(1)最主要的就是把标签变成one-hot编码然后与输入进行拼接
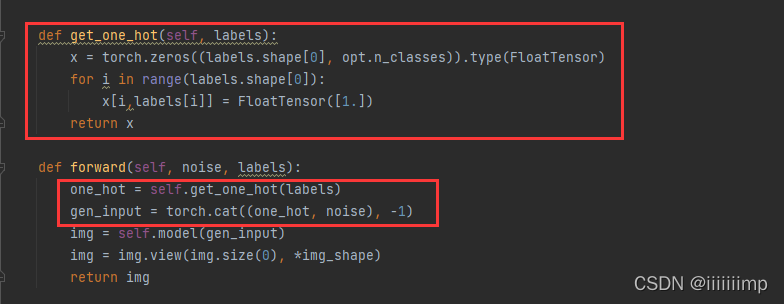
(2)原作者还有些代码写法可以借鉴一下
定义数据类型的代码
保存图片的代码,用的from torchvision.utils import save_image
结果,跑了20轮
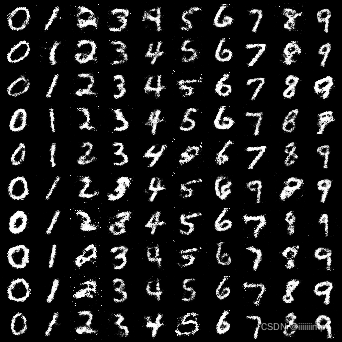
(DCGAN)UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS
1、这篇文章的核心是通过对网络结构做出一定的限制要求,来使得GAN训练更加稳定和提高生成图片的质量。
2、作者发现把有监督训练中常用的CNN网络结构套用到GAN上效果并不好,因此作者在进行大量实验后提出了以下设计要求来让模型训练更加稳定以及提高生成图像质量
(1)使用全卷积网络,用带stride(步长)卷积代替maxpool(我的理解就是加大卷积的步长11改为22)。这样就能让生成器和鉴别器自己去学习下采样的方式,而不是暴力的直接用maxpool下采样。
(2)使用卷积代替全连接。作者认为有人使用全局平均池化代替全连接虽然提高了模型的稳定性,但会降低训练的收敛速度。
全连接参数多训练慢不说,还容易导致过拟合,所以不太推荐。
(3)使用batchnorm,对每一层的输入都归一化为均值为0方差为1。作者说这可以使训练更加稳定,有助于降低因初始化的问题所造成的训练不好,也缓解了深层网络中的梯度溢出问题,防止模式崩塌。但是作者又说将BN作用于每一层上会造成训练的不稳定,因此在生成器最后一层和鉴别器输入层没有用BN。
由于深度学习的神经网络层数多,每一层都会使得输出数据的分布发送变化,随着层数的增加网络的整体偏差会越来越大。BN的目标是为了解决这一问题,通过对每一层的输入进行归一化处理,能有效使得数据服从某个固定的数据分布。
(4)生成器中,除去最后一层使用Tanh之外,每一层都使用ReLU来激活。这样可以让模型更快的学习图像的颜色空间分布。在判别器中用LeakyReLU ,能提高生成高分辨率模型的效果。
Sigmoid的缺点:当输入很大或很小时,函数梯度几乎为0,不利于反向传播。Sigmoid的均值不是0,这使得网络训练过程中只会产生全正或全负的反馈。
Tanh解决了Sigmoid函数均值不为0的问题,实践中通常Tanh函数优于Sigmoid函数。因此作者最后一层用Tanh而不用Sigmoid。
ReLU能比Sigmoid和Tanh更容易使得网络收敛。但是ReLU可能导致某些神经元永远无法更新,因此LeakyReLU能够缓解这种梯度消失的问题。但为什么只在鉴别器中用呢?我就不知道了~
总结:
- 判别器中使用步长的卷积层来替换所有pooling层,生成器中使用分步(反)卷积来代替pooling层。
- 在生成器和判别器中使用BN。
- 生成器和判别器都不用全连接。
- 生成器除最后一层使用Tanh之外其他每一层都使用ReLU来激活。
- 鉴别器每一层都使用LeakReLU来激活。
3、训练参数
- 对图像的预处理,除了将像素值缩放到Tanh的[-1,1]以外就没做其他任何处理
- 使用小批量SGD,batch为128
- 模型权重初始化为均值为0方差为0.02的正太分布
- LeakReLU的负向权重为0.1
- 使用Adam优化器,但是学习率0.001太大了,所以使用了0.0002。并且β1=0.9的动量会导致训练不稳定,所以改为0.5。
这就是炼丹的过程了~
5、作者通过慢慢改变生成器的输入向量值来探索输入是如何影响图像生成的,并且还能判断网络是真的学到了语义信息还是只是单纯的记住了图像。
可以看到作者慢慢改变输入后,生成的图像逐渐有了窗子,因此这证明了网络是真的学到了语义信息,并不是只是单纯的记住了图像。因为如果改变一点点输入图像就变化很大或完全没有什么变化就可以说明网络只是单纯的记住了图像和输入的映射关系,而没有学习到分布特征。

6、作者可视化鉴别器学习的特征,证明了鉴别器学习到了层次特征。这个层次特征是不是就是高级语义信息哦?

7、作者用逻辑回归分类去找出生成器中与窗子有关的卷积核并将其权重置0,然后发现窗子都消失了
这表面生成器在分离场景表示和对象表示方面做得很好。至于为什么我也不知道~

8、有研究表面"国王"向量-"男人"向量+"女人"向量="王后"向量,于是作者也做了相同的实验
"开心"女人-"无表情"女人+"无表情"男人="开心"男人
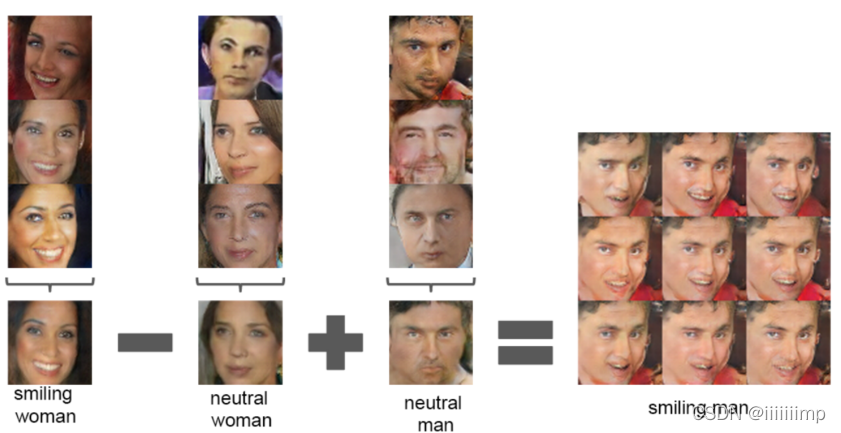
注意,作者的生成器输入向量是三个向量的平均了。这是为了综合掉输入向量的一些噪声,不这样做就会造成以下结果

9、作者把输入向量慢慢变成另一个输入向量发现对应图片也会逐渐慢慢变化,这证明了CGAN的可靠性。

10、代码:https://github.com/hahahappyboy/GAN-Thesis-Retrieval/tree/main/DCGAN
结果:
我感觉从最终结果上来看使用ReLU和使用LeakyReLU并没有特别大的差别。使用IN比使用BN生成的头发纹理更加清晰,所以个人感觉还是因情况而定吧,也有人说GAN中IN好于BN。

感觉还是to(device)这种用法比较好

原来[100, 1, 1]的向量也能反卷积啊~
(GAN训练提升)Improved Techniques for Training GANs
1、这篇文章作者提出了一些方法可以提高生成图像的质量。
2、作者说训练GAN就是对抗的两个玩家之间寻找纳什均衡,但之前GAN使用梯度下降来最小化损失函数并不是寻找使G和D的纳什均衡。因为当D去最小化其损失J(D)时会增加G的损失J(G),而G去最小化其损失J(G)会增加D的损失J(D),从而使模型无法收敛。
作者这里举了一个例子,假如一个是控制x来最小化xy,一个是控制y来最小化-xy。控制x来最小化xy的会让x越小越好,这是就会让-xy变大。而控制y来最小化-xy的会让y越大越好,这时会让xy变大,这样当梯度下降稳定后并不能到达最佳点(x=0,y=0)。
3、作者提出了特征匹配损失来提高GAN训练的稳定性。生成器在优化对抗损失时还要优化特征匹配损失从防止生成器过度依赖鉴别器的输出来更新自己的参数。具体做法是让生成器生成的样本经过鉴别器各个中间层得到的特征图与真实样本经过鉴别器中间层得到的特征图越接近也好。理论依据就是:鉴别器本身就是要寻找生成样本的特征与真实样本的特征最显著差别的地方,因此作者认为这些差别是生成器值得学习的。
f(x)是鉴别器各个层的输出
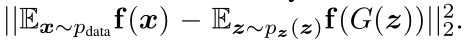
4、作者提出了小批量训练鉴别器。这是为了缓解模式崩塌,因为如果batchsize为1的话,即便出现了模式崩塌,但由于鉴别器只接受一张图片为输入,并不知道生成器只输出单一的图片,所以无法指导生成器生成不一样的图片。因此作者借鉴BN的想法,想让鉴别器训练时看到多个样本。于是将鉴别器的输入xi(xi为小批量数,也就是一次输入鉴别器的样本数)经过中间层得到的特征f(xi)乘以一个张量T得到矩阵Mi,再计算各个矩阵与其他矩阵之间的L1距离并求和得到o(xi),最后再将所有o(xi)与特征f(xi)拼接在一起作为下一层的输入。
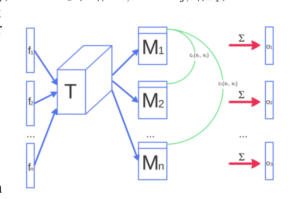
但是不同于BN,作者的小批量(Minibatch)鉴别器依然输出的是一个值,鉴别器只是把minibatch作为辅助信息。
5、作者在鉴别器和生成器的损失中加入了正则项,说是可以让梯度不容易进入稳定,能够继续向纳什均衡更新。具体我也没看明白。
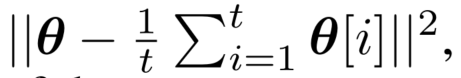
6、使用标签平滑。作者认为用0.1~0.9代替0~1能使分类器降低对对抗样本的敏感性,因此作者将对于鉴别器的输出0~1的标签平滑为α~β。在应用的时候将真实数据的正样本判别为0.9和生成数据的负样本设置为0.1既可。
7、虚拟BN。作者认为BN有个缺点,即会使G生成一个batch的图片中,每张图片都有相关性,比如生成的一个batch图片中绿色比较多。为了解决这个问题,作者提出了VBN(虚拟BN)。具体过程我也不太清楚。反正会导致训练一次要进行两次正向传播,比较耗时,从而只在生成器中用。
8、对于生成图像的评价,作者除了使用人工评价(MTurk)还提出了Inception Score用来降低人力成本,并且实验证明Inception Score与人类判断高度一致,是可行的。但是作者说并不能把这个指标用来直接优化送给模型来优化,因为这样会导致生成对抗样本。
(Pix2Pix)Image-to-Image Translation with Conditional Adversarial Networks
蓝色字代表作者的想法
\color{blue}{ 蓝色字代表作者的想法}
蓝色字代表作者的想法
红色字代表作者的创新
\color{red}{ 红色字代表作者的创新}
红色字代表作者的创新
1
、
\color{blue}{ 1、}
1、以前的方法做图像翻译都会单独的为某一功能设计损失函数,例如对图像上色设计一种损失函数,为标签到图像又设计一种损失函数,这样就很麻烦,因此作者想要用一种统一的框架去处理这一类从图像到图像的问题,因此提出了Pix2Pix。
2 、 \color{blue}{2、} 2、 作者认为CNN的任务是最小化我们提出的损失,但是前提是我们要清楚的知道我们提出的损失到底是干嘛的,其实作者想要表达的就是如果我们想要做边缘检测或者还原真实图像,那么我们最小化的损失函数是不一样的。例如不能天真的都用欧氏距离使预测和真实标签的距离最小化,因为这样照成模糊。
3 、 \color{blue}{3、} 3、为什么GAN生成的图片不会像CNN那样模糊呢?作者认为这是因为GAN训练生成器去最小化鉴别器分清楚生成图片和真实图片之间差别的loss。生成的模糊图片将在两个网络对抗时就被修正。因此GAN具备自动适应数据分布损失的能力,就不需要额外的损失函数。
4
、对于损失函数,在
C
G
A
N
L
o
s
s
上加入了
L
1
L
o
s
s
。
\color{red}{4、对于损失函数,在CGANLoss上加入了L1Loss。}
4、对于损失函数,在CGANLoss上加入了L1Loss。作者认为把GAN的loss与其他loss结合起来能优化最终结果,因此作者选择在生成器中加入L1Loss,之所以不用L2Loss可能是因为L1Loss比L2Loss更能避免模糊。
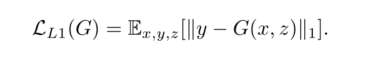
需要注意的是其实作者并没有像CGAN那样加入随机噪声z,这是为了让生成器产生确定的输出。
因此最终Loss变成了GANLoss+L1Loss
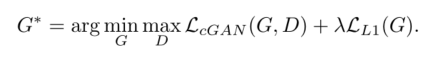
作者之后说了,虽然加入L1Loss/L2Loss都会使得生成图像变得模糊,但是加入它们能准确地捕捉图像的低频,因此还是用了L1Loss。这里我们可以想到既然低频信息是L1Loss来捕捉,那么高频信息自然就是GANLoss来捕捉了。

5
、对于生成器网络结构,使用了
U
n
e
t
。
\color{red}{5、对于生成器网络结构,使用了Unet。}
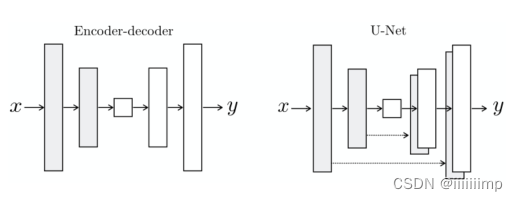
5、对于生成器网络结构,使用了Unet。作者认为输入和输出图像表面上是不同的但是其内在结构是相同的,例如图片夏天到冬天转换,其实景色是不变的,山还是山,树还是树,只不过把草地变为的雪地,即整幅图的框架结构没变。因此作者采用了Unet结构而不是编解码器结构,Unet结构相对于编解码器结构唯一多的就是跳跃连接。之所以要加跳跃连接是因为作者认为输入图片和输出图片之间有大量的底层信息是需要共享的,例如说颜色和边缘(也就是上面说的结构信息),而这些信息最好能通过跳跃连接直接传到上采样层,避免了下采样时的信息丢失。
5
、对于鉴别器网络结构,使用了
P
a
t
c
h
G
A
N
。
\color{red}{5、对于鉴别器网络结构,使用了PatchGAN。}
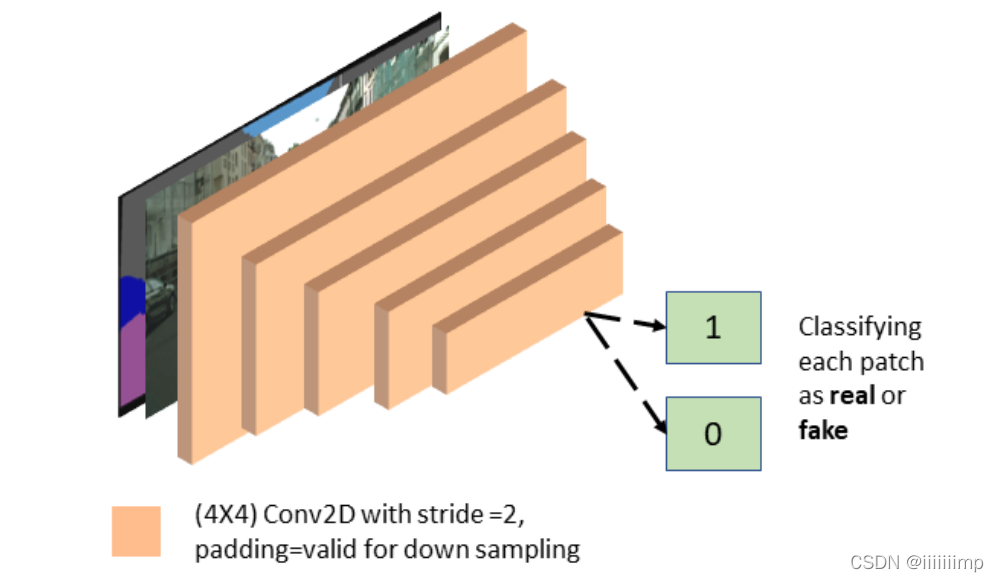
5、对于鉴别器网络结构,使用了PatchGAN。前面说了作者加入L1Loss是为了保留住低频信息,那么高频信息自然而然就要用GANLoss来保留了,因此作者将鉴别器设计层PatchGAN的结构。其输出为一个NN的块。这样的好处是能减少参数、使模型运行更快、能应用于任意大小的图片,并且最终结构还不差。并且因为PatchGAN输出的NN由N个11组成的,而这些11的感受野相比之前鉴别器模型D最后直接输出1个11要小(因为卷积层数更少),从而使得PathGAN更能关注到图像细节。同理之前鉴别器模型D因为最后直接输出1个11所以拥有全局感受野,更关注到图像整体。
6、代码:https://github.com/hahahappyboy/GAN-Thesis-Retrieval/tree/main/Pix2Pix
参考了官方代码
时间原因只复现了模型和训练流程
作者生成器下采样用的是LeakyReLU,而上采样用的是ReLU,并且上采样还加了Dropout,归一化用的是BN,最后输出为Tanh
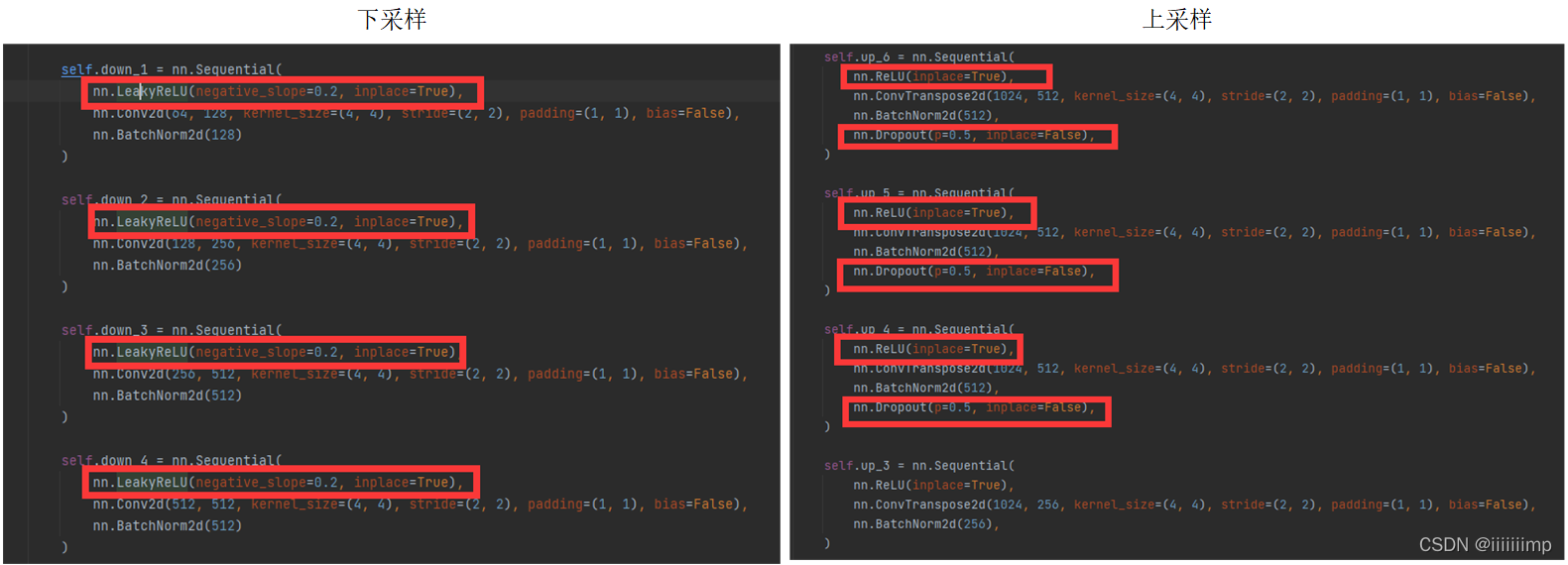
跳跃连接前的通道拼接是按NCHW的C维度进行拼接
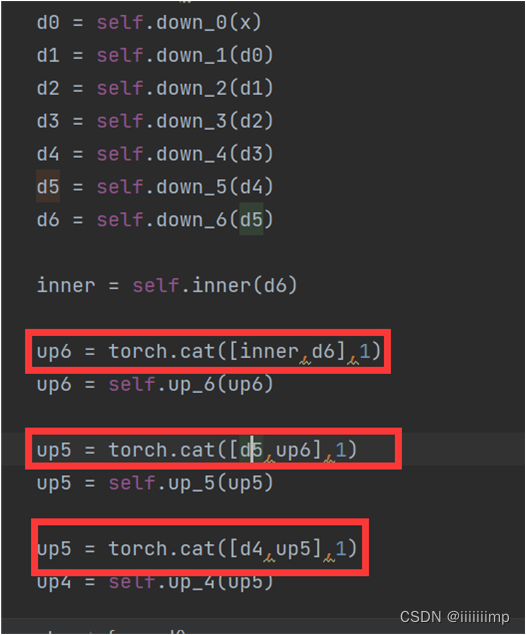
鉴别器,输入是生成器的输入和真实/伪造图片,所以为6维,输出为1维的patch
训练,由于鉴别器输入用了detach,所以训练生成器时还要重新forward一次鉴别器
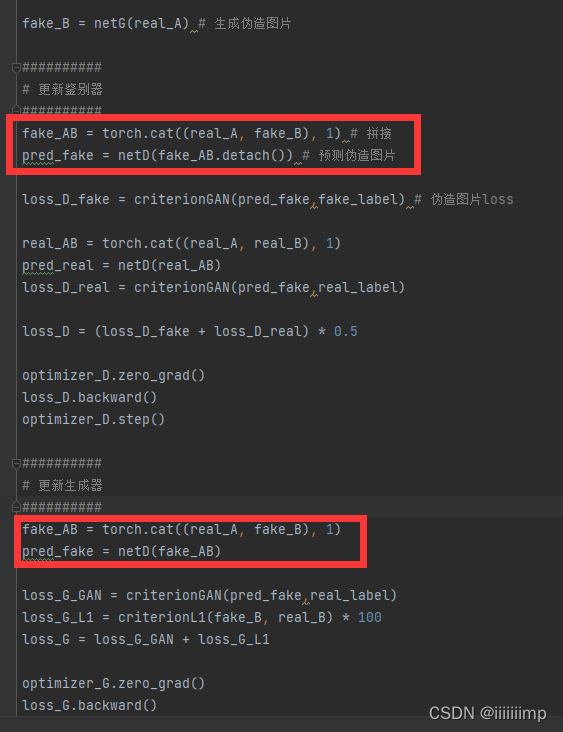
(CycleGAN)Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
GAN风格迁移鼻祖
蓝色字代表作者的想法
\color{blue}{ 蓝色字代表作者的想法}
蓝色字代表作者的想法
红色字代表作者的创新
\color{red}{ 红色字代表作者的创新}
红色字代表作者的创新
1
、创新点
\color{blue}{1、创新点}
1、创新点
由于成对的图像实在太少了。因此作者想能不能用非成对数据完成风格迁移。但是作者发现用之前的方法对GAN进行训练,非常容易出现模式不同。然后受到pix2pix思想启发(生成器的输入也是鉴别器的输入)以及利用循环一致性监督训练的思想,提出了CycleGAN。
所以创新点为:
(1)提出了GAN的无监督风格迁移
(2)提出了GAN的循环一致性损失
(3)提出了恒等损失
2
、网络结构
\color{red}{2、网络结构}
2、网络结构
生成器是Unet 鉴别器是PatchGAN
一共2个生成器2个鉴别器
一轮分两次训练:
(1)x通过生成器Gx2y生成器得到Y ^,Y ^给鉴别器DY做真假判断,Y ^再给生成器Gy2x得到x ^。
(2)y通过生成器Gy2x生成器得到X ^,X ^给鉴别器DX做真假判断,X ^再给生成器Gx2y得到y ^。
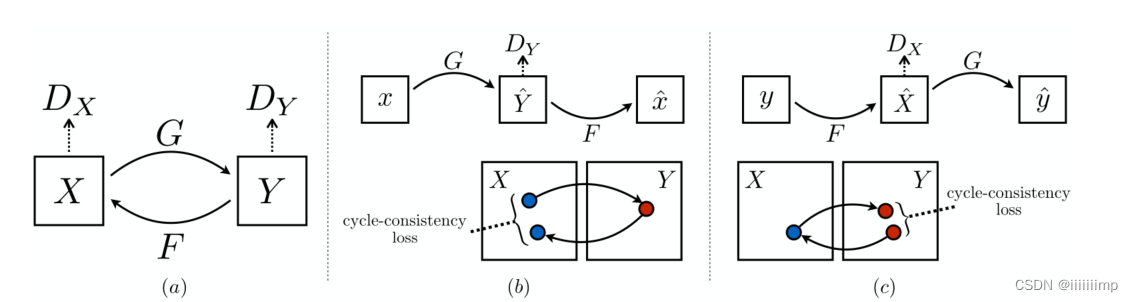
3
、对抗损失的作用
\color{red}{3、对抗损失的作用}
3、对抗损失的作用
对抗损失能让风格迁移进行,但并没有用交叉熵损失而是最小二乘损失,因为这个损失更加稳定,生成的图像质量更高。
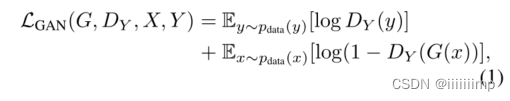
4
、循环一致性损失的作用
\color{red}{4、循环一致性损失的作用}
4、循环一致性损失的作用
循环一致性损失就是让x和x ^以及y和y ^做L1Loss
作用就是让风格迁移的图片与原图对应起来,因为如果不做这一个过程那么很容易造成模式崩塌,因为在无监督下生成器完全可以忽略输入,自己随便生成一张风格迁移图片,从而让原图与生成图完全看不出是原图通过风格迁移来的。因此才要循环损失,让生成的图再通过一个生成器转换为伪原图做L1Loss,这样就能保证生产的图一定看的出来是原图通过风格迁移来的。
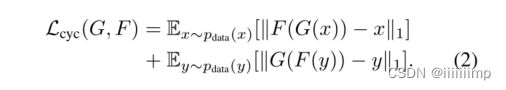
5
、恒等损失
\color{red}{5、恒等损失}
5、恒等损失
作者发现将y给Gx2y和把x给Gy2x做L1Loss能使生成的图像色彩更加饱和
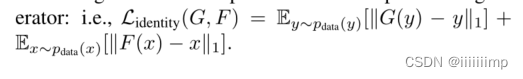

6
、训练技巧
\color{red}{6、训练技巧}
6、训练技巧
作者为了减小模型训练时候的震荡,在更新判别器的时候,采用的一段时间之前生成器生成的图片而不是最近生成的图片。具体实现是采用了长度为50的缓冲去存储生成的图片。
另外作者也认为成对训练始终比非成对训练出来的效果要好。
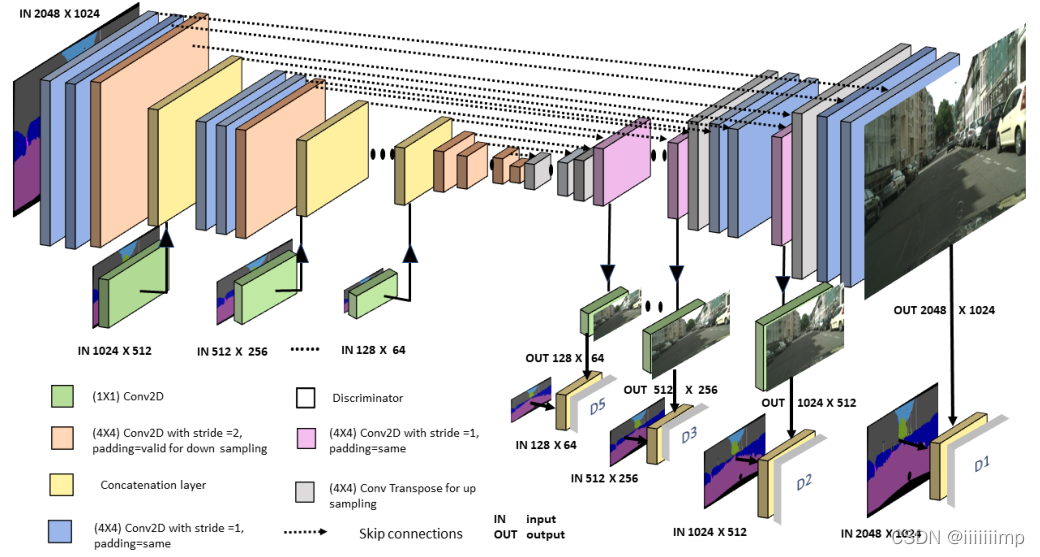
(Pix2PixHD)High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs
蓝色字代表作者的想法
\color{blue}{ 蓝色字代表作者的想法}
蓝色字代表作者的想法
红色字代表作者的创新
\color{red}{ 红色字代表作者的创新}
红色字代表作者的创新
1、之前的基于CGAN的网络如Pix2Pix并不能产生高清晰度的图像,因此作者提出了在Pix2Pix基础上提出了Pix2PixHD来解决这个问题。
2 、 L 1 L o s s 会使得图片模糊,而 G A N L o s s 不会。 \color{blue}{ 2、L1Loss会使得图片模糊,而GANLoss不会。} 2、L1Loss会使得图片模糊,而GANLoss不会。这是因为鉴别器会学习一个可训练loss函数以及自动的去适应生成图片和真实图片在目标域之间的不同。
3
、使用粗到细的生成器。
\color{red}{3、使用粗到细的生成器。}
3、使用粗到细的生成器。 G1作为全局生成器,G2作为局部增强器。
全局生成器器由下采样模块+残差模块+上采样模块构成,其输入是1024*512,输出也是1024 * 512。
局部增强器同样也是由下采样模块+残差模块+上采样模块构成,不同的是,其上采样模块的输入是其残差模块输出和全局生成器的输出的拼接。输入输出都是2048 * 1024。在训练的时候先训练全局生成器G1,然后训练局部增强器G2,G1负责生成全局信息,例如物体的轮廓,而G2负责生成局部信息,如物体纹理,通过G1和G2的合作从而生成高分辨率图像。
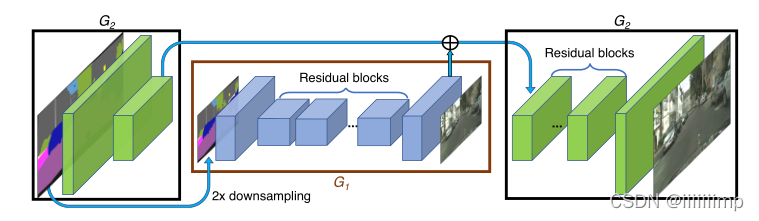
4
、使用多尺度鉴别器。
\color{red}{4、使用多尺度鉴别器。}
4、使用多尺度鉴别器。 为了增强鉴别器区分真实图片和伪造图片的能力,往往都会设计更大的感受野给鉴别器,但是其结果就是导致内存消耗大并且网络容易过拟合。为了解决这个问题,作者使用了多尺度鉴别器。就是使用三个一模一样的鉴别器但是输入的图片尺寸不一样,输入小尺寸的图片就相当于变相增加了鉴别器的感受野大小。这样输入低分辨率图片的鉴别器具有更大的感受野,就可以保证生成图片的全局一致性。输入为高分辨率图片的鉴别器具有较小的感受野,可以促进生成图像细节方面的合成。作者还说,如果不使用多尺度鉴别器容易造成模式崩塌。
5 、在多尺度鉴别器上使用特征匹配损失。 \color{red}{5、在多尺度鉴别器上使用特征匹配损失。} 5、在多尺度鉴别器上使用特征匹配损失。 就是让生成图片和真实图片通过鉴别器某些层后得到的特征图越接近越好,这样能让生成的图片更自然,并且提高生成器训练的稳定性。
6
、使用实例映射。
\color{red}{6、使用实例映射。}
6、使用实例映射。 将label的边界图像与label按通道维度拼接一并送人生成器能使生成的图片有更加清晰的边界。
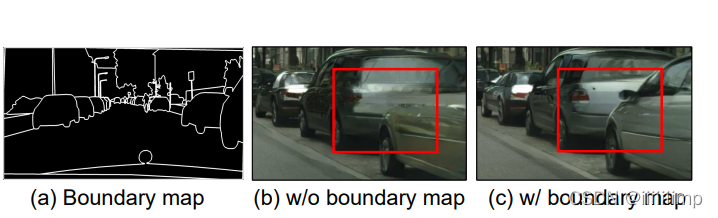
7
、使用感知损失。
\color{red}{7、使用感知损失。}
7、使用感知损失。与特征匹配损失差不多,只不过是让生成图片和真实图片通过预训练的VGG19,让后取出某些层的特征图让他们做L1Loss。
8、代码:https://github.com/hahahappyboy/GAN-Thesis-Retrieval/tree/main/Pix2PixHD
参考了作者的代码
时间原因只复现了模型和训练流程
作者默认只使用了全局生成器,下采样+残差块+上采样,注意残差块用的是相加,不是通道拼接

