
用人话讲明白AHP层次分析法(非常详细原理+简单工具实现)
用人话讲明白AHP层次分析法(非常详细原理+简单工具实现)
文章目录
目录
2.3.3 根据CI、RI值求解CR值,判断其一致性是否通过。
1、前言与算法简述
今天应粉丝要求,梳理一下层次分析法。
层 次 分 析 法, 即Analytic Hierarchy Process(AHP) , 是美国运筹学家 Saaty 于 20 世纪 70 年代初 期提出的一种主观赋值评价方法。 层次分析法将与决策有关的元素分解成目标、 准则、方案等多个层次, 并在此基础上进行定性和定量分析, 是一种系统、简便、灵活有效的决策方法。
这个算法是一个多指标综合评价算法,由于这个算法简单、实用,因此在经管类或者实际生活中应用的非常多,其一般有两个用途:
-
指标定权
给指标制定权重,打个比方,例如选择旅游地这个决策,可能一般我们由以下5个因素组成,但是每个人(主观)对因素的重视程度不一,ahp可以实现在无需搜集数据的情况下,给这些指标制定权重。

-
量化方案选择
同样是选择旅游地这个决策,可能我们有一些方案,例如苏杭、北戴河、桂林这三个方案,层次分析法可以综合以上5个因素,给这些方案计算得出一个量化得分,例如苏杭0.3分、北戴河0.35分、桂林0.45分,这样根据分值大小,我们就可以选择得到内心或者经验上最心怡的方案了。

通过上面讲解层次分析法的作用,在生活、工作中其实我们可以应用这个模型的渠道是非常广的,特别是那些需要主观决策的、或者需要用经验判断的决策方案,例如:
-
买房子(主观决策)
-
选择旅游地(主观决策)
-
给员工进行绩效评估(经验判断)
-
选择开店地址(经验判断)
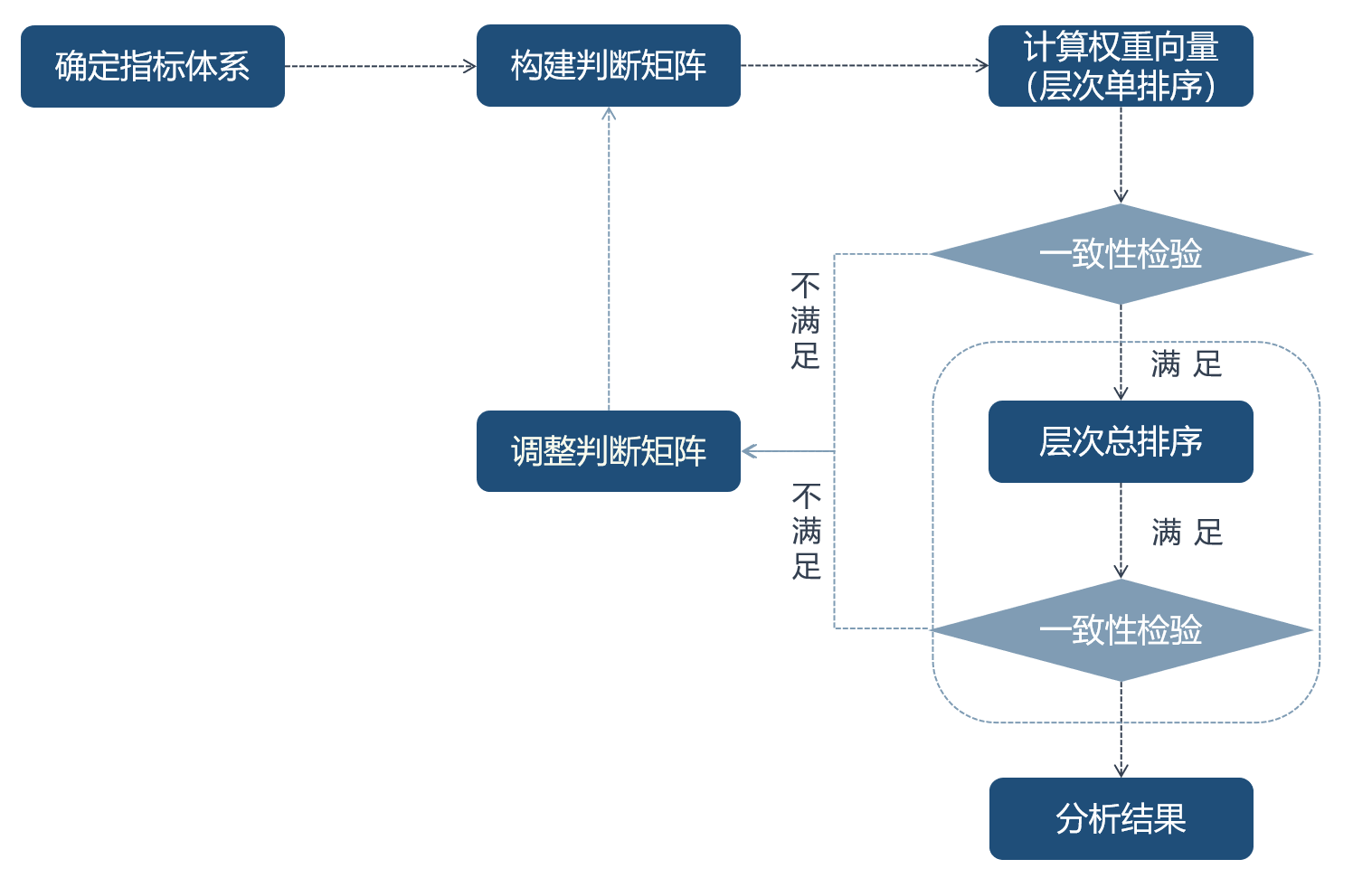
2、AHP层次分析法过程
层次分析法的原理,是在分析一个现象或问题之前,首先将现象或问题根据它们的性质分解为有关因素,并根据它们之间的关系分类而形成一个多层次的结构模型。然后通过经验或专家,来判断和衡量低层因素对高层因素的相对重要性,并根据重要性的程度得出权重排序,进而可以量化分析比较。层次分 析法的核心是将影响因素层次化和数据化,它把一个抽象的现象或问题由难到 易地予以分解,易于对复杂问题进行直观地判断,并作出决策。层次分析法具有将复杂问题简单化且计算简单等优点,应用十分广泛,诸如在人员素质评估、 多方案比较、科技成果评比和工作成效评价等多领域多方面都有运用。
简单地说,层次分析法就是将一个决策事件分解为目标层(例如选择旅游地),准则层(影响决策的因素,例如景色、交通、费用等)以及方案层(指的是方案,例如去广州、桂林等地旅游)。

