
Storm流式计算入门
流式计算实时获取数据,实时数据储存,实时数据计算,实时结果缓存,持久化存储(mysql)代表技术:Flume:实时获取数据Kafka:实时数据存储Storm/jstorm:实时数据计算Redis:实时结果缓存总结:将源源不断产生的数据实时收集并实时计算,迅速得到计算结果关于storm1、storm是twitter的开源流计算解决方案,因为对hadoop的ma...
流式计算
实时获取数据,实时数据储存,实时数据计算,实时结果缓存,持久化存储(mysql)
代表技术:
Flume:实时获取数据
Kafka:实时数据存储
Storm/jstorm:实时数据计算
Redis:实时结果缓存
总结:将源源不断产生的数据实时收集并实时计算,迅速得到计算结果
关于storm
1、storm是twitter的开源流计算解决方案,因为对hadoop的mapreduce的高延迟缺点而出现
2、应用场景:
- 信息流处理:聚合,分析
- 持续计算:如实时数据统计,监控
3、Storm的延迟性为毫秒级,而spark streaming为数十秒或分钟,难度上storm远大于spark
storm本质为逐行或逐批次计算,按行数处理
主要特性
- 使用场景广泛
- 可伸缩性高:可以让storm每秒可以处理的消息量达到很高,扩展一个实时计算任务,只需要加机器并提高这个计算任务的并行度,storm使用zookeeper来协调集群中的各种配置
- 保证无数据丢失:实时系统必须保证所有数据被成功处理,即失败重发 异常健壮:storm集群易于管理,轮流重启节点不影响使用
- 容错性好:消息处理过程中出现异常,storm会重试 语言无关性:storm的拓扑和bolt消息处理组件可以用任何语言来定义
storm集群架构
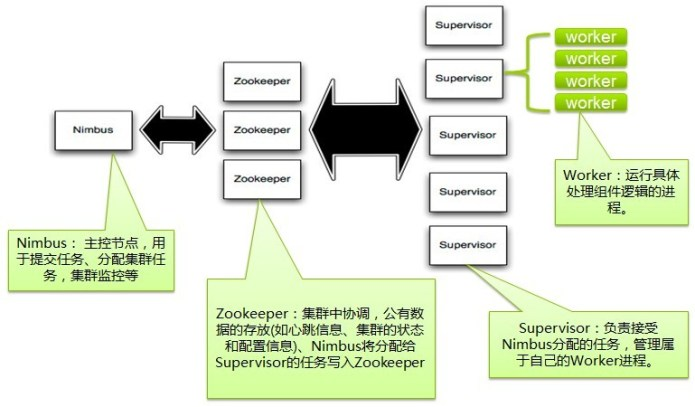
-
主节点:nimbus,工作节点:supervisor 两者之间所有的协调工作通过zookeeper集群
-
numbus进程和supervisor进程是无法直接连接的,同时他们都是无状态的,所有的状态维持在zookeeper中或保存在本地磁盘上
-
