
Ansj中文分词说明
Ansj分词这是一个基于n-Gram+条件随机场模型的中文分词的java实现.分词速度达到每秒钟大约200万字左右(mac air下测试),准确率能达到96%以上目前实现了.中文分词. 中文姓名识别 . 用户自定义词典可以应用到自然语言处理等方面,适用于对分词效果要求高的各种项目.源码:https://github.com/NLPchina/ansj_seg
Ansj分词
这是一个基于n-Gram+条件随机场模型的中文分词的java实现.
分词速度达到每秒钟大约200万字左右(mac air下测试),准确率能达到96%以上
目前实现了.中文分词. 中文姓名识别 . 用户自定义词典
可以应用到自然语言处理等方面,适用于对分词效果要求高的各种项目.
源码:https://github.com/NLPchina/ansj_seg
四种分词模式
基本分词是什么
基本就是保证了最基本的分词.词语颗粒度最非常小的.所涉及到的词大约是10万左右.
基本分词速度非常快.在macAir上.能到每秒300w字每秒.同时准确率也很高.但是对于新词他的功能十分有限
基本分词具有什么功能
| 用户自定义词典 | 数字识别 | 人名识别 | 机构名识别 | 新词发现 |
|---|---|---|---|---|
| Χ | √ | Χ | Χ | Χ |
精准分词是Ansj分词的推荐款
它在易用性,稳定性.准确性.以及分词效率上.都取得了一个不错的平衡.
如果你初次赏识Ansj如果你想开箱即用.那么就用这个分词方式是不会错的.
精准分词具有什么功能| 用户自定义词典 | 数字识别 | 人名识别 | 机构名识别 | 新词发现 |
|---|---|---|---|---|
| √ | √ | √ | Χ | Χ |
nlp分词是总能给你惊喜的一种分词方式.
它可以识别出未登录词.但是它也有它的缺点.速度比较慢.稳定性差.ps:我这里说的慢仅仅是和自己的其他方式比较.应该是40w字每秒的速度吧.
个人觉得nlp的适用方式.1.语法实体名抽取.未登录词整理.只要是对文本进行发现分析等工作
NLP分词具有什么功能| 用户自定义词典 | 数字识别 | 人名识别 | 机构名识别 | 新词发现 |
|---|---|---|---|---|
| √ | √ | √ | √ | √ |
面向索引的分词是什么
面向索引的分词。故名思议就是适合在lucene等文本检索中用到的分词。 主要考虑以下两点
- 召回率
- 召回率是对分词结果尽可能的涵盖。比如对“上海虹桥机场南路” 召回结果是[上海/ns, 上海虹桥机场/nt, 虹桥/ns, 虹桥机场/nz, 机场/n, 南路/nr]
- 准确率
- 其实这和召回本身是具有一定矛盾性的Ansj的强大之处是很巧妙的避开了这两个的冲突 。比如我们常见的歧义句“旅游和服务”->对于一般保证召回 。大家会给出的结果是“旅游 和服 服务” 对于ansj不存在跨term的分词。意思就是。召回的词只是针对精准分词之后的结果的一个细分。比较好的解决了这个问题
分词具有什么功能
| 用户自定义词典 | 数字识别 | 人名识别 | 机构名识别 | 新词发现 |
|---|---|---|---|---|
| √ | √ | √ | Χ | Χ |
Ansj词性标注是基于HMM的。主要利用了ngram的方式,相对而言作的还是比较粗
Ansj分词可以说是一个ictclas的Java版本,基本原理一致,只不过在分词优化算法上做了一些改进。
实现分词有以下几个步骤:
- 全切分,原子切分;
- N最短路径的粗切分,根据隐马尔科夫模型和viterbi算法,达到最优路径的规划;
- 人名识别;
- 系统词典补充;
- 用户自定义词典的补充;
- 词性标注(可选)
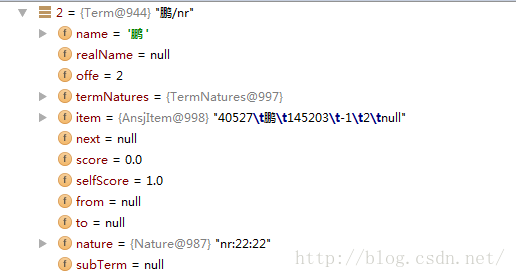
private static final long serialVersionUID = 1L;进入Graph构建最短路径,Graph的类成员:
// 当前词
private String name;
//
private String realName;
// 当前词的起始位置
private int offe;
// 词性列表
private TermNatures termNatures = TermNatures.NULL;
// 词性列表
private AnsjItem item = AnsjItem.NULL;
// 同一行内数据
private Term next;
// 分数
private double score = 0;
// 本身分数
private double selfScore = 1;
// 起始位置
private Term from;
// 到达位置
private Term to;
// 本身这个term的词性.需要在词性识别之后才会有值,默认是空
private Nature nature = Nature.NULL;
private List<Term> subTerm = null;
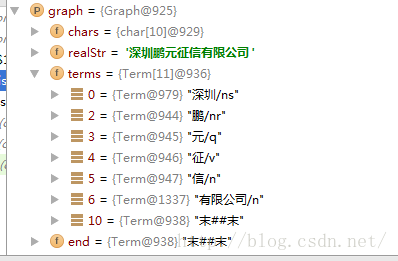
public char[] chars = null;
public String realStr = null;
public Term[] terms = null;
protected Term end = null;
protected Term root = null;
protected static final String E = "末##末";
protected static final String B = "始##始";
// 是否有人名
public boolean hasPerson;
// 是否有数字
public boolean hasNum;
28145 深 156288 -1 2 {a=103, an=2, d=34, j=9, ng=0}

protected String name;所有实词都是status是3的base都是65536.
