
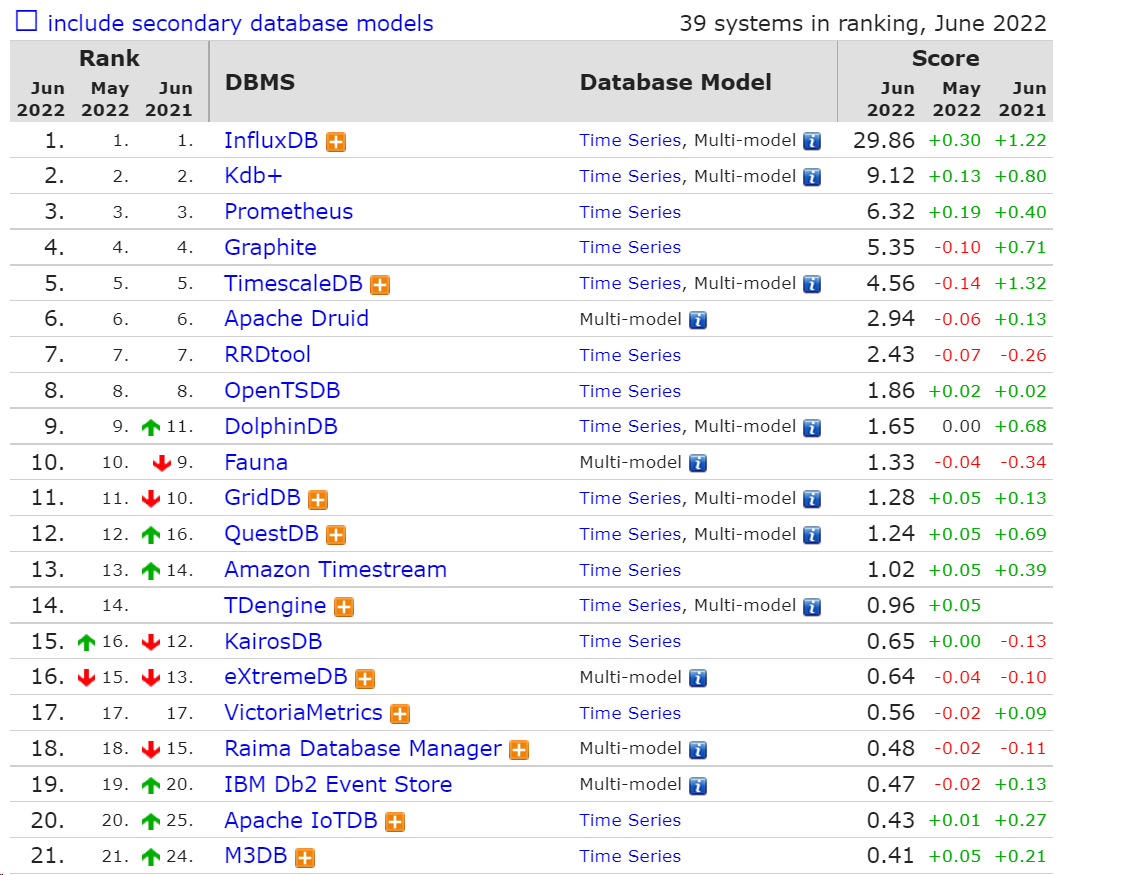
三种常用时序数据库对比调研-InfluxDB、Prometheus、IotDB
针对三种常见的时序数据库进行了对比,主要从网络上的资料进行了对比,也有一点自己进行的实际读写性能的测试。
1、引言
时序数据治理是数据治理领域核心、打通IT与OT域数据链路,是工业物联网基石、大数据价值创造的关键、企业管理提升的发动机、是数字化转型的重要支撑。
工业企业在生产经营过程中,会运用物联网技术,采集大量的数据并进行实时处理,这些数据都是时序的,而且具有显著的特点,比如带有时间戳、结构化、没有更新、数据源唯一等。
时序数据处理应用于智慧城市、物联网、车联网、工业互联网领域的过程数据采集、过程控制,并与过程管理建立一个数据链路,属于工业数据治理的新兴领域。
时序数据库的应用场景在物联网和互联网APM等场景应用比较多,下面是列举了一些时序数据库的应用场景,但不是全部:
- 公共安全:上网记录、通话记录、个体追踪、区间筛选;
- 电力行业:智能电表、电网、发电设备的集中监测;
- 互联网:服务器/应用监测、用户访问日志、广告点击日志;
- 物联网:电梯、锅炉、机械、水表等各种联网设备;
- 交通行业:实时路况、路口流量监测、卡口数据;
- 金融行业:交易记录、存取记录、ATM、POS机监测。
2、概述
2.1时序数据库的定义
时序数据是随时间不断产生的一系列数据,简单来说,就是带时间戳的数据。时序数据库 (Time Series Database,TSDB) 是优化用于摄取、处理和存储时间戳数据的数据库。此类数据可能包括来自服务器和应用程序的指标、来自物联网传感器的读数、网站或应用程序上的用户交互或金融市场上的交易活动。
其主要数据属性如下:
- 每个数据点都包含用于索引、聚合和采样的时间戳。该数据也可以是多维的和相关的;
- 写多读少,需要支持秒级和毫秒级甚至纳秒级高频写入;查询通常是多维聚合查询,对查询的延迟要求比较高
- 数据的汇总视图(例如,下采样或聚合视图、趋势线)可能比单个数据点提供更多的洞察力。例如,考虑到网络不可靠性或传感器读数异常,我们可能会在一段时间内的某个平均值超过阈值时设置警报,而不是在单个数据点上这样做;
- 分析数据通常需要在一段时间内访问它(例如,给我过去一周的点击率数据);
