

如何用SPSS做logistic回归
详细到只有作者本人能看懂的SPSS逻辑回归育儿经
参考教程:B站教程👈课讲的挺垃圾的,主要还是看pdf👈pdf其实也蛮垃圾的,主要还是看文献1和2
通过该例,我们尝试用年龄、肿瘤大小、肿瘤扩散等级来预测癌变部位的淋巴结是否含有癌细胞。
无法使用多元线性回归模型的原因,老师在这里提到“因为残差不满足正态性、无偏性、共方差性等假设”。(←也是一种思路,可以与之前从吴恩达老师那里学的思路进行比较。)
步骤1
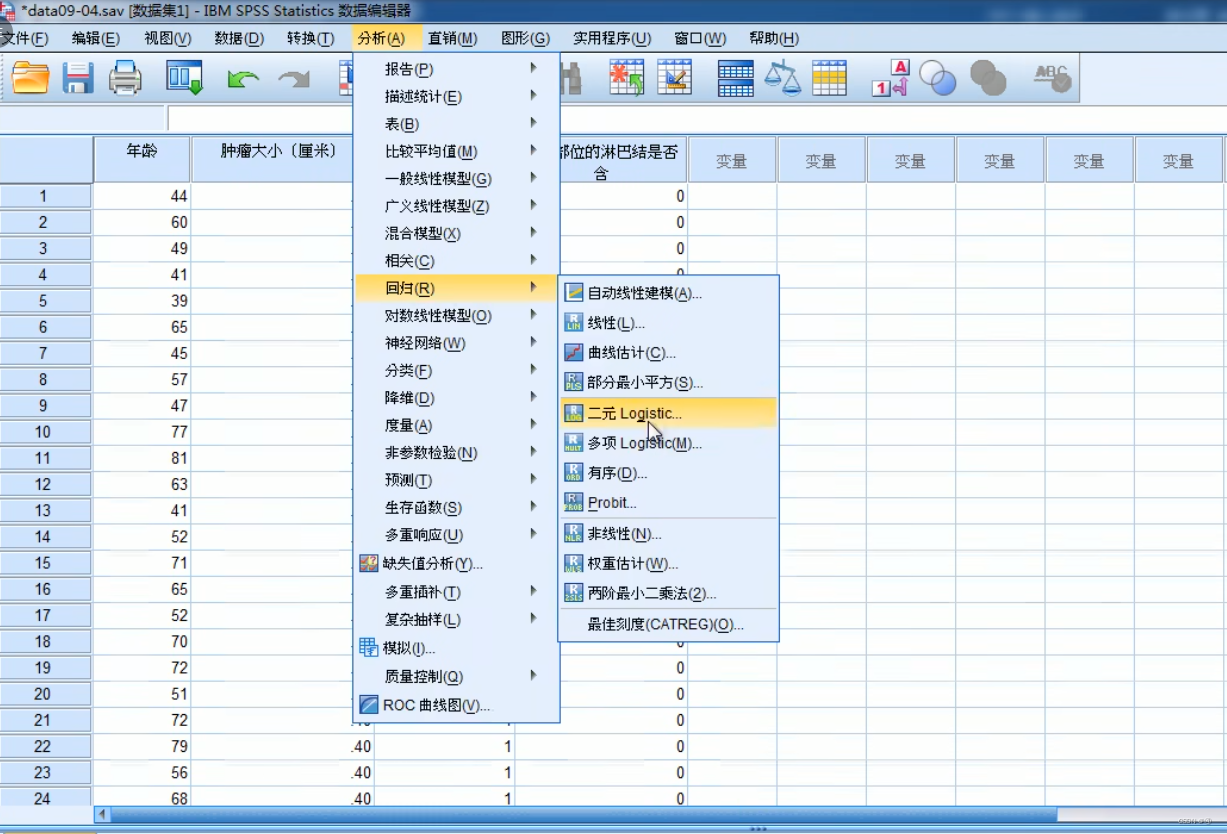
步骤2
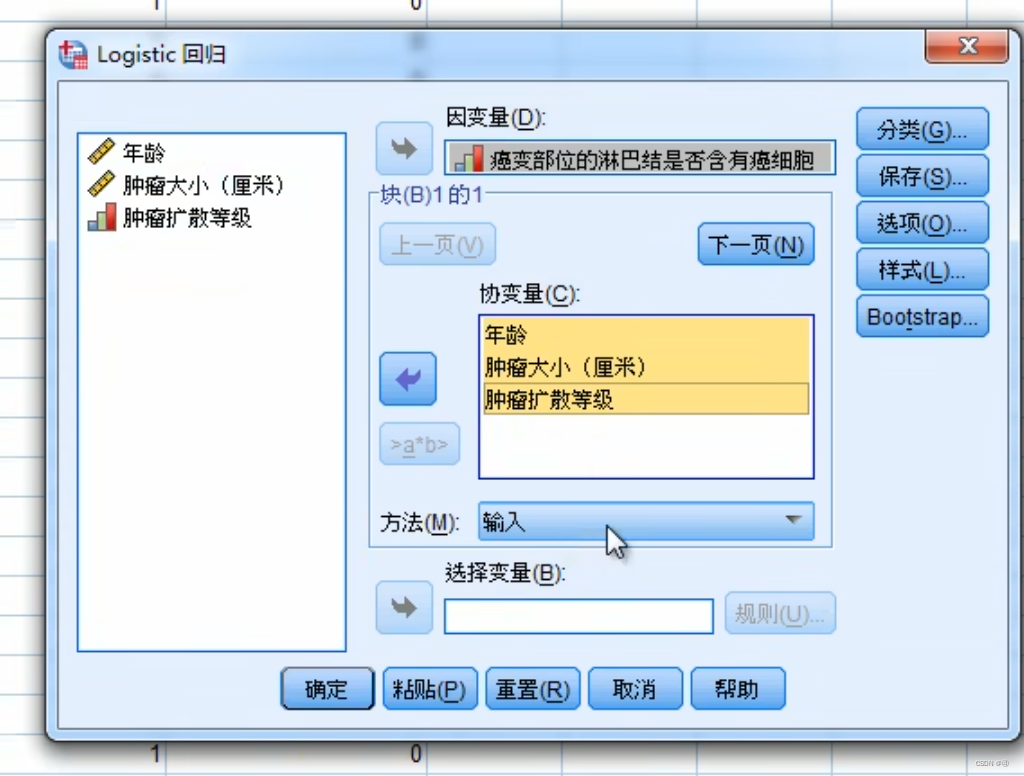
因变量自然就是癌变部位xxx,协变量在这里就相当于自变量的意思?通过百度的搜索,协变量应该是控制变量的感觉,但这里似乎就直接看作自变量了,暂且先这么认为。
可以通过该按钮 将两个变量处理为交互项,放入该协变量组,不过本例中不涉及交互项。
将两个变量处理为交互项,放入该协变量组,不过本例中不涉及交互项。
如果想设立多个协变量组,可以通过上一页、下一页进行切换(应该就是设置自变量不同的模型?)
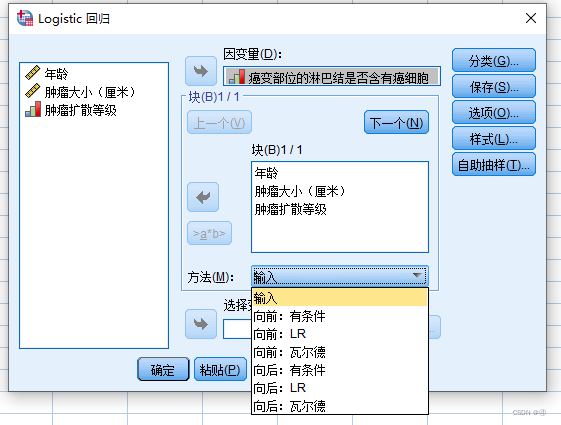
方法这里有7种不同的方法,其中输入就是协变量全部进入模型;向前/向后分别代表着向前/向后逐步法(应该涉及到逐步回归的方法),有条件/LR/瓦尔德,分别代表着将变量剔除出模型的不同依据(老师有进行简单说明但暂时听不懂,之后学了逐步回归相关的知识再回来看看)←记得参考pdf教程进行学习,老师解释的内容大多是pdf教程中的
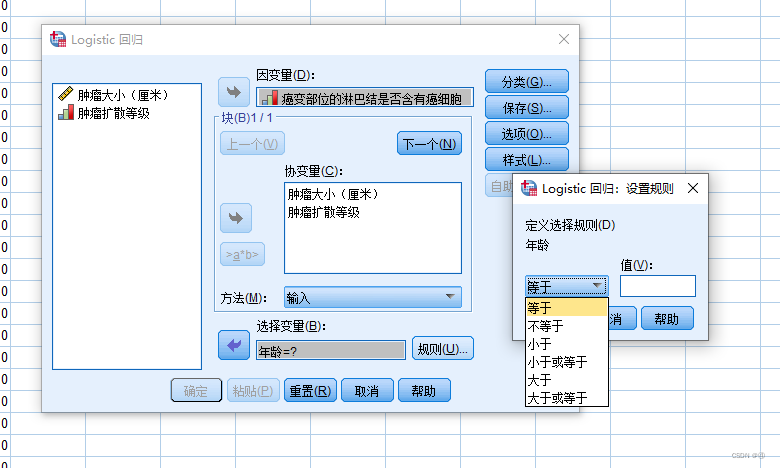
下面的选择变量,应该就是可以选择一个变量来设置样本入选的规则,例如年龄小于50才可入选(但好像只能选择一个规则,假如说我要20<年龄<50就做不到?需要通过外部的选择个案来筛选?)
