
深度学习——ResNet超详细讲解,详解层数计算、各层维度计算
残差神经网络(ResNet)
1 缘由
在ResNet之前的网络层数都不是很高,14年的VGG网络才只有19层,但是ResNet的网络层数达到了惊人的152层。许多人会有一个直观的印象,也就是网络层数越多,训练效果越好,但是这样的话VGG网络为什么不采取152层而是采用19层呢?其实是因为训练模型的准确度不一定和模型层数呈真相关的关系。因为随着网络层数的加深,网络准确需出现饱和,会出现下降的现象。

上图中明显可以看出56层的网络比20层网络的训练效果要差,许多人第一反应就是过拟合,但事实并不如此,因为过拟合现象的训练集准确度会很高,但是从图中可以看出56层网络的训练集准确度同样很低。很显然可知的是,随着层度加深,会出现梯度消失或梯度爆炸的问题,使得深度模型很难训练,但是已经存在BatchNorm等手段缓解这一问题,因此如何解决深度网络的退化问题是神经网络发展的下一个方向。
ResNet是在Alexnet的基础上发展优化而来,残差神经网络的一大优势就是恒等映射。AlexNet的问题在于随着层数的增加导致优化退步的后果。
- GoogleNet采用稀疏结构来一定量减缓这一影响
- 卷积分解(Factorizing Convolutions)
大尺寸的卷积核可以带来更大的感受野,但也意味着会产生更多的参数,比如5x5卷积核的参数有25个,3x3卷积核的参数有9个,前者是后者的25/9=2.78倍。因此,GoogLeNet团队提出可以用2个连续的3x3卷积层组成的小网络来代替单个的5x5卷积层,即在保持感受野范围的同时又减少了参数量
- 卷积分解(Factorizing Convolutions)
- ResNet是通过引入残差来缓解梯度消失/爆炸的现象,但是只能说是缓解,本质上还是存在的。只是由于从loss到输入的有效路径变短了,而求导的时候可以直接加上shortcut的终点层的delta。

2 维度不一致
虚线部分前后block前后的维度不一致,每隔x层,空间上下采样但是深度翻倍。
-
维度不一致体现在两个方面上
-
空间不一致
- 在跳接部分给输入的x加上线性映射W

-
深度不一致
- 全0填充
- 跳接时加1×1卷积层升维
-
-
计算细节
-
基本计算
-
标准卷积

-
1 × 1卷积
-
全连接层卷积
-



3 优势
残差神经网络相较于VGG等神经网络最大的优势在于他引入了恒等映射从而通过计算残差来解决由层数过高产生的退化问题

所谓残差表现在这张图里就是F(x)
- F(x) = H(x) + x
- 其中H(x)就是对于输入X的一个恒等映射
- X就是通过已经捷径(shortcut)得到了原始值
- 如果添加的层可以被构建为恒等映射,更深模型的训练误差应该不会大于他对应的更浅版本。
- 如果恒等映射是最优的,求解器可能简单地将多个非线性连接的权重推向零来接近恒等映射
- 在实际情况下,恒等映射不太可能是最优的,但是有助于对问题进行预处理,如果最优函数比零映射更接近恒等映射,则求解器应该更容易找到关于恒等映射的抖动,而不是将函数作为新函数来学习。

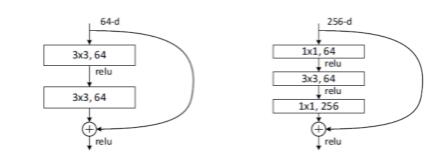
4 残差块的两种结构

官方给了两个ResNet块的结构图,图一为BasicBlock也就是最常规的块,图二被成为BottleBlock
- BasicBlock(常规)(两层结构)
- 在ResNet34的时候是用的这个
- BottleBlock(三层结构)
- 在ResNet50/101/152的时候用的是这个
- 是参考GoogleNet的方式对网络内容进行的一定优化
- 在计算前先接用1×1的卷阶层降维,既保持精度又减少计算量,再对64维进行计算后经过1×1的卷积恢复
- 原结构:3×3×256×256×2 = 1179648
- 现结构:1×1×256×64 + 3×3×64×64 + 1×1×64×256 = 69632
- 从而实现十几倍的计算量缩减,节约计算成本和参数量同时不会影响精度
5 不同层次的ResNet的解析