protected byte status;
protected int base = 65536;
protected int index;
protected int check;
default:
start = i;
end = i;
c = chars[start];
while (IN_SYSTEM[c] > 0) {
end++;
if (++i >= endOffe)
break;
c = chars[i];
}
if (start == end) {
gp.addTerm(new Term(String.valueOf(c), i, TermNatures.NULL));
continue;
}
gwi.setChars(chars, start, end);
while ((str = gwi.allWords()) != null) {
gp.addTerm(new Term(str, gwi.offe, gwi.getItem()));
}
/**
* 如果未分出词.以未知字符加入到gp中
*/
if (IN_SYSTEM[c] > 0 || status(c) > 3 || Character.isHighSurrogate(chars[i]) ) {
i -= 1;
} else {
gp.addTerm(new Term(String.valueOf(c), i, TermNatures.NULL));
}
break;
}
/**从前往后遍历打分,逻辑为
* 干涉性增加相对权重
*
* @param relationMap
*/
public void walkPath(Map<String, Double> relationMap) {
Term term = null;
// BEGIN先行打分
merger(root, 0, relationMap);
// 从第一个词开始往后打分
for (int i = 0; i < terms.length; i++) {
term = terms[i];
while (term != null && term.from() != null && term != end) {
int to = term.toValue();
merger(term, to, relationMap);
term = term.next();
}
}
optimalRoot();
}
/**计算的结果是:
* 具体的遍历打分方法
*
* @param i
* 起始位置
* @param j
* 起始属性
* @param to
*/
private void merger(Term fromTerm, int to, Map<String, Double> relationMap) {
Term term = null;
if (terms[to] != null) {
term = terms[to];
while (term != null) {
// 关系式to.set(from)
term.setPathScore(fromTerm, relationMap);
term = term.next();
}
} else {
char c = chars[to];
TermNatures tn = DATDictionary.getItem(c).termNatures;
if (tn == null || tn == TermNatures.NULL) {
tn = TermNatures.NULL;
}
terms[to] = new Term(String.valueOf(c), to, tn);
terms[to].setPathScore(fromTerm, relationMap);
}
}
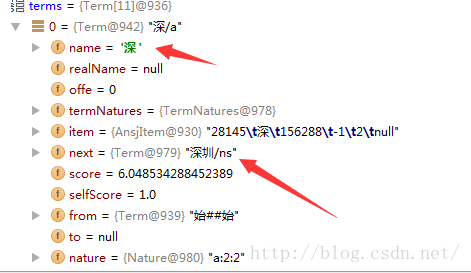
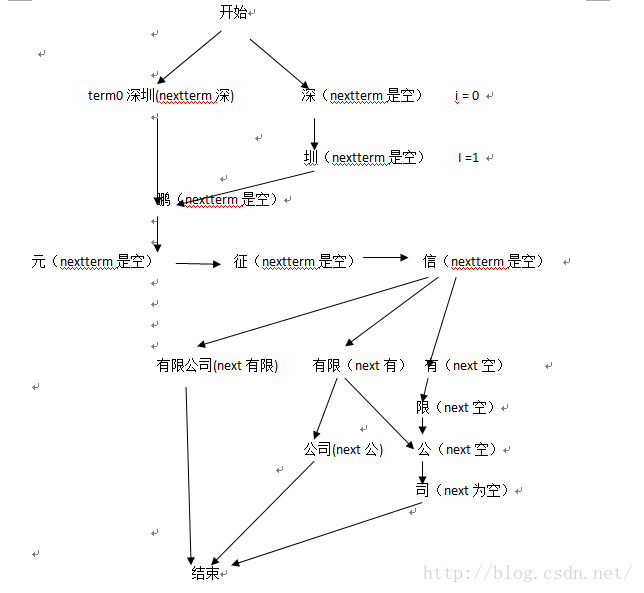
// 维特比进行最优路径的构建如“深”:next:深圳;
double score = MathUtil.compuScore(from, this, relationMap);


旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)