层次分析法应用过程中,大体步骤主要包括四个。第一步是层次结构模型的构建。第二步构造判断矩阵,第三步为层次单排序及其一致性检验,这步即为对指标定权,第四步为层次总排序及其一致性检验,这布如果没有决策层的话,通常可以省略。
PS:一致性检验的含义用于确定构建的判断矩阵是否存在逻辑问题,例如以A、B、C构建判断矩阵,若判定A相当于B为3(A比B稍微重要),A相当于C为1/3(C比A稍微重要),在判断B相当于C时,根据上述的逻辑,理应C比B重要,若我们在构建判断矩阵时,错误填写为B相当于C为3(B比C稍微重要),那么就犯了逻辑错误。
2.1 构建层次评价模型
顾名思义,在这个层次评价模型里面,我们需要确认整个决策事件的目标层、准则层、方案层

其中,
目标层:最优旅游地选择
准则层:景色、费用、居住、饮食、旅途
方案层:西安、云南、西藏、青海
需要注意的时,准则层如果有多层,例如下图所示,依次类推就行了。

2.2 构造判断矩阵
构造判断矩阵就是通过各要素之间相互两两比较,并确定各准则层对目标层的权重。
简单地说,就是把准则层的指标进行两两判断,通常我们使用Santy的1-9标度方法给出。

对于准则层A,我们可以构建一个

其中A 中的元素满足:

简单说,例如对于准则层:景色、费用、居住、饮食、旅途,我们可以构建这样一个5*5的判断矩阵:

其中对角线为各个指标自己的判断,例如对于【景色】与【景色】,其重要性为1,因为肯定是指标自身对比自身肯定是1:1。对于第二行第一列,也就是【费用】与【景色】对比,可能我认为【费用】比【景色】明显重要,那么就可以标值为5

那么判断矩阵就会变为:

以此类推,直到构建完成一个完整的判断矩阵。
2.3 层次单排序与一致性检验
这里列出一般在文献中的说明:
step1:层次单排序
层次单排序是指针对上一层某元素将本层中所有元素两两评比,并开展层次排序, 进行重要顺序的排列,具体计算可依据判断矩阵 A 进行,计算中确保其能够符合 AW=𝜆𝑚𝑎𝑥𝑊的特征根和特征向量条件。在此,A 的最大特征根为λmax,对应λmax的正规化的特征向量为 W,𝑤𝑖为 W 的分量,其指的是权值,与其相应元素单排序对应。 利用判断矩阵计算各因素𝑎𝑖𝑗对目标层的权重(权系数)。
权重向量(W)与最大特征(λmax)的计算步骤(方根法或者和法)如下表所示:

step2:求解最大特征根与CI值
设 n 阶判断矩阵为 B,则可用以下方法求出其最大的特征根𝜆𝑚𝑎𝑥:
BW=λW
其中,W 是 B 的特征向量。 在层次分析法中, 我们用以下的一致性指标 CI 来检验判断的一致性指标 (Consistency Index):

C.I.=0 表示判断矩阵完全一致,C.I.越大,判断矩阵的不一致性程度越严重。
step3:根据CI、RI值求解CR值,判断其一致性是否通过
Satty 模拟 1000 次得到的随机一致性指标 R.I.取值表(如下表 所示):


当 C.R.<0.1 时,表明判断矩阵 A 的一致性程度被认为在容许的范围内,此时可 用 A 的特征向量开展权向量计算;若 C.R.≥0.1, 则应考虑对判断矩阵 A 进行修正。
下面我用人话说一下:
2.3.1 层次单排序
简单地说,层次单排序就是根据我们构成的判断矩阵,求解各个指标的权重。
例如我们现在在2.2构建完成了准则层的判断矩阵A如下:

那么我们可以计算其权重(权重向量),有两种方式,一种是方根法,一种是和法。
其中方根法计算权重如下:
-
计算每行乘积的m次方,得到一个m维向量

即:

(2)将将向量标准化即为权重向量,即得到权重

即:

而和法计算权重如下:
step1:先将矩阵的每列进行标准化
step2:将标准化后的各元素按行求和
step3:将求和结果进行标准化
例如这张图所示:

2.3.2 求解最大特征根与CI值
以上,求得权重矩阵后,可以计算最大特征根,其公式为:

其中n为维度数,例如构建的判断矩阵为:景色、费用、居住、饮食、旅途时,n=5;
AW为:判断矩阵*标准化后的权重,然后按按行的累加值。
即判断矩阵A为:
| 指标 | 景色 | 费用 | 居住 | 饮食 | 旅途 |
| 景色 | 1 | 5 | 5 | 0.3333 | 8 |
| 费用 | 0.2 | 1 | 0.25 | 0.1667 | 2 |
| 居住 | 0.2 | 4 | 1 | 0.2 | 3 |
| 饮食 | 3 | 6 | 5 | 1 | 6 |
| 旅途 | 0.125 | 0.5 | 0.3333 | 0.1667 | 1 |
标准化后权重W为:
| 景色 | 费用 | 居住 | 饮食 | 旅途 |
| 0.3104 | 0.0591 | 0.1157 | 0.4716 | 0.0432 |
其中A*W为:
| 指标 | 景色 | 费用 | 居住 | 饮食 | 旅途 |
| 景色 | 0.3104 | 0.2955 | 0.5785 | 0.15718428 | 0.3456 |
| 费用 | 0.06208 | 0.0591 | 0.028925 | 0.07861572 | 0.0864 |
| 居住 | 0.06208 | 0.2364 | 0.1157 | 0.09432 | 0.1296 |
| 饮食 | 0.9312 | 0.3546 | 0.5785 | 0.4716 | 0.2592 |
| 旅途 | 0.0388 | 0.02955 | 0.03856281 | 0.07861572 | 0.0432 |
AW:

λmax:
AW1/W1+AW2/W2+AW3/W3+···+AWn/Wn=x

最大特征值λmax=x/矩阵阶数=5.416
最大特征值λmax求解出来后,C.I值就好算多了,
根据C.I值公式,λmax=5.416,n=5,代入可得C.I值=0.1042

