
YOLO等目标检测模型的非极大值抑制NMS和评价指标(Acc, Precision, Recall, AP, mAP, RoI)、YOLOv5中mAP@0.5与mAP@0.5:0.95的含义
一、正负样本
YOLOv5正负样本定义
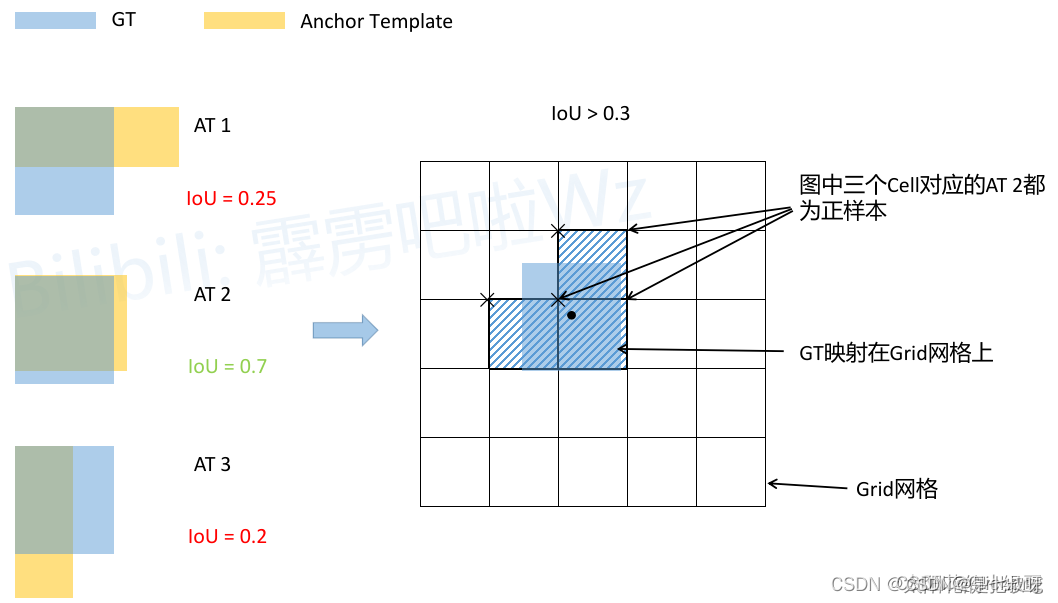
- 1 yolov5输出有3个预测分支,每个分支的每个网格有3个anchor与之对应。
- 2 没有采用IOU最大的匹配方法,而是通过计算该boundingbox和当前层的anchor的宽高比,如果最大比例大于4(设定阈值),则比例过大,则说明匹配度不高,将该bbox过滤,在当前层认为是背景;
- 3 计算这些box落在哪个网格内,同时利用四舍五入规则,找出最近的两个网格,将这三个网格都认为是负责预测该bbox的,所以理论上最多一个gt会分配9个正样本anchor,最少为3个(因为引入了相邻两个网格)

二、YOLOv5 - 在多类别中应用NMS(非极大值抑制)
2.1 非极大值抑制(NMS)
非极大值抑制虽然一般不作评价指标,但是也是目标检测中一个很重要的步骤,因为下期就要步入经典模型的介绍了,所以这里随着评价指标简单介绍下。
单个预测目标
NMS的英文为Non-Maximum Suppression,就是在预测的结果框和相应的置信度中找到置信度比较高的bounding box。对于有重叠在一起的预测框,如果和当前最高分的候选框重叠面积IoU大于一定的阈值的时候,就将其删除,而只保留得分最高的那个。如下图:

计算步骤:
- NMS计算出每一个bounding box的面积,然后根据置信度进行排序,把
置信度最大的bounding box作为队列中首个要比较的对象; 计算其余bounding box与当前最大score box的IoU,去除得到的IoU大于设定的阈值的bounding box【比如0.6】,保留小的IoU预测框;- 然后重复上面的过程,直至候选bounding box为空。
YOLOv5针对多个类别的预测目标
根据参数执行多个类一起应用NMS还是执行按照不同的类分别应用NMS
不同的类分别应用NMS(非极大值抑制),即每个索引值对应一个类别,不同类别的元素之间不会应用NMS。
实现方法一句话
多类别NMS(非极大值抑制)的处理策略是为了让每个类都能独立执行NMS,在所有的边框上添加一个偏移量。偏移量仅取决于类IDX,并且足够大,以便来自不同类的框不会重叠。
三、目标检测模型的评价指标(交并比、Acc, Precision, Recall, AP, mAP, RoI)
3.1 交并比 — IoU

