
Mysql数据库进阶之select for update(五)
文章目录
select for update 使用详解
在 MySQL 中会使用 select for update 来实现悲观锁(乐观锁通过 version 字段来实现)。
for update 仅适用于 InnoDB ,且必须在事务块(BEGIN/COMMIT)中才能生效。
前提条件
不同的事务隔离级别会影响到 MySQL 的上锁策略。以下内容均是基于 MySQL 的默认隔离级别 REPEATABLE-READ 进行的。
确保你当前的 MySQL 连接的事务隔离级别是 RR 级别。
- 执行 SQL 语句查询当前的事务隔离级别:
show variables like 'transaction_isolation';
如果你没有改动过它,那么应该是 REPEATABLE-READ ,也就是所谓的 RR 级别。
- 如果不是 RR 级别,执行下面两条 SQL 语句,设置为 RR :
set session transaction isolation level repeatable read;
set global transaction isolation level repeatable read;
- 为后续的操作准备素材:
drop table IF EXISTS employee;
drop table IF EXISTS department;
create table department
(
`id` BIGINT AUTO_INCREMENT COMMENT '部门ID',
`name` VARCHAR(15) COMMENT '部门名称',
`location` VARCHAR(13) COMMENT '部门所在地',
PRIMARY KEY (`id`),
UNIQUE INDEX (name)
) COMMENT '部门信息表';
insert into department
values (1, 'ACCOUNTING', 'NEW YORK'),
(2, 'RESEARCH', 'DALLAS'),