2.3.3 根据CI、RI值求解CR值,判断其一致性是否通过。
一致性检验的含义用于确定构建的判断矩阵是否存在逻辑问题,例如以A、B、C构建判断矩阵,若判定A相当于B为3(A比B稍微重要),A相当于C为1/3(C比A稍微重要),在判断B相当于C时,根据上述的逻辑,理应C比B重要,若我们在构建判断矩阵时,错误填写为B相当于C为3(B比C稍微重要),那么就犯了逻辑错误;
RI值通过查表可以得知,这个是Satty 模拟 1000 次得到的随机一致性指标 R.I.取值表(如下表 所示):
而我们的矩阵是5阶(准则层因子个数),矩阵阶数为5时对应的RI值为1.12,代入公式:
可以得到C.R.值为0.1042/1.12=0.093。
所以 C.R.=0.093<0.1 时,表明判断矩阵 A 的一致性程度被认为在容许的范围内,此时可 用 A 的特征向量开展权向量计算;若 C.R.≥0.1, 说明我们在构建判断矩阵时出现了逻辑错误,
例如B矩阵,我们假设在两两对比第三行第二列时,填入了1/5,这个时候就无法通过一致性检验,因为其犯了逻辑错误,我们根据第二行第一列,可以知道上海的地位比广州稍微重要,根据第三行第一列,可以知道北京的地位比广州强烈重要,所以根据逻辑:上海>广州,北京》广州,那么北京应该是>上海,但是我们填入了1/5,也就是北京比上海相当不重要,所以就出现了逻辑错误,这个时候,我们需要对判断矩阵 A 进行修正,修正为北京>上海。

至此,我们便完成了层次单排序与一致性检验,通过我们在使用层次分析法只使用到这里,用于对指标进行定权,假如我们有方案层,便需要做层次总排序与其一致性检验。
2.4 层次总排序与一致性检验
这里列出一般在文献中的说明:
计算某一层次所有因素对于最高层(目标层)相对重要性的权值,称为层次总排 序。该过程是从最高层次向最低层次依次进行:

设 B 层𝐵1 ,𝐵2 ⋯ ,𝐵𝑛对上层(A 层)中因素𝐴𝑗(𝑗 = 1,2, ⋯ ,𝑚)的层次排序 一致性指标为𝐶𝐼𝑗,随机一致性指标为𝑅𝐼𝑗 ,则层次总排序的一致性比率为:
![]()
当𝐶𝑅 < 0.1时,认为层次总排序通过一致性检验,否则就需要重新调整判断矩阵 的元素取值。到此,根据最下层(决策层)的层次总排序做出最后的决策。
下面我用人话说一下:
层次总排序,其实就是通过类型层次单排序的方法来给方案打分。

打个比方,我们根据2.3的层次单排序,现在确定A1~A5的权重为
| 景色 | 费用 | 居住 | 饮食 | 旅途 |
| 0.3104 | 0.0591 | 0.1157 | 0.4716 | 0.0432 |
现在我想要计算方案B1:苏杭的得分,但是我们并不知道苏杭的景色得分为多少,那该怎么办呢?
类似2.3的层次单排序,对于景色这个因素,我们可以构建一个3*3的矩阵,如下所示:

通过层次单排序两两对比各个方案在景色的比较,我们可以得到苏杭、北戴河、桂林的权重,那么这个权重就可以作为苏杭、北戴河、桂林在景色上的得分。
依次类推,我们构造得到苏杭、北戴河、桂林在景色上的得分矩阵A1,在费用上的得分矩阵A2,在居住上的得分矩阵A3,在饮食上的得分矩阵A4,在旅途上的得分矩阵A5:

计算得到其得分为:

PS:以上全部的判断矩阵都需要做一致性检验。
那么对于方案B1(苏杭),它的总得分为:
苏杭在景色上的得分*景色的权重+苏杭在费用上的得分*费用的权重+苏杭在居住上的得分*居住的权重+苏杭在饮食上的得分*饮食的权重+苏杭在旅途上的得分*旅途的权重=0.5954*0.3104+0.819*0.0591+0.4286*0.1157+0.6337*0.4716+0.1667*0.0432=0.5889
以此类推,可以计算得到方案B2(北戴河)为
0.2764*0.3104+0.2363*0.0591+0.4286*0.1157+0.1919*0.4716+0.1667*0.0432=0.2471
方案B3(桂林):
0.1283*0.3104+0.6817*0.0591+0.1429*0.1157+0.1744*0.4716+0.6667*0.0432=0.2077
因此苏杭得分最高,选择去苏杭。
3、案例以及工具实现
3.1 外出旅游最重视的因素
这里的作用其实就是求因子权重,因此只计算到层次单排序,没有方案层,即无需层次总排序。
3.1.1 使用工具
SPSSPRO—>【层次分析法(AHP简化版)】
3.1.2 案例操作

step1:选择【层次分析法(AHP简化版)】;
step2:选择判断矩阵阶层
step3:设置判断矩阵(判断矩阵是对称矩阵)
step4:点击【开始分析】,完成全部操作。
3.1.3 分析结果解读
以下生成的结果来源于SPSSPRO软件的分析结果导出,计算方式我在第二章有说过,下面直接就列分析结果了。
输出结果1:构建判断矩阵结果

