
PyTorch nn.GRU 使用详解
我们看官方文档一些参数介绍,以及如下一个简单例子:看完之后,还是一脸懵逼: 输入什么鬼? 输出又什么鬼?(这里我先把官网中 h0 去掉了,便于大家先理解更重要的概念)import torchfrom torch import nnrnn = nn.GRU(10, 20, 2)input = torch.randn(5, 3, 10)output, hn = rnn(input)运行之后,各变量的s
我们看官方文档一些参数介绍,以及如下一个简单例子:
看完之后,还是一脸懵逼: 输入什么鬼? 输出又什么鬼?
(这里我先把官网中 h0 去掉了,便于大家先理解更重要的概念)
import torch
from torch import nn
rnn = nn.GRU(10, 20, 2)
input = torch.randn(5, 3, 10)
output, hn = rnn(input)
运行之后,各变量的shape如下:
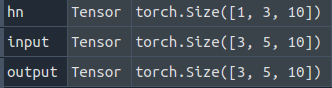
要使用GRU这个layer,就要明白,要先定义GRU,然后才是调用这个定义好的GRU.
咱们先针对例子中的涉及到参数先讲解
定义GRU
rnn = nn.GRU(input_size,
hidden_size,
num_layers
在上述例子中,rnn = nn.GRU(10, 20, 2)
input_size = 10
hidden_size = 20
layer_num = 2
只有 input_size 是要根据你的 input tensor来设置,而hidden_size就是控制输出中的hidden_out的维度(输出tensor最后一个维度D*hidden_out,这个D默认是1,bidirectional=True时变成 2)。num_layers跟最后输出的hidden tensor第一个维度相关。
例子中,初始化了一个 输入 tensor,input = torch.randn(5, 3, 10)
注意,这个 tensor 是要塞进 GRU的,所以每个维度的含义要跟GRU规定的对应的上。
GRU的输入: input, h_0
定义完了GRU,使用的时候,两个输入,一个是 input tensor, 一个是 h_0 tensor.
h_0 tensor咱们先不管,所以调用 GRU一般这样用
rnn(input)
对于这个input tensor,GRU是这样的定义的。
如果输入的tensor只有两个维度: (sequence_length, input_size)
如果输入的tensor有三个维度: (sequence_length, batch_size, input_size)
如果在定义 GRU 的时候,设置了 batch_first = True
那么输入的tensor的三个维度: (batch_size, sequence_length, input_size)
这就是为什么,很多人 embedding 之后,要把 tensor 的前两个维度转置一下,因为,大家正常使用的时候,batch_size在第一维度。也可以设置batch_first=True,这样就不用转置了。
GRU的输出
output, hn = rnn(input)
输出为两个 tensor.
咱们先看output的每个维度的含义
如果没有设置 batch_first=True,且有 batch_size这个维度的话,那么输出为:
(sequence_length, batch_size, D*hidden_out)
输出怎么用?
输出有两个 output, hidden,一般用hidden,与后面的层连接
bidirectional = False
output, hn = rnn(input)
h = hn[-(1 + int(bidirectional)):] # 用最后一个hidden layer的结果
x = torch.cat(h.split(1), dim=-1).squeeze(0) # 在上一步操作中,0维中只有一个元素,用squeeze把0维缩掉,变成两维( batch_size, hidden_out)
x = self.fc1(x) # 与下面的层连接即可
上述代码解释:
bidirectional是定义 GRU时的一个参数,分 True 和 False.
输出的hidden各个维度的含义: (D∗num_layers, batch_size,hidden_out)

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 19
19 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)