
2020CCF BDCI 企业非法集资风险预测-线上0.848(水哥的baseline),在此基础已做到线上0.848,排名前1%(参赛队伍3000+))。
首先感谢DataWhale这个组织,今年上半年在学校机器学习的过程中得知有这么个开源组织,南瓜书也是他们一起编写,看过西瓜书《机器学习-周志华》的同学应该都知道吧。感觉组织内的水哥和鱼佬baseline的分享,从他们的baseline中学到了不少。Coggle数据科学:2020企业非法集资风险水哥b站直播回放文章目录一、赛题介绍1.数据简介2.数据说明3.结果提交要求4.评测标准二、数据预处理1.
首先感谢DataWhale这个组织,今年上半年在学校机器学习的过程中得知有这么个开源组织,南瓜书也是他们一起编写,看过西瓜书《机器学习-周志华》的同学应该都知道吧。感谢组织内的水哥和鱼佬baseline的分享,从他们的baseline中学到了不少。Coggle数据科学:2020企业非法集资风险水哥b站直播回放
数据集在这,直接上gitee下载即可:https://gitee.com/code-to-xiaobai/CCF
文章目录
一、赛题介绍
赛题地址:企业非法集资风险预测
1.数据简介
该数据集包含约25000家企业数据,其中约15000家企业带标注数据作为训练集,剩余数据作为测试集。数据由企业基本信息、企业年报、企业纳税情况等组成,数据包括数值型、字符型、日期型等众多数据类型(已脱敏),部分字段内容在部分企业中有缺失,其中第一列id为企业唯一标识。
2.数据说明
该比赛一共提供了八张表,其实包含预测集。

每一个表的内容都不一样,里面所含的特征、企业数量等,都是不同的,所以如果选取特征是这个比赛一个比较关键的地方,也是帮助你上分的一个很重要的因素!
水哥在直播的时候分享了他自己对于这些数据的处理,先对每一个表做一个思维导图,看每一个表其中都包含哪些特征,每个特征的类别,等等,这些都是方便后面做数据的预处理和特征工程!
在比赛的初期有一位老哥在知乎分享了天的baseline,这个分数应该是[0.83]多左右,只用了第一张表base_info,这张表也是包含信息最多的,单表貌似可以上到0.84多,群内有大佬做到了。
