
【动态SLAM】经典开源论文(更新中)
【动态SLAM】经典开源论文(更新中)
- 0 简介
- 1.DynaSLAM(IROS 2018)
- 2.DS-SLAM(IROS 2018, 清华大学)
- 3.Detect-SLAM(2018 IEEE WCACV, 北京大学)
- 4.VDO-SLAM(arXiv 2020)
- 5.Co-Fusion(ICRA 2017)
- 6.Learning Rigidity in Dynamic Scenes with a Moving Camera for 3D Motion Field Estimation(2018,ECCV,NVIDIA)
- 7.ReFusion(2019 IROS)
- 8.RGB_D-SLAM-with-SWIAICP(2017)
- 9.RDS-SLAM(2021,Access)
0 简介
本文首发自我的古月居社区博客https://www.guyuehome.com/34287,总结了一些经典开源的动态slam论文,后续会更新TUM数据集的介绍、经典论文的汇总、Dyna-SLAM源码讲解等内容。
1.DynaSLAM(IROS 2018)
论文:DynaSLAM: Tracking, Mapping and Inpainting in Dynamic Scenes
代码:https://github.com/BertaBescos/DynaSLAM
主要思想:(语义+几何)
1.使用Mask-CNN进行语义分割;
2.在low-cost Tracking阶段将动态区域(人)剔除,得到初始位姿;
3.多视图几何方法判断外点,通过区域增长法生成动态区域;
4.代码中将多视图几何的动态区域与语义分割人的区域全都去除,将mask传给orbslam进行跟踪;
5.背景修复,包括RGB图和深度图。
**创新点:**语义分割无法识别移动的椅子,需要多视图几何的方法进行补充
**讨论:**DynaSLAM与下面的DS-SLAM是经典的动态slam系统,代码实现都很简洁。Dyna-SLAM的缺点在于:1.多视图几何方法得到的外点,在深度图上通过区域增长得到动态区域,只要物体上存在一个动态点,整个物体都会被“增长”成为动态 2.其将人的区域以及多视图几何方法得到的区域都直接去掉,与论文不符。


2.DS-SLAM(IROS 2018, 清华大学)
论文:DS-SLAM: A Semantic Visual SLAM towards Dynamic Environments
代码:https://github.com/ivipsourcecode/DS-SLAM
主要思想:(语义+几何)
1.SegNet进行语义分割(单独一个线程);
2.对于前后两帧图像,通过极线几何检测外点;
3.如果某一物体外点数量过多,则认为是动态,剔除;
4.建立了语义八叉树地图。
讨论:这种四线程的结构以及极线约束的外点检测方法得到了很多论文的采纳,其缺点在于:1.极线约束的外点检测方法并不能找到所有外点,当物体沿极线方向运动时这种方法会失效 2.用特征点中的外点的比例来判断该物体是否运动,这用方法存在局限性,特征点的数量受物体纹理的影响较大 3.SegNet是2016年剔除的语义分割网络,分割效果有很大提升空间,实验效果不如Dyna-SLAM

3.Detect-SLAM(2018 IEEE WCACV, 北京大学)
论文:Detect-SLAM: Making Object Detection and SLAM Mutually Beneficial
代码:https://github.com/liadbiz/detect-slam
主要思想:
目标检测的网络并不能实时运行,所以只在关键帧中进行目标检测,然后通过特征点的传播将其结果传播到普通帧中
1.只在关键帧中用SSD网络进行目标检测(得到的是矩形区域及其置信度),图割法剔除背景,得到更加精细的动态区域;
2.在普通帧中,利用feature matching + matching point expansion两种机制,对每个特征点动态概率传播,至此得到每个特征点的动态概率;
3.object map帮助提取候选区域。

4.VDO-SLAM(arXiv 2020)
论文:VDO-SLAM: A Visual Dynamic Object-aware SLAM System
代码: https://github.com/halajun/vdo_slam
主要思想:
1.运动物体跟踪,比较全的slam+运动跟踪的系统;
2.光流+语义分割。

5.Co-Fusion(ICRA 2017)
论文:Co-Fusion: Real-time Segmentation, Tracking and Fusion of Multiple Objects
代码:https://github.com/martinruenz/co-fusion
**主要思想:**学习和维护每个物体的3D模型,并通过随时间的融合提高模型结果。这是一个经典的系统,很多论文都拿它进行对比

6.Learning Rigidity in Dynamic Scenes with a Moving Camera for 3D Motion Field Estimation(2018,ECCV,NVIDIA)
论文:Learning Rigidity in Dynamic Scenes with a Moving Camera for 3D Motion Field Estimation
代码:https://github.com/NVlabs/learningrigidity.git
主要思想:
1.RTN网络用于计算位姿以及刚体区域,PWC网络用于计算稠密光流;
2.基于以上结果,估计刚体区域的相对位姿;
3.计算刚体的3D场景流;
此外还开发了一套用于生成半人工动态场景的工具REFRESH。