公式即为: IoU = (A∩B) / (A∪B)
3.2 准确率/精度/召回率/FPR/F1指标
预测值为正例,记为P(Positive)- 预测值为反例,记为N(Negative)
预测值与真实值相同,记为T(True)预测值与真实值相反,记为F(False)
那么从上面可以知道:
TP -- 预测值和真实值一样,预测值为正样本(真实值为正样本)
TN -- 预测值和真实值一样,预测值为负样本(真实值为负样本)
FP -- 预测值和真实值不一样,预测值为正样本(真实值为负样本)【FP中的P表示预测为正例,但是预测错了】
FN -- 预测值和真实值不一样,预测值为负样本(真实值为正样本)
3.2.1、 准确率accuracy
就是被分对的样本数除以所有的样本数,通常来说,正确率越高,分类器越好,如下:
accuracy = (TP+TN)/(TP+TN+FP+FN)
上公式中的TP+TN即为所有的正确预测为正样本的数据与正确预测为负样本的数据的总和,TP+TN+FP+FN即为总样本的个数。
3.2.2、精度precision
是从预测结果的角度来统计的,是说预测为正样本的数据中,有多少个是真正的正样本,即“找的对”的比例,如下:
precision = TP/( TP+FP)
上公式中的TP+FP即为所有的预测为正样本的数据,TP即为预测正确的正样本个数。
3.2.3、召回率recall / TPR(灵敏度true positive rate)
召回率recall和TPR(灵敏度(true positive rate))是一个概念,都是从真实的样本集来统计的,是说在总的正样本中,模型找回了多少个正样本,即“找的全”的比例,如下:
recall/TPR = TP/(TP+FN)
3.2.4、F1-Score
F1分数(F1-score)是分类问题的一个衡量指标。F1分数认为召回率和精度同等重要, 一些多分类问题的机器学习竞赛,常常将F1-score作为最终测评的方法。它是精确率和召回率的调和平均数,最大为1,最小为0。计算公式如下:
F1 = 2TP/(2TP+FP+FN)
3.2.5、PR曲线—AP值 / ROC曲线-AUC值
PR曲线,就是precision和recall的曲线,PR曲线中precision为纵坐标,recall为横坐标,如下图:

那么PR曲线如何评估模型的性能呢?从图上理解,如果模型的精度越高,召回率越高,那么模型的性能越好。也就是说PR曲线下面的面积越大,模型的性能越好。绘制的时候也是设定不同的分类阈值来获得对应的坐标,从而画出曲线。
平均准确率AP
AP即Average Precision,称为平均准确率,是对不同召回率点上的准确率进行平均,在PR曲线图上表现为PR曲线下面的面积。AP的值越大,则说明模型的平均准确率越高。
ROC曲线和AUC值
ROC的全称是Receiver Operating Characteristic Curve,中文名字叫“受试者工作特征曲线”,对于ROC来说,横坐标就是FPR,而纵坐标就是TPR,因此可以想见,当TPR越大,而FPR越小时,说明分类结果是较好的。如下图:

3.2.6、 平均精度均值 — mAP
mAP是英文mean average precision的缩写,意思是平均精度均值,这个词听起来有些拗口,我们来仔细捋一捋。上面我们知道了什么是AP,AP就是PR曲线下面的面积(如下图),是指不同召回率下的精度的平均值。
然而,在目标检测中,一个模型通常会检测很多种物体,那么每一类都能绘制一个PR曲线,进而计算出一个AP值。那么多个类别的AP值的平均就是mAP.

YOLOv5中mAP@0.5与mAP@0.5:0.95的含义
- mAP@0.5:mean Average Precision(IoU=0.5)
即将IoU设为0.5时,计算每一类的所有图片的AP,然后所有类别求平均,即mAP
如图所示,AP50,AP60,AP70……等等指的是取detector的IoU阈值大于0.5,大于0.6,大于0.7……等等。数值越高,即阈值越大,精度越低。

- mAP@.5:.95(mAP@[.5:.95])
表示在不同IoU阈值(从0.5到0.95,步长0.05)(0.5、0.55、0.6、0.65、0.7、0.75、0.8、0.85、0.9、0.95)上的平均mAP。
参考:目标检测 YOLOv5 - 在多类别中应用NMS(非极大值抑制)

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐
 38
38 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)