这个就是前面操作页面所填写的判断矩阵
输出结果2:AHP层次分析结果

基于方根法的权重计算结果显示,景色的权重得分为0.2657,费用的权重得分为0.4212,居住的权重得分为0.0657,饮食的权重得分为0.1067,旅途的权重得分为0.1407,最大特征根为5.1352,CI为0.0338。
输出结果3:一致性检验结果

计算结果显示,最大特征根为5.1352,根据RI表查到对应的RI值为1.11,因此CR=CI/RI=
0.0305<0.1,通过一次性检验,说明该权重确定方法的合理性,无需要对判断矩阵进行修改。
需要注意的是,这里的RI值采用近年来更受认可的Franek and Kresta (2014)的方式,不再使用satty的方法。
3.1.4 小结
由3.1.3可以知道,外出旅游最重视的因素是费用,其权重得分为0.4212,这个结果是很主观的,因为本身选择旅游地这个决策就是一个非常主观的决策,就像推广到买房,本身影响买房的决策因子也是非常主观的,每个人都有自己的一杆秤,但是如果是店铺,例如奶茶店选址,那么我们可以找有经验的人来两两判断,或者多收集一些专家的判断,求平均值,对于主观的事情,当想法一致的人多了,那么也便了一个客观的事实。
3.2 选择最佳外出旅游地
这里的作用其实就是求方案的量化得分,因此需要对准则层计算层次单排序,对方案层进行层次总排序。
3.2.1 使用工具
SPSSPRO—>【层次分析法(AHP专业版)】
3.2.2 案例操作

Step1:选择层次分析法(AHP专业版);
Step2:选择构建决策模型;

Step3:输入构建的评价指标;
Step4:输入最终的方案;
Step5:确认以进入下一步指标评分;

Step6:输入指标之间两两比对的重要程度值;

Step7:输入不同方案的对应评价值的重要程度评价;
3.1.3 分析结果解读
以下生成的结果来源于SPSSPRO软件的分析结果导出,计算方式我在第二章有说过,下面直接就列分析结果了。
输出结果1:方案得分

基于指标层次单排序与方案层次总排序后,对于旅游地选择最好的方案为北戴河、其次为桂林。北戴河的量化得分为1.435,高过第二桂林近一倍。
输出结果2:层次决策模型

由图可见,其中最重要的两个决定因素是旅游地的景色和费用,而饮食、居住情况则属于低权重。
输出结果3:判断矩阵汇总结果

这里列出来了特征向量和权重,CR值小于0.1,一致性检验通过,层次分析法结果有效。
输出结果4:方案层判断矩阵汇总结果

上表展示了层次分析法的方案层的权重计算结果(即层次总排序),构建了个数为叶子节点指标的数目的判断矩阵对各个指标的权重进行分析,通过展示了一致性检验结果,用于判断方案层权重矩阵是否存在构建判断矩阵的逻辑问题。由于上一级节点的得分可以根据其子节点得分*权重计算得到,因此构建方案层判断矩阵时,只对叶子节点进行构建,即N个叶子节点就构建N个判断矩阵,用于综合两两对比情况,得到方案层对于某个叶子节点的得分;
可以看到,方案的得分都满足了一致性检验。
3.2.4 小结
由3.2.3可以知道,对于旅游地选择最好的方案为北戴河,其量化得分为1.435,层次总排序的方案层判断矩阵,是在没有数据的情况下才做的,现实情况下,我们如果面临选择旅游地、选择租房、选择买房这类偏主观的决策,那么是可以采用层次总排序的,如果推广到店铺选址、快递柜选择、活动方案选择等需要客观决策的事情,我们其实可以通过两种方式来优化:
-
基于大多数有经验的人,采用层次总排序,求均值,把主观转为客观(这里通常结合一种方法叫德尔菲法,也叫专家调查法)
-
基于真实数据做层次总排序,例如店铺选择,假设有人流量这个指标,可以采用真实指标来量化求解。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐
 469
469 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)