7.ReFusion(2019 IROS)
论文:ReFusion: 3D Reconstruction in Dynamic Environments for RGB-D Cameras Exploiting Residuals
代码:https://github.com/PRBonn/refusion
主要思想:
主流的动态slam方法需要用神经网络进行分实例分割,此过程需要预先定义可能动态的对象并在数据集上进行大量的训练,使用场景受到很大的限制。而ReFusion则使用纯几何的方法分割动态区域,具体的:在KinectFusion稠密slam系统的基础上,计算每个像素点的残差,通过自适应阈值分割得到大致动态区域,形态学处理得到最终动态区域,与此同时,可得到静态背景的TSDF地图。
讨论:为数不多的不使用神经网络的动态slam系统
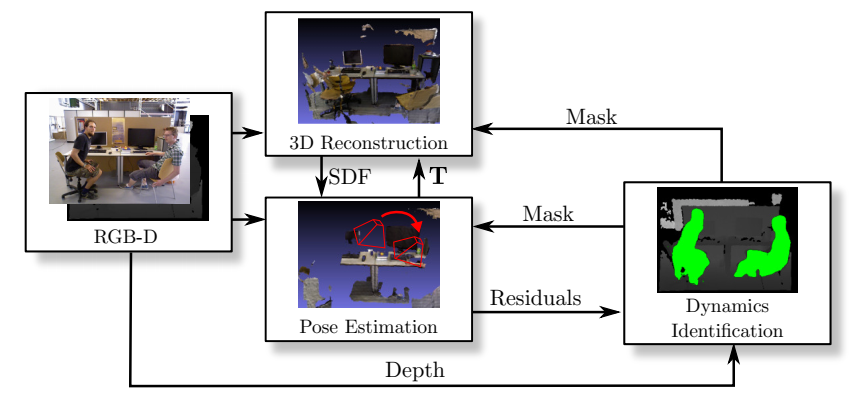
8.RGB_D-SLAM-with-SWIAICP(2017)
论文:RGB-D SLAM in Dynamic Environments Using Static Point Weighting
代码:https://github.com/VitoLing/RGB_D-SLAM-with-SWIAICP
主要思想:
1.仅使用前景的边缘点进行跟踪( Foreground Depth Edge Extraction);
2.每隔n帧插入关键帧,通过当前帧与关键帧计算位姿;
3.通过投影误差计算每个点云的静态-动态质量,为下面的IAICP提供每个点云的权重;
4.提出了融合灰度信息的ICP算法–IAICP,用于计算帧与帧之间的位姿。
**讨论:**前景物体的边缘点能够很好地表征整个物体,实验效果令人耳目一新。但是文中所用的ICP算法这并不是边缘slam常用的算法,边缘slam一般使用距离变换(DT)描述边缘点的误差,其可以避免点与点之间的匹配。论文Robust RGB-D visual odometry based on edges and points提出了一种很有意思的方案,用特征点计算位姿,用边缘点描述动态区域,很好地汲取了二者的优势。

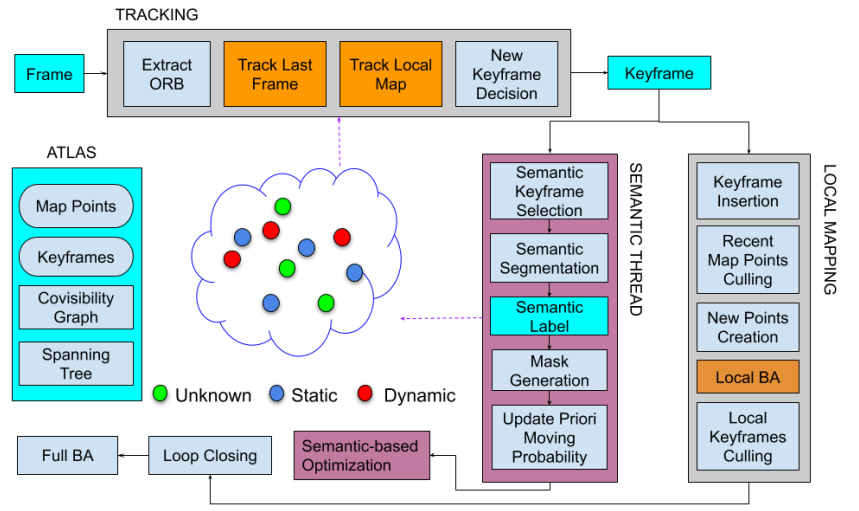
9.RDS-SLAM(2021,Access)
论文:RDS-SLAM: Real-Time Dynamic SLAM Using Semantic Segmentation Methods
代码:https://github.com/yubaoliu/RDS-SLAM.git
主要思想:克服不能实时进行语义分割的问题
1.选择最近的关键帧进行语义分割;
2.基于贝叶斯的概率传播;
3.通过上一帧和局部地图得到当前帧的外点;
4.根据运动概率加权计算位姿。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐
 22
22 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)