虽然其他数据库也可以在数据规模较小时一定程度上处理时间序列数据,但 TSDB可以更有效地处理随时间推移的数据摄取、压缩和聚合。简而言之,时序数据库是专门用于存储和处理时间序列数据的数据库,支持时序数据高效读写、高压缩存储、插值和聚合等功能。
2.2时序数据库的概念
时序数据库是专门处理时序数据的数据库,因此其相关概念是和时序数据紧密联系的,下面是时序数据库的一些基本概念。
- 度量 Metric:Metric 类似关系型数据库里的表(Table),代表一系列同类时序数据的集合,例如为空气质量传感器建立一个 Table,存储所有传感器的监测数据。
- 标签 Tag:Tag 描述数据源的特征,通常不随时间变化,例如传感器设备,包含设备 DeviceId、设备所在的 Region 等 Tag 信息,数据库内部会自动为 Tag 建立索引,支持根据 Tag 来进行多维检索查询;Tag 由 Tag Key、Tag Value 组成,两者均为 String 类型。
- 时间戳 Timestamp:Timestamp代表数据产生的时间点,可以写入时指定,也可由系统自动生成;
- 量测值 Field:Field描述数据源的量测指标,通常随着时间不断变化,例如传感器设备包含温度、湿度等Field;
- 数据点Data Point: 数据源在某个时间产生的某个量测指标值(Field Value)称为一个数据点,数据库查询、写入时按数据点数来作为统计指标;
- 时间线 Time Series :数据源的某一个指标随时间变化,形成时间线,Metric + Tags + Field 组合确定一条时间线;针对时序数据的计算包括降采样、聚合(sum、count、max、min等)、插值等都基于时间线维度进行;
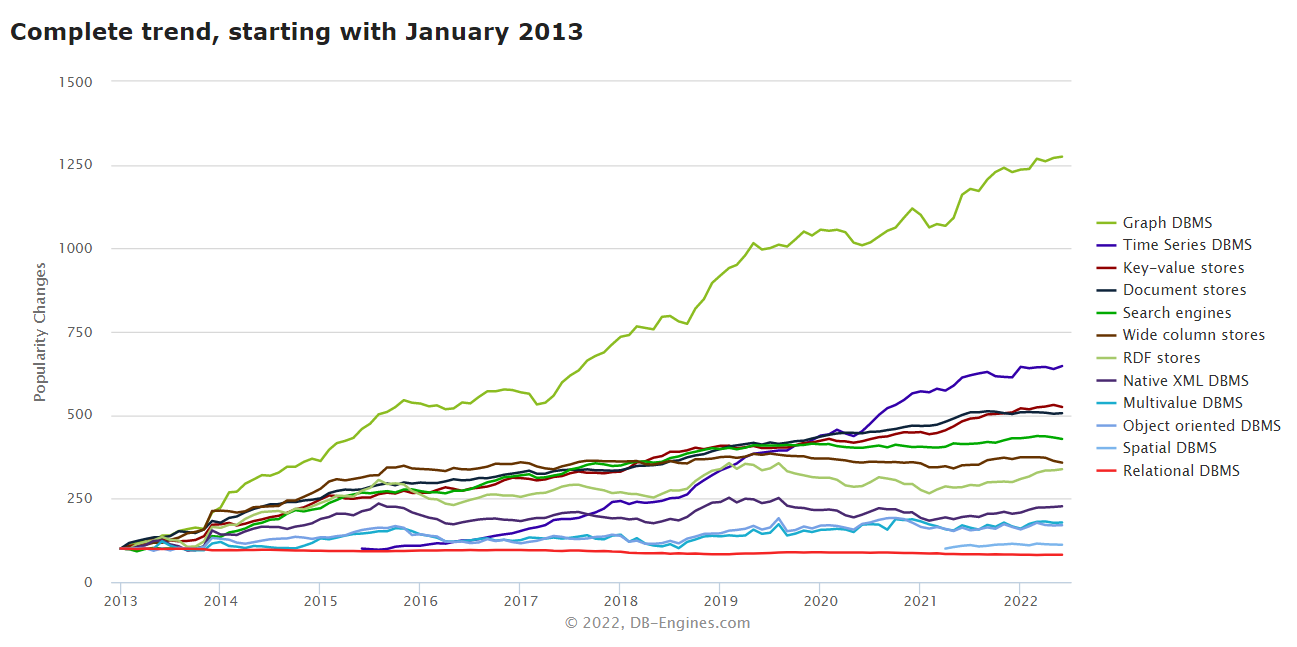
2.3时序数据库的趋势
时序数据库的发展趋势,可以从DB-engines(Knowledge Base of Relational and NoSQL Database Management Systems)获取获取到,下图是DB-engines收录的数据库近24个月的发展趋势,其中时序数据库的活跃度最高,且随时间呈现越来越活跃的趋势。

3、常用时序数据库测试
3.1读写测试
写入测试
| 指标 | InfluxDB | Prometheus | IoTDB |
| 10000 | 185ms | 192ms | 183ms |