鉴别器主要就是要把各个模块分开定义,这是为了提取中间的特征图用于后面的loss计算,forward函数也是返回的一个特征图List
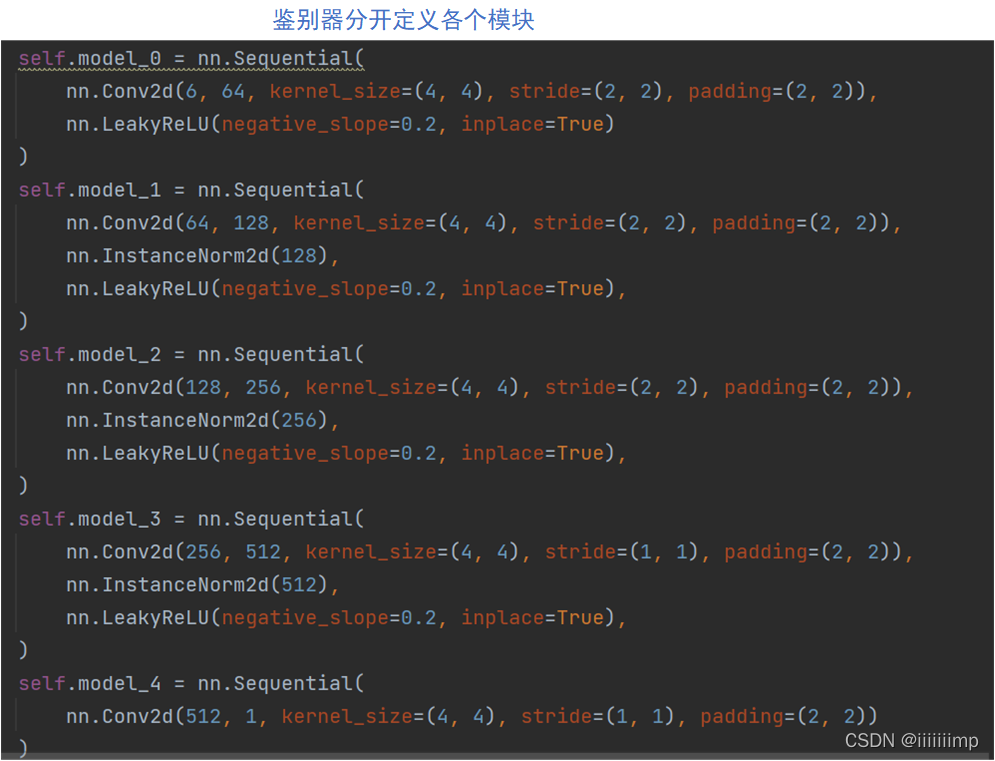

多尺度鉴别器就是在模型中定义两个鉴别器,一个鉴别器原图尺寸输入,另一个做一个平局池化后输入,最后返回的也是两个鉴别器各模块特征图的list
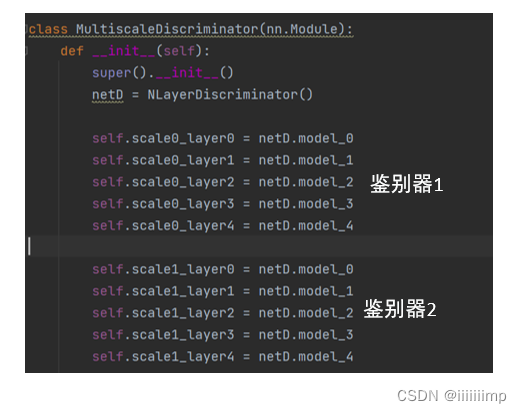
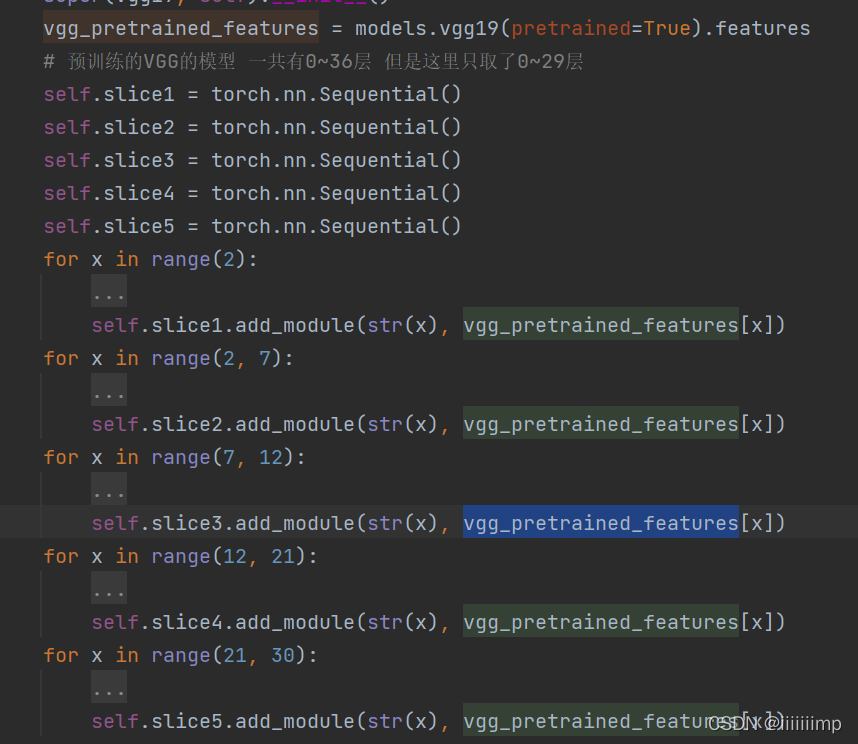
VGG的定义也和鉴别器差不多,从torchvision中得到与训练的VGG模型把他差分层几个模块,forward也是返回的是特征图的list,用于后面计算感受野损失
(U-GAT-IT)U-GAT-IT UNSUPERVISED GENERATIVE ATTENTIONAL NETWORKS WITH ADAPTIVE LAYER- INSTANCE NORMALIZATION FOR IMAGE-TO-IMAGE TRANSLATION
蓝色字代表作者的想法
\color{blue}{ 蓝色字代表作者的想法}
蓝色字代表作者的想法
红色字代表作者的创新
\color{red}{ 红色字代表作者的创新}
红色字代表作者的创新
这篇文章讲的挺好的,我也主要参考了这篇文章的观点。
1、文章的baseline是基于CycleGAN改进的,增加了一个新的注意力机制(CAM)和可学习的归一化函数(Adam)来提升风格迁移效果。
2
、使用
C
A
M
注意力机制来增强风格迁移中重要区域的转换。
\color{red}{2、使用CAM注意力机制来增强风格迁移中重要区域的转换。}
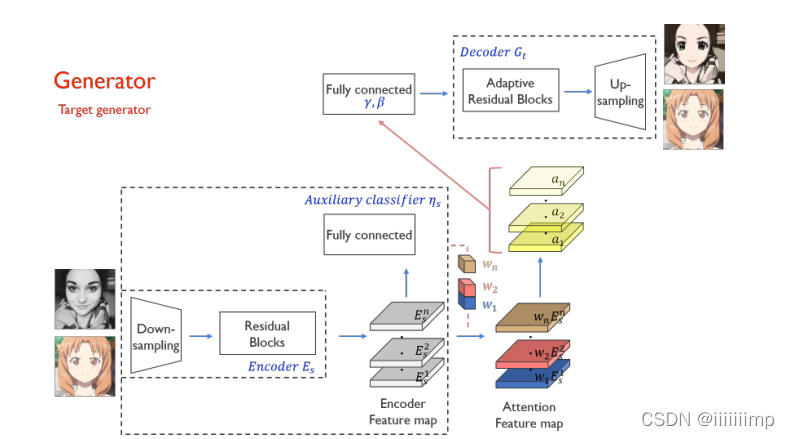
2、使用CAM注意力机制来增强风格迁移中重要区域的转换。 生成器的注意力机制用来判断其来自源域的概率(例如如果是把A转为B的生成器,如果输入为A则其辅助分类器的目标是接近于1,如果输入的是B<因为IdentityLoss>则其辅助分类器的目标是接近于0)。鉴别器的注意力机制是希望真实图片接近于1,伪造图片接近于0,而生成器则希望鉴别器的注意力机制能把伪造图片接近于1。
具体做法就是把就是将经过编码器后得到的特征图进行全局平局池化和全局最大池化,从而得到通道数量的1*1的值,将这些在输入到辅助分类器(全连接)做分类,再把全连接的权重取出来重新乘到经过编码器得到的特征图上,最终得到注意力特征图。
3
、使用
A
d
a
L
I
N
,自适应层实例归一化。
\color{red}{3、使用AdaLIN,自适应层实例归一化。}
3、使用AdaLIN,自适应层实例归一化。 学习一个比例自动调节归一化中IN和LN的比例,从而让模型更灵活的控制图像形状和纹理的变化。
IN和LN都是对一个instance做正则化,而与batch无关,不同在于IN只对一张特征图(即一个通道)做归一化,而LN对所有通道做。因此IN是假设同一instance在同一层得到的不同特征图是无关的,但个人看来还是多少有点关系,因此如果用IN单独作用于每个特征图可能会产生一些对原来语义具有干扰的信息。而LN是对所有特征图进行归一化,这就导致无法较好的保存每个特征图的特性,从而使归一化后会丢失一些信息。因此作者才想能不能把IN和LN两者结合起来,结合两者的优势,抵消相互的不足。
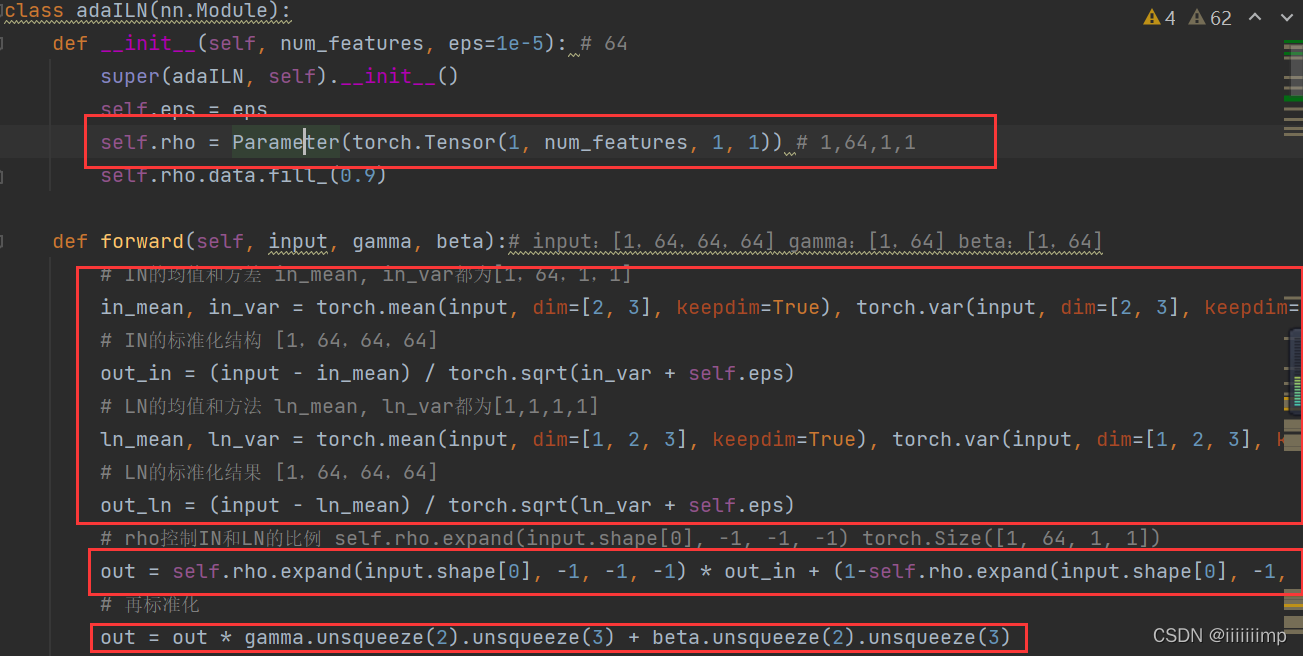
具体做法是将注意力特征图经过一些卷积层后得到的特征图全部一下子拉平输入到2个全连接层中,分别得到γ和β。然后再将这些特征图分别用IN和BN的方式,求出其均值{uI,uL},方差{δI,δL},最后对特征图进行标准化得到{αI,αL},然后用一个可学习参数ρ控制其比例。可以看出ρ接近1则IN重要,ρ接近0则LN重要。ρ在残差模块中初始化为1,在上采样模块中初始化为0(上采样其实用的LIN)
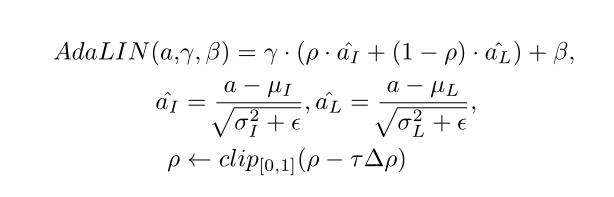
4
、损失上用
L
S
G
A
N
+
C
y
c
l
e
L
o
s
s
+
I
d
e
n
t
i
t
y
L
o
s
s
+
C
A
M
L
o
s
s
。
\color{red}{4、损失上用LSGAN+CycleLoss+IdentityLoss+CAMLoss。}
4、损失上用LSGAN+CycleLoss+IdentityLoss+CAMLoss。 CycleLoss是为了缓解模式崩塌。IdentityLoss是保护颜色的一致性。CAMLoss是告诉G和D两个域之间最大的差别。注意的是CAMLoss中,生成器的CAMLoss用的是BCELoss,其他的都是MSELoss。
但是我不理解,为什么生成器的CAMLoss要用BCELoss?而且为什么要让输入源域时接近于1,输入目标域时接近于0.
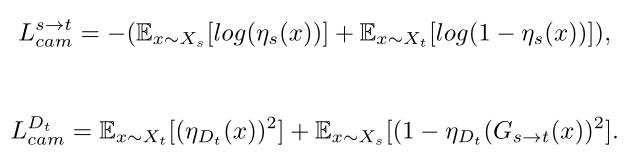
5
、为什么要
A
d
a
L
I
N
?
\color{blue}{5、为什么要AdaLIN?}
5、为什么要AdaLIN? 作者在实验中发现如果在生成器中全使用IN的话(c),那么在之前编码阶段的残差模块使用IN所保留下来的耳环和颧骨周围的阴影等特征就并不能在上采样中的IN层被捕获到这些全局特征,这也就导致了风格迁移量并不多。
但是如果 (d)在生成器中都使用LN的话,虽热风格迁移量是多了,但是残差模块中使用LN会导致源域的一些信息不能像IN那样被保留。
这就告诉了我们其实在编码阶段,其实IN比LN要重要些,因为IN能更好的保留源域的信息,但是在上采样阶段进行风格迁移时,LN就比IN重要了。
因此作者就想到用AdaLIN来在解码阶段自动的调节IN和LN的比例,从而更好的进行风格迁移。

6
、用
K
I
D
做评价指标。
\color{blue}{6、用KID做评价指标。}
6、用KID做评价指标。
7 、 I N 在风格迁移中比 B N 和 L N 中用的更多。 \color{blue}{7、IN在风格迁移中比BN和LN中用的更多。} 7、IN在风格迁移中比BN和LN中用的更多。
8、代码:https://github.com/hahahappyboy/GAN-Thesis-Retrieval/tree/main/U-GAT-IT
参考了官方代码
CAM是把经过下采样和Res模块后得到的特征r3[1,64,64,64](NCHW),进行全局平局池化和全局最大池化得到2个通道维度数量的向量[1,64,1,1],再将这个向量拉平后送入64->1的FC层,从而得到两个11的值gap_logit和gmp_logit,然后将FC的权重取出来乘到r3上得到注意力图gap和gmp,经过通道合并后送入11卷积将通道还原。
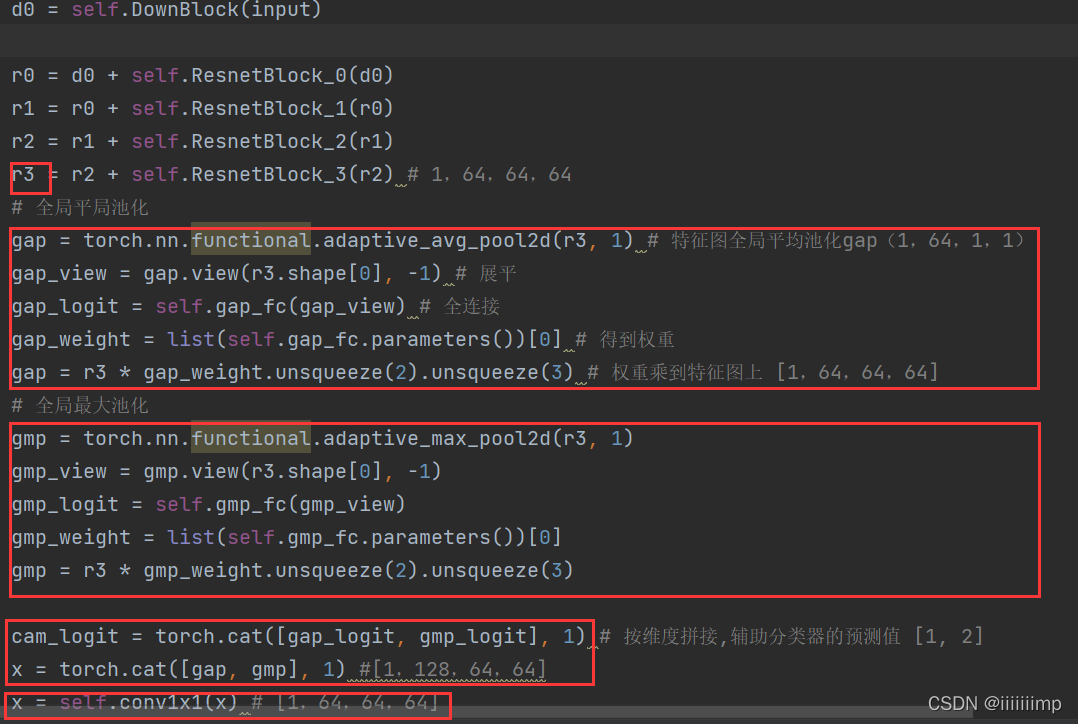
AdaLIN是将CAM得到的注意力特征图直接拉平x_送入全连接self.gamma和self.beta得到AdaLIN参数gamma和beta,再送给上采样模块。
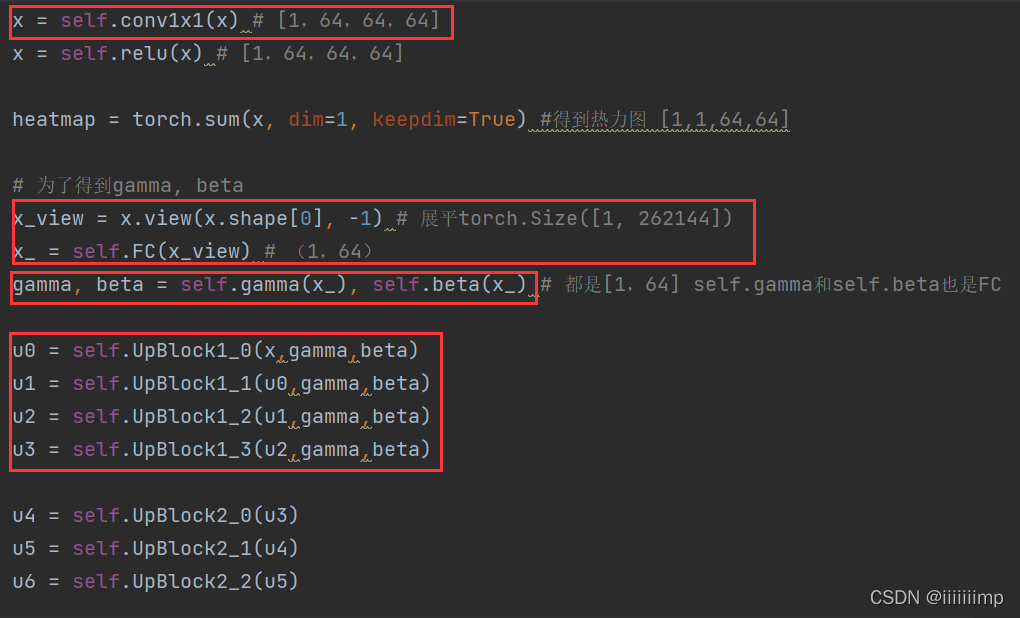
AdaLIN中可学习参数为rho[1,64,1,1],计算注意力特征图的IN[1,64,64,64]和LN[1,64,64,64],然后用rho控制其占比,最终用之前全连接得到的参数参数gamma和beta再标准化一次
CAMLoss中注意,鉴别器的希望真实图片在辅助分类器中的得分越接近于1越好,希望伪造图片在辅助分类器的得分越接近于0越好,并且用的是MSELoss。
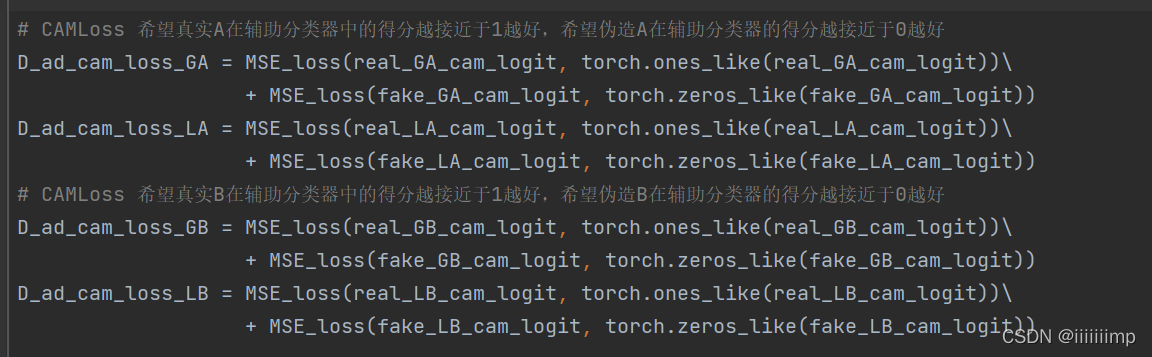
生成器希望生成的伪造图在判别器的辅助分类器得分越接近1越好,并且还希望生成器输入为源域时A2A或B2B<IdentityLoss需要>其辅助分类器接近于0,输入为目标域时A2B或B2A接近于1,并且用的是BCELoss。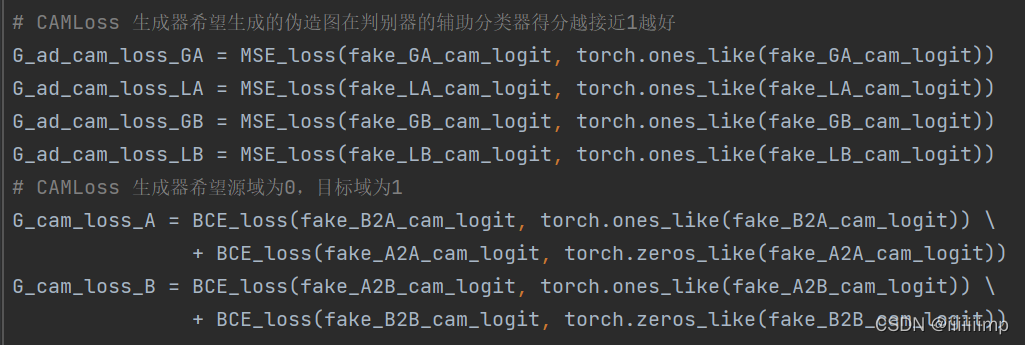
(CAM)Learning Deep Features for Discriminative Localization
蓝色字代表作者的想法
\color{blue}{ 蓝色字代表作者的想法}
蓝色字代表作者的想法
红色字代表作者的创新
\color{red}{ 红色字代表作者的创新}
红色字代表作者的创新
因为U-GAT-IT用到了CAM,所以这里大概看了一些CAM的论文
1 、 C N N 的各,层的卷积单元实际是物体检测器。 \color{blue}{1、CNN的各,层的卷积单元实际是物体检测器。} 1、CNN的各,层的卷积单元实际是物体检测器。 因为经过卷积后产生的特征图会有高亮的地方,这些高亮的地方就表示输入图片与卷积核的特征匹配上了,经过卷积的加权求和从而产生了高亮区域。因此这些区域可以用于定位。但是经过全连接过后由于会把特征图展平,因此这种位置信息就会消失。
2 、用全局平均池化。 \color{red}{2、用全局平均池化。} 2、用全局平均池化。 因为全局平均池化(GAP)会涉及到整张特征图的值,所有低激活值也会影响输出,而全局最大池化(GMP)除了最具辨别性的特征区域以外,所有特征区域的低分不会影响最后结果。换句话说GAP会鼓励网络识别对象的整体,而GMP则鼓励网络关注对象的一个部分。因此作者选择在CAM中使用GAP。
3 、 C A M 。 \color{red}{3、CAM。} 3、CAM。 假设卷积后的特征图为[1,3,64,64]即3张6464大小的特征图,经过全局平局池化得到[1,3,1,1]的特征,即把6464的特征图去加起来求平均值。然后拉平为[1,3]经过一个全连接层(3->1),得到1个值,这个值就是物体类别Astralian terrier的得分。最后把全连接的权重取出来[1,3]乘到特征图[1,3,64,64]上去得到CAM[1,3,64,64 ]。
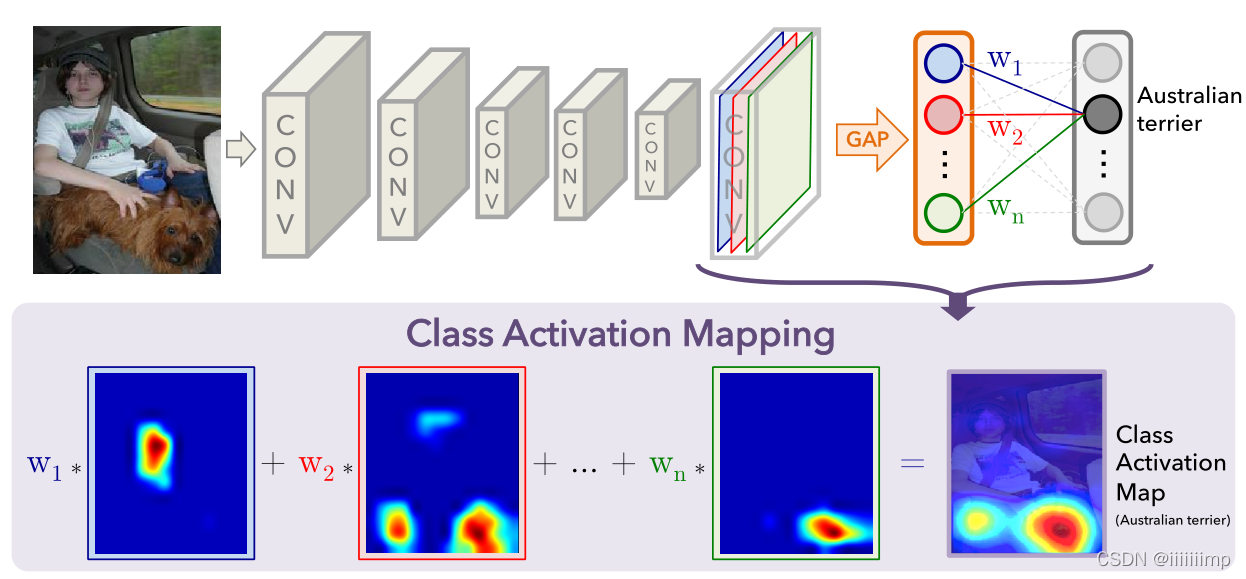 CAM简单来说就是不同空间区域的线性加权可视化。将CAM图Resize为输入图片大小就能清楚看出网络认为是某类物体时所看重的相关区域。如其下图,如果网络认为是狗的依据是通过看到狗头来判断的。
CAM简单来说就是不同空间区域的线性加权可视化。将CAM图Resize为输入图片大小就能清楚看出网络认为是某类物体时所看重的相关区域。如其下图,如果网络认为是狗的依据是通过看到狗头来判断的。
(Hourglass)Stacked Hourglass Networks for Human Pose Estimation
蓝色字代表作者的想法
\color{blue}{ 蓝色字代表作者的想法}
蓝色字代表作者的想法
红色字代表作者的创新
\color{red}{ 红色字代表作者的创新}
红色字代表作者的创新
因为photo2cartoon)用到了Hourglass来增强模型,所以这里大概看了一下Hourglass的论文
1、HouGlass本来是用来做姿态估计的,主要贡献在于利用多尺度特征来识别姿态。以前估计姿态的网络结构,大多只使用最后一层的卷积特征,这样会造成信息的丢失。
2
、
H
o
u
r
G
l
a
s
s
模块结构。
\color{red}{2、HourGlass模块结构。}
2、HourGlass模块结构。
像FCN那种网络结构,更注重编码阶段,而在解码阶段不太注重,因为FCN将更多的层数放在了编码阶段。
但作者用了对称的结构,即编码和解码层数相同。
下图,每个白框都是一个残差模块。整个网络有点像Unet的形式,只不过把Unet的卷积模块换为了残差模块,以及在跳跃连接上加了残差模块。
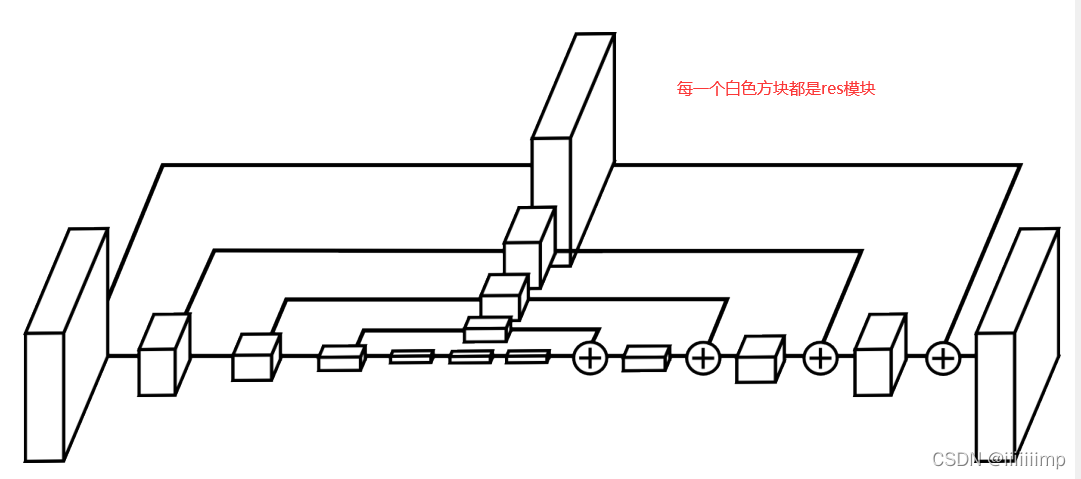
残差模块如下
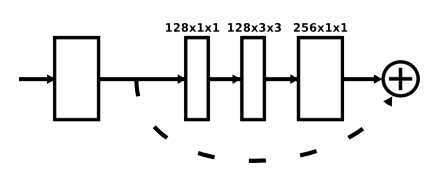
整个网络是串联起来的,一个HourGlass接了另一个HourGlass,这是为了反复评估全局特征和局部特征,因为作者认为姿态估计是如果在一个HourGlass中如果出错了还能在之后的HourGlass中纠正回来。
蓝色区域是热力图,是通过1*1卷积改变通道得来的,可以用于计算loss。
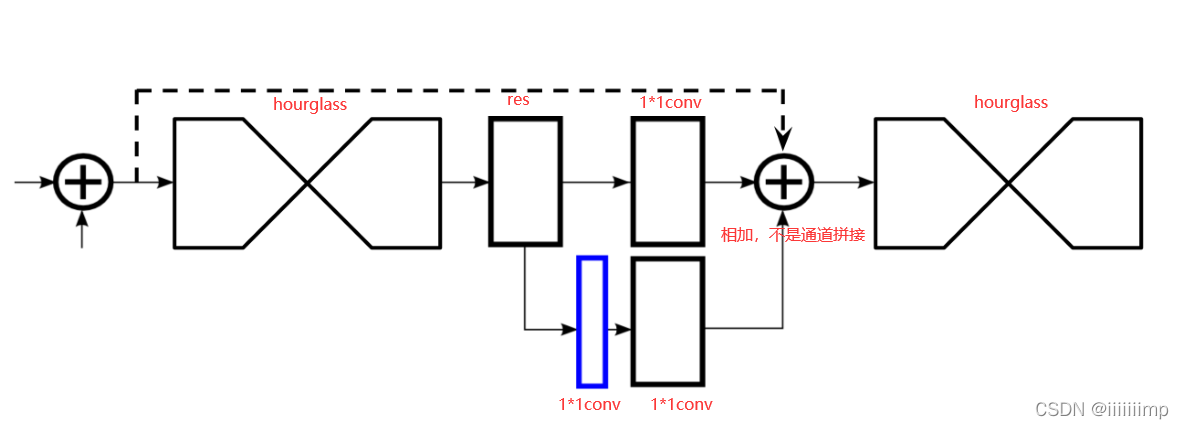
3 、小卷积核比大卷积更能捕捉更大的空间上下文信息。 \color{blue}{3、小卷积核比大卷积更能捕捉更大的空间上下文信息。} 3、小卷积核比大卷积更能捕捉更大的空间上下文信息。 例如使用2个独立的33卷积来替换5%卷积。
8、代码:https://github.com/hahahappyboy/GAN-Thesis-Retrieval/tree/main/HourGlass
参考了photo2cartoon的Hourglass代码
残差模块其实用的是Inception结构
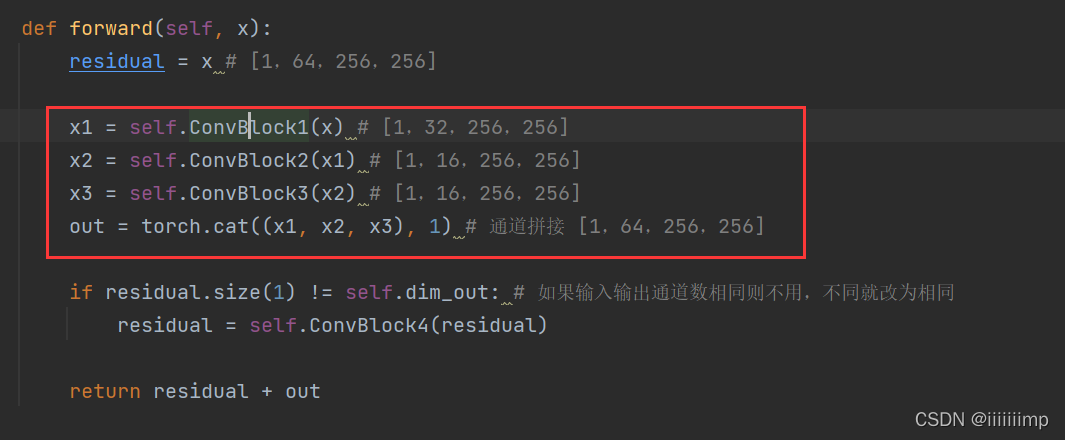
HourGlass模块的特征一个经过残差模型用于之后的跳跃连接,另一个经过池化后继续下采样编码。
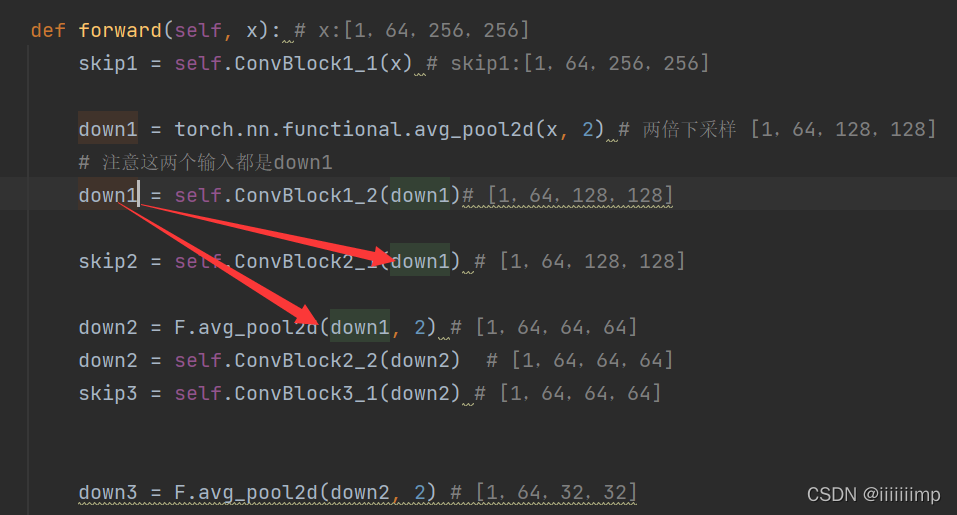
(photo2cartoon)Few-shot Knowledge Transfer for Fine-grained Cartoon Face Generation
蓝色字代表作者的想法
\color{blue}{ 蓝色字代表作者的想法}
蓝色字代表作者的想法
红色字代表作者的创新
\color{red}{ 红色字代表作者的创新}
红色字代表作者的创新
这篇文章是在U-GAT-IT基础上进行改进的,是为了解决少样本人像卡通画的问题。
1
、以前人像卡通画遇到的问题。
\color{blue}{1、以前人像卡通画遇到的问题。}
1、以前人像卡通画遇到的问题。 以前的卡通画并没有考虑到人年龄的问题,例如女生照片有大眼睛,而男生不会有,老人有皱纹,而儿童没有。并且不同年龄的训练样本还不平衡,年轻女性的样本多,其他年龄组的样本少。
2 、 p h o t o 2 c a r t o o n 基础模型。 \color{red}{2、photo2cartoon基础模型。} 2、photo2cartoon基础模型。 作者的基础模型是在U-GAT-IT上面进行改进的,主要是在U-GAT-IT生成器上加了四个hourglass,loss增加了Face-IDloss,使用了Soft-AdaIN归一化。
3 、编码器的底层和解码器的上层特征不共享,而编码器的上层和解码器的低层特征不共享。 \color{blue}{3、编码器的底层和解码器的上层特征不共享,而编码器的上层和解码器的低层特征不共享。} 3、编码器的底层和解码器的上层特征不共享,而编码器的上层和解码器的低层特征不共享。 这是在One-Shot Unsupervised Cross Domain Translation中提到。并且作者在发现用小样本训练模型容易造成网络过拟合,但如果固定那些共享特征层不backward的话,就会提升效果。
4
、网络结构。
\color{red}{4、网络结构。}
4、网络结构。
样本分组 0组:年轻女性 1组:年轻男性 2组:小孩 3组:老人
只有训练第0组时才会更新红框的部分,训练1、2、3组都不会更新。