步骤3
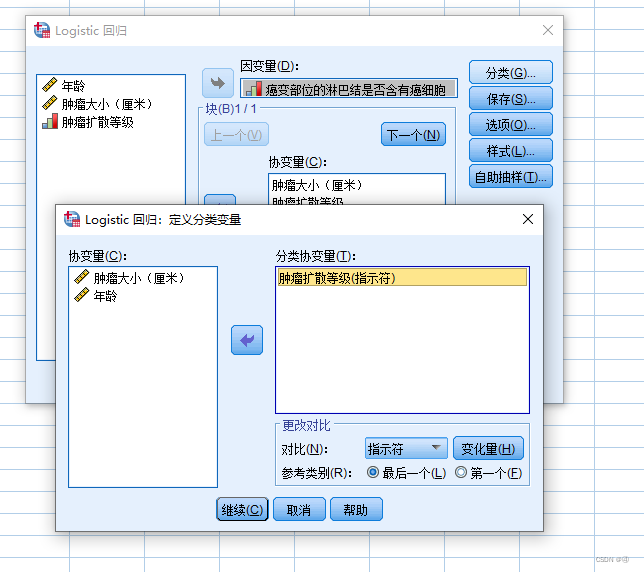
之后点击右侧第一个按钮:分类,弹出上图所示的对话框,该对话框的作用在于能将一个多分类变量转换成多个二分类变量,也就是转换成哑变量(或称之为虚拟变量)。为什么要这么做呢?假如一个多分类变量的编码分别为0、1、2、3,放在同一个变量中进行回归,得到的回归系数是没有意义的(比如回归系数是10,那就代表1分类比0分类多了10,2分类比1分类多了10…实际情况中,每个分类的区别不会是像这样相同的,甚至正负都有可能不一样)。因此我们要将其转化为哑变量,才能放入回归模型中。不只是在logistic回归中,在其他回归例如多重线性回归里,遇到多分类变量也需要设置哑变量。更多拓展可见:文献1
下方更改对比的意思就是不同的哑变量的编码方式,不同编码方式的区别具体可见文献2,一般来说似乎用默认的“指示符”就可以了:
Indicator(指示对比):用于指定某一分类为参照,指定的参照取决于Reference Category中选择Last还是First,即只能以该变量的第一类或者最后一类作为参照。Indicator为默认方法,也是我们最常用的设置参照类的方法。
假如说想要更改编码方式,就选中要更改的新方式后,点击“变化量”按钮(其实应该是变化change,软件的翻译出错了)
参考类别的意思是,在输出结果后以哑变量中哪个种类作为参照系。我们先来看一下这个变量:
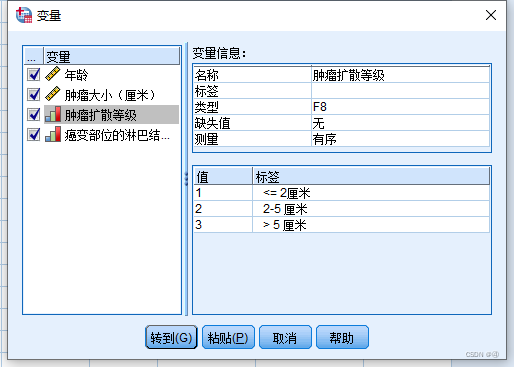
那么在参考类别中选中“最后一个”的意思是,以“>5厘米”作为参照系。后续输出结果时,我们能看到各个变量是否是显著的,而这种多分类变量则是进行分类变量内部水平的比较,例如“≤2cm”与“>5cm”相比是否有显著差异,“2-5cm”与“>5cm”是否有显著差异。这可以在结果观测中的块1——⑤方程中的变量 处看到。
设置完哑变量后点击“继续”
步骤4