(3, 'SALES', 'CHICAGO'),
(4, 'OPERATIONS', 'BOSTON'),
(5, 'hello', 'world');
1. 介绍
简单来说 select for update 所实现的效果就是:一旦 A 事务中执行了 select for update ,那么,在 A 事务结束(提交或回滚)之前,B 事务就无法操作 A 事务的 select for update 所涉及的这条数据,哪怕是去查也不行,直到 A 事务提交之后才可以。
以下用一个简单的示例展示 select for update 的锁现象:

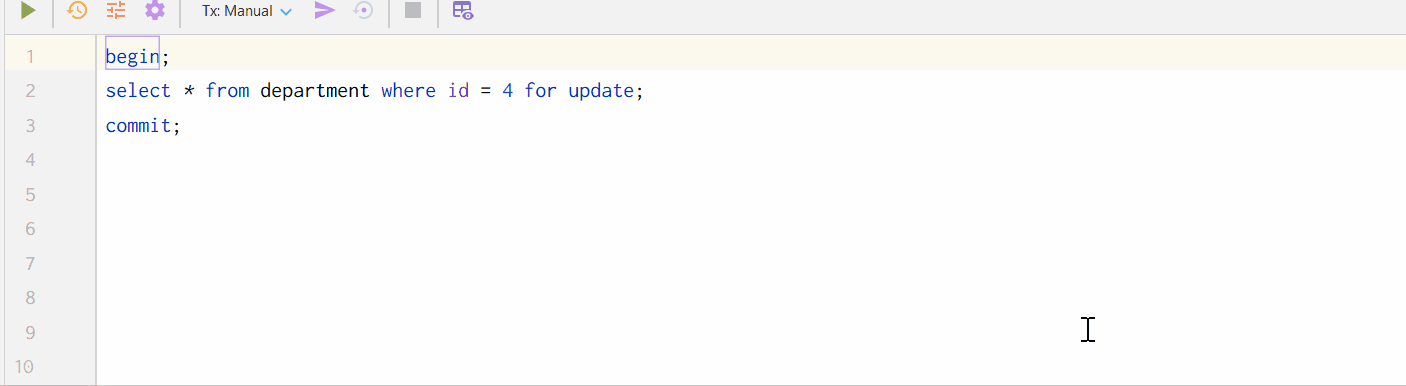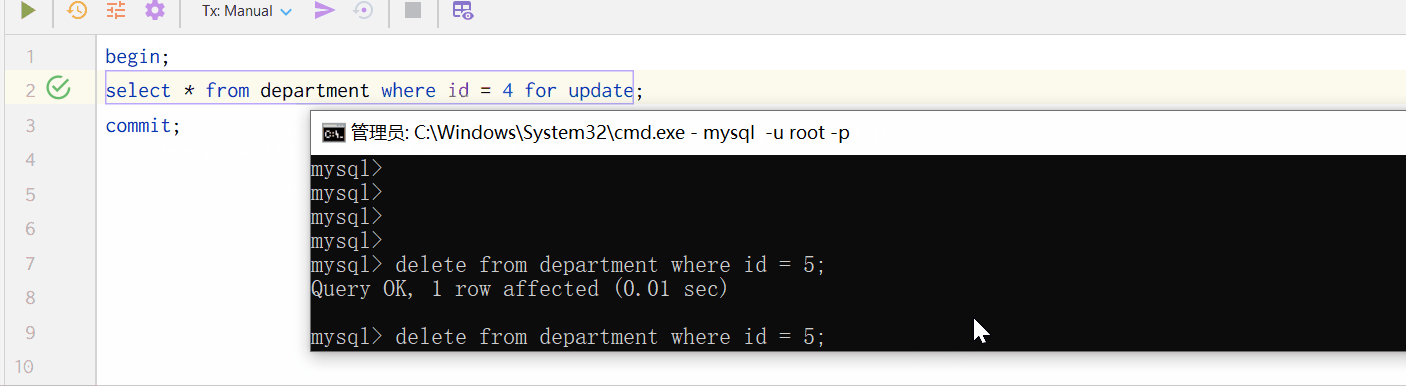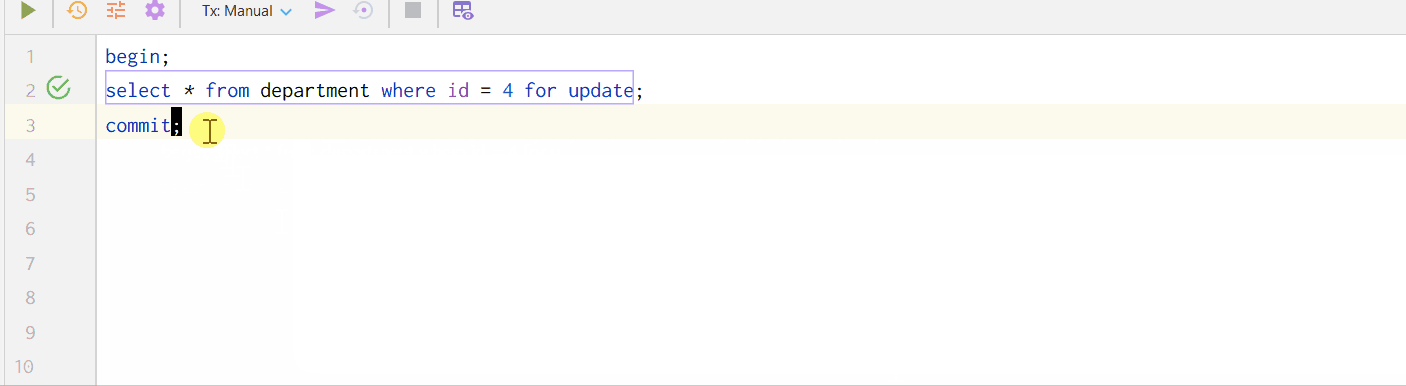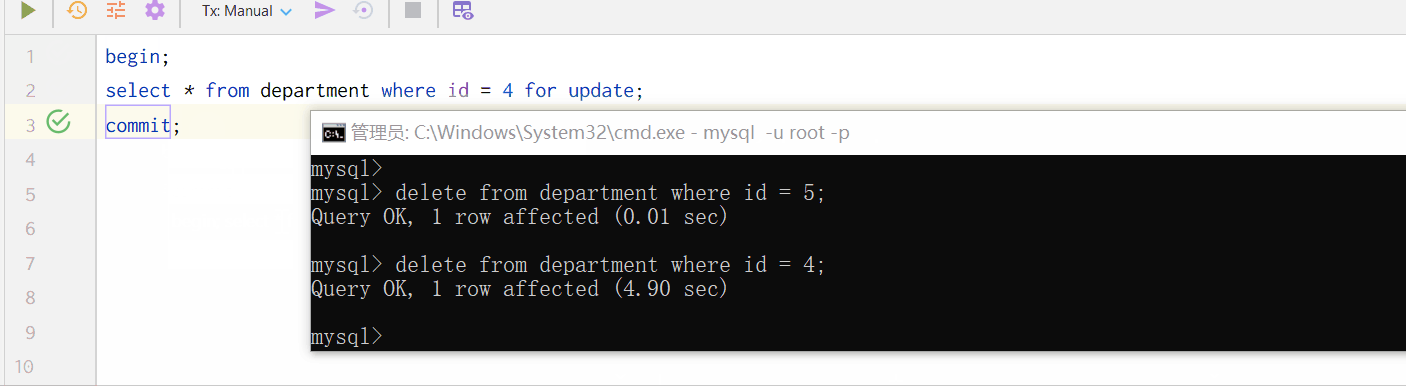
A 事务中使用 id = 4 作为 where 条件,进行了 select for update 操作,此后,你会发现 B 事务中就无法删除 id = 4 的部门信息了,知道 A 事务提交或回滚,B 事务中才能删除这条数据。
在第一个事务执行期间(begin 之后,commit 之前),第二个事务的执行:
-
删除 id = 5 的部门,成功。因为第一个事务涉及到的并非它。双方互不干扰、互不影响;
-
删除 id = 4 的部门,出现阻塞等待现象。因为第一个事务涉及的就是它!因此,在第一个事务结束前(执行 commit),第二个事务无法进行。
2. 行锁和表锁
2.1 行锁
在两个不同的 MySQL 客户端中分别执行下面两组 SQL 语句:
-
事务 A :通过 select-for-update 锁定 id=4 的数据(不提交);
-
事务 B :通过 delete 删除 id=5 的数据。
观察执行结果,你会发现事务 B 能执行成功。
原因在于事务 A 对 id=4 的这一行数据上锁,而事务 B 是对 id=5 的这行数据进行操作。
就是所谓的行锁,即,事务 A 只锁定了 id=4 这一行,与事务 B 需要操作 id=5 这一行无影响。