5
、损失函数。
\color{red}{5、损失函数。}
5、损失函数。
GANLoss用的LSGAN
CycleLoss为了避免模式崩塌
IdentityLoss保证颜色
CAMLoss让模型找到两个域最大的不同
FaceIDLoss保证真实人脸和卡通人脸的一致性,F为与训练的人脸识别模型
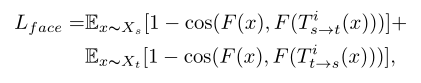
Group classification Loss,这个loss放在D的最后一层,判断是哪个组的,估计是为了更加好的帮助生成器区分不同组吧。
(ViT)AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
蓝色字代表作者的想法
\color{blue}{ 蓝色字代表作者的想法}
蓝色字代表作者的想法
红色字代表作者的创新
\color{red}{ 红色字代表作者的创新}
红色字代表作者的创新
Transformer已经统一了NLP,但是在CV中的应用还是很少,并且CV中Attention结构更多的是对Conv的一种补充来使用。因此作者就想能不能用纯Transformer的结构做图像分类,并且尽可能的不修改其结构。
1
、
V
i
T
模型结构。
\color{red}{1、ViT模型结构。}
1、ViT模型结构。
(1)我们假设,输入的图像为[1,3,256,256]。然后把其拆分成8 * 8=64个patch,每个patch为32 * 32大小,通道为3,则得到[1,8 * 8,32 * 32 * 3]即[1,64,3072]的数据。
(2)送入全连接,全连接(图中的Linear Projection of Flattened Patches部分)为3072->1024,因此得到[1,64,1024]的Patch embedding。
(3)加入类别向量[1,1,1024]与上一步的Patch embedding构成了[1,65,1024]。
(4)加入Position Embedding。将一个可学习的位置向量[1,65,1024],将其加到(3)中的[1,65,1024]向量中得到一个新的向量[1,65,1024],这就是Embedded Patches。
(5)将Embedded Patches[1,65,1024]送入L个Transfomer Encoder中经过一系列的层归一化+多头注意力机制+跳跃连接等,得到[1,65,1024]的输出。
(6)取出第一个向量[1,1,1024]将其经过一个1024->num_class的MLP得到[1,1,num_clas]的向量即为分类结果。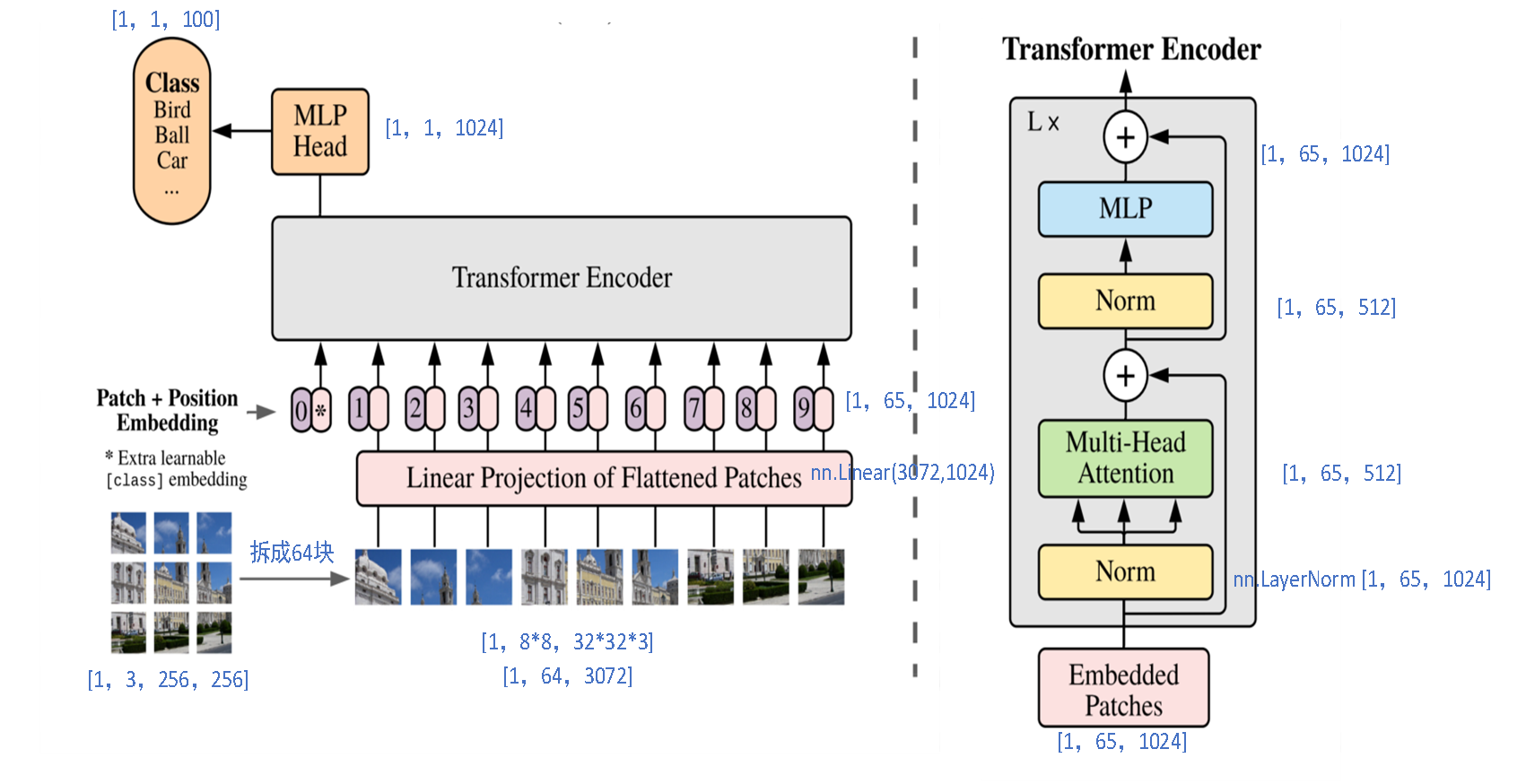
2 、为什么要加类别向量。 \color{red}{2、为什么要加类别向量。} 2、为什么要加类别向量。 假设不加类别向量,那么就是将[1,64,1024]的向量送入Transformer Encoder中去,最后Transformer Encode输出也是[1,64,1024],我们知道自注意力机制会让输入向量中的每个向量去考虑另外的每个向量,那么问题来了最后输出的64个1024向量到底用哪一个向量送入分类的MLP呢?显然用哪一个都不合适,因此作者就想到人为添加一个可学习的类别向量,让该向量去参考其他64个向量,然后去这个向量作为类别预测的输入。
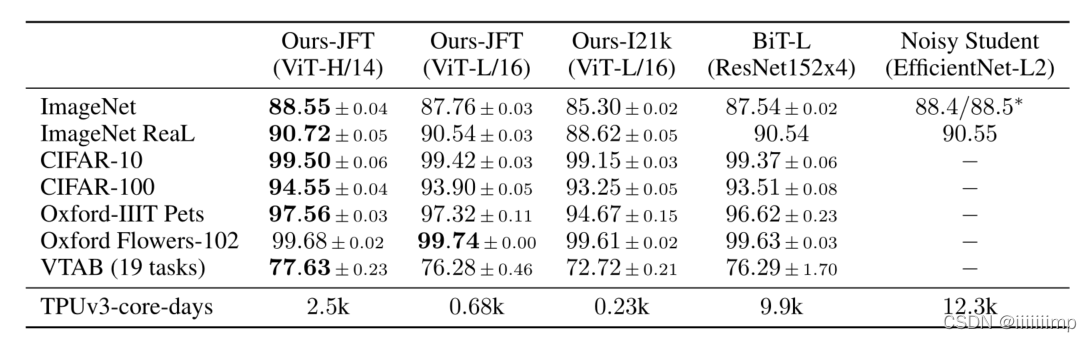
3 、经过大数据集预训练在迁移到小数据集上 V i T 效果能超过 C N N 的 S O T A \color{blue}{3、经过大数据集预训练在迁移到小数据集上ViT效果能超过CNN的SOTA} 3、经过大数据集预训练在迁移到小数据集上ViT效果能超过CNN的SOTA
4
、小数据集预训练后
V
i
T
不如
B
i
T
。
\color{blue}{4、小数据集预训练后ViT不如BiT。}
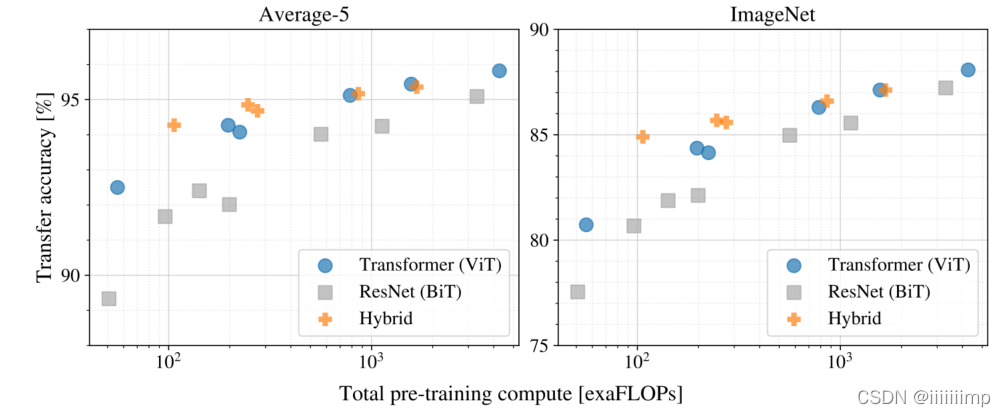
4、小数据集预训练后ViT不如BiT。 在小数据集上预训练的ViT结果不如基于ResNet的BiT,在中数据集上两者差不多,只有在大数据上预训练后效果才优于BiT。
5
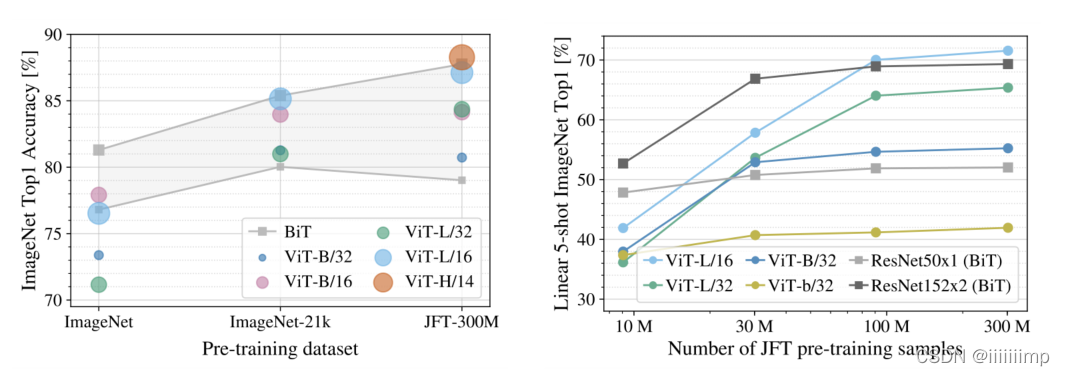
、预训练数据要求。
\color{blue}{5、预训练数据要求。}
5、预训练数据要求。 在相同的预训练量下ViT效果优于BiT。混合模型(Transformer+CNN)在预训练epoch少的情况下优于ViT。
6
、
P
o
s
i
t
i
o
n
e
m
b
e
d
d
i
n
g
能自己学习到位置特征。
\color{blue}{6、Position embedding能自己学习到位置特征。}
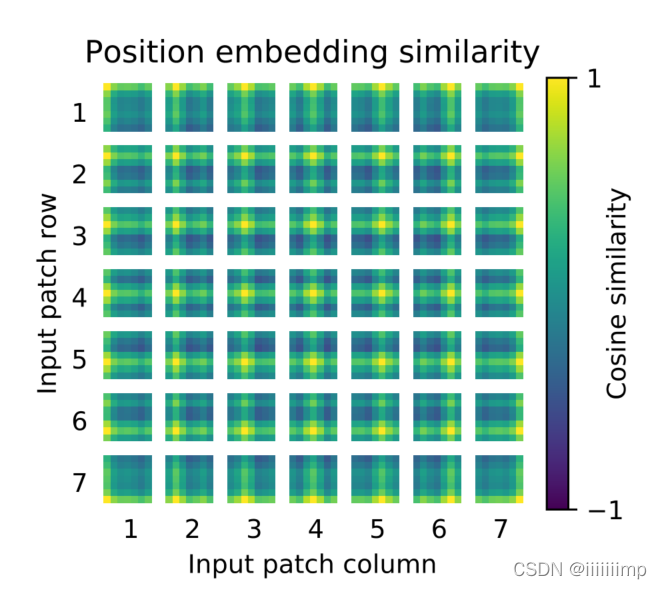
6、Positionembedding能自己学习到位置特征。 可以看到随机初始化的Position embedding学习到了2D图像的位置信息,所以说就不需要使用2D的Position embedding而用1D的就行,也不用人工设计Position embedding。
7
、
V
i
T
的第
0
层就已经能获得全局信息。
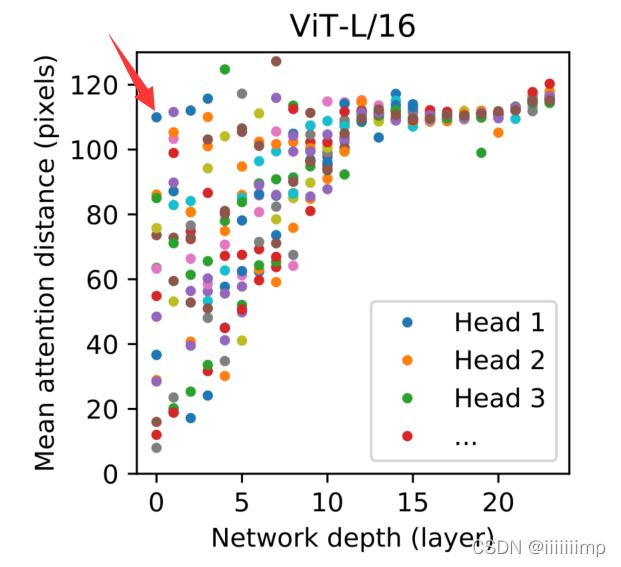
\color{blue}{7、ViT的第0层就已经能获得全局信息。}
7、ViT的第0层就已经能获得全局信息。 ViT网络的第0层就已经能获得全局信息,并且随着层数增加获得全局信息的感受野也越多,这在CNN中第0层是无法实现的。
8、代码:https://github.com/hahahappyboy/GAN-Thesis-Retrieval/tree/main/ViT
参考了的代码
(1)把[1,3,256,256]的图片拆分成64个patch得到[1,8 * 8, 32 * 32 * 3],然后经过 Liner Projection of Flattened Patches把32 * 32 * 映射为1024得到[1,64,1024]

(2)用self.cls_token = nn.Parameter(torch.randn(1, 1, dim))生成类别patch[1,1,1024]与(1)的[1,64,1024]按通道拼接得到[1,65,1024]的Patch Embedding

(3)用self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, dim))生成[1,65,1024]大小的Position Embedding直接加到Patch Embedding上得到[1,65,1024]的Embeded Patches,因为Liner Projection of Flattened Patches是MLP所以又加了个dropout层

(4)在Transformer中先用nn.LayerNorm(dim)对[1,65,1024]的Embeded Patches进行归一化然后送入全连接 self.to_qkv = nn.Linear(dim, inner_dim * 3, bias = False)中得到q、k、v [1,65,512]再用rearrange将其reshape为矩阵形状[1,8,65,64],其中8为head的个数。
(5)按照如下公式进行点积得到
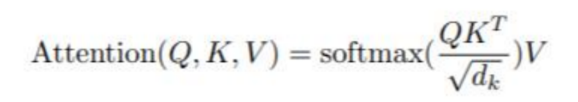

(6)将点积后的结果(多个heads的)concat到一起在经过一个全连接,这是为了使得多个head的信息进行交互并且把维度转为最初的1024维,所以最终输出为[1,65,1024]。

(PVT)Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions
蓝色字代表作者的想法
\color{blue}{ 蓝色字代表作者的想法}
蓝色字代表作者的想法
红色字代表作者的创新
\color{red}{ 红色字代表作者的创新}
红色字代表作者的创新
1
、
V
i
T
不适合做下游任务。
\color{blue}{1、ViT不适合做下游任务。}
1、ViT不适合做下游任务。ViT对于识别效果很好,但是其在物体检测、语义分割和实例分割上其实是不适合的。原因是因为ViT是柱形结果,其输入是多大输出就是多大,但对于那种需要结合多种尺度特征来进行预测的任务(如分割FPN)就不太适用。另外像分割这种任务往往需要你切分的patch越小越好(因为可以更精细的预测),但是这是不现实的,因为显存不够,所以往往大家都采用32 * 32或16 * 16的patch。为了解决这个问题,作者提出了PVT。
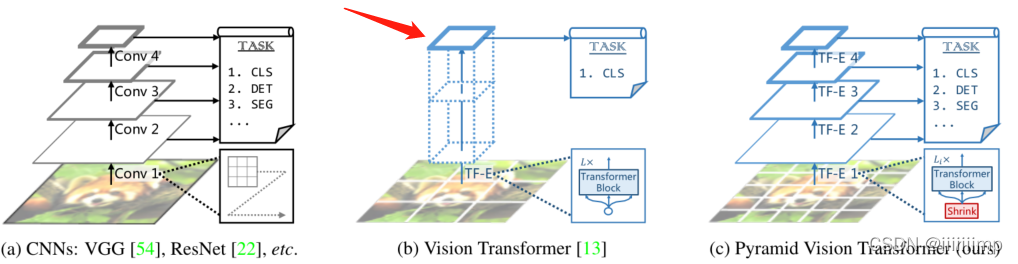
2
、
P
V
T
网络结构。
\color{red}{2、PVT网络结构。}
2、PVT网络结构。
(1)将H * W * 3的图片划分为(H * W)/(P * P)块,每块的大小就是P * P * C,即维度为[(H/P,W/P, P * P * C]。
(2)经过Patch Embedding。里面有个全连接将P * P * C映射为C1维,得到[(H/P,W/P, C1]的数据。然后在经过一个norm,维度是不变的。
(3)将[(H/P,W/P, C1]的数据reshape为[(H * W)/(P * P), C1]的数据并加入位置信息(同ViT一样),维度不变还是[(H * W)/(P * P), C1]。
(4)经过Transomer Encoder后输出为[(H * W)/(P * P), C1],最后reshape为[H/P,W/P, C1]。这样特征图就从[H,W, C]变为了[H/P,W/P, C1]。
这是PTV减小参数量的第一个原因。

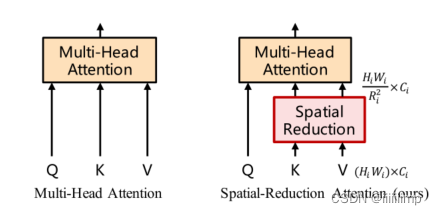
3
、
S
R
A
结构。
\color{red}{3、SRA结构。}
3、SRA结构。 这是PTV能减小参数量的第二原因。因为self-attention中的Q、K、V是相当大的,并且每一给patch都有一个Q、K、V,这就很占显存。因此作者想到了减少K、V的大小来降低显存。
假设输入的x维度为[H * W,C],ViT是将其分别与Wq、Wk、Wv相乘得到Q、K、V然后送入多头注意力机制。但是这样需要的Q和V的维度就特别大,Q点乘V的计算也更耗时,最后生成的注意力特征图的维度也特别大。
因此作者就先将维度为[H * W,C]的K和Vreshape为[(H * W )/ (R * R),(R * R) * C]大小,然后通过一个全连接将R * R * C维映射到C维上,之后再经过一个LN,就得到了[(H * W )/ (R * R),C]维度的Q和V,之后才送入多头注意力机制,从而实现了降低K、V的大小来减小显存消耗以及计算耗时。
(AdaIN)Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization
蓝色字代表作者的想法
\color{blue}{ 蓝色字代表作者的想法}
蓝色字代表作者的想法
红色字代表作者的创新
\color{red}{ 红色字代表作者的创新}
红色字代表作者的创新
因为StyleGAN会用到AdIN,所以这里大概总结一下AdaIN
1
、
B
N
会抑制风格迁移。
\color{blue}{1、BN会抑制风格迁移。}
1、BN会抑制风格迁移。
γ和β是可学习参数,BN是所有batch的同一个通道进行归一化
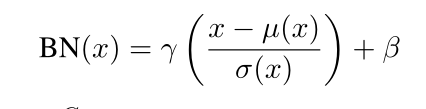
2
、
I
N
在风格迁移中比
B
N
更能提升效果。
\color{blue}{2、IN在风格迁移中比BN更能提升效果。}
2、IN在风格迁移中比BN更能提升效果。
IN是一个batch的每一个通道单独做归一化
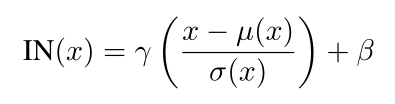
3
、风格迁移中用
I
N
比用
B
N
的模型
L
o
s
s
下降更快
\color{blue}{3、风格迁移中用IN比用BN的模型Loss下降更快}
3、风格迁移中用IN比用BN的模型Loss下降更快
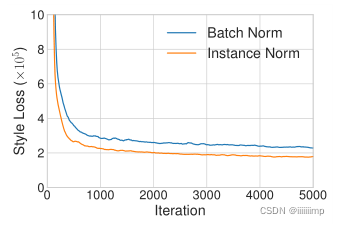
4
、
I
N
和
B
N
都只能进行一种风格迁移
\color{blue}{4、IN和BN都只能进行一种风格迁移}
4、IN和BN都只能进行一种风格迁移
5
、
A
d
a
I
N
\color{red}{5、AdaIN}
5、AdaIN
x为内容图像的编码特征图,y为风格图像的编码特征图。其实就是将x减去均值除以方差来去除x本身的风格信息,然后再乘上y的方差,加上y的均值,从而转变为y的风格
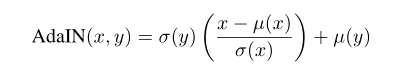
5
、损失函数
\color{red}{5、损失函数}
5、损失函数
分为风格损失Ls和内容损失Lc
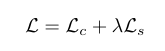
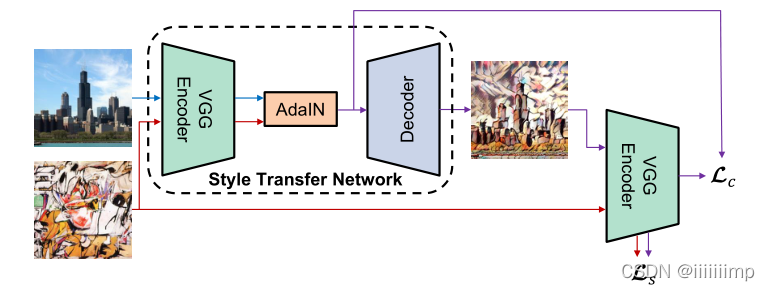
内容损失就是将AdaIN输出的特征图t与最后Decoder(g)后生成的图片再经过一次VGGEncoder(f)后得到的特征图f(g(t))计算欧式距离
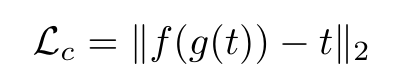
风格损失就是将模型输入的风格图s与Decoder后生成的图片再经过VGGEncoder,将VGGEncoder的某些层特征图拿出来计算欧式距离。
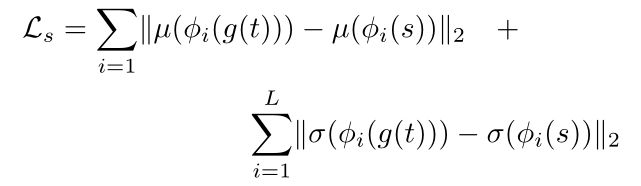
6、代码:https://github.com/hahahappyboy/GAN-Thesis-Retrieval/tree/main/AdaIN
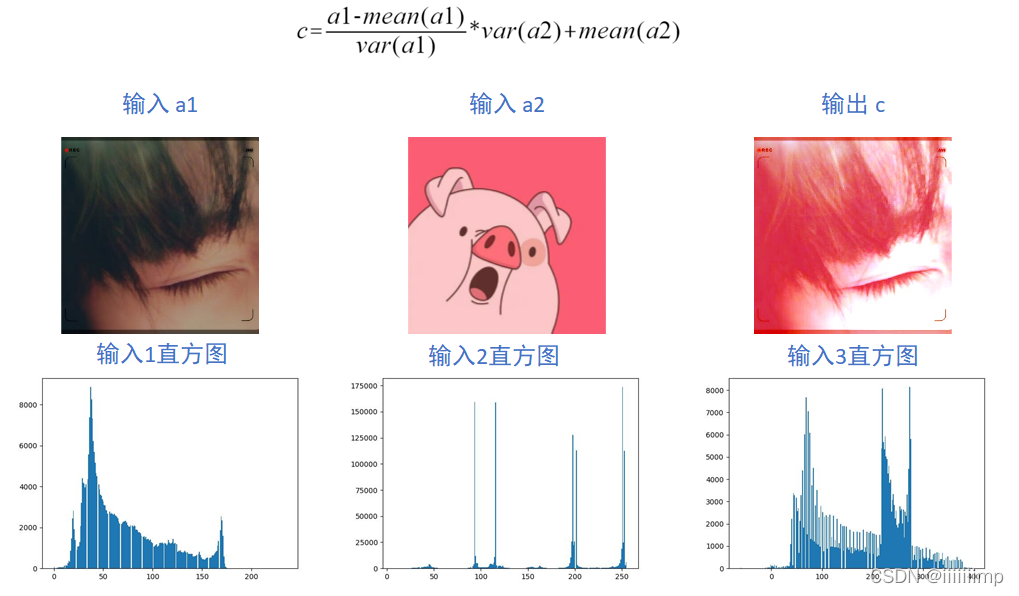
代码比较简单就是一input1减去均值除以方差再乘上input2的方差加均值