启动节点会从磁盘读取到zookeeper集群中,只要集群是启动的,永远只从zookeeper拿数据,拿状态,当关闭也会持久化到从磁盘上,这样可以使用kill -9 numbus和supervisor进程,而不需要做备份!
- topo只能在nimbus机器上提交,将任务分配给其他节点
- supervisor监听zookeepr集群,根据numbus的委派在必要时启动和关闭工作进程,每个工作进程执行topology的一个子集为进程~
- storm中数据源为流stream的抽象,流是不间断无界连续的tuple,storm建模事件流
工作原理
-》storm任务每个stream都有一个源头,即spout:管口,水龙头,即原始元祖的源头
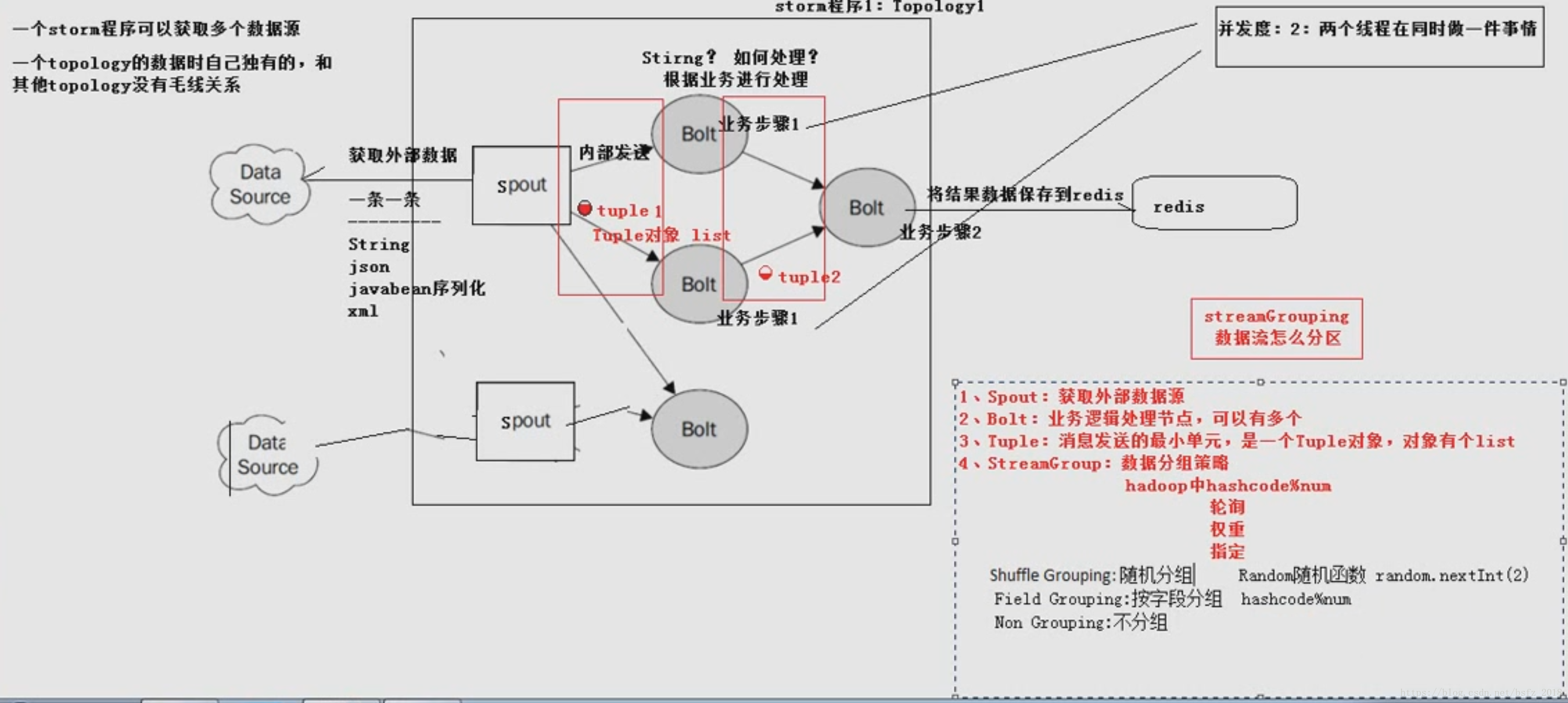
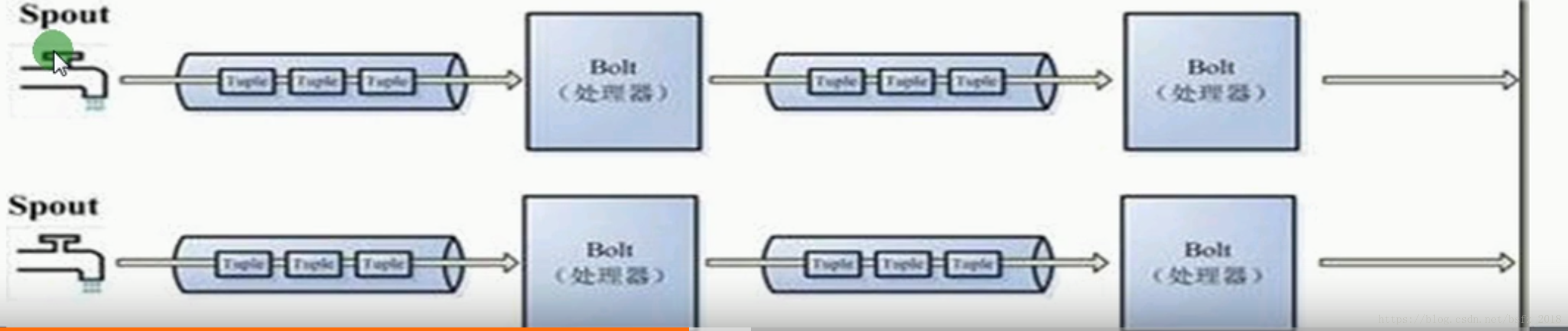
-》处理stream流中的tuple,这个处理器抽象为bolt(水处理器),可以消费任意数量的输入流
它也可以发送新的流给其他bolt使用,即只要打开特定的spout再将spout中流出的tuple导向
特定的bolt,这个bolt对导入的流做处理后在导向其他bolt或者目的地
-》spout为水龙头,每个水龙头流出水不同,我们想得到哪种水就拧开哪个水龙头,然后使用
管道将水龙头的水导入到bolt,然后bolt处理器再使用管道导向另一个处理器或者存入容器
-》为了增大水处理效率,我们可以在同一个水源处接上多个水龙头并使用多个水处理器
即拓扑toplogy结构,一个拓扑就是一个流转换图
-》每个同一级spout或者bolt如果拿到数据是10000行,那么他们都是10000行,为广播方式
-》spout到单个bolt有6种分组策略
spout通过分组策略将数据发到bolta和boltc,bolta处理完就发到boltb
-》streams:消息流:没有边界的tuple序列,每个tuple可以包含多列,字段类型可以是任意8种基本类型等
-》spout是topology消息生产者,消息源从消息队列读取数据向topology发出tuple,消息源spouts可以有多个
一个可靠的消息源可以重新发射一个处理失败的tuple,一个不可靠的消息源spouts不会

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)