
时间序列分析|LSTM多变量时间序列预测
基于LSTM多变量的时间序列预测
从这篇博客你将学到
(1) 何为时间序列
(2) 多变量时间序列建模
(3) 基于LSTM模型的时间序列预测
(4) 如何免费加入交流群
时间序列
我们常说历史总是惊人的相似,时间序列预测正式依循这个道理来预测未来,时间序列英文名称为Time Series,简称TS,其假设某变量的值构成的序列依赖于时间,随着时间的变化而变化,如果时间确定了,这个变量的值也就确定了,任何一个时刻都是可以度量的,因为从现在起未来的或者过去的某一时间是可以通过现在时间演算的,同时,随着时间的变化,变量往往会呈现出某些特殊的结构特征,如上升或下降的大体趋势,季节性变动,一些循环往复的周期变动,还有一些不规则变动,而这些特质往往是可以捕捉的,所以常用时间序列模型来预测未来某一确定时间的变量的值。下图是早些年某国的航空乘客人数统计数据,单位是千人
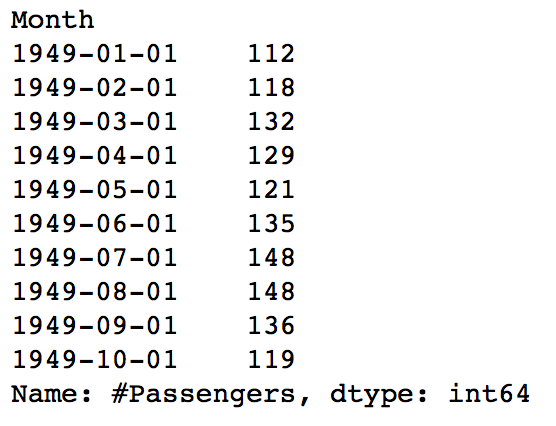
我们用折线图将每月的航空乘客人数描绘出来
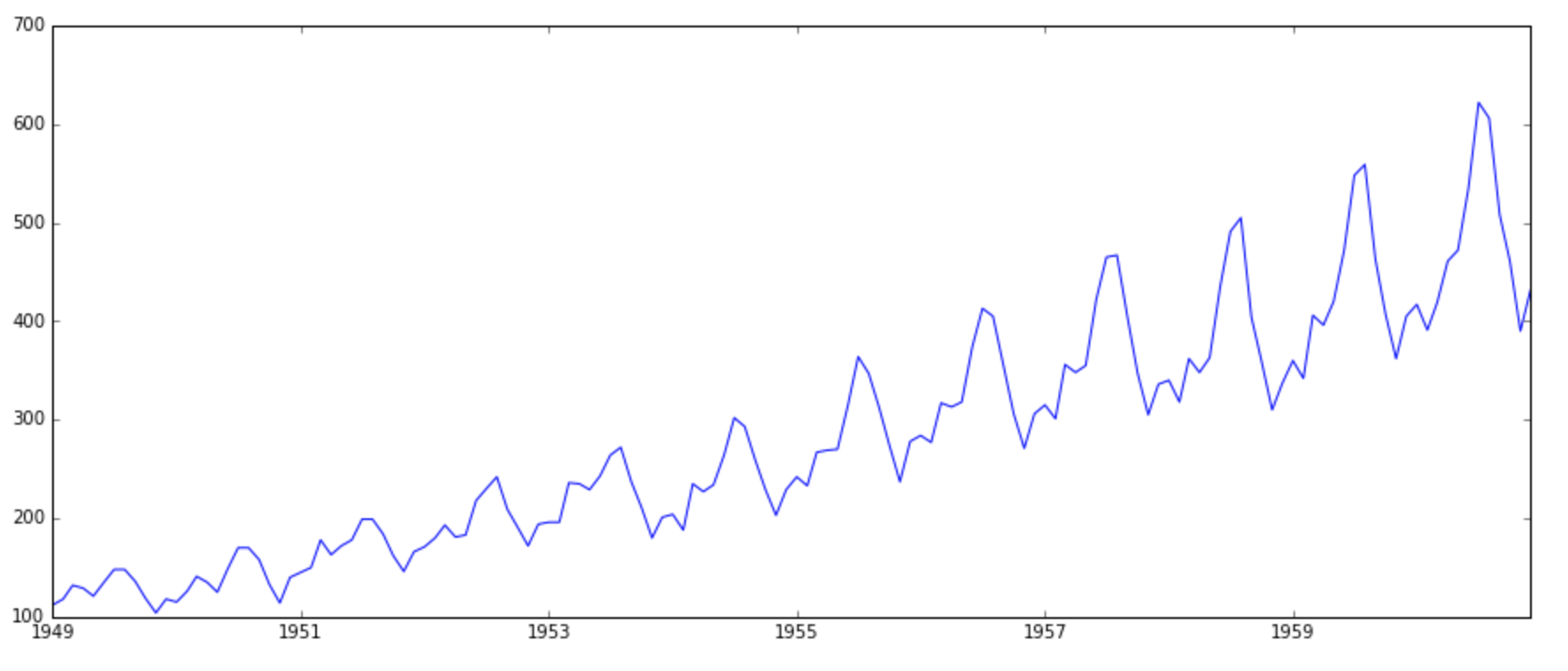
很明显可以看到航空乘客人数总体呈上升趋势,同时出现每隔一段时间上升隔一段时间下降的周期性特征,每个周期变动之间又蕴含一些细微的波动。针对不同特征的时间序列数据可以构建不同的模型,常见的时间序列模型有
(1) AR(Autoregressive model)自回归模型
(2) MA(Moving Average Model)移动平均模型
(3) ARMA(Auto Regressive and Moving Average Model)自回归移动平均模型
(4) ARIMA(Autoregressive Integrated Moving Average model)差分回归移动平均模型
(5) SARIMA(seasonal autoregressive integrated moving average)季节性差分回归移动平均模型
(6) SARIMAX(seasonal autoregressive integrated moving average with exogenous regressor)带外 变量的季节性差分回归移动平均模型
(7) VAR(Vector autoregression)矢量自回归模型模型
(6) SVAR(Structural VAR)结构自回归模型
多变量时间序列
平常我们构建的大多属于单变量时间序列,在构建预测模型的时候往往只有时间和变量本身可以参考,而这样的变量往往会显得很单薄,同时,时间往往是解释性因子而不是因果性因子,就以航空公司的某个常飞的航班乘客人数为例,如果说成因为是某年某月某日,所以航空乘客人数是多少多少,恐怕太牵强了,所以还需要考虑其他影响因素,比如天气,航线,节假日,旅游季等,于是就有了多变量时间序列,多变量时间序列是指除了时间依赖外,还有其他因素共同影响某一结果的发生。例如下表是某地的气象监控数据
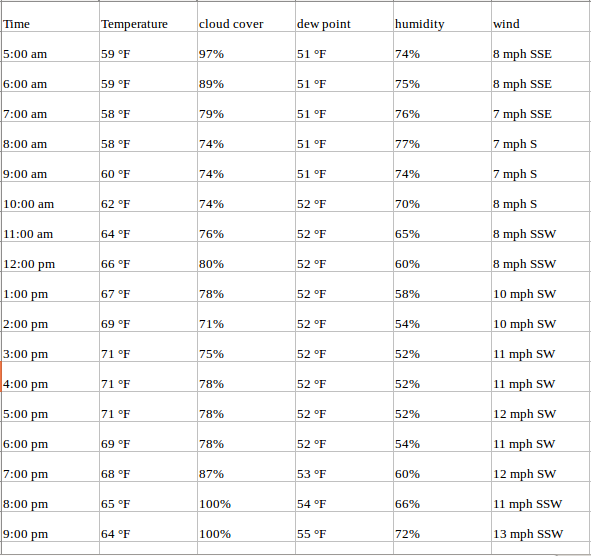
其中包含时间,温度,云层覆盖率,露点、湿度、风速及风向等,在这种情况下,云层覆盖率,露点、湿度、风速及风向都有可能被认为是影响温度的因果原因,而时间只是恰巧发生在此时此刻的一个表象因子。这时候建模就可以建立既包含因果原因和又包含表现原因在内的多变量时间序列模型。
多变量时间序列建模
假设数据如下所示