可以看到adaIN后a1的整体色调和亮度变成了a2的了,因为adaIN把a1的数据分布转化为a2的数据分布了。
(TransGAN)TransGAN Two Pure Transformers Can Make One Strong GAN, and That Can Scale Up
蓝色字代表作者的想法
\color{blue}{ 蓝色字代表作者的想法}
蓝色字代表作者的想法
红色字代表作者的创新
\color{red}{ 红色字代表作者的创新}
红色字代表作者的创新
1
、卷积的不足。
\color{blue}{1、卷积的不足。}
1、卷积的不足。 卷积是局部感受野,不能得到全局信息,除非通过充足的层数。但更深的层数就容易导致细节的丢失。
2 、纯 t r a n s f o r m e r 在分类任务上效果很好,但在图像生成任务上却不一定。 \color{blue}{2、纯transformer在分类任务上效果很好,但在图像生成任务上却不一定。} 2、纯transformer在分类任务上效果很好,但在图像生成任务上却不一定。
3
、内存友好生成器。
\color{red}{3、内存友好生成器。}
3、内存友好生成器。
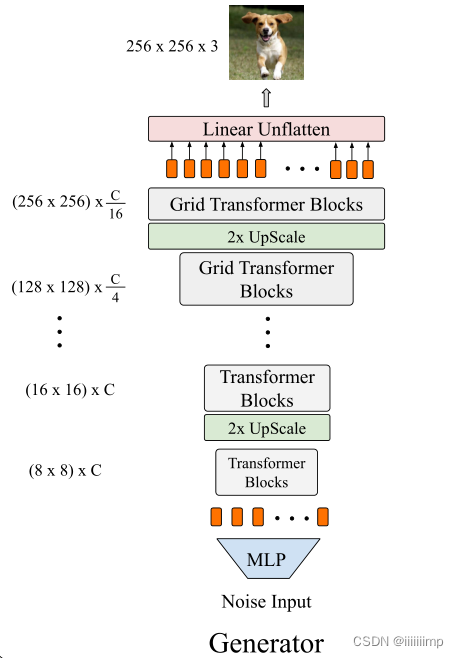
如果通过堆叠transformer编码器以逐像素的方式生成图像,会容易导致显存爆炸,因此作者想即使用transfomer结构又不想显存爆炸,所以提出了该模型。
(1)先通过MLP把随机噪声生成[64,C]大小的序列然后加上可学习的位置信息维度不变,还是[64,C]。
(2)经过transformer模块,维度还是[64,C]
(3)经过上采样模块,对于低分辨率特征图(分辨率在64 * 64 以下的),采样的双三次线性插值,先把[64,C],reshape为2D的[8,8,C],然后插值为[16,16,C],最后再reshape为[16 * 16,C],送入下一个transformer模块
(4)这样一直持续到特征图大小为[64 * 64,C],之后上采样模块就用pixelshuffle模块了,pixelshuffle其实就是把特征图重排列,如把[C * R * R,H,W]reshape为[C,H * R,W * R]。这里为了与下图对应,拿特征图为[128 * 128,C/4]举例。先reshape为[128,128,C/4],用pixelshuffle变为[256,256,C/16],最后再resahpe回[256 * 256,C/16]的向量。
(5)最后一层是把[256 * 256,C/16]的向量送入MLP映射为[256 * 256,3],最后reshape为[256,256,3],得到小狗的图片
4
、多尺度鉴别器。
\color{red}{4、多尺度鉴别器。}
4、多尺度鉴别器。
作者在切分patch送入鉴别器时,patch大了会牺牲纹理细节,小的patch会导致更长的序列,从而小号更多的内存,因此设计了多尺度鉴别器。
(1)先把[H,W,3]的图片reshape为[(H/P) * (H/P),P * P * 3]的向量然后MLP为[(H/P) * (H/P),C/4]的向量,然后加上位置信息。
(2)[(H/P) * (H/P),P * P * 3]的向量reshape为[(H/P),(H/P),C/4]再平均池化为[(H/2P),(H/2P),C/4]再reshape为[(H/2P) * (H/2P),C/4]的向量。
(3)把输入图[H,W,3]reshape为[(H/2P) * (H/2P),4 * P * P * 3],然后经过MLP映射为[(H/2P) * (H/2P),C/4]的向量
(4)把(2)中得到的[(H/2P) * (H/2P),C/4]的向量与(3)得到的[(H/2P) * (H/2P),C/4]向量拼接到一起得到[(H/2P) * (H/2P),C/2]的向量送入下一个tranformers模块,这一步是为了让模型又有语义细结构又具有纹理细节。
(5)再最后一个transformer模块的输入加入类别向量,拿该向量对应的的输出去做分类。
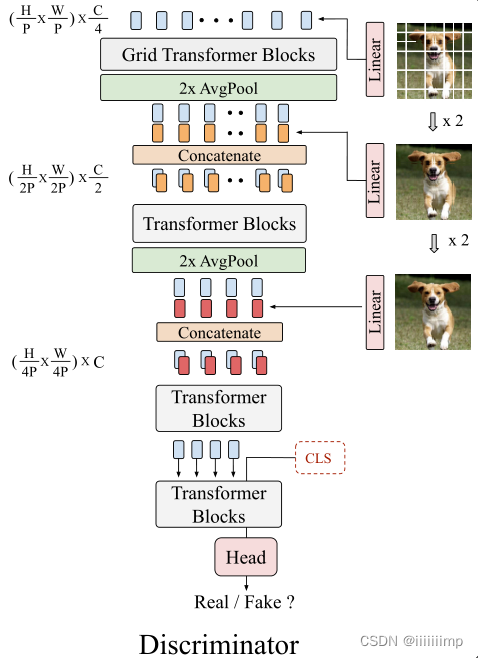
5
、
G
r
a
i
d
S
e
l
f
−
a
t
t
e
n
t
i
o
n
。
\color{red}{5、Graid Self-attention。}
5、GraidSelf−attention。
Self-attention虽然可以捕捉全局的信息,但是内存消耗实在太大了,如果输入图像分辨率高就不行了。
Graid Self-attention就是把特征图分为几块,分别用Self-attention,这样就降低了内存消耗。
Graid Self-attention会导致各个分割块之间信息无法直接交互从而导致块的边界无法衔接。但是实际上在足够多的训练时间下,这种情况会逐渐消失,这是因为鉴别器的感受野是覆盖了整张图片的,从而指导生成器去消除这种边界影响。
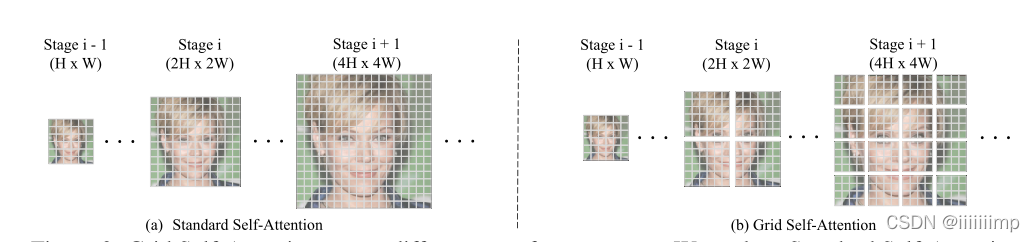
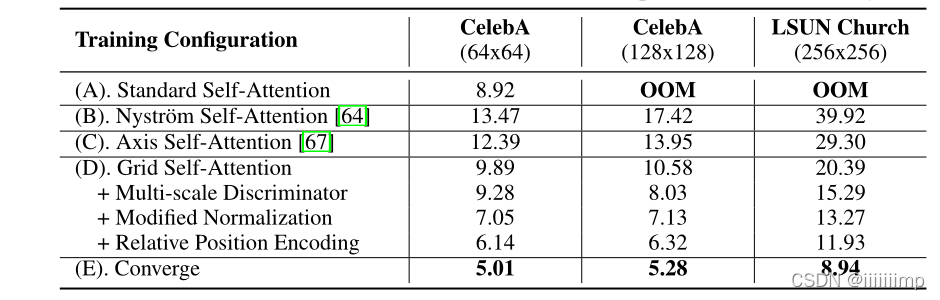
6
、作者还用了一系列方法来提高
G
A
N
的稳定性,可惜我看不懂。
\color{red}{6、作者还用了一系列方法来提高GAN的稳定性,可惜我看不懂。}
6、作者还用了一系列方法来提高GAN的稳定性,可惜我看不懂。
7
、作者评价指标用
I
S
和
F
I
D
,并且在消融实验中,逐渐增加每一项创新,来查看提升结果。
\color{blue}{7、作者评价指标用IS和FID,并且在消融实验中,逐渐增加每一项创新,来查看提升结果。}
7、作者评价指标用IS和FID,并且在消融实验中,逐渐增加每一项创新,来查看提升结果。这一点可以借鉴
(Perceptual Loss)Perceptual Losses for Real-Time Style Transfer and Super-Resolution
蓝色字代表作者的想法
\color{blue}{ 蓝色字代表作者的想法}
蓝色字代表作者的想法
红色字代表作者的创新
\color{red}{ 红色字代表作者的创新}
红色字代表作者的创新
1 、使用逐像素求差的损失函数无法抓住两幅图像在视觉上存在的差异。 \color{blue}{1、使用逐像素求差的损失函数无法抓住两幅图像在视觉上存在的差异。} 1、使用逐像素求差的损失函数无法抓住两幅图像在视觉上存在的差异。 作者认为使用逐像素求差的损失函数是无法捕获输出与标签之间的视觉感知上的差异的。例如考虑两张一摸一样的图像,只有1像素偏移上的擦会议,尽管从人类视觉感知上这两幅图片是一摸一样的,但如果使用逐像素求差的方法来衡量,这两幅图像就会非常不一样。
2
、感受野损失。
\color{red}{2、感受野损失。}
2、感受野损失。
这里只介绍特征重构损失,在风格迁移中也主要使用这个损失。另一个风格重构损失,我看不懂。。。
特征重构损失其实就是让两幅图像ŷ和y经过网络后,在某些层得到的特征图计算MSE误差
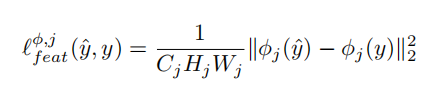
作者发现找到一个图像ŷ使较低层的特征损失最小化往往能产生视觉上和y不太能区分清楚的图像,如果用高层特征来计算特征损失最小化,那么生成的图片内容和全局结果会被保留下来,但是颜色纹理和精确的形状就不复存在了。

(Pix2PixHD改进)采用pix2pixHD的高分辨率皮肤镜图像合成方法
蓝色字代表作者的想法
\color{blue}{ 蓝色字代表作者的想法}
蓝色字代表作者的想法
红色字代表作者的创新
\color{red}{ 红色字代表作者的创新}
红色字代表作者的创新
作者对Pix2PixHD进行了些许改进以便其生成更好的皮肤镜图像来扩充样本,最终提升分割网络的精确度
1
、使用超像素算法构造领域边界映射。
\color{red}{1、使用超像素算法构造领域边界映射。}
1、使用超像素算法构造领域边界映射。
超像素块的数量设置为1000,也就是把图像分为1000个小块。将超像素块从左到右、从上到下的升序编号。
然后对超像素块进行遍历,如果超像素块中超过一半的区域属于正常的皮肤区域,则像素值从1000开始编号,每次递增1;否则,对于痣病变皮肤区域,超像素块的像素值从2000开始编号,每次递增1;黑色素瘤病变从3000、脂溢性角化并从4000开始,都是每次递增1.通过编码好的实例映射得到领域边界映射。
如下,左边是超像素算法分块结果,可以看到图像被分为了1000个小块。中间就是利用这1000个小块的像素值的不同得到的领域边界映射。

2
、
P
i
x
2
P
i
x
H
D
生成器结构。
\color{red}{2、Pix2PixHD生成器结构。}
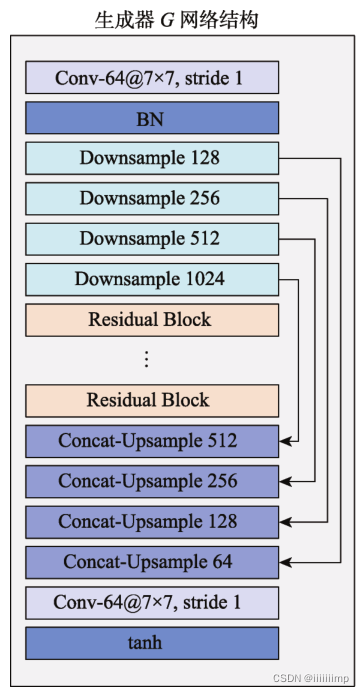
2、Pix2PixHD生成器结构。
由于全局生成器的输出分辨率满足数据的大小要求,为了减少计算量,作者只使用了Pix2pixHD的全局生成器,就没用局部增强器。
此外作者在全局生成器中加入了跳跃连接,有效的融合图像的浅层和深层特征
3
、损失函数设计。
\color{red}{3、损失函数设计。}
3、损失函数设计。
作者引入了标准差损失函数,来对特征匹配损失进行微调。
其实就是在匹配损失后面加了一个标准差,为什么加作者也没说。

(FusionGAN)Generating a Fusion Image One’s Identity and Another’s Shape
蓝色字代表作者的想法
\color{blue}{ 蓝色字代表作者的想法}
蓝色字代表作者的想法
红色字代表作者的创新
\color{red}{ 红色字代表作者的创新}
红色字代表作者的创新
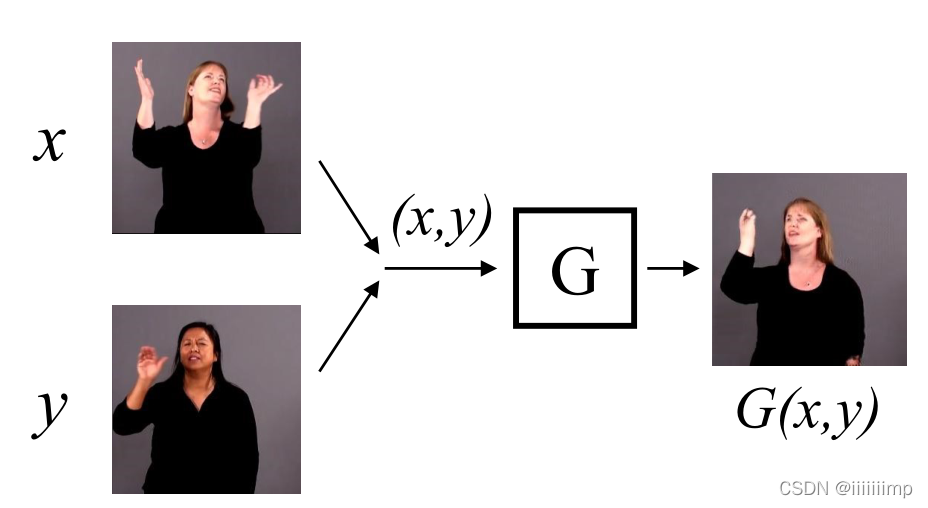
作者想用一个网络在无标签的情况下,让生成器生成具有输入x的身份(外貌),输入y的动作的图片
1
、身份损失,学习输入图像的身份。
\color{red}{1、身份损失,学习输入图像的身份。}
1、身份损失,学习输入图像的身份。
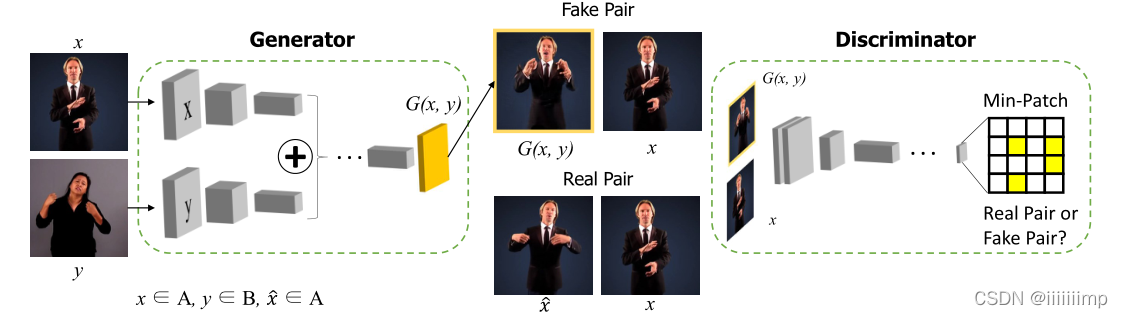
为了让生成器学到输入x的身份Ix,作者将x,y两张图片(来自不同的人物)送入生成器生成伪造图片G(x,y),再结合上真实图片x拿去给鉴别器判断是不是属于同一个人物。注意这里鉴别器并不在乎输入的2张图片动作是咋样的,只管身份是不是一样的。Loss用的LSGAN。
2
、
C
y
c
l
e
G
A
N
和
D
i
s
c
o
G
A
N
的缺陷。
\color{blue}{2、CycleGAN和DiscoGAN的缺陷。}
2、CycleGAN和DiscoGAN的缺陷。CycleGAN和DiscoGAN为了保证风格迁移的形状使用了两个连续的转换X->Y->X。即CycelLoss,但是这样做有一个缺点就是可能第两次转换只是学到第一次转换的反映射,而并没有去学到形状信息。
3
、形状损失,学习输入图像的动作。
\color{red}{3、形状损失,学习输入图像的动作。}
3、形状损失,学习输入图像的动作。
如果只用身份损失的话,生成器将只会生成一张与输入x身份相同的图像,而完全不在乎输入y。再加上并没有(Ix,Sy)这样的标签,那么该如何做才能让生成器学习y的动作呢?
为了让生成器学习y的动作,作者想到如果与x有相同身份的y给生成器,再用L1Loss处理y与G(x,y),那么生成器生成的G(x,y)就应该是输入y本身。这是因为本来生成器是要生成G(x,y)=(Ix,Sy),但是因为x与y有相同的身份,Ix=Iy,那么G(x,y)=(Ix,Sy)=(Iy,Sy)=y。
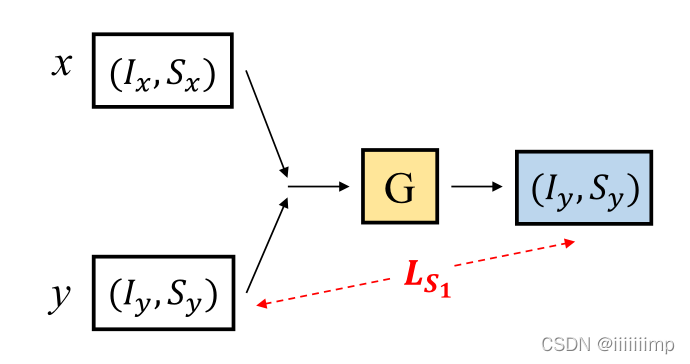
从而构成Ls1Loss,这里x与y是相同身份,不同动作
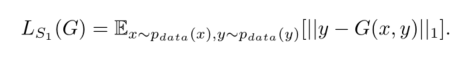
但是这么做有个问题,那就是可能生成器只会学习y而完全忽视了x,所以作者再这基础上增加了Ls2aLoss和Ls2bLoss,这里拿Ls2bLoss举例
x=(Ix,Sx)与y=(Iy,Sy)输入生成器G得到G(x,y)=(Ix,Sy)作为新x’=(Ix,Sy),再把之前的y=(Iy,Sy)作为新y’=(Iy,Sy)再输入生成器G中得到G(x’,y‘)=(Ix,Sy),再把G(x’,y‘)与y’=(Iy,Sy)做L1Loss得到Ls2bLoss。Ls2aLoss同理。
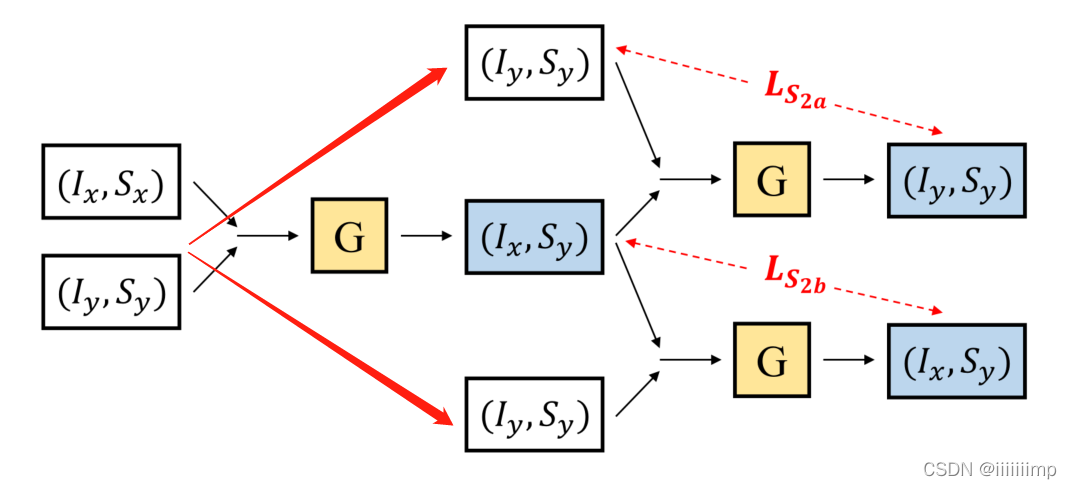
这样就让生成器也注意到输入x了。最终Loss为所有Loss之和。
4 、 M i n − P a t c h 训练,让生成器将注意力集中在图像中最奇怪的地方。 \color{red}{4、Min-Patch训练,让生成器将注意力集中在图像中最奇怪的地方。} 4、Min−Patch训练,让生成器将注意力集中在图像中最奇怪的地方。
之前的模型用的都是PatchGAN,作者在训练生成器的时候,在最后加了一个min pool。在G试图最大化身份损失的时候(即让鉴别器输出越接近于1越好),最大化的不是鉴别器最后的Patch而是最大化Patch之后的minpool的值。从而让生成器注意到生成的最不真实的地方。
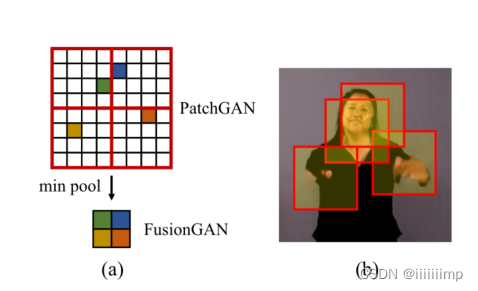
训练流程如下:

(StyleGAN)A Style-Based Generator Architecture for Generative Adversarial Networks
蓝色字代表作者的想法
\color{blue}{ 蓝色字代表作者的想法}
蓝色字代表作者的想法
红色字代表作者的创新
\color{red}{ 红色字代表作者的创新}
红色字代表作者的创新
1
、研究成果。
\color{red}{1、研究成果。}
1、研究成果。
(1)提出了基于样式的生成器解构,实现了隐变量的解耦,进一步提高了生成图片的质量
(2)提出了对隐空间进行量化分析的指标
(3)提出了真正的1024 * 1024分辨率的人脸数据集
2
、基于样式的生成器。
\color{red}{2、基于样式的生成器。}
2、基于样式的生成器。
以前都是从输入端直接输入latent code(隐变量)会导致纠缠。
而作者认为如果从中间层输入就会解纠缠。因此作者将隐变量z通过8个全连接的非线性变换映射到w,然后将w通过一个可学习的放射变换A变为y=(ys,yb)作为AdaIN的参数进行归一化,使得w可以对各个尺度的整体style进行控制。
将输入改成一个可学习的固定tensor
此外对于细节的控制,在每层特征中加入随机高斯噪声Noise,并在B处对每个通道的Noise进行缩放,缩放系数是可以学习的。
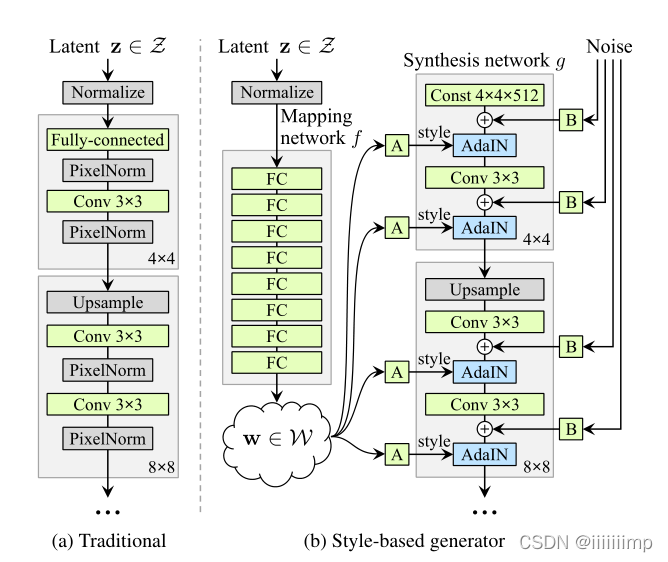
3
、
A
d
a
I
I
N
只影响当前的那个层的特征。
\color{red}{3、AdaIIN只影响当前的那个层的特征。}
3、AdaIIN只影响当前的那个层的特征。
AdaIN后的特征图会影响后面的一个Conv操作。但由于归一化的存在使特征图的每个通道不依赖于原始数据因此每个Style只能控制在进入下一个AdaIN层之前的这一段的特征。
4 、样式混合,减少网络各个样式产生关联 \color{red}{4、样式混合,减少网络各个样式产生关联} 4、样式混合,减少网络各个样式产生关联
作者在训练的时候用了两个隐变量z1、z2产生w1、w2,用于不同阶段的Style。这样做的好处就是能如果只使用一个w,那么网络中各个阶段的样式可能会产生关联(因为AdaIN的参数就是这个w的方式仿射变换结果),为了防止这种情况作者使用了两个w拼接的方法。经过测试还提高了FID。
如下图所示SourceA来自w1,SourceB来自w2。如果网络底层用w2(前3行)那么可以看到,生成的图像脸型、五官与SourceB接近,而颜色、皮肤与SourceA接近,这是因为底层如4 * 4、8 * 8大小的特征图控制的是人脸的整体轮廓,而头发、皮肤这种细节是顶层控制的。因此当w2用于顶层时(最后一行),可以看到人的头发、皮肤都接近SourceB了,而人脸结构却接近SourceA。

5
、随机变化,更丰富的纹理细节
\color{red}{5、随机变化,更丰富的纹理细节}
5、随机变化,更丰富的纹理细节
例如发丝的位置、胡子、雀斑这些的放的改变并不会在人的视觉上引起偏差,那怎样增加这些地方的随机性呢?
如果像传统生成器那样只在一开始加入了Noise,这样效率就会比较低,并且容易生成一些重复的部分,因为毕竟只有一个噪声嘛。
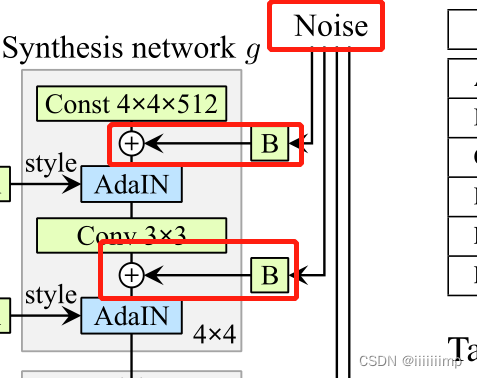
于是作者想到在各个层的卷积之后加入Noise。这样使得图像的细节部分发生了一些随机的变化,但是人脸的整体结构没有改变,并且还增加了更多细节。
下图可以看到增加Noise后细节发生了一些随机的变换,并且主要是发丝位置、皱纹这些,而人的脸部结构没有什么变化。

下图可以看出加入Noise比不加Noise图像产生了更多的细节。

6
、
w
控制
s
t
y
l
e
,而
N
o
i
s
e
控制细节
\color{red}{6、w控制style,而Noise控制细节}
6、w控制style,而Noise控制细节
style会影响整个图像,这是因为所有特征图都使用相同的w做AdaIN。
但是因为Noise独立的添加到每个像素,若使用噪声控制姿势等整体特征,由于不同的噪声没有关系很容易造成生成图像的空间不一致性,从而受到鉴别器惩罚。因此,网络学会了在没有明确知道的情况下适当的使用全局和局部信息。
7
、解纠缠的研究
\color{red}{7、解纠缠的研究}
7、解纠缠的研究
我们要求隐变量的每一个元素能单独的控制一个图像的因素。
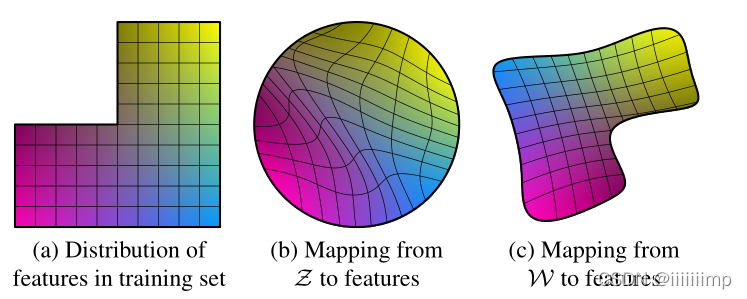
作者提出的映射网络f(z)能够很好的解开生成w的纠缠,使其生成的因子更线性。解纠缠能够使生成的图片更加逼真。
下图a中,假设横轴为男性,竖轴为头发长度。如果是生成军人的话,那么空缺的那一部分就是男子长发的军人,这显然是不存在的。
下图b,为z直接到图像的映射,因为要防止生成训练集中不存在的因素组合,所以映射变得扭曲,这也就导致z变一下最后生成的图片就会变很多。
下图c,为w映射到图像,可以看到纠缠已经解开了。
为了评价解纠缠的效果,作者提出了感知路径长度和线性可分性两种指标。
8、代码:https://github.com/hahahappyboy/GAN-Thesis-Retrieval/tree/main/StyleGAN
参考了:https://github.com/tomguluson92/StyleGAN_PyTorch
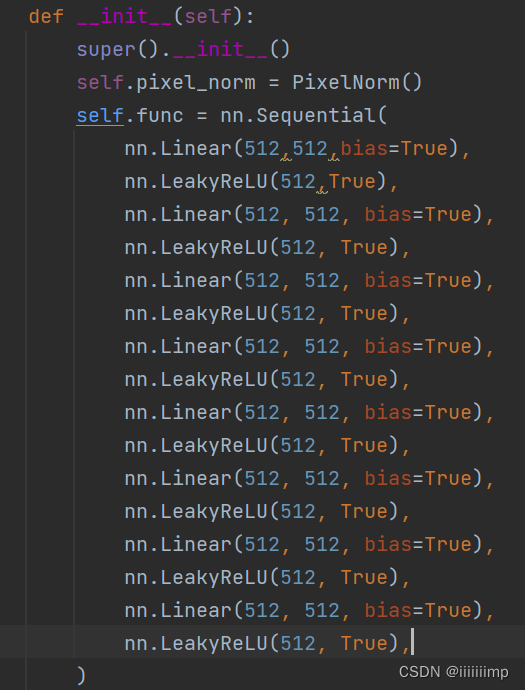
(1)映射网络
就是一个PixelNorm加上8个MLP
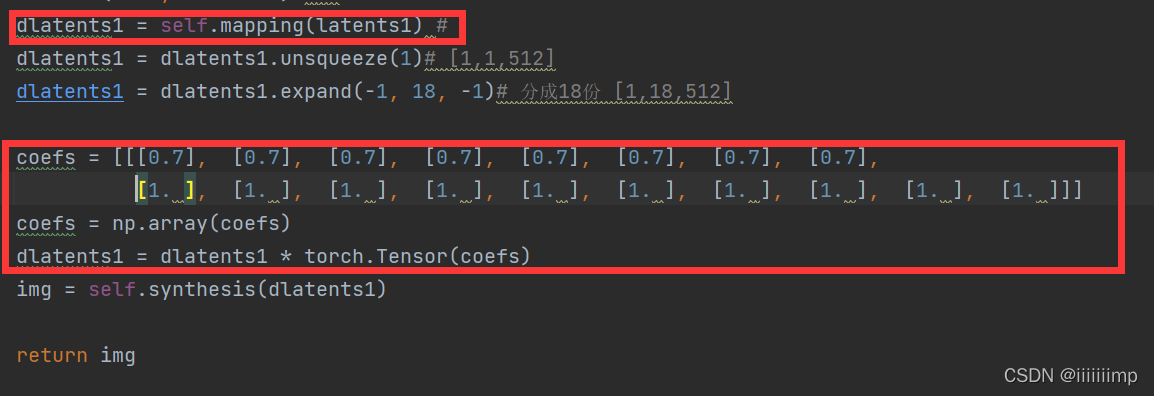
论文中的Style mixing样式混合其实就是z经过映射网络得到w过后将w复制18份前8份乘上0.7,后10份乘上1.0
(2)主干网络
输入的是[1,512,4,4]的固定的高斯噪声,然后加上一个可学习的偏执bias
之后就是论文所讲的先up_sample->noise->adaIN->conv->noise->adaIN为一个block
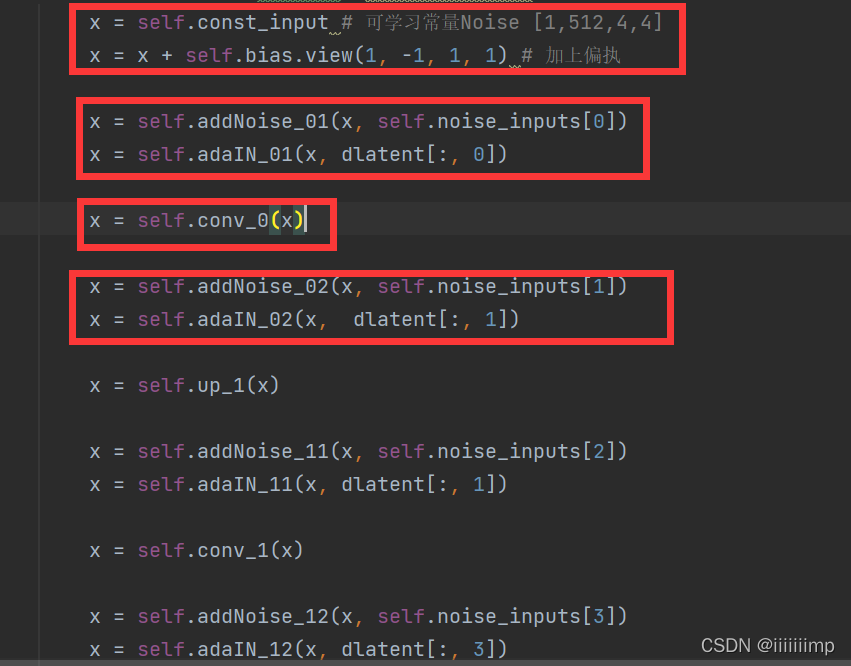
(3)各层加上Noise
noise的维度在模型初始化的时候就已经计算好了的。
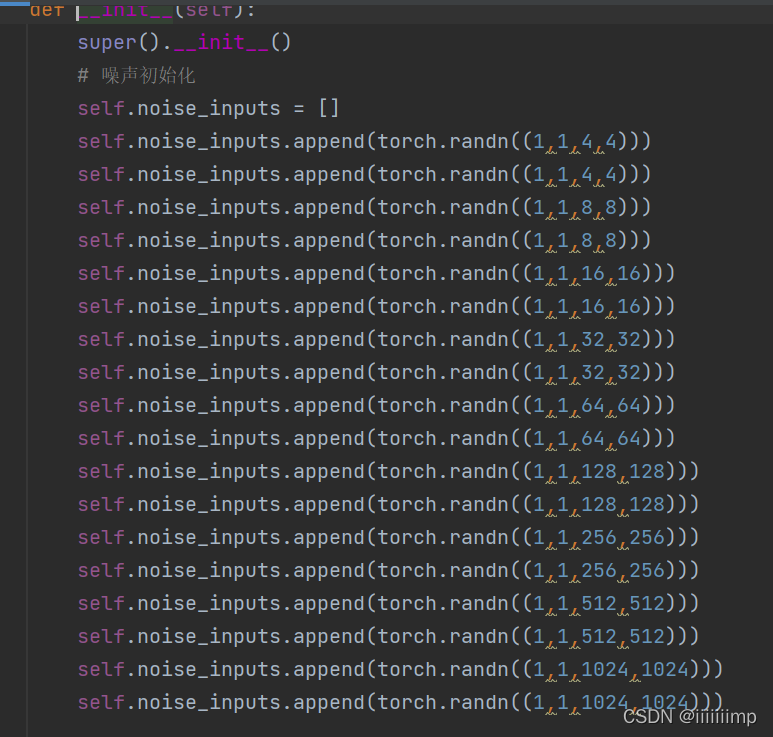
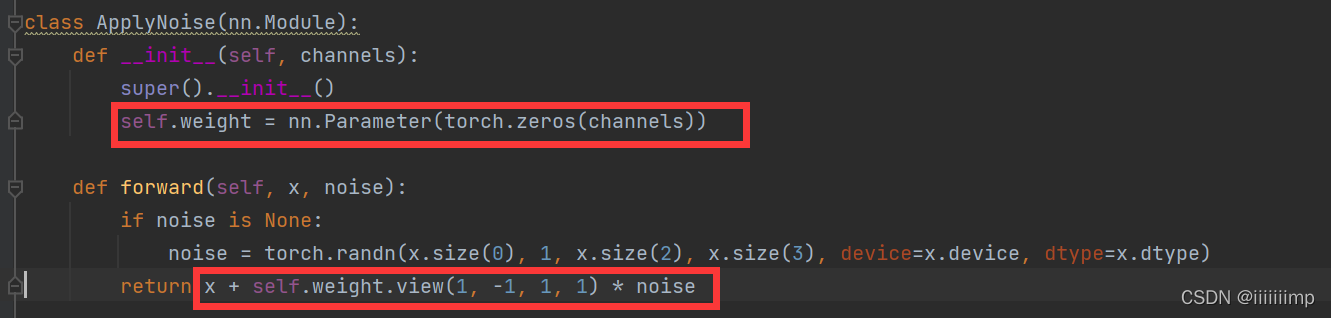
之后每个阶段把上采样或者卷积过后的x直接加上对应尺寸大小和维度的noise就行了