再次执行上述的 SQL(只需要执行事务 A 的),然后执行下列 SQL 语句:
-- 查看正在锁的事务
select
ENGINE_TRANSACTION_ID, OBJECT_SCHEMA,
OBJECT_NAME, INDEX_NAME,
LOCK_TYPE, LOCK_MODE,
LOCK_STATUS, LOCK_DATA
from
performance_schema.data_locks;
你会发现事务 A 对 id=4 的数据行上锁成功。
2.2 表锁
下面用一个简单的示例展示 select for update 产生表锁的情景:

在两个不同的 MySQL 客户端中分别执行下面两组 SQL 语句:
- 事务 A:通过 select-for-update 以 location=‘BOSTON’ 对数据上锁。从上帝视角看,这就是 id = 4 的那条数据。;
- 事务 B:通过 delte 删除 id=5 的数据;
对执行结果进行观察,你会发现事务 B 对 id=5 的数据进行删除时,出现了阻塞等待现象!即,当下不允许操作 id = 5 的那条数。
原因在于以 location=‘BOSTON’ 进行 select-for-update 操作时,产生了表锁!
再次执行上述的事务 A 的 SQL ,然后执行下列 SQL 语句:
-- 查看正在锁的事务
select
ENGINE_TRANSACTION_ID, OBJECT_SCHEMA,
OBJECT_NAME, INDEX_NAME,
LOCK_TYPE, LOCK_MODE,
LOCK_STATUS, LOCK_DATA
from
performance_schema.data_locks;
你会发现事务 A 对 id 为 1、2、3、4、5 的数据行上锁成功。
所以,此时,事务 B 再来删除 id=5 的数据时,会阻塞等待。
那么问题来了:从上帝视角看,明明 location=‘BOSTON’ 就是 id=4 那条数据,为什么 select-for-update 会锁包括 id=4 在内的所有数据?