( x 11 x 12 ⋯ x 1 n y 1 x 21 x 22 ⋯ x 2 n y 2 ⋮ ⋮ ⋮ ⋮ x m 1 x m 2 ⋯ x m n y m ) \left( \begin{matrix} x_{11} & x_{12} & \cdots & x_{1n} & y_1 \\ x_{21} & x_{22} & \cdots & x_{2n} & y_2 \\ \vdots & \vdots & & \vdots & \vdots \\ x_{m1} & x_{m2} & \cdots & x_{mn} & y_m \\ \end{matrix} \right) ⎝⎜⎜⎜⎛x11x21⋮xm1x12x22⋮xm2⋯⋯⋯x1nx2n⋮xmny1y2⋮ym⎠⎟⎟⎟⎞
其中 x i j ( 1 ≤ i ≤ m , 1 ≤ j ≤ n ) x_{ij}(1\leq i\leq m, 1\leq j \leq n) xij(1≤i≤m,1≤j≤n) 表示第 i i i期的第 j j j个特征的值, y i ( 1 ≤ i ≤ m ) y_i(1\leq i\leq m) yi(1≤i≤m)表示第 i i i期的目标值,先从最简单的开始
(1) 一阶滞后
为了预测第 m m m 期的 y m y_m ym值,我们可以利用第 m − 1 m-1 m−1期的所有信息
( x m − 1 , 1 , x m − 1 , 2 , ⋯ , x m − 1 , n , y m − 1 ) (x_{m-1,1} , x_{m-1,2} , \cdots , x_{m-1,n} , y_{m-1}) (xm−1,1,xm−1,2,⋯,xm−1,n,ym−1)
建立第
m
m
m 期的目标值
y
m
y_m
ym值与第
m
−
1
m-1
m−1期所有信息的线性模型
y
m
=
w
0
y
m
−
1
+
w
1
x
m
−
1
,
1
+
w
2
x
m
−
1
,
2
+
⋯
+
w
n
x
m
−
1
,
n
+
ϵ
y_m= w_0y_{m-1}+w_1x_{m-1,1}+w_2x_{m-1,2} + \cdots + w_nx_{m-1,n}+\epsilon
ym=w0ym−1+w1xm−1,1+w2xm−1,2+⋯+wnxm−1,n+ϵ
而不是仅仅利用第 m − 1 m-1 m−1期的结果 y m − 1 y_{m-1} ym−1这一单一的信息, 这就是多变量时间序列的优势,再推广到p阶滞后。
(2) p阶滞后
我们亦可以利用第 m − p m-p m−p 到第 m − 1 m-1 m−1期的所有信息来进行预测
( x m − p , 1 x m − p , 2 ⋯ x m − p , n y m − p x m − p + 1 , 1 x m − p + 1 , 2 ⋯ x m − p + 1 , n y m − p + 1 ⋮ ⋮ ⋮ ⋮ x m − 1 , 1 x m − 1 , 2 ⋯ x m − 1 , n y m − 1 ) \left( \begin{matrix} x_{m-p,1} & x_{m-p,2} & \cdots & x_{m -p, n} & y_{m-p} \\ x_{m-p+1,1} & x_{m-p+1,2} & \cdots & x_{m-p+1,n} & y_{m-p+1} \\ \vdots & \vdots & & \vdots & \vdots \\ x_{m-1,1} & x_{m-1,2} & \cdots & x_{m-1,n} & y_{m-1} \\ \end{matrix} \right) ⎝⎜⎜⎜⎛xm−p,1xm−p+1,1⋮xm−1,1xm−p,2xm−p+1,2⋮xm−1,2⋯⋯⋯xm−p,nxm−p+1,n⋮xm−1,nym−pym−p+1⋮ym−1⎠⎟⎟⎟⎞