做到可学习是因为把noise和可学习参数相乘之后再加上x的
(4)鉴别器结构
鉴别器结构就非常的常规了
(数据增强)Differentiable Augmentation for Data-Efficient GAN Training
蓝色字代表作者的想法
\color{blue}{ 蓝色字代表作者的想法}
蓝色字代表作者的想法
红色字代表作者的创新
\color{red}{ 红色字代表作者的创新}
红色字代表作者的创新
1 、少样本训练会让鉴别器简单地记住整个训练集,从而导致生成质量下降 \color{blue}{1、少样本训练会让鉴别器简单地记住整个训练集,从而导致生成质量下降} 1、少样本训练会让鉴别器简单地记住整个训练集,从而导致生成质量下降
少样本训练让鉴别器简单地记住整个训练集,使得鉴别器过拟合会惩罚任何生成的样本(因为鉴别器只会觉得训练集的标签是对的,其他都是伪造的),从而导致生成器无法提高。
2 、当 G A N 训练不稳定的时候常常使用正则化技术 \color{blue}{2、当GAN训练不稳定的时候常常使用正则化技术} 2、当GAN训练不稳定的时候常常使用正则化技术
3
、谱归一化常常用来防止过拟合
\color{blue}{3、谱归一化常常用来防止过拟合}
3、谱归一化常常用来防止过拟合
U-GAT-IT在鉴别器中使用谱归一化从而增强 GAN 在训练过程中的稳定性,防止鉴别器过拟合。
4 、在 G A N 上直接使用数据增强不会提高 b a s e l i n e \color{blue}{4、在GAN上直接使用数据增强不会提高baseline} 4、在GAN上直接使用数据增强不会提高baseline
5 、使用水平翻转能够提高 G A N 的性能 \color{blue}{5、使用水平翻转能够提高GAN的性能} 5、使用水平翻转能够提高GAN的性能
6
、只对真实数据增强,效果差
\color{red}{6、只对真实数据增强,效果差}
6、只对真实数据增强,效果差
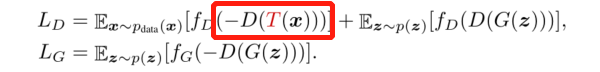
作者经过实验发现如果只对真实数据增强。那么生成的数据也会有增强的效果,如带有遮蔽、颜色抖动等。
这是因为模型现在学习的是一个不同的数据集分布T(x),而不是x,这就导致并不能生成接近x的分布。

7
、对真实和生成样本进行数据增强来训练鉴别器,效果更差
\color{red}{7、对真实和生成样本进行数据增强来训练鉴别器,效果更差}
7、对真实和生成样本进行数据增强来训练鉴别器,效果更差
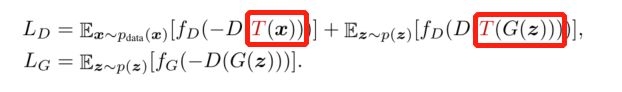
这是因为虽然D对增强后的T(G(z))和T(x)进行了很好的分类,但是对生成的没有增强的图像G(z)却不能进行识别。因此生成器能用G(z)很好的骗过鉴别器,从而无法得到鉴别器较好的反馈。这表明,任何打破G和D之间微妙平衡的尝试都容易失败。
8
、对真实和生成样本进行数据增强来训练鉴别器和鉴别器,效果很好
\color{red}{8、对真实和生成样本进行数据增强来训练鉴别器和鉴别器,效果很好}
8、对真实和生成样本进行数据增强来训练鉴别器和鉴别器,效果很好
作者在T得设计上,使用了:平移(在图像大小得[-1/8,1/8]内,用零填充),遮蔽(用图像大小的一半的随机正方形遮蔽),颜色(包括随机亮度在[-0.5,0.5]内,对比度[0.5,1.5]内,饱和度在[0,2]内)。
DiffAugment能缓解过拟合问题,最终达到较好的收敛效果
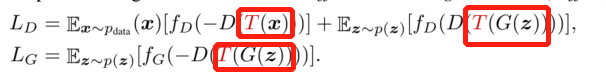
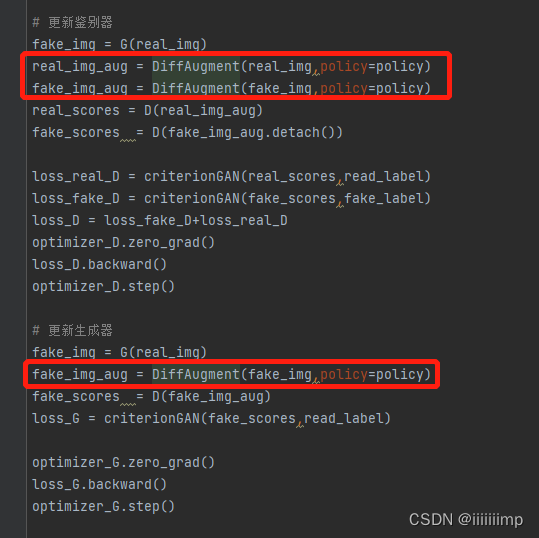
9、代码:https://github.com/hahahappyboy/GAN-Thesis-Retrieval/tree/main/DiffAugment
作者提供了源码直接用就好

在训练D和G的时候做一下增强就好
10
、
D
i
i
f
A
u
g
m
e
n
t
在
P
i
x
2
p
i
x
和
C
y
c
e
l
G
A
N
上没什么效果
\color{red}{10、DiifAugment在Pix2pix和CycelGAN上没什么效果}
10、DiifAugment在Pix2pix和CycelGAN上没什么效果
使用 pix2pix 和 CycleGAN 的实验中,作者发现 Color DiffAugment 可能有效,但性能提升非常有限。可能生成器的架构太弱而无法过拟合判别器。
(SPADE)Semantic Image Synthesis with Spatially-Adaptive Normalization
蓝色字代表作者的想法
\color{blue}{ 蓝色字代表作者的想法}
蓝色字代表作者的想法
红色字代表作者的创新
\color{red}{ 红色字代表作者的创新}
红色字代表作者的创新
1
、传统网络架构的归一化层容易洗掉语义信息。
\color{blue}{1、传统网络架构的归一化层容易洗掉语义信息。}
1、传统网络架构的归一化层容易洗掉语义信息。
通过叠加卷积、归一化和非线性层而构建的传统网络架构[22,48],充其量是次优的,因为它们的归一化层往往会“洗去”输入语义mask中包含的信息。为了解决这个问题,作者提出了空间自适应归一化。
2
、无条件归一化和有条件归一化。
\color{blue}{2、无条件归一化和有条件归一化。}
2、无条件归一化和有条件归一化。
作者说像IN、BN、LN、GN等都是条件归一化,因为其不依赖外部数据就能进行归一化。
像CBN、AdaIN这些就是有条件归一化,因为他们需要外部数据。作者提出的SPADE也是条件归一化,其目的是在生成器归一化时提供语义信息。
3
、空间自适应归一化。
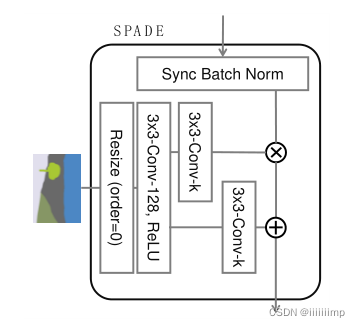
\color{red}{3、空间自适应归一化。}
3、空间自适应归一化。
μ和δ的计算方式和BN是一样的,都是通道维度进行归一化。
不同的是BN中的γ和β的计算是通过网络训练得到的,而SPADE中的γ和β是通过语义图像计算得到的(Condition Norm和AdaIN都是这样)。SPADE和BN除了γ和β的计算方式不同外,γ和β维度也不一样。在BN中,γ和β是向量(也就是一维的),其中每个值对应输入特征图的每个通道,而SPADE中的γ和β是三维矩阵,除了通道维度外,还有宽高维度,因此公式(1)中的γ和β下表包含c,y,x三个符号,这也就是Spatially-adptive的含义。假如是BN,那么γ和β的下标只有c,也就是通道,显然BN这种不区分空间维度的计算方式容易丢失输入图像的信息。

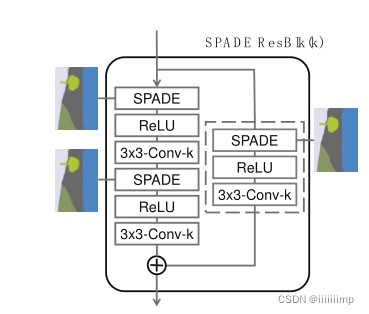
4
、生成结构。
\color{red}{4、生成结构。}
4、生成结构。
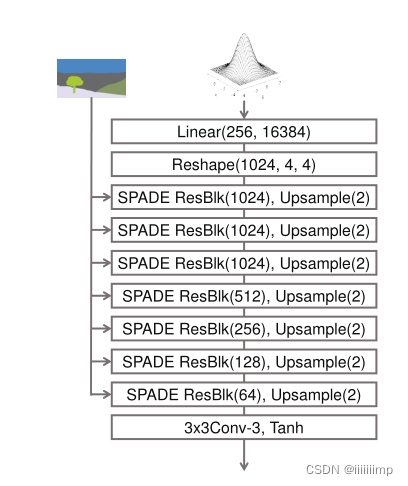
因为SPADE本身就是用mask作为输入,因此就没必要在第一层用mask作为输入了。并且也去除了encoder,将随机向量作为输入。上采样用的最近邻上采样。
实验证明了去除encoder,只用decoder效果也不会差,并且参数还少了一半。
5
、鉴别器结构。
\color{red}{5、鉴别器结构。}
5、鉴别器结构。
作者使用了pix2pixHD的多尺度鉴别器(归一化用的IN),只是在所有卷积层之后都加了空间归一化。
6
、将
M
S
E
L
o
s
s
换为
H
i
n
g
e
L
o
s
s
\color{red}{6、将MSELoss换为HingeLoss}
6、将MSELoss换为HingeLoss
作者沿用了Pix2pixHD的Loss函数,除了MSELoss换为HingeLoss,并且作者发现去掉任何Pix2pixHD的任何Loss函数都将造成性能下降。
7
、
I
N
不好的原因。
\color{bLUE}{7、IN不好的原因。}
7、IN不好的原因。
前面说了IN、BN等归一化会洗掉mask的一些信息。之所以会这样,作者举了一个例子,如下图所示,假如一幅mask图的输入就只有一种颜色,如只有蓝色、绿色。那么经过一层卷积后就会再一次均匀化mask(因为卷积实际也是加权求和嘛),之后在经过IN,那么无论输入的是什么颜色的语义信息归一化后都会为0,因此语义信息完全的丢掉了。而作责提出的空间自适应模块就没有这样的归一化因此语义信息就没有被丢失。

8
、
m
I
o
U
、
a
c
c
u
、
F
I
D
\color{bLUE}{8、mIoU、accu、FID}
8、mIoU、accu、FID
作者用训练好的DeepLabV2去测试生成的图片,然后比较其与GT的mIoU和accu。作者还使用了FID作为评价指标。
9
、
P
i
x
2
p
i
x
H
D
的增强
\color{red}{9、Pix2pixHD的增强}
9、Pix2pixHD的增强
作者为了验证SPADE的有效性做的实验
pix2pixHD++:在pix2pixHD基础上使用了一些有效的增强计算
pix2pixHD++ w/Concat:在pix2pixHD++中把mask按通道方向凭借到所有的中间层上
pix2pixHD++ w/SPADE:在pix2pixHD++中加入SPADE模块
实验发现直接把mask按通道方向凭借到所有的中间层上是SPADE的一种可行的替代方案,但任然不能实现SPADE相同的功能。
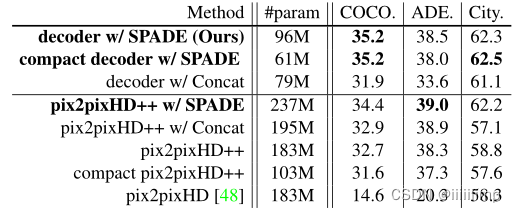
作者还发现使用Spectral Norm、synchronized BatchNorm,TTUR,hinge loss都有助于性能提升
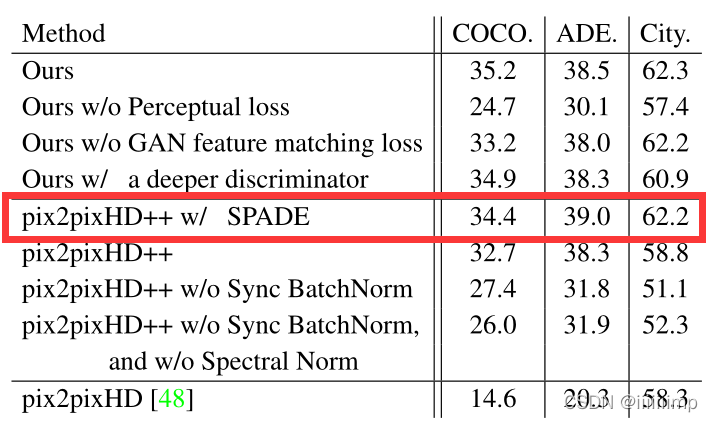
10
、
S
P
A
D
E
实验
\color{red}{10、SPADE实验}
10、SPADE实验
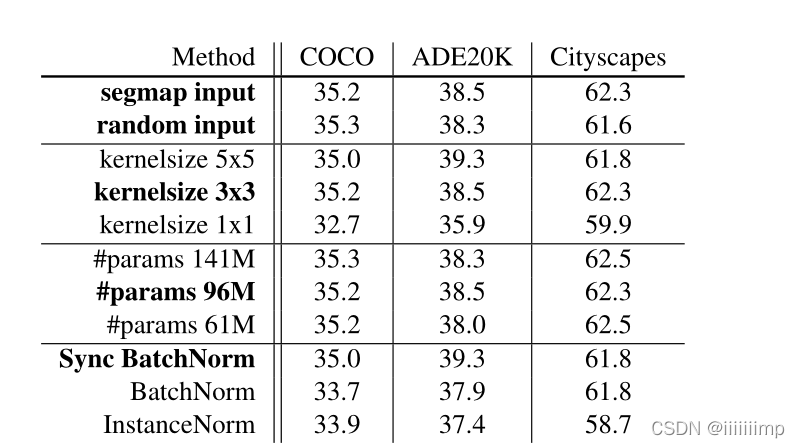
作者在SPADE上进行了一系列的消融实验
(1)使用裁剪后的mask和随机噪声作为模型的输入,发现效果才不多,原因是因为SPADE已经提供了足够的信息了。
(2)作者把模型中的无参的归一化替换为各种归一化方法,发现效果差不多,说明SPADE的鲁棒性较强。
(3)作者使用了不同的卷积大小,发在只有1 * 1的卷积核会影响很大的效果,原因是因为1 * 1的卷积无法提取上下文信息。
(4)作者改变卷积核数,发现并不是卷积核越多越好,但其实效果差不多。
11
、
S
P
A
D
E
编码器
\color{red}{11、SPADE编码器}
11、SPADE编码器
作者使用一个编码器来编码出均值和方差,作者随机噪声的分布的均值和方差,来输入到生成器中。

11、代码:https://github.com/hahahappyboy/GAN-Thesis-Retrieval/tree/main/SPADE
(1)编码器
编码器就是把输入的风格图像resize为256 * 256大小,然后经过几个Conv2d+spectral_norm+InstanceNorm2d+LeakyReLU后变为[1,512,4,4]大小然后展平送个两个全连接得到两个[1,256]的向量作为均值和标准差得到高斯分布z[1,256]
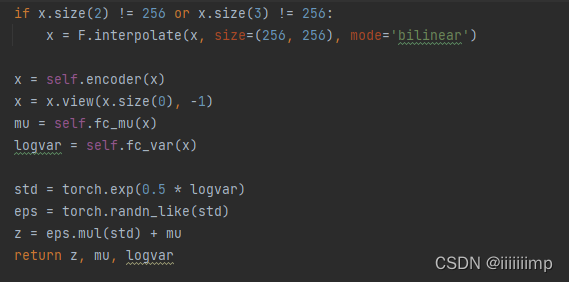
(2)生成器
生成器就是把Encoder生成的z[1,256]通过fc和reshape后变为[1,1024,4,8],之后就是连续的几个上采样+SPADE,得到图片[1,3,256,512]。
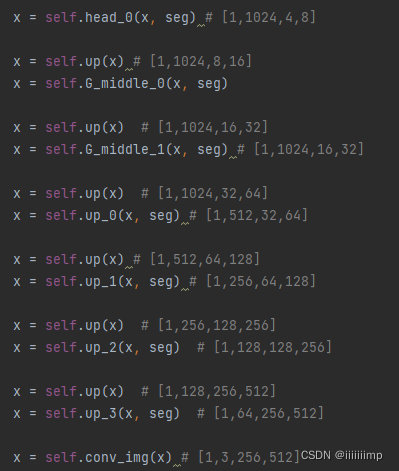
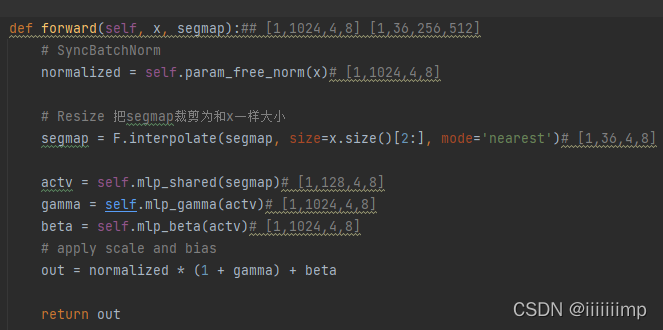
SPADE
感觉没什么好说的,就和论文的结构是一样,把mask裁剪为和上一层的输出x一样的大小然后去运算。
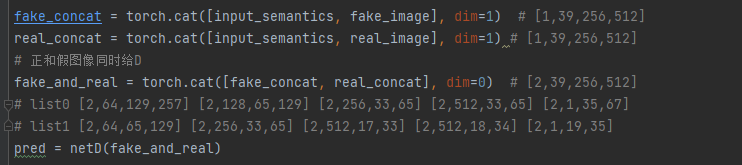
(3)鉴别器
用的多尺度鉴别器和以前模型唯一的区别去就是Conv后加了spectral_norm才InstanceNorm

(4)训练
需要注意的是作者是把伪造图片和真实图片,说是为了避免真假图片的统计差异。
(MSG-GAN用于图像翻译)Efficient High-Resolution Image-to-Image Translation using Multi-Scale Gradient U-Net
蓝色字代表作者的想法
\color{blue}{ 蓝色字代表作者的想法}
蓝色字代表作者的想法
红色字代表作者的创新
\color{red}{ 红色字代表作者的创新}
红色字代表作者的创新
1
、
P
i
x
2
P
i
x
H
D
有很大的内存消耗
\color{blue}{1、Pix2PixHD有很大的内存消耗}
1、Pix2PixHD有很大的内存消耗
Pix2PixHD需要大量的计算支援,推理内存消耗也很大。作者受到MSG-GAN的启发,将其用到图像翻译上,实现了一个MSG U-net的模型,其计算消耗仅为Pix2PixHD的一半,并且达到了差不多的生成效果。
2
、生成器结构
\color{red}{2、生成器结构}
2、生成器结构
主要就每个阶段都将mask减小1倍,让其经过卷积(左边绿色)得到的特征图与Encoder下采样后(黄色)的特征图进行拼接。通过这样的方式让Encoder学到mask的局部特征和全局特征。
在Decoder部分,每一次反卷积过后的特征图Encoder对应的特征图concat+conv之后,让特征图(粉色部分)经过一个卷积(右边绿色)得到输出。这种中间层产生输出的方式能够有效的缓解梯度消失的问题。因为鉴别器不仅要接受最后一层的输出,还要接受中间层的输出,这样在backward后就能让鉴别器的梯度直接传到生成器的中间层,从而增加网络训练的稳定性。
3
、鉴别器结构
\color{red}{3、鉴别器结构}
3、鉴别器结构
鉴别器还是使用的是多尺度鉴别器,只不过任务为接受生成器中层的输出与对应尺度的mask拼接后作为输入。
4
、损失函数
\color{red}{4、损失函数}
4、损失函数
沿用Pix2PixHD的对抗损失、特征匹配损失、感知损失。
(CC-FPSE)Learning to Predict Layout-to-image Conditional Convolutions for Semantic Image Synthesis
和SPADE一样,是语义合成的守门员。
蓝色字代表作者的想法
\color{blue}{ 蓝色字代表作者的想法}
蓝色字代表作者的想法
红色字代表作者的创新
\color{red}{ 红色字代表作者的创新}
红色字代表作者的创新
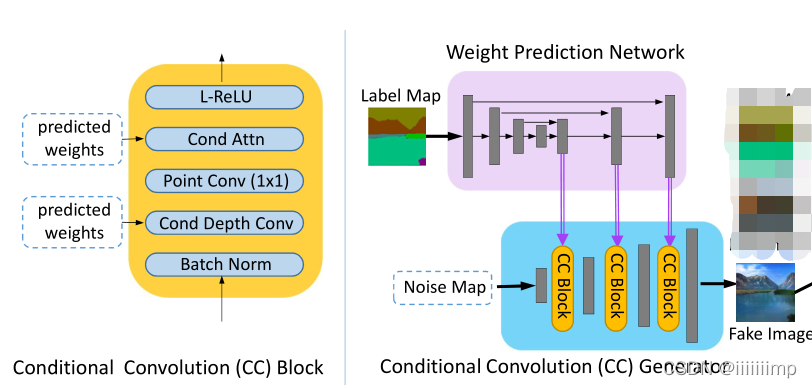
1
、之前语义合成生成器的不足和启发
\color{blue}{1、之前语义合成生成器的不足和启发}
1、之前语义合成生成器的不足和启发
之前的网络只把mask用在G的输入层这样不能很好的保护mask的分布信息。为了缓解这个问题,SPADE提出了空间自适应归一化,但是作者认为空间自适应归一化这种简单的放射变化会到时网络的表征能力和灵活性受到限制。
另外之前的卷积都是应用于所用样本的特征图的所有位置上,不会管不同位置语义标签是什么。但是作者认为,不同的卷积核应该用于生成不同的对象。
因此作者想到使用mask来预测卷积核,用预测的卷积核去卷积特征图从而来生成图像。但是如果预测每一个卷积核会造成内存爆炸,因此作者想到了使用可分离卷积的方法,来降低预测的参数。
可分离卷学习https://www.bilibili.com/video/BV1wA411Y7eB?spm_id_from=333.337.search-card.all.click
2
、之前语义合成鉴别器的不足和启发
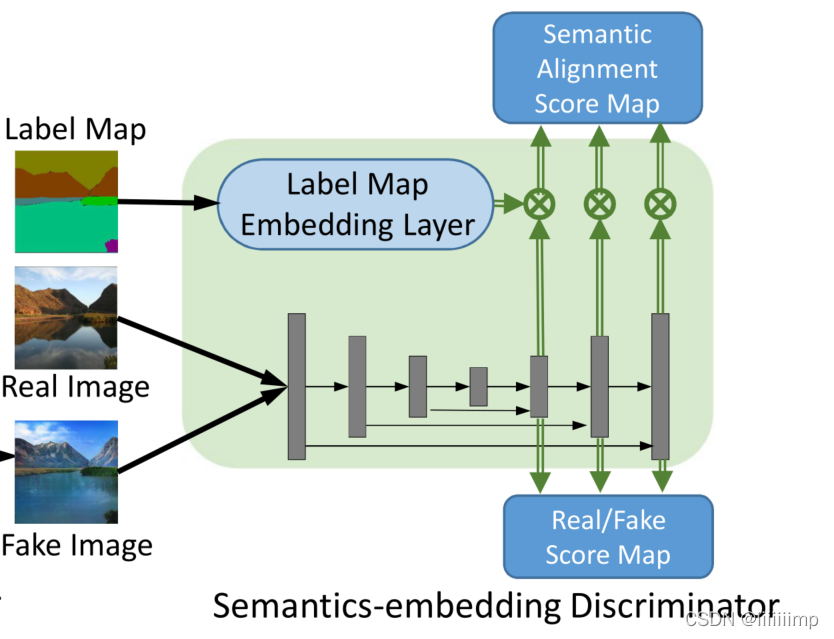
\color{blue}{2、之前语义合成鉴别器的不足和启发}
2、之前语义合成鉴别器的不足和启发
以前的多尺度鉴别器PatchGAN都只关注生成的质量,作者认为还应该关注图像与mask的对齐关系,因此作者提出了一个特征金字塔语义嵌入鉴别器。
3
、
C
C
−
F
P
S
E
生成器结构
\color{red}{3、CC-FPSE生成器结构}
3、CC−FPSE生成器结构
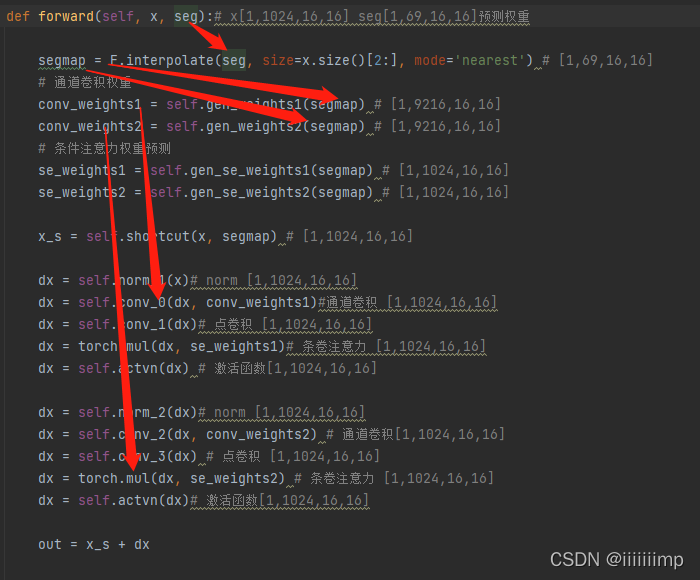
总体结构就是把mask(Lable Map)输入到一个Unet的权重网络中,然后把各层上采样的特征图作为权重输入到主干网络的CC Block中。主干网络结构类似于SPADE,就是一个只有解码器的结构。
CC Block里面也比较简单,就是BN,通道卷积(一个特征图对应一个卷积核),点卷积(1 * 1卷积),条件注意力机制(其实就是预测权重与特征图点乘),最后ReLU。
因为使用了Unet结构的跳跃连接后的特征图作为权重预测,所以预测的权重即具有局部信息也具有全局信息。而SPADE的自适应归一化就仅仅只有两个卷积结构也就是只有一个5 * 5大小的感受野,也就是没有全局信息。
4
、
C
C
−
F
P
S
E
鉴别器结构
\color{red}{4、CC-FPSE鉴别器结构}
4、CC−FPSE鉴别器结构
前面说了之前的那些多尺度鉴别器没办法辨别细微的细节,并且不会强制的约束mask与图像是否对齐了。因此作者提出了一个特征金字塔结构的鉴别器。
首先是把真实图像和伪造图像(现在的鉴别器都是真实和伪造一并输入,这样对训练有好处)输入特征金字塔中,经过上采样的通道合并后做真假判断,这样D给出的打分就既有局部信息也有全局信息了。
另外,为了避免之前多尺度鉴别器那种把image和mask给concat后作为输入然而D却只看image不看mask的情况,作者将mask下采样到与特征金字塔输出特征图相同的维度后做内积得到语义对齐分数判断,从而让D对image和mask是否对齐做判断。
其实特征金字塔和Unet的区别就是特征金字塔把上采样的每一层的输出了,而Unet就只输出了最后一层。
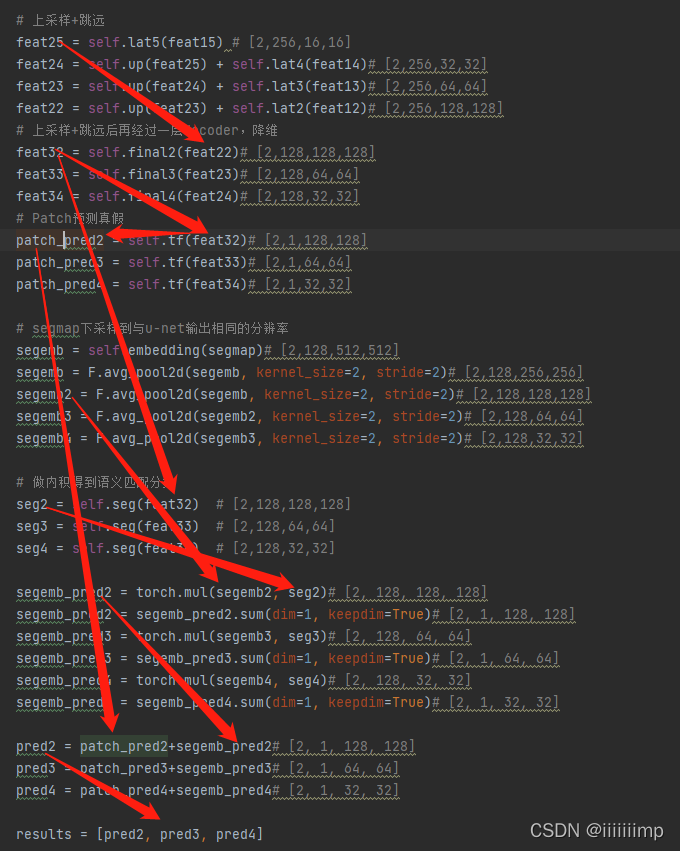
5、代码:https://github.com/hahahappyboy/GAN-Thesis-Retrieval/tree/main/CC-FPSE
(1)生成器的权重预测网络有点类似与之前说的HourGlass结构,就是跳跃连接之前其实是把下采样的图多经过了一个卷积层(入下图中的labellat1),这样做的原因是想过滤调一些下采样特征图中concat后对上采样特征图来说没有必要补充的信息。
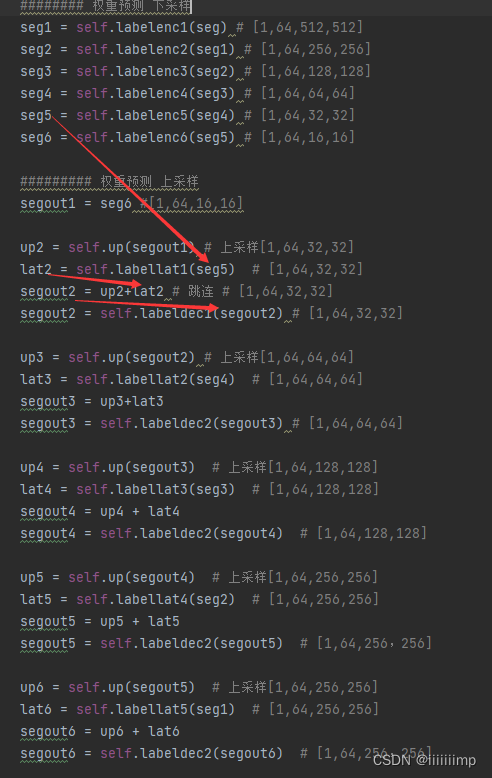
之后就是把concat后的特征图后经过一层decoder之后得到的预测权重再与mask(reszie成与特征图一样大小)caoncat后送入到主干网络的CC-Block中去了。
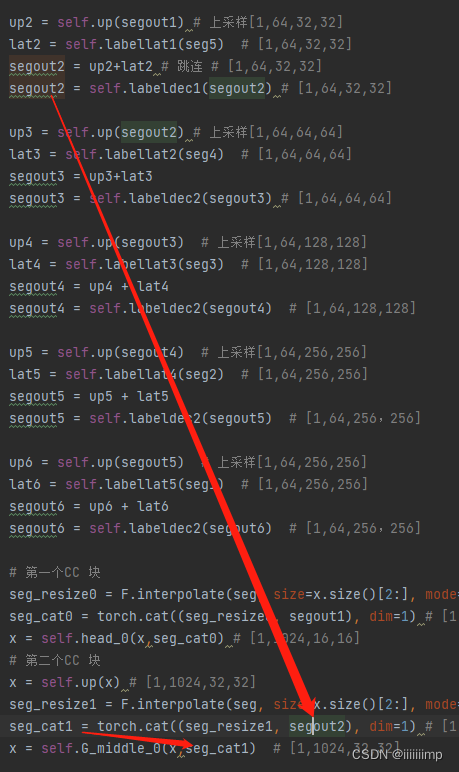
CC-Block中把seg(就是权重预测网络得到的特征图)经过gen_weights(其实就是两个卷积)得到的两个卷积权重分别作为通道卷积权重和条件注意力机制权重。可以看到,条件注意力卷积权重其实就是点乘。
通道卷积的预测权重其实也是点乘