行锁和表锁的规则
select for update 之后产生的行锁还是表锁,以"向 MySQL 询问"的结果为准:
-- 查看正在锁的事务
select
ENGINE_TRANSACTION_ID, OBJECT_SCHEMA,
OBJECT_NAME, INDEX_NAME,
LOCK_TYPE, LOCK_MODE,
LOCK_STATUS, LOCK_DATA
from
perfrmance_schema.data_locks;
查询条件影响锁规则
where 条件的情况分为 3 种:
| 条件 | 说明 |
|---|---|
| where id = … | 使用主键索引列作为查询条件; |
| where name = … | 使用普通索引列作为查询条件; |
| where location = … | 使用普通列(无索引)作为查询条件 |
以“主键索引”作为条件上锁
在素材中,department 表的 id 列是主键列,有主键索引。
这种情况最简单、直观:匹配查询条件的行会被上锁。这里锁定的是行,即,表中的部分数据。
begin;
select * from department where id in (1, 3, 5) for update;
-- 查看正在锁的事务
select
ENGINE_TRANSACTION_ID, OBJECT_SCHEMA, OBJECT_NAME,
IDEX_NAME, LOCK_TYPE, LOCK_MODE, LOCK_STATUS, LOCK_DATA
from
performance_schema.data_locks;
-- rolback ;
在 select-for-update 之后,查看相关信息,你会发现 id 为 1、3、5 的数据被上锁了。
显然,这是完全符合 id in (1, 3, 5) 查询条件的。
在事务 A 没释放锁(提交或回滚)之前,其它事务对 1、3、5 的数据进行写操作,都会阻塞等待。
以"普通索引"作为条件上锁
在素材中,department 表的 name 列有 UNIQUE 索引。
这种情况会上多把锁,不过,归根结底还是对主键上了锁。这里锁定的是行,即,表中的部分数据。
begin;
select * from department where name = 'OPERATIONS' for update;
-- 查看正在锁的事务
select
ENGINE_TRANSACTION_ID, OBJECT_SCHEMA, OBJECT_NAME,
IDEX_NAME, LOCK_TYPE, LOCK_MODE, LOCK_STATUS, LOCK_DATA
from
performance_schema.data_locks;
-- rolback ;
这里可以看到,MySQL 对 name 索引 上了一把锁,另外,找到了 name='OPERATION' 对应的那条数据,即 id=4 的那条数据,然后对 id 再次上锁。
所以,事务 B 无论直接以 id=4 作为条件来删除,还是间接以 id=4 作为条件来删除,都无法删除,因为,事务 A 还没有释放锁(提交或回滚)。
以"普通列"作为条件上锁
在素材中,department 表的 location 列没有任何索引,是普通列。
这种情况会产生表锁,即,多个行锁,对表中的所有数据行上锁。
begin;
select * from department where location = 'BOSTON' for update;
-- 查看正在锁的事务
select
ENGINE_TRANSACTION_ID, OBJECT_SCHEMA, OBJECT_NAME,
INDEX_NAME, LOCK_TYPE, LOCK_MODE, LOCK_STATUS, LOCK_DATA
from
performance_schema.data_locks;
rollback ;
执行上面的 SQL 语句,你会发现整个 department 的所有的数据行都被锁上了,即,整个 department 表都被上锁了!