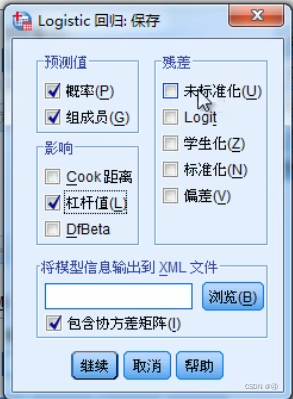
接下来打开保存这一选项,预测值的框如上图所示,较好理解就不解释了,一般来说概率和组成员都可以勾起来,功能都很实用。
—————————————————————————————————————————————
接下来讲解“影响”这一框。
在PDF线性回归的章节中,对于cook距离和杠杆值的解释是:

百度百科对cook距离的解释是:

也就是说,cook距离是一个用于诊断个案中异常数据的指标,较大的cook距离表示该个案对回归模型(系数)的影响较大。(但影响较大就一定是异常值吗?)不过话又说回来,logistic回归模型中,回归系数的数学意义是什么呢?后续需要再研究一下→见本文结果观测3.⑤或《例解回归分析》P253
杠杆值的作用看起来似乎和cook距离相似,不过后者是测量对回归系数的影响,前者是测量对整体拟合效果的影响?这只是我自己的解读,暂未经过证实,有待后续考证。
DfBeta同样在线性回归的章节中有解释:

这看起来也就很好理解了。
————————————————————————————————————————————————————
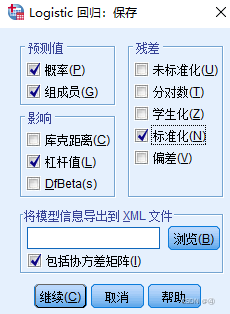
接下来讲解“残差”这一框。
这里面的各个选项同样在PDF线性回归章节中有解释:


相当好理解。不过偏差是啥?对应的是删除吗?
根据视频演示,一般来说只需勾选如下几个:
步骤5
接下来打开选项,看“统计和图”这一栏:
根据PDF:

其中PDF的P434页解释了该拟合度/统计量的含义,也就是用来检测整个模型的拟合优度(注意该统计量的适用情况!!!):

个案残差列表也相对好理解:

即输出离群值个案,还是所有个案的上述统计量
估值的相关性、迭代历史记录我不太理解,但看了各种文章似乎都没解释,也没勾上,就先不管了;而exp(B)就是置信区间,很好理解:

————————————————————————————————————————————————————————————
接下来看“输出”这一栏:

很好理解,一般是按默认的勾选“在每个步骤中”,但这真的不会输出太多表吗?
————————————————————————————————————————————————————————————
接下来看“步进概率”这一栏:

查了一下别的文章:

还是不太能很好地理解什么叫做“进入模型和从模型中剔除的依据”,在选择变量,还没有开始跑模型的时候已经做了一次显著性检验了吗?还是说只是单纯地,在跑完模型之后,看看各个自变量是否对因变量有显著影响,以p≤0.05作为有显著影响的标准,以p>0.10作为没有显著影响的标准?←有待后续验证←已解决,见结果观测的第二个表
后续的几项相对好理解:

一般来说只要勾选以下这些,看别的文章也有多勾个置信区间的(本PDF也勾了):
结果观测
文献1:完整的二元logistic回归spss教学
文献2:与文献1相互补充,使用同一数据集
↑以上两篇文献相当重要,之后的说明很大程度上也以它们为主,以PDF为辅(因为感觉PDF很多表都没说清楚)
1.输出表格的第一部分:回归前的情况概览
输出的表可以分为三大部分,第一大部分有三个表:
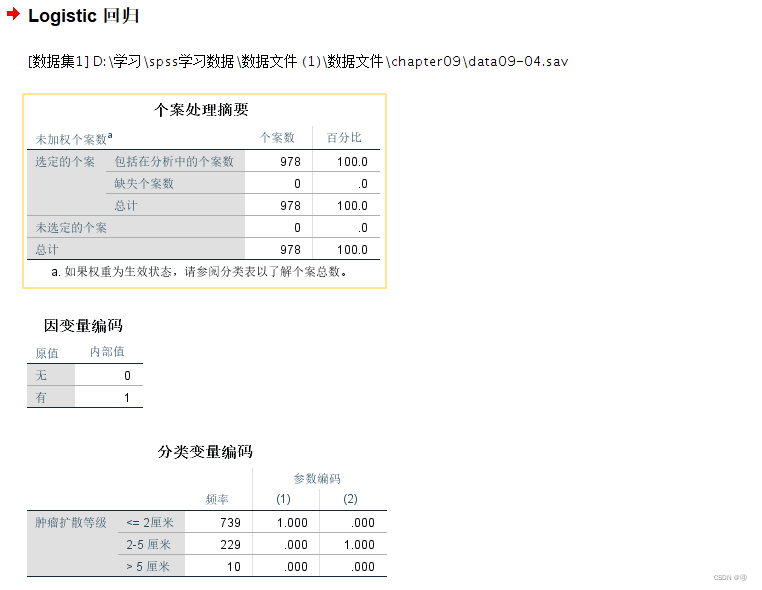
可以理解为在回归前进行的各种处理,其中第三个表就是解释虚拟变量设置的,总共分为三组,小于等于2cm的编为为(1,0),有739个样本,其余如表所示同理可得。
——————————————————————————————————————————————————————————
2.输出表格的第二部分:起始块
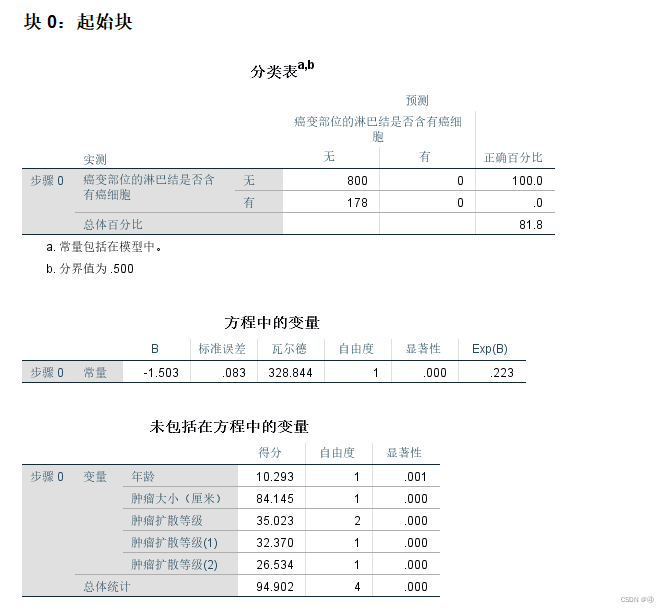
块0:起始块,指的是模型中未纳入任何自变量,只有常数项时的输出结果。也可以称之为基线模型或无效模型。在起始块中一般我们只需要看第三个表,不过来都来了还是全介绍下。
①分类表
模型中只有常数项时,预测结果的正确率,本例为81.8%
②方程中的变量
解释第二个表之前我们需要先来了解一个瓦尔德统计量:

如图中所述,该统计量是用来检验各自变量与因变量之间是否存在显著的线性关系,这让我联想到了线性回归中要进行的两个检验——T检验与F检验,其中,F检验是检验整个模型的,而T检验则与此处的利用wald统计量进行的检验相似,用来检验各回归系数是否显著。
回到第二个表中来,由于P<0.05,因此拒绝原假设,即β≠0,常数项不等于0。(不过由于未纳入其他变量,该表也是无意义的)
但要注意的是,除了PDF中所说的解释变量的系数绝对值较大时不适合用wald检验外,文献2还提到了存在共线性时同样不适合适用wald检验:

联想了一下T检验,听起来似乎确实如此。
③未包括在方程中的变量
在块0中,除了常数项,其他都可以称作“未包括在方程中的变量”
我们来看看文献1是怎么说的:
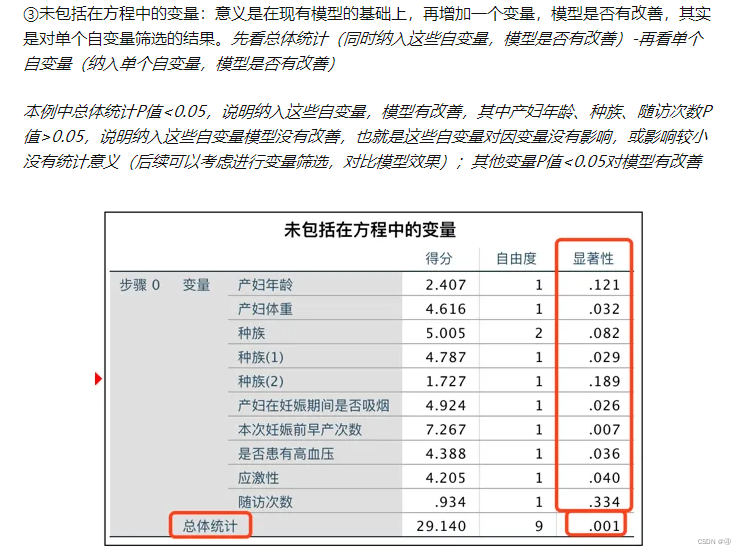
所谓“现有模型”就是指仅有常数项的基线模型。不过有一点不明白的是,此处检验模型是否改善用的是什么方法?我们来看看PDF上是怎么说的:
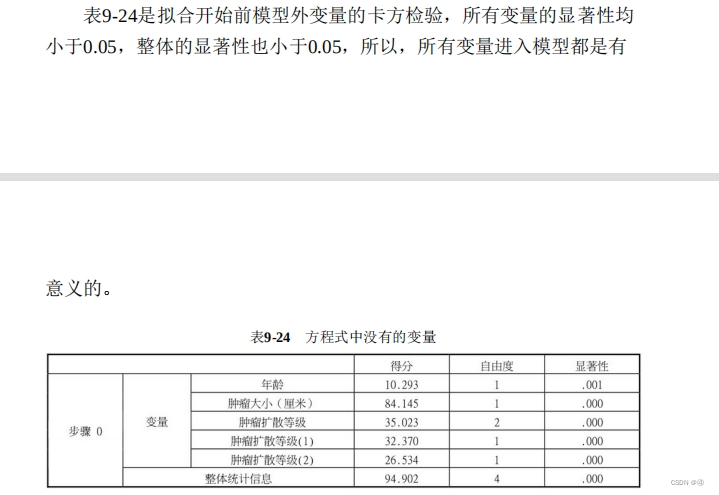
该表解释了前面提到的【选项】→【步进概率】的作用,即在拟合前进行卡方检验,分别检验每个自变量与因变量“是否有癌细胞”的关系,从而得出显著性水平,再与进入(0.05)和删除(0.10)的两个值进行比较。由于本例中所有变量显著性都小于0.05,因此都没有删除。
问题1:等一下,卡方检验的自变量因变量不都应该是定类的数据吗?年龄、肿瘤大小作为定距的数据,为啥可以进行卡方检验?????而且在线性回归中也没有这个步骤啊,在没有控制变量的情况下对单个变量进行单独的检验真的有意义吗?在线性回归里不是做完回归后,对各个自变量的回归系数进行t检验吗?
问题2:如果p值在0.10和0.05之间,那要怎么处理?按照文献1似乎也要舍弃?
问题3:这个得分是啥来着我有点忘了,卡方检验好像确实是有好几种得分计算方式的。
总结:这个点研究了好长时间都没能弄明白,暂时先放过自己吧。可能此处的卡方检验和我之前所学的狭义上的卡方检验不太一样?只是利用了卡方统计量进行了某种别的检验?
—————————————————————————————————————————————————————————————
3.输出表格的第三部分:块1
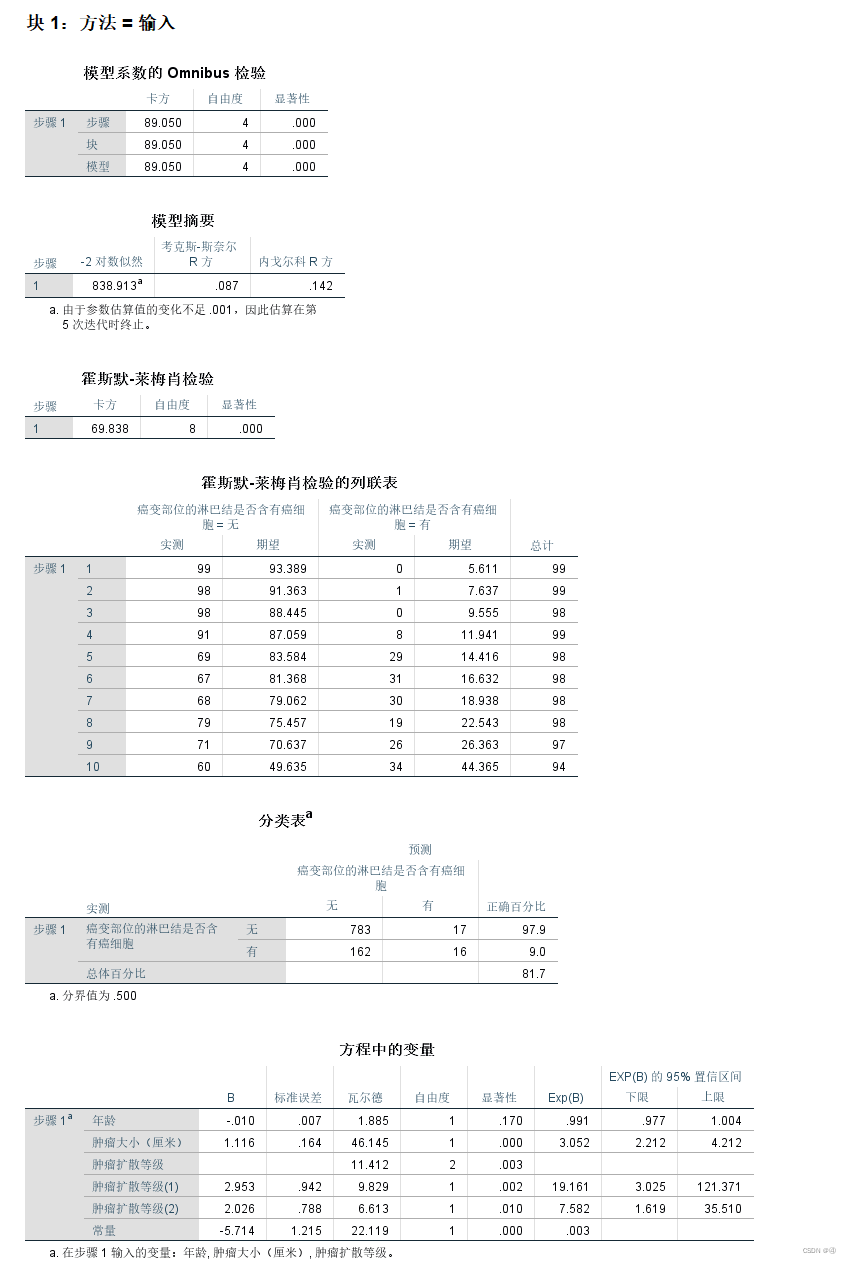
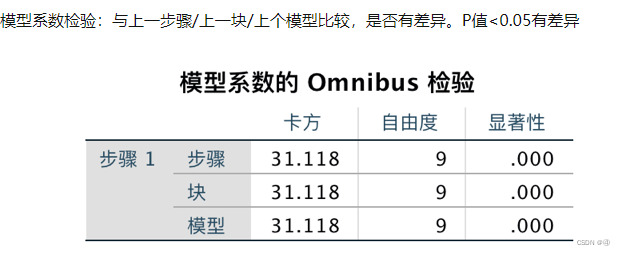
①模型系数的omnibus检验
关于该检验,我到最后都没完全弄懂,只能集各方资料之和去尝试理解。
先来看一下模型、块、步长是啥:

由于我们的例子中只有一组解释变量,并且选择了“输入”的方法,将所有自变量一次性同时全部放入模型,因此在第一个表中,步骤、块、模型的相关数据都是一样的。
那么omnibus检验到底是干了啥?以下摘自各种文献:



注意:此处也称该检验为“似然比卡方检验”,这与下文中文献4所提及的检验,以及《例解回归分析》P255中提到的检验看起来较为相似。只不过《例解》中是用两模型的似然值之差,而文献4用的是两模型的似然值之比。同时,在《例解》中也是用这一方法判断模型是否得到优化,从而决定变量的去留,这与Omnibus检验想要做的事情是一致的。所以Omnibus检验就是似然比卡方检验?
👉突然发现文献2说的也是两模型似然值(不过是-2对数似然值)之差:

以及最终来看看PDF上是咋说的:

综上所述,omnibus检验做的事情就是将加入了各个自变量的模型与块0中的基线模型进行比较,显著则说明这些自变量的加入是对模型有价值的。听起来其实和块0表3中的“总体统计”很像。(不过说了这么多我还是不太理解原理就是了)
但有一点比较奇怪的是PDF上的说法和其他地方的说法不是那么像,“解释变量全体与Logit p之间的线性关系显著”听起来就像是多元线性回归中的F检验。不知道是不是我理解的问题,总之先按照其他地方的说法来理解。(特别是根据上方的“注意”,看了《例解》后我愈发觉得PDF上的说法不靠谱)
——————————————————————————————————————————————————————————
②模型摘要
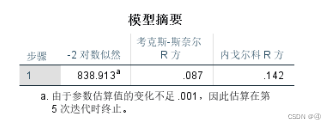
首先我们要了解一下什么叫【似然比检验】:
注意:文献4中的似然比检验在原理上和该表的相似,但具体的公式、细节并不相同
文献4先告诉了我们什么叫做似然函数:

似然比检验:

借助极大似然估计法的思想,令似然函数取得最大值时,参数θ的估计值就最可能是其实际值;反过来,当θ的估计值越接近实际值,似然函数也就会越大!
因此,似然比的公式就是让备择假设θ1的似然函数/原假设θ0的似然函数,如果λ>1,θ1的似然函数大于θ0的似然函数,那就说明θ1比θ0更接近参数实际值(听起来有点像方差分析中的F检验)。如上图所述,当λ大于某个临界值时,就可以拒绝原假设。
—————————————————————————————————————————————
两个需要区分的概念:
1.似然值和似然比:我们统一称由似然函数计算出的值为似然值,而非似然比。因为似然比听名字总让人联想到两个似然函数的比值。像在PDF中提到的“似然比值”其实就是似然值。
2.似然值和对数似然值:网上查到的,以及《高级心理统计》中用的-2LL(log likelihood)指的是-2倍的对数似然值,即对似然值取对数再乘以-2。是否取了对数影响到了值域

(上图即为-LL)
—————————————————————————————————————————————
如何评价逻辑回归模型的拟合度


如图中所述,由于似然函数是概率的累乘,因此似然值必定在0~1之间,-2*似然值的值域为(-2,0)。而SPSS中的“-2对数似然”取值则为(0,+∞),所以例子里能取到八百多是正常的。
似然值越大,拟合效果越好,相对应的就是对数似然越大,以及-2对数似然(-2LL)越小,拟合效果越好。
Cox和Nag两种伪测定系数也很好理解,看上图,以及pdf中:

(补充最后一句话:“说明回归方程的拟合度越高”)
不过要注意的是,“由于它们不能直接反映模型对结果变量方差的解释比例,因此不是真正意义上的测定系数,故命名为伪测定系数”
此外,在《例解》p257中也有提到其他测量拟合度的指标——根据分类的准确度来评判模型的拟合度,具体看书。
—————————————————————————————————————————————
回到表2本身来,尽管我们知道了-2对数似然越小,拟合效果越好,但是有没有什么判断的标准呢?该表中也没有一个显著性检验的P值让我们参考。
PDF中是这么说的,感觉很不靠谱:
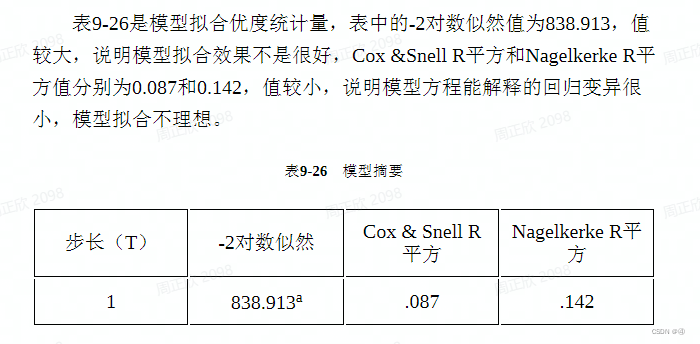
文献2中提到:

文献1中提到:
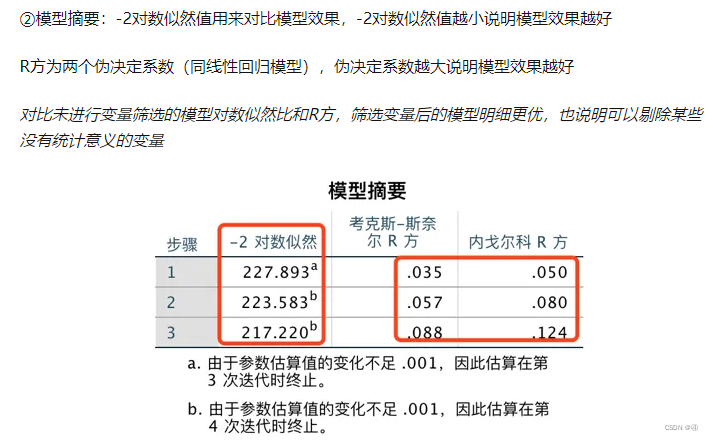
综上,不管是-2对数似然,还是两个伪测定(决定)系数,都应该是进行模型间的比较来得出拟合效果是否得到优化,而不是单纯地看值的大小(尽管Nagelkerke R²越接近1拟合度越高,但由前文可知,这个指标也不能反映真正的方差解释比例)
—————————————————————————————————————————————————————————————
③霍斯默-莱梅肖检验(同为拟合度检验)
该表在文献1、2中是没有的,原因在于该拟合度检验的应用场景不太一样:

HL检验的文章1
HL检验的文章2 ←基本上看文章2就可以了
HL3

复习一下卡方检验的卡方统计量:
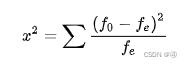
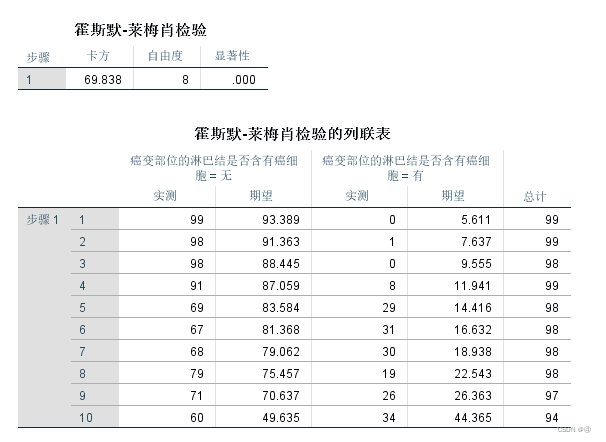
结合上述的四个步骤,以及列联表卡方检验的原理,我们可以发现这个Hosmer检验其实很简单:先是按预测概率由小到大排序分组,例如上表中第一组是含癌细胞概率最小的组,第十组则概率最大。得出实测f0与期望fe之后,便可以计算卡方统计量了。然后根据卡方的P值来确定实际情况与预测结果之间的差异是否显著,从而判断出该模型的拟合效果好不好。简单来说,就是在传统的列联表卡方检验之前需要做一个分组的工作。
—————————————————————————————————————————————————————————————
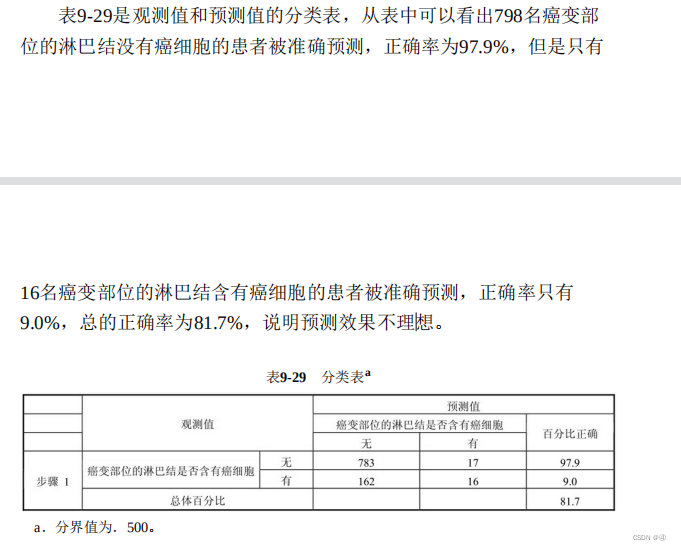
④分类表(预测正确率)
这个表我们在块0中也有见过,翻上去看看,当时的正确率是81.8%;
而此处,没有癌细胞的正确预测率虽然很高,但有癌细胞的正确预测率不到10%,整体预测的正确率甚至还不如基线模型!
—————————————————————————————————————————————————————————————
⑤方程中的变量
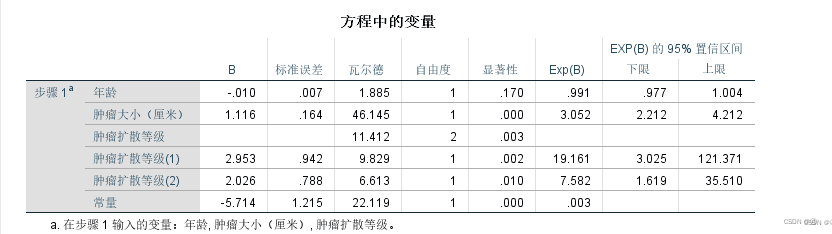
这个表是我们的老朋友了,详情可以见起始块②这一部分。从该表中我们可以看到,年龄是不显著的;肿瘤扩散大小是显著的;结合步骤3中的说明,扩散等级1(≤2厘米)与扩散等级2(2-5厘米),与“>5厘米”相比都是显著的。
B代表的是解释变量的回归系数,那Exp(B)是什么意思?从文献1得知:

结合p值与OR值进行综合解释(文献1):
(ps:文中说的“其他种族”指的并不是除了某个种族外的其他种族,而是一个确实存在的分类叫做其他种族,在此处被作为参照系)
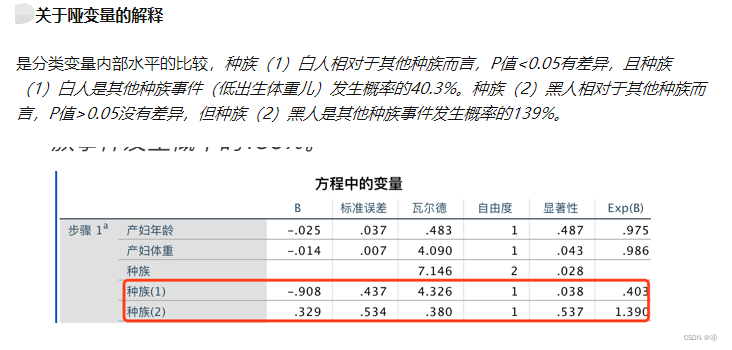
上面的说法有点容易让人产生疑惑,难道黑人是其他种族发生事件概率的1.4倍,也是没有差异吗?答案应该确实如此,你看白人0.4倍,相比于黑人的1.4倍,差异确实是更大的,因此在统计学上才是显著的。←此处是我自己的猜想,但应该没错
此外,还需要注意的是,在做自变量筛选时,哑变量遵循同进同出原则,整体上不满足,即使单个分类满足也不纳入(摘自文献1)
4.结果观测总结
写了一大堆的结果观测的指标,有些不同指标的意义是重复的,整体上显得比较凌乱,下文综合梳理一下。
①块0
在回归前先看起始块的第三个表“未包括在方程中的变量”,看看和基线模型相比这些新加入的变量是否有价值
②
后续步骤
逻辑回归并不是这样跑一次就结束了,后续的步骤从文献1的这里开始读:
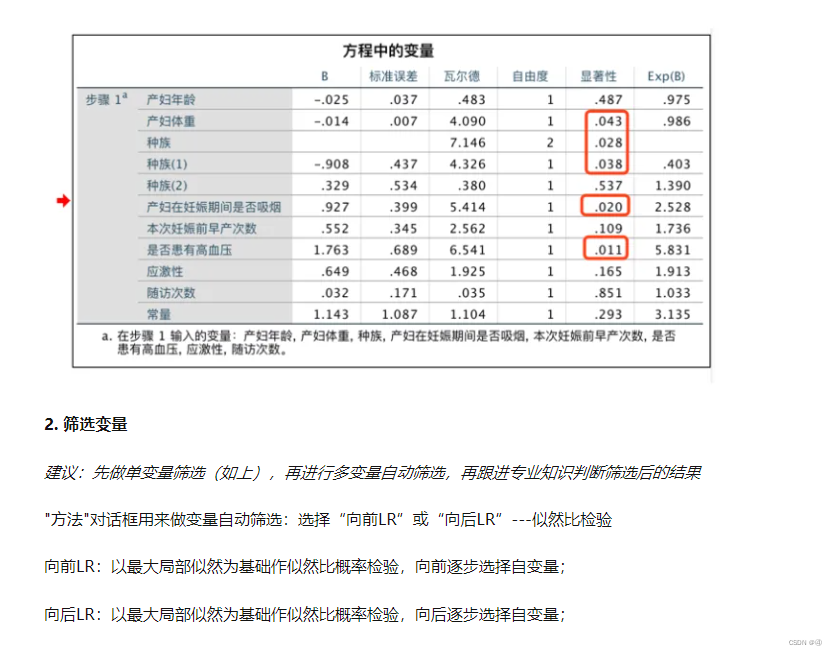
—————————————————————————————————————————————————————
什么叫做“先做单变量筛选”呢?我个人认为指的就是把上表中不显著的变量剔除,留下红框中显著的变量。
但事实上这么做又不完全对,文献2里面提到:

比分检验我有点不知道指啥,但似然比检验指的就是-2对数似然及其相对应的两种R²。
文献1提到的多变量自动筛选又是啥?就是在步骤2的对话框中,将方法由输入切换成向前LR/向后LR,通过SPSS的自动筛选方法选出合适的自变量,文献2也是这么教的。所以前面这个我们很熟悉的,利用wald检验的“方程中的变量”的表似乎可以无视了?或者说参考参考,简单看看就好。
后续就很简单了,继续按文献1中的思路,根据向前/向后LR给出的多次迭代结果,比较R²、预测准确率这些数据,看看迭代多次的模型效果如何,以及还有哪些自变量包含在最终的模型中。如果有一些被剔除的变量但根据专业知识却是认为有用的,就可以强行纳入,然后再用输入的办法跑一遍,得到最终的模型即可。
所以中间说了半天的一大堆指标,比如omnibus检验和霍斯默-莱梅肖检验就没用了?←omnibus好像还真没用上,而霍斯默-莱梅肖检验的应用场景不太一样(虽然我也没完全搞懂),其他所有指标都用上啦~!

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 27
27 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)