具体的数据说明大家可以关注水哥他们的公众号:Coggle数据科学,后台回复企业风险,即可领取本赛题baseline和水哥自制思维导图,水哥:关注走一走,baseline免费送,不收一分钱。O(∩_∩)O哈哈~
3.结果提交要求
参赛队伍需依据提供的数据集8,给出企业是否有非法集资风险的预测概率值,每条预测需提供 2 列,列之间采用 “,” 分隔符分割。
请注意:请勿改变验证集列的顺序,请按照给出的文件的列顺序加入预测值。
[id, score]
1.企业id
2.预测的非法集资风险概率值,取值范围 [0, 1]
id, score
XXXXXX,0.1246
XXXXXX,0.8796
4.评测标准
本赛题采用分类任务的精确率 P(precision)、召回率 R(recall) 和 F1 -score三个指标作为模型性能的评判标准。

说明:在计算精确率、召回率和 F1-score时,系统会自动将提交结果中概率大于0.5的识别为1(有非法集资风险),概率小于等于0.5的识别为0(无非法集资风险)。
二、数据预处理
1.分别查看每个表的数据缺失情况
这里以第一个表base_info.csv为例
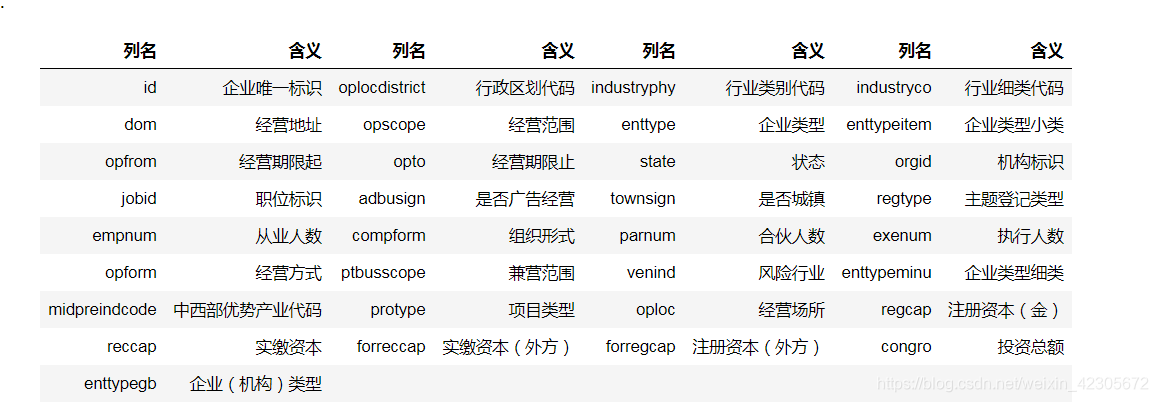
包含数据集7和8中涉及到的所有企业的基本信息,每一行代表一个企业的基本数据,每一行有33列,其中id列为企业唯一标识,列之间采用“,”分隔符分割。
数据格式如下:
#读取数据
base_info = pd.read_csv(PATH + 'base_info.csv')
#输出数据shape和不重复企业id数
print(base_info.shape, base_info['id'].nunique())
#读取数据
base_info.head(1)
#查看缺失值,这里借助了missingno这个包,import missingno as msno。
msno.bar(base_info)#查看缺失值
结果图:
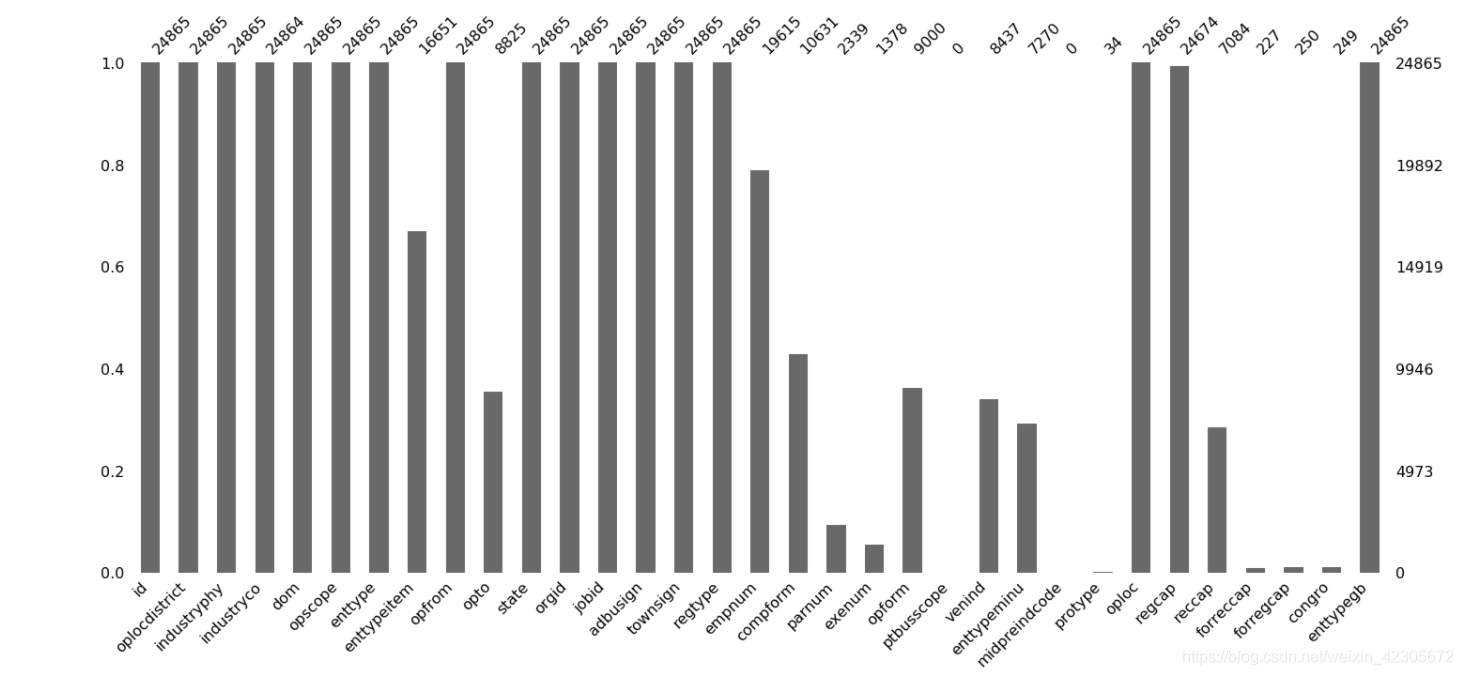
这个图就很明显的看出哪些数据存在缺失值,横轴是特征,纵轴的数据是非缺失值数,每个柱形的白色区域都代表缺失!