这个时候,你在事务 B 中要删哪个都必须阻塞等待。
3. 更多示例
在执行 select-for-update 之后,执行下列 SQL 语句查看锁的相关情况以进行验证:
-- 查看正在锁的事务
select
ENGINE_TRANSACTION_ID, OBJECT_SCHEMA, OBJECT_NAME,
INDEX_NAME, LOCK_TYPE, LOCK_MODE, LOCK_STATUS, LOCK_DATA
from
performance_schema.data_locks;
单条件查询
- 只根据 “主键索引” 进行查询(且数据存在),产生行锁,匹配行被上锁,其他事务对该数据行无法写。
select * from department where id = 1 for update;
- 根据 “普通索引” 进行查询(且数据存在),产生行锁,匹配行被上锁,其它事务对该数据行无法写。
select * from department where name='hello' for update;
- 根据 “普通列” 进行查询(且数据存在),产生表锁,所有行都被上锁,其它事务对表中任何数据都无法写。
SELECT * FROM department where location='boston' for update;
and 组合条件查询
- 根据 “主键索引 and 普通索引” 进行查询(且数据存在),产生行锁,匹配行被上锁,其他事务对该数据行无法写。
select * from department where id = 5 and name='hello' for update;
条件一产生行锁,条件二产生行锁,综合效果仍然是行锁。
- 根据 “主键索引 and 普通列” 进行查询(且数据存在),产生行锁,匹配行被上锁,其他事务对该数据行无法写。
select * from department where id = 5 and location='world' for update;
虽然以 “普通列” 应该是产生表锁(锁定全表数据),但是由于是结合(and)主键列进行查询,所以查询的结果是具有确定性、唯一性的,所以,这里 MySQL 并没有傻啦吧唧地锁全表,而是锁了匹配行。
- 根据 “普通索引 and 普通列” 进行查询(且数据存在),产生行锁,匹配行被上锁,其他事务对该数据行无法写。
select * from name="hello" and location="world" for update;
这里和上面的情况很类似,MySQL 对此进行了优化,并没有因为 location 列是普通列而直接上表锁,仅仅是对匹配行上锁。
or 组合条件查询
- 根据 “主键索引 or 普通索引” 进行查询(且数据存在),产生行锁,匹配行被上锁,其他事务对该数据行无法写。
select * from department where id = 1 or name='hello' for update;
单独看,条件一和条件二都是产生行锁,所以他们的 or 的组合查询,产生的自然也是行锁。
- 根据 “主键索引 or 普通列” 进行查询(且数据存在),产生行锁,匹配行被上锁,其他事务对该数据行无法写。
select * from department where id=1 or location='world' for update;
单独看,条件一产生的是行锁(锁某一行),条件二产生的是表锁(锁所有行),两者以 or 的方式组合,最终的效果是所有行被锁,即"表锁"的效果。
- 根据 “普通索引 and 普通列” 进行查询(且数据存在),产生行锁,匹配行被上锁,其他事务对该数据行无法写。
select * from department where name='sales' or location='world' for update;
和上一种情况一样,行锁叠加表锁,最终效果就是表锁。
查询未命中
无论什么情况,如果表中没有符合查询条件的数据,MySQL 不产生任何锁。
select * from department where id=10086 for update;
select * from department where name='good' for update;
select * from department where location='bye' for update;
select * from department where id=1 and name='good' for update;
select * from department where id=1 and location='bye' for update;
select * from department where name='SALES' and location='bye' for update;
select * from department where id=10086 or name='good' for update;
select * from department where id=10086 or location='bye' for update;
select * from department where name='good' or location='world' for update;
总结
-
所谓的"表锁",从某种意义来说,就是"批量行锁":对表中的所有数据行上锁。
-
因为有索引并使用索引作为查询条件,对于选中的数据,MySQL 中锁定匹配行,其他行数据不上锁。
-
当表有多个索引的时候,不同的事务可以使用不同的索引锁定不同的行,另外,不论是使用主键索引、唯一索引或普通索引,InnoDB 都会使用行锁来对数据加锁。
-
即便在条件中使用了索引字段,但是否使用索引来检索数据是由 MySQL 通过判断不同执行计划的代价来决定的,如果 MySQL 认为全表扫描效率更高,比如对一些很小的表,它就不会使用索引,这种情况下 InnoDB 将使用表锁,而不是行锁。因此,在分析锁冲突时,别忘了检查 SQL 的执行计划,以确认是否真正使用了索引。
-
检索值的数据类型与索引字段不同,虽然 MySQL 能够进行数据类型转换,但却不会使用索引,从而导致 InnoDB 使用表锁。通过用 explain 检查两条 SQL 的执行计划,我们可以清楚地看到了这一点。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐
 30
30 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)