写成向量形式就是
y m = W 0 Y + W m − 1 X m − 1 + W m − 2 X m − 2 + W m − 3 X m − 3 + ⋯ + W m − p X m − p + ϵ y_m = W_0Y+ W_{m-1}X_{m-1}+W_{m-2}X_{m-2}+W_{m-3}X_{m-3}+\cdots+W_{m-p}X_{m-p}+\epsilon ym=W0Y+Wm−1Xm−1+Wm−2Xm−2+Wm−3Xm−3+⋯+Wm−pXm−p+ϵ
其中,
Y
Y
Y表示前第
m
−
1
m-1
m−1 到第
m
−
p
m-p
m−p期的目标值
y
m
−
1
,
⋯
,
y
m
−
p
y_{m-1}, \cdots, y_{m-p}
ym−1,⋯,ym−p
X
m
−
i
X_{m-i}
Xm−i表示前
i
(
1
≤
i
≤
p
)
i(1\leq i\leq p)
i(1≤i≤p)期的特征向量
(
x
m
−
i
,
1
,
x
m
−
i
,
2
,
⋯
,
x
m
−
i
,
n
)
T
(x_{m-i,1}, x_{m-i,2},\cdots,x_{m-i,n})^T
(xm−i,1,xm−i,2,⋯,xm−i,n)T
W
0
W_0
W0表示前
i
(
1
≤
i
≤
p
)
i(1\leq i\leq p)
i(1≤i≤p)期的目标值的系数
w
m
−
1
,
⋯
,
w
m
−
p
w_{m-1}, \cdots, w_{m-p}
wm−1,⋯,wm−p
W m − i W_{m-i} Wm−i表示前 i ( 1 ≤ i ≤ p ) i(1\leq i\leq p) i(1≤i≤p)期的特征向量的系数
( w m − i , 1 , w m − i , 2 , ⋯ , w m − i , n , w m − i ) (w_{m-i,1}, w_{m-i,2},\cdots,w_{m-i,n},w_{m-i} ) (wm−i,1,wm−i,2,⋯,wm−i,n,wm−i)
ϵ \epsilon ϵ服从高斯分布,这样第 m m m期的目标值就可以通过第 m − p m-p m−p到第 m − 1 m-1 m−1期的特征变量和目标值线性表出。与单变量时间序列不同,多变量时间序列不仅利用了纵向的时间特征还利用横向的其他特征,所以多变量时间序列不仅能够时间带来的沧桑变化也能够理解和使用多个变量之间的关系,这有助于描述数据的动态行为,并提供更好的预测结果。
LSTM模型
LSTM是一种时间递归神经网络,它出现的原因是为了解决RNN的一个致命的缺陷。原生的RNN会遇到一个很大的问题,叫做The vanishing gradient problem for RNNs,也就是后面时间的节点会出现老年痴呆症,也就是忘事儿,这使得RNN在很长一段时间内都没有受到关注,网络只要一深就没法训练。后来有些大牛们开始使用递归神经网络来对时间关系进行建模。而根据深度学习三大牛的阐述,针对时间序列数据,LSTM网络已被证明比传统的RNNS更加有效。
适合多输入变量的神经网络模型一直让开发人员很头痛,但基于(LSTM)的循环神经网络能够几乎可以完美的解决多个输入变量的问题。
基于LSTM的循环神经网络可以很好的利用在时间序列预测上,因为很多古典的线性方法难以适应多变量或多输入预测问题。下面我们通过一个案例来看看LSTM在多元时间序列预测上的表现。
实践项目
通过本案例实践,你将学会
- 如何将原始数据集转换为可用于时间序列预测的数据集;
- 如何准备数据并创建适应多变量时间序列预测问题的LSTM;
- 如何做出预测并将结果重新调整到原始单位;
原始pm2.5数据