(2)鉴别器
先把拼接在一起的真实图像和伪造图像下采样得到的特征图作为特征匹配损失用到输入
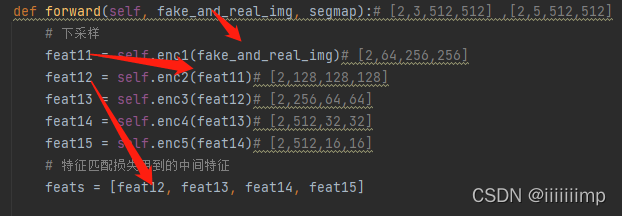
之后把上采样concat后的特征图与经过经过一层卷积后变为通道为1的patch(图中的patch_pred2、3、4)作为真假判断的patch
又上采样concat后的特征图经过一层卷积得到的特征图与缩放成相同大小的mask图相乘得到语义对齐度的patch
最后把真假判断的patch和语义对齐度的patch相加作为鉴别器的输出
(超声合成)Sketch guided and progressive growing GAN for realistic and editable ultrasound image synthesis
一篇刚出的关于超声的图像翻译。
蓝色字代表作者的想法
\color{blue}{ 蓝色字代表作者的想法}
蓝色字代表作者的想法
红色字代表作者的创新
\color{red}{ 红色字代表作者的创新}
红色字代表作者的创新
1
、创新点
\color{red}{1、创新点}
1、创新点
(1)为了增强生成图像的结构细节,将图像边缘纹理的mask与对象mask何在以前作为网络的输入
(2)为了生成高清分辨率的超声(US)图像,采用了渐进式训练的模型
(3)为了进一步提高生成图片的质量,提出了一种特征损失
2
、当前医学图像面临样本少的问题
\color{blue}{2、当前医学图像面临样本少的问题}
2、当前医学图像面临样本少的问题
作者说医学缺少数据集和标注图片,所以很需要数据增强
3
、语义合成有基于物理的和基于可学习的
\color{blue}{3、语义合成有基于物理的和基于可学习的}
3、语义合成有基于物理的和基于可学习的
基于物理的方法很耗时,所以作者选择基于可学习的,也就是用深度学习
4
、什么是棋盘效应
\color{blue}{4、什么是棋盘效应}
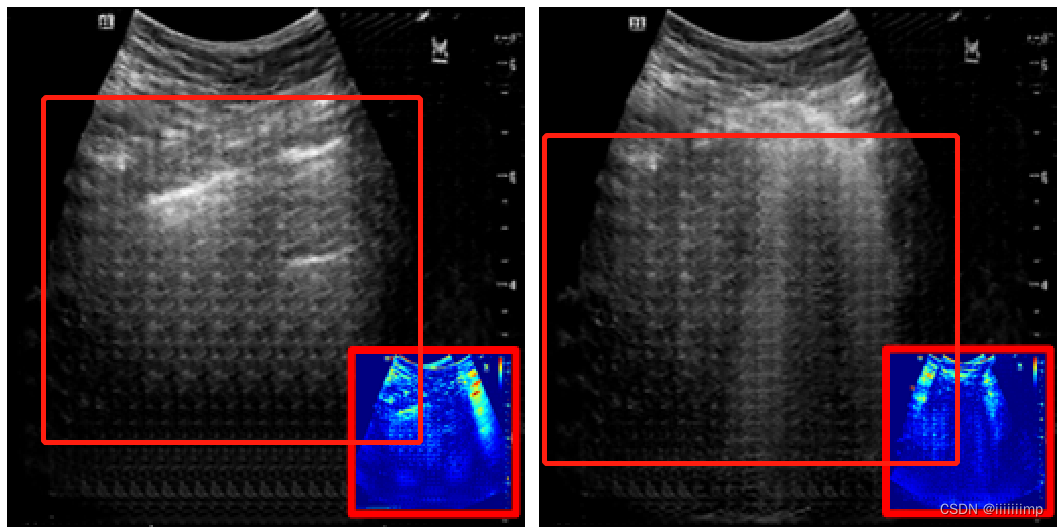
4、什么是棋盘效应
这种生成的效果像一个棋盘网格一样就叫棋盘效应
5
、
l
a
b
e
l
中加入边缘纹理
\color{red}{5、label中加入边缘纹理}
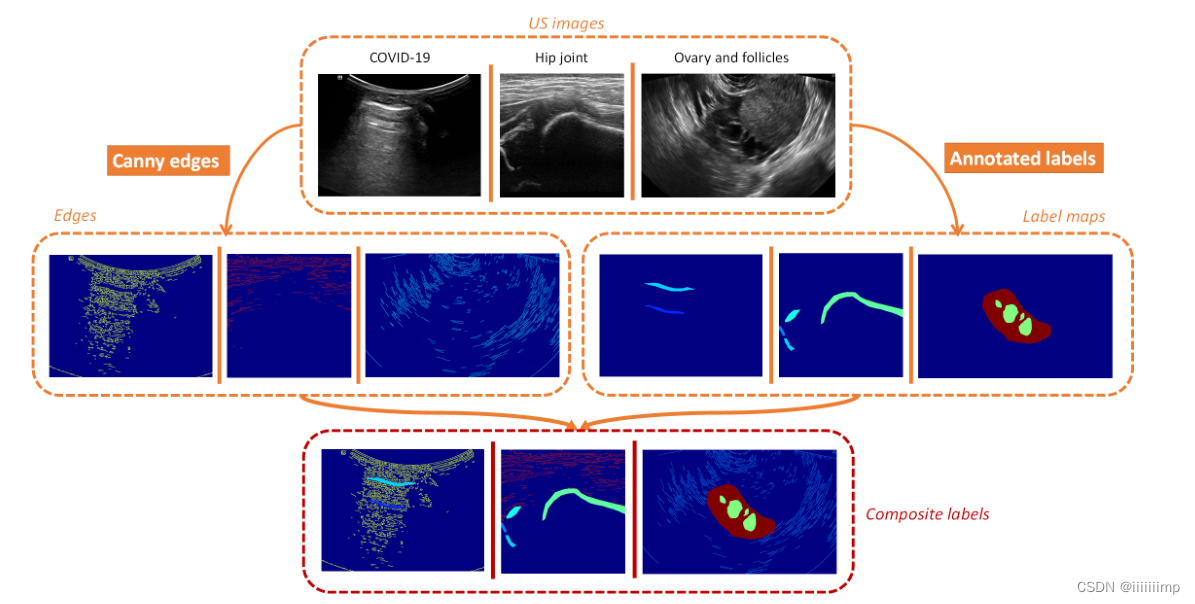
5、label中加入边缘纹理
作者使用canny算子得到US图片的边缘再与标注的label进行组合得到复合的label作为G的D的输入
6
、网络主架构
\color{red}{6、网络主架构}
6、网络主架构
生成器的主干使用下采样+残差+上采用的结构
鉴别器采用PatchGAN,因为作者认为PatchGAN对局部区域有更多的限制,有更高频的信息被回传道生成器。
7
、渐进式训练
\color{red}{7、渐进式训练}
7、渐进式训练
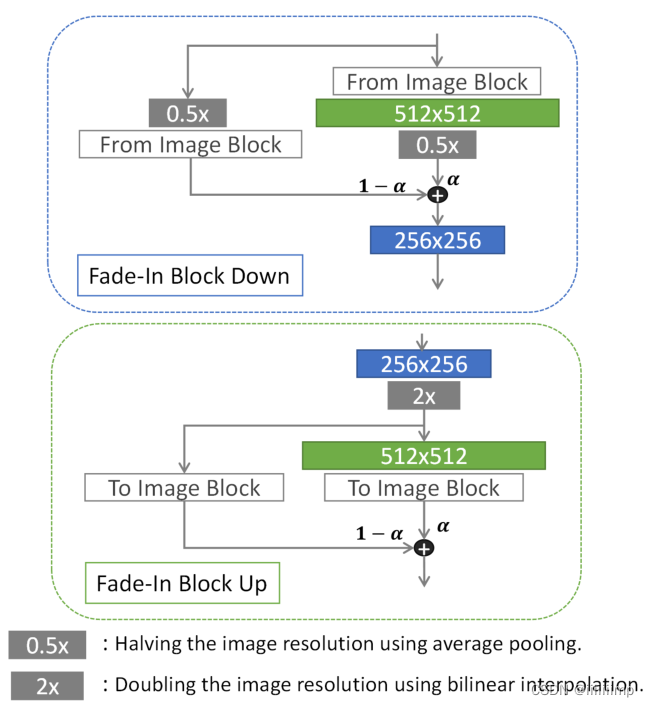
训练步骤:
(1)先用G和D训练出256 * 256 的US图,知道生成的质量不错为止
(2)将新的FIB层添加的网络中,用a控制添加的比例,使FIB层满满淡入网络,以避免之前训练好的层收到很大冲击。
D与G更早的训练,以补充更多的梯度信息,从而使G学习更高分辨率图像的生成
(3)最后G和D以前训练,以进一步提高性能。
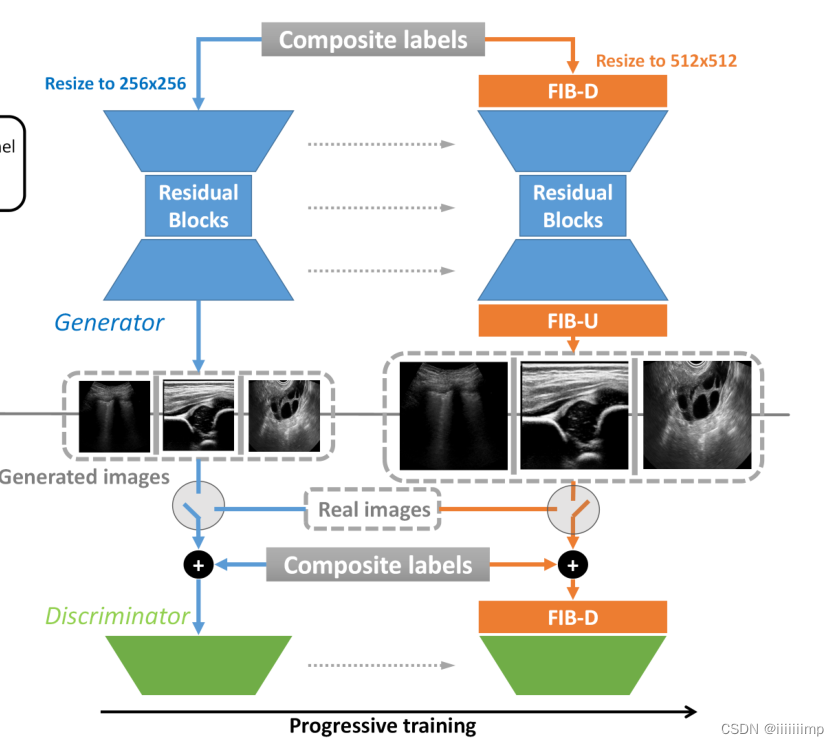
这是FIB层
8
、特征损失
\color{red}{8、特征损失}
8、特征损失
作者说生成的图像有点模糊,并且带有椒盐噪声,尤其在没有标注对象和边缘的地方。这可能是由于L1Loss造成的,因为L1Loss关注的是像素级的差异,而忽略了像素之间的空间相似性。但是删除了L1Loss又会缺少低频信息。
因此受到感知损失的启发。计算真实图像和生成图像的高级特征,并试图最小化他们之间的均值和方差
图中的FEN就是作者自己用Resnet-50训练的用于提取高级特征的网络
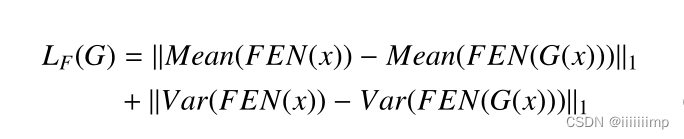
因此总的Loss就是:GANLoss+L1Loss+FLoss
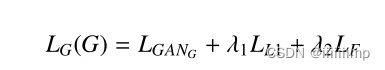
9
、评价指标
\color{red}{9、评价指标}
9、评价指标
作者使用了KID、FID、MS-SSIM、LPIPS作为评价指标。
KID、FID、LPIPS越低越好
MS-SSIM越高越好
10
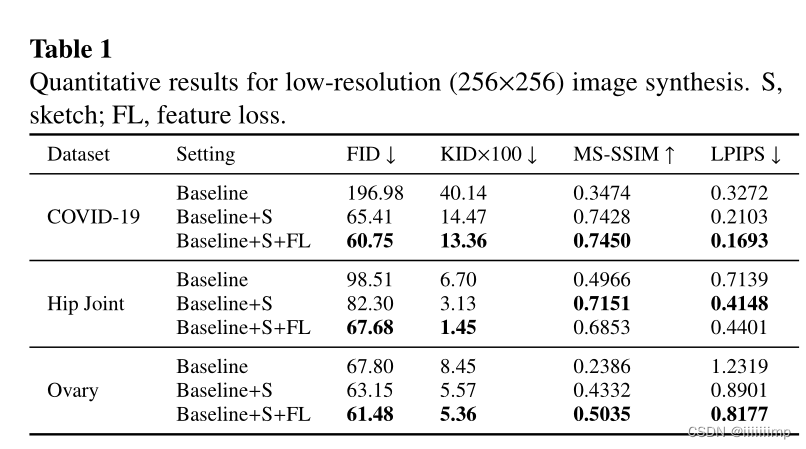
、作者做实验的方式
\color{red}{10、作者做实验的方式}
10、作者做实验的方式
作者通过一步一步的加入自己创新的东西,来表明自己的创新是有用的
作者还叫来了医生去判断真假,进一步说明自己生成图片的效果不错

11
、加入边缘纹理的
l
a
b
e
l
能有效解决棋盘效应
\color{red}{11、加入边缘纹理的label能有效解决棋盘效应}
11、加入边缘纹理的label能有效解决棋盘效应
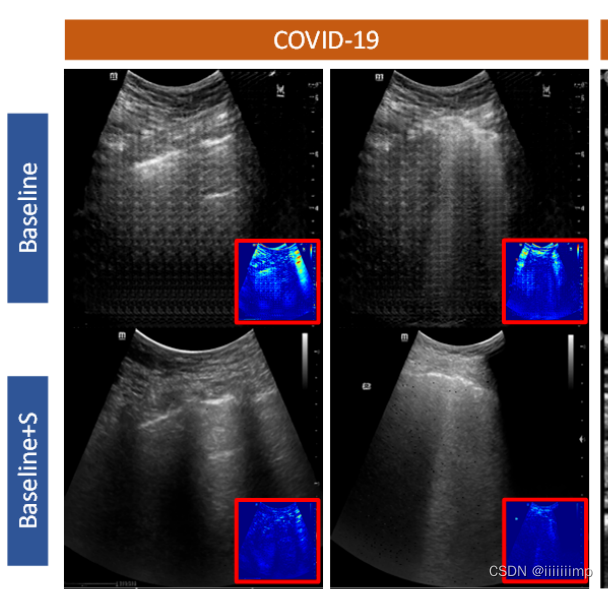
12
、用于语义分割的样本扩充
\color{red}{12、用于语义分割的样本扩充}
12、用于语义分割的样本扩充
作者分别用不做数据增强、用传统数据增强、用GAN做数据增强三种方式,其中传统数据增强包括旋转、平移、缩放等,GAN是用形态学操作随机编辑的标签用GAN生成的
使用全数据集和20%的数据集
用Unet网络+DICE评估

13
、更具实验结果确定网络部分参数
\color{red}{13、更具实验结果确定网络部分参数}
13、更具实验结果确定网络部分参数
对于特征损失权重λ2的确定,作者是通过实验确定的,经过实验发现对于COVID-19、Hit Joint数据集λ2为10,而Ovary数据集λ2为5效果最好。作者给出的原因是因为较大的λ2意味着更多的强调高级特征的相似性、而不是像素级或结构级级L1Loss的相似。对于Ovary数据集中的样本结构边界清晰,形状规则,因此较小的λ2更适合Ovary数据集。
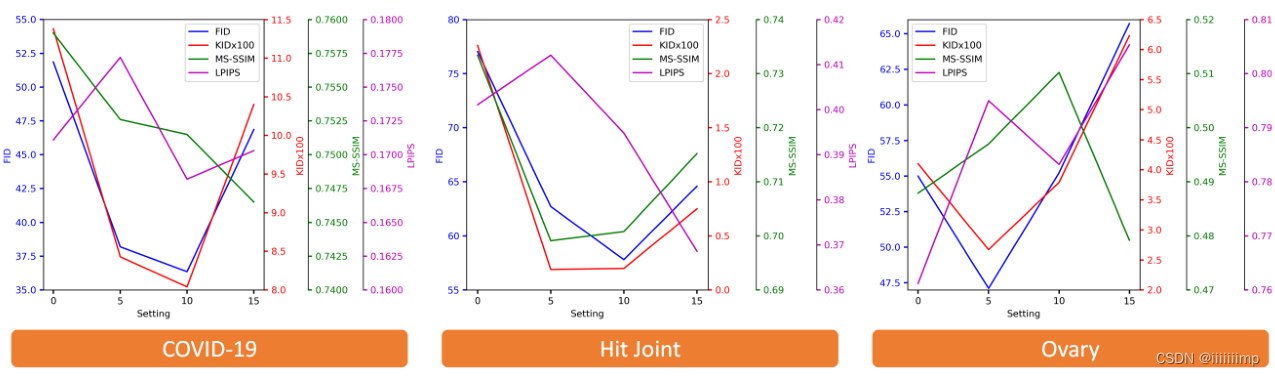
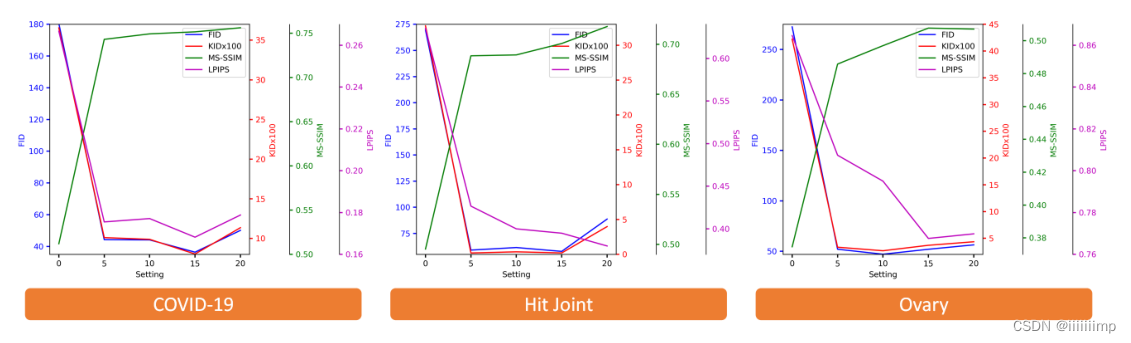
对于网络中残差块n的个数,作者也是通过实验得出来的,本来对于Hit Joint数据集n=20的时候MS-SSIM和LPIPS最高但是n=15的时候人眼看上去最好,因此作者最终选择了n=15,这也表明人眼视觉的效果是第一评价指标,而其他的方法都是参考。
对于Voary数据集n=10,作者给出的解释是因为G中残差块较多,学习能力越强,然而过多的残差快往往会降低效果。所以对于Voary数据集这种纹理比较简单的样本,选择较少的残差块是比较好的。
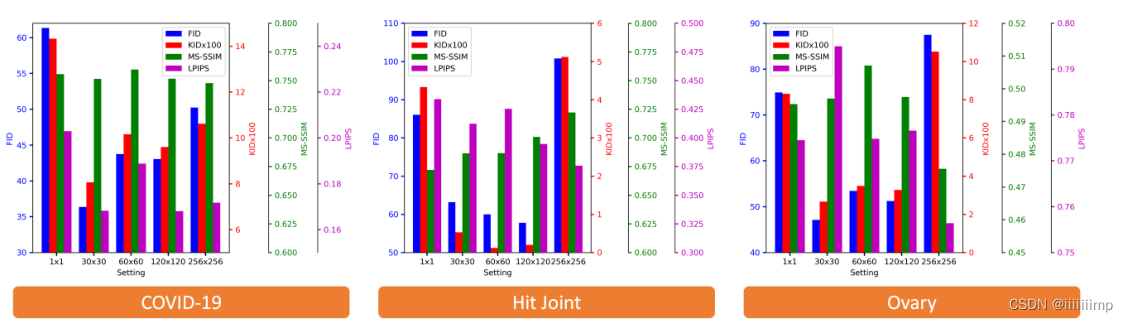
PatchGAN的输出大小也是做实验得出来的,反正1 * 1的一定不好
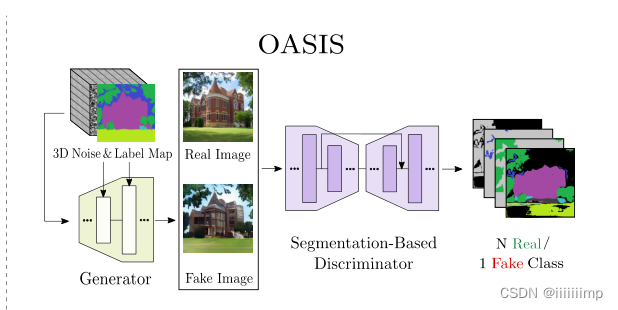
(OASIS)YOU ONLY NEED ADVERSARIAL SUPERVISION FORSEMANTIC IMAGE SYNTHESIS
2021图像翻译SOTA。
蓝色字代表作者的想法
\color{blue}{ 蓝色字代表作者的想法}
蓝色字代表作者的想法
红色字代表作者的创新
\color{red}{ 红色字代表作者的创新}
红色字代表作者的创新
1
、创新点
\color{red}{1、创新点}
1、创新点
(1)提出了一个新的基于分割的鉴别器网络结构,该结构为G提供了更强大的反馈,并且没有使用感知损失。
(2)提出了一种简单的3D噪声采样方案,显著增加了多模态合成的多样性。
2
、感受野损失的缺点
\color{blue}{2、感受野损失的缺点}
2、感受野损失的缺点
感知损失虽然效果好,但在训练的时候容易压过对抗损失,让模型更看重感知损失,从而导致生成图像的多样性和质量下降。
3
、多尺度鉴别器的缺点
\color{blue}{3、多尺度鉴别器的缺点}
3、多尺度鉴别器的缺点
传统的多尺度鉴别器,将label和image并且一起作为输入,然后做全局的增加判断。这种鉴别器无法表示高保真度的图像细节以及无法保证label和image的精准对齐。
4
、
S
P
A
D
E
生成器的缺点
\color{blue}{4、SPADE生成器的缺点}
4、SPADE生成器的缺点
SPADE生成器用的1D噪声作为输入,这样容易造成G完全忽略输入的1D噪声。解决的方法就是使用一个编码器用一张图片输入得到一个1D噪声,但是这样做的缺点就是编码器会消耗额外的内存。
5
、
O
A
S
I
S
鉴别器
\color{red}{5、OASIS鉴别器}
5、OASIS鉴别器
作者将鉴别器的鉴别任务转变为一个多类语义分割任务,将真实/生成图片作为D的输入,输出为分割图,用真实分割图为标签进行监督。因为要进行分割任务,所以鉴别器网络结构也改为Unet的结构。
D的分割任务是用语义标签作为GT,预测给定图片的类别,D除了预测输入图片的N个语义类别之外,还会多预测一个类别,这个类别是D觉得图像中假的部分,所以一共会预测N+1个类别。使用N+1类交叉熵损失进行训练。
由于N个语义类大小不同,有些语义类很小,因此作者根据每个语义类像素频率对每个类进行加权,从而赋予稀有语义类更多的权重。其中ac是类别平衡权重,ac是图片像素出现频率的倒数。
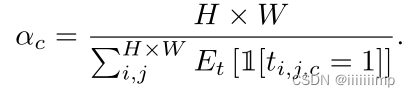
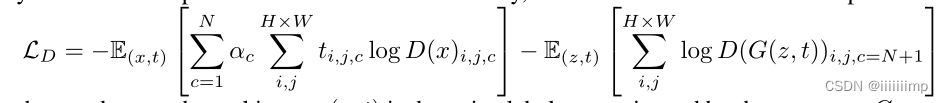
6
、标签混合正则化
\color{red}{6、标签混合正则化}
6、标签混合正则化
为了让D能更好的区分真图片x和假图片x ^的内容和结构。作者提出了一共标签混合正则化,先生成一张二值图M来将x和x ^融合为一张图片,输入到鉴别器之中做分割。
这个公式效果如下图
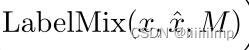

7
、内容损失
\color{red}{7、内容损失}
7、内容损失
将标签混合的图像给D与D对真假图分割后再进行标签混合正则化的结果进行L2Loss,从而得到内容损失。用内容损失鼓励生成器生成更加自然的分割边界,以及提高图像的真实性。
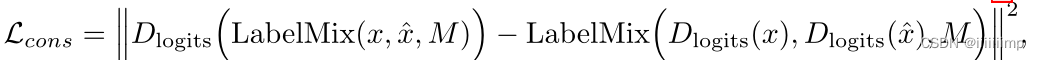

8
、
O
A
S
I
S
生成器
\color{red}{8、OASIS生成器}
8、OASIS生成器
SPADE的多模态设计采用了一共编码器结构,作者提出了一个更加简单的方案,将64 * H * W的noise与label拼接送入G。从而实现只要操控noise就能实现生成图像的控制。为了进一步降低复杂度,作者还去掉了生成器中的第一个残差快以此来降低参数量,并且没有损失什么性能。

9
、评价指标的是使用
\color{red}{9、评价指标的是使用}
9、评价指标的是使用
用FID评价图像的质量与多样性
用mIoU评价image与label的对齐情况
用颜色直方图评价real和fake的颜色
用卡方距离评价real和fake的纹理
10
、特征匹配损失有消极的影响,
E
M
A
则能提高损失精度。
\color{red}{10、特征匹配损失有消极的影响,EMA则能提高损失精度。}
10、特征匹配损失有消极的影响,EMA则能提高损失精度。
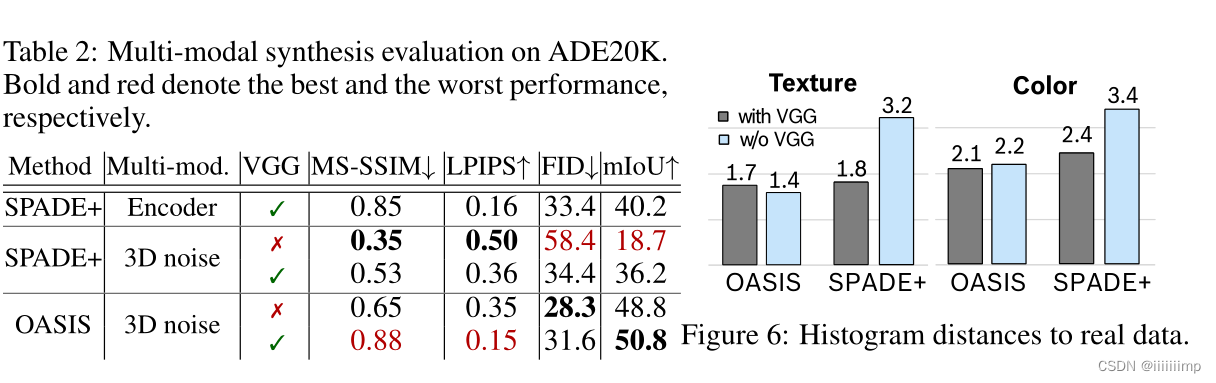
作者去掉特征匹配损失再加上EMA作为SPADE+,然后发现特征匹配损失有消极的影响,EMA则能提高损失精度。而OASIS只使用对抗损失就能达到很高的精度。
11
、
3
D
N
o
i
s
e
与感知损失的关系
\color{red}{11、3DNoise与感知损失的关系}
11、3DNoise与感知损失的关系
3DNosie以图像质量为代价改善图像多样性,而感知损失以图像多样性为代价改善图像代价。
12
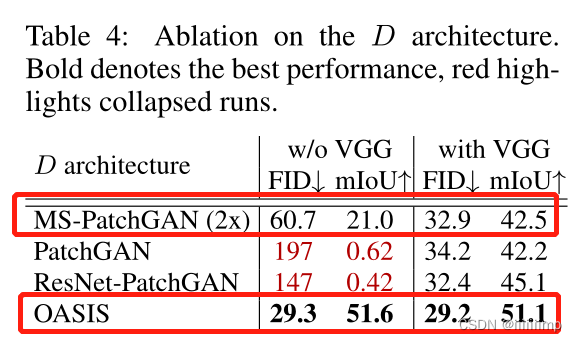
、鉴别器结构的选择
\color{red}{12、鉴别器结构的选择}
12、鉴别器结构的选择
作者分别使用了多尺度鉴别器(就是多个PatchGAN),PatchGAN,Resnet-based鉴别器,OASIS鉴别器。发现OASIS鉴别器最好、多尺度鉴别器次优。
13
、加入
3
D
N
o
i
s
e
没有提高
F
I
D
,而提高了
S
S
−
S
S
I
M
\color{red}{13、加入3DNoise没有提高FID,而提高了SS-SSIM}
13、加入3DNoise没有提高FID,而提高了SS−SSIM
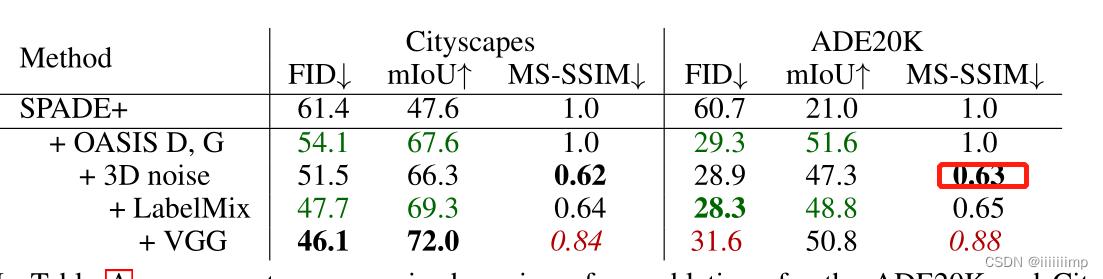
14
、
O
A
S
I
S
的鉴别器只使用了一个
\color{red}{14、OASIS的鉴别器只使用了一个}
14、OASIS的鉴别器只使用了一个
之所以只使用一个D是因为OASIS的D是U-net结构,已经存在多尺度信息了,所以用两个是多余的。
15
、
3
D
N
o
i
s
e
不被忽略的原因
\color{red}{15、3DNoise不被忽略的原因}
15、3DNoise不被忽略的原因
一是因为噪声加到了每一层,二是3Dnoise有空间一致性。
16、代码:https://github.com/hahahappyboy/GAN-Thesis-Retrieval/tree/main/OASIS
(1)生成器
OASIS的生成器还是主要参考了SPADE,只不过就是去掉了编码器部分,换为了随机噪声
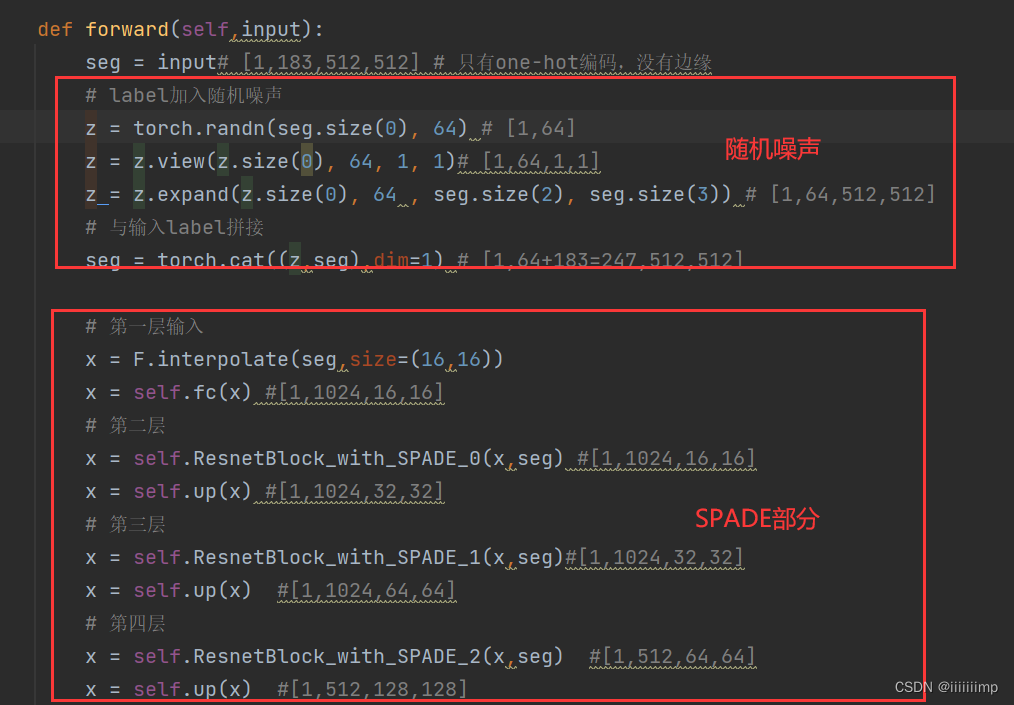
(2)鉴别器
鉴别器是Unet的结构
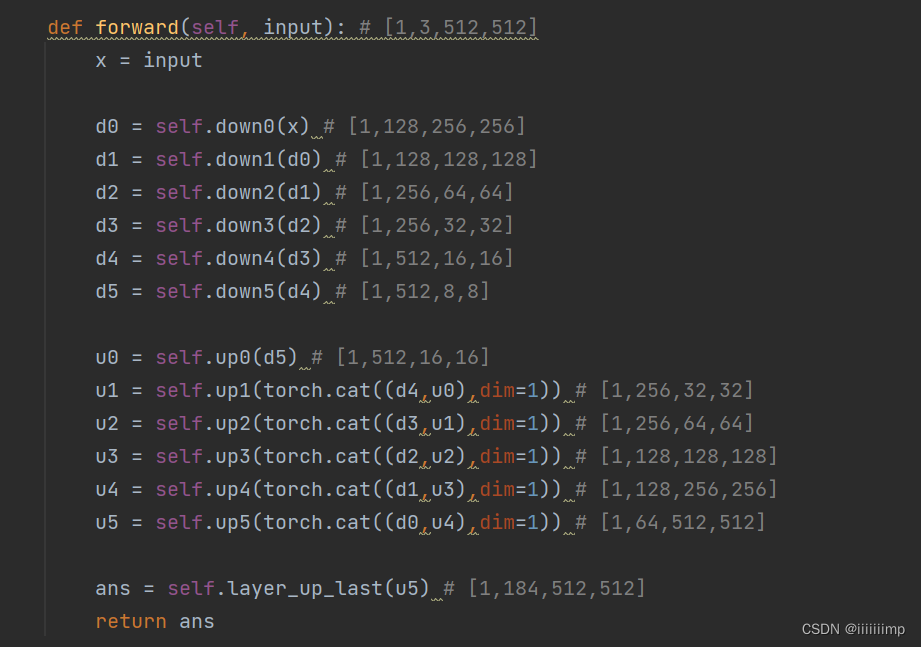
不同的是,这里并不是使用的全卷积网络,下采样用的AvgPool2d上采样用的是Upsample,且每层都有跳跃连接

