
大数据竞赛平台——Kaggle 入门
大数据竞赛平台——Kaggle 入门篇
这篇文章适合那些刚接触Kaggle、想尽快熟悉Kaggle并且独立完成一个竞赛项目的网友,对于已经在Kaggle上参赛过的网友来说,大可不必耗费时间阅读本文。本文分为两部分介绍Kaggle,第一部分简单介绍Kaggle,第二部分将展示解决一个竞赛项目的全过程。如有错误,请指正!
1、Kaggle简介



2、竞赛项目解题全过程
(1)知识准备
(2)Digit Recognition解题过程
下面我将采用kNN算法来解决Kaggle上的这道Digit Recognition训练题。上面提到,我之前用kNN算法实现过,这里我将直接copy之前的算法的核心代码,核心代码是关于kNN算法的主体实现,我不再赘述,我把重点放在处理数据上。
以下工程基于Python、numpy
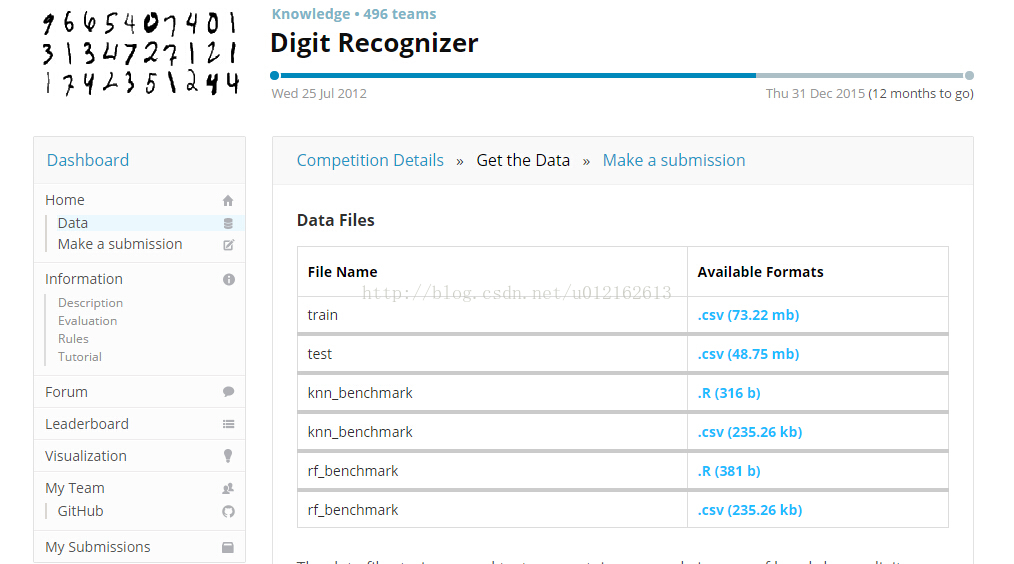
- 获取数据
从”Get the Data“下载以下三个csv文件:

- 分析train.csv数据
train.csv是训练样本集,大小42001*785,第一行是文字描述,所以实际的样本数据大小是42000*785,其中第一列的每一个数字是它对应行的label,可以将第一列单独取出来,得到42000*1的向量trainLabel,剩下的就是42000*784的特征向量集trainData,所以从train.csv可以获取两个矩阵trainLabel、trainData。
下面给出代码,另外关于如何从csv文件中读取数据,参阅:csv模块的使用
def loadTrainData():
l=[]
with open('train.csv') as file:
lines=csv.reader(file)
for line in lines:
l.append(line) #42001*785
l.remove(l[0])
l=array(l)
label=l[:,0]
data=l[:,1:]
return nomalizing(toInt(data)),toInt(label)这里还有两个函数需要说明一下,toInt()函数,是将字符串转换为整数,因为从csv文件读取出来的,是字符串类型的,比如‘253’,而我们接下来运算需要的是整数类型的,因此要转换,int(‘253’)=253。toInt()函数如下:
def toInt(array):
array=mat(array)
m,n=shape(array)
newArray=zeros((m,n))
for i in xrange(m):
for j in xrange(n):
newArray[i,j]=int(array[i,j])
return newArray
nomalizing()函数做的工作是归一化,因为train.csv里面提供的表示图像的数据是0~255的,为了简化运算,我们可以将其转化为二值图像,因此将所有非0的数字,即1~255都归一化为1。nomalizing()函数如下:
def nomalizing(array):
m,n=shape(array)
for i in xrange(m):
for j in xrange(n):
if array[i,j]!=0:
array[i,j]=1
return array
- 分析test.csv数据
test.csv里的数据大小是28001*784,第一行是文字描述,因此实际的测试数据样本是28000*784,与train.csv不同,没有label,28000*784即28000个测试样本,我们要做的工作就是为这28000个测试样本找出正确的label。所以从test.csv我们可以得到测试样本集testData,代码如下:
def loadTestData():
l=[]
with open('test.csv') as file:
lines=csv.reader(file)
for line in lines:
l.append(line)
#28001*784
l.remove(l[0])
data=array(l)
return nomalizing(toInt(data)) - 分析knn_benchmark.csv
前面已经提到,由于digit recognition是训练赛,所以这个文件是官方给出的参考结果,本来可以不理这个文件的,但是我下面为了对比自己的训练结果,所以也把knn_benchmark.csv这个文件读取出来,这个文件里的数据是28001*2,第一行是文字说明,可以去掉,第一列表示图片序号1~28000,第二列是图片对应的数字。从knn_benchmark.csv可以得到28000*1的测试结果矩阵testResult,代码:
def loadTestResult():
l=[]
with open('knn_benchmark.csv') as file:
lines=csv.reader(file)
for line in lines:
l.append(line)
#28001*2
l.remove(l[0])
label=array(l)
return toInt(label[:,1])到这里,数据分析和处理已经完成,我们获得的矩阵有:trainData、trainLabel、testData、testResult
- 算法设计
def classify(inX, dataSet, labels, k):
inX=mat(inX)
dataSet=mat(dataSet)
labels=mat(labels)
dataSetSize = dataSet.shape[0]
diffMat = tile(inX, (dataSetSize,1)) - dataSet
sqDiffMat = array(diffMat)**2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5
sortedDistIndicies = distances.argsort()
classCount={}
for i in range(k):
voteIlabel = labels[0,sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]关于这个函数,参考: kNN算法实现数字识别
- 保存结果
def saveResult(result):
with open('result.csv','wb') as myFile:
myWriter=csv.writer(myFile)
for i in result:
tmp=[]
tmp.append(i)
myWriter.writerow(tmp)- 综合各函数
上面各个函数已经做完了所有需要做的工作,现在需要写一个函数将它们组合起来解决digit recognition这个题目。我们写一个handwritingClassTest函数,运行这个函数,就可以得到训练结果result.csv。
def handwritingClassTest():
trainData,trainLabel=loadTrainData()
testData=loadTestData()
testLabel=loadTestResult()
m,n=shape(testData)
errorCount=0
resultList=[]
for i in range(m):
classifierResult = classify(testData[i], trainData, trainLabel, 5)
resultList.append(classifierResult)
print "the classifier came back with: %d, the real answer is: %d" % (classifierResult, testLabel[0,i])
if (classifierResult != testLabel[0,i]): errorCount += 1.0
print "\nthe total number of errors is: %d" % errorCount
print "\nthe total error rate is: %f" % (errorCount/float(m))
saveResult(resultList)运行这个函数,可以得到result.csv文件:
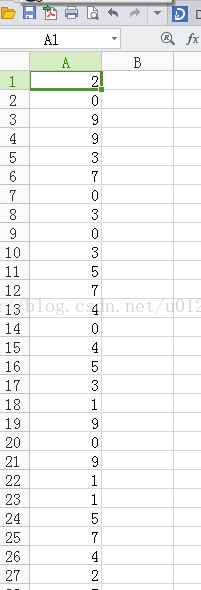
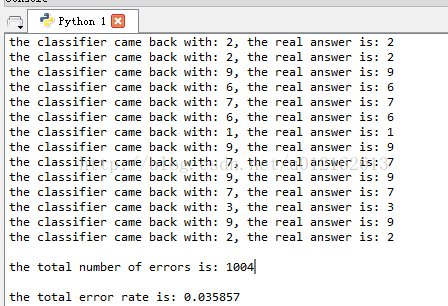
28000个样本中有1004个与kknn_benchmark.csv中的不一样。错误率为3.5%,这个效果并不好,原因是我并未将所有训练样本都拿来训练,因为太花时间,我只取一半的训练样本来训练,即上面的结果对应的代码是:
classifierResult = classify(testData[i], trainData[0:20000], trainLabel[0:20000], 5)训练一半的样本,程序跑了将近70分钟(在个人PC上)。
- 提交结果


旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐
 423
423 2
2- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)