在这个案例中,我们将使用PM2.5空气质量数据集,是美国驻北京大使馆五年内收集的PM2.5污染水平及天气情况。字段包括时间、PM2.5浓度、以及一些关键天气信息,详细字段释义如下(需要这份数据的朋友可以来三行科创交流群获取)
NO:行号。
year:年。
month:月。
day:日。
hour:小时。
pm2.5:PM2.5浓度。
DEWP:露点温度。
TEMP:温度。
PRES:压力。
cbwd:风向。
Iws:风速。
ls:积雪的时间
Ir:累积的下雨时数
我们可以使用这些数据并构建一个预测问题,基于前一个或几个小时天气条件和PM2.5的污染,预测在下一个小时的PM2.5的污染值。
第一步 导入用到的库
本案例是基于keras深度学习库完成多变量时间序列模型的开发,涉及到的库比较多
# -*- encoding: utf-8 -*-
'''
@Project : LSTM多变量时间序列预测
@Desc : 利用LSTM模型进行多变量时间啊序列预测
@Time : 2021/03/21 12:16:13
@Author : 帅帅de三叔,zengbowengood@163.com
'''
import math
import pandas as pd
from datetime import datetime
import matplotlib.pyplot as plt
from pandas.core.algorithms import mode
from sklearn.preprocessing import LabelEncoder, MinMaxScaler
from tensorflow.python.keras.backend import concatenate
from sklearn.metrics import mean_squared_error
from tensorflow.python.keras.callbacks import History
from series_to_supervised import series_to_supervised
from keras.models import Sequential
from keras.layers import Dense, Activation, Embedding, LSTM
第二步 数据探索
数据探索主要是查看原始数据的缺失情况,完整度怎么样,有没有明显的谬误等,对数据及数据之间有个感性的认真,如果能够画出原数据的图像那会更直观。
dataset = pd.read_csv("raw.csv", index_col= "datetime", parse_dates = {"datetime":['year', 'month', 'day', 'hour']}, date_parser= lambda x:datetime.strptime(x,'%Y %m %d %H')) #读取数据并拼接时间
dataset.drop("No", axis = 1, inplace = True) #去掉No列
dataset.columns = ["pm25", "dew", "temp", "press", "wnd_dir", "wnd_spd", "snow", "rain"] #重命名表头
dataset.dropna(subset = ['pm25'], inplace = True) #去掉pm25为空的行
values = dataset.values #数值特征变量
groups = [0, 1, 2, 3, 5, 6, 7]
i = 1