(3)没有使用VGGLoss
(4)对抗损失
首先获取类别权重,需要注意的是作者把第0类归为0代表不关心的类别,这也对应cityscapes数据集第0类为unlabel类别。
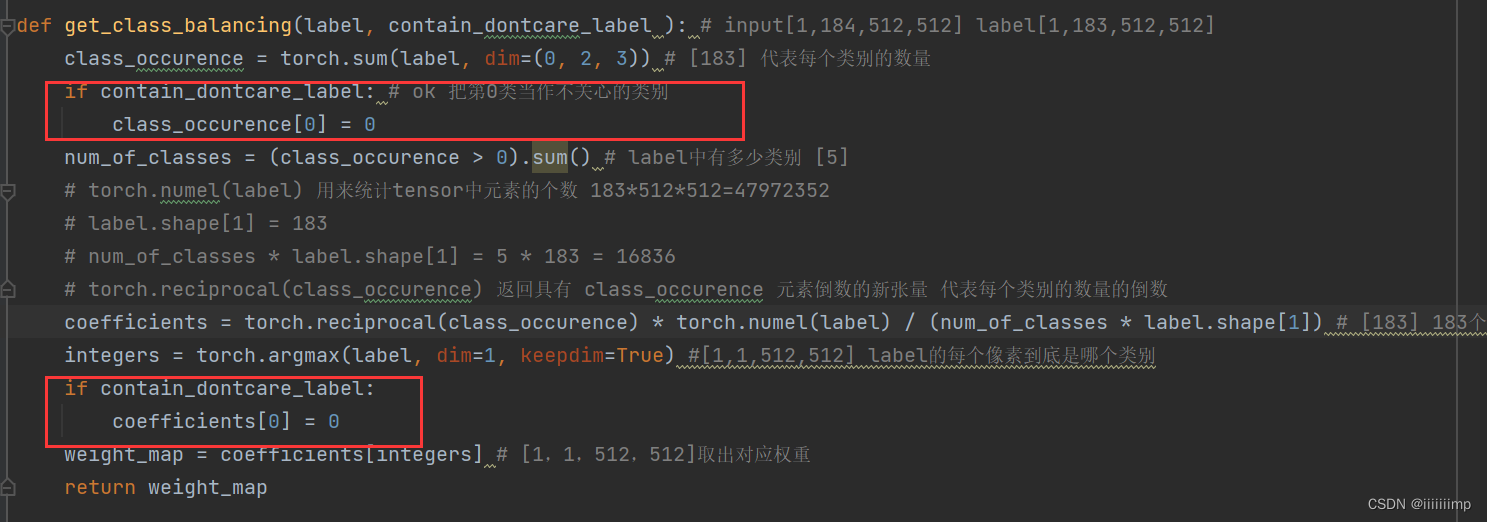
得到目标类别,即label到底是到底是哪一类,然后做交叉熵分类。训练鉴别器的时候因为要求生成器的为假,所以target的值全为0
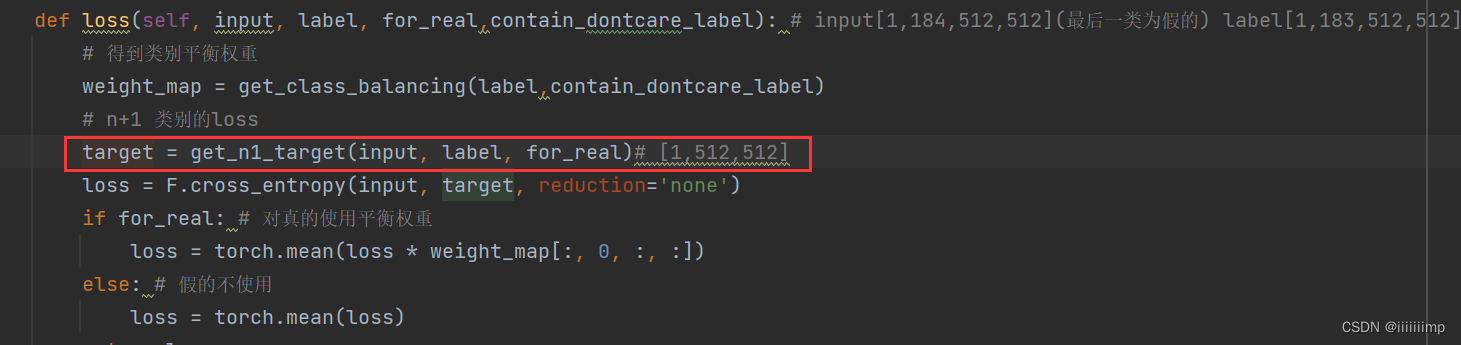
这里着重说一下这个get_n1_target函数,感觉这是作者的精髓所在
当训练生成器时(生成器希望鉴别器以为给它的是真图,但其实是生成器生成的假图)或则用真图训练鉴别器时,都是希望鉴别器全部分割出来,让鉴别器用于寻找假图的那一维度全为0。拿cocoStuff这个数据集举例子,这个数据集一共有183个种类,所以鉴别器输出的维度为[1,184,512,512]。代码中,用于判断假图的维度为第0维,而1 ~ 183维度用于分割真图,而不少论文中的第N+1维度用来判断假图、第1 ~ N维度用来分割真图。所以当训练生成器时或则用真图训练鉴别器时,代码中的return的integers的数值范围其实是1 ~ 183 。而不是0 ~ 182 。而当用假图训练鉴别器的时候return的integers的数值全为0,即要求鉴别器全部判定为假图,假图被放在第0维度,而不少论文中的第N+1维度,这一点和论文有点出入。

(5)标签混合的内容Loss
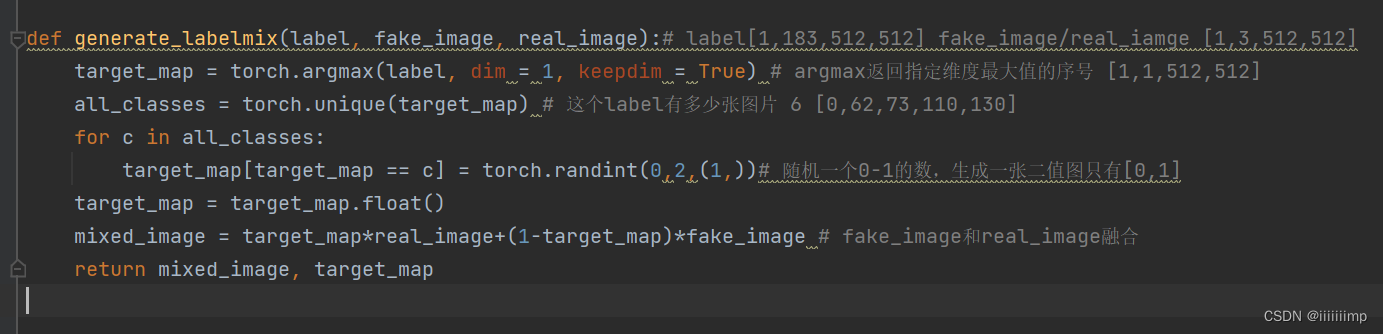
鉴别器处理判断真假的对抗Loss以外还有标签混合Loss,和论文说的一样,产生一个随机的二值图,再通过乘法把fake_image和real_image融合起来

(6)关于预处理作者用了一个只用来one-hot编码、每加边缘信息。且one-hot编码于你标签值一一对应,例如如果标签值为0的像素,那一定全是是one-hot编码后的的0维度。
具体可以去看看https://github.com/hahahappyboy/GAN-Thesis-Retrieval/tree/main/OASIS%20Loss
(StyleGAN2)Analyzing and Improving the Image Quality of StyleGAN
StyleGAN2永远滴神。
蓝色字代表作者的想法
\color{blue}{ 蓝色字代表作者的想法}
蓝色字代表作者的想法
红色字代表作者的创新
\color{red}{ 红色字代表作者的创新}
红色字代表作者的创新
1
、创新点
\color{red}{1、创新点}
1、创新点
(1)重新设计了生成器的调制和解调模块,消除了伪影。
(2)延迟正则化,降低计算量
(3)路径长度(PPL)正则化,提高生成图像的质量
(4)去掉渐进式增长,生成器和鉴别器采用不同架构解决移位不变性。
(5)扩大网络规模,提高生成质量。
2
、消除因归一化导致的伪影
\color{red}{2、消除因归一化导致的伪影}
2、消除因归一化导致的伪影
作者认为人工伪影的的产生是因为AdaIN会把上层传下来的信息摧毁。生成器为了让信息不被AdaIN摧毁,于是就产生了一个很强的信号(伪影)强行改变图像像素值的分布,让AdaIN不能轻易破坏上层信息,从而把上层信息传过AdaIN。也就是说伪影是为了抵挡AdaIN归一化对信息产生破坏而产生的。

下面是解决这个问题的思路
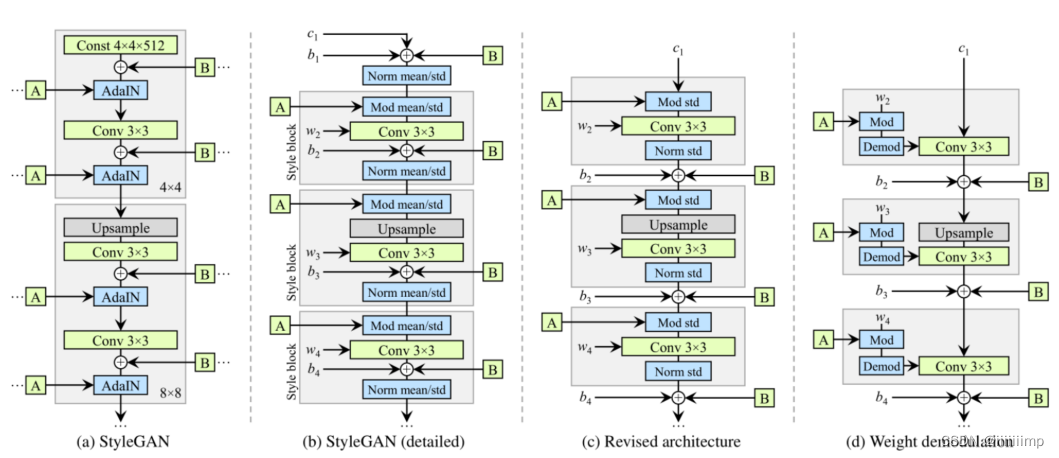
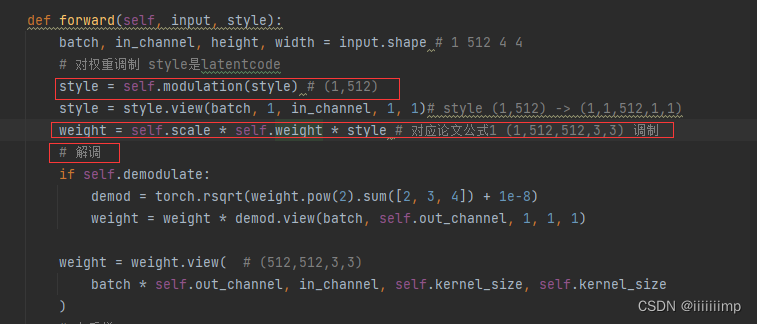
(b)是(a)的细化,可以看到AdaIN其实一个实例归一化(调制)+乘std加mean(解调)。作者把(b)中灰色块成为样式块(Style block)。作者对样式块进行修改,把偏置和Noise放在了实例归一化之后之后,并且只对标准差进行归一化和解调,从而得到©。
但是直接对特征图的调制,可以将某些特征映射放大一个数量级或更多。这并不有利于风格混合控制图像的生成(Style mixing),为了使风格混合发挥作用,就必须在每个样本的基础上明确抵消调值的放大,否则后续层将无法以有意义的方式对图像进行操作。
所以作者把对特征图的调制给位只对卷积权重的调制
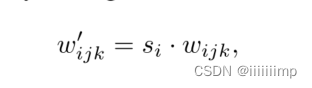
这里wijk为卷积原始权重,si为比例缩放,w’ijk为调制后的权重。接着进行解调,这是为了让卷积权重标准差、方差回归到调制之前的状态。
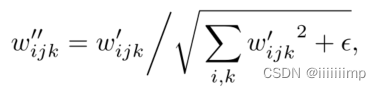
从而得到了(d)。通过以上操作,即消除了伪影,同时保持了Style完全的可操控性。
4
、延迟正则化
\color{red}{4、延迟正则化 }
4、延迟正则化
StyleGAN1中用了R1正则化,作者发现把R1正则化的频率降低为16个小batch执行1次,即降低了计算量、内存还不影响最终结果。
5
、
F
I
D
和
R
&
P
的缺点
\color{blue}{5、FID和R\&P的缺点 }
5、FID和R&P的缺点
GAN评价指标FID、R&P能成功地捕获生成器地许多方面,但是它们在图像评价上依然有缺点,FID、R&P都是基于ImageNet训练地分类器,倾向于将决策更多地基于纹理而不是形状,而人类往往更加关注形状。这就导致下图所示,即便有些图像不像猫,但是因为其有猫地纹理,FID、R&P和会给出不错的评分。

6
、路径长度
(
P
P
L
)
正则化
\color{red}{6、路径长度(PPL)正则化}
6、路径长度(PPL)正则化
作者实验发现PPL分数低,则生成的图像质量高,反之亦然。
在训练过程中,生成器提升效果最直接的方法就是让能生成好质量的图像的分布区域越大越好,而差质量区域越小越好,这样生成图像分布落在好质量区域的概率就大,自然图像平均质量就高了。但是这也导致差图像区域生成的图像失真会很严重,损害训练状态,进而损害最终图像质量。
因此作者做实验发现把PPL作为正则项加入到网络中能够改善以前生成器把生成差图像的概率降低这种情况,而是平滑生成器映射分布,让整个生成分布区域都提升,不仅仅是一块区域好,一块区域差。
做法是,当在latent space中对latent vector进行插值操作时,我们希望对latent vector的等比例的变化直接反映到图像中去。即:“在latent space和image space应该有同样的变化幅度(线性的latent space)”(比如说,当你对某一组latent vector进行了5个degree的偏移,那么反映在最后的生成图像中,应该是同样的效果, 如下图所示)。

来自https://blog.csdn.net/g11d111/article/details/109187245
7
、去掉渐进式增长
\color{red}{7、去掉渐进式增长}
7、去掉渐进式增长
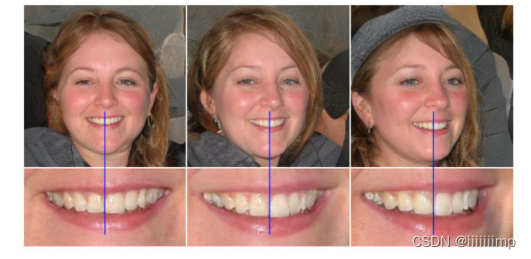
作者发现StyleGAN中渐进增长的训练方式会导致位移不变性。如下图所示,不管生成的人怎么变,牙齿的位置一直没变。作者认为由于渐进增长是让每层分辨率都作为过输出分辨率,来使生成器生成最大分辨率的细节,但是这也导致了训练的网络中间层就有较高级的特征了,然后面的层不太好改变特征的位置,所以损害了位移不变性。
因此作者在以下备选方案中进行排列组合寻找渐进增长的替代方案,最终发现跳越生成器(b)中的连接会大大改善 PPL,而残差的判别器©网络显然对 FID有利。因此作者决定用跳越生成器和残差判别器,而不使用渐进式增长。

8
、扩大网络规模
\color{red}{8、扩大网络规模}
8、扩大网络规模
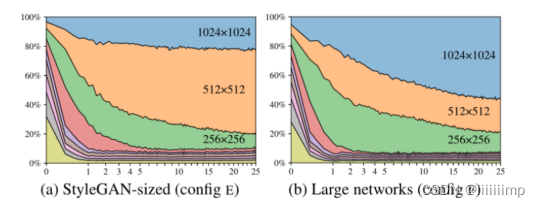
再使用了跳越生成器后,作者计算每层的tRGB(就是一张RGB的图像)对最终图像的贡献度,发现512 * 512的占比最大,也就是说最后输出的图像是以512 * 512的tRGB为主,这代表1024 * 1024 的信息并没有被充分利用,为了解决这个问题,作者通过把SytleGAN和StyleGAN2最高分辨率层特征图数量加倍来解决。
9
、代码
\color{red}{9、代码}
9、代码 https://github.com/hahahappyboy/GAN-Thesis-Retrieval/tree/main/StyleGAN2
(1)生成器结构
输入的2个style会经过同一个18层线性映射网络得到2个style,再将这两个style按比例各区一部分组合成一个[1,16,512]的latentcode。
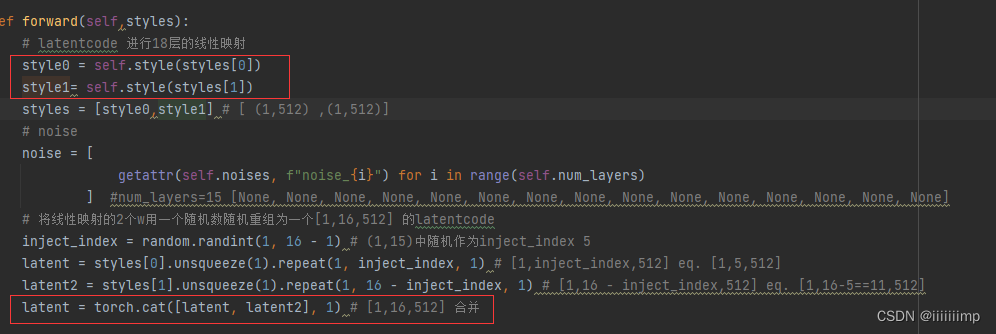
整体网络结构还是和styleGAN差不多都是对输入常量不断向上采样
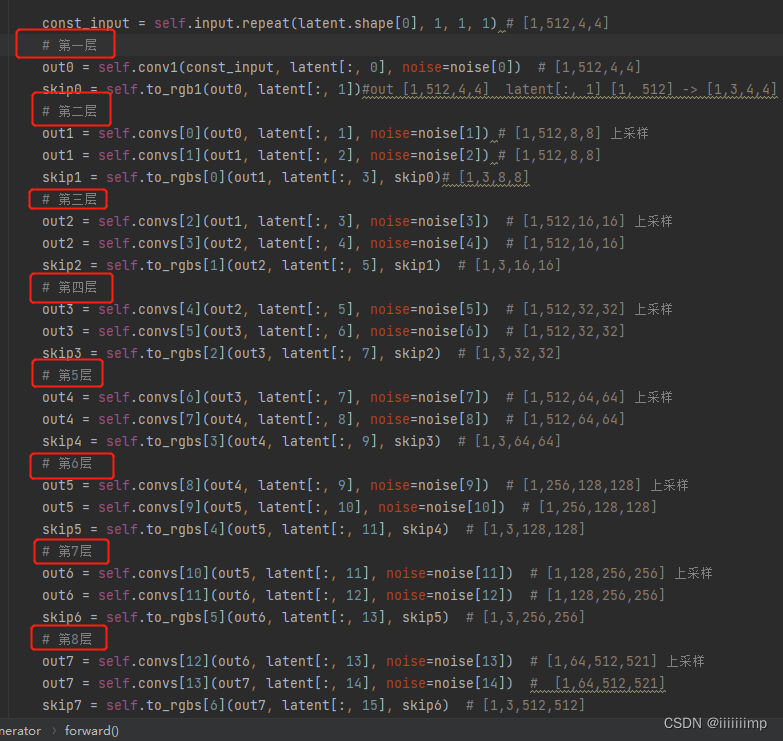
重点是卷积怎么做的,在ModulatedConv2d模块中可以看到,latentcode经过self.modulation映射为论文中图2的A后,按照公式1的方式对卷积进行调制,然后再进行解调。