| 10000 | 186ms | 195ms | 120ms |
| 20000 | 252ms | 268ms | 236ms |
| 20000 | 264ms | 273ms | 219ms |
| 30000 | 385ms | 401ms | 274ms |
查询测试
| 指标 | InfluxDB | Prometheus | IoTDB |
| 10000 | 14ms | 18ms | 16ms |
| 20000 | 31ms | 32ms | 35ms |
| 40000 | 56ms | 58ms | 54ms |
| 60000 | 75ms | 82ms | 78ms |
| 90000 | 96ms | 99ms | 97ms |
3.2 功能对比
DB-Engines提供的编辑信息
| 名字 | InfluxDBX | Prometheus | Apache IoTDBX |
| 描述 | 用于存储时间序列、事件和指标的 DBMS | 开源时间系列DBMS和监控系统 | 具有高性能数据管理和分析的物联网原生数据库,可部署在边缘和云端,并与Hadoop,Spark和Flink集成 |
| 主数据库模型 | |||
| 辅助数据库模型 | |||
| 数据库引擎排名 | 得分 29.86 排 #29 整体 | 得分 6.32 排 #67 整体 | 得分 0.43 排 #255 整体 |
| 网站 | |||
| 技术文档 | |||
| 开发人员 | Apache Software Foundation | ||
| 初始版本 | 2013 | 2015 | 2018 |
| 当前版本 | 2.0.8, 八月 2021 | ||
| 许可证信息 | 开源信息 | 开源信息 | 开源信息 |
| 仅基于云的信息 | 不 | 不 | 不 |
| DBaaS 产品/服务信息 | |||
| 实现语言 | Go | Go | Java |
| 服务器操作系统 | Linux OS X | Linux Windows | 具有 Java 虚拟机的操作系统(>= 1.8) |
| 数据方案 | 无架构 | 是 | 是 |
| 类型 | 数值数据和字符串 | 仅数字数据 | 是 |
| XML支持 | 不 | 不 | 不 |
| 二级索引 | 不 | 不 | 是 |