plt.figure() #新建画布
for group in groups:
plt.subplot(len(groups), 1, i) #子图
plt.plot(values[:, group]) #折线图
plt.title(dataset.columns[group], y = 0.5, fontsize = 10, loc = "right") #取字段为子图标题
i +=1
plt.show()

第三步 特征工程
将原数据处理成LSTM模型能够识别的格式,并且保持LSTM模型的输入格式要求(samples, timesteps, features),同时数据集进行划分,分为训练集和测试集,要注意这里是需要学习到时间因素,所以在训练集和测试集划分上不能破坏数据原有的序列,可以按照时间切分,比如这里用第一年数据进行训练,用剩下的4年进行评估。
encoder = LabelEncoder() #编码
values[:,4] = encoder.fit_transform(values[:,4]) #将第4列编码
values = values.astype('float32') #使得所有数值类型都是float类型
scaler = MinMaxScaler(feature_range = (0, 1)) #0-1归一化
scaled = scaler.fit_transform(values)
reframed = series_to_supervised(scaled, 1, 1) #调用series_to_supervised函数将数据转为监督数据变成16列
reframed.drop(reframed.columns[[9, 10, 11, 12, 13, 14, 15]], axis= 1,inplace = True)
values = reframed.values
n_train_hours = 365*24 #一年的小时数
train = values[:n_train_hours, :] #训练集
test = values[n_train_hours:, :] #测试集
train_x, train_y = train[:, :-1], train[:, -1] #训练集特征和标签
test_x, test_y = test[:, :-1], test[:, -1] #测试集的特征和标签
train_x = train_x.reshape((train_x.shape[0], 1, train_x.shape[1])) #转为LSTM模型的输入格式(samples, timesteps, features)
test_x = test_x.reshape((test_x.shape[0], 1, test_x.shape[1])) #转为LSTM模型的输入格式(samples, timesteps, features)
第四步 设计LSTM模型
模型的设计是很关键的一环,一个简洁高效的模型往往能够使得训练和验证结果事半功倍,这里隐藏层有50个神经元,输出层1个神经元(回归问题),输入变量是一个时间步(t-1)的特征,损失函数采用Mean Absolute Error(MAE),优化算法采用Adam,模型采用50个epochs并且每个batch的大小为72, shuffle要设置成False,随后画出测试集的误差曲线和训练集的误差曲线。
model = Sequential()
model.add(LSTM(50, input_shape = (train_x.shape[0], train_x.shape[2]))) #8760*8