表格中提到了五种深度的ResNet,分别是18,34,50,101,152。表格的最左侧是说明无论是深度为多少的ResNet都将网络分成了五部分。分别是:conv1,conv2_x,conv3_x,conv4_x,conv5_x。而仔细观察图,可以得出一下几个结论。
- 从50-layer之后,conv2——conv5都是采取三层块结构以减小计算量和参数数量
- 说明50-layer以后开始采用BottleBlock
- 从50-layer之后,层数的加深仅仅体现在conv4_x这一层中,也就是output size为14×14的图像
层数计算(以101-layer为例)
- 首先经过7 × 7 × 64的卷积**(一层)**
- 经过 3 + 4 + 23 + 3 = 33个BottleBlock**( 33 × 3 = 99 层)**
- fc层用于分类 (一层)
- 共计:1+99+1=101层,因此称为101-layer。
- 注:在计算层数的时候仅仅包括卷积层和全连接层不包括池化层等
维度计算(以50-layer为例)
-
Input的img为256×256×3,经过矩阵变换得到3×224×224
-
conv1_x是经过kernel_size(卷积边长) = 7,in_channel(输入频道数) = 3,output_channel(输出频道数) = 64,stride(步长) = 2,padding(边框边界) = 3的卷积
- 可以计算得到输出矩阵的边长应该为 output_size = (224 - 7 + 3 ×2 ) \ 2 + 1 = 112,因此输出64 × 112 × 112的特征矩阵(feature map)
-
conv2_x 经过3 × 3,步长=2,padding = 1的池化后得到(112-3 + 2)\2+1 = 56,因此输出 64 × 56 × 56 的feature map
-
然后再经过如上图所示的三层块结构(BottleBlock)
- 从conv2_x到conv5_x总共经过了(3+4+6+3)=16个BottleBlock块
- 对conv2_x的三个块
- 块1
- F4经过kernel size = 1,in_channel=64,out_channel=64,stride=1的卷积,bn,relu,得到64x56x56的feature map.
接着经过一个kernel size=3,in_channel=64,out_channel=64的卷积,bn,relu,得到64x56x56的feature map.
接着经过一个kernel size=3,in_channel=64,out_channel=256的卷积,bn得到256x56x56的feature map:F4_1
将F4经过一个kernel size=1,in_channel=64,out_channel=256,stride=1的卷积,bn得到256x56x56的feature map:F4_2
F4_1+F4_2后,再经过激活函数relu得到256x56x56 的 F5
- F4经过kernel size = 1,in_channel=64,out_channel=64,stride=1的卷积,bn,relu,得到64x56x56的feature map.
- 块2
- F5经过kernel size = 1,in_channel=256,out_channel=64,stride=1的卷积,bn,relu,得到64x56x56的feature map.
接着经过一个kernel size=3,in_channel=64,out_channel=64的卷积,bn,relu,得到64x56x56的feature map.
接着经过一个kernel size=3,in_channel=64,out_channel=256的卷积,bn得到256x56x56的feature map:F5_1
F5_1+F5后,再经过激活函数relu得到256x56x56 的 F6
- F5经过kernel size = 1,in_channel=256,out_channel=64,stride=1的卷积,bn,relu,得到64x56x56的feature map.
- 块3
- F6经过kernel size = 1,in_channel=256,out_channel=64,stride=1的卷积,bn,relu,得到64x56x56的feature map.
接着经过一个kernel size=3,in_channel=64,out_channel=64的卷积,bn,relu,得到64x56x56的feature map.
接着经过一个kernel size=3,in_channel=64,out_channel=256的卷积,bn得到256x56x56的feature map:F6_1
F6_1+F6后,再经过激活函数relu得到256x56x56 的 F7
- F6经过kernel size = 1,in_channel=256,out_channel=64,stride=1的卷积,bn,relu,得到64x56x56的feature map.
- 块1
- 对conv3_x的四个块
- 块1(涉及矩阵size变化)
- F7经过kernel size = 1,in_channel=256,out_channel=128,stride=2的卷积,bn,relu,得到128x28x28的feature map.
接着经过一个kernel size=3,in_channel=128,out_channel=128的卷积,bn,relu,得到128x28x28的feature map.
接着经过一个kernel size=1,in_channel=128,out_channel=512的卷积,bn得到512x28x28的feature map:F7_1
将F7经过一个kernel size=1,in_channel_256,out_channel=512,stride=2的卷积,bn得到512x28x28的feature map:F7_2
F7_1+F7_2后,再经过激活函数relu得到512x28x28的feature map F8
- F7经过kernel size = 1,in_channel=256,out_channel=128,stride=2的卷积,bn,relu,得到128x28x28的feature map.