2.数据处理
2.1数据初步处理
这里分别要对没一个表进行处理,首先就是需要把所有的表中缺失值验证的列给剔除,这里可以自己写一个函数filter_col_by_nan,详细见下:
#用于剔除空值的函数
def filter_col_by_nan(df, ratio=0.05):
cols = []
for col in df.columns:
if df[col].isna().mean() >= (1-ratio):
cols.append(col)
return cols
这里给个参数ratio用于控制缺失值比例,比如给个0.01,意思就是缺失值超过99%这个特诊就剔除,或者可以这么写:
thr = (1 - 0.3) * data.shape[0] # 可以根据实际情况设定不同阈值, 此处设为30%, 则非缺失值的数量大于70%
data = data.dropna(thresh=thr, axis=1) #若某一列数据缺失的数量超过阀值就会被删除
print("去除掉缺失值占比大于0.3的特征之后,当前还剩%d列特征" %(data.shape[1]))
其他几个表分别做了一些其他的处理,详细的大家可以看baseline。
2.2主表base_info的处理
一开始也说了,这个表的信息是最完整的,所以对于这个表大家可以多花点时间来做一下特征的处理。
#orgid 机构标识 oplocdistrict 行政区划代码 jobid 职位标识
base_info['district_FLAG1'] = (base_info['orgid'].fillna('').apply(lambda x: str(x)[:6]) == \
base_info['oplocdistrict'].fillna('').apply(lambda x: str(x)[:6])).astype(int)
base_info['district_FLAG2'] = (base_info['orgid'].fillna('').apply(lambda x: str(x)[:6]) == \
base_info['jobid'].fillna('').apply(lambda x: str(x)[:6])).astype(int)
base_info['district_FLAG3'] = (base_info['oplocdistrict'].fillna('').apply(lambda x: str(x)[:6]) == \
base_info['jobid'].fillna('').apply(lambda x: str(x)[:6])).astype(int)
#parnum 合伙人数 exenum 执行人数 empnum 从业人数
base_info['person_SUM'] = base_info[['empnum', 'parnum', 'exenum']].sum(1)
base_info['person_NULL_SUM'] = base_info[['empnum', 'parnum', 'exenum']].isnull().astype(int).sum(1)
#regcap 注册资本(金) congro 投资总额
# base_info['regcap_DIVDE_empnum'] = base_info['regcap'] / base_info['empnum']
# base_info['regcap_DIVDE_exenum'] = base_info['regcap'] / base_info['exenum']
# base_info['reccap_DIVDE_empnum'] = base_info['reccap'] / base_info['empnum']
# base_info['regcap_DIVDE_exenum'] = base_info['regcap'] / base_info['exenum']
#base_info['congro_DIVDE_empnum'] = base_info['congro'] / base_info['empnum']
#base_info['regcap_DIVDE_exenum'] = base_info['regcap'] / base_info['exenum']
base_info['opfrom'] = pd.to_datetime(base_info['opfrom'])#opfrom 经营期限起
base_info['opto'] = pd.to_datetime(base_info['opto'])#opto 经营期限止
base_info['opfrom_TONOW'] = (datetime.now() - base_info['opfrom']).dt.days
base_info['opfrom_TIME'] = (base_info['opto'] - base_info['opfrom']).dt.days
#opscope 经营范围
base_info['opscope_COUNT'] = base_info['opscope'].apply(lambda x: len(x.replace("\t", ",").replace("\n", ",").split('、')))
#对类别特征做处理
cat_col = ['oplocdistrict', 'industryphy', 'industryco', 'enttype',
'enttypeitem', 'enttypeminu', 'enttypegb',
'dom', 'oploc', 'opform','townsign']
#如果类别特征出现的次数小于10转为-1
for col in cat_col:
base_info[col + '_COUNT'] = base_info[col].map(base_info[col].value_counts())
col_idx = base_info[col].value_counts()
for idx in col_idx[col_idx < 10].index:
base_info[col] = base_info[col].replace(idx, -1)
# base_info['opscope'] = base_info['opscope'].apply(lambda x: x.replace("\t", " ").replace("\n", " ").replace(",", " "))
# clf_tfidf = TfidfVectorizer(max_features=200)
# tfidf=clf_tfidf.fit_transform(base_info['opscope'])
# tfidf = pd.DataFrame(tfidf.toarray())
# tfidf.columns = ['opscope_' + str(x) for x in range(200)]
# base_info = pd.concat([base_info, tfidf], axis=1)
base_info = base_info.drop(['opfrom', 'opto'], axis=1)#删除时间
for col in ['industryphy', 'dom', 'opform', 'oploc']:
base_info[col] = pd.factorize(base_info[col])[0]
我自己在代码里把这些字段的含义都加上了,也便于自己理解这些含义,从而做一些处理,大家同样可以把这些含义加上。
其中一些注释掉的信息,水哥说大家可以自行尝试一下,有的可能会上分,有的可能会掉分,说实话这个比较确实有点玄学上分的过程。
三、模型训练与预测
这里水哥采用给的是单模的lightbgm,效果还不错,群里也有其他小伙伴尝试了Catboost,貌似效果不太好,大家可以多尝试尝试,结果融合看看怎么样。
这里将模型循环执行了20次,每次都是5折的交叉验证。
1.五折交叉验证
def eval_score(y_test,y_pre):
_,_,f_class,_=precision_recall_fscore_support(y_true=y_test,y_pred=y_pre,labels=[0,1],average=None)
fper_class={'合法':f_class[0],'违法':f_class[1],'f1':f1_score(y_test,y_pre)}
return fper_class
def k_fold_serachParmaters(model,train_val_data,train_val_kind, test_kind):
mean_f1=0
mean_f1Train=0
n_splits=5
cat_features = ['oplocdistrict', 'industryphy', 'industryco', 'enttype',
'enttypeitem', 'enttypeminu', 'enttypegb',
'dom', 'oploc', 'opform']
sk = StratifiedKFold(n_splits=n_splits, shuffle=True, random_state=2021)
pred_Test = np.zeros(len(test_kind))
for train, test in sk.split(train_val_data, train_val_kind):
x_train = train_val_data.iloc[train]
y_train = train_val_kind.iloc[train]
x_test = train_val_data.iloc[test]
y_test = train_val_kind.iloc[test]
model.fit(x_train, y_train,
eval_set=[(x_test, y_test)],
categorical_feature = cat_features,
early_stopping_rounds=100,
verbose=False)
pred = model.predict(x_test)
fper_class = eval_score(y_test,pred)#验证集的准确率
pred_Train = model.predict(x_train)
pred_Test += model.predict_proba(test_kind)[:, 1]/n_splits
fper_class_train = eval_score(y_train,pred_Train)
mean_f1 += fper_class['f1']/n_splits
mean_f1Train+=fper_class_train['f1']/n_splits
# print(mean_f1, mean_f1Train)
return mean_f1, pred_Test
2.循环执行代码
将模型的一些参数加入随机性,然后训练20次,然后得到最终的结果。说实话这里的操作有点秀,学到了。
score_tta = None
score_list = []
tta_fold = 20
for _ in range(tta_fold):
clf = lgb.LGBMClassifier(
num_leaves=np.random.randint(6, 10), min_child_samples= np.random.randint(2,5),
max_depth=5,learning_rate=0.03,
n_estimators=150,n_jobs=-1,silent=False)
score, test_pred = k_fold_serachParmaters(clf,
train_data.drop(['id', 'opscope','label'], axis=1),
train_data['label'],
test_data.drop(['id', 'opscope'], axis=1),
)
if score_tta is None:
score_tta = test_pred/tta_fold
else:
score_tta += test_pred/tta_fold
# print(score)
score_list.append(score)
print(np.array(score_list).mean(), np.array(score_list).std())
3.自动寻最优参数
手动的调参可能也能提升,这里使用过的是自动寻找参数,然后将最优的参数反代回上面的模型中。
lg = lgb.LGBMClassifier(silent=False)
param_dist = {"max_depth": [4,5,6,7,8],
"learning_rate" : [0.01,0.03,0.05,0.07,0.09],
"num_leaves": [4, 5, 6, 7, 8],
"n_estimators": [50, 100, 150,200]
}
cat_features = ['oplocdistrict', 'industryphy', 'industryco', 'enttype',
'enttypeitem', 'enttypeminu', 'enttypegb',
'dom', 'oploc', 'opform']
grid_search = GridSearchCV(lg, n_jobs=-1, param_grid=param_dist, cv = 5, scoring='f1', verbose=5)
grid_search.fit(train_data.drop(['id', 'opscope','label'], axis=1),
train_data['label'], categorical_feature = cat_features,)
grid_search.best_estimator_, grid_search.best_score_

四、总结
这个比赛也是自己第一次参加这种结构化的比赛,也是第一次将之前学的一些机器学习和数据预处理的内容用到比赛中,一开始看到比赛虽然知道是个分类问题,但是拿到数据确实不知道如何下手,在此再次感谢水哥和群里的大佬分享的baseline,对算法比赛也有一点感觉了。再接再厉吧!!!
记录时间:2020年11月27日

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 15
15 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)