model.add(Dense(1))
model.compile(loss = "mae",optimizer= "adam")
history =model.fit(train_x, train_y, epochs= 50, batch_size=72, validation_data=(test_x, test_y), verbose=2, shuffle=False)
plt.figure()
plt.plot(history.history["loss"], label = "train")
plt.plot(history.history["val_loss"], label = "test")
plt.legend()
plt.show()
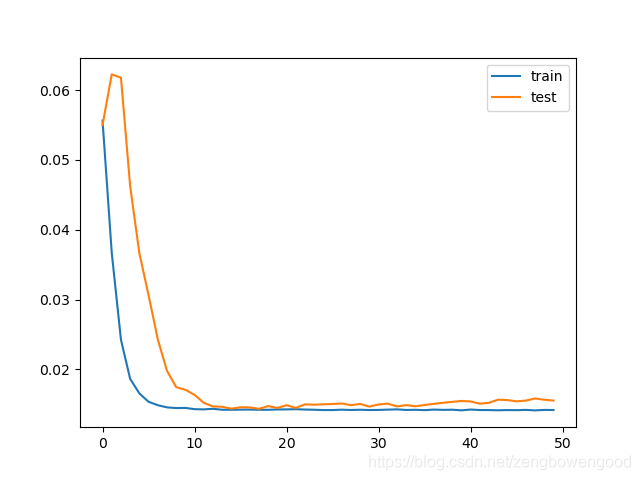
第五步 模型的评估
一个模型的好坏还需要进行严格的评估工作,需要将预测结果和部分测试集数据组合然后进行比例反转(invert the scaling),同时也需要将测试集上的预期值也进行比例转换。至于在这里为什么进行比例反转,是因为我们将原始数据进行了预处理(连同输出值y),此时的误差损失计算是在处理之后的数据上进行的,为了计算在原始比例上的误差需要将数据进行转化,同时反转时的矩阵大小一定要和原来的大小(shape)完全相同,否则就会报错。通过以上处理之后,再结合RMSE(均方根误差)计算损失。
yhat = model.predict(test_x)
test_x = test_x.reshape((test_x.shape[0], test_x.shape[2]))
inv_yhat = concatenate((yhat,test_x[:, 1:]), axis = 1)
inv_yhat = scaler.inverse_transform(inv_yhat)
inv_yhat = inv_yhat[:, 0]
test_y = test_y.reshape((len(test_y), 1))
inv_y = concatenate((test_y, test_x[:, 1:]), axis =1)
inv_y = scaler.inverse_transform(inv_y)
inv_y = inv_y[:, 0]
rmse = math.sqrt(mean_squared_error(inv_y, inv_yhat))
print("the rmse is: %.3f" %rmse)
最后均方根误差值保持在26附近。
进一步思考
(1)在数据处理可以尝试的
- 加入季节特征;
- 时间步长大于1。
- 舍去一些影响不大的特征
(2)在设计模型的时候可以尝试
- 隐藏层神经元个数,
- 优化算法
- 模型的epochs数,每个batch的大小
参考资料
1,https://www.analyticsvidhya.com/blog/2016/02/time-series-forecasting-codes-python/
2,https://blog.csdn.net/qq_28031525/article/details/79046718
3,https://www.analyticsvidhya.com/blog/2016/02/time-series-forecasting-codes-python/


旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 101
101 1
1- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)