- 块2
- F8经过kernel size = 1,in_channel=512,out_channel=128,stride=1的卷积,bn,relu,得到128x28x28的feature map.
接着经过一个kernel size=3,in_channel=128,out_channel=128的卷积,bn,relu,得到128x28x28的feature map.
接着经过一个kernel size=1,in_channel=128,out_channel=512的卷积,bn得到512x28x28的feature map:F8_1
F8_1+F8后,再经过激活函数relu得到512x28x28的 feature map F9
- F8经过kernel size = 1,in_channel=512,out_channel=128,stride=1的卷积,bn,relu,得到128x28x28的feature map.
- 块3
- F9经过kernel size = 1,in_channel=512,out_channel=128,stride=1的卷积,bn,relu,得到128x28x28的feature map.
接着经过一个kernel size=3,in_channel=128,out_channel=128的卷积,bn,relu,得到128x28x28的feature map.
接着经过一个kernel size=1,in_channel=128,out_channel=512的卷积,bn得到512x28x28的feature map:F9_1
F9_1+F9后,再经过激活函数relu得到512x28x28的 feature map F10
- F9经过kernel size = 1,in_channel=512,out_channel=128,stride=1的卷积,bn,relu,得到128x28x28的feature map.
- 块4
- F10经过kernel size = 1,in_channel=512,out_channel=128,stride=1的卷积,bn,relu,得到128x28x28的feature map.
接着经过一个kernel size=3,in_channel=128,out_channel=128的卷积,bn,relu,得到128x28x28的feature map.
接着经过一个kernel size=1,in_channel=128,out_channel=512的卷积,bn得到512x28x28的feature map:F8_1
F10_1+F10后,再经过激活函数relu得到512x28x28的 feature map F11
- F10经过kernel size = 1,in_channel=512,out_channel=128,stride=1的卷积,bn,relu,得到128x28x28的feature map.
- 块1(涉及矩阵size变化)
- 对conv4_x的六个块
- 块1(涉及矩阵size变化)
- F11经过kernel size = 1,in_channel=512,out_channel=256,stride=2的卷积,bn,relu,得到256x14x14的feature map.
接着经过一个kernel size=3,in_channel=256,out_channel=256的卷积,bn,relu,得到256x14x14的feature map.
接着经过一个kernel size=1,in_channel=256,out_channel=1024的卷积,bn得到1024x14x14的feature map:F11_1
将F11经过一个kernel size=1,in_channel=512,out_channel=1024,stride=2的卷积,bn得到1024x14x14的feature map:F11_2
F11_1+F11_2后,再经过激活函数relu得到1024x14x14的F12
- F11经过kernel size = 1,in_channel=512,out_channel=256,stride=2的卷积,bn,relu,得到256x14x14的feature map.
- …以此类推
- 最终得到 1024 × 14 × 14的feature map F17
- 块1(涉及矩阵size变化)
- 对conv5_x的三个块
- 块1(涉及矩阵size变化)
- F17经过kernel size = 1,in_channel=1024,out_channel=512,stride=2的卷积,bn,relu,得到512x7x7的feature map.
接着经过一个kernel size=3,in_channel=512,out_channel=512的卷积,bn,relu,得到512x7x7的feature map.
接着经过一个kernel size=1,in_channel=512,out_channel=2048的卷积,bn得到512x7x7的feature map:F17_1
将F17经过一个kernel size=1,in_channel=1024,out_channel=2048,stride=2的卷积,bn得到2048x7x7的feature map:F17_2
F17_1+F17_2后,再经过激活函数relu得到2048x7x7的F18
- F17经过kernel size = 1,in_channel=1024,out_channel=512,stride=2的卷积,bn,relu,得到512x7x7的feature map.
- 同理类推,最后经过激活函数relu得到2048x7x7的F20
- 块1(涉及矩阵size变化)
- 最后经过 average pool的池化得到 2048 × 1 × 1 的F21
- F21经过2048 × 1000 的 fc,再经过bn,softmax输出1000个类的概率值
- 注:如果是45类,那么输入的也是45类的数据,在最后经过 2048 × 45 的fc即可

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐
 92
92 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)