| 断续器信息 | 类似 SQL 的查询语言 | 不 | 类似 SQL 的查询语言 |
| API 和其他访问方法 | HTTP API JSON over UDP | RESTful HTTP/JSON API | JDBC Native API |
| 支持的编程语言 | .Net Clojure Erlang Go Haskell Java JavaScript JavaScript (Node.js) Lisp Perl PHP Python R Ruby Rust Scala | .Net C++ Go Haskell Java JavaScript (Node.js) Python Ruby | |
| 服务器端脚本 | 不 | 不 | 是 |
| 触发器 | 不 | 不 | 是 |
| 分布方法 | 分片 | 分片 | |
| 复制方法 | 可选复制因子 | 是 | |
| 地图共享资源 | 不 | 不 | 与Hadoop和Spark集成 |
| 一致性概念 | 没有 | 最终一致性 与Raft的强一致性 | |
| 外键 | 不 | 不 | 不 |
| 交易概念 | 不 | 不 | 不 |
| 并发 | 是 | 是 | 是 |
| 耐久性 | 是 | 是 | 是 |
| 内存中功能 | 是 | 不 | 是 |
| 用户概念 | 通过用户账户进行简单的权限管理 | 不 | 是 |
系统供应商提供的详细信息
| 名字 | InfluxDBX | Prometheus | Apache IoTDBX |
| 具体特性 |
| \ | |
| 竞争优势 |
| \ |
|
| 典型用户场景 |
| \ |
|
| 主要客户 |
| \ |
|
| 市场指标 |
| \ |
|
| 许可和定价模式 |
| \ |
|
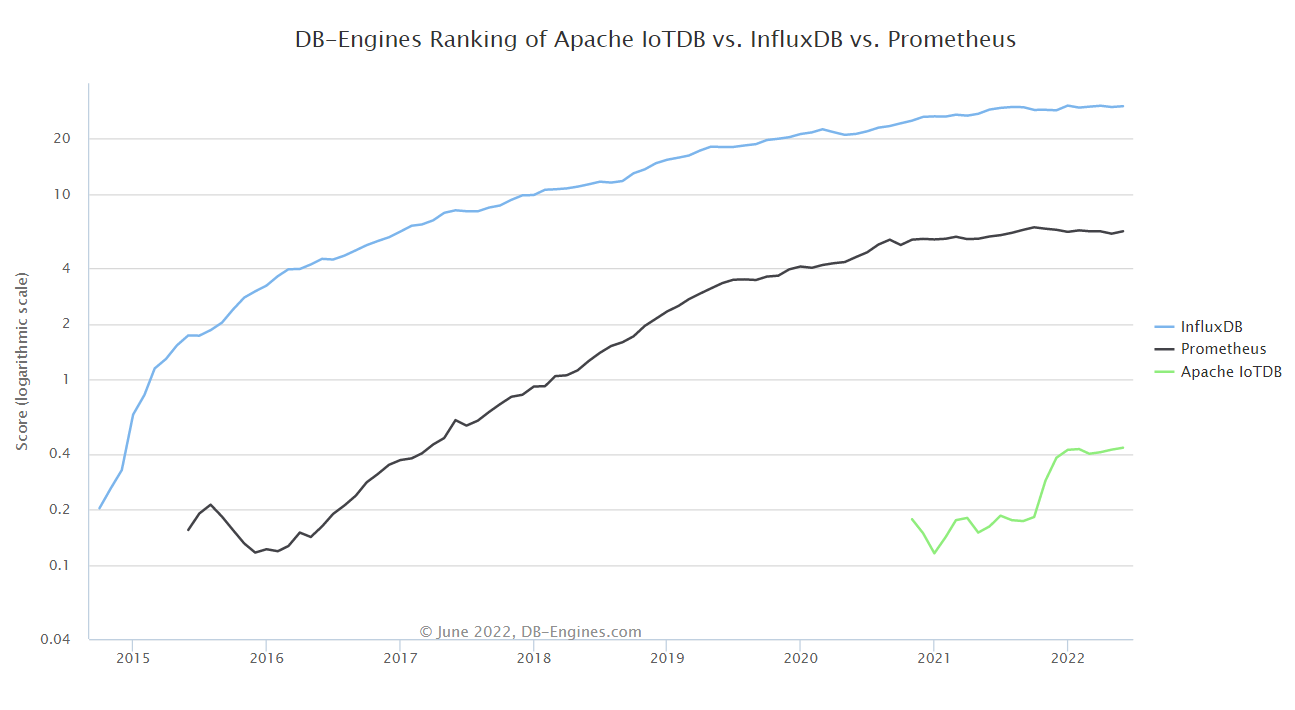
3.3总结
系统供应商提供的详细信息
| 指标 | InfluxDBX | Prometheus | Apache IoTDBX |
| 优点 |
|
|
|
| 缺点 |
|
|
|

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 14
14 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)