之后将调制和解调后的权重拿去对常量输入做卷积。
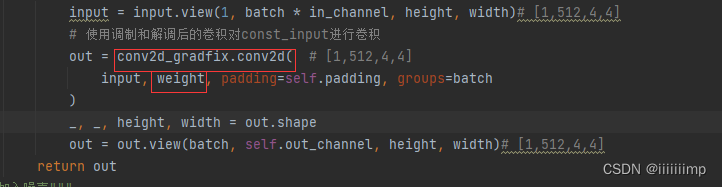
最后再加入noise,即论文图1中的B
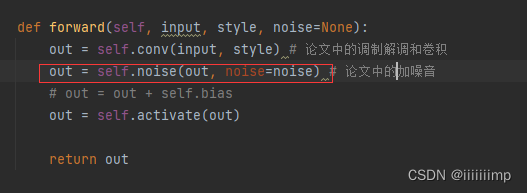
输出会被送到论文图7的tRGB模块,这个模块其实也是调制,只不过不会解调,目的是将通道压缩到3。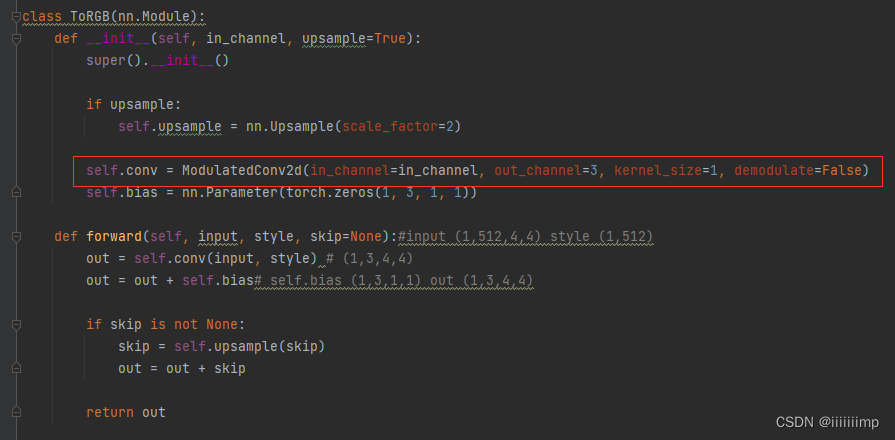
然后送到下一层,这样不断往复,直到把输入常量从[1,512,4,4]变为 [1,3,512,512]。
(2)鉴别器
主要就是resnet结构
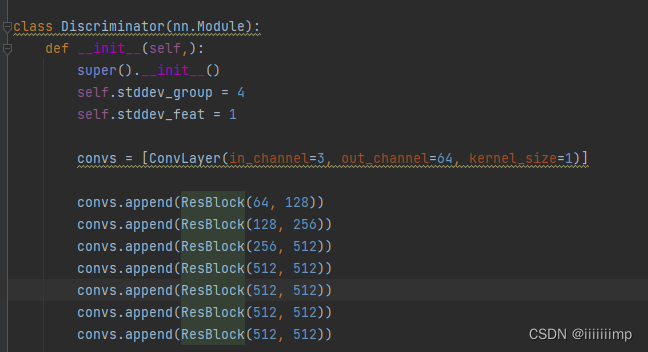
不同的是,在这几个resnet过后,作者使用了一个MinibatchStdDev模块,主要是计算一个sample的group里的标准差,计算结果拼接到resnet结果后,所以有513维度。之后拉平再用全部连接计算预测结果。
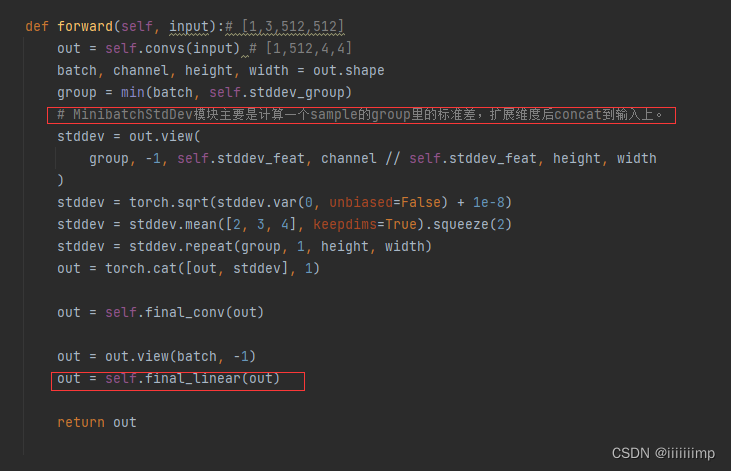
(3)训练方式
r1正则话 每d_reg_every个step一次,感知路径长度 每g_reg_every个step执行一次。
(Pixel2Style2Pixel)Encoding in Style: a StyleGAN Encoder for Image-to-Image Translation
基于StyleGANV1改进的网络可用于语义合成,Pixel2Style2Pixel简称pSp。
蓝色字代表作者的想法
\color{blue}{ 蓝色字代表作者的想法}
蓝色字代表作者的想法
红色字代表作者的创新
\color{red}{ 红色字代表作者的创新}
红色字代表作者的创新
1
、创新点
\color{red}{1、创新点}
1、创新点
(1)提出了一个pSp编码器用于StyleGAN,能直接将真实图像编码为StyleGAN的W+向量,用于控诉生成图像的细节。
(2)使用LPLIP损失代替感知损失PerceptualLoss更能保护图像质量
(3)使用身份损失,为了保证输出是人脸
(4)将语义图像生成通过pSpEncoder生成的WI和随机采样的WR进行样式混合组成新的W,实现多模态。
(5)为了让网络不关心生成的背景,而是更多的关注生成的人物,作者面部将LPIPSLoss和L2Loss调大,而背景着将两者调小。
2
、以前方法的缺点
\color{blue}{2、以前方法的缺点}
2、以前方法的缺点
以前有些方法通过把图像转为一个W,把这个W复制18份给StyleGAN每层,但此方法效果不小,生成的细节不多。一个改进的方法就是生成18个W,组成W+,给StyleGAN,但是这样太费时间了。因此作者提出了仅使用一个编码器就将一个图像转为了W+,大大节约了时间,而且效果还好。
3
、
p
S
p
网络架构
\color{red}{3、pSp网络架构}
3、pSp网络架构
pSp需要预训练StyleGAN。
传统而直接的方案是直接使用encoder最后一层的512维向量直接repeat18次,但是这会导致编码生成地很随意,表征不够丰富,生成缺乏细节。
StyleGAN在合成网络中不同层的W实际代表了不同层次的特征,大致可以分为三组coarse、medium和fine。借鉴了该思路,psp在模型结构中使用FPN(特征金字塔网络结构)来实现pSp的encoder,生成了三种不同level的特征。
作者也试了直接从最大的特征图李生成所有的W+,可以取得相似的效果,但是会影响模型的大小。也可以从最小的特征图生成所需要的W+,在足够维度下也能保证性能。
如图FPN的解码器被分为coarse、medium和fine三组。最上面的0-2的map2style为coarse组,用于控制生成器小的特征图的Style,同理3-6为medium、7-18fine。
map2style为全卷积网络,输出一个512的向量W,给A做仿射变换。
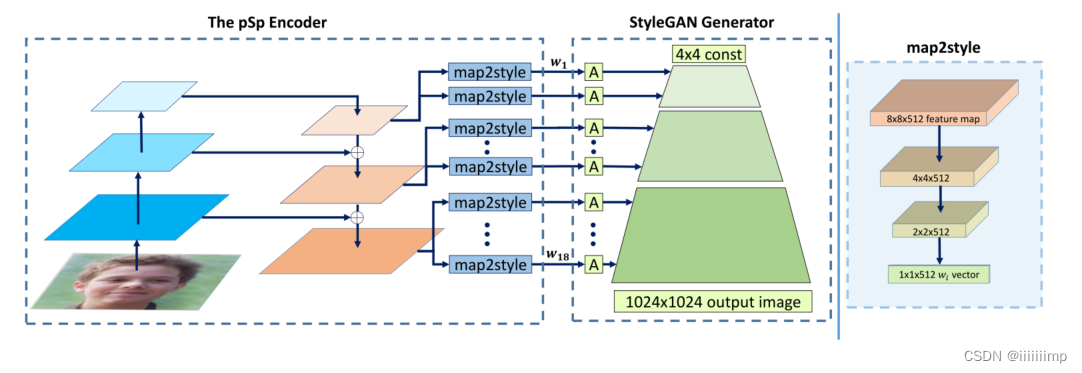
4
、损失函数
\color{red}{4、损失函数}
4、损失函数
L2Loss作为GANLoss
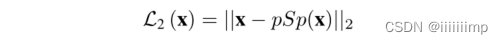
作者认为LPLIP损失比感知损失Perceptual更能保护图像质量,F为感知特征提取器
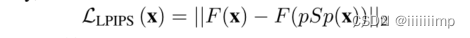
身份损失,为了保证输出是人脸,引入了身份损失。
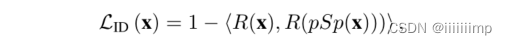
总损失为三者相加
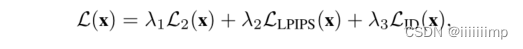
5
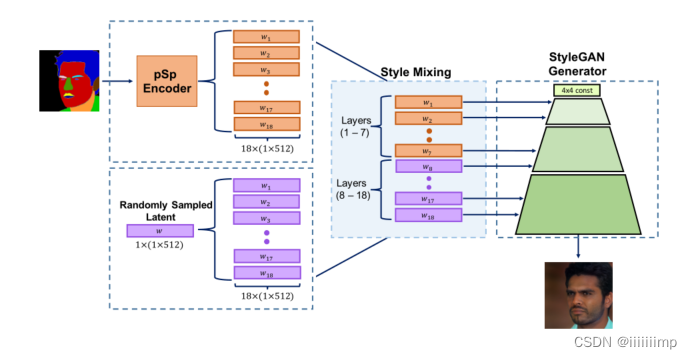
、语义合成的多模态
\color{red}{5、语义合成的多模态}
5、语义合成的多模态
作者想StyleGAN实现的解纠缠是通过W+的分成表示实现的。这种独立控制Style的方法应该也可以用于多模态。
如图,将语义图像生成通过pSpEncoder生成的WI和随机采样的WR进行样式混合组成新的W,其中1-7层用WI,8-18层用WR,这样底层就能保证角色大体轮廓不变,高层能出现细节差异,从而实现多模态。
注意,在语义合成中,作者没有用身份损失,
6
、让网络不关心背景
\color{red}{6、让网络不关心背景}
6、让网络不关心背景
为了让网络不关心生成的背景,而是更多的关注生成的人物,作者面部将LPIPSLoss和L2Loss调大,而背景着将两者调小。
7
、不足
\color{blue}{7、不足}
7、不足
(1)pSp因为要用到StyleGAN预训练模型,所以如果StyleGAN没有训练过的类型图片就没法生成高质量的图片
(2)pSp更关注全局,所以细节还不够
8
、代码
\color{red}{8、代码}
8、代码
见https://github.com/hahahappyboy/GAN-Thesis-Retrieval/tree/main/Pixel2Style2Pixel
(1)注意,pSp网络是没有鉴别器的,只有生成器。生成器是由编码器encoder和解码器decoder组成,decoder就是StyleGAN2的代码,完全没改,可以见我复现的StyleGAN2的代码。唯一变的就是StyleGAN2的latent code不再是来自18层全连接后的。而是由encoder提供。所以我们重点讲encoder,这也是作责的创新部分。
(2)encoder网络结构
输入是mask语义图
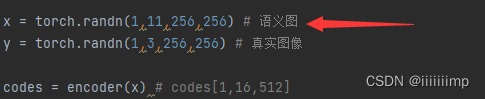
然后经过这么多个bottleneck_IR_SE,bottleneck_IR_SE就是resnet结构。所有bottleneck_IR_SE一共分为低中高3个阶段分界线为第6、20、23个bottleneck_IR_SE。可以认为是FPN结构中coarse、mid、fine的分界点,但是这个FPN结构只有下采样,没有上采样。这个过程使得输入从[1,11,256,256]下采样到[1,512,16,16]
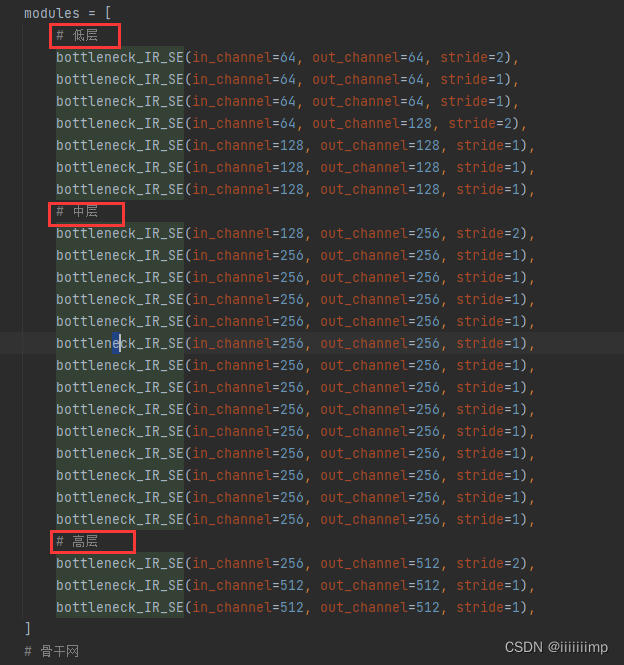
取出第6、20、23个bottleneck_IR_SE的feature map用于生成最终的w。这一部分对应论文图2中map2style的左边部分。
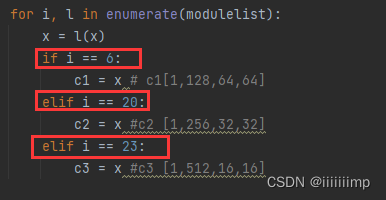
把这3组feature map送人map2style得到w。同理map2style也是分了3组的,总共有16个map2style,正好对应StyleGAN2的16层。
 map2style就是几个卷积后再经过全连接,得到一个[1,512]大小的w
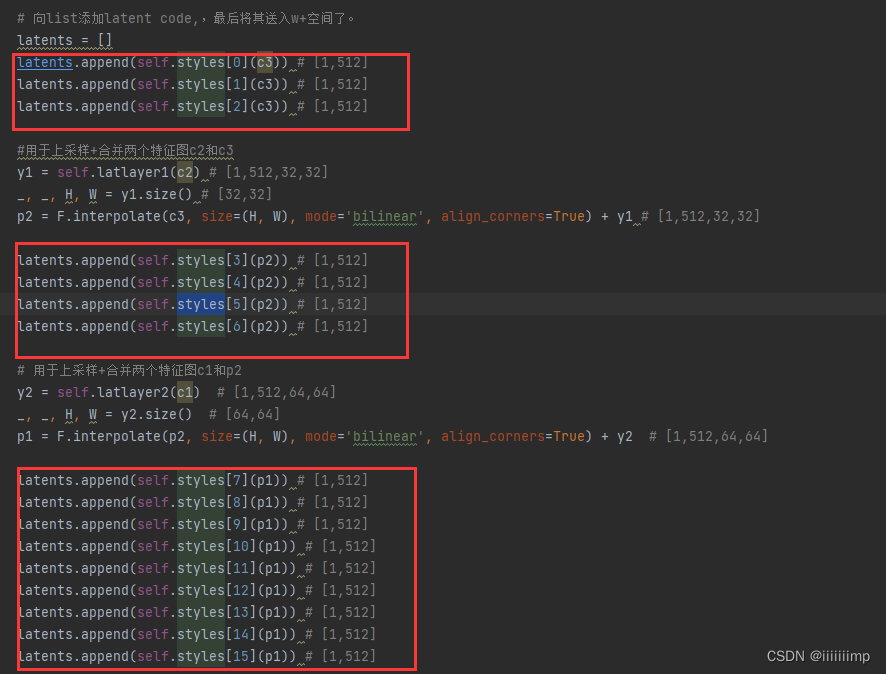
map2style就是几个卷积后再经过全连接,得到一个[1,512]大小的w
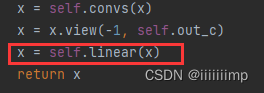
最后将16个[1,512]的w组成[16,512]大小作为latent code送给StyleGAN2
(3)不关心背景
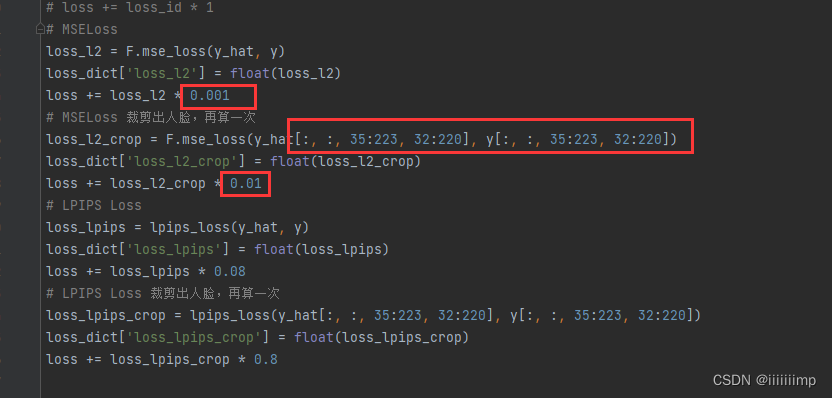
作者所谓的让网络不关心背景,就是把生成图的中间部分截取出来再多计算一次损失。
(SEAN)SEAN: Image Synthesis with Semantic Region-Adaptive Normalization
也是基于SPADE修改的
蓝色字代表作者的想法
\color{blue}{ 蓝色字代表作者的想法}
蓝色字代表作者的想法
红色字代表作者的创新
\color{red}{ 红色字代表作者的创新}
红色字代表作者的创新
1
、创新点
\color{red}{1、创新点}
1、创新点
1、提出了语义区域自适应归一化(SEAN)可以单独控制每个图像的边界,并且生成的图像质量更高。
2
、
S
P
A
D
E
的优缺点
\color{blue}{2、SPADE的优缺点}
2、SPADE的优缺点
(1)SPADE只用一种style code来控制图像生成的整个风格,这样无法生成高质量的图像,这里应该是指SPADE的Encoder编码器输出的style code作为SPADE生成器的输入。这导致了SPADE无法控制mask的不同区域。因此作为的第一个改进是实现对mask每个颜色区域的单一控制,让每个mask区域都能使用一种风格图像作为输入。
(2)SPADE只在网络开头加入style code,但styleGAN证明在网络中间层加入style信息可以提高风格质量。因此作者提出了SEAN模块,其可以使用风格输入图像为每个语义区域创建空间上不同的归一化函数。
3
、如何实现
m
a
s
k
每个区域的编码与控制?
\color{blue}{3、如何实现mask每个区域的编码与控制?}
3、如何实现mask每个区域的编码与控制?
作者根据如何实现mask每个区域的编码与控制,提出了两步骤战略
(1)如何根据mask提取每个区域风格?
(2)如何根据mask提取到的每个区域编码风格合成逼真图像?
解决方法见下面4、5
4
、如何根据
m
a
s
k
提取每个区域风格?
\color{red}{4、如何根据mask提取每个区域风格?}
4、如何根据mask提取每个区域风格?
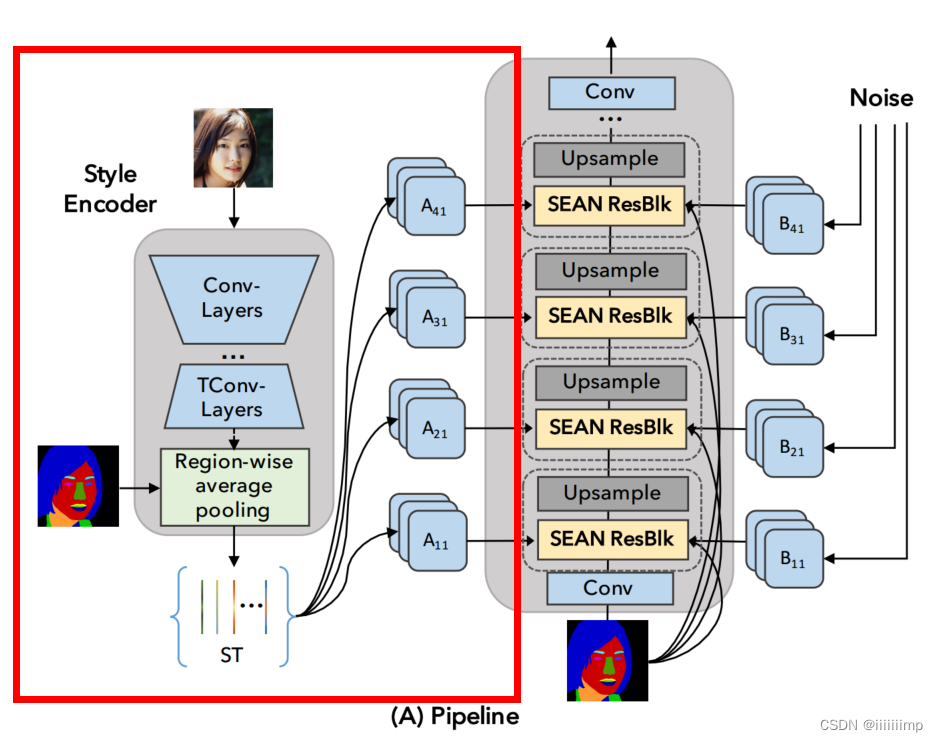
为了提取每个区域的风格,作者提出了一种新的风格编码器网络,从输入图像的每个语义区域提取相应的风格代码。
输入风格图像(真人图)经过下采样(Conv-Layers)后到达一个“瓶颈”结构网络块(TConv-Layers),从输入图像中删除与风格无关的信息。结合风格应该独立于语义区域形状的先验知识,TConv-Layers生成的中间特征图(512通道)通过区域平均池化层(Region-wise average pooling),并将其降为512维向量的集合,从而得到风格矩阵。
得到的风格矩阵ST大小为512 × s,s为输入图像中语义区域的数量,矩阵的每一列都对应于语义区域的样式代码。
5
、得到风格矩阵后如何控制生成图像的风格?
\color{red}{5、得到风格矩阵后如何控制生成图像的风格?}
5、得到风格矩阵后如何控制生成图像的风格?
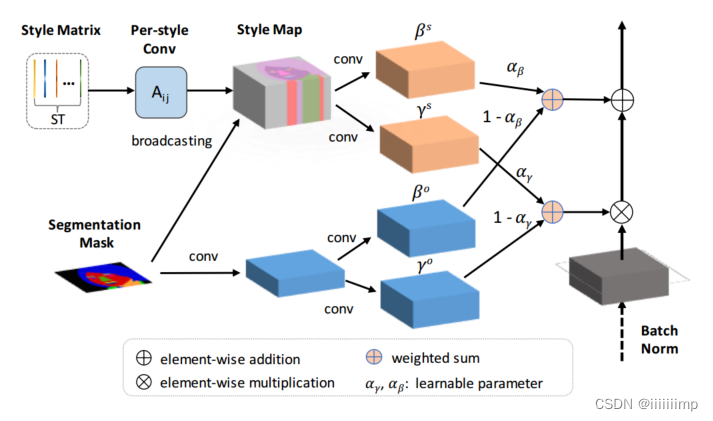
为了解决这个问题作者提出了SEAN归一化。
风格矩阵ST进行逐风格卷积(Per-style)后,根据mask广播(broadcasting)到相应语义区域,得到StyleMap。StyleMap通过两个分别的卷积层生成归一化所需参数scalse和biases即γs和βs,这是上半部分,下班部分就是SPADE的归一化。
SEAN的归一化方式和SPADE一样的只是参数γ和β的来源变了,SEAN的来源是风格矩阵ST和mask,而SPADE的归一化来源只有mask。
6
、生成器网络结构
\color{red}{6、生成器网络结构}
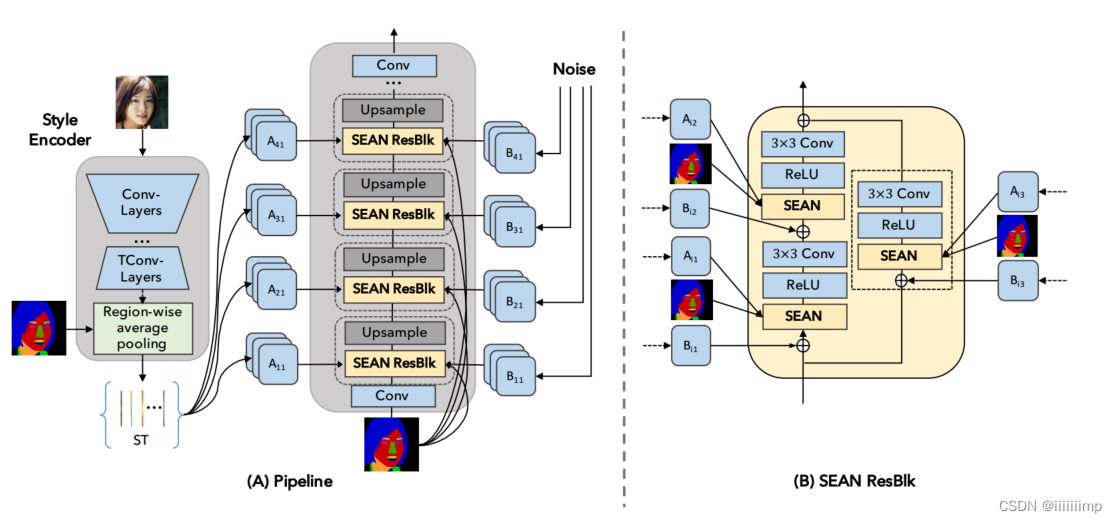
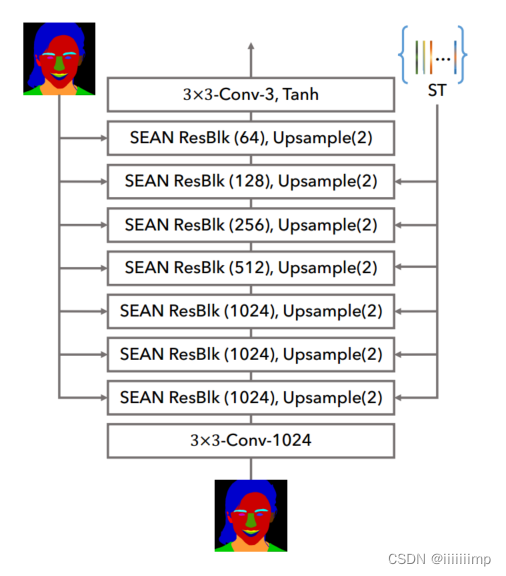
6、生成器网络结构
左边是生成器网络结构,右边是SEAN块,这里着重说SEAN块内部结构,经典resnet结构
每个SEAN块有两个输入,每个区域的风格矩阵 ST和mask M。
输入的mask下采样到同一层中特征图相同的宽高。ST进入1 × 1的conv层Aij对每个区域进行风格控制。作者认为初始的风格控制(应该是网络底层的Aij,如A11,A21等)是不可或缺的,早期的层可能控制人脸图像的发型(如波浪,直发),而后期的层可能指的是灯光和颜色。
此外,在SEAN的输入中加入噪声可以提高合成图像的质量,类似于StyleGAN 。
风格矩阵ST指在前六个SEAN块输入,这也对应了作者说前期的风格控制比较重要。
5.5
、鉴别器
\color{red}{5.5、鉴别器}
5.5、鉴别器
鉴别器没做什么改变
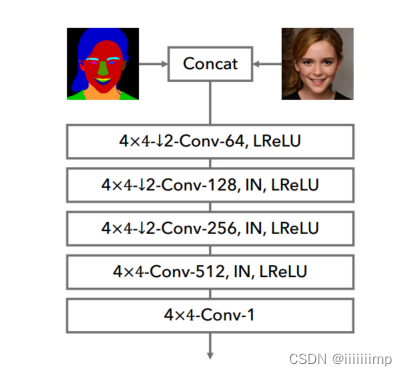
6
、
L
o
s
s
\color{red}{6、Loss}
6、Loss
训练的时候所有输入image的大小为256 * 256
GANLoss+特征匹配Loss+感知损失
7
、定量质量评价
\color{red}{7、定量质量评价}
7、定量质量评价
(1)mIou和accu衡量分割准确度,越高越好
(2)FID,越低越好
(3)SSIM结构性相似度,越高越好
(4)PSNR峰值信噪比,越高越好
(5)RMSE均方根误差,越低越好

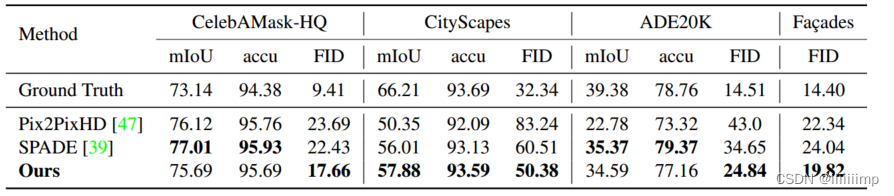
8
、定性评价
\color{red}{8、定性评价}
8、定性评价
SPADE和Pix2PixHD不能处理更极端的姿势和老年人。作责推测,由于改进了样式编码器,作者的网络更适合学习更多数据的可变性。

9
、代码
\color{red}{9、代码}
9、代码
见https://github.com/hahahappyboy/GAN-Thesis-Retrieval/tree/main/SEAN
SEAN主要就是生成器的结构很复杂
(1)提取风格矩阵ST
输入的是rgb真实图像和segmap

论文中的ConvLayers和T-ConvLayers就是一个encoder和decoder结构
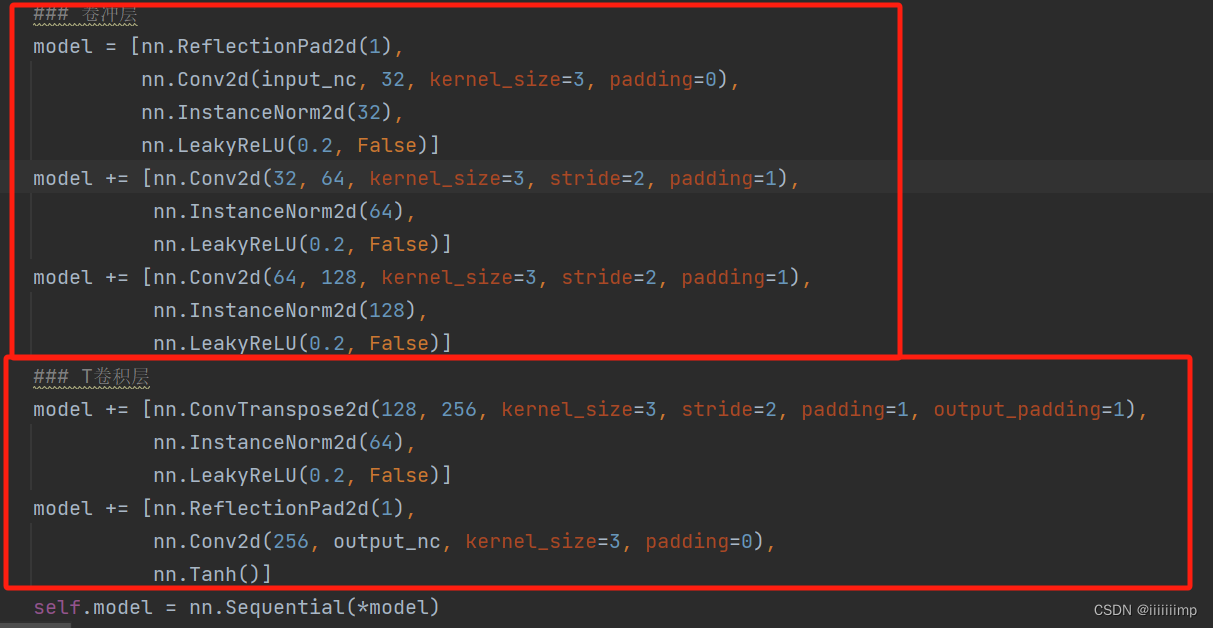
将真实图像[1,3,512,512]编码为[1,512,256,256]的风格无关特征图

之后就是将风格无关特征图codes[1,512,256,256]和缩放后的语义图Segmap[1,512,256,256]编码为风格矩阵ST的步骤为
1)遍历语义图每个通道j,这里假设one-hot编码后的语义图有12个通道。统计通道j中值为1的像素个数
2)如果像素个数>0说明该通道有语义信息,所以要编码该区域
3)设在语义图Segmap的通道j中为1值的位置(x,y),然后取出codes中(x,y)的值。例如假设语义图Segmap的通道j中为1值有35783,那么取出codes中(x,y)的值就有[512, 35783],从而得到codes_component_feature [512, 35783]
4)然后对codes_component_feature 按维度1平均池化得到[512]。
5)这个[512]的向量就是真实图像在语义图第j个语义通道的风格编码向量
6)语义图有12个通道,所以会得到12个风格编码向量,大小就为[1,12,512],这就是风格矩阵ST
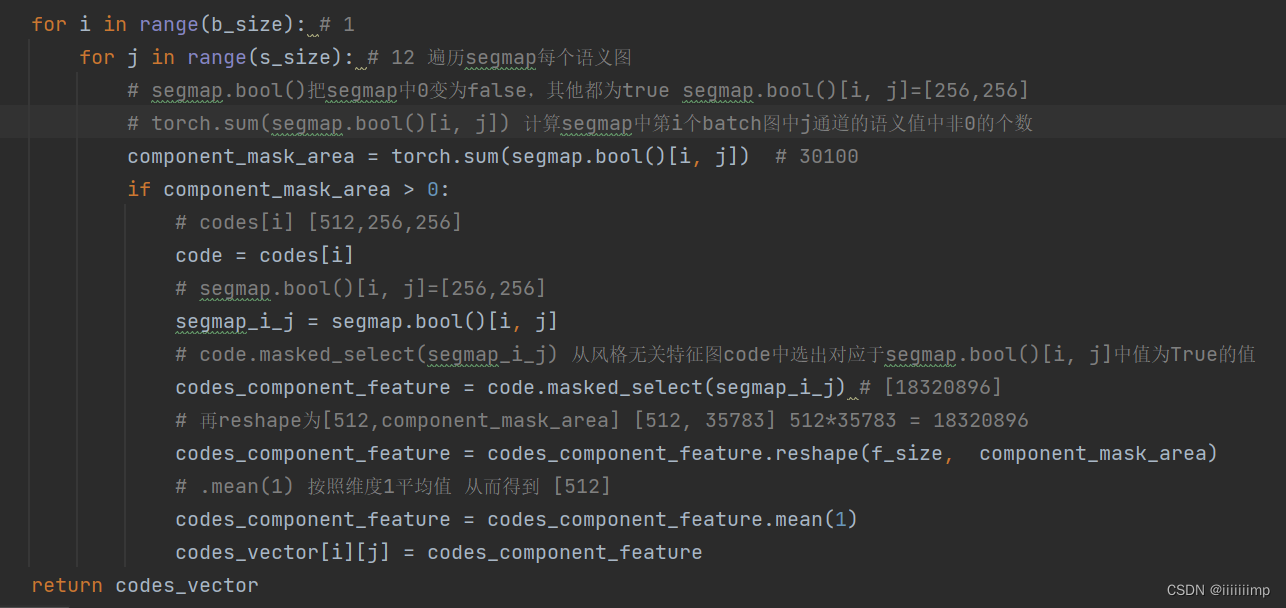
(2)SEAN归一化
在得到风格矩阵ST后,论文叫style_codes
就将其style_codes和语义图seg,上一层特性图x送入到SEAN模块中。假设上一层特征图为[1,1024,16,16],seg缩放后为[[1,12,16,16]
SEAN模块整体看就是残差结构
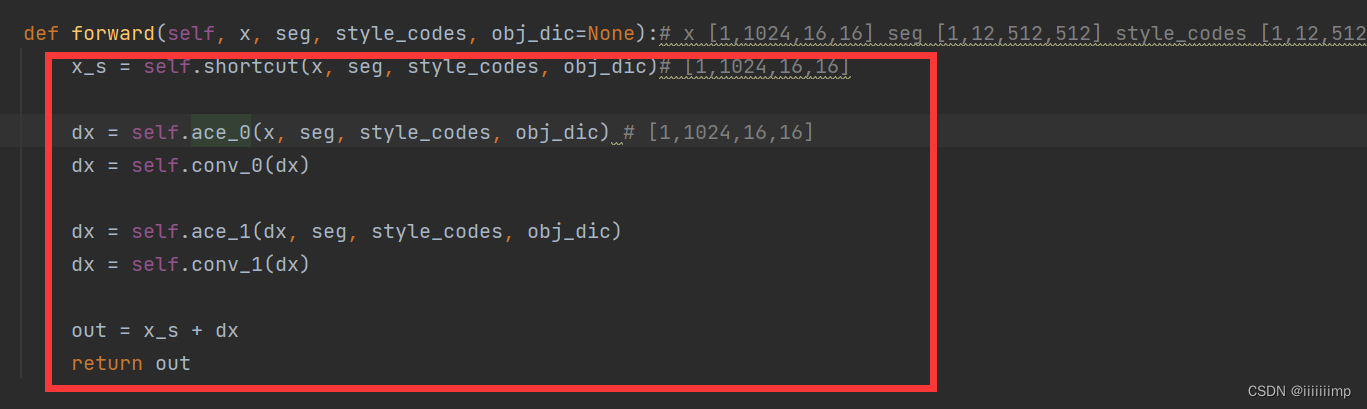
SEAN归一化在论文中叫ACE模块
首先是给上一层特性图x加上StyleGAN的Noise

假设语义图seg的j通道有104个值为1的像素
SEAN归一化就是先将第j个语义的风格向量[512]经过一个全连接j(这个全连接j只用于第j个语义向量),论文中应该叫风格卷积。
然后复制104份(论文中叫广播)得到component_mu [512,104]
最后将语义图seg中j通道值为1的104个值用风格图的值替换。从而得到风格图(Style Map)middle_avg [1,512,16,16]
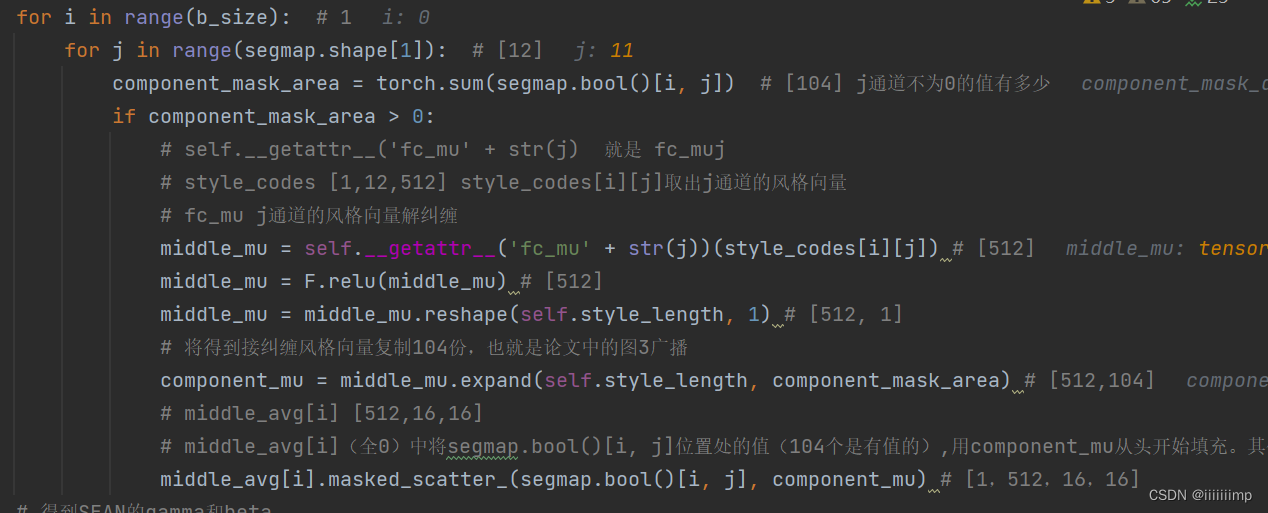
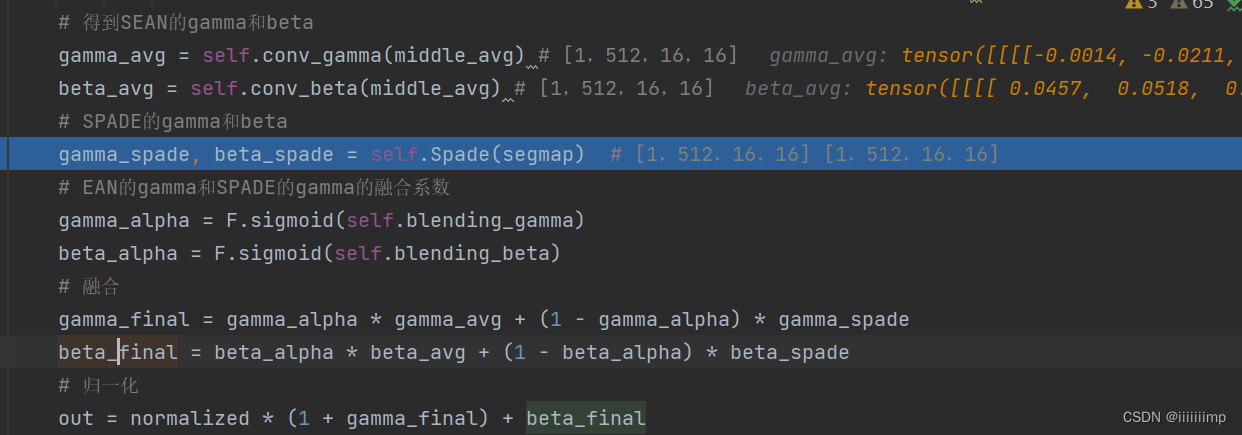
之后便是SPADE的归一化了
将刚刚得到的风格图(Style Map)middle_avg做SEAN归一化得到参数gamma_avg,beta_avg
SPADE对segmap归一化得到gamma_spade、beta_spade
然后用一个可学习参数gamma_alpha、beta_alpha将SEAN归一化和SPADE归一化融合起来
写在后面
[唐]金缕衣-------佚名
劝君莫惜金缕衣,劝君惜取少年时。
花开堪折直须折,莫待无花空折枝。


旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 122
122 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)